写在前面:基于PaddleOCR代码库对其中所涉及到的算法进行代码简读,如果有必要可能会先研读一下原论文。
class EASTProcessTrain(object):
def __init__(self,
image_shape=[512, 512],
background_ratio=0.125,
min_crop_side_ratio=0.1,
min_text_size=10,
**kwargs):
self.input_size = image_shape[1]
self.random_scale = np.array([0.5, 1, 2.0, 3.0])
self.background_ratio = background_ratio
self.min_crop_side_ratio = min_crop_side_ratio
self.min_text_size = min_text_size
...
def __call__(self, data):
im = data['image']
text_polys = data['polys']
text_tags = data['ignore_tags']
if im is None:
return None
if text_polys.shape[0] == 0:
return None
#add rotate cases
if np.random.rand() < 0.5:
# 旋转图片和文本框(90,180,270)
im, text_polys = self.rotate_im_poly(im, text_polys)
h, w, _ = im.shape
# 限制文本框坐标到有效范围内、检查文本框的有效性(基于文本框的面积)、以及点的顺序是否是顺时针
text_polys, text_tags = self.check_and_validate_polys(text_polys,
text_tags, h, w)
if text_polys.shape[0] == 0:
return None
# 随机缩放图片以及文本框
rd_scale = np.random.choice(self.random_scale)
im = cv2.resize(im, dsize=None, fx=rd_scale, fy=rd_scale)
text_polys *= rd_scale
if np.random.rand() < self.background_ratio:
# 只切纯背景图,如果有文本框会返回None
outs = self.crop_background_infor(im, text_polys, text_tags)
else:
"""
随机切图并以及crop图所包含的文本框,并基于缩小的文本框生成了几个label map:
- score_map: shape=[h,w],得分图,有文本的地方是1,其余地方为0
- geo_map: shape=[h,w,9]。前8个通道为缩小文本框内的像素到真实文本框的水平以及垂直距离,
最后一个通道用来做loss归一化,其值为每个框最短边长的倒数
- training_mask: shape=[h,w],使无效文本框不参与训练,有效的地方为1,无效的地方为0
"""
outs = self.crop_foreground_infor(im, text_polys, text_tags)
if outs is None:
return None
im, score_map, geo_map, training_mask = outs
# 产生最终降采样的score map,shape=[1,h//4,w//4]
score_map = score_map[np.newaxis, ::4, ::4].astype(np.float32)
# 产生最终降采样的gep map, shape=[9,h//4,w//4]
geo_map = np.swapaxes(geo_map, 1, 2)
geo_map = np.swapaxes(geo_map, 1, 0)
geo_map = geo_map[:, ::4, ::4].astype(np.float32)
# 产生最终降采样的training mask,shape=[1,h//4,w//4]
training_mask = training_mask[np.newaxis, ::4, ::4]
training_mask = training_mask.astype(np.float32)
data['image'] = im[0]
data['score_map'] = score_map
data['geo_map'] = geo_map
data['training_mask'] = training_mask
return data
采用resnet50_vd,得到1/4、1/8、1/16以及1/32倍共计4张降采样特征图。
基于Unect decoder架构,完成自底向上的特征融合过程,从1/32特征图逐步融合到1/4的特征图,最终得到一张带有多尺度信息的1/4特征图。
def forward(self, x):
# x是存储4张从backbone获取的特征图
f = x[::-1] # 此时特征图从小到大排列
h = f[0] # [b,512,h/32,w/32]
g = self.g0_deconv(h) # [b,128,h/16,w/16]
h = paddle.concat([g, f[1]], axis=1) # [b,128+256,h/16,w/16]
h = self.h1_conv(h) # [b,128,h/16,w/16]
g = self.g1_deconv(h) # [b,128,h/8,w/8]
h = paddle.concat([g, f[2]], axis=1) # [b,128+128,h/8,w/8]
h = self.h2_conv(h) # [b,128,h/8,w/8]
g = self.g2_deconv(h) # [b,128,h/4,w/4]
h = paddle.concat([g, f[3]], axis=1) # [b,128+64,h/4,w/4]
h = self.h3_conv(h) # [b,128,h/4,w/4]
g = self.g3_conv(h) # [b,128,h/4,w/4]
return g
输出分类头和回归头(quad),部分参数共享。
def forward(self, x, targets=None):
# x是融合后的1/4特征图,det_conv1和det_conv2用于进一步加强特征抽取
f_det = self.det_conv1(x) # [b,128,h/4,w/4]
f_det = self.det_conv2(f_det) # [b,64,h/4,w/4]
# # [b,1,h/4,w/4] 用于前、背景分类,注意kernel_size=1
f_score = self.score_conv(f_det)
f_score = F.sigmoid(f_score) # 获取相应得分
# # [b,8,h/4,w/4],8的意义:dx1,dy1,dx2,dy2,dx3,dy3,dx4,dy4
f_geo = self.geo_conv(f_det)
# 回归的range变为:[-800,800],那么最终获取的文本框的最大边长不会超过1600
f_geo = (F.sigmoid(f_geo) - 0.5) * 2 * 800
pred = {'f_score': f_score, 'f_geo': f_geo}
return pred
分类采用dice_loss,回归采用smooth_l1_loss。
class EASTLoss(nn.Layer):
def __init__(self,
eps=1e-6,
**kwargs):
super(EASTLoss, self).__init__()
self.dice_loss = DiceLoss(eps=eps)
def forward(self, predicts, labels):
"""
Params:
predicts: {'f_score': 前景得分图,'f_geo': 回归图}
labels: [imgs, l_score, l_geo, l_mask]
"""
l_score, l_geo, l_mask = labels[1:]
f_score = predicts['f_score']
f_geo = predicts['f_geo']
# 分类loss
dice_loss = self.dice_loss(f_score, l_score, l_mask)
channels = 8
# channels+1的原因是最后一个图对应了短边的归一化系数(后面会讲),前8个代表相对偏移的label
# [[b,1,h/4,w/4], ...]共9个
l_geo_split = paddle.split(
l_geo, num_or_sections=channels + 1, axis=1)
# [[b,1,h/4,w/4], ...]共8个
f_geo_split = paddle.split(f_geo, num_or_sections=channels, axis=1)
smooth_l1 = 0
for i in range(0, channels):
geo_diff = l_geo_split[i] - f_geo_split[i] # diff=label-pred
abs_geo_diff = paddle.abs(geo_diff) # abs_diff
# 计算abs_diff中小于1的且有文本的部分
smooth_l1_sign = paddle.less_than(abs_geo_diff, l_score)
smooth_l1_sign = paddle.cast(smooth_l1_sign, dtype='float32')
# smoothl1 loss,大于1和小于1的两个部分对应loss相加,只不过这里<1的部分没乘0.5,问题不大
in_loss = abs_geo_diff * abs_geo_diff * smooth_l1_sign + \
(abs_geo_diff - 0.5) * (1.0 - smooth_l1_sign)
# 用短边*8做归一化
out_loss = l_geo_split[-1] / channels * in_loss * l_score
smooth_l1 += out_loss
# paddle.mean(smooth_l1)就可以了,前面都乘过了l_score,这里再乘没卵用
smooth_l1_loss = paddle.mean(smooth_l1 * l_score)
# dice_loss权重为0.01,smooth_l1_loss权重为1
dice_loss = dice_loss * 0.01
total_loss = dice_loss + smooth_l1_loss
losses = {"loss":total_loss, \
"dice_loss":dice_loss,\
"smooth_l1_loss":smooth_l1_loss}
return losses
公式:
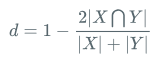
代码:
class DiceLoss(nn.Layer):
def __init__(self, eps=1e-6):
super(DiceLoss, self).__init__()
self.eps = eps
def forward(self, pred, gt, mask, weights=None):
# mask代表了有效文本的mask,有文本的地方是1,否则为0
assert pred.shape == gt.shape
assert pred.shape == mask.shape
if weights is not None:
assert weights.shape == mask.shape
mask = weights * mask
intersection = paddle.sum(pred * gt * mask) # 交集
union = paddle.sum(pred * mask) + paddle.sum(gt * mask) + self.eps # 并集
loss = 1 - 2.0 * intersection / union
assert loss <= 1
return loss
公式:
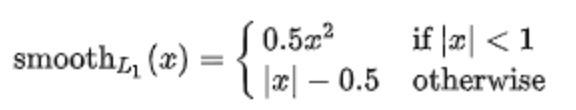
class EASTPostProcess(object):
def __init__(self,
score_thresh=0.8,
cover_thresh=0.1,
nms_thresh=0.2,
**kwargs):
self.score_thresh = score_thresh
self.cover_thresh = cover_thresh
self.nms_thresh = nms_thresh
...
def __call__(self, outs_dict, shape_list):
score_list = outs_dict['f_score'] # shape=[b,1,h//4,w//4]
geo_list = outs_dict['f_geo'] # shape=[b,8,h//4,w//4]
if isinstance(score_list, paddle.Tensor):
score_list = score_list.numpy()
geo_list = geo_list.numpy()
img_num = len(shape_list)
dt_boxes_list = []
for ino in range(img_num):
score = score_list[ino]
geo = geo_list[ino]
# 根据score、geo以及一些预设阈值和locality_nms操作拿到检测框
boxes = self.detect(
score_map=score,
geo_map=geo,
score_thresh=self.score_thresh,
cover_thresh=self.cover_thresh,
nms_thresh=self.nms_thresh)
boxes_norm = []
if len(boxes) > 0:
h, w = score.shape[1:]
src_h, src_w, ratio_h, ratio_w = shape_list[ino]
boxes = boxes[:, :8].reshape((-1, 4, 2))
# 文本框坐标根于缩放系数映射回输入图像上
boxes[:, :, 0] /= ratio_w
boxes[:, :, 1] /= ratio_h
for i_box, box in enumerate(boxes):
# 根据宽度比高度大这一先验,将坐标调整为以“左上角”点为起始点的顺时针4点框
box = self.sort_poly(box.astype(np.int32))
# 边长小于5的再进行一次过滤,拿到最终的检测结果
if np.linalg.norm(box[0] - box[1]) < 5 \
or np.linalg.norm(box[3] - box[0]) < 5:
continue
boxes_norm.append(box)
dt_boxes_list.append({'points': np.array(boxes_norm)})
return dt_boxes_list
def detect(self,
score_map,
geo_map,
score_thresh=0.8,
cover_thresh=0.1,
nms_thresh=0.2):
score_map = score_map[0] # shape=[h//4,w//4]
geo_map = np.swapaxes(geo_map, 1, 0)
geo_map = np.swapaxes(geo_map, 1, 2) # shape=[h//4,w//4,8]
# 获取score_map上得分大于阈值的点的坐标,shape=[n,2]
xy_text = np.argwhere(score_map > score_thresh)
if len(xy_text) == 0:
return []
# 按y轴从小到大的顺序对这些点进行排序
xy_text = xy_text[np.argsort(xy_text[:, 0])]
# 恢复成基于原图的文本框坐标
text_box_restored = self.restore_rectangle_quad(
xy_text[:, ::-1] * 4, geo_map[xy_text[:, 0], xy_text[:, 1], :])
# shape=[n,9] 前8个通道代表x1,y1,x2,y2的坐标,最后一个通道代表每个框的得分
boxes = np.zeros((text_box_restored.shape[0], 9), dtype=np.float32)
boxes[:, :8] = text_box_restored.reshape((-1, 8))
boxes[:, 8] = score_map[xy_text[:, 0], xy_text[:, 1]]
try:
import lanms
boxes = lanms.merge_quadrangle_n9(boxes, nms_thresh)
except:
print(
'you should install lanms by pip3 install lanms-nova to speed up nms_locality'
)
# locality nms,比传统nms要快,因为进入nms中的文本框的数量要比之前少很多。前面按y轴排序其实是在为该步骤做铺垫
boxes = nms_locality(boxes.astype(np.float64), nms_thresh)
if boxes.shape[0] == 0:
return []
# 最终还会根据框预测出的文本框内的像素在score_map上的得分再做一次过滤,感觉有一些不合理,因为score_map
# 上预测的是shrink_mask,会导致框内有很多背景像素,拉低平均得分,可能会让一些原本有效的文本框变得无效
# 当然这里的cover_thresh取的比较低,可能影响就比较小
for i, box in enumerate(boxes):
mask = np.zeros_like(score_map, dtype=np.uint8)
cv2.fillPoly(mask, box[:8].reshape(
(-1, 4, 2)).astype(np.int32) // 4, 1)
boxes[i, 8] = cv2.mean(score_map, mask)[0]
boxes = boxes[boxes[:, 8] > cover_thresh]
return boxes
def nms_locality(polys, thres=0.3):
def weighted_merge(g, p):
"""
框间merge的逻辑:坐标变为coor1*score1+coor2*score2,得分变为score1+score2
"""
g[:8] = (g[8] * g[:8] + p[8] * p[:8]) / (g[8] + p[8])
g[8] = (g[8] + p[8])
return g
S = []
p = None
for g in polys:
# 由于是按y轴排了序,所以循环遍历就可以了
if p is not None and intersection(g, p) > thres:
# 交集大于阈值那么就merge
p = weighted_merge(g, p)
else:
# 不能再merge的时候该框临近区域已无其他框,那么其加入进S
if p is not None:
S.append(p)
p = g
if p is not None:
S.append(p)
if len(S) == 0:
return np.array([])
# 将S保留下的文本框进行标准nms,略
return standard_nms(np.array(S), thres)
paddleocr最后几个库一个比一个难装,特别是lanms库,巨难装,拒绝任何花里胡哨,十分钟,三步内解决问题。pip下载报错Keyringisskippedduetoanexception:'keyring.backends'CollectinglanmsUsingcachedlanms-1.0.2.tar.gz(973kB)ERROR:Commanderroredoutwithexitstatus1:command:'C:\Users\TensorFlow\anaconda3\python.exe'-c'importsys,setuptools,tokenize;sys.argv[0]=
说明最近公司业务需要用到图文识别类似的功能,所以查阅了许多工具之后选择用百度开源的PaddleOCR来进行使用先看官方简介:百度飞桨PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力开发者训练出更好的模型,并应用落,支持多种OCR相关前沿算法,在此基础上打造产业级特色模型PP-OCR和PP-Structure,并打通数据生产、模型训练、压缩、预测部署全流程PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力开发者训练出更好的模型,并应用落地。PaddleOCR官方主页:https://www.paddlepaddle.org.cn/GitHub地址:https
我正在寻找一个消息队列即服务,它........托管在AWSus-east..提供真正的PubSub(不是轮询!)..可用于生产..提供高可用性..有一个很好的Java客户端我只找到了CloudAMQP(仍处于测试阶段),AppEngineTaskQueue(不是AWS),SQS(仅轮询),RedisToGo(没有高可用性?-twitter流似乎充满问题)和IronMQ(仅轮询)。我错过了什么? 最佳答案 您应该检查一种可用的开放式PaaS(例如Cloudify、OpenShift或Cloudfoundry),使用此类PaaS可以轻
背景我一直在努力为自己获取一个灵活的设置,以便在aws上使用spark和dockerswarm模式。我一直在使用的docker镜像配置为使用最新的spark,当时是2.1.0和Hadoop2.7.3,可在jupyter/pyspark-notebook获得。.这是有效的,我一直在测试我计划使用的各种连接路径。我遇到的问题是与s3交互的正确方式的不确定性。我一直在跟踪如何使用s3a为spark提供依赖项以连接到awss3上的数据。协议(protocol),对比s3n协议(protocol)。我终于找到了hadoopawsguide并认为我正在关注如何提供配置。但是,我仍然收到400Bad
本文简述了利用OpenCV库以及PaddleOCR库对视频预定位置进行字幕提取并整合识别,在实际工程中,可以调用OCR的识别输出接口进行识别内容的批量保存。 后续改进方向参考: 1.PaddleNLP进行识别文本纠错。 2.选取合适的方式做到字幕截取不重不漏: 简便思路可以采用高密度切图的方式,重复识别的文字内容在后续进行去重。而实际应用中应当采用识别前预处理的方式,从而减少重复识别带来的时间消耗。 切图后文字识别前的去重方式,可以参考我的另一篇图像相似度判别的小文章,主要原理是采用图像HASH值判别相似度的方式。 3.针对不同视频可
如何计算map东点和西点之间的距离(以米为单位)?假设用户改变了滚动map的位置,然后我用mapView:didChangeCameraPosition:委托(delegate)方法捕捉到移动,但我不知道如何计算距离。 最佳答案 这是一个辅助函数,可用于计算两个坐标之间的距离(以米为单位):doublegetDistanceMetresBetweenLocationCoordinates(CLLocationCoordinate2Dcoord1,CLLocationCoordinate2Dcoord2){CLLocation*l
可能出现的坑AttributeError:partiallyinitializedmodule'numpy'hasnoattribute'array 解决:更换numpy的版本,目前最新版本是1.24需要降低版本,采用1.22的版本就可解决这个问题。ifscoresisnotNoneand(scores[i] 解决:更换paddleOcr版本最新版本是2.6 V2.6的版本调用ocr.ocr返回的不是一个数组,是一个字符串,需要进行转换。环境搭建1、安装python环境,我这里采用的是Python3.8 2、安装paddlepaddle pipinstallpaddlepa
可能出现的坑AttributeError:partiallyinitializedmodule'numpy'hasnoattribute'array 解决:更换numpy的版本,目前最新版本是1.24需要降低版本,采用1.22的版本就可解决这个问题。ifscoresisnotNoneand(scores[i] 解决:更换paddleOcr版本最新版本是2.6 V2.6的版本调用ocr.ocr返回的不是一个数组,是一个字符串,需要进行转换。环境搭建1、安装python环境,我这里采用的是Python3.8 2、安装paddlepaddle pipinstallpaddlepa
近年来,随着经济社会数字化发展,商业银行逐步向数字化、智能化转型,监管部门对商业银行数据报送质量也越来越重视。自2020年5月9日工行、农行、中行、建行、交行、邮储、中信、光大8家商业银行因监管标准化数据(EAST)系统数据质量及报送存在违法违规行为,被银保监会罚款共计1770万元。 之后,银保监会又于2020年5月20日发布了《中国银保监会办公厅关于开展监管数据质量专项数据治理工作的通知》,要求银行保险机构充分认识提升监管数据质量的重要意义,严格落实监管数据质量主体责任,以发现监管数据质量问题为抓手,强化相关源头数据质量治理,夯实管理基础,补起组织、制度、机制、
近年来,随着经济社会数字化发展,商业银行逐步向数字化、智能化转型,监管部门对商业银行数据报送质量也越来越重视。自2020年5月9日工行、农行、中行、建行、交行、邮储、中信、光大8家商业银行因监管标准化数据(EAST)系统数据质量及报送存在违法违规行为,被银保监会罚款共计1770万元。 之后,银保监会又于2020年5月20日发布了《中国银保监会办公厅关于开展监管数据质量专项数据治理工作的通知》,要求银行保险机构充分认识提升监管数据质量的重要意义,严格落实监管数据质量主体责任,以发现监管数据质量问题为抓手,强化相关源头数据质量治理,夯实管理基础,补起组织、制度、机制、