文章目录
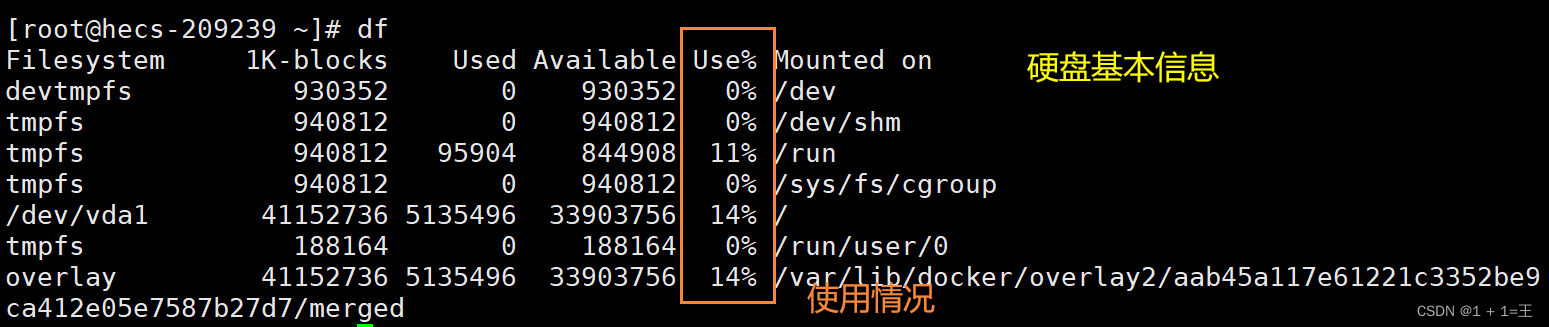
df命令常用选项如下:
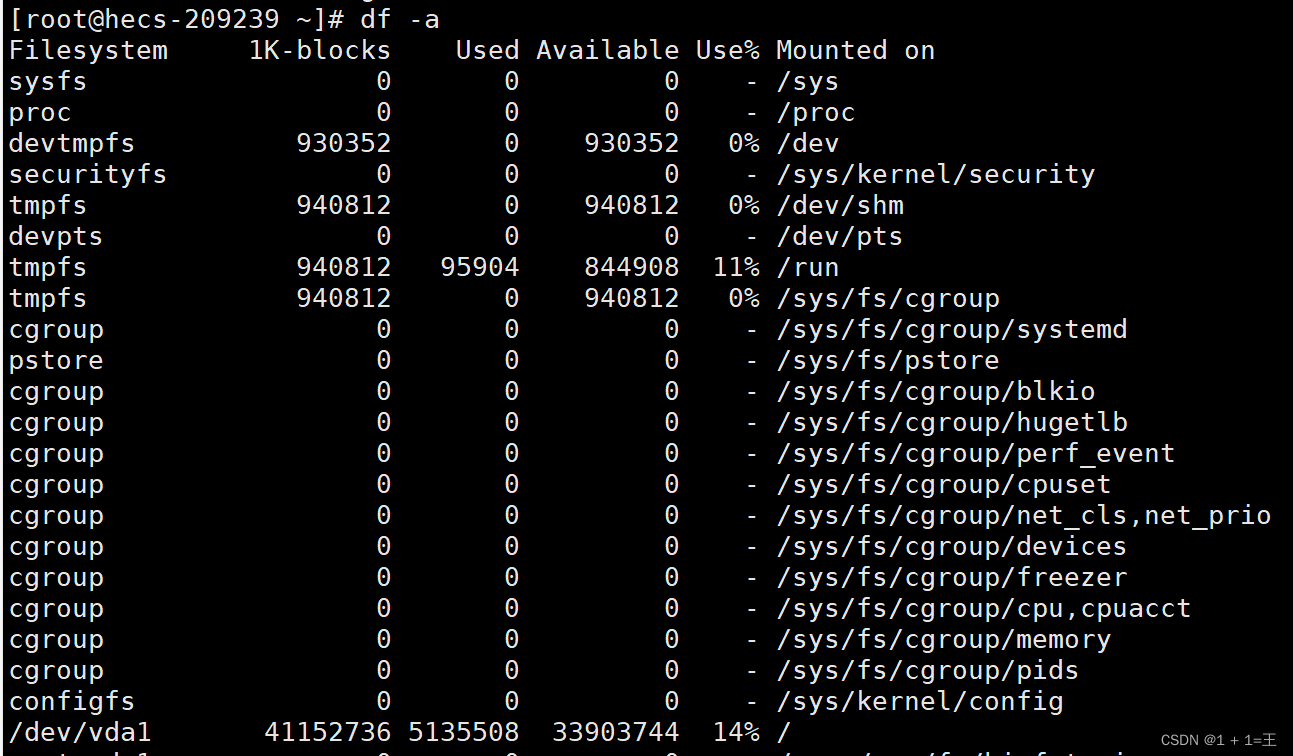
-a: 显示所有文件系统的磁盘使用情况
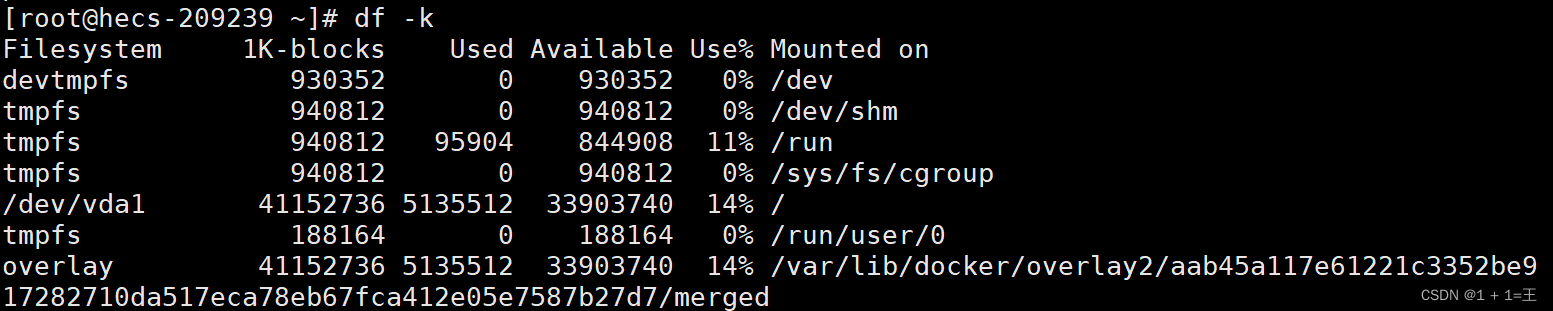
-k: 以k字节为单位显示.
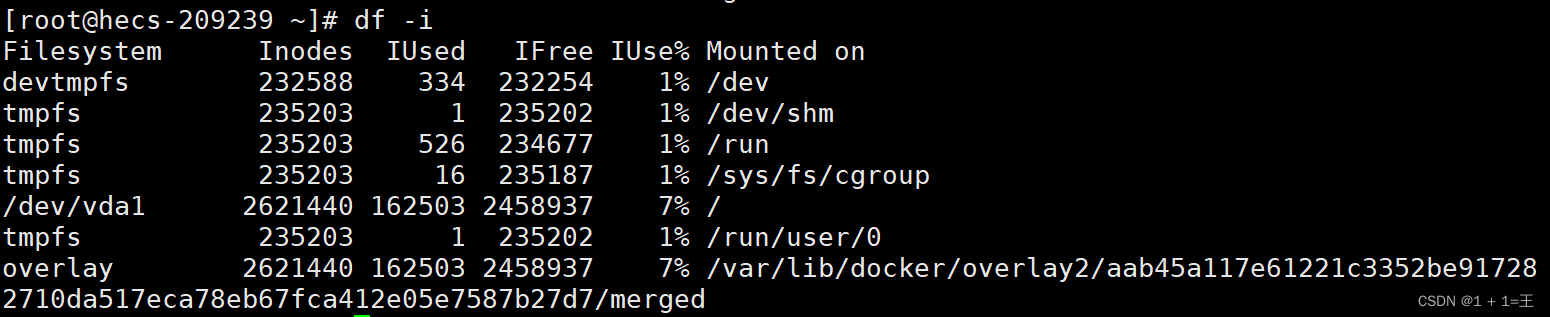
-i: 显示i节点信息,而不是磁盘块.
-t: 显示各指定类型的文件系统的磁盘空间使用情况.
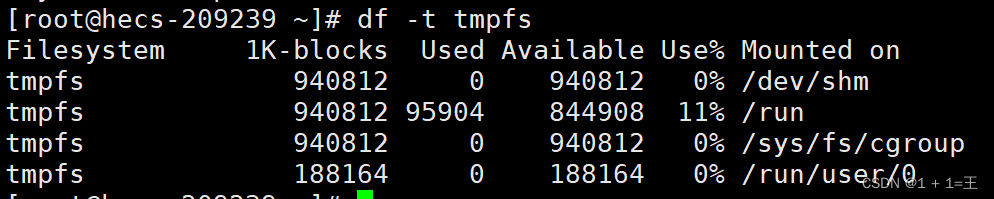
-x: 列出不是某一指定类型文件系统的磁盘空间使用情况(与t选项相反).

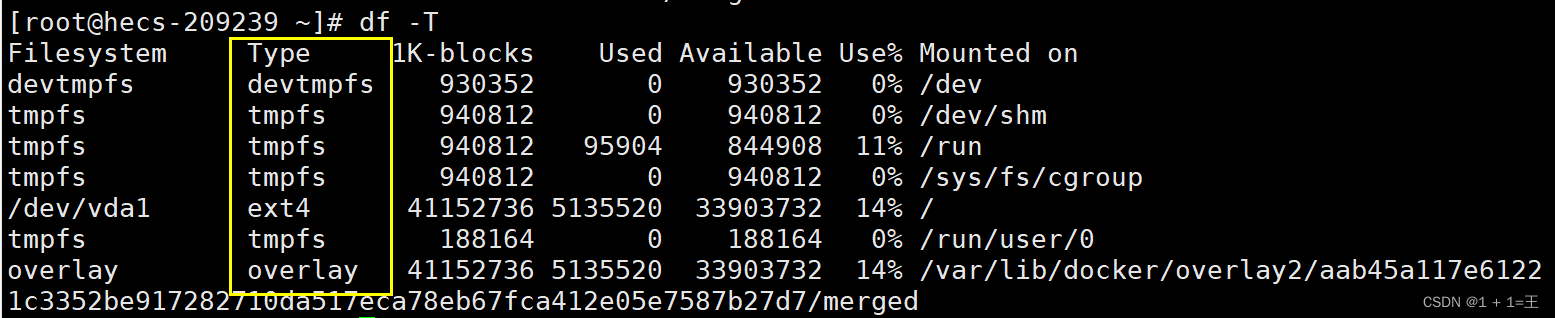
-T: 显示文件系统类型.

| 参数 | 说明 |
|---|---|
| -b | 以Byte为单位显示内存使用情况。 |
| -k | 以KB为单位显示内存使用情况。 |
| -m | 以MB为单位显示内存使用情况。 |
| -o | 不显示缓冲区调节列。 |
| -s<间隔秒数> | 持续观察内存使用状况。 |
| -t | 显示内存总和列。 |
| -V | 显示版本信息。 |
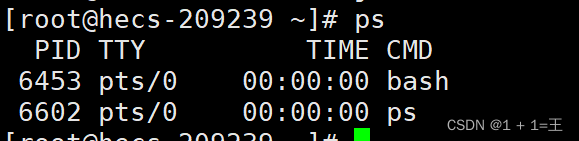
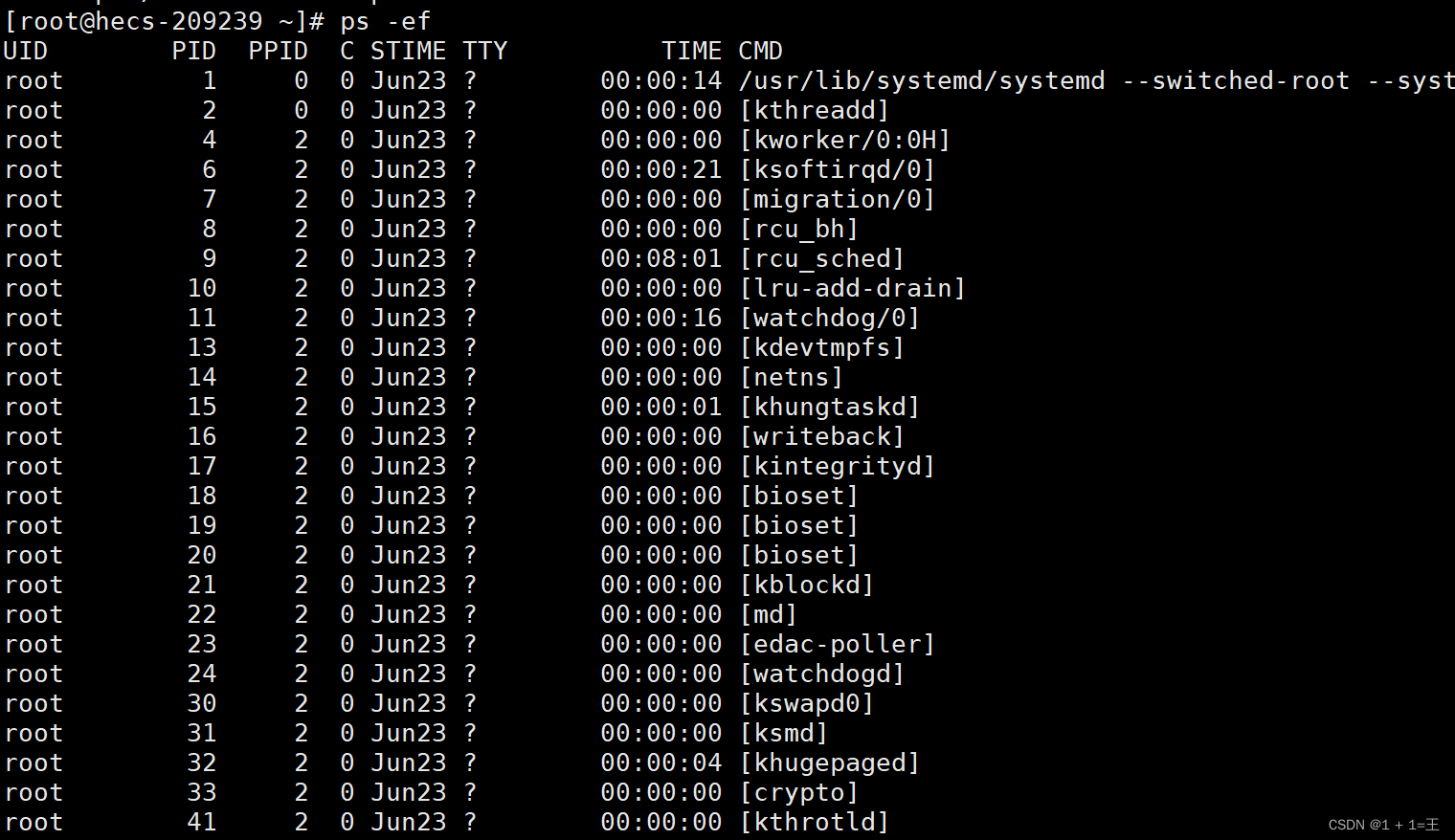
不带任何参数的ps命令,只输出用户自己的进程信息。
查看整个操作系统的进程需要使用 -ef参数:
ps -ef
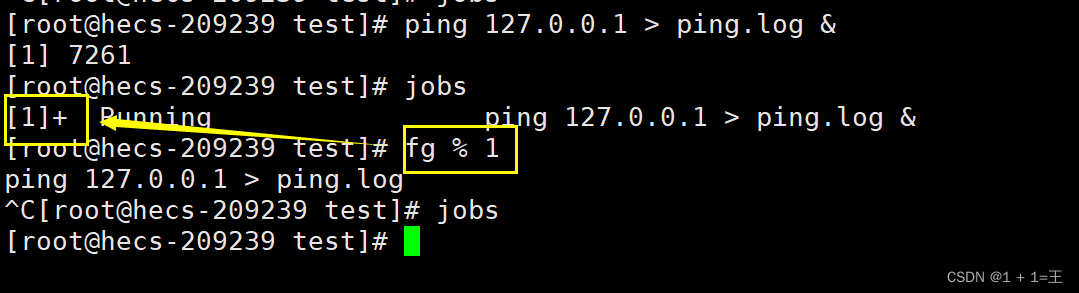
先使用“&”执行一个后台进程:
ping 127.0.0.1 > ping.log &

使用jobs命令查看后台进程:

fg % 进程号
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
我正在使用Ruby解决一些ProjectEuler问题,特别是这里我要讨论的问题25(Fibonacci数列中包含1000位数字的第一项的索引是多少?)。起初,我使用的是Ruby2.2.3,我将问题编码为:number=3a=1b=2whileb.to_s.length但后来我发现2.4.2版本有一个名为digits的方法,这正是我需要的。我转换为代码:whileb.digits.length当我比较这两种方法时,digits慢得多。时间./025/problem025.rb0.13s用户0.02s系统80%cpu0.190总计./025/problem025.rb2.19s用户0.0
我正在寻找一个用ruby演示计时器的在线示例,并发现了下面的代码。它按预期工作,但这个简单的程序使用30Mo内存(如Windows任务管理器中所示)和太多CPU有意义吗?非常感谢deftime_blockstart_time=Time.nowThread.new{yield}Time.now-start_timeenddefrepeat_every(seconds)whiletruedotime_spent=time_block{yield}#Tohandle-vesleepinteravalsleep(seconds-time_spent)iftime_spent
如果用户是所有者,我有一个条件来检查说删除和文章。delete_articleifuser.owner?另一种方式是user.owner?&&delete_article选择它有什么好处还是它只是一种写作风格 最佳答案 性能不太可能成为该声明的问题。第一个要好得多-它更容易阅读。您future的自己和其他将开始编写代码的人会为此感谢您。 关于ruby-on-rails-如果条件与&&,是否有任何性能提升,我们在StackOverflow上找到一个类似的问题:
我编写了一个Ruby应用程序,它可以解析来自不同格式html、xml和csv文件的源中的大量数据。我如何找出代码的哪些区域花费的时间最长?有没有关于如何提高Ruby应用程序性能的好资源?或者您是否有任何始终遵循的性能编码标准?例如,你总是用加入你的字符串吗?output=String.newoutput或者你会使用output="#{part_one}#{part_two}\n" 最佳答案 好吧,有一些众所周知的做法,例如字符串连接比“#{value}”慢得多,但是为了找出您的脚本在哪里消耗了大部分时间或比所需时间更多,您需要进行分
LL库和HAL库简介LL:Low-Layer,底层库HAL:HardwareAbstractionLayer,硬件抽象层库LL库和hal库对比,很精简,这实际上是一个精简的库。LL库的配置选择如下:在STM32CUBEMX中,点击菜单的“ProjectManager”–>“AdvancedSettings”,在下面的界面中选择“AdvancedSettings”,然后在每个模块后面选择使用的库总结:1、如果使用的MCU是小容量的,那么STM32CubeLL将是最佳选择;2、如果结合可移植性和优化,使用STM32CubeHAL并使用特定的优化实现替换一些调用,可保持最大的可移植性。另外HAL和L
Linux操作系统——网络配置与SSH远程安装完VMware与系统后,需要进行网络配置。第一个目标为进行SSH连接,可以从本机到VMware进行文件传送,首先需要进行网络配置。1.下载远程软件首先需要先下载安装一款远程软件:FinalShell或者xhell7FinalShellxhell7FinalShell下载:Windows下载http://www.hostbuf.com/downloads/finalshell_install.exemacOS下载http://www.hostbuf.com/downloads/finalshell_install.pkg2.配置CentOS网络安装好
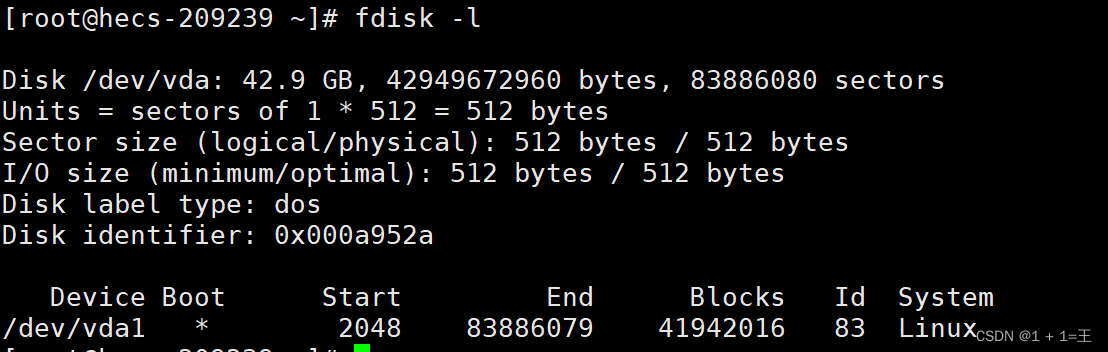
文章目录一基础定义二创建逻辑卷2-1准备物理设备2-2创建物理卷2-3创建卷组2-4创建逻辑卷2-5创建文件系统并挂载文件三扩展卷组和缩减卷组3-1准备物理设备3-2创建物理卷3-3扩展卷组3-4查看卷组的详细信息以验证3-5缩减卷组四扩展逻辑卷4-1检查卷组是否有可用的空间4-2扩展逻辑卷4-3扩展文件系统五删除逻辑卷5-1备份数据5-2卸载文件系统5-3删除逻辑卷5-4删除卷组5-5删除物理卷六LVM逻辑卷缩容6-1缩容注意事项6-2标准缩容步骤一基础定义LVM,LogicalVolumeManger,逻辑卷管理,Linux磁盘分区管理的一种机制,建立在硬盘和分区上的一个逻辑层,提高磁盘分
如何在Ruby中获取linux系统(这必须适用于Fedora、Ubuntu等)的软件/硬件信息? 最佳答案 Chef背后的优秀人才,拥有一颗名为Ohai的优秀gemhttps://github.com/opscode/ohai以散列形式返回系统信息,例如操作系统、内核、规范、fqdn、磁盘、空间、内存、用户、接口(interface)、sshkey等。它非常完整,非常好。它还会安装命令行二进制文件(也称为ohai)。 关于ruby-如何在Ruby中获取linux系统信息,我们在Stack
我在LinuxMint17.2上。我最近使用apt-getpurgeruby删除了ruby。然后我安装了rbenv然后rbenvinstall2.3.0所以现在,~/.rbenv/versions/2.3.0/bin/ruby存在。但是现在,我无法执行geminstallrubocop。我明白了:$geminstallrubocoprbenv:gem:commandnotfoundThe`gem'commandexistsintheseRubyversions:2.3.0但是我可以~/.rbenv/versions/2.3.0/bin/geminstallrubocop。但是,