众多大型集团公司在应用RPA(机器人流程自动化)之初,往往从某个具体的业务流程入手。随着越来越多部门开始部署RPA,集团整体自动化需求日益增加。如果缺乏统一调度,将造成企业内部资源冗余,各部门难以形成聚合效应。

01
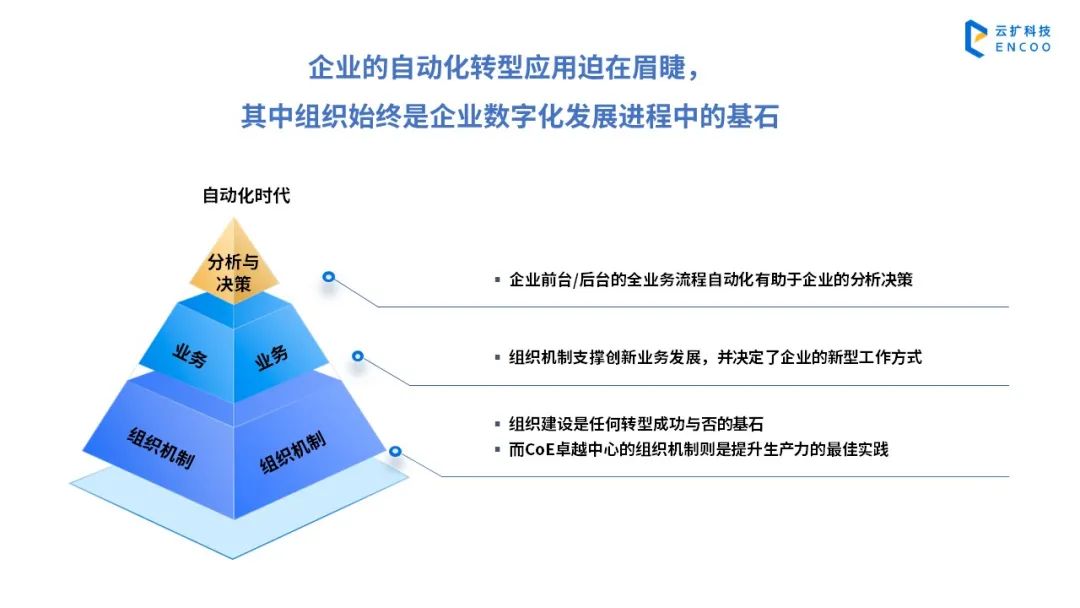
为加速企业自动化转型,大型集团公司纷纷采取建立RPA卓越中心(CoE)的方式,为企业赋能转型能力。RPA卓越中心是一个跨职能的虚拟组织模式,最早是为了促进协作,支持RPA专业部署和实现。数字化转型更趋于“由内而外”与“自下而上”进行,RPA卓越中心结合管理机制,逐渐发展成为了一种有效的治理机制。
RPA卓越中心能帮助多数集团公司低成本、高效率地推动数字化转型,促进集团人机协作的能力,为人工智能落地打好基础。
02
云扩五步法,助力集团公司从0到1轻松搭建RPA卓越中心:
与高层达成建立RPA卓越中心的战略共识,共同推进项目启动。
定义RPA卓越中心目标和成功指标、卓越中心覆盖的活动并创建活动目录。其次,明确启动时间,制定项目计划。根据企业的需求,可在此阶段估计运营成本和范围。
定义RPA卓越中心组织中的各类型角色,并制定员工选择标准;为RPA卓越中心进行内外部资源协调,如需要可进行外部招聘,最终构建RPA卓越中心敏捷小组。
建立RPA卓越中心沟通计划,以及日常的工作机制。
RPA卓越中心搭建完成后,对已成功运行的项目进行定期监控评估。

云扩已服务来自金融、能源、电信、财税、制造、物流、零售等多个行业的数千家集团,囊括国药集团、泉峰、强生等世界五百强集团,成功辅助众多客户从0到1构建起科学合理的RPA卓越中心,以创新驱动增长,为客户提供有竞争力、安全可信赖的RPA产品,以及更智能的流程自动化解决方案。
03
云扩帮助强生(中国)亚太区构建RPA卓越中心,搭建数字员工集群。通过RPA卓越中心,强生将自动化转型的能力赋予企业内部各个业务条线。
我们帮助企业挖掘项目潜力、启动试点、成熟化项目,并迅速扩大规模,在集团企业内部实现价值和最大限度地发挥RPA的技术潜力。集中协调亚太区域IT资源部署,覆盖中国、韩国、日本等多区域市场,实现强生自动化转型的持续高质量交付。

云扩协助强生建立RPA卓越中心小组,成员来自各个核心部门的同事,共同推进RPA在内部落地。其次,建立一套完善的日常工作沟通机制,定期开展周例会,并及时更新各相关方项目进度,便于跨区域的沟通对接。
流程上线后,卓越中心持续为公司提供培训、宣贯与日常维护。通过为客户定制RPA卓越中心内部落地方案,更快的赋能企业内部,自主开展自动化转型。
截至目前,强生内部已有100+自动化流程上线,覆盖电商订单管理、财务对账等多类型场景,需求仍在不断延伸。各区域的业务人员还通过云扩的控制台集中管理、监控区域内的所有机器人,实时掌握数字化平台为企业带来的效益与节省的人力。

RPA卓越中心为强生以及同类大型集团客户带来以下四大价值:
一、自上而下统一管理,加速RPA在企业内部的应用。过去各业务部门各自为政,缺少统一管理与规划。如今,由IT统一牵头,从战略层面向下渗透,更快速高效的在企业内部推广自动化转型。
二、集中有效管控,提升能力开发。RPA卓越中心能以组织机制建设为手段,集中专业知识和资源统一指导复杂问题的解决,提升部署开发能力。
三、以点及面牵头试水,降低其他市场潜在的部署成本。以韩国市场为试点作为最佳开发实践,降低其他市场的部署风险,确保RPA在企业应用中保持技术部署的一致性。
四、流程组件化在未来减少企业内部自动化成本。利用规模化和标准化的组件沉淀,设计稳定、标准和可重复的流程,提高企业内部生产力。
04
1.指定总管,执行负责。管理经营层的支持和参与可以帮助克服落地中的许多障碍,指定一个执行主席领导RPA项目发展必不可少。
2.制定目标,立马行动。为企业内部第一个RPA自动化项目制定部署时间目标,以目标为导向,尽快启动任务。
3.业务科技,紧密合作。业务部门需要与IT科技部门紧密合作,了解RPA落地过程中在企业内部的技术和安全需求。
4.投入人力,培训技能。通过培训,发展熟练的团队成员成为全职RPA开发人员。精通技术、了解企业内部业务流程的员工可以更快通过自动化推动价值。
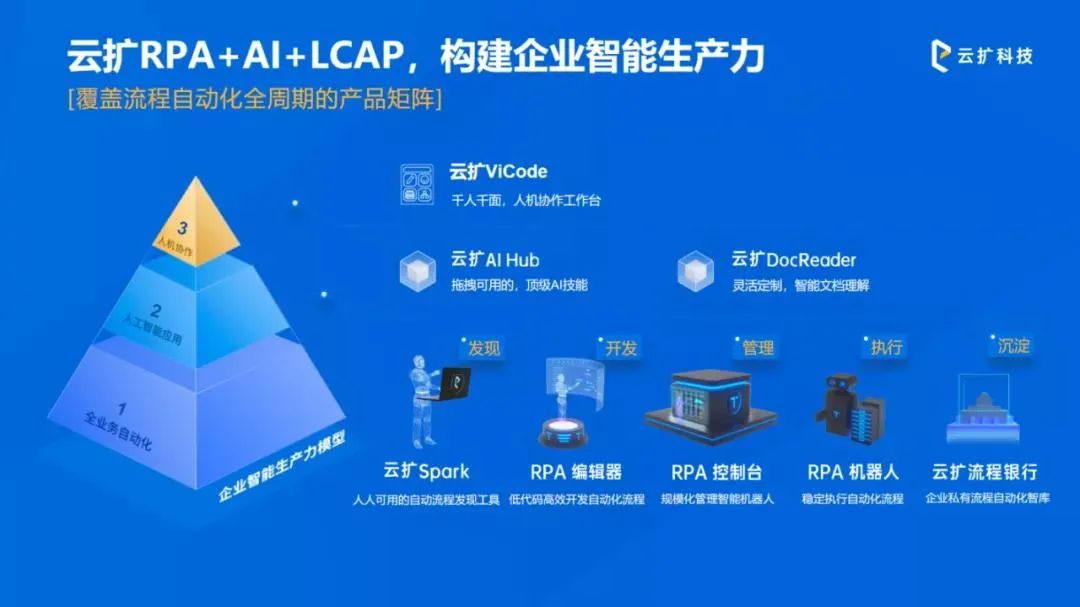
云扩以业内领先的RPA+LCAP双驱动模式,为集团提供覆盖流程自动化全周期的智能产品矩阵,在构建RPA卓越中心过程中,助力客户轻松实现跨部门流程优化,有效管理评估流程需求,建立成熟科学可实践的流程价值评估体系。
携手云扩快速构建RPA卓越中心,帮助企业以更灵敏、更具创造力的人工智能布局未来,以创新增效抵御风险,形成科学合规的自动化流程管理体系,指导业务部门更高效地落地人工智能,释放企业增长潜能,加速数字化转型。


推荐阅读



-END-
云扩科技是RPA领域的创新领军者,我们致力于构建业界领先的超自动化平台,助力企业提升智能生产力,加速数字化转型。
我有33个规范以大约5秒的速度运行,以这种速度运行会导致测试套件变慢。我追踪到请求规范(4秒以上),因为模型规范只用了一小部分时间。我已经检查过,我的请求规范没有任何过于复杂或不必要的东西,所以我不知道该去哪里让它们更快,而不是只在推送代码之前运行它们以确保一切正常.加快请求规范的最佳方法是什么? 最佳答案 我使用Spork来加速我的测试。它保持整个环境加载以赢得时间。看看这个博客:http://ykyuen.wordpress.com/2010/12/14/rails-running-rspec-with-spork-test-s
一、什么是web项目ui自动化测试?通过测试工具模拟人为操控浏览器,使软件按照测试人员的预定计划自动执行测试的一种方式,可以完成许多手工测试无法完成或者不易实现的繁琐工作。正确使用自动化测试,可以更全面的对软件进行测试,从而提高软件质量进而缩短迭代周期。二、构建测试用例的“九部曲”(一)创建流程包划分功能模块日常测试活动中,都会根据功能模块进行拆分,所以在设计器中我们可以通过创建流程包的方式来拆分需要测试的功能模块,如下图中操作创建一个电脑流程包并且取名为对应的功能模块名称,如果有多个功能模块就创建多个对应的流程包,实在RPA设计器有易用的图形可视化界面,方便管理较多的功能模块。(二)在流程包
我有一个客户列表,但在右栏的过滤器部分,我得到一个这样的列表#在选择菜单中。如何改为显示Customer的company_name属性? 最佳答案 明白了,谢谢!filter:customer,:collection=>proc{(Customer.all).map{|c|[c.company_name,c.id]}} 关于ruby-on-rails-Rails3和ActiveAdmin。过滤器显示对象而不是公司名称,我们在StackOverflow上找到一个类似的问题:
对于一个项目,我需要解析一些非常大的CSV文件。一些条目的内容存储在MySQL数据库中。我正在尝试使用多线程来加快速度,但到目前为止,这只会减慢速度。我解析了一个CSV文件(最大10GB),其中一些记录(20M+记录CSV中的大约5M)需要插入到MySQL数据库中。为了确定需要插入的记录,我们使用Redis服务器和包含正确ID/引用的集合。由于我们在任何给定时间处理大约30个这样的文件,并且存在一些依赖关系,我们将每个文件存储在一个Resque队列中,并让多个服务器处理这些(优先级)队列。简而言之:classWorkerdefself.perform(file)CsvParser.ea
我使用geokit和geokit-railsgemforrails有一段时间了,但我还没有找到答案的一个问题是如何找到一组点的计算聚合中心。我知道如何计算两点之间的距离,但不会超过2。我的理由是,我在同一个城市中有一系列的点……一切都完美的城市会有一个我可以使用的中心,但有些城市,比如柏林没有一个完美的中心。他们有多个中心,我只想使用我数据库中的所有地点列表来计算特定分布的中心。还有其他人遇到过这个问题吗?有什么建议吗?谢谢 最佳答案 之前从未使用过Geokit,这个操作背后的数学原理相对容易自己实现。假设这些点由纬度和经度组成,您
在编译sass时,我的编译时间往往很长(在当前的中型项目中长达9秒),而我的笔记本电脑速度非常快,而且带有ssd。我通过grunt-contrib-sass使用sassass一个grunt任务,但是直接从命令行运行sass时编译时间差别不大。Libsass另一方面,同一个项目只需要大约100毫秒,但它不支持我需要的几个功能。所以我想知道我有什么可能加快编译过程?拆分文件当然有帮助,但是还有其他副作用更小的方法吗?编辑:此外,我也很乐意解释libsass为什么比ruby-sass快得多。不知何故,我非常怀疑这只是因为ruby比C/C++慢得多。还是我错了?编辑2:当我使用Ubun
我使用Octopress作为我的博客引擎。这是完美的。但是如果帖子很多,比如400+,生成速度就很慢了。那么,有什么方法可以加快Jekyll/Octopress的生成速度吗?谢谢。 最佳答案 显然,如果您只处理一篇文章,则无需等待整个站点生成。您正在寻找的是rakeisolate[partial_post_name]任务。使用rakeisolate,您可以仅“隔离”您正在处理的帖子,并将所有其他帖子移至source/_stash文件夹。partial_post_name参数只是帖子文件名中的一些单词。例如,如果我想将帖子与前面的示例
(二十二)-框架主入口main.py设计&log日志调用和生成1测试目的2测试需求3需求分析4详细设计4.1新建存放日志目录log4.1.1配置config.py中写入log的目录4.2`baseInfo.py`中加入日志4.3`test_gedit.py`中加入日志4.4主函数入口main.py中调用日志5调用日志主函数main.py源码6`baseInfo.py`源码7`test_gedit.py`源码8运行效果9目前框架结构1测试目的组织运行所有的测试用例,并调用日志模块,便于问题定位。
(1)为什么写这个话题(Why)读万卷书不如行千里路。这次搭建MQTT服务,遇到了一些误解,特此记录备忘。主要包括:(1)服务(Broker)的账户管理与网页管理平台的账户(2)与web应用的集成(Spring系)(2)ActiveMQ版本选择因为JAVA环境是JDK8,所以按兼容性考虑选择了ActiveMQ5.15的最后版本5.15.15。如果你是JDK11则可考虑ActiveMQ的最新版本5.17或5.18。ActiveMQ支持MQTTv3.1.1andv3.1。(3)ActiveMQ与web应用的集成主要介绍与Spring系的webapp集成(SpringBoot和SpringMVC)。
这篇文章,主要介绍如何使用SpringCloud微服务组件从0到1搭建一个微服务工程。目录一、从0到1搭建微服务工程1.1、基础环境说明(1)使用组件(2)微服务依赖1.2、搭建注册中心(1)引入依赖(2)配置文件(3)启动类1.3、搭建配置中心(1)引入依赖(2)配置文件(3)启动类1.4、搭建API网关(1)引入依赖(2)配置文件(3)启动类1.5、搭建服务提供者(1)引入依赖(2)配置文件(3)启动类1.6、搭建服务消费者(1)引入依赖(2)配置文件(3)启动类1.7、运行测试一、从0到1搭建微服务工程1.1、基础环境说明(1)使用组件这里主要是使用的SpringCloudNetflix