YOLOv8 是 ultralytics 公司在 2023 年 1月 10 号开源的 YOLOv5 的下一个重大更新版本,目前支持图像分类、物体检测和实例分割任务,在还没有开源时就收到了用户的广泛关注。
考虑到 YOLOv8 的优异性能,MMYOLO 也在第一时间组织了复现,由于时间仓促,目前 MMYOLO 的 Dev 分支已经支持了 YOLOv8 的模型推理以及通过 projects/easydepoly 支持部署,我们将尽快发布可训练版本,敬请期待!
官方开源地址: https://github.com/ultralytics/ultralytics
MMYOLO 开源地址: https://github.com/open-mmlab/mmyolo/blob/dev/configs/yolov8/
按照官方描述,YOLOv8 是一个 SOTA 模型,它建立在以前 YOLO 版本的成功基础上,并引入了新的功能和改进,以进一步提升性能和灵活性。具体创新包括一个新的骨干网络、一个新的 Ancher-Free 检测头和一个新的损失函数,可以在从 CPU 到 GPU 的各种硬件平台上运行。
不过 ultralytics 并没有直接将开源库命名为 YOLOv8,而是直接使用 ultralytics 这个词,原因是 ultralytics 将这个库定位为算法框架,而非某一个特定算法,一个主要特点是可扩展性。其希望这个库不仅仅能够用于 YOLO 系列模型,而是能够支持非 YOLO 模型以及分类分割姿态估计等各类任务。
总而言之,ultralytics 开源库的两个主要优点是:
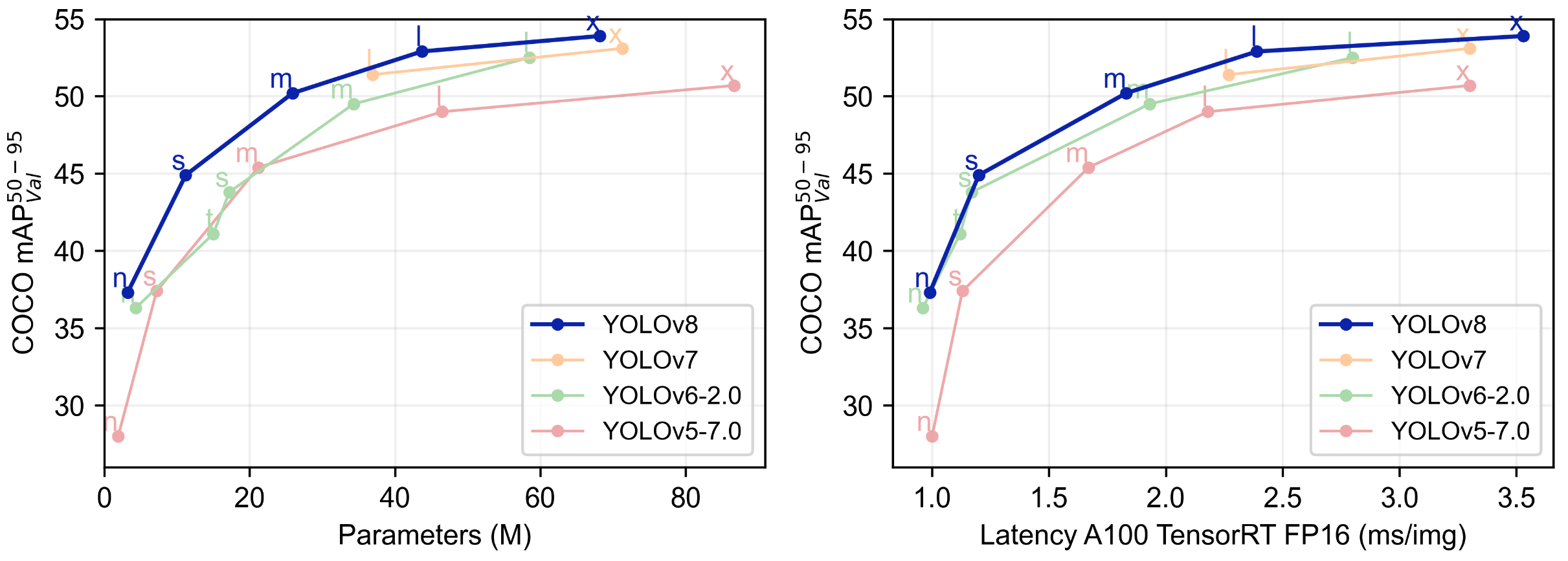
下表为官方在 COCO Val 2017 数据集上测试的 mAP、参数量和 FLOPs 结果。可以看出 YOLOv8 相比 YOLOv5 精度提升非常多,但是 N/S/M 模型相应的参数量和 FLOPs 都增加了不少,从上图也可以看出相比 YOLOV5 大部分模型推理速度变慢了。
| 模型 | YOLOv5 | params**(M)** | FLOPs**@640 (B)** | YOLOv8 | params**(M)** | FLOPs**@640 (B)** |
|---|---|---|---|---|---|---|
| n | 28.0(300e) | 1.9 | 4.5 | 37.3 (500e) | 3.2 | 8.7 |
| s | 37.4 (300e) | 7.2 | 16.5 | 44.9 (500e) | 11.2 | 28.6 |
| m | 45.4 (300e) | 21.2 | 49.0 | 50.2 (500e) | 25.9 | 78.9 |
| l | 49.0 (300e) | 46.5 | 109.1 | 52.9 (500e) | 43.7 | 165.2 |
| x | 50.7 (300e) | 86.7 | 205.7 | 53.9 (500e) | 68.2 | 257.8 |
额外提一句,现在各个 YOLO 系列改进算法都在 COCO 上面有明显性能提升,但是在自定义数据集上面的泛化性还没有得到广泛验证,至今依然听到不少关于 YOLOv5 泛化性能较优异的说法。对各系列 YOLO 泛化性验证也是 MMYOLO 中一个特别关心和重点发力的方向。
阅读本文前,如果你对 YOLOv5、YOLOv6 和 RTMDet 不熟悉,可以先看下如下文档:
具体到 YOLOv8 算法,其核心特性和改动可以归结为如下:
从上面可以看出,YOLOv8 主要参考了最近提出的诸如 YOLOX、YOLOv6、YOLOv7 和 PPYOLOE 等算法的相关设计,本身的创新点不多,偏向工程实践,主推的还是 ultralytics 这个框架本身 。
下面将按照模型结构设计、Loss 计算、训练数据增强、训练策略和模型推理过程共 5 个部分详细介绍 YOLOv8 目标检测的各种改进,实例分割部分暂时不进行描述。
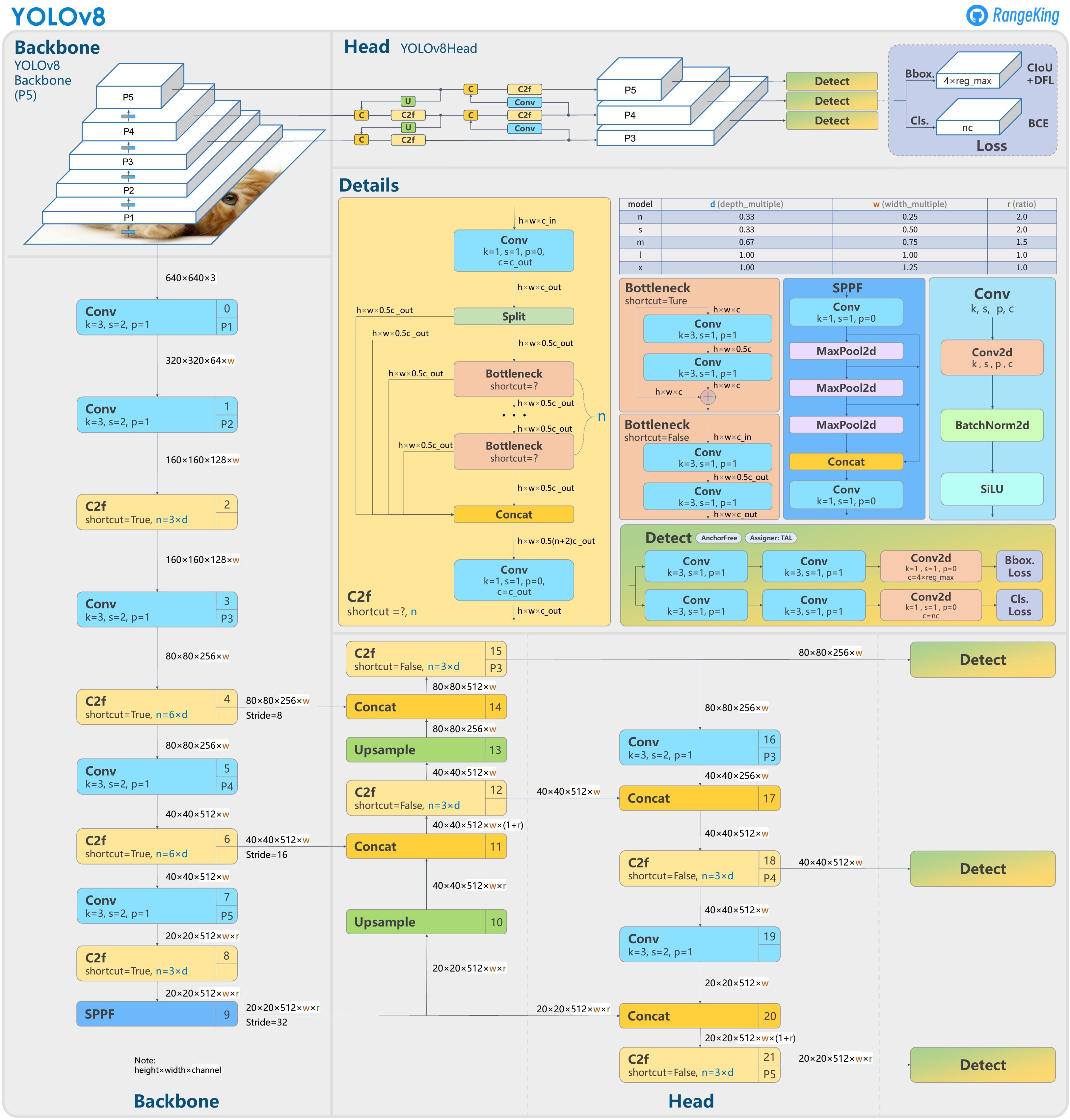
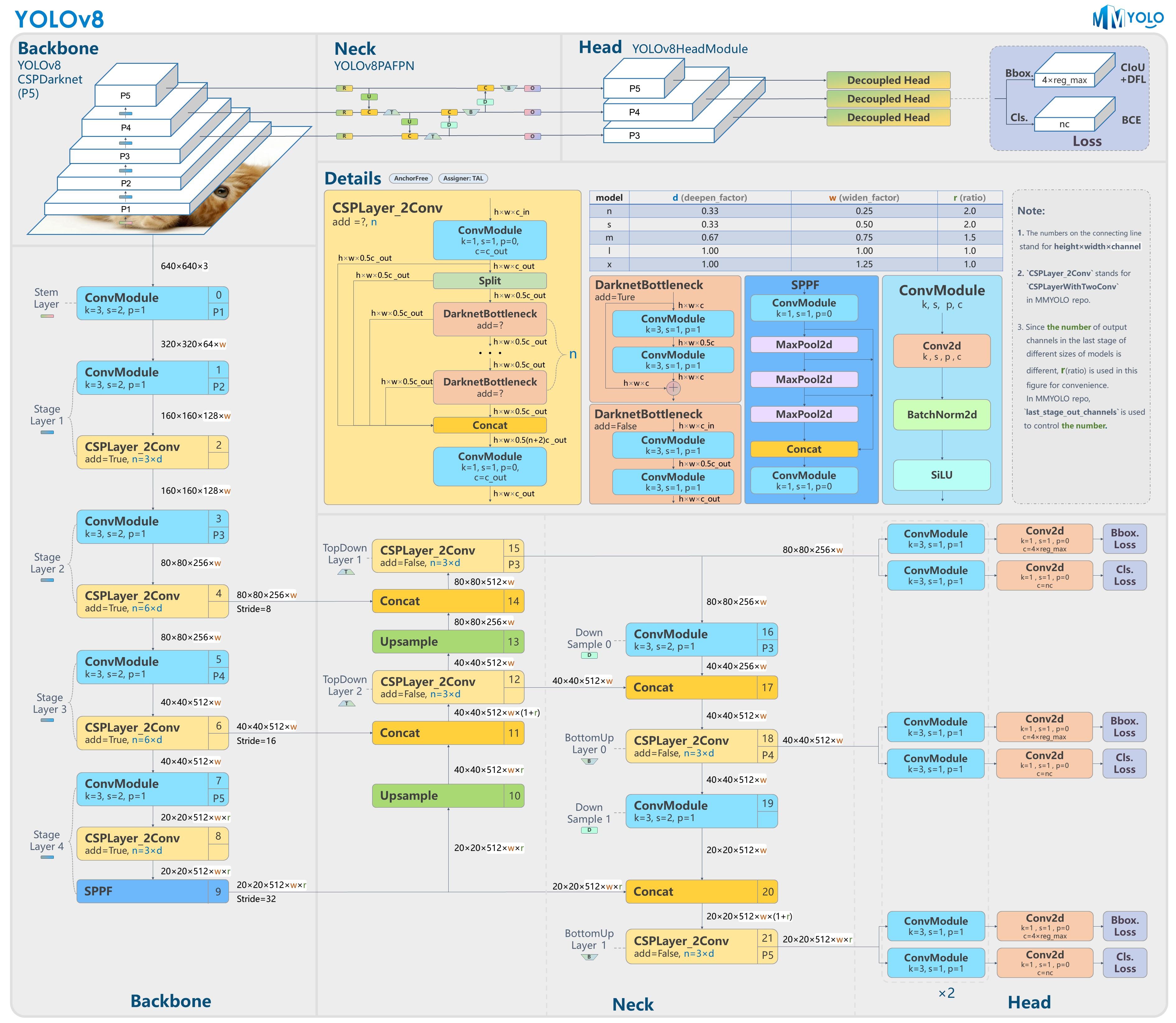
以上为基于 YOLOv8 官方代码所绘制的模型结构图。如果你喜欢这种模型结构图风格,可以查看 MMYOLO 里面对应算法 README 中的模型结构图,目前已经支持了 YOLOv5、YOLOv6、YOLOX、RTMDet 和 YOLOv8。MMYOLO 中重构的 YOLOv8 模型对应结构图如下所示:
详细地址为: https://github.com/open-mmlab/mmyolo/blob/dev/configs/yolov8/README.md
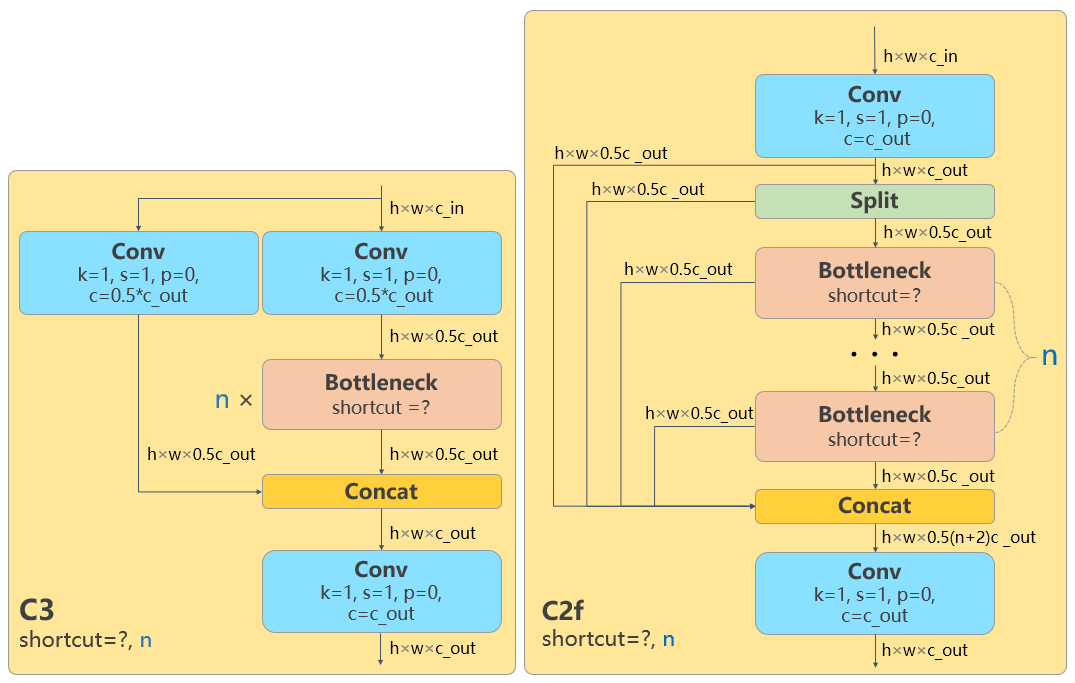
在暂时不考虑 Head 情况下,对比 YOLOv5 和 YOLOv8 的 yaml 配置文件可以发现改动较小。
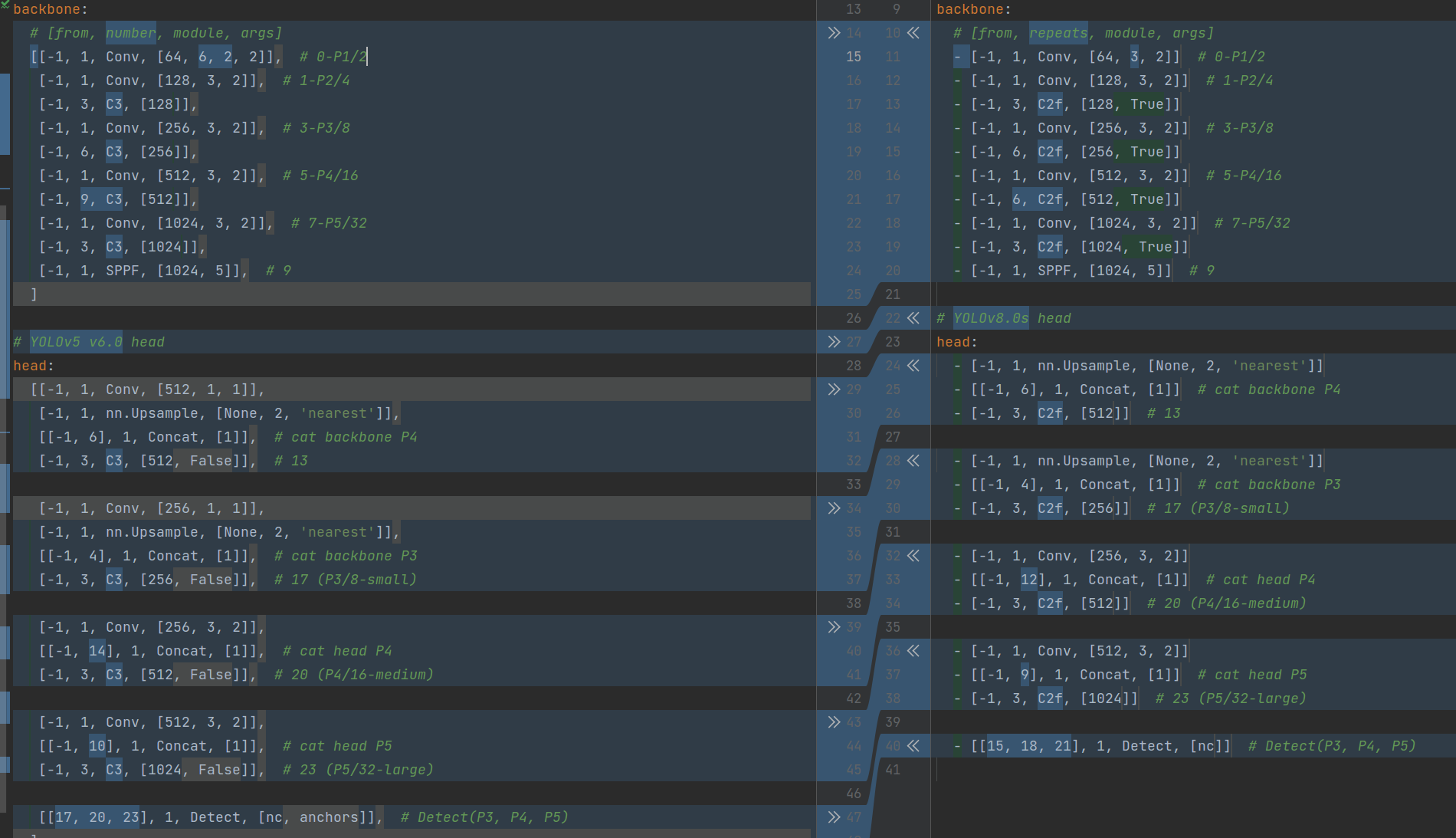
左侧为 YOLOv5-s,右侧为 YOLOv8-s
骨干网络和 Neck 的具体变化为:
Head 部分变化最大,从原先的耦合头变成了解耦头,并且从 YOLOv5 的 Anchor-Based 变成了 Anchor-Free。其结构如下所示:
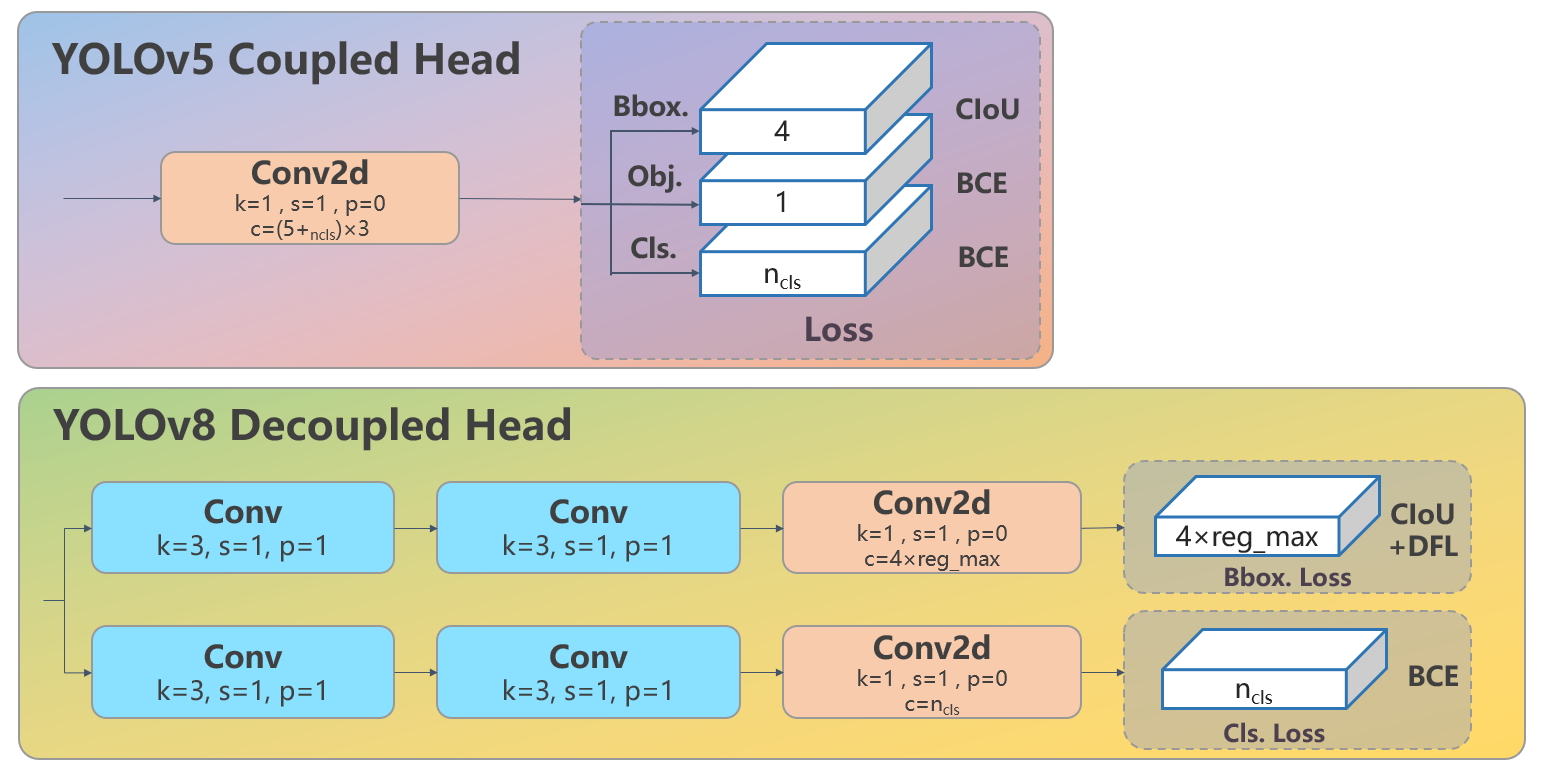
可以看出,不再有之前的 objectness 分支,只有解耦的分类和回归分支,并且其回归分支使用了 Distribution Focal Loss 中提出的积分形式表示法, DFL 的描述见知乎推文:https://zhuanlan.zhihu.com/p/147691786。
Loss 计算过程包括 2 个部分: 正负样本分配策略和 Loss 计算。
现代目标检测器大部分都会在正负样本分配策略上面做文章,典型的如 YOLOX 的 simOTA、TOOD 的 TaskAlignedAssigner 和 RTMDet 的 DynamicSoftLabelAssigner,这类 Assigner 大都是动态分配策略,而 YOLOv5 采用的依然是静态分配策略。考虑到动态分配策略的优异性,YOLOv8 算法中则直接引用了 TOOD 的 TaskAlignedAssigner。
TaskAlignedAssigner 的匹配策略简单总结为: 根据分类与回归的分数加权的分数选择正样本。
s 是标注类别对应的预测分值,u 是预测框和 gt 框的 iou,两者相乘就可以衡量对齐程度。
Loss 计算包括 2 个分支: 分类和回归分支,没有了之前的 objectness 分支。
3 个 Loss 采用一定权重比例加权即可。
数据增强方面和 YOLOv5 差距不大,只不过引入了 YOLOX 中提出的最后 10 个 epoch 关闭 Mosaic 的操作。假设训练 epoch 是 500,其示意图如下所示:
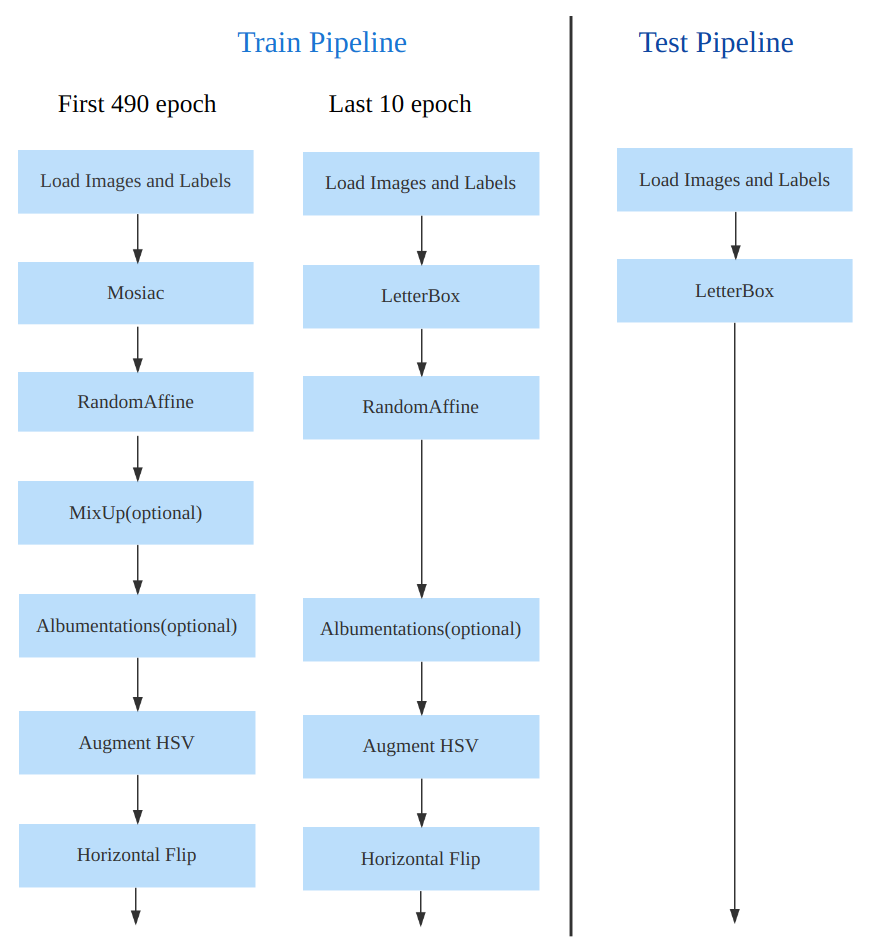
考虑到不同模型应该采用的数据增强强度不一样,因此对于不同大小模型,有部分超参会进行修改,典型的如大模型会开启 MixUp 和 CopyPaste。数据增强后典型效果如下所示:

上述效果可以运行 https://github.com/open-mmlab/mmyolo/blob/dev/tools/analysis_tools/browse_dataset.py 脚本得到
由于每个 pipeline 都是比较常规的操作,本文不再赘述。如果想了解每个 pipeline 的细节,可以查看 MMYOLO 中 YOLOv5 的算法解析文档 https://mmyolo.readthedocs.io/zh_CN/latest/algorithm_descriptions/yolov5_description.html#id2
YOLOv8 的训练策略和 YOLOv5 没有啥区别,最大区别就是模型的 训练总 epoch 数从 300 提升到了 500,这也导致训练时间急剧增加。以 YOLOv8-S 为例,其训练策略汇总如下:
| 配置 | YOLOv8-s P5 参数 |
|---|---|
| optimizer | SGD |
| base learning rate | 0.01 |
| Base weight decay | 0.0005 |
| optimizer momentum | 0.937 |
| batch size | 128 |
| learning rate schedule | linear |
| training epochs | 500 |
| warmup iterations | max(1000,3 * iters_per_epochs) |
| input size | 640x640 |
| EMA decay | 0.9999 |
YOLOv8 的推理过程和 YOLOv5 几乎一样,唯一差别在于前面需要对 Distribution Focal Loss 中的积分表示 bbox 形式进行解码,变成常规的 4 维度 bbox,后续计算过程就和 YOLOv5 一样了。
以 COCO 80 类为例,假设输入图片大小为 640x640,MMYOLO 中实现的推理过程示意图如下所示:
暂时无法在飞书文档外展示此内容
其推理和后处理过程为:
(1) bbox 积分形式转换为 4d bbox 格式
对 Head 输出的 bbox 分支进行转换,利用 Softmax 和 Conv 计算将积分形式转换为 4 维 bbox 格式
(2) 维度变换
YOLOv8 输出特征图尺度为 80x80、40x40 和 20x20 的三个特征图。Head 部分输出分类和回归共 6 个尺度的特征图。
将 3 个不同尺度的类别预测分支、bbox 预测分支进行拼接,并进行维度变换。为了后续方便处理,会将原先的通道维度置换到最后,类别预测分支 和 bbox 预测分支 shape 分别为 (b, 80x80+40x40+20x20, 80)=(b,8400,80),(b,8400,4)。
(3) 解码还原到原图尺度
分类预测分支进行 Sigmoid 计算,而 bbox 预测分支需要进行解码,还原为真实的原图解码后 xyxy 格式。
(4) 阈值过滤
遍历 batch 中的每张图,采用 score_thr 进行阈值过滤。在这过程中还需要考虑 multi_label 和 nms_pre,确保过滤后的检测框数目不会多于 nms_pre。
(5) 还原到原图尺度和 nms
基于前处理过程,将剩下的检测框还原到网络输出前的原图尺度,然后进行 nms 即可。最终输出的检测框不能多于 max_per_img。
有一个特别注意的点:YOLOv5 中采用的 Batch shape 推理策略,在 YOLOv8 推理中暂时没有开启,不清楚后面是否会开启,在 MMYOLO 中快速测试了下,如果开启 Batch shape 会涨大概 0.1~0.2。
MMYOLO 中提供了一套完善的特征图可视化工具,可以帮助用户可视化特征的分布情况。
以 YOLOv8-s 模型为例,第一步需要下载官方权重,然后将该权重通过 https://github.com/open-mmlab/mmyolo/blob/dev/tools/model_converters/yolov8_to_mmyolo.py 脚本将去转换到 MMYOLO 中,注意必须要将脚本置于官方仓库下才能正确运行,假设得到的权重名字为 mmyolov8s.pth。
假设想可视化 backbone 输出的 3 个特征图效果,则只需要
cd mmyolo # dev 分支
python demo/featmap_vis_demo.py demo/demo.jpg configs/yolov8/yolov8_s_syncbn_fast_8xb16-500e_coco.py mmyolov8s.pth --channel-reductio squeeze_mean
需要特别注意,为了确保特征图和图片叠加显示能对齐效果,需要先将原先的 test_pipeline 替换为如下:
test_pipeline = [
dict(
type='LoadImageFromFile',
file_client_args=_base_.file_client_args),
dict(type='mmdet.Resize', scale=img_scale, keep_ratio=False), # 这里将 LetterResize 修改成 mmdet.Resize
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor'))
]

从上图可以看出不同输出特征图层主要负责预测不同尺度的物体。
我们也可以可视化 Neck 层的 3 个输出层特征图:
cd mmyolo # dev 分支
python demo/featmap_vis_demo.py demo/demo.jpg configs/yolov8/yolov8_s_syncbn_fast_8xb16-500e_coco.py mmyolov8s.pth --channel-reductio squeeze_mean --target-layers neck

从上图可以发现物体处的特征更加聚焦。
本文详细分析和总结了最新的 YOLOv8 算法,从整体设计到模型结构、Loss 计算、训练数据增强、训练策略和推理过程进行了详细的说明,并提供了大量的示意图供大家方便理解。
简单来说 YOLOv8 是一个包括了图像分类、Anchor-Free 物体检测和实例分割的高效算法,检测部分设计参考了目前大量优异的最新的 YOLO 改进算法,实现了新的 SOTA。不仅如此还推出了一个全新的框架。不过这个框架还处于早期阶段,还需要不断完善。
由于时间仓促且官方代码在不断完善中,如果有不对的地方,欢迎批评和指正。MMYOLO 会尽快地跟进并复现该算法,敬请期待!
MMYOLO 开源地址: https://github.com/open-mmlab/mmyolo/blob/dev/configs/yolov8/README.md
MMYOLO 算法解析教程:https://mmyolo.readthedocs.io/zh_CN/latest/algorithm_descriptions/index.html#id2
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
有没有办法快速将表格格式的ruby哈希打印到文件中?如:keyAkeyBkeyC...1232343451253474456...其中散列的值是不同大小的数组。还是使用双循环是唯一的方法?谢谢 最佳答案 试试我写的这个gem(在表中打印散列、ruby对象、ActiveRecord对象):http://github.com/arches/table_print 关于ruby-如何以表格格式快速打印Ruby哈希值?,我们在StackOverflow上找到一个类似的问题:
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
电脑启动出现显示器黑屏是一个相当常见的问题。如果您遇到了这个问题,不要惊慌,因为它有很多可能的原因,可以采取一些简单的措施来解决它。在本文中,小编将介绍下面4种常见的电脑启动后显示器黑屏的原因,排查这些原因,快速解决! 演示机型:联想Ideapad700-15ISK-ISE系统版本:Windows10一、显示器问题如果出现电脑启动后显示器黑屏的情况。那么首先您需要检查一下显示器是否正常工作。您可以通过更换另一个显示器或将当前显示器连接到另一台计算机来检查显示器是否存在问题。如果问题仍然存在,那么您可以排除显示器故障的可能性。 二、显卡问题如果您的电脑配备了独立显卡,那么显卡故障也可能是导致电脑
一、什么是MQTT协议MessageQueuingTelemetryTransport:消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与HTTP一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。原理:(1)MQTT协议身份和消息格式有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为:主题(Topic)和负载(payload)两部分Topic,可以理解为消息的类型,订阅者订阅(Su
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
mutationtesting遇到一个问题是它很慢,因为默认情况下您会为每个生成的突变执行完整的测试运行(测试文件或一组测试文件)。加快突变测试的一种方法是,一旦遇到单一故障(但仅在突变测试期间),就停止对给定突变体的测试运行。更好的做法是让变异测试者记住杀死最后一个变异体的第一个测试是什么,并将其首先交给下一个变异体。ruby中是否有任何东西可以做这些事情,或者我最好的选择是开始猴子修补?(是的,我知道单元测试应该很快。显示所有失败的测试在突变测试之外很有用,因为它不仅可以帮助您识别出问题,还可以查明哪里出了问题)编辑:我目前正在对测试/单元使用heckle。如果测试/单元不可能记住
进行这种深度检查的最佳方法是什么:{:a=>1,:b=>{:c=>2,:f=>3,:d=>4}}.include?({:b=>{:c=>2,:f=>3}})#=>true谢谢 最佳答案 我想我从那个例子中明白了你的意思(不知何故)。我们检查子哈希中的每个键是否在超哈希中,然后检查这些键的对应值是否以某种方式匹配:如果值是哈希,则执行另一次深度检查,否则,检查值是否相等:classHashdefdeep_include?(sub_hash)sub_hash.keys.all?do|key|self.has_key?(key)&&ifs
我有一个Rails应用程序,它从WorldWeatherOnlineAPI获取响应。我正在使用rest-clientgem,响应采用JSON格式。我使用以下方法解析响应:parsed_response=JSON.parse(response)parsed_response显然是一个散列。我需要的数据是哈希内的字符串,数组内的哈希,另一个数组内的哈希,另一个哈希内的另一个哈希内的字符串。最内层的嵌套散列在["hourly"]中,这是一个由8个散列组成的数组,每个散列有20个键,拥有各种天气参数的字符串值。数组中的每个哈希值都是一天中的不同时间(预测是每三小时一次,3*8=24小时)。因此
一文解决关于VLAN所有的疑惑VLAN基本概念为什么需要VLAN?怎么在交换机上划分VLAN,VLAN的工作原理有了子网,已经隔离了广播,还需要VLAN干啥?只进行子网划分,不进行VLAN划分VLAN划分与子网划分附加VLAN信息的方法VLAN划分交换机的端口类型(Access和Trunk)一、访问链接二、汇聚链接汇聚链接VLAN间通信为什么要进行VLAN间通信?路由器实现VLAN间通信路由器和交换机的连接方式通信细节三层交换机实现VLAN间通信加速VLAN间通信三层交换机与路由器三层交换机路由器路由器和交换机配合构建LAN的实例使用VLAN设计局域网的特点VLAN增加网络的灵活性不使用VLA