摘要:在最新发布的1.5版本中,Karmada 提供了多调度组的能力,利用该能力,用户可以实现将业务优先调度到成本更低的集群,或者在主集群故障时,优先迁移业务到指定的备份集群。
本文分享自华为云社区《Karmada v1.5发布!多调度组助力成本优化》,作者:华为云云原生团队。
Karmada 是开放的多云多集群容器编排引擎,旨在帮助用户在多云环境下部署和运维业务应用。凭借兼容 Kubernetes 原生 API 的能力,Karmada 可以平滑迁移单集群工作负载,并且仍可保持与 Kubernetes 周边生态工具链协同。在最新发布的1.5版本中,Karmada 提供了多调度组的能力,利用该能力,用户可以实现将业务优先调度到成本更低的集群,或者在主集群故障时,优先迁移业务到指定的备份集群。

本版本其他新增特性:
根据 Flexera 发布的《2023 年云现状调查报告》,云成本的管理取代了安全性话题,成为当下云使用者面临的首要问题。
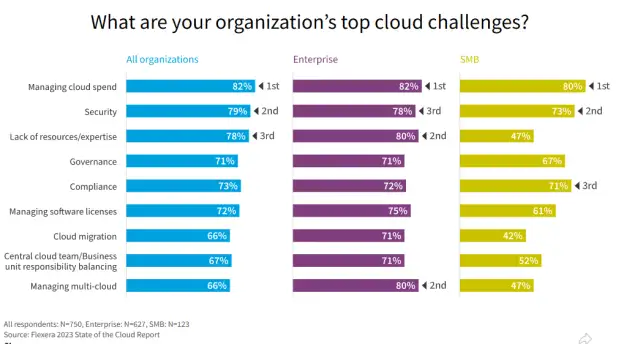
Karmada 秉承这一趋势,同样关注云成本管理。从v1.5版本开始,用户可以在 PropagationPolicy/ClusterPropagationPolicy 中设置多个集群组,实现将业务优先调度到成本更低的集群组。下面我们给出一个针对成本优化进行调度的例子:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
clusterAffinities:
- affinityName: local-clusters
clusterNames:
- local-member1
- local-member2
- affinityName: cloud-clusters
clusterNames:
- huawei-member1
- huawei-member2上面的例子配置有本地集群组(local-clusters)和云上集群组(cloud-clusters),Karmada 在选择集群组进行资源分发时, 将按顺序对集群组逐一进行评估,直到找到满足调度约束的集群组。所以在调度Deployment/nginx时,会优先尝试调度到本地集群组的local-member1和local-member2,如果失败(如资源不足),则选择云上集群组,从而实现在本地集群资源足够时,优先选择成本更低的本地集群。基于此,系统管理员也可以定义主集群组和备份集群组,在主集群组故障时,将业务往备份集群组的集群迁移。下面我们给出一个针对容灾迁移的例子:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
clusterAffinities:
- affinityName: primary-cluster
clusterNames:
- member1
- affinityName: backup-cluster
clusterNames:
- member2上面的例子通过配置主群组(primary-cluster)和备份集群组(backup-cluster),在调度 Deployment/nginx 时,如果主集群组满足要求,会调度到主集群组的member1。在主集群组的集群故障时,调度器按顺序匹配新集群组,将业务迁移到备份集群组的member2。
关于多调度组更多信息,请参考:https://github.com/karmada-io/karmada/tree/master/docs/proposals/scheduling/multi-scheduling-group
Karmada 默认调度器内置多款可灵活配置的插件,可以满足大部分使用场景,用户还可以使用插件扩展机制来实现个性化调度诉求。Karmada 1.5版本提供了多调度器支持能力,Karmada 默认调度器可以与第三方自定义调度器协同工作,以提供更强的定制能力。用户可以参考默认调度器实现自定义调度器,当多个调度器共存时,需通过命令行启动参数指定调度器名称,如 --scheduler-name=my-scheduler 。如果自定义调度器与默认调度器部署在同一namespace中,建议同时配置 --leader-elect-resource-name 参数,以避免副本选主冲突。关键命令行启动参数如下所示:
command:
- /bin/karmada-scheduler
- --kubeconfig=/etc/kubeconfig
- --bind-address=0.0.0.0
- --secure-port=10351
- --enable-scheduler-estimator=true
- --leader-elect-resource-name=my-scheduler # 你的自定义调度器名称
- --scheduler-name=my-scheduler # 你的自定义调度器通过参数 --scheduler-name 将多个调度器进行区分,每个调度器将只负责调度特定的工作负载。通过 Karmada 分发工作负载时,可以在 PropagationPolicy/ClusterPropagationPolicy 的 schedulerName 字段指定调度器名字,如下所示:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
schedulerName: my-scheduler
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
clusterAffinity:
clusterNames:
- member1
- member2上例通过 schedulerName 指定此Deployment必须由名为 my-scheduler 的调度器进行调度,此时默认调度器将自动忽略该工作负载。schedulerName 如果没有指定,则默认值为 default-scheduler ,意味着由默认调度器进行调度,前面版本的用户升级到新版本时无需额外配置。关于如何扩展调度器插件和实现自定义调度器,请查看官方文档:https://karmada.io/docs/developers/customize-karmada-scheduler/
Karmada v1.5版本API兼容v1.4版本API,v1.4版本的用户仍然可以平滑升级到v1.5版本。可参考升级文档:https://karmada.io/docs/administrator/upgrading/v1.4-v1.5
Karmada v1.5版本包含了来自25位贡献者的数百次代码提交,在此对各位贡献者表示由衷的感谢:
贡献者GitHub ID:
@a7i@calvin0327@carlory@chaunceyjiang@fengshunli@Fish-pro@Garrybest@helen-frank@ikaven1024@jwcesign@lonelyCZ@maoyangLiu@my-git9@Poor12@qingwave@RainbowMango@VedRatan@Wang-Kai@whitewindmills@wlp1153468871@wongearl@XiShanYongYe-Chang@yanfeng1992@yanggangtony@Zhuzhenghao
Release Notes:https://github.com/karmada-io/karmada/releases/tag/v1.5.0
多调度组:https://github.com/karmada-io/karmada/tree/master/docs/proposals/scheduling/multi-scheduling-group
2023 年云现状调查报告:https://info.flexera.com/CM-REPORT-State-of-the-Cloud
扩展调度器插件和实现自定义调度器:https://karmada.io/docs/developers/customize-karmada-scheduler/
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
有人知道在发布新版本的Ruby和Rails时收到电子邮件的方法吗?他们有邮件列表,RubyonRails有一个推特,但我不想听到那些随之而来的喧嚣,我只想知道什么时候发布新版本,尤其是那些有安全修复的版本。 最佳答案 从therailsblog获取提要.http://weblog.rubyonrails.org/feed/atom.xml 关于ruby-on-rails-如何在发布新的Ruby或Rails版本时收到通知?,我们在StackOverflow上找到一个类似的问题:
尝试从我的AngularJS端将数据发布到Rails服务器时出现问题。服务器错误:ActionController::RoutingError(Noroutematches[OPTIONS]"/users"):actionpack(4.1.9)lib/action_dispatch/middleware/debug_exceptions.rb:21:in`call'actionpack(4.1.9)lib/action_dispatch/middleware/show_exceptions.rb:30:in`call'railties(4.1.9)lib/rails/rack/logg
当音乐碰上区块链技术,会擦出怎样的火花?或许周杰伦已经给了我们答案。8月29日下午,B站独家首发周杰伦限定珍藏Demo独家访谈VCR,周杰伦在VCR里分享了《晴天》《青花瓷》《搁浅》《爱在西元前》四首经典歌曲Demo背后的创作故事,并首次公布18年前未发布的神秘作品《纽约地铁》的Demo。在VCR中,方文山和杰威尔音乐提及到“多亏了区块链技术,现在我们可以将这些Demos,变成独一无二具有收藏价值的艺术品,这些Demos可以在薄盒(国内数藏平台)上听到。”如何将音乐与区块链技术相结合,薄盒方面称:“薄盒作为区块链技术服务方,打破传统对于区块链技术只能作为数字收藏的理解。聚焦于区块链技术赋能,在
我希望Ruby的解析器会进行这种微不足道的优化,但似乎并没有(谈到YARV实现,Ruby1.9.x、2.0.0):require'benchmark'deffib1a,b=0,1whileb由于这两种方法除了在第二种方法中使用预定义常量而不是常量表达式外是相同的,因此Ruby解释器似乎在每个循环中一次又一次地计算幂常数。是否有一些Material说明为什么Ruby根本不进行这种基本优化或只在某些特定情况下进行? 最佳答案 很抱歉给出了另一个答案,但我不想删除或编辑我之前的答案,因为它下面有有趣的讨论。正如JörgWMittag所说,
我想上传我在运行时用Ruby生成的数据,就像从block中提供上传数据一样。我找到的所有示例仅展示了如何流式传输必须在请求之前位于磁盘上的文件,但我不想缓冲该文件。除了滚动我自己的套接字连接之外,最好的解决方案是什么?这是一个伪代码示例:post_stream('127.0.0.1','/stream/')do|body|generate_xmldo|segment|body 最佳答案 有效的代码。require'thread'require'net/http'require'base64'require'openssl'class
我正在尝试从数据库中读取大量单元格(超过100.000个)并将它们写入VPSUbuntu服务器上的csv文件。碰巧服务器没有足够的内存。我正在考虑一次读取5000行并将它们写入文件,然后再读取5000行,等等。我应该如何重构我当前的代码以使内存不会被完全消耗?这是我的代码:defwrite_rows(emails)File.open(file_path,"w+")do|f|f该函数由sidekiqworker调用:write_rows(user.emails)感谢您的帮助! 最佳答案 这里的问题是,当您调用emails.each时,
我需要一个用于大型动态任务集合的调度程序。目前我正在查看resque-scheduler,rufus-scheduler,和clockwork.如果您提供有关选择使用哪一个(或其他替代方案)的建议,我将不胜感激。一些细节:有大量要定期执行的任务(最多100K)。最短执行周期为1h。新任务可能会不时出现。现有任务可能会更改或删除。调度延迟最小化在这里不是关键任务(可扩展性和可持续性最重要)。任务执行不是繁重的操作,可以轻松并行。总结,我需要类似cron的Ruby项目,它可以处理大量动态变化的任务集合。更新:我花了一天时间尝试调度库,现在我想简单总结一下新获得的经验。我已经不再关注Cloc
昨晚看到IDEA官推宣布IntelliJIDEA2023.1正式发布了。简单看了一下,发现这次的新版本包含了许多改进,进一步优化了用户体验,提高了便捷性。至于是否升级最新版本完全是个人意愿,如果觉得新版本没有让自己感兴趣的改进,完全就不用升级,影响不大。软件的版本迭代非常正常,正确看待即可,不持续改进就会慢慢被淘汰!根据官方介绍:IntelliJIDEA2023.1针对新的用户界面进行了大量重构,这些改进都是基于收到的宝贵反馈而实现的。官方还实施了性能增强措施,使得Maven导入更快,并且在打开项目时IDE功能更早地可用。由于后台提交检查,新版本提供了简化的提交流程。IntelliJIDEA
文章目录前言约束硬约束的轨迹优化Corridor-BasedTrajectoryOptimizationBezierCurveOptimizationOtherOptions软约束的轨迹优化Distance-BasedTrajectoryOptimization优化方法前言可以看看我的这几篇Blog1,Blog2,Blog3。上次基于MinimumSnap的轨迹生成,有许多优点,比如:轨迹让机器人可以在某个时间点抵达某个航点。任何一个时刻,都能数学上求出期望的机器人的位置、速度、加速度、导数。MinimumSnap可以把问题转换为凸优化问题。缺点:MnimumSnap可以控制轨迹一定经过中间的