文章目录
1.机器,依此配置host
| IP | 主机名 | 角色 |
|---|---|---|
| 192.168.10.135 | fileOS1 | master & node |
| 192.168.10.136 | fileOS2 | node |
| 192.168.10.137 | fileOS3 | node |
2.软件环境
| 类型 | 参数 |
|---|---|
| 操作系统 | CentOS7 |
| java环境 | jdk8 |
| es | elasticsearch-7.8.0 |
3.资源包
https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-8-0
代码如下(示例):
# 解压缩
tar -zxvf elasticsearch-7.8.0-linux-x86_64.tar.gz -C /opt/module
# 改名
mv elasticsearch-7.8.0 es
useradd es #新增 es 用户
passwd es #为 es 用户设置密码
userdel -r es #如果错了,可以删除再加
chown -R es:es /opt/module/es-cluster #文件夹所有者
chown -R es:es /datas/es #自定义的es专用存储目录权限
注:es脚本不允许root用户启动
三个节点的node.name分别为es-node-1、es-node-2、es-node-3
network.host分别为fileOS1、fileOS2、fileOS3
#集群名称
cluster.name: my-es-cluster
#节点名称,每个节点的名称不能重复
node.name: es-node-1
#ip 地址,每个节点的地址不能重复
network.host: fileOS1
#是不是有资格主节点
node.master: true
node.data: true
http.port: 9200
# head 插件需要这打开这两个配置
http.cors.allow-origin: "*"
http.cors.enabled: true
http.max_content_length: 200mb
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举 master
cluster.initial_master_nodes: ["es-node-1"]
#es7.x 之后新增的配置,节点发现
discovery.seed_hosts: ["fileOS1:9300","fileOS2:9300","fileOS3:9300"]
gateway.recover_after_nodes: 2
network.tcp.keep_alive: true
network.tcp.no_delay: true
transport.tcp.compress: true
#集群内同时启动的数据任务个数,默认是 2 个
cluster.routing.allocation.cluster_concurrent_rebalance: 16
#添加或删除节点及负载均衡时并发恢复的线程个数,默认 4 个
cluster.routing.allocation.node_concurrent_recoveries: 16
#初始化数据恢复时,并发恢复线程的个数,默认 4 个
cluster.routing.allocation.node_initial_primaries_recoveries: 16
#数据目录
path.data: /datas/es/path/to/data
#日志目录
path.logs: /datas/es/path/to/logs
es soft nofile 65536
es hard nofile 65536
es soft nofile 65536
es hard nofile 65536
* hard nproc 4096
注:* 带表 Linux 所有用户名称
vm.max_map_count=655360
sysctl -p
用es账号在所有节点分别启动
cd /opt/module/es
#方式一:前台启动
bin/elasticsearch
#方式二:后台启动
bin/elasticsearch -d
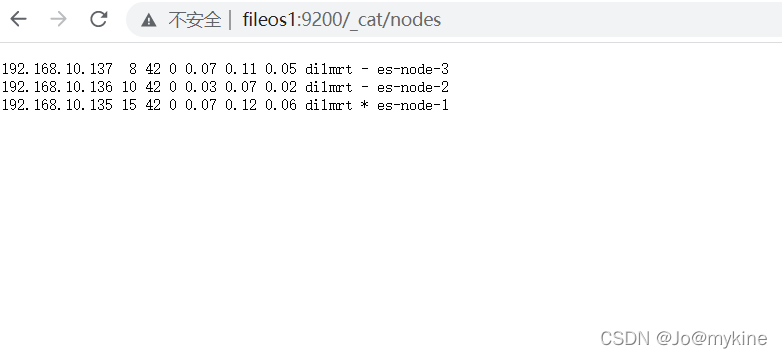
http://fileos1:9200/_cat/nodes
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
文章目录查看ES信息查看节点信息查看分片信息实际场景下ES分片及副本数量应该怎么分关于ES的灵活使用查看ES信息查看版本kibana:GET/查看节点信息GET/_cat/nodes?v解释:ip:集群中节点的ip地址;heap.percent:堆内存的占用百分比;ram.percent:总内存的占用百分比,其实这个不是很准确,因为buff/cache和available也被当作使用内存;cpu:cpu占用百分比;load_1m:1分钟内cpu负载;load_5m:5分钟内cpu负载;load_15m:15分钟内cpu负载;node.role:上图的dilmrt代表全部权限master:*代表
elasticsearch查看当前集群中的master节点是哪个需要使用_cat监控命令,具体如下。查看方法es主节点确定命令,以kibana上查看示例如下:GET_cat/nodesv返回结果示例如下:ipheap.percentram.percentcpuload_1mload_5mload_15mnode.rolemastername172.16.16.188529952.591.701.45mdi-elastic3172.16.16.187329950.990.991.19mdi-elastic2172.16.16.231699940.871.001.03mdi-elastic4172
(二十二)-框架主入口main.py设计&log日志调用和生成1测试目的2测试需求3需求分析4详细设计4.1新建存放日志目录log4.1.1配置config.py中写入log的目录4.2`baseInfo.py`中加入日志4.3`test_gedit.py`中加入日志4.4主函数入口main.py中调用日志5调用日志主函数main.py源码6`baseInfo.py`源码7`test_gedit.py`源码8运行效果9目前框架结构1测试目的组织运行所有的测试用例,并调用日志模块,便于问题定位。
(1)为什么写这个话题(Why)读万卷书不如行千里路。这次搭建MQTT服务,遇到了一些误解,特此记录备忘。主要包括:(1)服务(Broker)的账户管理与网页管理平台的账户(2)与web应用的集成(Spring系)(2)ActiveMQ版本选择因为JAVA环境是JDK8,所以按兼容性考虑选择了ActiveMQ5.15的最后版本5.15.15。如果你是JDK11则可考虑ActiveMQ的最新版本5.17或5.18。ActiveMQ支持MQTTv3.1.1andv3.1。(3)ActiveMQ与web应用的集成主要介绍与Spring系的webapp集成(SpringBoot和SpringMVC)。
Kubernetes(K8s)是一个用于管理容器化应用程序的开源平台,可以帮助开发人员更轻松地部署、管理和扩展应用程序。在Kubernetes中,集群划分是一种重要的概念,可以帮助我们更好地组织和管理集群中的节点和资源。本文将介绍如何使用Kubernetes对集群进行划分,并提供详细的操作示例,希望能够帮助读者更好地了解和使用Kubernetes平台。Node划分Node划分是将集群中的节点按照一定的规则进行划分。在Kubernetes中,可以使用NodeSelector和Affinity机制来实现Node划分。NodeSelectorNodeSelector是一种将Pod调度到符合特定节点标
这篇文章,主要介绍如何使用SpringCloud微服务组件从0到1搭建一个微服务工程。目录一、从0到1搭建微服务工程1.1、基础环境说明(1)使用组件(2)微服务依赖1.2、搭建注册中心(1)引入依赖(2)配置文件(3)启动类1.3、搭建配置中心(1)引入依赖(2)配置文件(3)启动类1.4、搭建API网关(1)引入依赖(2)配置文件(3)启动类1.5、搭建服务提供者(1)引入依赖(2)配置文件(3)启动类1.6、搭建服务消费者(1)引入依赖(2)配置文件(3)启动类1.7、运行测试一、从0到1搭建微服务工程1.1、基础环境说明(1)使用组件这里主要是使用的SpringCloudNetflix
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。我目前正在尝试搭建一个学习Ruby的开发环境。环境主要是为了掌握这门语言,但我很可能会在很长一段时间后转向使用Rails进行开发。以Web开发为目标,我想了解首选的Web服务器和数据库。我打算在虚拟机上设置环境,所以我不担心把它弄坏。因此,我愿意使用Linux发行版、OSX或Windows作为操作系统。我正从C#转向,所以我想在一定程度上被迫采用Ruby的