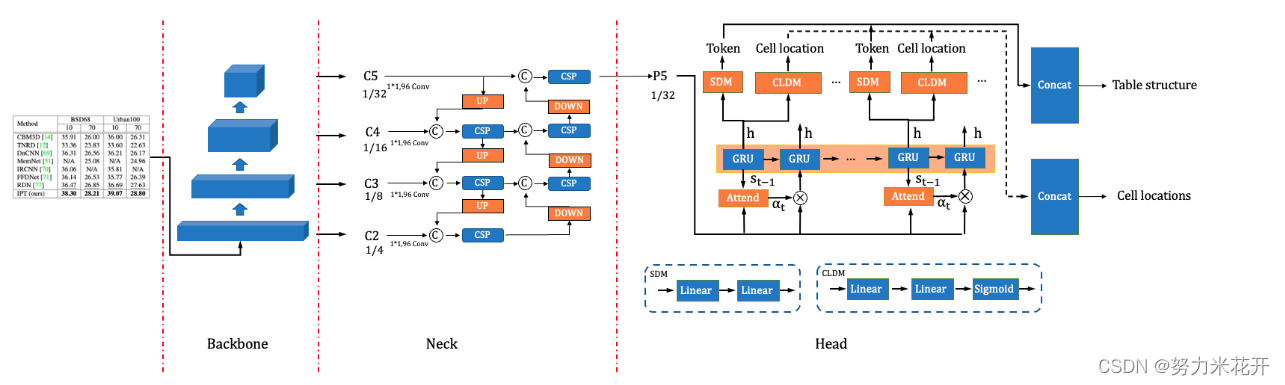
百度飞桨202210更新的表格识别模型SLENET(Structure Location Alignment Network)。
官方给出的优化点如下:
PP-LCNet:CPU 友好型轻量级骨干网络
CSP-PAN:轻量级高低层特征融合模块
SLAHead:结构与位置信息对齐的特征解码模块
在PubTabNet英文表格识别数据集上的消融实验如下:
| 策略 | Acc | TEDS | 推理速度(CPU+MKLDNN) | 模型大小 |
|---|---|---|---|---|
| TableRec-RARE | 71.73% | 93.88% | 779ms | 6.8M |
| +PP-LCNet | 74.71% | 94.37% | 778ms | 8.7M |
| +CSP-PAN | 75.68% | 94.72% | 708ms | 9.3M |
| +SLAHead | 77.70% | 94.85% | 766ms | 9.2M |
| +MergeToken | 76.31% | 95.89% | 766ms | 9.2M |
在PubtabNet英文表格识别数据集上,和其他方法对比如下:
| 策略 | Acc | TEDS | 推理速度(CPU+MKLDNN) | 模型大小 |
|---|---|---|---|---|
| TableMaster | 77.90% | 96.12% | 2144ms | 253.0M |
| TableRec-RARE | 71.73% | 93.88% | 779ms | 6.8M |
| SLANet | 76.31% | 95.89% | 766ms | 9.2M |
以上数据来自官方github主页。
下面详细介绍一些网络的结构
首先看一下前处理操作
主要的图片前处理操作包括
ResizeTableImage {'max_len': 1000, }
PaddingTableImage 'size': [1000, 1000]
NormalizeImage {
'std': [0.229, 0.224, 0.225],
'mean': [0.485, 0.456, 0.406],
'scale': '1./255.',
'order': 'hwc'
}
ToCHWImage
KeepKeys {'keep_keys': ['image', 'shape']}
从上面的配置就可以看出对图片的预处理操作,具体就不展开了。
网络代码保存在ppocr/modeling/backbones/PPLCNet中。
主要的结构是类似典型的FPN网络,但是在细节上做了一些处理。熟悉FPN网络的同学可以直接通过下面的配置信息看到网络的结构。
PP-LCNet是结合Intel-CPU端侧推理特性而设计的轻量高性能骨干网络,该方案在图像分类任务上取得了比ShuffleNetV2、MobileNetV3、GhostNet等轻量级模型更优的“精度-速度”均衡。PP-StructureV2中,我们采用PP-LCNet作为骨干网络,表格识别模型精度从71.73%提升至72.98%;同时加载通过SSLD知识蒸馏方案训练得到的图像分类模型权重作为表格识别的预训练模型,最终精度进一步提升2.95%至74.71%。
主要的特点是:
"blocks2":
# k, in_c, out_c, s, use_se
[[3, 16, 32, 1, False]],
"blocks3": [[3, 32, 64, 2, False], [3, 64, 64, 1, False]],
"blocks4": [[3, 64, 128, 2, False], [3, 128, 128, 1, False]],
"blocks5":
[[3, 128, 256, 2, False], [5, 256, 256, 1, False], [5, 256, 256, 1, False],
[5, 256, 256, 1, False], [5, 256, 256, 1, False], [5, 256, 256, 1, False]],
"blocks6": [[5, 256, 512, 2, True], [5, 512, 512, 1, True]]
}
对骨干网络提取的特征进行融合,可以有效解决尺度变化较大等复杂场景中的模型预测问题。
早期,FPN模块被提出并用于特征融合,但是它的特征融合过程仅包含单向(高->低),融合不够充分。CSP-PAN基于PAN进行改进,在保证特征融合更为充分的同时,使用CSP block、深度可分离卷积等策略减小了计算量。在表格识别场景中,我们进一步将CSP-PAN的通道数从128降低至96以降低模型大小。最终表格识别模型精度提升0.97%至75.68%,预测速度提升10%。
-----以上描述来自官方的github介绍
输入为block3-block6层的输出,输入的通道数量分别为[64,128,256,512]
输出为一个包含96个通道的feature map。网络默认采用DWlayer(也就是deepwise+pointwise层,不过这里的激活函数默认leaky_relu),用于减少参数量。
四个输入层首先各自通过一个普通1*1卷积层+BN+hardwish激活函数,将每层的输出通道数量都统一为96。
CSP-PAN网络在backbone网路的基础上进行了依次自上而下的特征融合,又进行了依次自下而上的特征融合。通过融合低级与高级信息来增强不同 scale 的特征。因为它由分离的、仅需要最小计算量的(深度可分离卷积)卷积构成,所以即使增加了额外的自下而上的融合操作,计算量也没有增加很多。
在自上而下的上采样过程采用最近邻插值法实现,比如
{
b
l
o
c
k
6
上
采
样
⊕
b
l
o
c
k
5
}
→
C
S
P
l
a
y
e
r
→
i
n
n
e
r
3
\{block6上采样 \oplus block5\}\to CSPlayer\to inner3
{block6上采样⊕block5}→CSPlayer→inner3;
{
i
n
n
e
r
3
上
采
样
⊕
b
l
o
c
k
4
}
→
C
S
P
l
a
y
e
r
→
i
n
n
e
r
2
\{inner3上采样\oplus block4\} \to CSPlayer\to inner2
{inner3上采样⊕block4}→CSPlayer→inner2;
{
i
n
n
e
r
2
上
采
样
⊕
b
l
o
c
k
3
}
→
C
S
P
l
a
y
e
r
→
i
n
n
e
r
1
\{inner2上采样\oplus block3\} \to CSPlayer\to inner1
{inner2上采样⊕block3}→CSPlayer→inner1
原本的block6的特征层保存,记为
i
n
n
e
r
4
inner4
inner4.
这样就可以得到CSP网络中自上而下的特征列表[inner1,inner2,inner3,inner4].
这里提到的CSPLayer结构如下所示。

其中的short_conv和main_conv都是简单的
1
∗
1
卷
积
→
B
N
→
H
a
r
d
w
i
s
h
激
活
1*1卷积\to BN\to Hardwish激活
1∗1卷积→BN→Hardwish激活
输出通道数量为输入的一半,用于进一步提取特征。其中main_conv输出进入一个DarknetBottleneck结构中,这个结构通过一个
1
∗
1
1*1
1∗1卷积进一步压缩特征,然后通过一个deepwise+pointwise结构,其中deepwise的卷积尺寸为
5
∗
5
5*5
5∗5,进一步提升了特征的感受野区域。最终将main_conv和short_conv中的特征进行concat融合。
CSP结构将原来DenseNet中对于全部feature map的重复梯度计算降低了一半。
TableRec-RARE的TableAttentionHead如下图a所示,TableAttentionHead在执行完全部step的计算后拿到最终隐藏层状态表征(hiddens),随后hiddens经由SDM(Structure Decode Module)和CLDM(Cell Location Decode Module)模块生成全部的表格结构token和单元格坐标。但是这种设计忽略了单元格token和坐标之间一一对应的关系。
PP-StructureV2中,我们设计SLAHead模块,对单元格token和坐标之间做了对齐操作,如下图b所示。在SLAHead中,每一个step的隐藏层状态表征会分别送入SDM和CLDM来得到当前step的token和坐标,每个step的token和坐标输出分别进行concat得到表格的html表达和全部单元格的坐标。此外,考虑到表格识别模型的单元格准确率依赖于表格结构的识别准确,我们将损失函数中表格结构分支与单元格定位分支的权重比从1:1提升到8:1,并使用收敛更稳定的Smoothl1 Loss替换定位分支中的MSE Loss。最终模型精度从75.68%提高至77.7%。
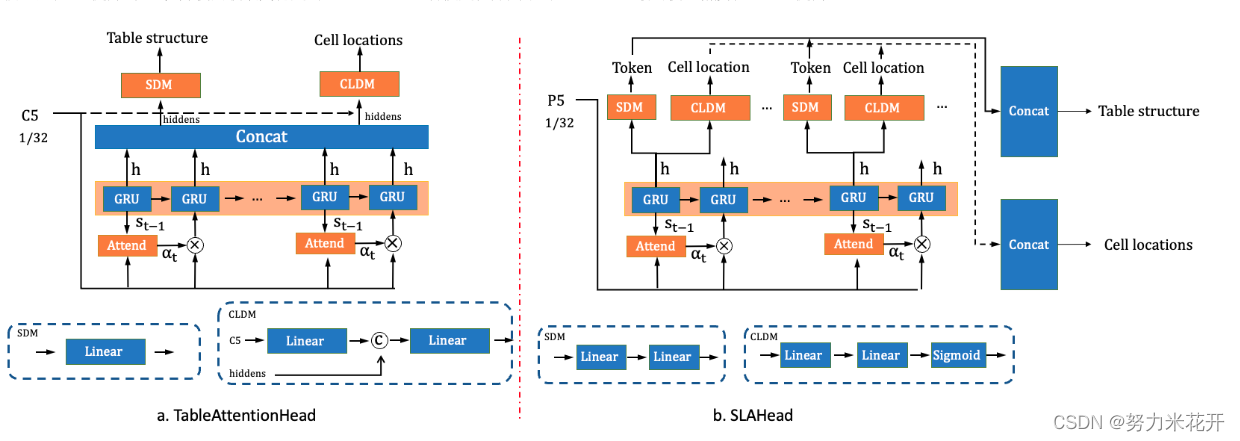
上述内容来自官方介绍
网络的核心部分是一个 G R U C e l l GRUCell GRUCell这是一个典型的RNN网络结构单元。因此预测表格结构任务是一个预测xml元素序列的任务。
只采用Head层的最后一层输出作为head层的输入。因此输入为[B,C,H,W]的特征图,通过转换轴等方式变为[B,H*W,C],这样的序列就变为[B,T,C]的输入,可以将第二个轴看为是时间片,每个时间片的特征为C-embedding。
那么怎么体现输入的注意力机制呢?
通过下面的结构实现,假设每个时间可能的输出xml元素类型有N个分类选项。
<thead>
<tr>
<td>
</td>
</tr>
</thead>
<tbody>
</tbody>
<td
colspan="5"
>
colspan="2"
colspan="3"
rowspan="2"
colspan="4"
colspan="6"
rowspan="3"
colspan="9"
colspan="10"
colspan="7"
rowspan="4"
rowspan="5"
rowspan="9"
colspan="8"
rowspan="8"
rowspan="6"
rowspan="7"
rowspan="10"
对于输入input为[B,T,C],这里C为96;前一刻的隐藏层pre_hidden为[B,H],其中H为隐藏层的输出通道数量,这里设置为256。那么通过线性结构将输入input转为[B,T,256],实现隐藏层和输入层的通道统一,然后通过一系列的
线
性
组
合
+
激
活
组
合
+
s
o
f
t
m
a
x
组
合
线性组合+激活组合+softmax组合
线性组合+激活组合+softmax组合得到每个时间片t对于当前预测序列的重要程度,通过矩阵乘法实现注意力机制,最终输出的维度为[B,C],其中C通道的特征可以看成是通过对T个时间片(也就是H*W个特征图元素)进行了权重筛选之后的得到的最终特征。这个特征并不是GRUCell的输入,这个特征需要concat前一个时刻的预测输出元素的one_hot结果,序列预测输出的one_hot表征为[B,N],因此得到的[B,C+N]才是GRU的输入。
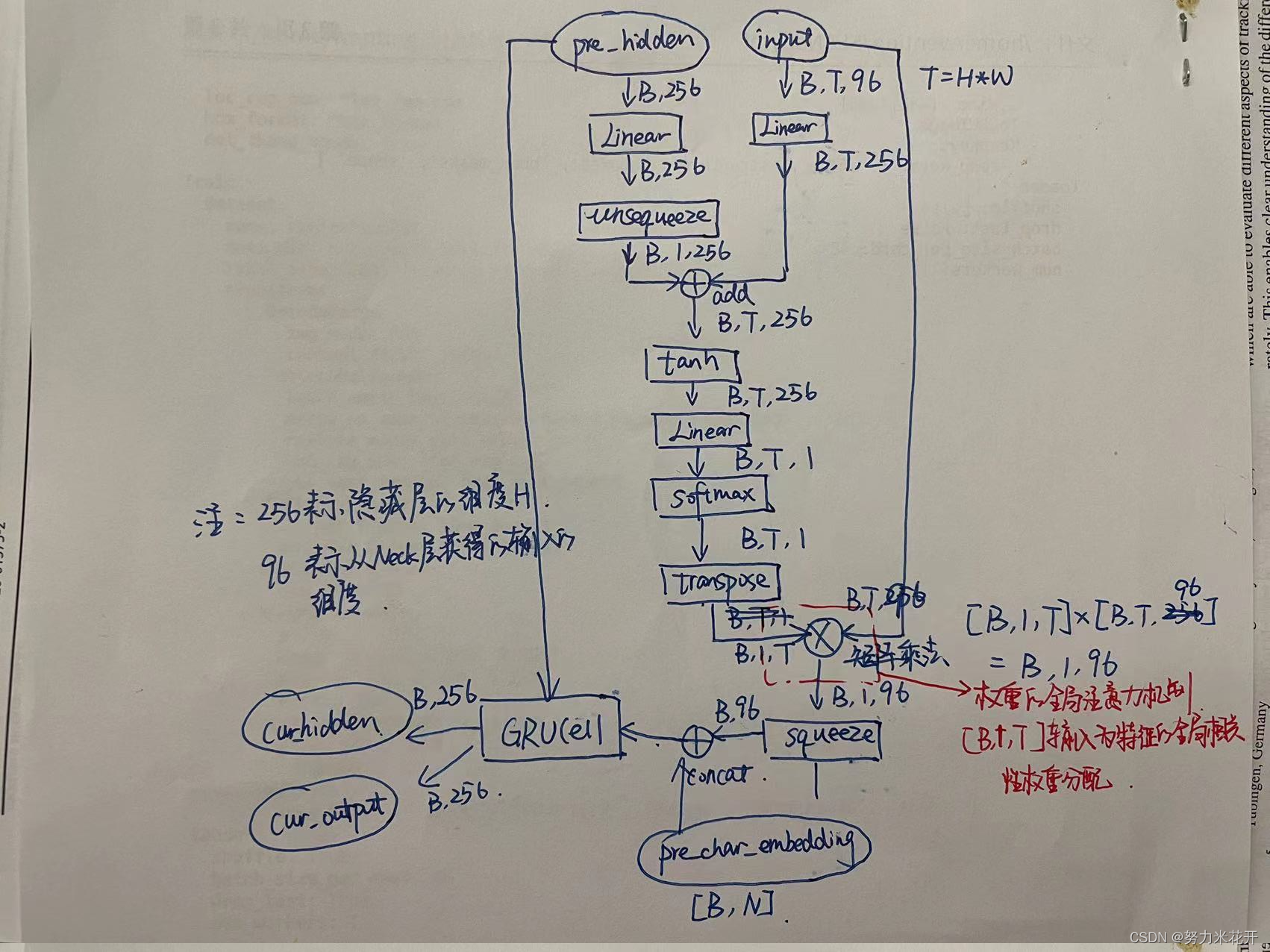
再来重申一遍,GRU的输入有两个,一个是前面提到的[B,C+N]的输入,这个输入既包含了图片特征图的注意力机制输入又包括上一个时间片的预测输入;另一个是上一个时间片的隐藏层输出[B,H]。GRU的输出为当前的隐藏层cur_hidden,维度为[B,H]以及一个当前序列输出output,维度也是[B,H]。
输出output通过两个线性层可以得到[B.N]结构的序列预测输出;也可以通过两个线性层得到[B,8]的单元格坐标输出。这样就得到最终需要的xml结构信息和单元格坐标信息。
对于非训练任务来说,输出output通过两个线性结构转为[B,N],然后通过argmax得到概率最大的那个index作为预测结果,接着通过one_hot编码转为下一个时间片的预测输入;
对于训练任务来说,直接采用GT的对应xml元素的one_hot_enbedding作为下一个时间片的预测输入。
损失函数有两个,一个是预测的结构序列T中每个位置的预测损失,假设每个元素的可能值有N个,对于每个位置而言这就是一个多分类任务,因此采用分类损失函数交叉熵损失来计算,取序列元素的损失均值作为最终的structure_los。
第二个损失是每个单元格的坐标预测,这是一个回归任务,因此可以用回归任务的损失函数smooth L1 loss来计算。

最终的损失为两者的权重和
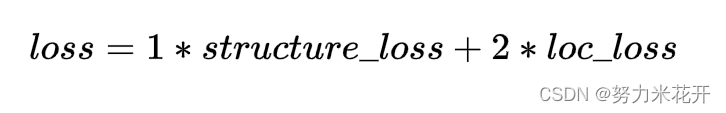
后处理decoder
后处理的输入为一个dict是来自SLAhead输出outputs.
preds[‘structure_probs’]为一个列表[B,T,N],B为batchsize,T为序列预测长度,N为序列元素可能值的数量,其中每个元素为预测的xml标签元素的预测概率;
preds[‘loc_preds’] 对每个preds[‘structure_probs’]元素都唯一生成一个八点坐标(四角坐标),如果这个元素恰为[‘’, ‘<td’, ‘’]中的一个,那么这个坐标信息就是单元格的坐标,其他的标签元素的坐标信息没什么作用,毕竟我们只关心单元格的四点坐标。
采用贪心策略,序列每个位置的预测值为概率最大的值对应的xml标签元素index,通过一个字典得到index对应的标签元素内容。
遍历T中的每个标签元素,如果遇到终止符,则退出,遇到忽略值,则忽略。最终输出序列的xml列表和对应位置八点坐标。
后面会有文字检测文字识别结果和表格结果的匹配过程。这里暂时忽略。
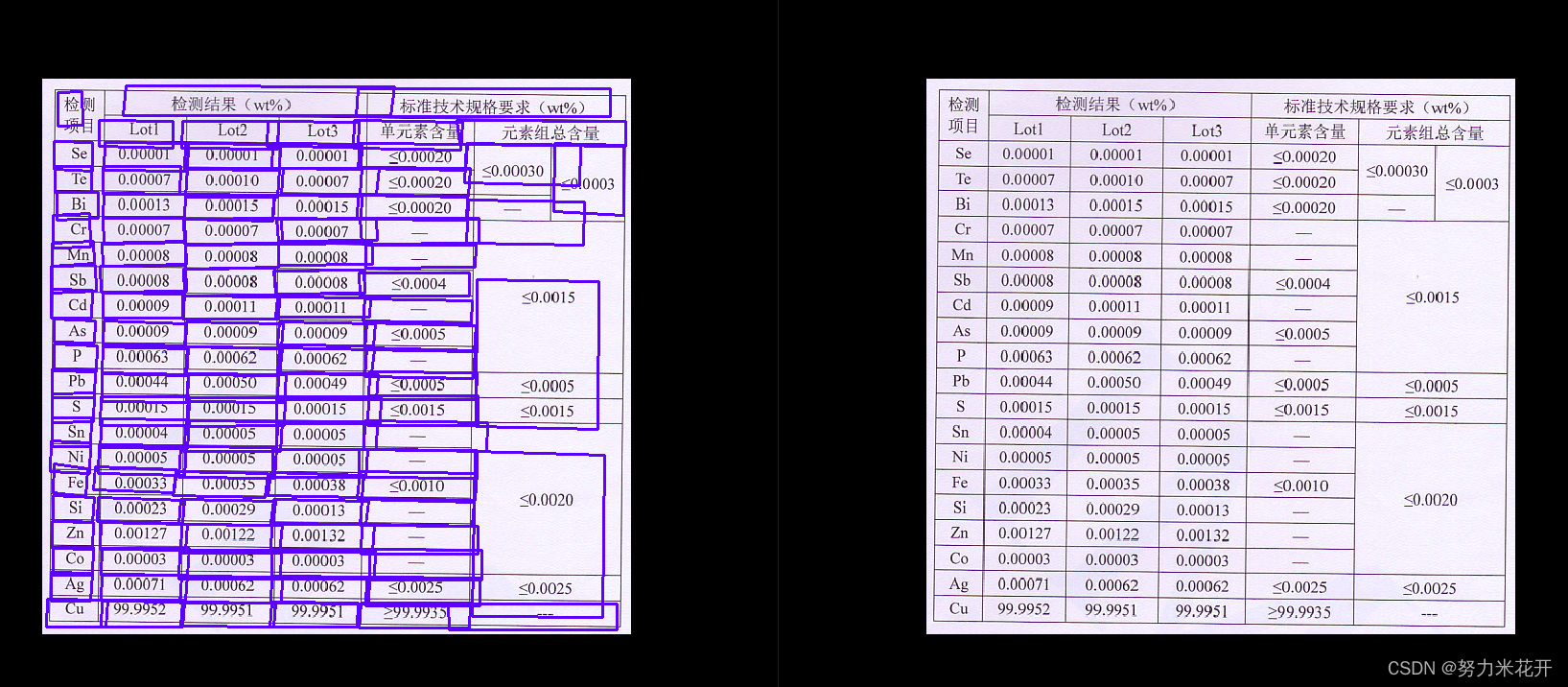
实际使用paddle给出的模型,会发现会与不存在很多跨行的表格图片,效果挺好的。但是对于发票这类图片以及一些稍微复杂一些的表格,效果并没有那么出色。还需要自行训练一下。
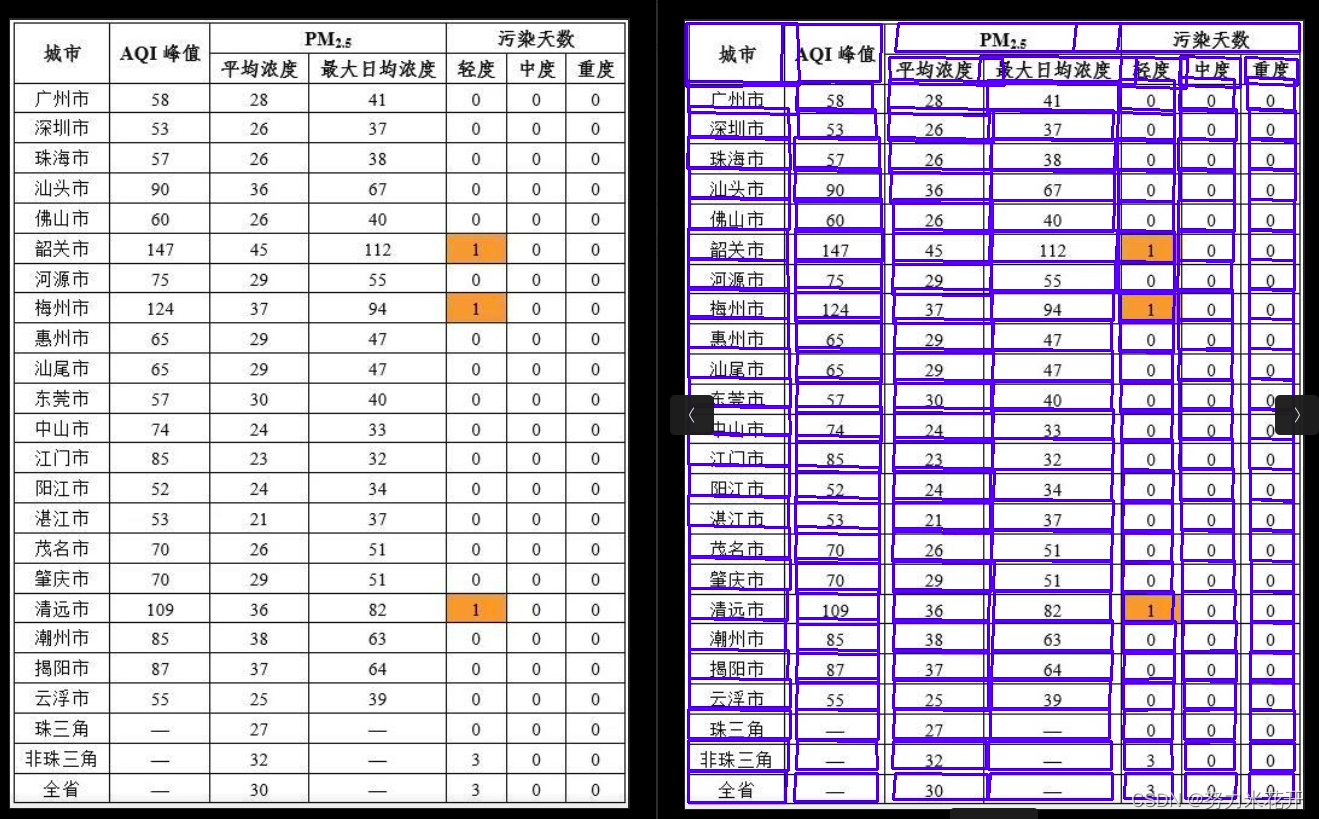
效果不佳的一些例子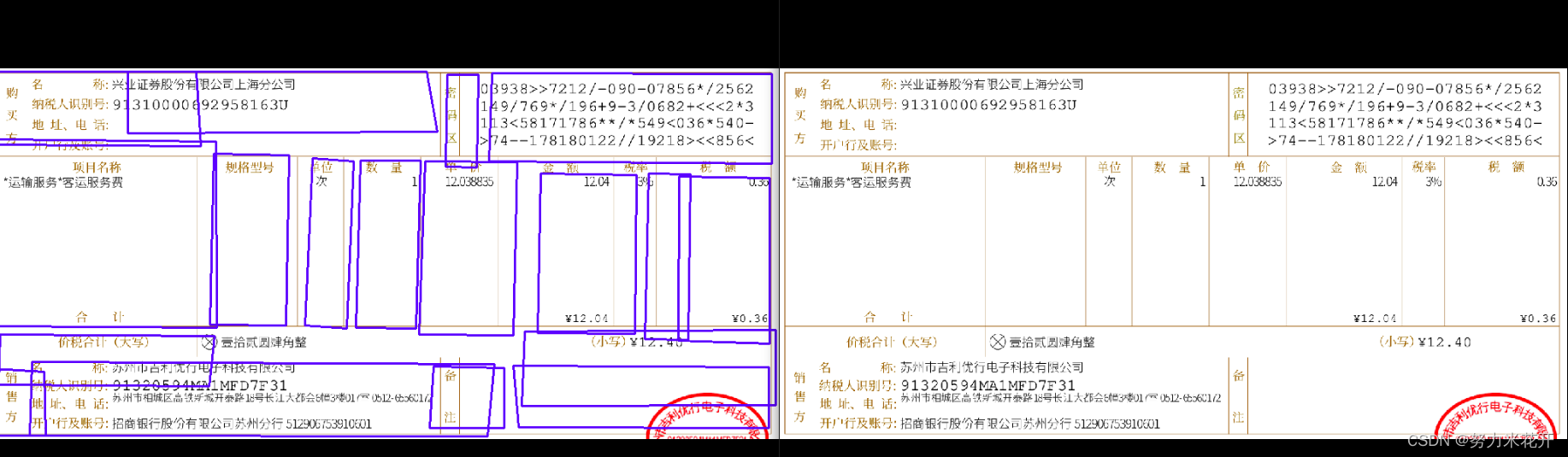
参考文章:
https://github.com/PaddlePaddle/PaddleOCR
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我正在尝试用Prawn生成PDF。在我的PDF模板中,我有带单元格的表格。在其中一个单元格中,我有一个电子邮件地址:cell_email=pdf.make_cell(:content=>booking.user_email,:border_width=>0)我想让电子邮件链接到“mailto”链接。我知道我可以这样链接:pdf.formatted_text([{:text=>booking.user_email,:link=>"mailto:#{booking.user_email}"}])但是将这两行组合起来(将格式化文本作为内容)不起作用:cell_email=pdf.make_c
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
之前说过10之后的版本没有3dScan了,所以还是9.8的版本或者之前更早的版本。 3d物体扫描需要先下载扫描的APK进行扫面。首先要在手机上装一个扫描程序,扫描现实中的三维物体,然后上传高通官网,在下载成UnityPackage类型让Unity能够使用这个扫描程序可以从高通官网上进行下载,是一个安卓程序。点到Tools往下滑,找到VuforiaObjectScanner下载后解压数据线连接手机,将apk文件拷入手机安装然后刚才解压文件中的Media文件夹打开,两个PDF图打印第一张A4-ObjectScanningTarget.pdf,主要是用来辅助扫描的。好了,接下来就是扫描三维物体。将瓶
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
Heroku支持人员告诉我,为了在我的Web应用程序中使用自定义字体(未安装在系统中,您可以在bash控制台中使用fc-list查看已安装的字体)我必须部署一个包含所有字体的.fonts文件夹里面的字体。问题是我不知道该怎么做。我的意思是,我不知道文件名是否必须遵循heroku的任何特殊模式,或者我必须在我的代码中做一些事情来考虑这种字体,或者如果我将它包含在文件夹中它是自动的......事实是,我尝试以不同的方式更改字体的文件名,但根本没有使用该字体。为了提供更多详细信息,我们使用字体的过程是将PDF转换为图像,更具体地说,使用rghostgem。并且最终图像根本不使用自定义字体。在
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
我正在尝试将一个简单的CSV文件读入HTML表格以在浏览器中显示,但我遇到了麻烦。这就是我正在尝试的:Controller:defshow@csv=CSV.open("file.csv",:headers=>true)end查看:输出:NameStartDateEndDateQuantityPostalCode基本上我只获取标题,而不会读取和呈现CSV正文。 最佳答案 这最终成为最终解决方案:Controller:defshow#OpenaCSVfile,andthenreaditintoaCSV::Tableobjectforda