
在之前的文章 “Elasticsearch:集群管理” ,我们对集群管理做了一些介绍。在今天的文章中,我们接着来聊一下有关配置的方面的问题。这在很大程度上取决于你的用例,是索引还是搜索繁重。 我们将在这里讨论在集群设置方面我们需要关注的最佳实践是什么。
在一个由多个 master 符合条件的节点组成的集群中,我们总是担心,如果网络出现分区或不稳定,那么集群会意外地选举出多个 master,这被称为 “脑裂” 场景。 因此,为了避免这种情况,我们至少需要最少的主节点投票才能赢得主节点选举。 创建 3 个专用主节点。
Elasticsearch 要求半数 +1 的符合主节点资格的节点必须投票选举新的主节点,从而避免了这种情况。 因此,强烈建议使用 3 个节点来提供能够失去 1 个主节点并保持稳定的结构。
注意:集群在负载过重时会变得不稳定。
如果主节点除了其常规任务之外还必须执行索引和搜索操作,它可能最终没有足够的资源来执行和监视对集群稳定性至关重要的其他操作,例如创建或删除索引,决定哪些分片应该 分配到哪些节点上,并在每个节点上维护集群状态。
主节点通常比数据节点需要更少的资源。 在其余节点上将 node master 设置为 false。
node.master: false更多阅读,请参考文章 “Elasticsearch:理解 Master,Elections,Quorum 及 脑裂”。
Elasticsearch 和 Lucene 是用 Java 编写的,我们需要调整最大堆空间和 JVM 统计信息。 需要注意的是,Elasticsearch 可用的堆越多,它可以用于过滤、缓存和其他进程以提高查询性能的内存就越多。 此外,过多的堆空间会导致大量垃圾回收。
将 Xms 和 Xmx 设置为不超过总内存的 50%。 Elasticsearch 需要内存用于 JVM 堆以外的用途。 例如,Elasticsearch 使用堆外缓冲区来实现高效的网络通信,并依赖于操作系统的文件系统缓存来实现对文件的高效访问。
操作系统尝试将尽可能多的内存用于文件系统缓存,并急切地换出未使用的应用程序内存。 当操作系统决定这样做时,Elasticsearch 性能可能会受到严重影响,因为它甚至可以将 Elasticsearch 可执行页面换出磁盘。 禁用操作系统级交换并启用内存锁可以帮助我们避免这种情况。
Just add the below in your elasticsearch.yml file.
Set bootstrap.memory_lock: true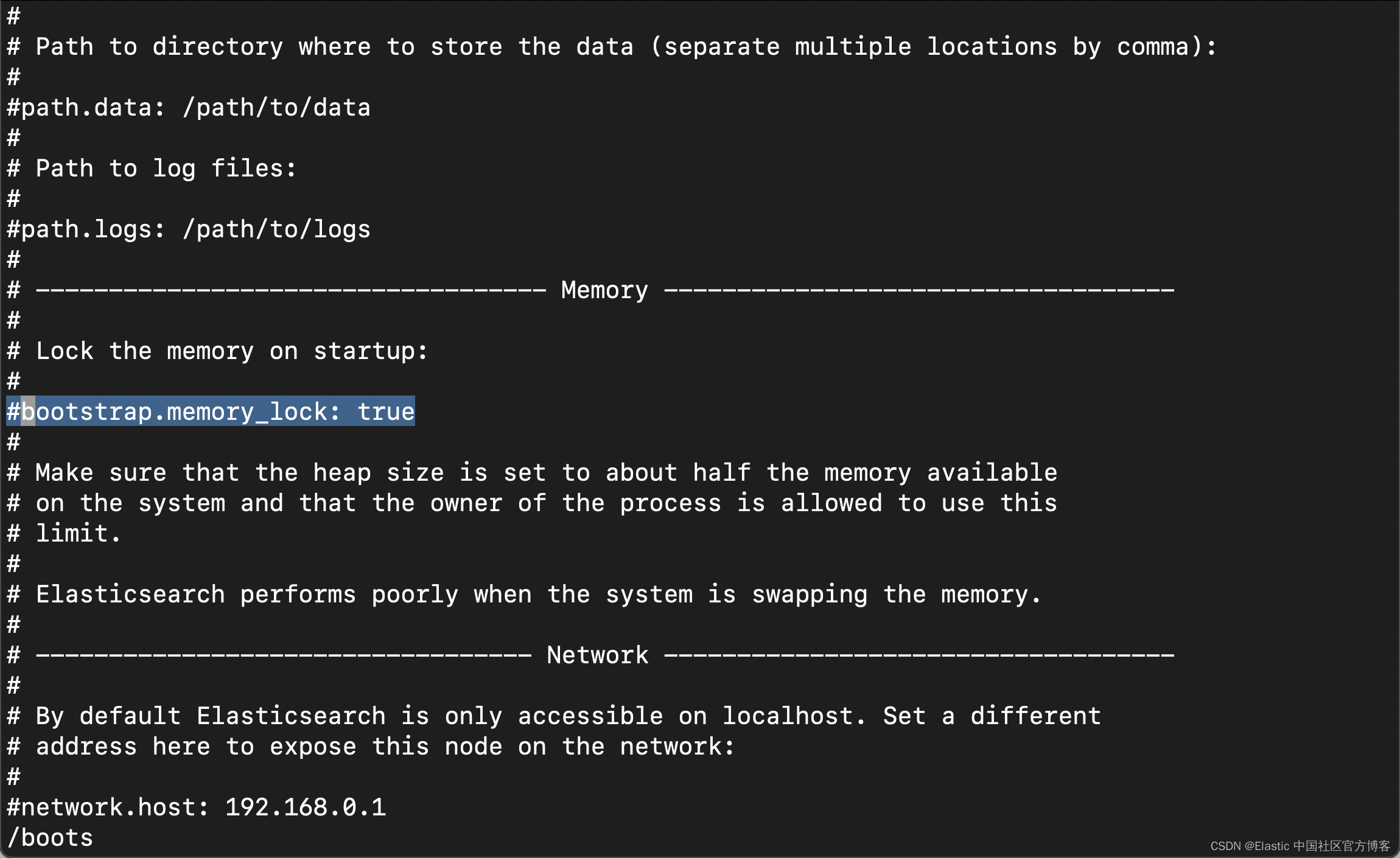
Elasticsearch 默认使用 mmaps 目录来存储其索引。 默认操作系统限制 mmap 计数并且可能太低,这可能导致内存不足异常。 因此,为避免虚拟内存耗尽,请增加对 mmap 计数的限制。
/etc/sysctl.conf file
Set vm.max_map_count=262144注意:通常情况下,deb 及 rpm 安装包可以帮我们自动配置这些。我们不需要手动来配置,但是当我们使用解压缩包的情况下来进行安装,那么我们需要进行手动配置。详细情况,请参考文章链接 “如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch”。
确保将运行 Elasticsearch 的用户的打开文件描述符数量限制增加到 65,536 或更高。
You can get from:
http://IP:PORT/_nodes/stats/process?filter_path=**.max_file_descriptorsGET _nodes/stats/process?filter_path=**.max_file_descriptors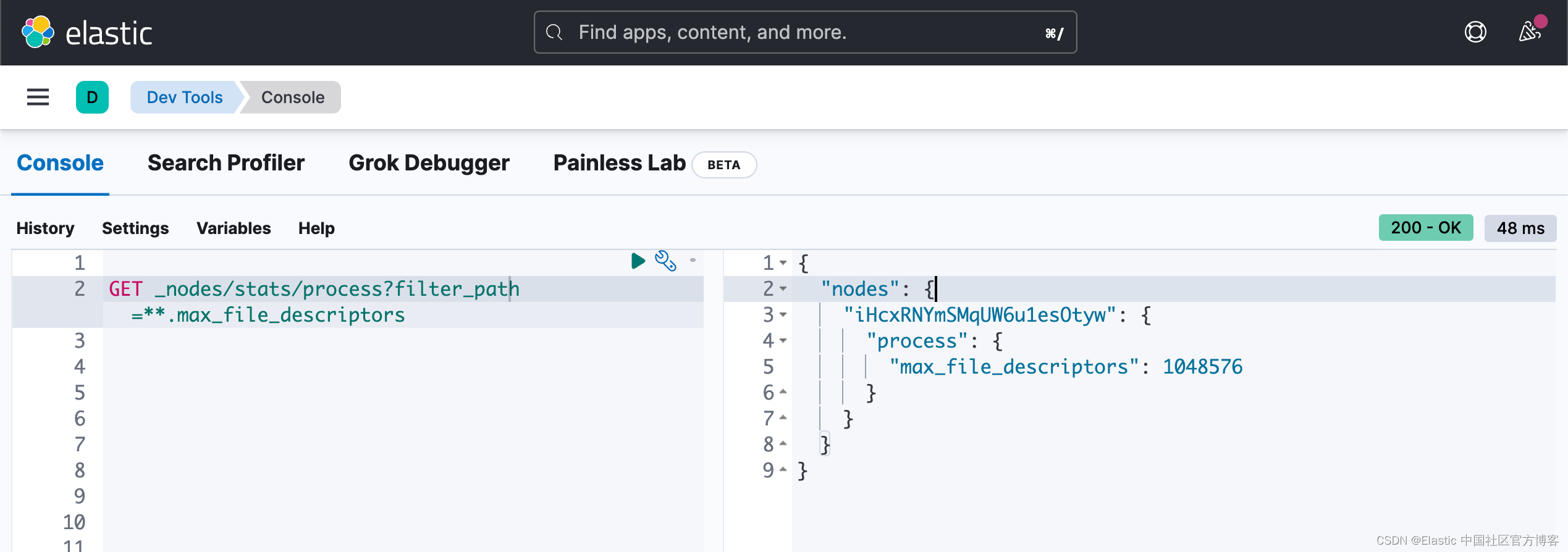
我们可以在如下的文件中进行设置:
set nofile to 65535 in /etc/security/limits.conf
由于无法检索从 Elasticsearch 集群中删除的数据,因此要确保有人不会对所有索引(* 或 _all)发出 DELETE 操作,请禁用通过通配符查询删除所有索引。
Set action.destructive_requires_name to true我们可以通过如下的命令来进行设置:
PUT /_cluster/settings
{
"transient": {
"action.destructive_requires_name":true
}
}如果你想设置为允许,你可以通过如下的命令来进行设置:
PUT /_cluster/settings
{
"transient": {
"action.destructive_requires_name":false
}
}
分片大小没有硬性限制,但经验表明,10GB 到 50GB 之间的分片通常适用于日志和时间序列数据。 它的大小太大会在节点发生故障时花费太多时间来恢复,Elasticsearch 会在数据层的剩余节点之间重新平衡节点的分片,并且也需要时间来运行,但这并不意味着较小的分片在所有情况下都表现良好。
更多信息,请详细阅读 “Elasticsearch:我的 Elasticsearch 集群中应该有多少个分片?”。
Old generation 收集暂停发生在重负载下,此时所有去往该节点上分片的请求都被冻结,直到垃圾收集完成。 在繁重的索引负载下,这些集合可能需要几秒钟或更长时间。
Elasticsearch 中的默认垃圾收集器是 Concurrent Mark and Sweep (CMS)。 直到 old generation 的收集器占用率达到 CMSInitiatingOccupancyFraction 中设置的值,CMS才会启动。 当此值过高时会出现问题,从而导致 GC 延迟。 将会有很多长寿命对象,这意味着 CMS 将需要更多时间来清除 old generation。 较新版本的 Java 中最近的 GC 选项是 Garbage First Garbage Collector (G1GC),它旨在最大限度地减少垃圾收集器必须停止所有应用程序线程的时间。 G1GC 将堆分成更小的区域,每个区域可以是年轻代或老年代。 GC 可以决定分析有更多垃圾的区域,通过避免一次收集整个老年代来减少 GC 暂停时间。 查看分片的当前大小
查看分片的当前大小:
http://IP:PORT/_cat/shards?v=true&h=index,prirep,shard,store&s=prirep,store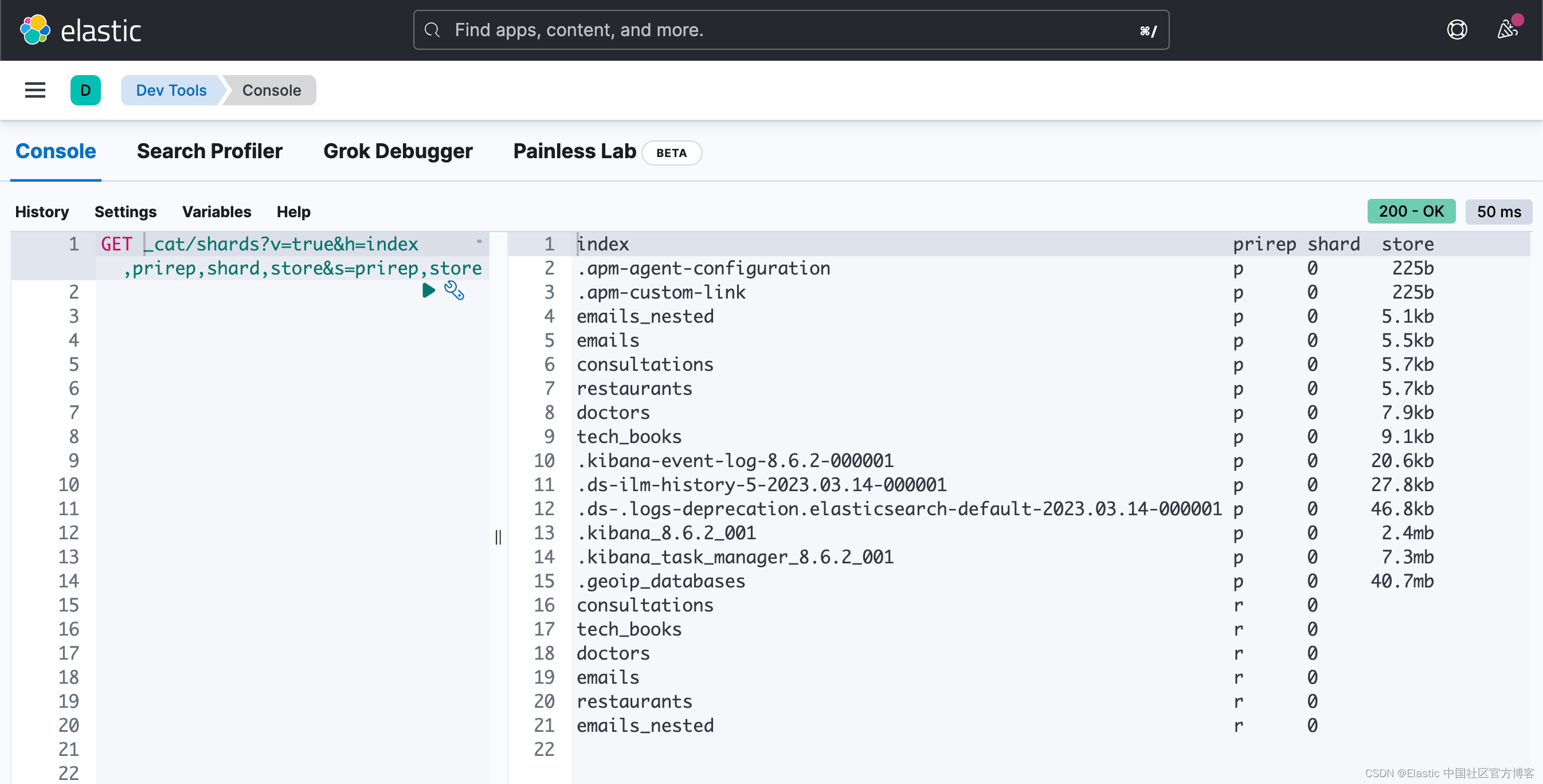
查看每个节点的分片数:
http://IP:PORT/_cat/shards?v=true
获取集群设置:
http://IP:PORT/_cluster/settings?pretty&include_defaults
检查节点统计信息:
http://IP:PORT/_nodes/stats?metric=adaptive_selection,breaker,discovery,fs,http,indices,jvm,os,process,thread_pool,transport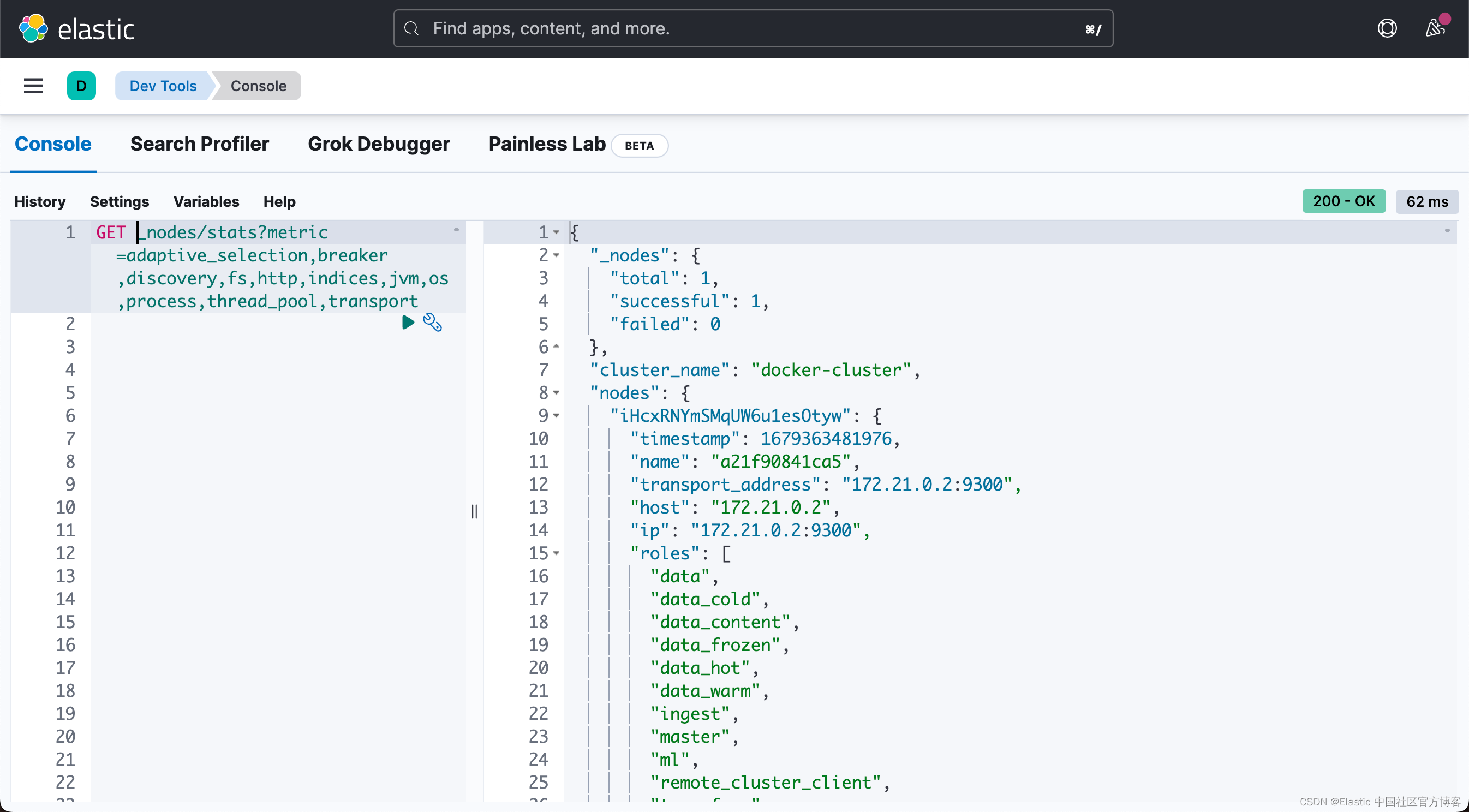
我正在使用i18n从头开始构建一个多语言网络应用程序,虽然我自己可以处理一大堆yml文件,但我说的语言(非常)有限,最终我想寻求外部帮助帮助。我想知道这里是否有人在使用UI插件/gem(与django上的django-rosetta不同)来处理多个翻译器,其中一些翻译器不愿意或无法处理存储库中的100多个文件,处理语言数据。谢谢&问候,安德拉斯(如果您已经在rubyonrails-talk上遇到了这个问题,我们深表歉意) 最佳答案 有一个rails3branchofthetolkgem在github上。您可以通过在Gemfi
我安装了ruby版本管理器,并将RVM安装的ruby实现设置为默认值,这样'哪个ruby'显示'~/.rvm/ruby-1.8.6-p383/bin/ruby'但是当我在emacs中打开inf-ruby缓冲区时,它使用安装在/usr/bin中的ruby。有没有办法让emacs像shell一样尊重ruby的路径?谢谢! 最佳答案 我创建了一个emacs扩展来将rvm集成到emacs中。如果您有兴趣,可以在这里获取:http://github.com/senny/rvm.el
我正在使用RubyonRails3.0.9,我想生成一个传递一些自定义参数的link_toURL。也就是说,有一个articles_path(www.my_web_site_name.com/articles)我想生成如下内容:link_to'Samplelinktitle',...#HereIshouldimplementthecode#=>'http://www.my_web_site_name.com/articles?param1=value1¶m2=value2&...我如何编写link_to语句“alàRubyonRailsWay”以实现该目的?如果我想通过传递一些
是否有简单的方法来更改默认ISO格式(yyyy-mm-dd)的ActiveAdmin日期过滤器显示格式? 最佳答案 您可以像这样为日期选择器提供额外的选项,而不是覆盖js:=f.input:my_date,as::datepicker,datepicker_options:{dateFormat:"mm/dd/yy"} 关于ruby-on-rails-事件管理员日期过滤器日期格式自定义,我们在StackOverflow上找到一个类似的问题: https://s
Region是HBase数据管理的基本单位,region有一点像关系型数据的分区。region中存储这用户的真实数据,而为了管理这些数据,HBase使用了RegionSever来管理region。Region的结构hbaseregion的大小设置默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的RegionServer,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的RegionServer。RegionSplit时机:当1个region中的某个Store下所有StoreFile
我想用这两种语言中的任何一种(最好是ruby)制作一个窗口管理器。老实说,除了我需要加载某种X模块外,我不知道从哪里开始。因此,如果有人有线索,如果您能指出正确的方向,那就太好了。谢谢 最佳答案 XCB,X的下一代API使用XML格式定义X协议(protocol),并使用脚本生成特定语言绑定(bind)。它在概念上与SWIG类似,只是它描述的不是CAPI,而是X协议(protocol)。目前,C和Python存在绑定(bind)。理论上,Ruby端口只是编写一个从XML协议(protocol)定义语言到Ruby的翻译器的问题。生
我想找到在某些文本中找到一些(让它是两个)句子的好方法。什么会更好-使用正则表达式或拆分方法?你的想法?应JeremyStein的要求-有一些例子示例:输入:ThefirstthingtodoistocreatetheCommentmodel.We’llcreatethisinthenormalway,butwithonesmalldifference.IfwewerejustcreatingcommentsforanArticlewe’dhaveanintegerfieldcalledarticle_idinthemodeltostoretheforeignkey,butinthis
这是我在ActiveAdmin中的自定义页面ActiveAdmin.register_page"Settings"doaction_itemdolink_to('Importprojects','settings/importprojects')endcontentdopara"Text"endcontrollerdodefimportprojectssystem"rakedataspider:import_projects_ninja"para"OK"endendend我想做的是,当我单击“导入项目”按钮时,我想在Controller中执行rake任务。但是我无法访问该方法。可能是什
我正在寻找用于Rails的优质管理插件。似乎大多数现有的插件/gem(例如“restful_authentication”、“acts_as_authenticated”)都围绕着self注册等展开。但是,我正在寻找一种功能齐全的基于管理/管理角色的解决方案——但不是简单地附加到另一个非基于角色的解决方案。如果我找不到,我想我会自己动手......只是不想重新发明轮子。 最佳答案 RyanBates最近做了两个关于授权的railscast(注意身份验证和授权之间的区别;身份验证检查用户是否如她所说的那样,授权检查用户是否有权访问资源
我正在使用Maruku,将Markdown(超集)转换为HTML,你知道我该怎么做才能从HTML转换为Markdown吗? 最佳答案 Google发现了一个名为reverse_markdown的ruby脚本.它似乎可以满足您的需求。 关于ruby-on-rails-我需要从HTML转到markdown,有什么建议吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/175162