Stable Diffusion 只做AI动画是基于把原有视频按照帧进行提取之后对每一帧的图像进行标准化流程操作,中间可以掺杂Controlnet对人物进行控制,使用关键词对画面进行控制,但是很多小伙伴不太会掌握一些编辑视频软件或者python的操作导致视频转帧,帧转视频会出现一些问题。
这里分享2套方法。
文章目录
在你的文件目录下和我一致即可。
from moviepy.editor import *
import os
import cv2
# 加载视频文件
dir_list = os.listdir("video")
video_capture = cv2.VideoCapture("video/" + dir_list[0])
# 初始化帧计数器
frame_count = 0
# 逐帧读取视频并保存图像
while True:
# 读取视频帧
ret, frame = video_capture.read()
# 检查是否成功读取帧
if not ret:
break
# 保存图像
cv2.imwrite(f"video_img/frame{frame_count}.jpg", frame)
# 帧计数器加1
frame_count += 1
# 释放视频捕捉对象
video_capture.release()
from moviepy.editor import *
import os
import numpy as np
# 按帧合成视频
os.system("ffmpeg -i video_img/frame%d.jpg -acodec libvo_aacenc -vcodec mpeg4 -r 60 video_out/merged.mp4")
# os.system("ffmpeg -i video_img/%6d.png -acodec libvo_aacenc -vcodec mpeg4 -r 60 video_out/merged.mp4")
# 共读取原视频
dir_list = os.listdir("video")
video_source = VideoFileClip("video/" + dir_list[0])
# 提取视频中的音频
video_mp3 = video_source.audio
# 提取视频中的时长
video_duration = video_source.duration
# 读取merge视频
video_merge = VideoFileClip("video_out/merged.mp4")
# 提取视频中的时长
merge_duration = video_merge.duration
# 计算加速的倍数
factor = merge_duration / video_duration
result = video_merge.speedx(factor)
# 设置视频的音频
result = result.set_audio(video_mp3)
result.write_videofile("video_merge/diy_result.mp4")
脚本放到你的 Stable Diffusion 的 Script 下。
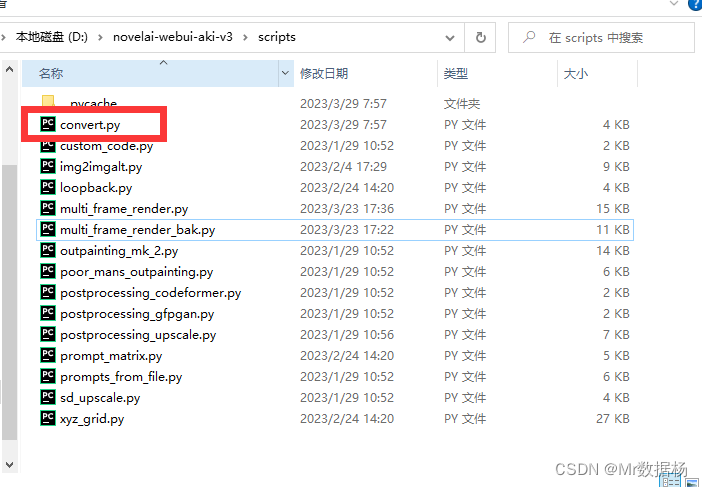
在你的Stable Diffusion中会看到对应的选项卡。
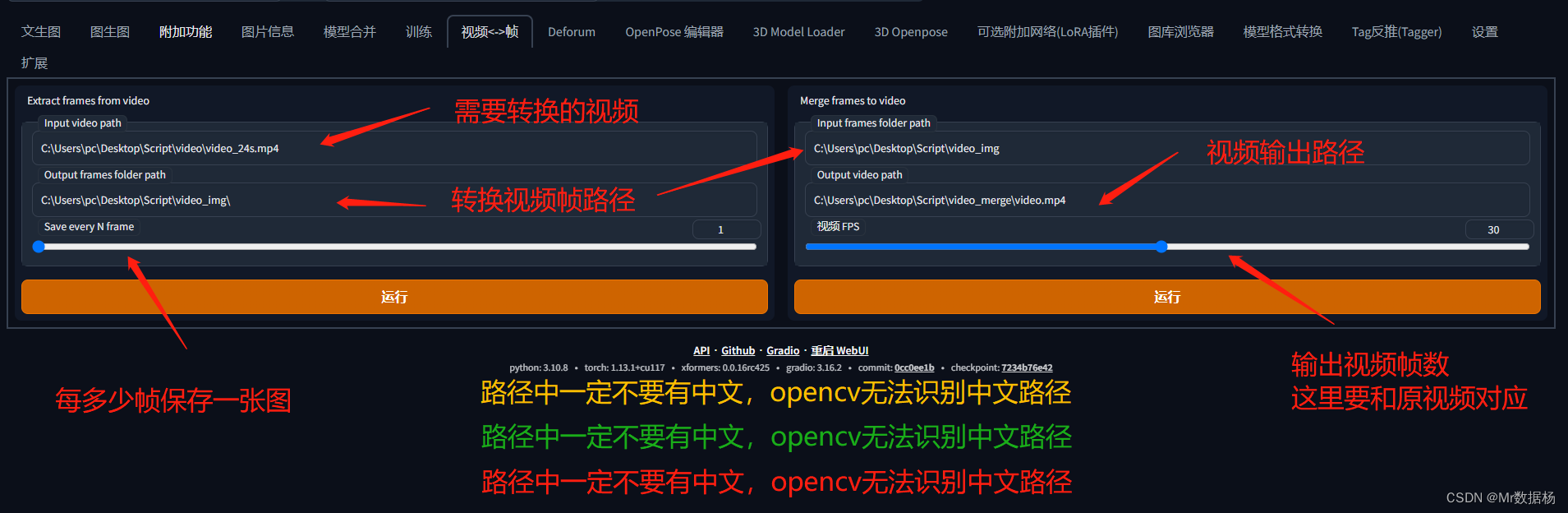
生成的视频转图像帧。
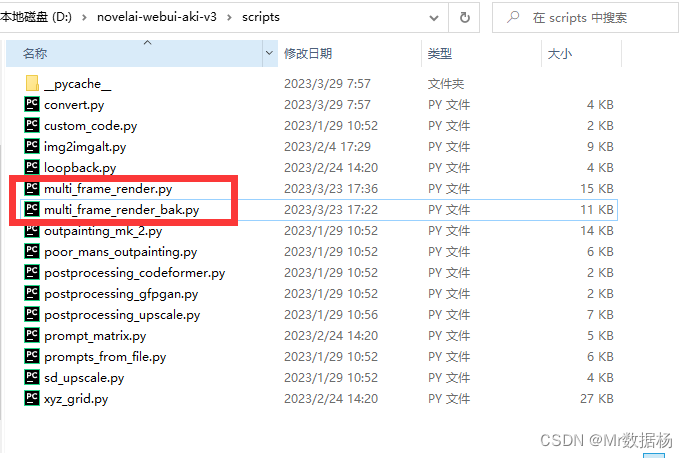
感谢原作者提供脚本 multi-frame-rendering-for-stablediffusion
脚本放到你的 Stable Diffusion 的 Script 下,但是原作者这个脚本似乎有点问题,图片超过2800张之后就无法处理了,所以对这个脚本进行了一些修改,代码在最后先看流程在操作。
这样进行基础的文生图的样子。
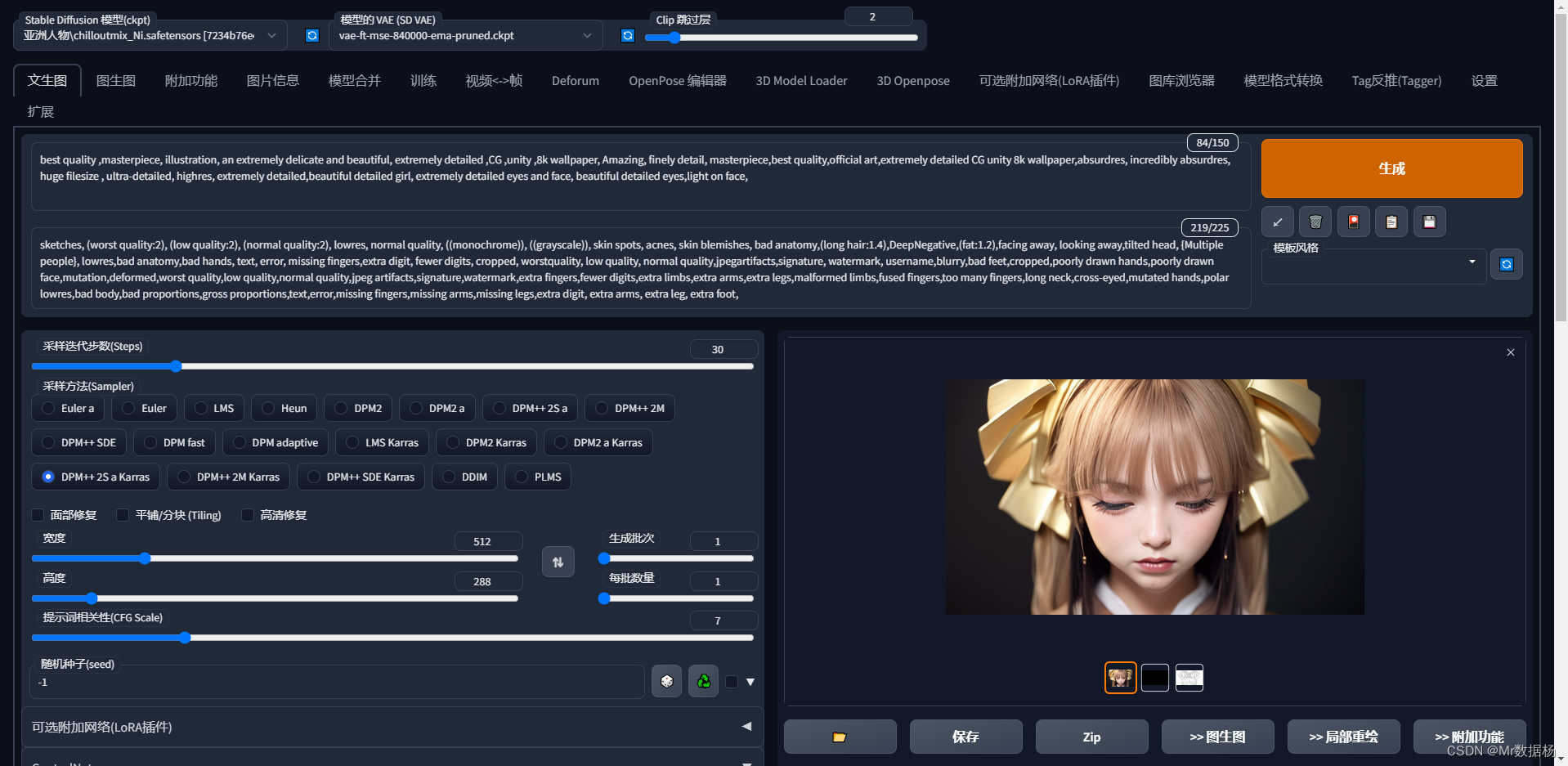
然后添加Controlnet控制人物,这里建议添加openpose和canny。
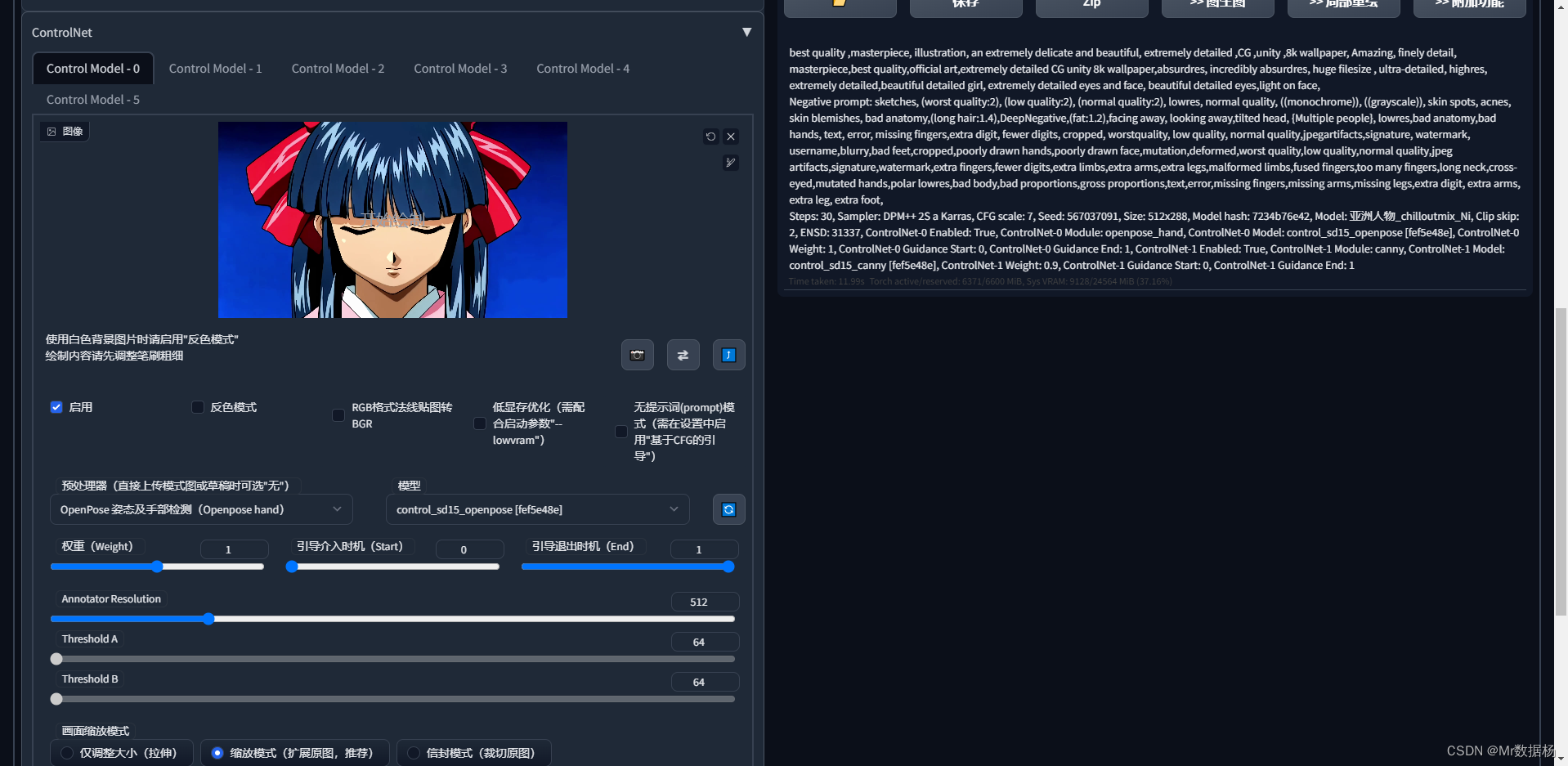
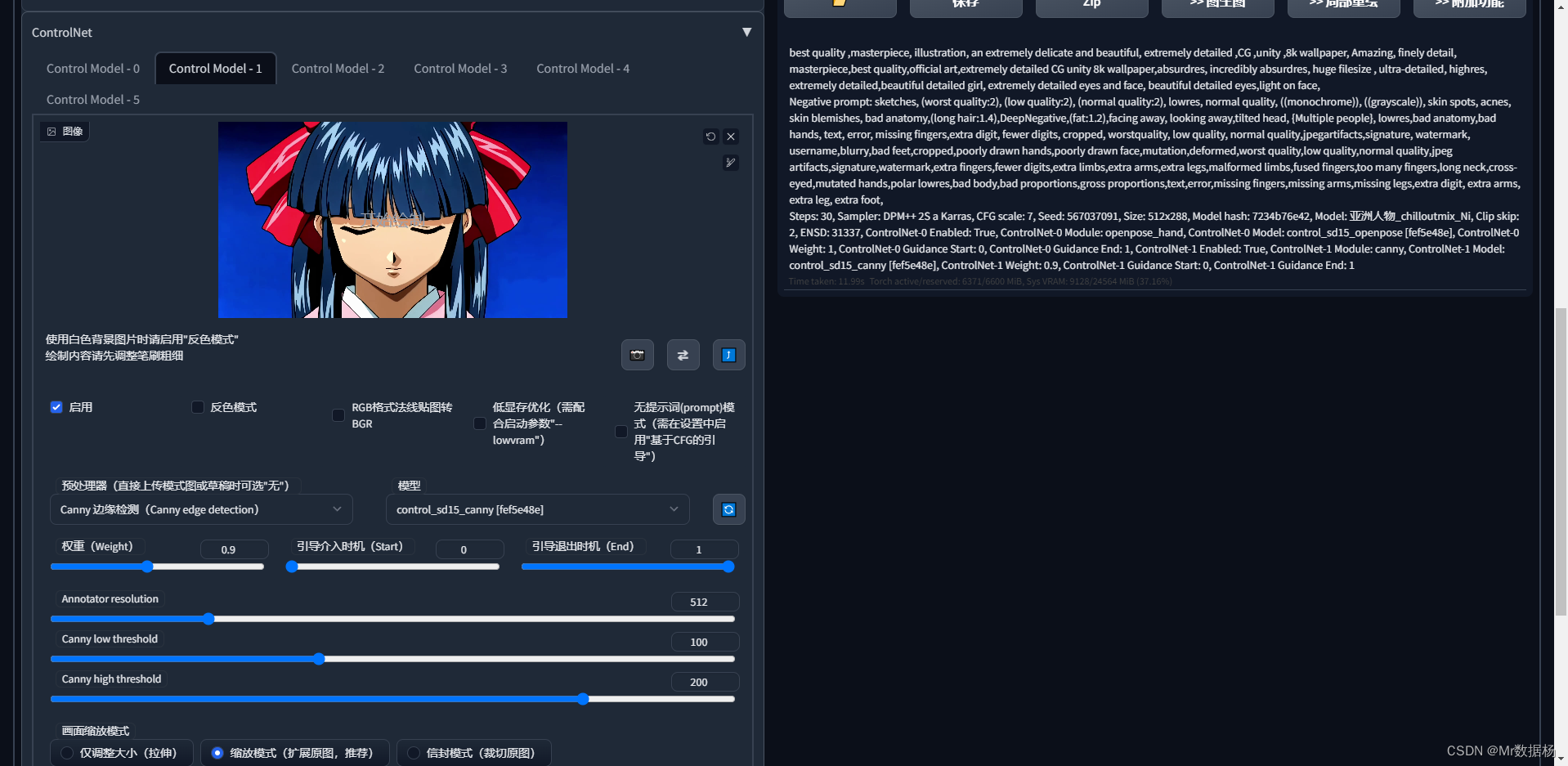
点击生成好的图像到图生图界面,复制图像的种子。

勾选和之前文生图中Controlnet相同的配置,但是这里不需要加入图片。

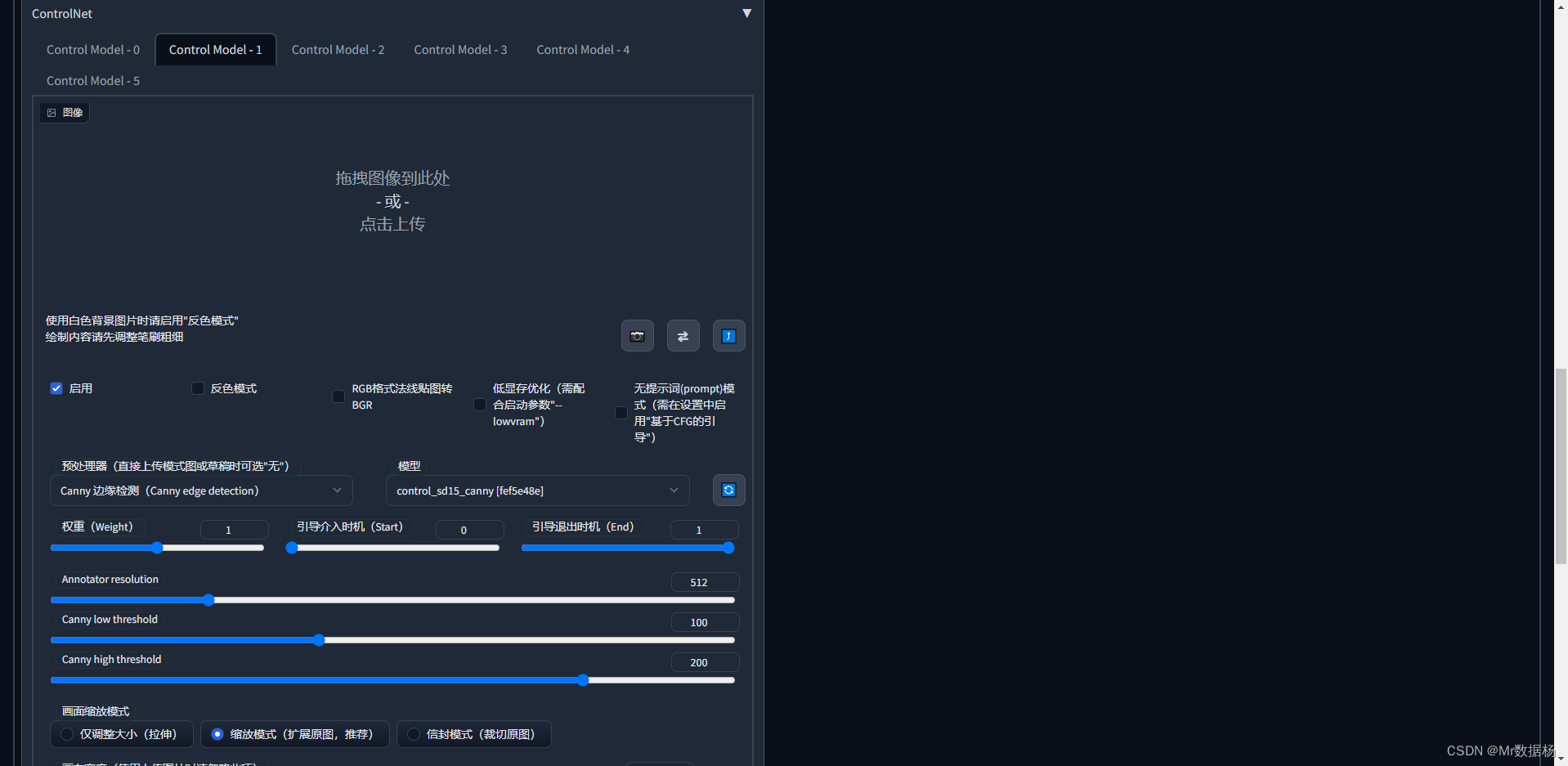
打开下方的脚本选择输入和输出的文件路径就按照下图配置好久可以点击生成。自己制定好图片输入输入的路径就可以了,其他的地方按照我这里设置即可。
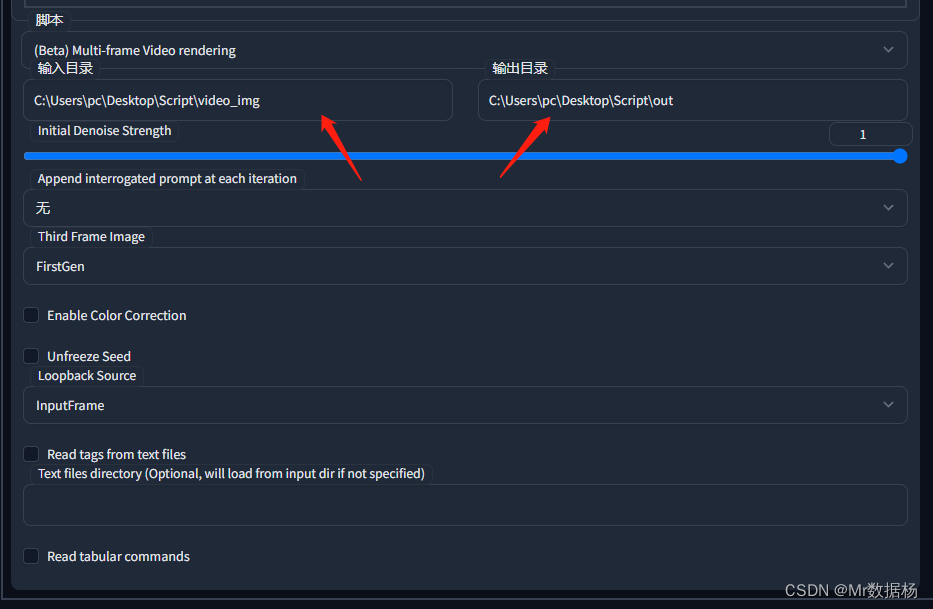
复制修改的代码新建一个脚本即可。
import numpy as np
from tqdm import trange
from PIL import Image, ImageSequence, ImageDraw, ImageFilter, PngImagePlugin
import modules.scripts as scripts
import gradio as gr
from modules import processing, shared, sd_samplers, images
from modules.processing import Processed
from modules.sd_samplers import samplers
from modules.shared import opts, cmd_opts, state
from modules import deepbooru
from modules.script_callbacks import ImageSaveParams, before_image_saved_callback
from modules.shared import opts, cmd_opts, state
from modules.sd_hijack import model_hijack
import pandas as pd
import piexif
import piexif.helper
import os, re
def gr_show(visible=True):
return {"visible": visible, "__type__": "update"}
def gr_show_value_none(visible=True):
return {"value": None, "visible": visible, "__type__": "update"}
def gr_show_and_load(value=None, visible=True):
if value:
if value.orig_name.endswith('.csv'):
value = pd.read_csv(value.name)
else:
value = pd.read_excel(value.name)
else:
visible = False
return {"value": value, "visible": visible, "__type__": "update"}
class Script(scripts.Script):
def title(self):
return "(Beta) Multi-frame Video rendering"
def show(self, is_img2img):
return is_img2img
def ui(self, is_img2img):
with gr.Row():
input_dir = gr.Textbox(label='Input directory', lines=1)
output_dir = gr.Textbox(label='Output directory', lines=1)
# reference_imgs = gr.UploadButton(label="Upload Guide Frames", file_types = ['.png','.jpg','.jpeg'], live=True, file_count = "multiple")
first_denoise = gr.Slider(minimum=0, maximum=1, step=0.05, label='Initial Denoise Strength', value=1, elem_id=self.elem_id("first_denoise"))
append_interrogation = gr.Dropdown(label="Append interrogated prompt at each iteration", choices=["None", "CLIP", "DeepBooru"], value="None")
third_frame_image = gr.Dropdown(label="Third Frame Image", choices=["None", "FirstGen", "OriginalImg", "Historical"], value="FirstGen")
color_correction_enabled = gr.Checkbox(label="Enable Color Correction", value=False, elem_id=self.elem_id("color_correction_enabled"))
unfreeze_seed = gr.Checkbox(label="Unfreeze Seed", value=False, elem_id=self.elem_id("unfreeze_seed"))
loopback_source = gr.Dropdown(label="Loopback Source", choices=["PreviousFrame", "InputFrame","FirstGen"], value="InputFrame")
with gr.Row():
use_txt = gr.Checkbox(label='Read tags from text files')
with gr.Row():
txt_path = gr.Textbox(label='Text files directory (Optional, will load from input dir if not specified)', lines=1)
with gr.Row():
use_csv = gr.Checkbox(label='Read tabular commands')
csv_path = gr.File(label='.csv or .xlsx', file_types=['file'], visible=False)
with gr.Row():
with gr.Column():
table_content = gr.Dataframe(visible=False, wrap=True)
use_csv.change(
fn=lambda x: [gr_show_value_none(x), gr_show_value_none(False)],
inputs=[use_csv],
outputs=[csv_path, table_content],
)
csv_path.change(
fn=lambda x: gr_show_and_load(x),
inputs=[csv_path],
outputs=[table_content],
)
return [append_interrogation, input_dir, output_dir, first_denoise, third_frame_image, color_correction_enabled, unfreeze_seed, loopback_source, use_csv, table_content, use_txt, txt_path]
def run(self, p, append_interrogation, input_dir, output_dir, first_denoise, third_frame_image, color_correction_enabled, unfreeze_seed, loopback_source, use_csv, table_content, use_txt, txt_path):
freeze_seed = not unfreeze_seed
if use_csv:
prompt_list = [i[0] for i in table_content.values.tolist()]
prompt_list.insert(0, prompt_list.pop())
reference_imgs = [os.path.join(input_dir, f) for f in os.listdir(input_dir) if re.match(r'.+\.(jpg|png)$', f)]
print(f'Will process following files: {", ".join(reference_imgs)}')
if use_txt:
if txt_path == "":
files = [re.sub(r'\.(jpg|png)$', '.txt', path) for path in reference_imgs]
else:
files = [os.path.join(txt_path, os.path.basename(re.sub(r'\.(jpg|png)$', '.txt', path))) for path in reference_imgs]
prompt_list = [open(file, 'r').read().rstrip('\n') for file in files]
loops = len(reference_imgs)
processing.fix_seed(p)
batch_count = p.n_iter
p.batch_size = 1
p.n_iter = 1
output_images, info = None, None
initial_seed = None
initial_info = None
initial_width = p.width
initial_img = reference_imgs[0] # p.init_images[0]
grids = []
all_images = []
original_init_image = p.init_images
original_prompt = p.prompt
if original_prompt != "":
original_prompt = original_prompt.rstrip(', ') + ', ' if not original_prompt.rstrip().endswith(',') else original_prompt.rstrip() + ' '
original_denoise = p.denoising_strength
state.job_count = loops * batch_count
initial_color_corrections = [processing.setup_color_correction(p.init_images[0])]
# for n in range(batch_count):
history = None
# frames = []
third_image = None
third_image_index = 0
frame_color_correction = None
# Reset to original init image at the start of each batch
p.init_images = original_init_image
p.width = initial_width
for i in range(loops):
if state.interrupted:
break
filename = os.path.basename(reference_imgs[i])
p.n_iter = 1
p.batch_size = 1
p.do_not_save_grid = True
p.control_net_input_image = Image.open(reference_imgs[i]).convert("RGB").resize((initial_width, p.height), Image.ANTIALIAS)
if(i > 0):
loopback_image = p.init_images[0]
if loopback_source == "InputFrame":
loopback_image = p.control_net_input_image
elif loopback_source == "FirstGen":
loopback_image = history
if third_frame_image != "None":
p.width = initial_width * 3
img = Image.new("RGB", (initial_width*3, p.height))
img.paste(p.init_images[0], (0, 0))
# img.paste(p.init_images[0], (initial_width, 0))
img.paste(loopback_image, (initial_width, 0))
if i == 1:
third_image = p.init_images[0]
img.paste(third_image, (initial_width*2, 0))
p.init_images = [img]
if color_correction_enabled:
p.color_corrections = [processing.setup_color_correction(img)]
msk = Image.new("RGB", (initial_width*3, p.height))
msk.paste(Image.open(reference_imgs[i-1]).convert("RGB").resize((initial_width, p.height), Image.ANTIALIAS), (0, 0))
msk.paste(p.control_net_input_image, (initial_width, 0))
msk.paste(Image.open(reference_imgs[third_image_index]).convert("RGB").resize((initial_width, p.height), Image.ANTIALIAS), (initial_width*2, 0))
p.control_net_input_image = msk
latent_mask = Image.new("RGB", (initial_width*3, p.height), "black")
latent_draw = ImageDraw.Draw(latent_mask)
latent_draw.rectangle((initial_width,0,initial_width*2,p.height), fill="white")
p.image_mask = latent_mask
p.denoising_strength = original_denoise
else:
p.width = initial_width * 2
img = Image.new("RGB", (initial_width*2, p.height))
img.paste(p.init_images[0], (0, 0))
# img.paste(p.init_images[0], (initial_width, 0))
img.paste(loopback_image, (initial_width, 0))
p.init_images = [img]
if color_correction_enabled:
p.color_corrections = [processing.setup_color_correction(img)]
msk = Image.new("RGB", (initial_width*2, p.height))
msk.paste(Image.open(reference_imgs[i-1]).convert("RGB").resize((initial_width, p.height), Image.ANTIALIAS), (0, 0))
msk.paste(p.control_net_input_image, (initial_width, 0))
p.control_net_input_image = msk
# frames.append(msk)
# latent_mask = Image.new("RGB", (initial_width*2, p.height), "white")
# latent_draw = ImageDraw.Draw(latent_mask)
# latent_draw.rectangle((0,0,initial_width,p.height), fill="black")
latent_mask = Image.new("RGB", (initial_width*2, p.height), "black")
latent_draw = ImageDraw.Draw(latent_mask)
latent_draw.rectangle((initial_width,0,initial_width*2,p.height), fill="white")
# p.latent_mask = latent_mask
p.image_mask = latent_mask
p.denoising_strength = original_denoise
else:
latent_mask = Image.new("RGB", (initial_width, p.height), "white")
# p.latent_mask = latent_mask
p.image_mask = latent_mask
p.denoising_strength = first_denoise
p.control_net_input_image = p.control_net_input_image.resize((initial_width, p.height))
# frames.append(p.control_net_input_image)
# if opts.img2img_color_correction:
# p.color_corrections = initial_color_corrections
if append_interrogation != "None":
p.prompt = original_prompt
if append_interrogation == "CLIP":
p.prompt += shared.interrogator.interrogate(p.init_images[0])
elif append_interrogation == "DeepBooru":
p.prompt += deepbooru.model.tag(p.init_images[0])
if use_csv or use_txt:
p.prompt = original_prompt + prompt_list[i]
# state.job = f"Iteration {i + 1}/{loops}, batch {n + 1}/{batch_count}"
processed = processing.process_images(p)
if initial_seed is None:
initial_seed = processed.seed
initial_info = processed.info
init_img = processed.images[0]
if(i > 0):
init_img = init_img.crop((initial_width, 0, initial_width*2, p.height))
comments = {}
if len(model_hijack.comments) > 0:
for comment in model_hijack.comments:
comments[comment] = 1
info = processing.create_infotext(
p,
p.all_prompts,
p.all_seeds,
p.all_subseeds,
comments,
0,
0)
pnginfo = {}
if info is not None:
pnginfo['parameters'] = info
params = ImageSaveParams(init_img, p, filename, pnginfo)
before_image_saved_callback(params)
fullfn_without_extension, extension = os.path.splitext(
filename)
info = params.pnginfo.get('parameters', None)
def exif_bytes():
return piexif.dump({
'Exif': {
piexif.ExifIFD.UserComment: piexif.helper.UserComment.dump(info or '', encoding='unicode')
},
})
if extension.lower() == '.png':
pnginfo_data = PngImagePlugin.PngInfo()
for k, v in params.pnginfo.items():
pnginfo_data.add_text(k, str(v))
init_img.save(
os.path.join(
output_dir,
filename),
pnginfo=pnginfo_data)
elif extension.lower() in ('.jpg', '.jpeg', '.webp'):
init_img.save(os.path.join(output_dir, filename))
if opts.enable_pnginfo and info is not None:
piexif.insert(
exif_bytes(), os.path.join(
output_dir, filename))
else:
init_img.save(os.path.join(output_dir, filename))
if third_frame_image != "None":
if third_frame_image == "FirstGen" and i == 0:
third_image = init_img
third_image_index = 0
elif third_frame_image == "OriginalImg" and i == 0:
third_image = original_init_image[0]
third_image_index = 0
elif third_frame_image == "Historical":
third_image = processed.images[0].crop((0, 0, initial_width, p.height))
third_image_index = (i-1)
p.init_images = [init_img]
if(freeze_seed):
p.seed = processed.seed
else:
p.seed = processed.seed + 1
# p.seed = processed.seed
if i == 0:
history = init_img
# history.append(processed.images[0])
# frames.append(processed.images[0])
# grid = images.image_grid(history, rows=1)
# if opts.grid_save:
# images.save_image(grid, p.outpath_grids, "grid", initial_seed, p.prompt, opts.grid_format, info=info, short_filename=not opts.grid_extended_filename, grid=True, p=p)
# grids.append(grid)
# # all_images += history + frames
# all_images += history
# p.seed = p.seed+1
# if opts.return_grid:
# all_images = grids + all_images
processed = Processed(p, [], initial_seed, initial_info)
return processed
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我是Rails的新手,所以请原谅简单的问题。我正在为一家公司创建一个网站。那家公司想在网站上展示它的客户。我想让客户自己管理这个。我正在为“客户”生成一个表格,我想要的三列是:公司名称、公司描述和Logo。对于名称,我使用的是name:string但不确定如何在脚本/生成脚手架终端命令中最好地创建描述列(因为我打算将其设置为文本区域)和图片。我怀疑描述(我想成为一个文本区域)应该仍然是描述:字符串,然后以实际形式进行调整。不确定如何处理图片字段。那么……说来话长:我在脚手架命令中输入什么来生成描述和图片列? 最佳答案 对于“文本”数
我正在使用RubyonRails3.0.9,我想生成一个传递一些自定义参数的link_toURL。也就是说,有一个articles_path(www.my_web_site_name.com/articles)我想生成如下内容:link_to'Samplelinktitle',...#HereIshouldimplementthecode#=>'http://www.my_web_site_name.com/articles?param1=value1¶m2=value2&...我如何编写link_to语句“alàRubyonRailsWay”以实现该目的?如果我想通过传递一些
有这些railscast。http://railscasts.com/episodes/218-making-generators-in-rails-3有了这个,你就会知道如何创建样式表和脚手架生成器。http://railscasts.com/episodes/216-generators-in-rails-3通过这个,您可以了解如何添加一些文件来修改脚手架View。我想把两者结合起来。我想创建一个生成器,它也可以创建脚手架View。有点像RyanBates漂亮的生成器或web_app_themegem(https://github.com/pilu/web-app-theme)。我
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
Unity自动旋转动画1.开门需要门把手先动,门再动2.关门需要门先动,门把手再动3.中途播放过程中不可以再次进行操作觉得太复杂?查看我的文章开关门简易进阶版效果:如果这个门可以直接打开的话,就不需要放置"门把手"如果门把手还有钥匙需要旋转,那就可以把钥匙放在门把手的"门把手",理论上是可以无限套娃的可调整参数有:角度,反向,轴向,速度运行时点击Test进行测试自己写的代码比较垃圾,命名与结构比较拉,高手轻点喷,新手有类似的需求可以拿去做参考上代码usingSystem.Collections;usingSystem.Collections.Generic;usingUnityEngine;u