在文章《Apache Beam入门及Java SDK开发初体验》中大概讲了Apapche Beam的简单概念和本地运行,本文将讲解如何把代码运行在GCP Cloud Dataflow上。
通过maven命令来创建项目:
mvn archetype:generate \
-DarchetypeGroupId=org.apache.beam \
-DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \
-DarchetypeVersion=2.37.0 \
-DgroupId=org.example \
-DartifactId=word-count-beam \
-Dversion="0.1" \
-Dpackage=org.apache.beam.examples \
-DinteractiveMode=false
上面会创建一个目录word-count-beam,里面是一个例子项目。做一些简单修改就可以使用了。
先build一次,保证依赖下载成功:
$ mvn clean package
通过IDEA本地运行一下,添加入参如下:
--output=pkslow-beam-counts --inputFile=/Users/larry/IdeaProjects/pkslow-samples/README.md
处理的文件是README.md,输出结果前缀为pkslow-beam-counts:
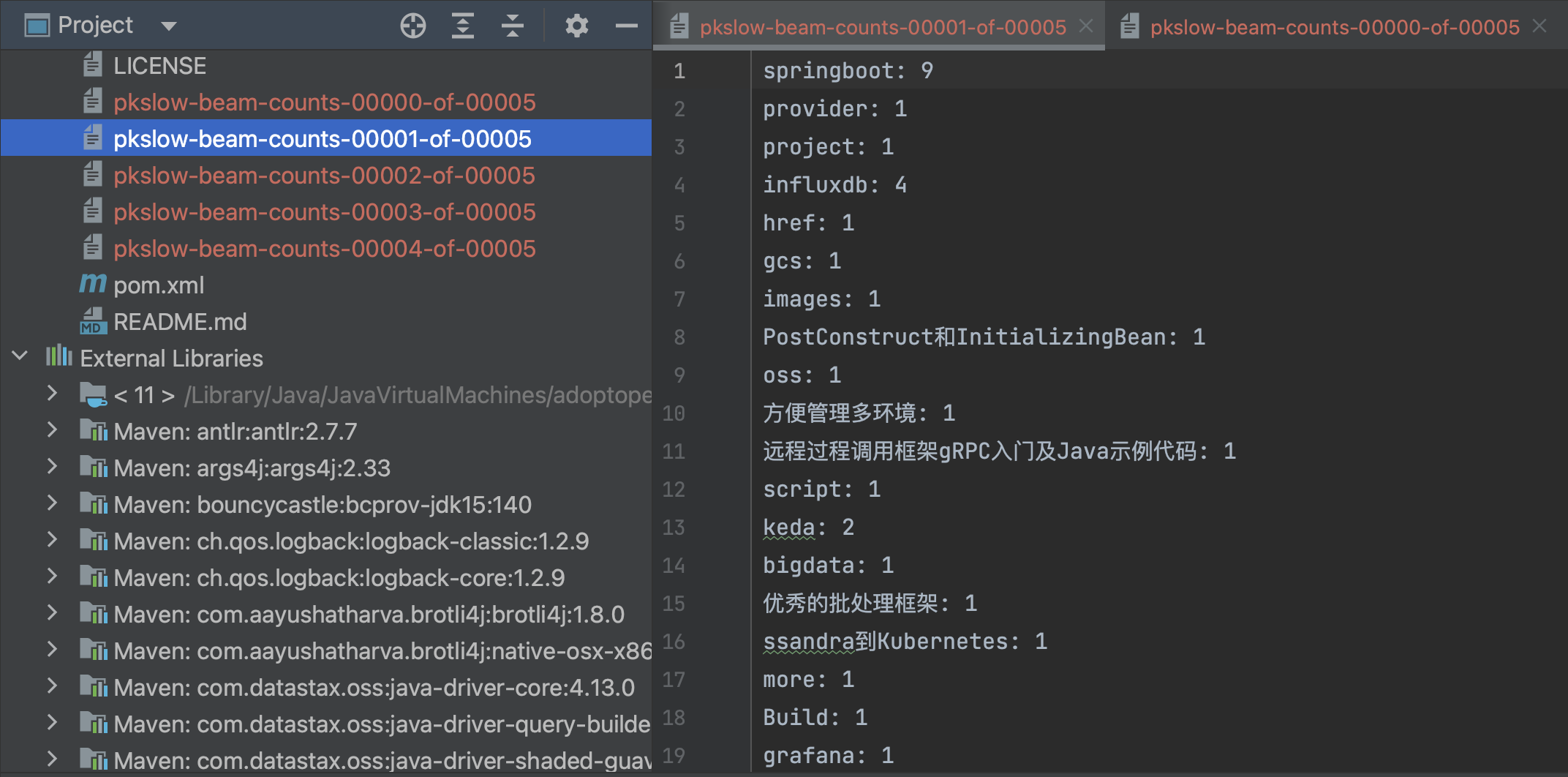
或者通过命令行来运行也可以:
mvn compile exec:java \
-Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--output=pkslow-beam-counts --inputFile=/Users/larry/IdeaProjects/pkslow-samples/README.md"
要有对应的Service Account和key,当然还要有权限;
要打开对应的Service;
创建好对应的Bucket,上传要处理的文件。
然后在本地执行命令如下:
$ mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--runner=DataflowRunner --gcpTempLocation=gs://pkslow-dataflow/temp \
--project=pkslow --region=us-east1 \
--inputFile=gs://pkslow-dataflow/input/README.md --output=gs://pkslow-dataflow//pkslow-counts" \
-Pdataflow-runner
日志比较长,它大概做的事情就是把相关Jar包上传到temp目录下,因为执行的时候要引用。如:
Nov 03, 2022 8:41:48 PM org.apache.beam.runners.dataflow.util.PackageUtil tryStagePackage
INFO: Uploading /Users/larry/.m2/repository/org/apache/commons/commons-compress/1.8.1/commons-compress-1.8.1.jar to gs://pkslow-dataflow/temp/staging/commons-compress-1.8.1-X8oTZQP4bsxsth-9F7E31Z5WtFx6VJTmuP08q9Rpf70.jar
Nov 03, 2022 8:41:48 PM org.apache.beam.runners.dataflow.util.PackageUtil tryStagePackage
INFO: Uploading /Users/larry/.m2/repository/org/codehaus/jackson/jackson-mapper-asl/1.9.13/jackson-mapper-asl-1.9.13.jar to gs://pkslow-dataflow/temp/staging/jackson-mapper-asl-1.9.13-dOegenby7breKTEqWi68z6AZEovAIezjhW12GX6b4MI.jar
查看Bucket,确实有一堆jar包:
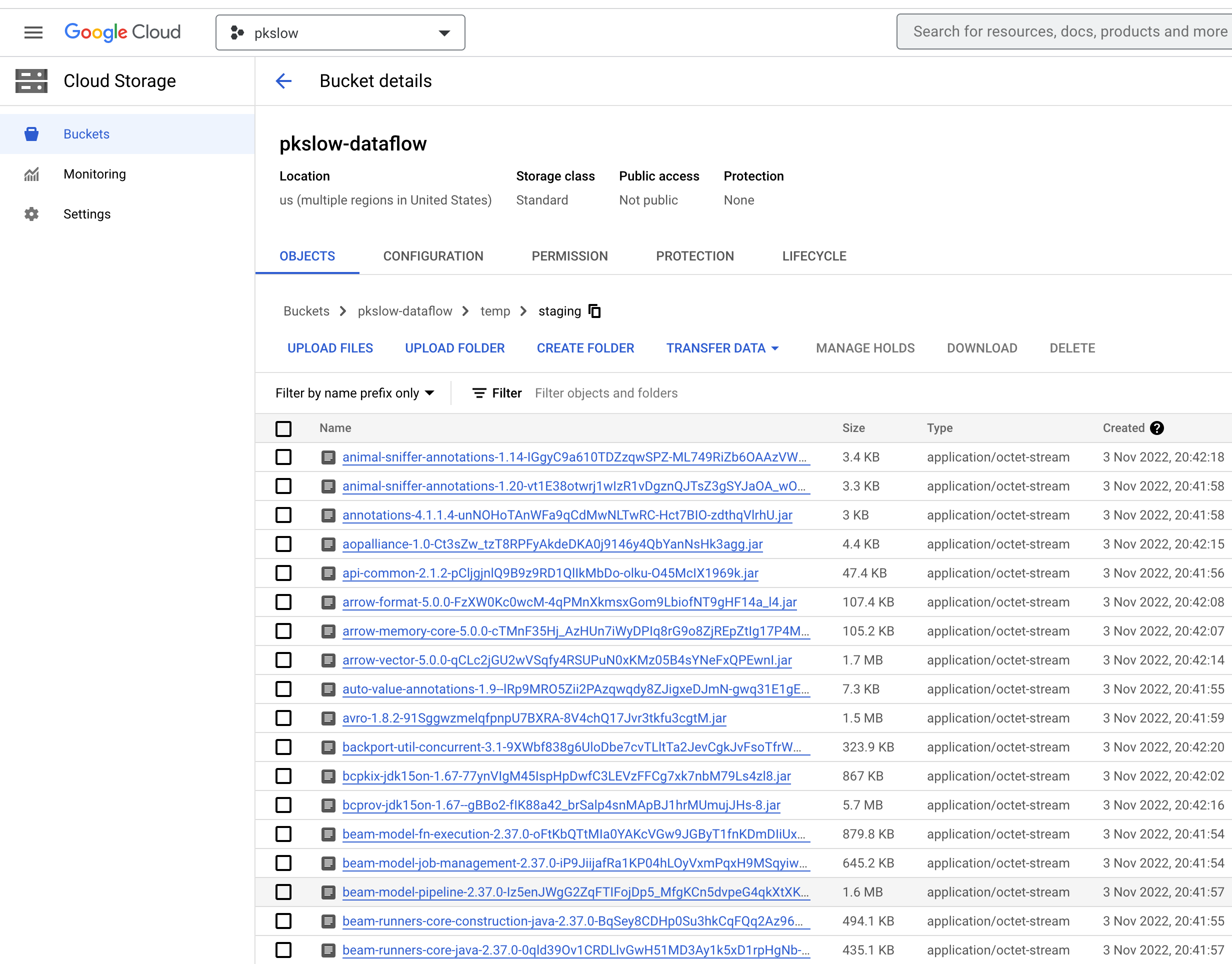
接着会创建dataflow jobs开始工作了。可以查看界面的Jobs如下:
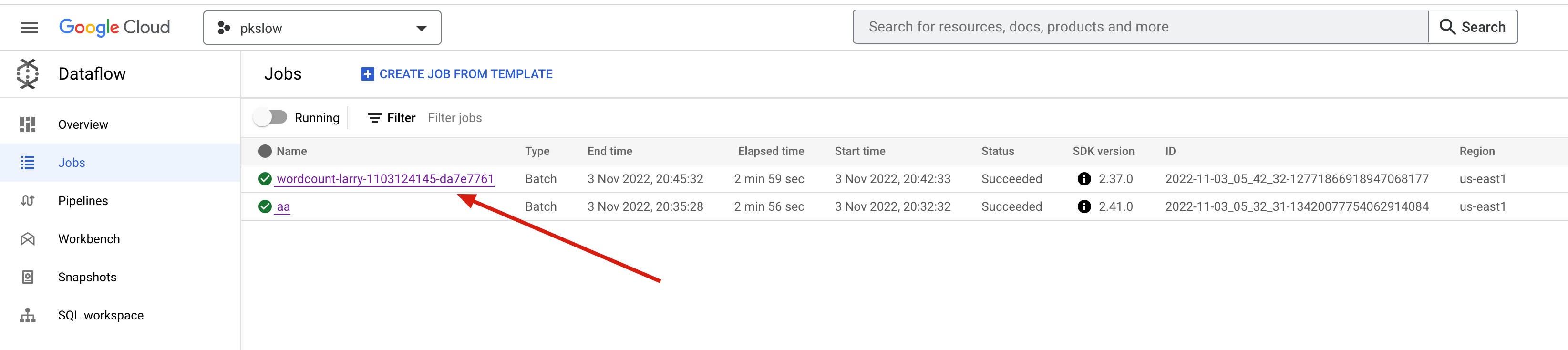
点进去可以看到流程和更多细节:

最后到Bucket查看结果也出来了:

代码请看GitHub: https://github.com/LarryDpk/pkslow-samples
我有以下字符串:a="001;Barbara;122"我拆分成字符串数组:names=a.split(";")names=["001","Barbara","122"]我应该怎么做才能将每个元素另外用''引号括起来?结果应该是names=["'001'","'Barbara'","'122'"]我知道这听起来很奇怪,但我需要它在rubyonrails中进行数据库查询。出于某种原因,如果我的名字在“”引号中,我将无法访问数据库记录。我在数据库中确实有mk1==0006但rails不想以某种方式访问它。但是,它确实访问1222。sql="SELECTmk1,mk2,pk1,pk
我的Rails应用程序在暂存服务器上运行速度非常慢,这让我遇到了一些麻烦。最令人困惑的是每个请求的日志输出的最后一行。看起来View和数据库时间甚至不接近整个渲染时间。在一页上,完成时间大约1000毫秒,View大约450毫秒,数据库大约20毫秒。渲染页面所需的其余时间从何而来? 最佳答案 当事情变得神秘时......分析器是你的friend!分析器将统计哪些方法被调用最多以及每个方法调用花费多长时间。ruby-prof当我在RubyLand时,它会帮我解决这个问题,它会生成一个漂亮的调用图(如果需要,可以是html格式),这使得查
条件:a+b+c=100a,b,cpositiveintegersor0期望的输出:[[0,0,100],[0,1,99],...#allotherpermutations[99,1,0],[100,0,0]] 最佳答案 我会写:(0..100).flat_map{|x|(0..100-x).map{|y|[x,y,100-x-y]}}#=>[[0,0,100],[0,1,99]],...,[99,1,0],[100,0,0]]站点注释1:这是一个经典示例,其中列表推导式大放异彩(如果某处有条件则更是如此)。由于Ruby没有LC,我
所以这很奇怪。我在Ruby1.9.3中,float加法没有像我预期的那样工作。0.3+0.6+0.1=0.99999999999999990.6+0.1+0.3=1我在另一台机器上试过了,得到了同样的结果。知道为什么会发生这种情况吗? 最佳答案 浮点运算是不精确的:它们将结果四舍五入到最接近的可表示浮点值。这意味着每个float操作是:float(aopb)=mathematical(aopb)+rounding-error(aopb)如上式所示,舍入误差取决于操作数a和b。因此,如果您以不同的顺序执行操作,float(float(
在处理相当大的Rails项目时,Zeus是一个很棒的工具,可以缩短Rails应用程序的加载时间并运行测试套件。但是过了一段时间后,我开始在启动zeus的所有项目中都遇到了这个问题:我做了一些研究并尝试了一些资源来解决这个错误,但都没有用。如果有人能指出解决此问题的正确方向,我将不胜感激。我在MacOSX10.8.2上谢谢 最佳答案 这两条评论实际上为我指明了正确的方向:如果ls-a显示.zeus.sock文件而不是做一个简单的删除解决问题是这样的:rm.zeus.sock 关于ruby-
classUserscope:active,->{where(active:true)}end运行rubocop我收到以下警告:Parenthesizetheparam->{where(active:true)}tomakesurethattheblockwillbeassociatedwiththe->methodcall.我完全不知道我的scope定义与这个警告有什么关系。你呢?除了关闭检查之外,我该如何修复警告,因为它目前没有意义? 最佳答案 它要你这样做:scope:active,(->{where(active:true)
我正在使用Ruby的内置CSV生成一些CSV输出。一切正常,但客户希望输出中的名称字段包含双引号,以便输出看起来像输入文件。例如,输入看起来像这样:1,1.1.1.1,"FirstnameLastname",more,fields2,2.2.2.2,"FirstnameLastname,Jr.",more,fieldsCSV的正确输出如下所示:1,1.1.1.1,FirstnameLastname,more,fields2,2.2.2.2,"FirstnameLastname,Jr.",more,fields我知道CSV的做法是正确的,因为它没有双引号第三个字段,只是因为它嵌入了空格,
为什么这个Ruby对象的to_s和inspect方法看起来做同样的事情?p方法调用inspect和puts/print调用to_s来表示对象。如果我跑classGraphdefinitialize@nodeArray=Array.new@wireArray=Array.newenddefto_s#calledwithprint/puts"Graph:#{@nodeArray.size}"enddefinspect#calledwithp"G"endendif__FILE__==$0gr=Graph.newpgrprintgrputsgrend我明白了GGraph:0Graph:0那么,
我完全是ruby初学者,所以这是一个非常新手的问题。我正在尝试将一个字符串与一个浮点值连接起来,如下所示,然后打印它。puts"TotalRevenueofEastCost:"+total_revenue_of_east_costtotal_revenue_of_east_cost是一个保持浮点值的变量,我怎样才能让它打印出来? 最佳答案 这不完全是连接,但它会完成你想做的工作:puts"TotalRevenueofEastCost:#{total_revenue_of_east_cost}"从技术上讲,这是插值。不同之处在于连
我在某处遗漏了备忘录,希望您能向我解释一下。为什么一个对象的特征类不同于self.class?classFoodefinitialize(symbol)eigenclass=class我的逻辑系列将特征类等同于class.self很简单:class是一种声明类方法而不是实例方法的方法。这是defFoo.bar的快捷方式.所以在对类对象的引用中,返回self应与self.class相同.这是因为class会设置self至Foo.class用于类方法/属性的定义。我只是糊涂了吗?或者,这是Ruby元编程的偷偷摸摸的把戏吗? 最佳答案 c