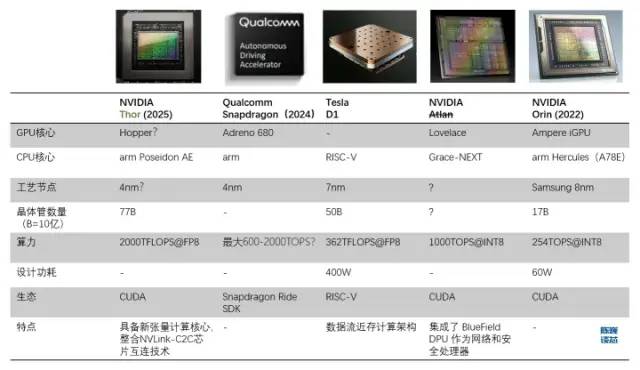
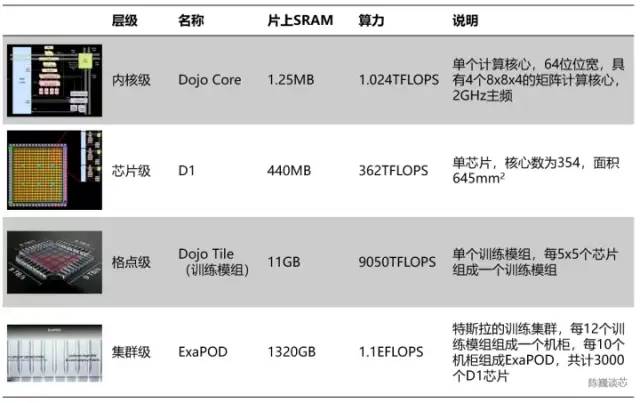
 按照层次划分的话,每354个Dojo核心组成一块D1芯片,而每25颗芯片组成一个训练模组。最后120个训练模组组成一组ExaPOD计算集群,共计3000颗D1芯片。一个特斯拉Dojo芯片训练模组可以达到6组GPU服务器的性能,成本却少于单组GPU服务器。单台Dojo服务器算力甚至达到了54PFLOPS。只用 4 个 Dojo 机柜就能取代由 4000 颗 GPU 组成的 72 组 GPU 机架。Dojo 将通常需要几个月的AI计算(训练)工作减少到了1 周。这样的“大算力出奇迹”,与特斯拉自动驾驶的风格一脉相承。显然芯片也会大大加速特斯拉AI技术的进步速度。当然,这一芯片模组还没有到达“完美”的程度,尽管采用了数据流近存计算的思路,其算力能效比并没有超过GPU。单个服务器的功耗巨大,电流达到了2000A,需要特殊定制的电源供电。特斯拉D1芯片已经是近存计算架构的结构极限了。如果特斯拉采用“存内计算”或者“存内逻辑”架构,或许芯片性能或能效比还会有大幅度提升。
按照层次划分的话,每354个Dojo核心组成一块D1芯片,而每25颗芯片组成一个训练模组。最后120个训练模组组成一组ExaPOD计算集群,共计3000颗D1芯片。一个特斯拉Dojo芯片训练模组可以达到6组GPU服务器的性能,成本却少于单组GPU服务器。单台Dojo服务器算力甚至达到了54PFLOPS。只用 4 个 Dojo 机柜就能取代由 4000 颗 GPU 组成的 72 组 GPU 机架。Dojo 将通常需要几个月的AI计算(训练)工作减少到了1 周。这样的“大算力出奇迹”,与特斯拉自动驾驶的风格一脉相承。显然芯片也会大大加速特斯拉AI技术的进步速度。当然,这一芯片模组还没有到达“完美”的程度,尽管采用了数据流近存计算的思路,其算力能效比并没有超过GPU。单个服务器的功耗巨大,电流达到了2000A,需要特殊定制的电源供电。特斯拉D1芯片已经是近存计算架构的结构极限了。如果特斯拉采用“存内计算”或者“存内逻辑”架构,或许芯片性能或能效比还会有大幅度提升。 特斯拉Dojo芯片服务器由12个Dojo训练模组组成(2层,每层6个)
特斯拉Dojo芯片服务器由12个Dojo训练模组组成(2层,每层6个)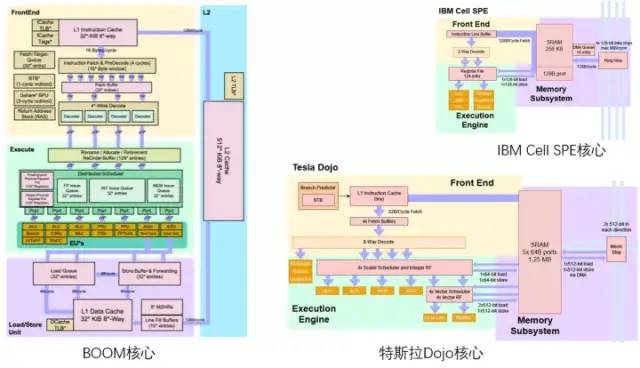 特斯拉Dojo核心与伯克利BOOM/ IBM Cell核心对比
特斯拉Dojo核心与伯克利BOOM/ IBM Cell核心对比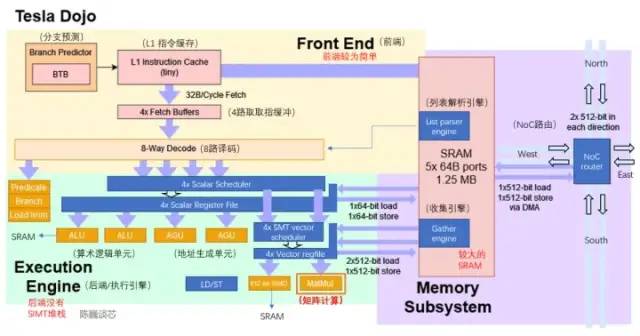 D1核心结构(蓝色部分为添加/修改的细节)从目前的架构图来看,Dojo核心由前端、执行单元、SRAM和NoC路由4部分组成,比CPU和GPU的控制部件都更少,具有类似CPU的AGU和思路类似GPU张量核心(Tensor core)的矩阵计算单元。Dojo核心结构比BOOM更加精简,没有Rename这些改善执行部件利用率的组件,同时也难于支持虚拟内存。但这样设计的好处是减少了控制部分占用的面积,可以把芯片上更多的面积划分给计算执行单元。每个Dojo核心提供了1.024TFLOPS的算力。可以看到,每个几乎所有的算力都由矩阵计算单元提供。因而矩阵计算单元和SRAM共同决定了D1处理器的计算能效比。Dojo核心的主要参数
D1核心结构(蓝色部分为添加/修改的细节)从目前的架构图来看,Dojo核心由前端、执行单元、SRAM和NoC路由4部分组成,比CPU和GPU的控制部件都更少,具有类似CPU的AGU和思路类似GPU张量核心(Tensor core)的矩阵计算单元。Dojo核心结构比BOOM更加精简,没有Rename这些改善执行部件利用率的组件,同时也难于支持虚拟内存。但这样设计的好处是减少了控制部分占用的面积,可以把芯片上更多的面积划分给计算执行单元。每个Dojo核心提供了1.024TFLOPS的算力。可以看到,每个几乎所有的算力都由矩阵计算单元提供。因而矩阵计算单元和SRAM共同决定了D1处理器的计算能效比。Dojo核心的主要参数
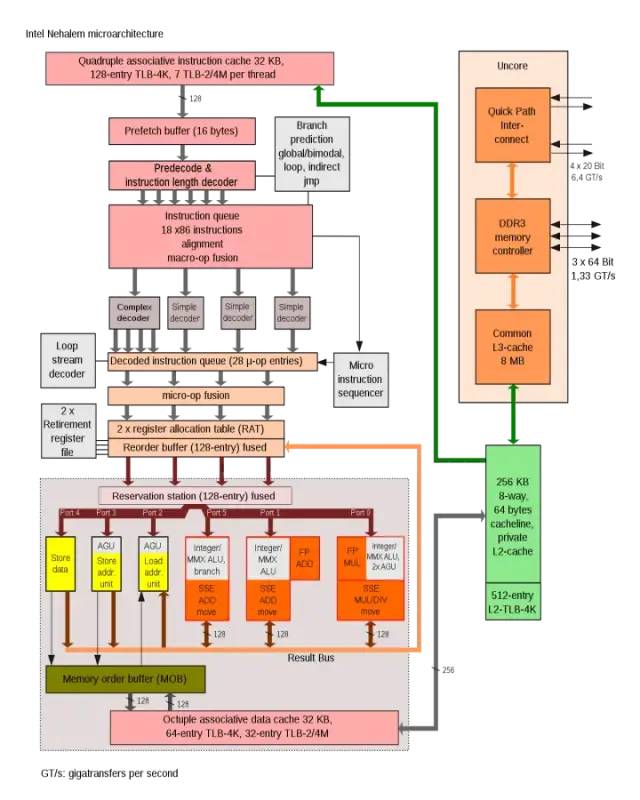 Intel Nehalem架构中使用AGU来提升单周期地址访问效率Dojo内核的连接方式比较像 IBM 的 Cell处理器中的SPE内核连接方式。主要的相似点包括:
Intel Nehalem架构中使用AGU来提升单周期地址访问效率Dojo内核的连接方式比较像 IBM 的 Cell处理器中的SPE内核连接方式。主要的相似点包括: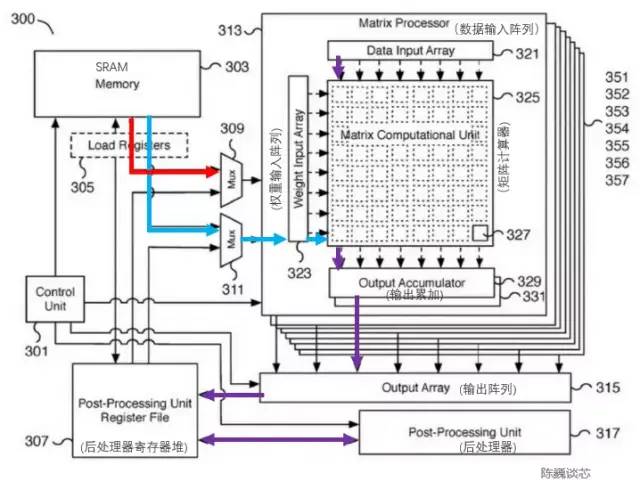 特斯拉矩阵计算单元专利由于架构图上只有一个L1 缓存和SRAM,大胆猜测特斯拉精简了RISC-V的缓存结构,目的是节约缓存面积并减少延迟。每个核心1.25MB的SRAM块可以为SIMD和矩阵计算单元提供2x512位的读(对应AI计算的权重和数据)和512位的写带宽,以及面向整数寄存器堆的64位读写能力。计算的主要数据流是从SRAM到SIMD和矩阵乘法单元。矩阵计算单元的主要处理流程为:通过多路选择器(Mux)从SRAM中加载权重到权重输入阵列(Weight input array),同时SRAM中加载数据到数据输入阵列(Data input array)。输入的数据与权重在矩阵计算器(Matrix computation Unit)中进行乘法计算(内积或外积?)乘法计算结果输出到输出累加(Output accumulator)中进行累加。这里计算时可以通过矩阵划分拼接的方式进行超过8x8的矩阵计算。累加后的输出传入后处理器寄存器堆进行缓存,随后进行后处理(可执行例如激活、池化、Padding等操作)。整个计算流程由控制单元(Control unit)直接控制,无需CPU干预。
特斯拉矩阵计算单元专利由于架构图上只有一个L1 缓存和SRAM,大胆猜测特斯拉精简了RISC-V的缓存结构,目的是节约缓存面积并减少延迟。每个核心1.25MB的SRAM块可以为SIMD和矩阵计算单元提供2x512位的读(对应AI计算的权重和数据)和512位的写带宽,以及面向整数寄存器堆的64位读写能力。计算的主要数据流是从SRAM到SIMD和矩阵乘法单元。矩阵计算单元的主要处理流程为:通过多路选择器(Mux)从SRAM中加载权重到权重输入阵列(Weight input array),同时SRAM中加载数据到数据输入阵列(Data input array)。输入的数据与权重在矩阵计算器(Matrix computation Unit)中进行乘法计算(内积或外积?)乘法计算结果输出到输出累加(Output accumulator)中进行累加。这里计算时可以通过矩阵划分拼接的方式进行超过8x8的矩阵计算。累加后的输出传入后处理器寄存器堆进行缓存,随后进行后处理(可执行例如激活、池化、Padding等操作)。整个计算流程由控制单元(Control unit)直接控制,无需CPU干预。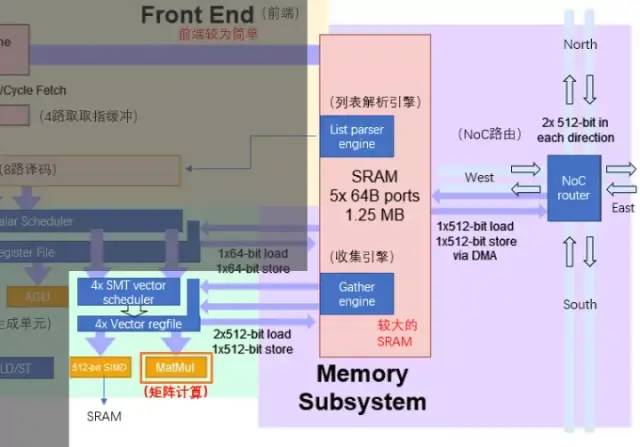 执行单元与SRAM/NoC的数据交互Dojo核心内的SRAM具有非常大的读写带宽,可以以 400 GB/秒的速度加载并以 270 GB/秒的速度写入。Dojo核心指令集具有专用的网络传输指令,通过NoC路由,可以直接将数据移入或移出 D1 芯片中甚至Dojo训练模块中其他内核的SRAM 存储器。与普通的SRAM不同,Dojo的SRAM包括列表解析引擎(list parser engine)和一个收集引擎(gather engine)。列表解析功能是 D1芯片的关键特性之一,通过列表解析引擎可以将复杂的不同数据类型的传输序列进行打包,提升传输效率。
执行单元与SRAM/NoC的数据交互Dojo核心内的SRAM具有非常大的读写带宽,可以以 400 GB/秒的速度加载并以 270 GB/秒的速度写入。Dojo核心指令集具有专用的网络传输指令,通过NoC路由,可以直接将数据移入或移出 D1 芯片中甚至Dojo训练模块中其他内核的SRAM 存储器。与普通的SRAM不同,Dojo的SRAM包括列表解析引擎(list parser engine)和一个收集引擎(gather engine)。列表解析功能是 D1芯片的关键特性之一,通过列表解析引擎可以将复杂的不同数据类型的传输序列进行打包,提升传输效率。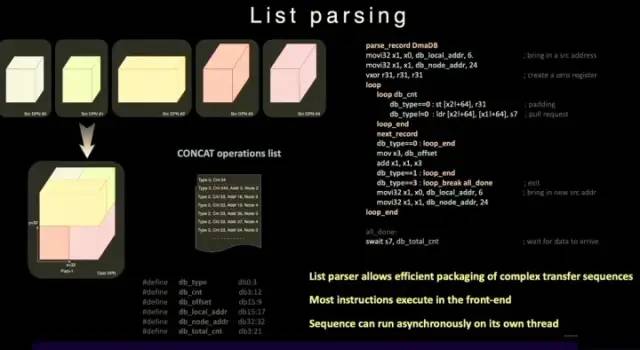 列表解析功能为了进一步减少操作延迟、面积和复杂度,D1 并不支持虚拟内存。在通常的处理器中,程序使用的内存地址不是直接访问物理内存地址,而是由 CPU 使用操作系统设置的分页结构转换为物理地址。在 D1内核中, 4 路 SMT 功能让计算具备显式并行性,简化 AGU 和寻址计算方式,以让特斯拉以足够低的延迟访问 SRAM,其优势是可避免中间L1 数据缓存的延迟。
列表解析功能为了进一步减少操作延迟、面积和复杂度,D1 并不支持虚拟内存。在通常的处理器中,程序使用的内存地址不是直接访问物理内存地址,而是由 CPU 使用操作系统设置的分页结构转换为物理地址。在 D1内核中, 4 路 SMT 功能让计算具备显式并行性,简化 AGU 和寻址计算方式,以让特斯拉以足够低的延迟访问 SRAM,其优势是可避免中间L1 数据缓存的延迟。 D1处理器指令集D1参考了RISC-V 架构的指令,并且自定义了一些指令,特别是矢量计算相关的指令。D1指令集支持 64 位标量指令和 64字节 SIMD 指令,网络传输与同步原语和机器学习/深度学习相关的专用原语(例如8x8矩阵计算)。在网络数据传输和同步原语方面,支持从本地存储(SRAM)到远程存储传输数据的指令原语(Primitives),以及信号量(Semaphore)和屏障约束( Barrier constraints)。这可以使D1支持多线程,其存储操作指令可以在多个 D1 内核中运行。针对机器学习和深度学习,特斯拉定义了包括 shuffle、transpose 和 convert 等数学操作的指令,以及随机舍入( stochastic rounding ),padding相关的指令。
D1处理器指令集D1参考了RISC-V 架构的指令,并且自定义了一些指令,特别是矢量计算相关的指令。D1指令集支持 64 位标量指令和 64字节 SIMD 指令,网络传输与同步原语和机器学习/深度学习相关的专用原语(例如8x8矩阵计算)。在网络数据传输和同步原语方面,支持从本地存储(SRAM)到远程存储传输数据的指令原语(Primitives),以及信号量(Semaphore)和屏障约束( Barrier constraints)。这可以使D1支持多线程,其存储操作指令可以在多个 D1 内核中运行。针对机器学习和深度学习,特斯拉定义了包括 shuffle、transpose 和 convert 等数学操作的指令,以及随机舍入( stochastic rounding ),padding相关的指令。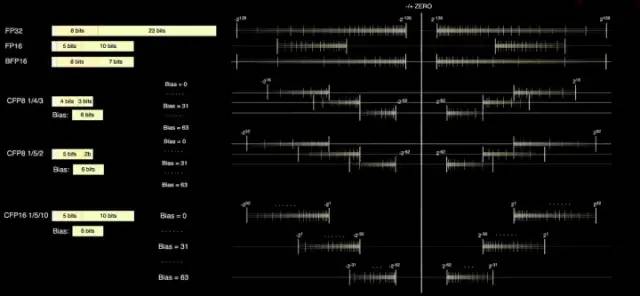 D1处理器的数据格式根据特斯拉提供的信息,在矩阵乘法单元内部可使用CFP8来进行计算(存储为CFP16格式)。
D1处理器的数据格式根据特斯拉提供的信息,在矩阵乘法单元内部可使用CFP8来进行计算(存储为CFP16格式)。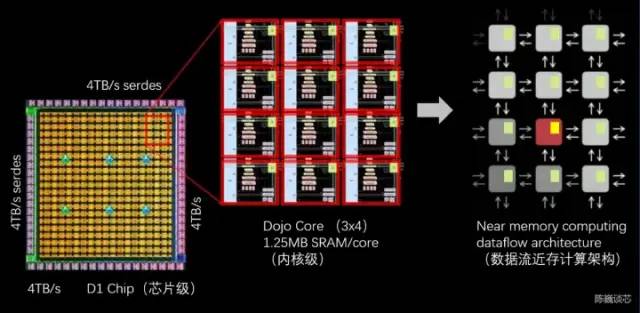 D1处理器结构每个D1处理器由 18 x 20 的Dojo核心拼接构成。每个D1处理器中有354个Dojo核心可用。(之所以只使用360个核心中的354个是出于良率和每处理器核心稳定考虑)由台积电制造,采用7nm制造工艺,拥有500亿个晶体管,芯片面积为645mm²。每个Dojo核心有一块1.25MB的SRAM作为主要的权重和数据存储。不同的Dojo核心通过片上网络路由(NoC路由)进行连接,不同的Dojo内核通过复杂的NoC网络进行数据同步,而不是共享数据缓存。NoC 可以处理跨节点边界4个方向(东南西北)的 8 个数据包,每个方向 64 B/每个时钟周期,即在所有四个方向上一个数据包输入和一个数据包输出到网格中每个相邻的Dojo核心。该NoC路由还可以在每个周期对核心内的 SRAM 进行一次 64 B 双向读写。
D1处理器结构每个D1处理器由 18 x 20 的Dojo核心拼接构成。每个D1处理器中有354个Dojo核心可用。(之所以只使用360个核心中的354个是出于良率和每处理器核心稳定考虑)由台积电制造,采用7nm制造工艺,拥有500亿个晶体管,芯片面积为645mm²。每个Dojo核心有一块1.25MB的SRAM作为主要的权重和数据存储。不同的Dojo核心通过片上网络路由(NoC路由)进行连接,不同的Dojo内核通过复杂的NoC网络进行数据同步,而不是共享数据缓存。NoC 可以处理跨节点边界4个方向(东南西北)的 8 个数据包,每个方向 64 B/每个时钟周期,即在所有四个方向上一个数据包输入和一个数据包输出到网格中每个相邻的Dojo核心。该NoC路由还可以在每个周期对核心内的 SRAM 进行一次 64 B 双向读写。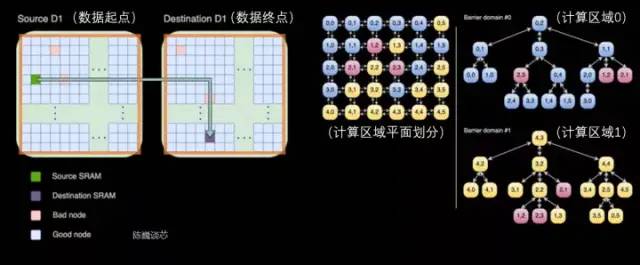 跨处理器传输和D1处理器内部的任务划分每个Dojo核心都是一个相对完整的带矩阵计算能力的类CPU(由于每个核心具备单独的矩阵计算单元,且前端相对较小,所以这里称为类CPU)其数据流架构则有点类似于SambaNova的二维数据流网格结构,数据直接在各个处理核心之间流转,无需回到内存。D1芯片运行在2GHz,拥有巨大的440MB SRAM。特斯拉将设计重心放在计算网格中的分布式SRAM,通过大量更快更近的片上存储和片上存储之间的流转减少对内存的访问频度,来提升整个系统的性能,具有明显的数据流存算一体架构(数据流近存计算)特征。每颗D1 芯片有 576 个双向 SerDes 通道,分布在四周,可连接到其他 D1 芯片,单边带宽为 4 TB/秒。D1处理器芯片主要参数
跨处理器传输和D1处理器内部的任务划分每个Dojo核心都是一个相对完整的带矩阵计算能力的类CPU(由于每个核心具备单独的矩阵计算单元,且前端相对较小,所以这里称为类CPU)其数据流架构则有点类似于SambaNova的二维数据流网格结构,数据直接在各个处理核心之间流转,无需回到内存。D1芯片运行在2GHz,拥有巨大的440MB SRAM。特斯拉将设计重心放在计算网格中的分布式SRAM,通过大量更快更近的片上存储和片上存储之间的流转减少对内存的访问频度,来提升整个系统的性能,具有明显的数据流存算一体架构(数据流近存计算)特征。每颗D1 芯片有 576 个双向 SerDes 通道,分布在四周,可连接到其他 D1 芯片,单边带宽为 4 TB/秒。D1处理器芯片主要参数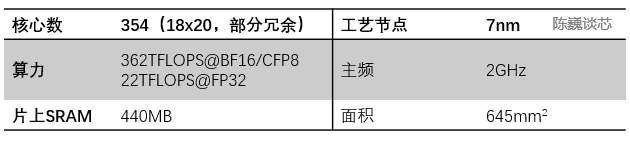
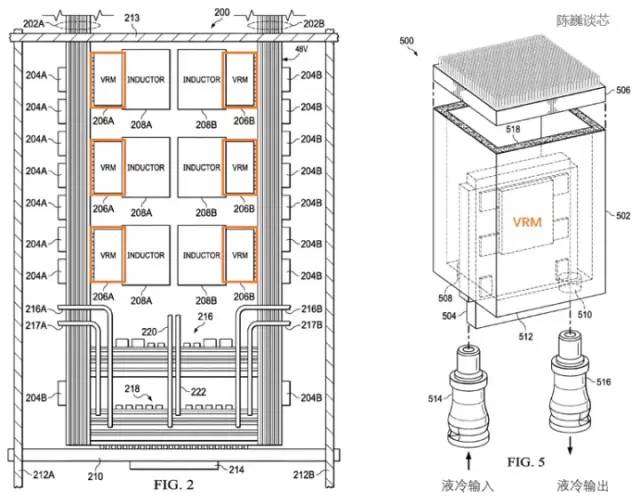 特斯拉D1处理器的散热结构专利特斯拉使用了专用的电源调节模块(VRM)和散热结构来进行功耗管理。在这里功耗管理的主要目的有2个:减少不必要的功耗损失,提升能效比。减少散热形变造成的处理器模组失效。根据特斯拉的专利,我们可以看到电源调节模块与芯片本身垂直,极大的减少了对处理器平面的面积占用,且可以通过液冷来迅速平衡处理器的温度。
特斯拉D1处理器的散热结构专利特斯拉使用了专用的电源调节模块(VRM)和散热结构来进行功耗管理。在这里功耗管理的主要目的有2个:减少不必要的功耗损失,提升能效比。减少散热形变造成的处理器模组失效。根据特斯拉的专利,我们可以看到电源调节模块与芯片本身垂直,极大的减少了对处理器平面的面积占用,且可以通过液冷来迅速平衡处理器的温度。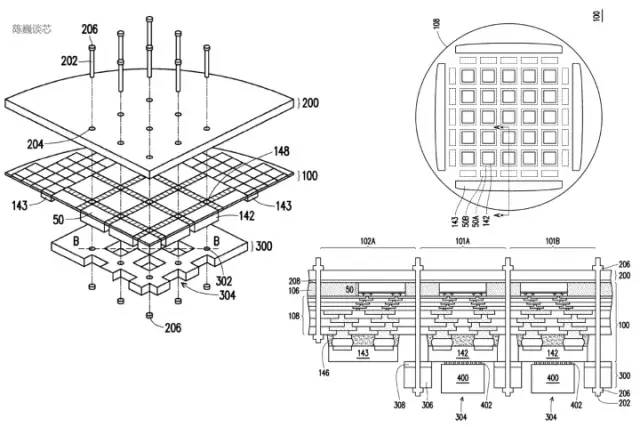 特斯拉D1处理器的散热和封装结构专利训练模组在封装上采用InFO_SoW(Silicon on Wafer)封装来提高芯片间的互连密度。该封装除了TSMC的INFO_SoW技术之外,也采用了特斯拉自己的机械封装结构,以减小处理器模组的失效。每个训练模块外部边缘的 40 个 I/O 芯片达到了 36 TB/s的聚合带宽,或者10TB/s的横跨带宽。每层训练模块都连接着超高速存储系统:640GB 运行内存可以提供超过 18TB/s的带宽,另外还有超过 1TB/s的网络交换带宽。数据传输方向与芯片平面平行,供电及液冷方向与芯片平面垂直。这是一个非常优美的结构设计,不同的训练模块之间还可以互连。通过立体结构,节约了芯片模组的供电面积,尽可能减少计算芯片间的距离。一个 Dojo POD 机柜由两层计算托盘和存储系统组成。每一层托盘都有 6 个 D1 训练模组。两层共 12个训练模组组成的一个机柜,可提供 108PFLOPS 的深度学习算力。
特斯拉D1处理器的散热和封装结构专利训练模组在封装上采用InFO_SoW(Silicon on Wafer)封装来提高芯片间的互连密度。该封装除了TSMC的INFO_SoW技术之外,也采用了特斯拉自己的机械封装结构,以减小处理器模组的失效。每个训练模块外部边缘的 40 个 I/O 芯片达到了 36 TB/s的聚合带宽,或者10TB/s的横跨带宽。每层训练模块都连接着超高速存储系统:640GB 运行内存可以提供超过 18TB/s的带宽,另外还有超过 1TB/s的网络交换带宽。数据传输方向与芯片平面平行,供电及液冷方向与芯片平面垂直。这是一个非常优美的结构设计,不同的训练模块之间还可以互连。通过立体结构,节约了芯片模组的供电面积,尽可能减少计算芯片间的距离。一个 Dojo POD 机柜由两层计算托盘和存储系统组成。每一层托盘都有 6 个 D1 训练模组。两层共 12个训练模组组成的一个机柜,可提供 108PFLOPS 的深度学习算力。 Dojo模组与Dojo POD机柜
Dojo模组与Dojo POD机柜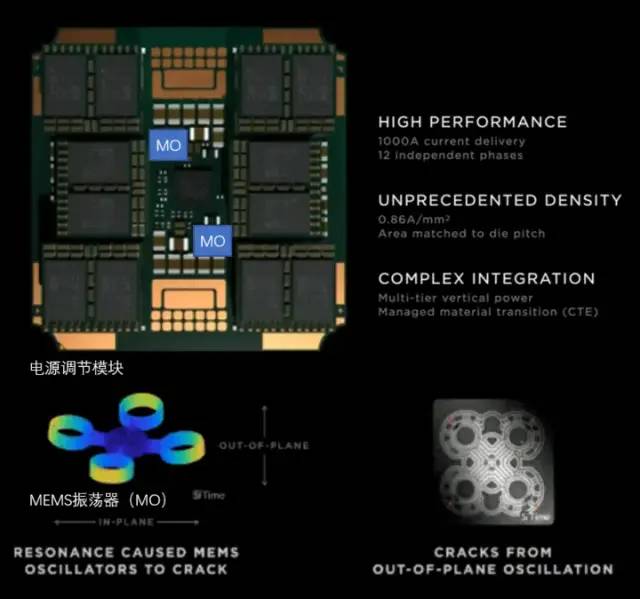 特斯拉的电源调节模组对高密度芯片散热而言,其重点是控制热膨胀系数(CTE)。Dojo系统的芯片密度极高,如果CTE稍微失控,都可能导致结构变形/失效,进而出现连接故障。特斯拉这套自研 VRM 在过去2年内迭代了 14 个版本,采用了MEMS振荡器(MO)来感知电源调节模组的热形变,最终才完全符合内部对 CTE 指标的要求。这种通过MEMS技术主动调节电源功率的方式,与控制火箭箭身振动的主动调节方式类似。
特斯拉的电源调节模组对高密度芯片散热而言,其重点是控制热膨胀系数(CTE)。Dojo系统的芯片密度极高,如果CTE稍微失控,都可能导致结构变形/失效,进而出现连接故障。特斯拉这套自研 VRM 在过去2年内迭代了 14 个版本,采用了MEMS振荡器(MO)来感知电源调节模组的热形变,最终才完全符合内部对 CTE 指标的要求。这种通过MEMS技术主动调节电源功率的方式,与控制火箭箭身振动的主动调节方式类似。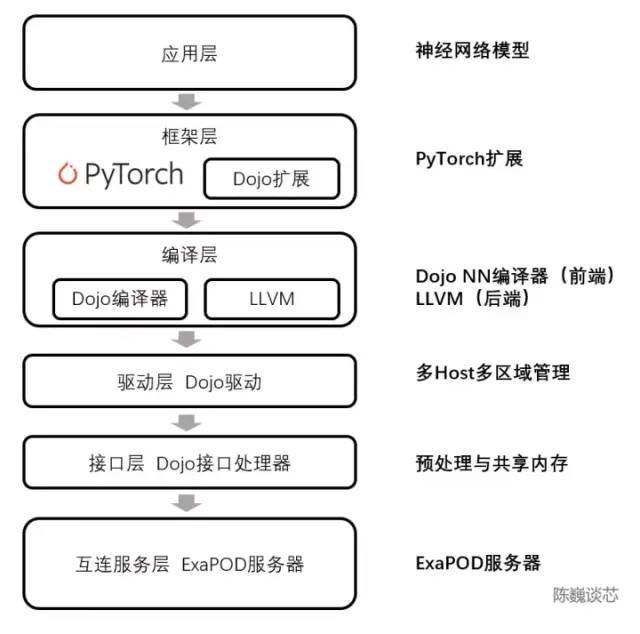 D1处理器软件栈对于D1这类AI芯片来说,编译生态的重要性不低于芯片本身。在D1处理器平面上,D1被划分为矩阵式的计算单元。编译工具链负责任务的划分和配置数据存储,并且通过多种方式进行细粒度的并行计算,并减少存储占用。Dojo编译器支持的并行方式包括数据并行、模型并行和图并行。支持的存储分配方式包括分布式张量、重算分配和分割填充。编译器本身可以处理各种CPU中常用的动态控制流,包括循环和图优化算法。借助Dojo编译器,用户可将Dojo大型分布式系统视作一个加速器进行整体设计和训练。整个软件生态的顶层基于PyTorch,底层基于Dojo驱动,中间使用Dojo编译器和LLVM形成编译层。这里加入LLVM后,可以使特斯拉更好的利用LLVM上已有的各种编译生态进行编译优化。
D1处理器软件栈对于D1这类AI芯片来说,编译生态的重要性不低于芯片本身。在D1处理器平面上,D1被划分为矩阵式的计算单元。编译工具链负责任务的划分和配置数据存储,并且通过多种方式进行细粒度的并行计算,并减少存储占用。Dojo编译器支持的并行方式包括数据并行、模型并行和图并行。支持的存储分配方式包括分布式张量、重算分配和分割填充。编译器本身可以处理各种CPU中常用的动态控制流,包括循环和图优化算法。借助Dojo编译器,用户可将Dojo大型分布式系统视作一个加速器进行整体设计和训练。整个软件生态的顶层基于PyTorch,底层基于Dojo驱动,中间使用Dojo编译器和LLVM形成编译层。这里加入LLVM后,可以使特斯拉更好的利用LLVM上已有的各种编译生态进行编译优化。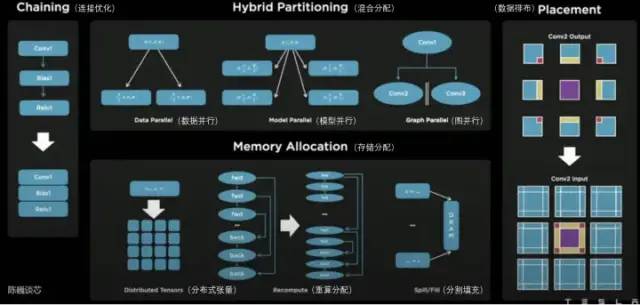 特斯拉Dojo 编译器
特斯拉Dojo 编译器一、概述在之前的一篇博文中,记录了AT24C01、AT24C02芯片的读写驱动,先将之前的相关文章include一下:1.IIC驱动:4位数码管显示模块TM1637芯片C语言驱动程序2.AT24C01/AT24C02读写:AT24C01/AT24C02系列EEPROM芯片单片机读写驱动程序本文记录分享AT24C04、AT24C08、AT24C16芯片的单片机C语言读写驱动程序。二、芯片对比介绍型号容量bit容量byte页数字节/页器件寻址位可寻址器件数WordAddress位数/字节数备注AT24C044k5123216A2A149/1WordAddress使用P0位AT24C088k1024
目录文章信息写在前面Background&MotivationMethodDCNV2DCNV3模型架构Experiment分类检测文章信息Title:InternImage:ExploringLarge-ScaleVisionFoundationModelswithDeformableConvolutionsPaperLink:https://arxiv.org/abs/2211.05778CodeLink:https://github.com/OpenGVLab/InternImage写在前面拿到文章之后先看了一眼在ImageNet1k上的结果,确实很高,超越了同等大小下的VAN、RepLK
汽车芯片赛道的「卷」,或许超出了所有人的预期。对于单纯TOPS算力的比拼,已经翻篇,如何让车企有的用,用得上,还要用得好,已经是新风向。实际上,在汽车智能化刚刚开始的2018年,彼时类似斑马智行这样的车机系统仅仅是从软件层面改变传统座舱的人机交互体验(从功能机到智能机)。而类似Mobileye这样的ADAS视觉感知系统方案(EyeQ5之前),也仅仅是辅助驾驶的入门级。在高工智能汽车研究院看来,汽车芯片赛道经历了几个发展周期,1.0时代(以2020年上车的高通8155为代表),智能座舱进入硬件变革节点;2.0时代(以2021年上车的英伟达Orin为代表),智能驾驶进入硬件变革节点。而3.0时代,
目录l298n模块详解l298n芯片简介 在嵌入式领域中l298n属于最常用的电机驱动模块,该模块稳定,耐用,操作简单备受广大电子爱好者的喜爱,今天小编结合自己开发的经验来给初学者门聊聊如何使用这款模块及芯片的用法l298n模块详解如图所示,模块左右两侧的2P的端子是接入电机的,左右两端分别可以接入一个直流电机。由于直流电机不分正负所以怎样接都是可以的。中间3P的端子分别接12V,GND,5V。黑色排针部分左右两端的跳帽插上代表使能,l298n有两个通道,所以有两个使能跳帽。中间的四个排针是逻辑输入,左边两个为一组,右边两个为另一组,真值表如下图所示下图附带了l298n模块的原理图,想自己di
随着人工智能领域不断取得突破性进展。作为实现人工智能技术的重要基石,AI芯片拥有巨大的产业价值和战略地位。作为人工智能产业链的关键环节和硬件基础,AI芯片有着极高的技术研发和创新的壁垒。从芯片发展的趋势来看,现在仍处于AI芯片发展的初级阶段。未来将是AI芯片发展的重要阶段,无论是架构还是设计理念都存在着巨大的创新空间。一、芯片的发展历史1956年达特茅斯会议上,科学家约翰·麦卡锡,克劳德·香农和马文·明斯基提出了"人工智能"一词。50年代末,阿瑟·萨缪尔(ArthurSamuel)提出了"机器学习"这个术语,他开发了一个西洋跳棋程序,可以从错误中吸取教训,经过学习后,甚至比编写程序的人棋力更强
你可以通过点击选择md-chips中的md-chip元素,但是我还没有找到一个很好的方法来找出哪个被选中在Controller中。有没有人完成过这个?{{$chip}}(fruit)http://codepen.io/anon/pen/QbOaLz 最佳答案 使用md-on-select:选择芯片时将调用的表达式。...在你的Controller中$scope.getChipInfo=function(chip_info){console.log(chip_info);} 关于javas
1基础1.1概述RK809是一款高性能PMIC,RK809集成5个大电流DCDC、9个LDO、2个开关SWITCH、1个RTC、1个高性能CODEC、可调上电时序等功能。系统中各路电源总体分为两种:DCDC和LDO。两种电源的总体特性如下(详细资料请自行搜索):DCDC:输入输出压差大时,效率高,但是存在纹波比较大的问题,成本高,所以大压差,大电流负载时使用。一般有两种工作模式。PWM模式:纹波瞬态响应好,效率低;PFM模式:效率高,但是负载能力差。LDO:输入输出压差大时,效率低,成本低,为了提高LDO的转换效率,系统上会进行相关优化如:LDO输出电压为1.1V,为了提高效率,其输入电压可以
在此前《大型语言模型的涌现能力》、《ChatGPT进化的秘密》两篇文章中,符尧剖析了大型语言模型的突现能力和潜在优势,大模型所带来的“潜在的”范式转变,并拆解了ChatGPT演进的技术路线图。在本文中,作者以终为始分析了大模型的智能极限及其演进维度。不同于刻舟求剑式只追求复现ChatGPT的经典互联网产品思维,而是指出了OpenAI组织架构和尖端人才密度的重要性,更重要的是,分享了模型演化与产品迭代及其未来,思考了如何把最深刻、最困难的问题,用最创新的方法来解决。(以下内容经授权后由OneFlow发布,原文:https://yaofu.notion.site/e1cd16d1fae84f87a
产品参数产品型号内核主频(MHz)Flash(Kbytes)STM32F030C8T6Cortex-M04864RAM(Kbytes)E2PROM(Bytes)封装IO80LQFP4839工作电压16位定时器32位定时器电机控制定时器(16-bit)2.4-3.6701低功耗定时器高分辨率定时器12位ADC转换单元12位ADC通道0011214位ADC转换单元14位ADC通道16位ADC转换单元16位ADC通道000012位DAC通道比较器放大器SPI0002I2SM-SPII2CU(S)ART0022低功耗UARTCANSDIOF(S)MC0000USBDeviceUSBFSHOST/OTG
写在前面:博主是一只经过实战开发历练后投身培训事业的“小山猪”,昵称取自动画片《狮子王》中的“彭彭”,总是以乐观、积极的心态对待周边的事物。本人的技术路线从Java全栈工程师一路奔向大数据开发、数据挖掘领域,如今终有小成,愿将昔日所获与大家交流一二,希望对学习路上的你有所助益。同时,博主也想通过此次尝试打造一个完善的技术图书馆,任何与文章技术点有关的异常、错误、注意事项均会在末尾列出,欢迎大家通过各种方式提供素材。对于文章中出现的任何错误请大家批评指出,一定及时修改。有任何想要讨论和学习的问题可联系我:zhuyc@vip.163.com。发布文章的风格因专栏而异,均自成体系,不足之处请大家指正