目录
整数二分步骤:
1.找一个区间[L,R],使得答案一定在该区间中
2找一个判断条件,使得该判断条件具有二段性,并且答案一定是该二段性的分界点。
3.分析终点M在该判断条件下是否成立,如果成立,考虑答案在哪个区间;如果不成立,考虑答案在哪个区间;
4.如果更新方式写的是R(右) = Mid,则不用做任何处理;如果更新方式写的是L(左)= Mid,则需要在计算Mid时加上1。
给定一个按照升序排列的长度为n的整数数组,以及q个查询。
对于每个查询,返回一个元素k的起始位置和终止位置(位置从О开始计数)。如果数组中不存在该元素,则返回-1 -1 。
输入格式
第一行包含整数n和q,表示数组长度和询问个数。
第二行包含n个整数(均在1~10000范围内),表示完整数组。接下来q行,每行包含一个整数k,表示一个询问元素。
输出格式
共q行,每行包含两个整数,表示所求元素的起始位置和终止位置。如果数组中不存在该元素,则返回-1 -1。
数据范围
1<n ≤100000
1≤q≤10000
1≤k ≤10000
输入样例:
6 3
1 2 2 3 3 4
3
4
5
输出样例:
3 4
5 5
-1 -1#include<iostream>
using namespace std;
const int N=100010;
int n,m;
int q[N];
int main()
{
scanf("%d%d",&n,&m);
for(int i=0;i<n;i++) scanf("%d",&q[i]);
while(m--)
{
int x;
scanf("%d",&x);
int l=0,r=n-1;
while(l<r) //取始下标
{
int mid=l+r>>1;
if(q[mid]>=x) r=mid;
else l=mid+1;
}
if(q[l]!=x) cout<<"-1 -1"<<endl;
else
{
cout<<l<<' ';
int l=0,r=n-1;
while(l<r) //取末下标
{
int mid=l+r+1>>1;
if(q[mid]<=x) l=mid;
else r=mid-1;
}
cout<<l<<endl;
}
}
return 0;
}记忆:写完模板后看案例分析始末下标,当 l (左)= mid 时必须mid+1
给定一个浮点数n,求它的三次方根。
输入格式
共一行,包含一个浮点数n。
输出格式
共一行,包含一个浮点数,表示问题的解。注意,结果保留6位小数。
数据范围
-10000<n≤10000
输入样例:
1000.00
输出样例:
10.000000#include<iostream>
using namespace std;
int main()
{
double l=-100000,r=100000; //数据结果必在其之间,不用思考
double n,m;
cin>>n;
while(r-l>1e-8) //精确到为1e-6,所以至少要多精确两位
{
m=(l+r)/2;
if(m*m*m>=n) r=m; //立方根n在mid的左边,缩右边界
else l=m;
}
printf("%.6f",m);
return 0;
}
来源:今日头条2019,笔试题

输入样例1:
5
3 4 3 2 4
输出样例1:
4
输入样例2:
3
4 4 4
输出样例2:
4
输入样例3:
3
1 6 4
输出样例3:
3思路:
如例一高度 3 4 3 2 4

可以发现通过计算 E=2E-H(k+1),那么只需要将数组所有值带入公式,找到刚好大于0的E即可;
#include<iostream>
#include<cstring>
using namespace std;
const int N=1e5+10;
int n;
int h[N];
bool check(int e)
{
for(int i=1;i<=n;i++)
{
e=e*2-h[i];
if(e<0) return false;
if(e>1e5) return true;//防止爆int
}
return true;
}
int main()
{
cin>>n;
for(int i=1;i<=n;i++) cin>>h[i];
int l=0,r=1e5;
while(l<r)
{
int mid=l+r>>1;
if(check(mid)) r=mid;
else l=mid+1;
}
cout<<l<<endl;
return 0;
}总结:
当题目求“至少”、“至多”,且具有二段性or单调性时,可以考虑二分
(二段性:以某个值为临界,这个值一边的都满足要求,另一边都不满足)
来源:第八届蓝桥杯省赛C++A/B组,第八届蓝桥杯省赛JAVAA/B组

输入样例:
2 10
6 5
5 6
输出样例:
2 
具有单调性与二段性,用二分!
#include<iostream>
using namespace std;
int n,k;
const int N=1e5+10;
int h[N],w[N];
int check(int m)
{
int ret=0;
for(int i=0;i<n;i++)
{
ret+=(h[i]/m)*(w[i]/m);
if(ret>=k) return 1;
}
return 0;
}
int main()
{
cin>>n>>k;
for(int i=0;i<n;i++) cin>>h[i]>>w[i];
int l=1,r=1e5;
while(l<r)
{
int mid=l+r+1>>1;
if(check(mid)) l=mid;
else r=mid-1;
}
cout<<l;
return 0;
}
输入一个长度为n的整数序列。
接下来再输入m个询问,每个询问输入一对l, r。
对于每个询问,输出原序列中从第 l 个数到第r个数的和。
输入格式
第一行包含两个整数n和m。
第二行包含n个整数,表示整数数列。
接下来m行,每行包含两个整数l和r,表示一个询问的区间范围。
输出格式
共m行,每行输出一个询问的结果。
数据范围
1≤l<r ≤n,1 ≤n, m ≤100000,
—1000≤数列中元素的值≤1000
输入样例:
5 3
2 1 3 6 4
1 2
1 3
2 4
输出样例:
3
6
10#include<iostream>
#include<algorithm>
#include<cstdio>
#include<cstring>
using namespace std;
const int N=1e5+10;
int n,m;
int a[N];
int s[N];
int main()
{
cin>>n>>m;
for(int i=1;i<=n;i++)
{
cin>>a[i];
s[i]=s[i-1]+a[i];
}
while(m--)
{
int l,r;
cin>>l>>r;
cout<<s[r]-s[l-1]<<endl;
}
return 0;
}
来源:第八届蓝桥杯省赛C++B组,第八届蓝桥杯省赛JAVAB组

思路:
#include<iostream>
using namespace std;
typedef long long ll;
const int N=1e5+10;
int n,k;
ll s[N];
int cnt[N];
int main()
{
scanf("%d%d",&n,&k);
for(int i=1;i<=n;i++)
{
scanf("%lld",&s[i]);
s[i]+=s[i-1];
}
ll ans=0;
cnt[0]=1;
for(int i=1;i<=n;i++)
{
ans+=cnt[s[i]%k];
cnt[s[i]%k]++;
}
cout<<ans;
return 0;
}
输入一个n行m列的整数矩阵,再输入q个询问,每个询问包含四个整数:x1,y1,x2,y2,表示一个子矩阵的左上角坐标和右下角坐标。
对于每个询问输出子矩阵中所有数的和。
输入格式
第一行包含三个整数n, m,q。
接下来n行,每行包含m个整数,表示整数矩阵。
接下来q行,每行包含四个整数x1,y1,x2,y2,表示一组询问。
输出格式
共q行,每行输出一个询问的结果。
数据范围
1≤n, m ≤1000, 1≤q≤200000, 1≤1 ≤2 ≤n,1≤91≤J2≤m,
-1000≤矩阵内元素的值≤1000
输入样例:
3 4 3
1 7 2 4
3 6 2 8
2 1 2 3
1 1 2 2
2 1 3 4
1 3 3 4
输出样例:
17
27
21

用容斥原理推出公式;

首先算出每一个坐标的前缀和s [ i ] [ j ],在前缀和矩阵中再用一次容斥原理
#include <cstdio>
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 1010;
int n, m, q;
int a[N][N], s[N][N];
int main()
{
scanf("%d%d%d", &n, &m, &q);
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= m; j ++ )
{
scanf("%d", &a[i][j]);
s[i][j] = s[i - 1][j] + s[i][j - 1] - s[i - 1][j - 1] + a[i][j];
}
while (q -- )
{
int x1, y1, x2, y2;
scanf("%d%d%d%d", &x1, &y1, &x2, &y2);
printf("%d\n", s[x2][y2] - s[x1 - 1][y2] - s[x2][y1 - 1] + s[x1 - 1][y1 - 1]);
}
return 0;
}

6 3
1 2 2 1 2 1
1 3 1
3 5 1
1 6 1差分思路:
首先给定一个原数组a:a[1], a[2], a[3],,,,,, a[n];
然后我们构造一个数组b : b[1] ,b[2] , b[3],,,,,, b[i];
使得 a[i] = b[1] + b[2 ]+ b[3] +,,,,,, + b[i]
即:
a[0 ]= 0;
b[1] = a[1] - a[0];
b[2] = a[2] - a[1];
b[3] =a [3] - a[2];
........
b[n] = a[n] - a[n-1];
a数组是b数组的前缀和数组,比如对b数组的b[i]的修改,会影响到a数组中从a[i]及往后的每一个数。
首先让差分b数组中的 b[l] + c ,a数组变成 a[l] + c ,a[l+1] + c,,,,,, a[n] + c;
然后我们打个补丁,b[r+1] - c, a数组变成 a[r+1] - c,a[r+2] - c,,,,,,,a[n] - c;
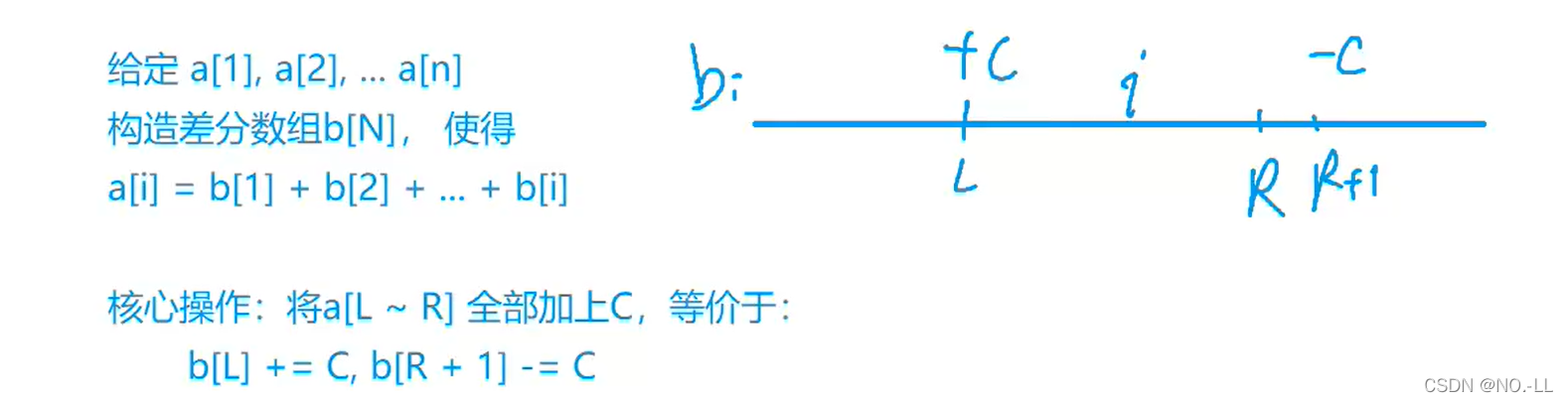
核心操作:对差分数组b做 b[l] + = c, b[r+1] - = c(时间复杂度为O(1) )

#include<iostream>
using namespace std;
const int N = 1e5 + 10;
int a[N], b[N];
int main()
{
int n, m;
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i++)
{
scanf("%d", &a[i]);
b[i] = a[i] - a[i - 1]; //构建差分数组
}
int l, r, c;
while (m--)
{
scanf("%d%d%d", &l, &r, &c);
b[l] += c; //将序列中[l, r]之间的每个数都加上c
b[r + 1] -= c;
}
for (int i = 1; i <= n; i++)
{
a[i] = b[i] + a[i - 1]; //前缀和运算
printf("%d ", a[i]);
}
return 0;
}

输入样例:
3 4 3
1 2 2 1
3 2 2 1
1 1 1 1
1 1 2 2 1
1 3 2 3 2
3 1 3 4 1
输出样例:
2 3 4 1
4 3 4 1
2 2 2 2
思路与二维前缀和相似:
操作1、
b[x1][y1] + = c;
b[x1,][y2+1] - = c;
b[x2+1][y1] - = c;
b[x2+1][y2+1] + = c;
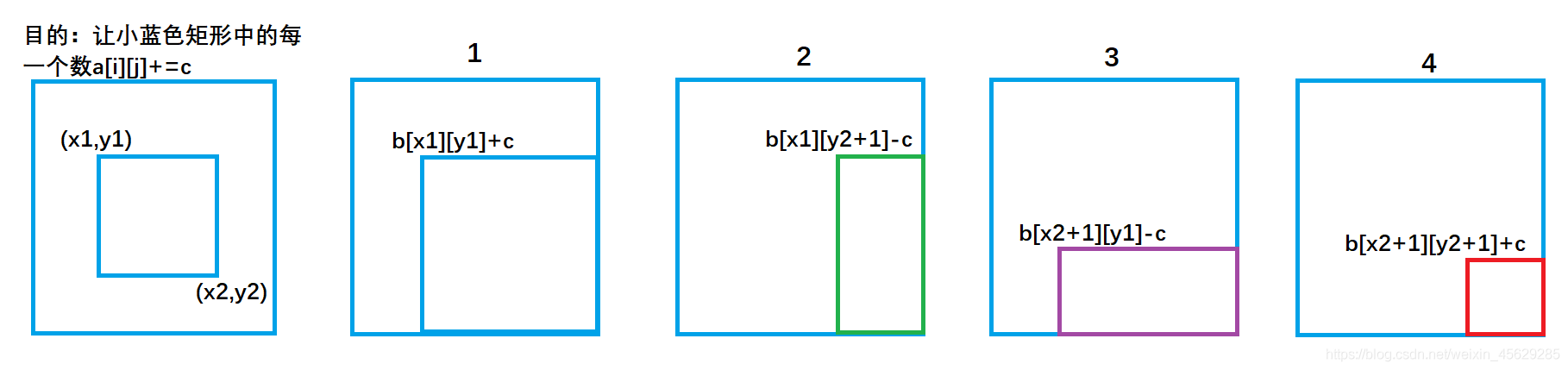 每次对b数组执行以上操作,等价于:
每次对b数组执行以上操作,等价于:
for(int i=x1;i<=x2;i++)
for(int j=y1;j<=y2;j++)
a[i][j]+=c;操作2、
我们每次让以(i,j)为左上角到以(i,j)为右上角面积内元素(其实就是一个小方格的面积)去插入 c=a[i][j],等价于原数组a中(i,j) 到(i,j)范围内 加上了 a[i][j] ,因此执行n*m次插入操作,就成功构建了差分b数组.
说白了,就是让c=a[i][j],把操作1的方法用在一个空数组上,用n*m遍,操作完之后这个数组就是差分数组b[i][j]。
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= m; j ++ )
insert(i, j, i, j, a[i][j]); //构建差分数组
AC代码:
#include <iostream>
using namespace std;
const int N = 1010;
int n, m, q;
int a[N][N], b[N][N];
void insert(int x1, int y1, int x2, int y2, int c)
{
b[x1][y1] += c;
b[x2 + 1][y1] -= c;
b[x1][y2 + 1] -= c;
b[x2 + 1][y2 + 1] += c;
}
int main()
{
scanf("%d%d%d", &n, &m, &q);
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= m; j ++ )
scanf("%d", &a[i][j]);
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= m; j ++ )
insert(i, j, i, j, a[i][j]); //构建差分数组
while (q -- )
{
int x1, y1, x2, y2, c;
cin >> x1 >> y1 >> x2 >> y2 >> c;
insert(x1, y1, x2, y2, c);
}
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= m; j ++ )
b[i][j] += b[i - 1][j] + b[i][j - 1] - b[i - 1][j - 1];
//a[i]是差分数组b[i]的前缀和
for (int i = 1; i <= n; i ++ )
{
for (int j = 1; j <= m; j ++ ) printf("%d ", b[i][j]);
puts("");
}
return 0;
}

目录前言: 一、ASC分析代码实现二、 卡片分析代码实现三、 直线分析代码实现四、货物摆放分析代码实现小结:前言: 在刷题的过程中,发现蓝桥杯的题目和力扣的差别很大。让人有一种不一样的感觉,蓝桥杯题目偏向对于实际问题用编程去的解决,而力扣给人感觉很锻炼自己的编程思维,逻辑能力。两者结合去刷,相信会有不一样的收获。 一、ASC 已知大写字母A的ASCII码为65,请问大写字母L的ASCII码是多少?分析 这道题目看上去很简单,我们需确定自己计算的准确,所以我建议用编程去解决。代码实现publicclassTest8{publicstaticvoidmain(String[]args){Sy
在DavidFlanagan的TheRubyProgrammingLanguage中;松本幸弘theystatethatthevariableprefixes($,@,@@)areonepricewepayforbeingabletoomitparenthesesaroundmethodinvocations.谁可以给我解释一下这个? 最佳答案 这是我不成熟的意见。如果我错了,请纠正我。假设实例变量没有@前缀,那么我们如何声明一个实例变量?classMyClassdefinitialize#Herefooisaninstanceva
Ruby错误消息通常包含带单字母前缀的词法常量,例如:syntaxerror,unexpectedtIDENTIFIER,expectingkENDt和k从哪里来?还有其他字母吗?可能的关键字的主列表? 最佳答案 对于此类问题,parse.y通常是看的地方。如果没记错的话,'t'代表token,而'k'代表关键字。以下是表示标识符的不同标记(在其他事物的名称意义上):%tokentIDENTIFIERtFIDtGVARtIVARtCONSTANTtCVARtLABEL我通过快速搜索找到的kEND的唯一定义是k_end:k_end:k
?作者主页:静Yu?简介:CSDN全栈优质创作者、华为云享专家、阿里云社区博客专家,前端知识交流社区创建者?社区地址:前端知识交流社区?博主的个人博客:静Yu的个人博客?博主的个人笔记本:前端面试题个人笔记本只记录前端领域的面试题目,项目总结,面试技巧等等。接下来会更新蓝桥杯官方系统基础练习的VIP试题,依然包括解题思路,源代码等等。问题描述:给定当前的时间,请用英文的读法将它读出来。时间用时h和分m表示,在英文的读法中,读一个时间的方法是: 如果m为0,则将时读出来,然后加上“o’clock”,如3:00读作“threeo’clock”。 如果m不为0,则将时读出来,然后将分读出来,如5
我的哈希中有以下键:address,postcode我想为它们中的每一个添加“shipping_”前缀,这样它们就变成了:shipping_address,shipping_postcode相反。我该怎么做? 最佳答案 hsh1={'address'=>"foo",'postcode'=>"bar"}hsh2=Hash[hsh1.map{|k,v|[k.dup.prepend("shipping_"),v]}]phsh2#>>{"shipping_address"=>"foo","shipping_postcode"=>"bar"}
本篇讲的是常见的搜索模板,搜索题的解法时比较固定的,只要把模板记熟,加上自己找几道习题练习体会后,相信各位下次遇到这类题一定能拿下!!下面我将已典型的题目为例子介绍几种常见的搜索方式。 1.二分搜索二分搜索代码模板:例题:#includeusingnamespacestd;doublen;constdoubleeps=1e-12;//二分搜索intmain(){ intt; cin>>t; while(t--){ cin>>n; doublel=0,r=100000,res=-1; while(ln)r=mid-0.0001; elseif(mid*mid*mid二分搜索是只能对有
RubyString类中是否有任何内置函数可以为我提供Ruby中字符串的所有前缀。像这样的东西:"ruby".all_prefixes=>["ruby","rub","ru","r"]目前我已经为此做了一个自定义函数:defall_prefixessearch_stringdup_string=search_string.dupreturn_list=[]while(dup_string.length!=0)return_list但我正在寻找更像ruby、更少代码和神奇的东西。注意:当然不用说original_string应该保持原样。 最佳答案
我正在尝试解析YoutubeGdata以查看是否存在具有给定ID的视频。但是没有普通的标签,而是带有命名空间。在链接上http://gdata.youtube.com/feeds/api/videos?q=KgfdlZuVz7I有标签:1有命名空间openSearch:xmlns:openSearch='http://a9.com/-/spec/opensearchrss/1.0/'但我不知道如何在Nokogiri和Ruby中处理它。部分代码如下:xmlfeed=Nokogiri::HTML(open("http://gdata.youtube.com/feeds/api/videos
在ruby中追加和前置冒号有什么区别?例子:#Inrailsyouoftenhavethingslikethis:has_many:models,dependent::destroy为什么dependent:有一个冒号,而:models和:destroy有一个冒号?有什么区别? 最佳答案 这是Ruby1.9中的新语法,用于定义散列中作为键的符号。前置和附加的:都定义了一个symbol,但后者仅在散列初始化期间有效。你可以想到一个symbol作为轻量级字符串常量。相当于:dependent=>:destroy在1.9之前,散列是使
十四届蓝桥青少组模拟赛Python-20221108T1.二进制位数十进制整数2在十进制中是1位数,在二进制中对应10,是2位数。十进制整数22在十进制中是2位数,在二进制中对应10110,是5位数。请问十进制整数2022在二进制中是几位数?print(len(bin(2022))-2)#运行结果:11T2.晨跑小蓝每周六、周日都晨跑,每月的1、11、21、31日也晨跑。其它时间不晨跑。已知2022年1月1日是周六,请问小蓝整个2022年晨跑多少天?#样例代码1ls=[0,31,28,31,30,31,30,31,31,30,31,30,31]ans=0k=6foriinrange(1,13)