在看论文时,常看到Kruskal-Wallis检验,却不知道它具体是一个什么样的检验,这篇文章主要介绍Kruskal-Wallis检验的检验方法,和检验目的,不涉及Kruskal-Wallis检验的证明。详情请看博客原文
Kruskal-Wallis检验是基于wilcox秩和检验发展而来的,其目的是检验不同分组之间中位数是否均相同。其原假设为 H 0 : M 1 = M 2 = ⋅ ⋅ ⋅ = M k H_0: M_1=M_2=\cdot \cdot \cdot =M_k H0:M1=M2=⋅⋅⋅=Mk 。其中, k 为分组数, M i M_i Mi为第 i 组样本总体的中位数。若拒绝原假设,则说明这k组之间的中位数不全相同,即这k组样本不全来自一个总体。Kruskal-Wallis检验是基于秩的非参数性检验对于样本的原分布没有要求。
Kruskal-Wallis构造的统计量为:
H = 12 N ( N − 1 ) ∑ i = 0 k R i 2 n i − 3 ( N + 1 ) , v = k − 1 H = \frac{12}{N(N-1)}\sum_{i=0}^{k} \frac{R_i^2}{n_i} - 3(N+1),\ v=k-1 H=N(N−1)12i=0∑kniRi2−3(N+1), v=k−1
H服从自由度为 v 的 χ 2 \chi^2 χ2分布,下表是变量解释:
n i : 第 i 组中所含有的样本数 , N : ∑ i = 0 k n i , R i : 第 i 组中所有样本排秩的和 , v : 自由度 \begin{align} n_i : 第i组中所含有的样本数, \ N : \sum_{i=0}^{k} n_i \ , \ R_i: 第i组中所有样本排秩的和, \ v: 自由度 \end{align} ni:第i组中所含有的样本数, N:i=0∑kni , Ri:第i组中所有样本排秩的和, v:自由度
这里,简单解释一下什么是排秩的和。Kruskal-Wallis检验是不关注原样本的实际测量值,而是同Wlicox秩和检验一样关注每个样本的实际测量值在所有样本中的排名情况,然后根据排名进行检验。而 R i R_i Ri表示的是所有i组的样本的排名进行相加得到的值。注意,在赋排名时遇到同样的观测值,一般是将这几个同样观测值先排名,然后根据他们的排秩求均值,最后算出的均值作为他们新的排秩。
下表是一项动物研究,研究者欲探究A,B两种菌对小鼠巨噬细胞吞噬功能的激活作用,将59只小鼠随机分为三组,其中一组为生理盐水对照,最后检测这59只小鼠的吞噬率。
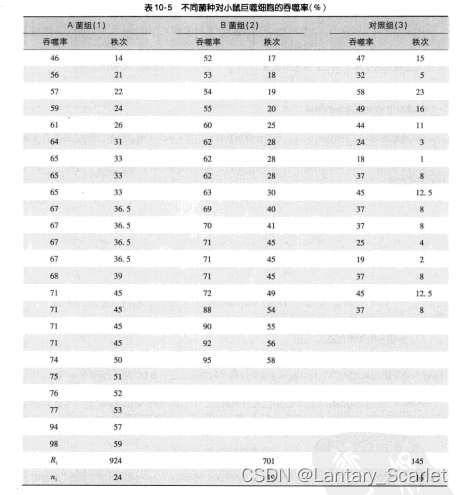
在对实验各结果进行正态性检验以及方差齐性检验后,发现A,B菌组不服从正态分布。因此,可以采用Kruskal-Wallis进行检验。下面是检验步骤:
H 0 : 三个总体的分布相同,即三个处理组的吞噬率相同 H 1 : 三个总体的分布不相同或不全相同,即三个处理组的吞噬率不相同或不全相同 α = 0.005 \begin{align} & H_0: 三个总体的分布相同,即三个处理组的吞噬率相同 \\\\ & H_1: 三个总体的分布不相同或不全相同,即三个处理组的吞噬率不相同或不全相同 \\\\ & \alpha = 0.005 \end{align} H0:三个总体的分布相同,即三个处理组的吞噬率相同H1:三个总体的分布不相同或不全相同,即三个处理组的吞噬率不相同或不全相同α=0.005
将各组样本混合,由小到大排序并编秩,如遇有相等数值则取平均秩次,如吞噬率为65的有3个,他们的秩次为32、33和34,取平均秩次为 ( 32 + 33 + 34 ) / 3 = 33 (32+33+34)/3 = 33 (32+33+34)/3=33。
分别求将各组秩次相加求得秩和 R 1 , R 2 和 R 3 R_1,R_2和R_3 R1,R2和R3。
H = 12 59 ( 59 + 1 ) ( 92 4 2 24 + 70 1 2 19 + 14 5 2 16 ) − 3 ( 59 + 1 ) = 32.72 H = \frac{12}{59(59+1)}(\frac{924^2}{24}+\frac{701^2}{19}+\frac{145^2}{16})-3(59+1)=32.72 H=59(59+1)12(249242+197012+161452)−3(59+1)=32.72
若相同秩次较多(如超过25%),则需考虑矫正H统计量,矫正公式如下:
H c = H c c = 1 − ∑ ( t j 3 − t j ) N 3 − N \begin{align} & H_c = \frac{H}{c} \\\\ & c= 1 - \frac{\sum (t_j^3-t_j)}{N^3-N} \end{align} Hc=cHc=1−N3−N∑(tj3−tj)
其中, t j t_j tj表示第 j 次相持时相同秩次的个数。本例中
c = 1 − ( 3 3 − 3 ) + ( 4 4 − 4 ) + ( 7 7 − 7 ) + ( 3 3 − 3 ) + ( 5 3 − 3 ) + ( 2 3 − 2 ) 5 9 3 − 59 = 0.997 H c = 32.72 / 0.997 = 32.818 \begin{align} & c = 1-\frac{(3^3-3)+(4^4-4)+(7^7-7)+(3^3-3)+(5^3-3)+(2^3-2)}{59^3-59} = 0.997 \\\\ & H_c = 32.72/0.997 = 32.818 \end{align} c=1−593−59(33−3)+(44−4)+(77−7)+(33−3)+(53−3)+(23−2)=0.997Hc=32.72/0.997=32.818
计算自由度,v = k - 1 = 3 - 1 = 2 。因此 χ 0.005 , 2 2 = 10.60 < H c = 32.818 \chi ^2_{0.005,2} = 10.60 < H_c = 32.818 χ0.005,22=10.60<Hc=32.818,故拒绝原假设,P < 0.005。可以认为,不同菌种对小鼠巨噬细胞的吞噬率有所不同。
[[2] 医学统计学8年制 颜虹编 第2版: 174-177]
如果gem具有rails依赖项,您认为以可以独立运行或在rails项目下运行的方式编写gem测试更好吗? 最佳答案 gem应该是一段独立运行的代码。否则它是应用程序的一部分,因此测试也应该独立创建。通过这种方式,其他人(假设)也可以执行测试。如果测试依赖于您的应用程序,则其他人无法测试您的gem。此外,当您想要测试您的gem时,它不应该因为您的应用程序失败而失败。在您的gem通过测试后,您可以测试应用程序,知道您的gem运行良好(假设您测试了所有内容)。gem是否依赖于Rails不是问题,因为Rails也已经过测试(您可以假设它工作
简单说就是:拒绝域与备择假设方向相同。假设检验就是一个证伪的过程,原假设和备择假设是一对"相反的结论"。"拒绝域",顾名思义,就是拒绝原假设的范围和方向,所以判断拒绝域在哪,可以直接看备择假设H1的条件是大于还是小于即可。上述只是判断方法之一,但如果你能明白置信区间原理,自然就可以明白单侧假设检验的位置了。从置信区间角度讲:例如,某个糖果厂宣称自家糖果的平均重量方法1:平均重量是6.5方法2:平均重量在[6.5-误差,6.5+误差]之间,置信度为0.95方法1是一种点估计方法,只给出了一个近似值,但没有给出这个近似值的范围和置信度,因此方法1的结果相对方法2并不可靠。双侧、单侧检验其实
之前收藏了极客时间的算法训练营3期共21课,计划每一课写博客来记录学习,主要形式为方法类型1题1题解题2题解方法类型2题1题解……题目大体来自leetcode和acwing主要记录和理解代码,所以基本完全搬运了视频题解代码,个人学习感受体现在大致思路的总结和注释上。第一题743.网络延迟时间Bellmen-ford最多n-1轮,可以处理有负数边的情况classSolution{public:intnetworkDelayTime(vector>×,intn,intk){vectordist(n+1,1e9);dist[k]=0;for(intround=1;roundtime:tim
我正在寻找一个高效的Java库(甚至是一个函数)来执行臭名昭著的精确二项式检验。类似于描述的R函数“binom.test”的东西here.你能帮帮我吗?非常感谢!:-) 最佳答案 除了BinomialDistributionApachecommons.math33.3(在撰写本文时未发布)还有一个BinomialTest这将为您提供p值以及BinomialConfidenceInterval.与您命名的statsR包相比,它并不多,但它不仅仅是上面提到的分布。在我找到您的问题时发布此信息,寻找一种方法来获取已知二项分布的pval,上
一、定义参考文章:SPSS中八类常用非参数检验之四:单样本K-S检验-dekevin-博客园(cnblogs.com) 单样本K-S检验是一种拟合优度的非参数检验方法。单样本K-S检验是利用样本数据推断总体是否服从某一理论分布的方法,适用于探索连续型随机变量的分布形态。1.目的:利用样本数据推断总体是否服从某个理论分布2.基本假设:H0:总体服从指定的分布.3.基本方法:①根据用户指定检验的总体分布,构造出一理论的频数分布,并计算相应的累计频率.②与样本在相同点的累计频率进行比较.如果相差较小,则认为样本所代表的总体符合指定的总体分布. 单样本K-S检验可以将一个变量的实际频数分布与正态分
我正在尝试编写一个程序来找到最小生成树。但是我在使用该算法时遇到的一个问题是测试电路。在Java中执行此操作的最佳方法是什么。好的,这是我的代码importjava.io.*;importjava.util.*;publicclassJungleRoads{publicstaticintFindMinimumCost(ArrayListgraph,intsize){inttotal=0;int[]marked=newint[size];//keepstrackoverintegerinthemst//convertanarraylisttoanarrayListwrapper=grap
🤵♂️个人主页:@艾派森的个人主页✍🏻作者简介:Python学习者🐋希望大家多多支持,我们一起进步!😄如果文章对你有帮助的话,欢迎评论💬点赞👍🏻收藏📂加关注+目录两独立样本的非参数检验两独立样本的极端反应检验两配对样本的非参数检验 两独立样本的非参数检验两独立样本的非参数检验在对总体分布不甚了解的情况下,通过对两个独立样本的分析推断样本来自的两总体的分布是否存在显著差异的方法独立样本是指在从一个总体中随机抽样对在另一个总体中随机抽样没有影响的情况下所获得的样本主要方法曼-惠特尼U检验(Mann-WhitneyU)K-S检验W-W游程检验极端反应检验 注意: 不同分析方法对同一批
目录ADF检验简介adftest的使用及参数介绍——简单调用:h=adftest(y)——多参数调用:[h,pValue,stat,cValue]=adftest(y,'alpha',0.05)adftest如何判断是否平稳?——原假设与备择假设——通过h判断是否平稳——通过pValue判单是否平稳——通过stat和cValue判断是否平稳应用举例(以1978年到2020年的中国GDP为例):原始序列的ADF检验一阶差分序列的ADF检验二阶差分序列完整代码及数据作者水平有限,第一次发文,有错误及需要改正的地方请指正ADF检验简介ADF检验全称为AugmentedDickey-Fullertes
b站课程视频链接:https://www.bilibili.com/video/BV19x411X7C6?p=1腾讯课堂(最新,但是要花钱,我花99😢😢元买了,感觉讲的没问题,就是知识点结构有点乱,有点废话):https://ke.qq.com/course/3707827#term_id=103855009 本笔记前面的笔记参照b站视频,【后面的画图】参考了付费视频笔记顺序做了些调整【个人感觉逻辑顺畅】,并删掉一些不重要的内容,以及补充了个人理解系列笔记目录【持续更新】:https://blog.csdn.net/weixin_42214698/category_11393896.html文
在数据分析过程中,往往需要数据服从正态分布,正态分布,也称“常态分布”,又名高斯分布,在求二项分布的渐近公式中得到。很多方法都需要数据满足正态分布,比如方差分析、独立t检验、线性回归分析(因变量)等。如果说没有这个前提可能会导致分析不严谨等等。所以进行数据正态性检验很重要。那么如何进行正态性检验?接下来进行说明。一、检验方法SPSSAU共提供三种正态性检验的方法,分别是描述法、正态性检验以及图示法,其中图示法包括直方图以及P-P/Q-Q图。1.1描述法理论上讲,标准正态分布偏度和峰度均为0,但现实中数据无法满足标准正态分布,因而如果峰度绝对值小于10并且偏度绝对值小于3,则说明数据虽然不是绝对