文章目录
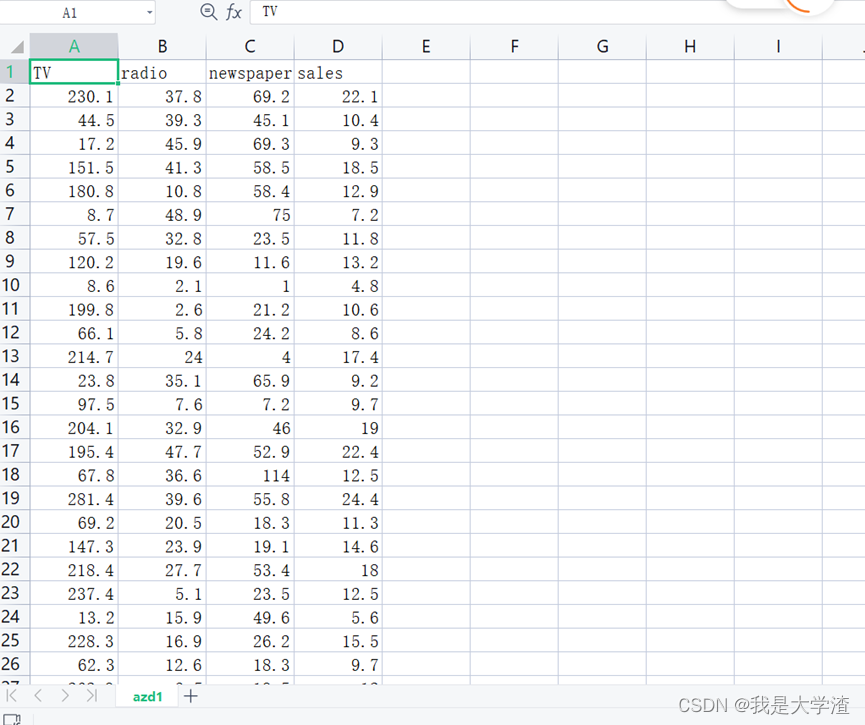
指标名称 指标含义
TV 电视广告投放
radio 电台广告投放
newspaper 报纸广告投放
sales 销售额
| 指标名称 | 指标含义 |
|---|---|
| TV | 电视广告投放 |
| radio | 电台广告投放 |
| newspaper | 报纸广告投放 |
| sales | 销售额 |
在Pycharm中输入下面程序,导入数据和工具包,并查看数据集的信息、大小,并初步观察头部信息。
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor #决策树
from sklearn.linear_model import LinearRegression #线性回归
from sklearn.linear_model import Ridge #岭回归
from sklearn.ensemble import RandomForestRegressor #随机森林
from sklearn.neighbors import KNeighborsRegressor #K邻近
from sklearn import metrics
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文显示
plt.rcParams['axes.unicode_minus'] = False # 解决符号无法显示
data = pd.read_csv("azd1.csv")
# 查看数据集大小
print(data.shape)
# 设置查看前15条数据
print(data.head(15))
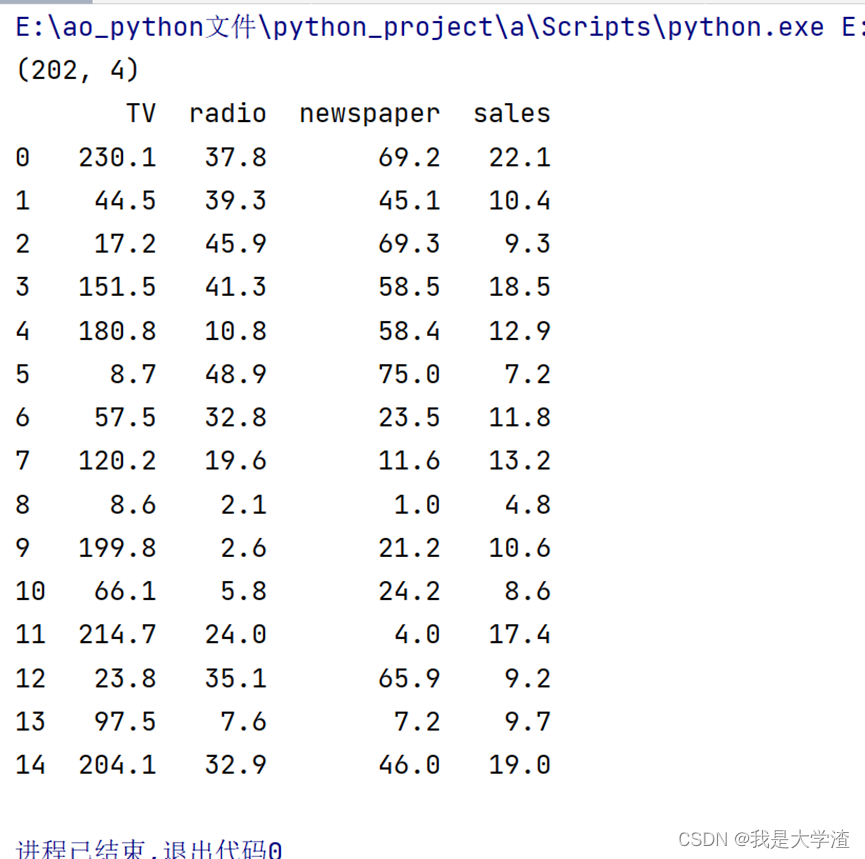
头部信息数据集有4个字段,与上述表 2 1所展示的信息一致,即说明信息加载成功。
首先,通过Dataframe中的info()函数查看各数据字段数据类型和缺失值情况
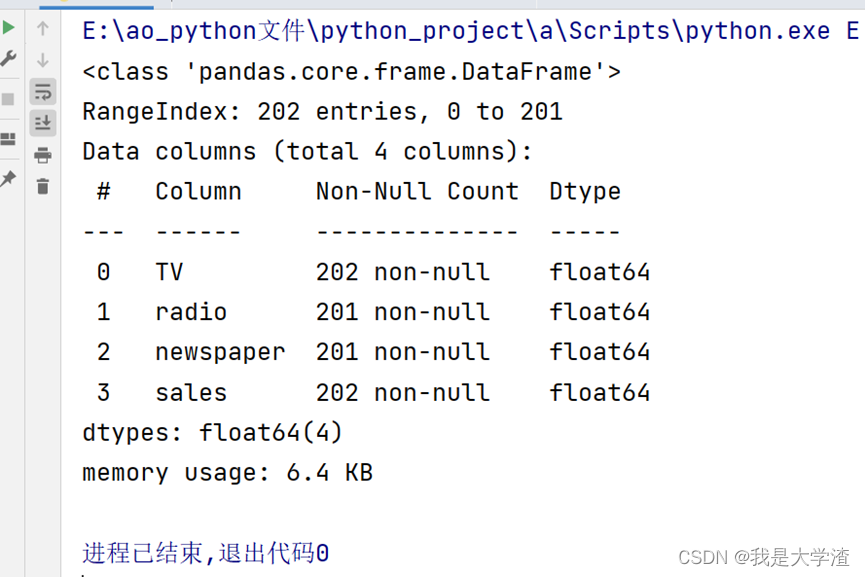

经过观察,发现所有数据类型都为浮点型数据,所以不需要进行数据类型的转换。

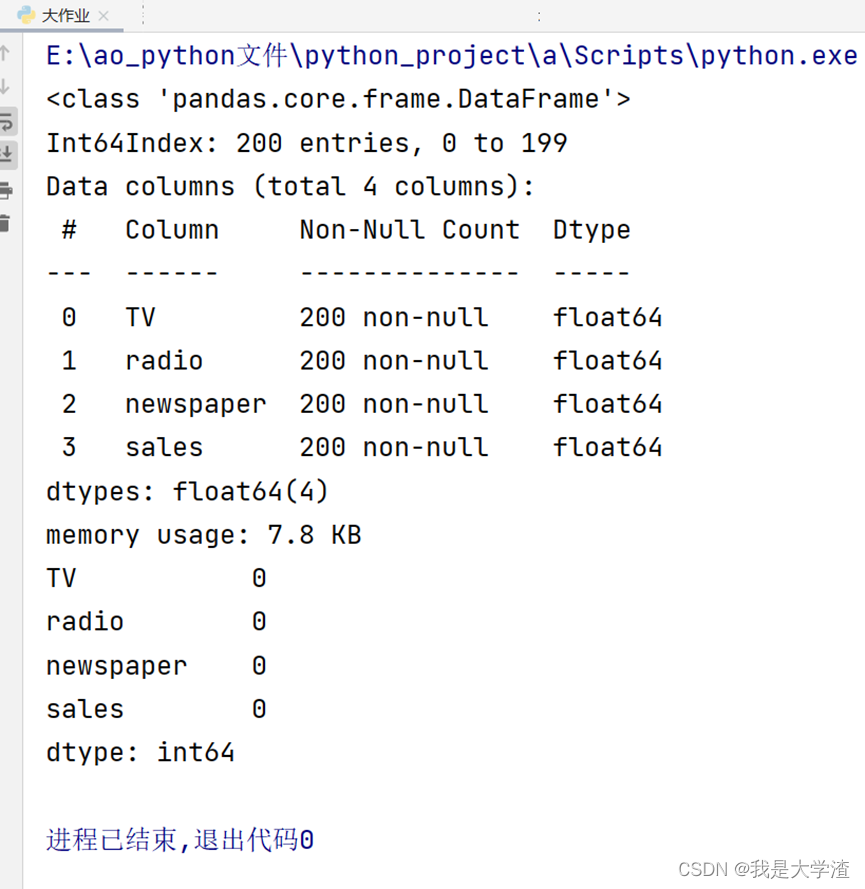
通过散点图分析每一种广告投放方式的销售额分布情况:
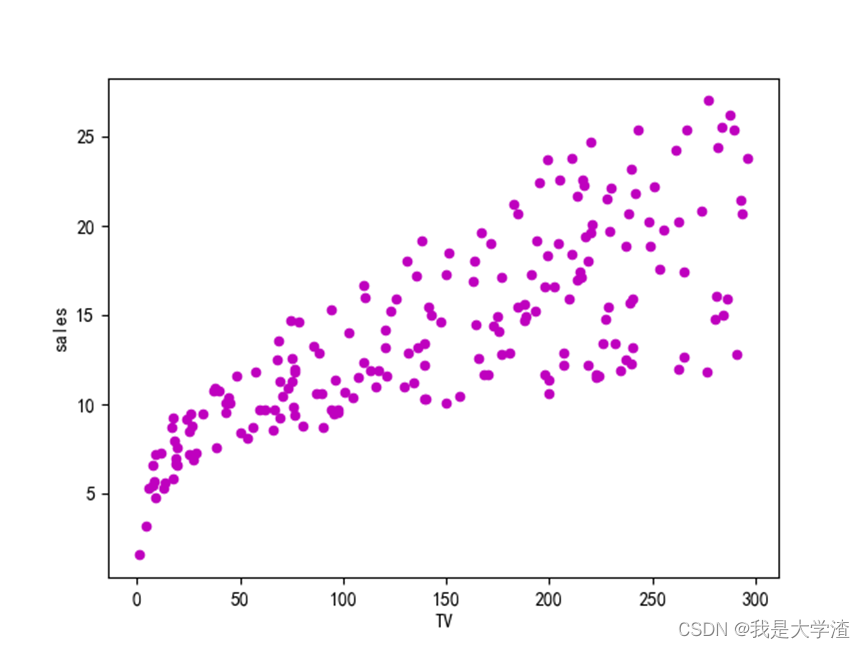
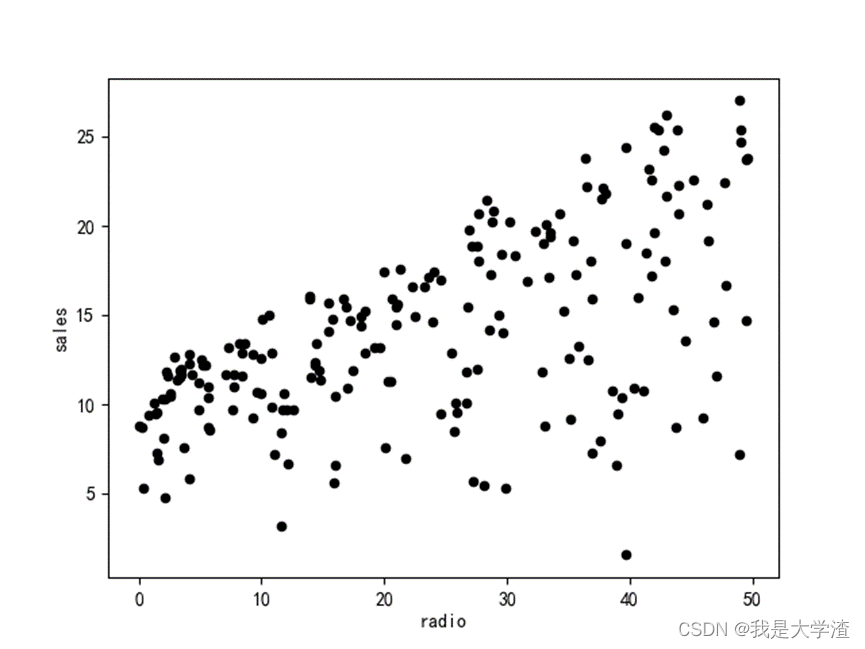
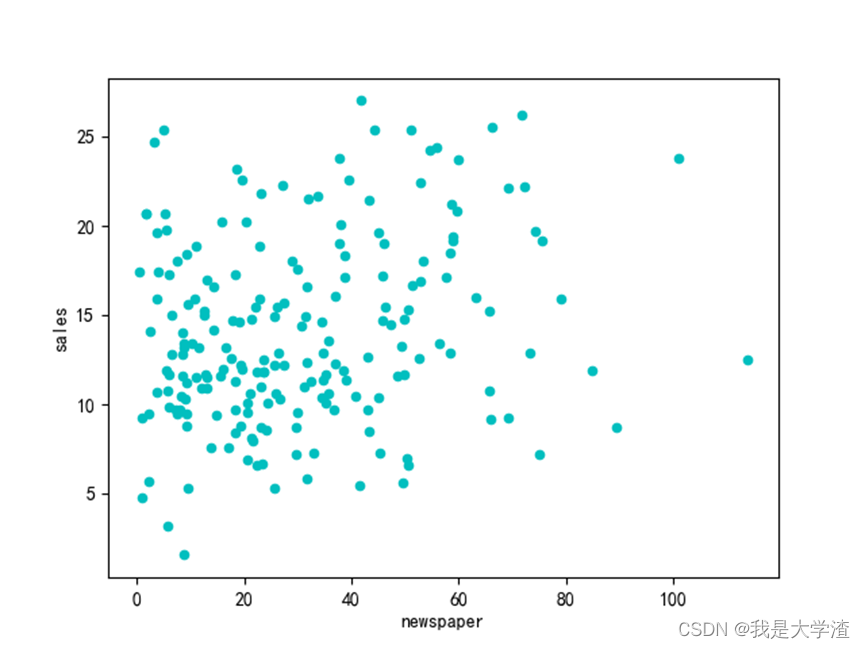
通过绘制每一个维度特征与销售额的散点图,可以大概看出,各种广告投入与销售额成正比。
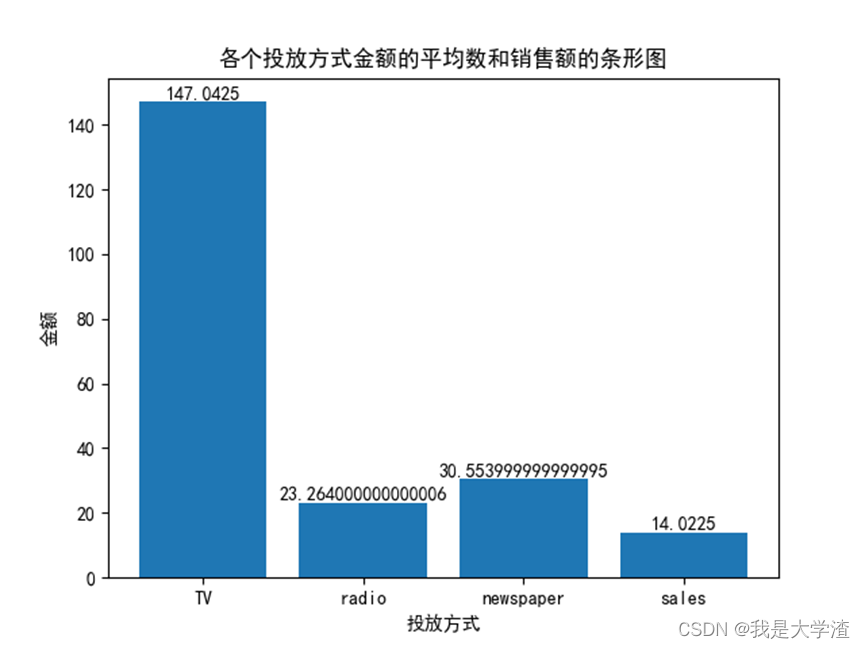
然后我们在画出各个投放方式金额的平均数和销售额的条形图来更加直观的证明这个结论。
从下图我们也可以清晰的看出电视这种广告投放方式的平均值最高,这和我们上面得到的散点图基本一致,电视广告投放散点图分布有明显的集中趋势。
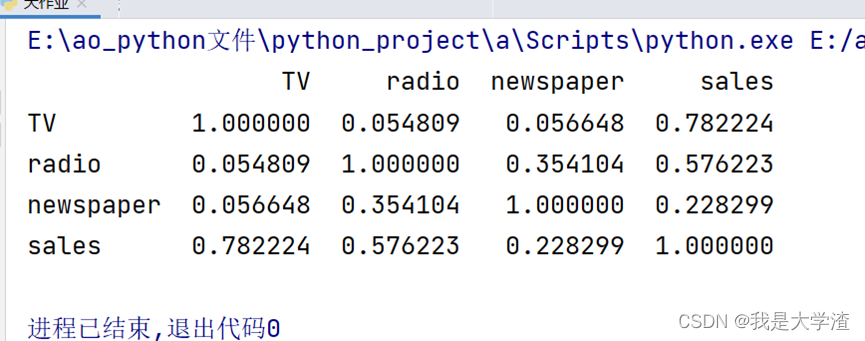
但是我们要清楚散点图分布只能看出一个模糊的大概,具体量化的关联性,可以通过关联矩阵和热力图进行展示,首先就是corr()方法输出关系矩阵。
然后可以将输出的数据进行图形可视化,较为常用的就是热力图,直接利用上面的结果进行输出。
绘制热力图的代码如下
def load_data():
data = pd.read_csv(r'azd1.csv', sep=',')
# 计算相关系数矩阵
corr = data.corr()
print(corr)
cor = corr
plt.figure() # 绘制热力图
sns.heatmap(cor, vmin=-1, cmap="plasma_r", annot=True)
plt.savefig("5")
plt.show()
# 找出对y相关系数大于0.5的因素
a = corr['sales']
a = a[abs(a) > 0.5].sort_values(ascending=False)
a_colums = np.array(a.index).tolist()
return data, a_colums
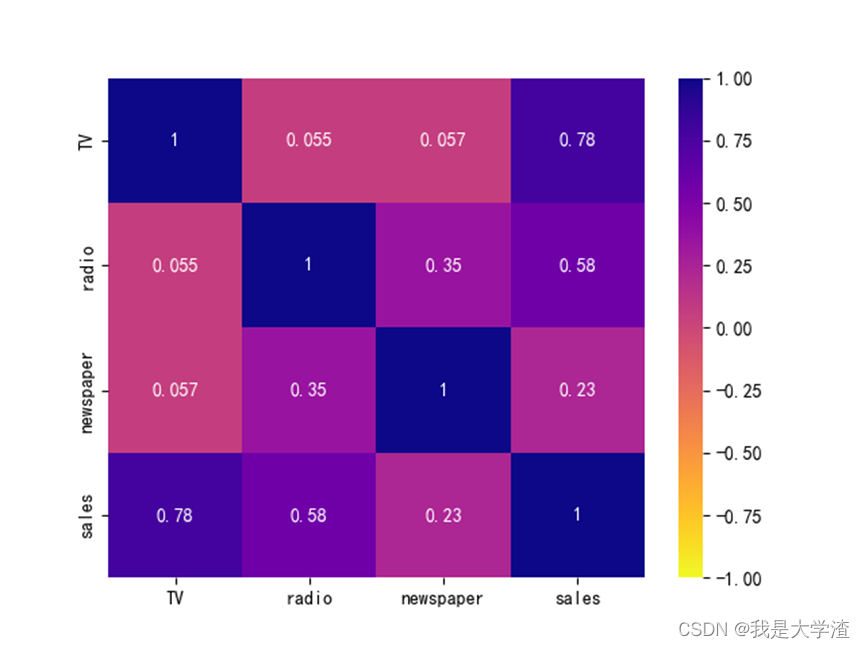
查看关联矩阵和热力图都只需要查看主对角线(左上角到右下角对角线)的一侧即可,由于这里探究的是利润与其它三个影响因素之间的关系,因此只需要看最后一行的数据即可。数值在(0.45,1)或者(-1,-0,45)之间,都可以认为两者具有相关性。比如上面的输出结果,利润和电视投放以及广播投放都是有关联,而与新闻报纸的投放没有关联。
1)导入相应的工具包
2)本项目采用决策树、随机森林、K近邻、线性回归、岭回归四种算法,分别对广告投入进行学习和预测,并根据结果(见图 4 24至图 4 27所示)的均方误差,平均绝对误差,R值进行分析。
def model_fit1(data, a_colums):
# 制作训练集和测试集的数据
data_01 = data[a_colums]
Y = np.array(data_01['sales'])
data_02 = np.array(data_01.drop('sales', axis=1))
# 分割训练集和测试集
train_X, test_X, train_Y, test_Y = train_test_split(data_02, Y, test_size=0.2)
# 加载模型
linreg = LinearRegression()
# 拟合数据
linreg.fit(train_X, train_Y)
return linreg, test_X, test_Y

def model_fit2(data,a_colums):
# 构建数据集 训练模型
# 制作训练集和测试集的数据
data_01 = data[a_colums]
Y = np.array(data_01['sales'])
data_02 = np.array(data_01.drop('sales', axis=1))
# 分割训练集和测试集
train_X, test_X, train_Y, test_Y = train_test_split(data_02, Y, test_size=0.2)
ridge=Ridge()
ridge.fit(train_X,train_Y)
return ridge, test_X, test_Y

def model_fit3(data,a_colums):
data_01 = data[a_colums]
Y = np.array(data_01['sales'])
data_02 = np.array(data_01.drop('sales', axis=1))
# 分割训练集和测试集
train_X, test_X, train_Y, test_Y = train_test_split(data_02, Y, test_size=0.2)
randomForestRegressor=RandomForestRegressor(n_estimators=200, random_state=0)
randomForestRegressor.fit(train_X,train_Y)
return randomForestRegressor, test_X, test_Y

def model_fit4(data,a_colums):
# 构建数据集 训练模型
# 制作训练集和测试集的数据
data_01 = data[a_colums]
Y = np.array(data_01['sales'])
data_02 = np.array(data_01.drop('sales', axis=1))
# 分割训练集和测试集
train_X, test_X, train_Y, test_Y = train_test_split(data_02, Y, test_size=0.2)
k=5
kNeighborsRegressor=KNeighborsRegressor(k)
kNeighborsRegressor.fit(train_X,train_Y)
return kNeighborsRegressor, test_X, test_Y

def model_fit5(data,a_colums):
data_01 = data[a_colums]
Y = np.array(data_01['sales'])
data_02 = np.array(data_01.drop('sales', axis=1))
# 分割训练集和测试集
train_X, test_X, train_Y, test_Y = train_test_split(data_02, Y, test_size=0.2)
decisionTreeRegressor=DecisionTreeRegressor()
decisionTreeRegressor.fit(train_X,train_Y)
return decisionTreeRegressor, test_X, test_Y

结果显示,随机森林和决策树模型的R2(拟合优度)较高,均大于百分之九十。
3)接下来画出模型的学习曲线,观察模型的拟合情况。
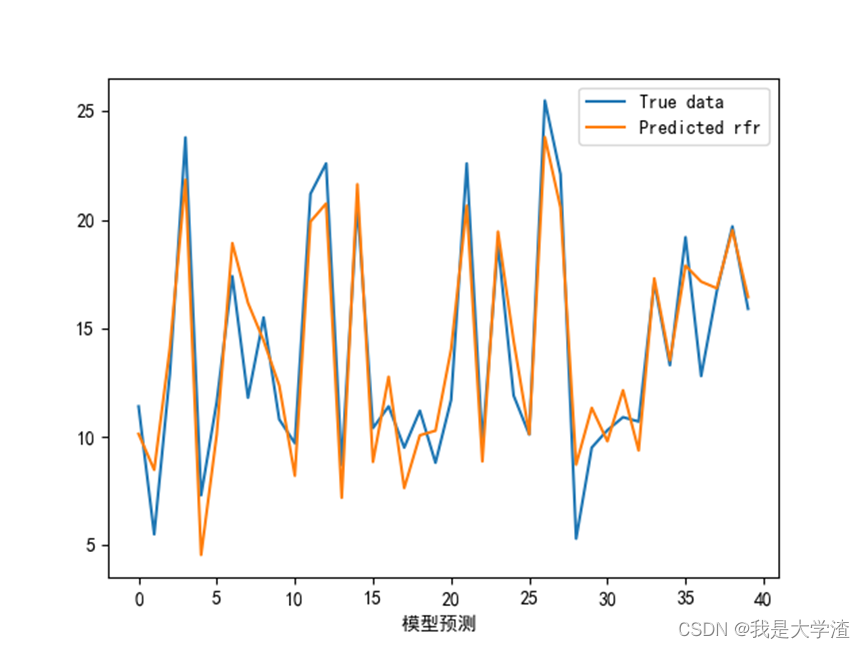
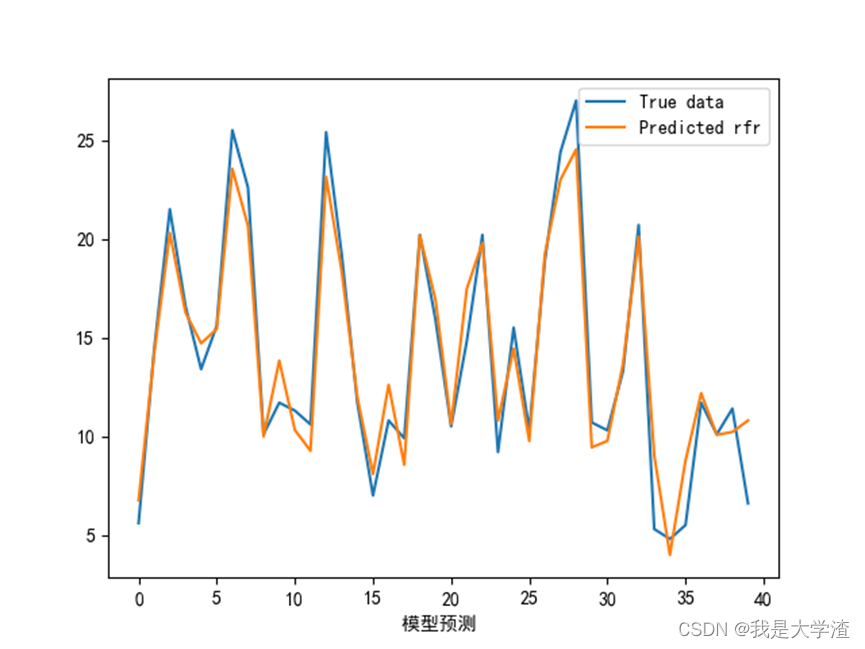
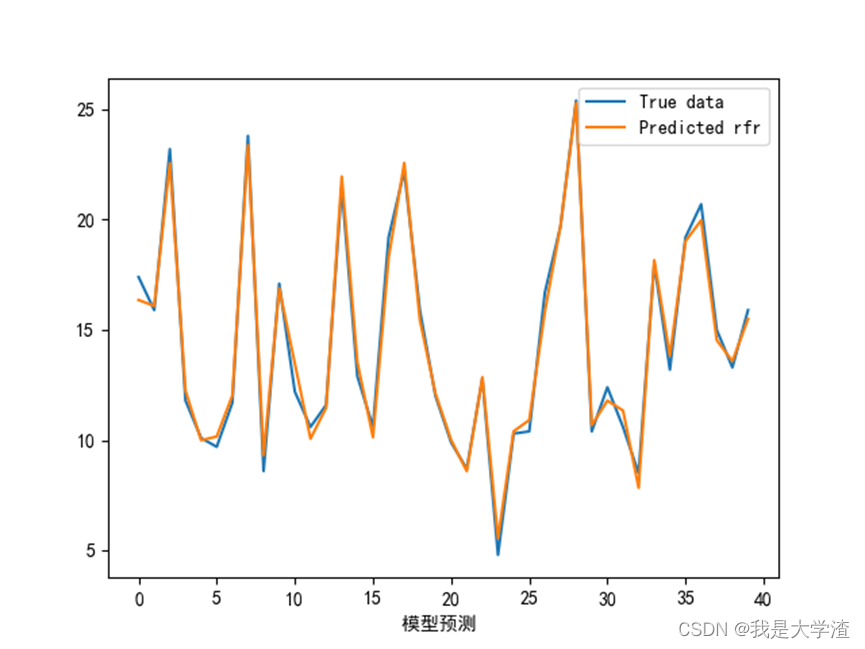
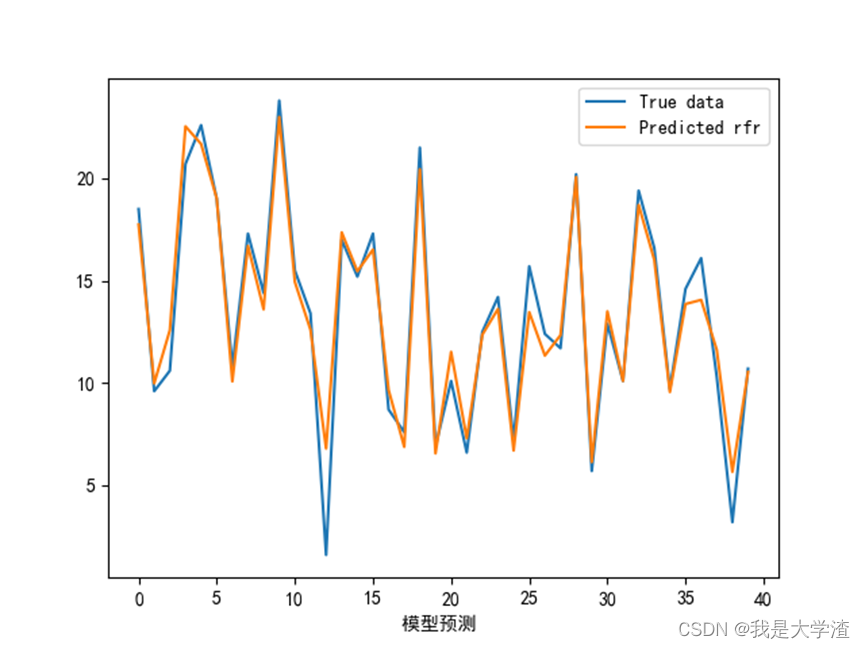
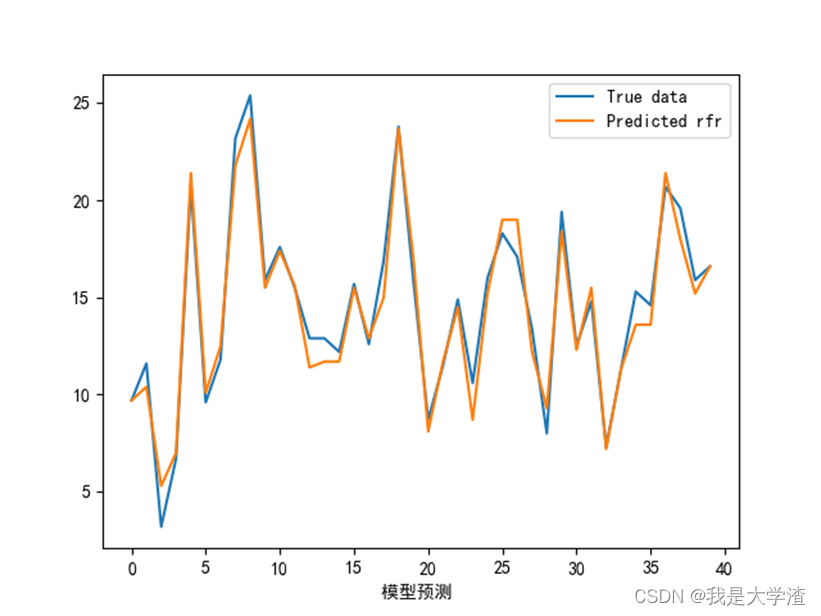
从结果来看,随机森林模型预测的准确性最高,基本与实际曲线拟合,这也更加直观的说明了此数据集用随机森林模型更加准确。
根据以上分析,可以得到如下结果:
要想增加商品的销售额,我们应该首先考虑增加电视广告和电台广告的投入量,因为商品的销售额与这两种广告投放方式的关系最大
我们要严格控制在报纸上的广告投入量,因为经过我们分析,报纸广告投入这种方式与销售额并没有什么明显关系,换句话说,加大报纸广告投入量并不能提高销售额,所以我们也就没有必要增加报纸的广告投入。
其实很早之前我就听说过python这门编程语言,它在各大编程排行网站上位居榜首,我也萌生出来想系统的学习它的想法,可是我总是给自己找借口,一拖再拖,始终没有开始学习。直到知道这学期我的专业课有python后,在选课时我特意选择了与之相关的这节选修课。在寒假时我也自行阅读了python的相关经典书籍和在专业课上的学习,掌握了基本语法和相关库的使用。可是我一直停留在看的阶段,并没有亲自去编写过较大的程序,也没有自己做过数据分析。经过这次项目的实战,我对python这门语言有了更深的理解,同时也了解了大数据分析的基本方法,也有了以下的总结。
1) python中的第三方库非常多,有很多程序不需要我们自己去编写,可以直接使用库里面的相关函数,这也是为什么python应用十分广泛的原因。
2) 伴随着大数据、云平台、物联网、人工智能技术的快速发展,大数据分析必然会发挥更大的作用。大数据的意义归根到底就四个字:辅助决策。利用大数据分析,能够分析现状、分析原因、发现规律、总结经验、和预测趋势,这些都可以为辅助决策服务。我们掌握的数据信息越多,我们的决策才能更加科学、精确、合理。从这个方面看,也可以说数据本身不产生价值,大数据必须和其他具体的领域、行业相结合,能够给决策者提供帮助之后,才具有价值。政府或企业都可以借助大数据,提升管理、决策水平,提升经济效益。
3) 只有实战才能真正提高自己的编程水平,和对相关知识的理解,单纯的听课和看书只能增加理论知识,编程需要实战,不然只会眼高手低,看着很简单的问题自己就是解决不了。
4) 课程虽然结束了,但是我不能停止学习,在后期的学习中,我应该注重自己在语言的应用上层面上,不能只会纸上谈兵,在编程的过程中难买会遇到问题,保持独立思考的习惯,查询相关资料去解决,而不能就此放弃。
✨ 原 创 不 易 , 还 希 望 各 位 大 佬 支 持 一 下
👍 点 赞 , 你 的 认 可 是 我 创 作 的 动 力 !
⭐️ 收 藏 , 你 的 青 睐 是 我 努 力 的 方 向 !
✏️ 评 论 , 你 的 意 见 是 我 进 步 的 财 富 !
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
我正在寻找用于Rails的优质管理插件。似乎大多数现有的插件/gem(例如“restful_authentication”、“acts_as_authenticated”)都围绕着self注册等展开。但是,我正在寻找一种功能齐全的基于管理/管理角色的解决方案——但不是简单地附加到另一个非基于角色的解决方案。如果我找不到,我想我会自己动手......只是不想重新发明轮子。 最佳答案 RyanBates最近做了两个关于授权的railscast(注意身份验证和授权之间的区别;身份验证检查用户是否如她所说的那样,授权检查用户是否有权访问资源
我正在根据Rakefile中的现有测试文件动态生成测试任务。假设您有各种以模式命名的单元测试文件test_.rb.所以我正在做的是创建一个以“测试”命名空间内的文件名命名的任务。使用下面的代码,我可以用raketest:调用所有测试require'rake/testtask'task:default=>'test:all'namespace:testdodesc"Runalltests"Rake::TestTask.new(:all)do|t|t.test_files=FileList['test_*.rb']endFileList['test_*.rb'].eachdo|task|n
我想要像“嘿那里”这样的东西变成,例如,#316583。我希望将任意长度的字符串“归结”为十六进制颜色。我不知道从哪里开始。我在想,每个字符串的MD5散列都是不同的-但如何将该散列转换为十六进制颜色数字? 最佳答案 你可以只取几位前几位:require'digest/md5'color=Digest::MD5.hexdigest('Mytext')[0..5] 关于ruby-如何使用Ruby基于字母数字字符串生成颜色?,我们在StackOverflow上找到一个类似的问题:
目录0专栏介绍1平面2R机器人概述2运动学建模2.1正运动学模型2.2逆运动学模型2.3机器人运动学仿真3动力学建模3.1计算动能3.2势能计算与动力学方程3.3动力学仿真0专栏介绍?附C++/Python/Matlab全套代码?课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等);局部规划(DWA、APF等);曲线优化(贝塞尔曲线、B样条曲线等)。?详情:图解自动驾驶中的运动规划(MotionPlanning),附几十种规划算法1平面2R机器人概述如图1所示为本文的研究本体——平面2R机器人。对参数进行如下定义:机器人广义坐标
网站的日志分析,是seo优化不可忽视的一门功课,但网站越大,每天产生的日志就越大,大站一天都可以产生几个G的网站日志,如果光靠肉眼去分析,那可能看到猴年马月都看不完,因此借助网站日志分析工具去分析网站日志,那将会使网站日志分析工作变得更简单。下面推荐两款网站日志分析软件。第一款:逆火网站日志分析器逆火网站日志分析器是一款功能全面的网站服务器日志分析软件。通过分析网站的日志文件,不仅能够精准的知道网站的访问量、网站的访问来源,网站的广告点击,访客的地区统计,搜索引擎关键字查询等,还能够一次性分析多个网站的日志文件,让你轻松管理网站。逆火网站日志分析器下载地址:https://pan.baidu.
文章目录1.自动驾驶实战:基于Paddle3D的点云障碍物检测1.1环境信息1.2准备点云数据1.3安装Paddle3D1.4模型训练1.5模型评估1.6模型导出1.7模型部署效果附录show_lidar_pred_on_image.py1.自动驾驶实战:基于Paddle3D的点云障碍物检测项目地址——自动驾驶实战:基于Paddle3D的点云障碍物检测课程地址——自动驾驶感知系统揭秘1.1环境信息硬件信息CPU:2核AI加速卡:v100总显存:16GB总内存:16GB总硬盘:100GB环境配置Python:3.7.4框架信息框架版本:PaddlePaddle2.4.0(项目默认框架版本为2.3
一、机器人介绍 此处是基于MATLABRVC工具箱,对ABB-IRB-1200型号的微型机械臂进行正逆向运动学分析,并利Simulink工具实现对机械臂进行具有动力学参数的末端轨迹规划仿真,最后根据机械模型设计Simulink-Adams联合仿真。 图1.ABBIRB 1200尺寸参数示意图ABBIRB 1200提供的两种型号广泛适用于各作业,且两者间零部件通用,两种型号的工作范围分别为700 mm 和 900 mm,大有效负载分别为 7 kg 和5 kg。 IRB 1200 能够在狭小空间内能发挥其工作范围与性能优势,具有全新的设计、小型化的体积、高效的性能、易于集成、便捷的接