
UNETR++: Delving into Efficient and Accurate 3D Medical Image Segmentation
论文链接:
https://arxiv.org/abs/2212.04497
代码链接:
https://github.com/Amshaker/unetr_plus_plus

这篇论文主要讲述了一种名为 UNETR++ 的 3D 医学图像分割方法,它提供了高质量的分割结果,并具有高效的参数和计算成本。作者介绍了一种新的有效的配对注意力(EPA)模块,该模块使用一对基于空间和通道注意的相互依赖分支来有效地学习空间和通道方向的区分性特征。实验结果表明,该方法在 Synapse、BTCV 和 ACDC 数据集上均优于现有方法。
3D 分割是医学图像中的一个基础问题,并且用于许多应用,包括肿瘤识别和器官定位等诊断目的。3D 分割任务通常采用 U-Net 类似的编码器-解码器架构,其中编码器生成 3D 图像的分层低维表示,解码器将这个学习的表示映射到体素分割。早期的基于 CNN 的方法在编码器和解码器中分别使用卷积和反卷积,但很难实现准确的分割结果,可能是由于其局限的局部感受野。另一方面,基于 transformer 的方法天生是全局的,并且最近已经证明了具有竞争性能的成本,但模型复杂度增加。这篇论文提出了一种混合架构来结合局部卷积和全局注意力的优点。作者指出,这种架构能够在提高分割精度的同时减小模型的参数数量和 FLOPs,提高模型的鲁棒性。作者认为,这种方法的优势在于它捕捉了空间和通道特征之间的显式依赖关系,从而提高了分割质量。
UNETR++是一种新型的3D医学图像分割混合层次架构,旨在提高分割准确度和效率。它是在UNET的基础上提出的一种改进模型,通过引入精细化模块和跨层连接来增强特征表示能力,并通过尺度匹配和跨层金字塔来减少模型参数和计算复杂度。经过实验验证,UNETR++在主流数据集上的分割准确度和效率都优于其他现有模型。UNETR++基于最近提出的UNETR框架,引入了一种新的有效的配对注意力(EPA)模块,通过在两个分支中应用空间注意力和通道注意力,有效地捕捉了丰富的相互依存的空间和通道特征。我们的EPA中的空间注意力将key和value投影到固定的较低维空间,self attention的计算与input token的数量成线性关系。这有助于提高模型的特征表示能力,同时又不会增加太多的参数和计算复杂度。另一方面,我们的通道注意力通过在通道维度上对query和key执行点积运算,强调了通道特征映射之间的依赖性。此外,为了捕捉空间和通道特征之间的强相关性,query和key的权重在两个分支之间共享,这也有助于控制网络参数的数量。相比之下,值的权重是独立的,以强制在两个分支中学习互补特征。这种设计能够有效地平衡两个分支的贡献,提高模型的性能。
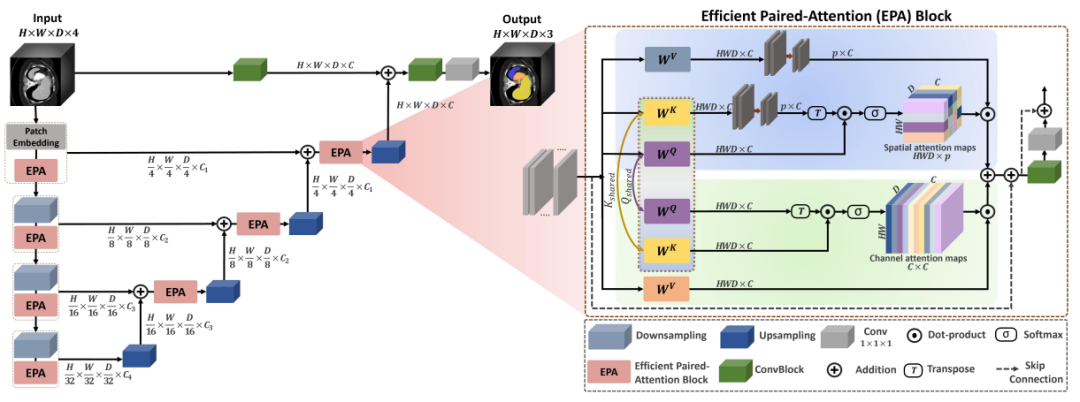
上图展示了UNETR++模型的层级编解码结构。
动机: 在设计混合框架时要考虑的两个理想属性:效率和准确性。这两个属性都非常重要,因为它们可以帮助框架在实际应用中更好地发挥作用。在设计混合框架时,应该尽量将这两个属性结合起来,以达到更好的性能。
有效的全局注意力: 现有混合方法中使用的自注意力操作复杂度为平方,并且在体积医学分割中具有较高的计算代价。与这些方法不同,作者认为,在特征通道而不是体积维度上计算自注意力可以将复杂度从平方降低到线性。此外,空间注意力信息可以通过将key和query空间矩阵投影到较低维空间中来有效地学习。这种方法可以在保证性能的同时减少计算复杂度,从而更好地处理大型体积数据。
增强空间和通道特征表示: 大多数现有的体积医学图像分割方法通常通过注意力计算来捕获空间特征,并忽略了通道信息。有效地结合空间维度中的交互作用和通道特征之间的相互依赖关系,有望提供丰富的上下文空间通道特征表示,从而提高掩模预测的准确性。通过这种方式,算法可以更好地利用通道信息来捕获更丰富的空间信息,从而提高分割精度。
本文提出了一种UNETR++框架,旨在更有效地学习空间信道特征表示。为了实现这一目标,这篇论文中提出了一种新的EPA模块,它包含两个注意力模块,通过共享key-query方案来有效地在空间和通道维度上编码信息。该论文还提出了在编码阶段和解码阶段之间通过跳过连接来连接的方法,以便在不同的分辨率上合并输出。这有助于恢复在下采样操作期间丢失的空间信息,从而预测更精确的输出。与编码器类似,解码器由四个阶段组成,每个阶段都包含一个使用反卷积来增加特征图分辨率的上采样层,然后是 EPA 模块(除了最后一个解码器)。在每两个解码器阶段之间,通道数减少了一倍。因此,最后一个解码器的输出与卷积特征图融合,以恢复空间信息并增强特征表示。然后将得到的输出输入 3×3×3 和 1×1×1 卷积块,生成体素方面的最终掩码预测。
接下来是 EPA 模块的介绍。EPA 模块执行高效的全局注意力,有效地捕获丰富的空间-通道特征表示。EPA 模块包括空间注意力和通道注意力模块。空间注意力模块将自我关注的复杂度从二次降低到线性。另一方面,通道注意力模块有效地学习通道特征图之间的相互依赖性。EPA 模块基于两个注意力模块之间的共享key和query方案,以便互相信息交流,以生成更好、更高效的特征表示。这可能是因为通过共享key和query来学习互补特征,但使用不同的值层。
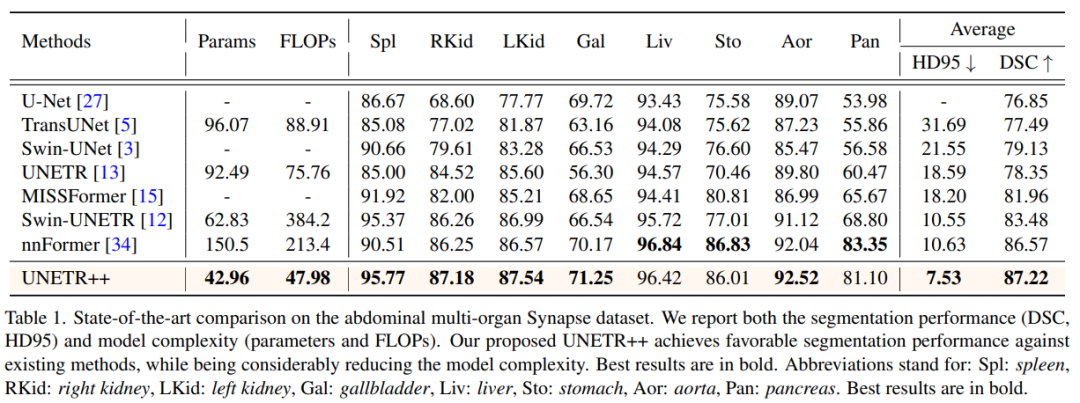
在abdominal multi-organ Synapse dataset中,对比SOTA模型,UNETR++仅用了其1/3的参数量和1/4的计算量取得了最高的精度。

在多器官分割的BTCV测试集中,UNETR++的综合精度比SOTA模型高出1.5%以上。
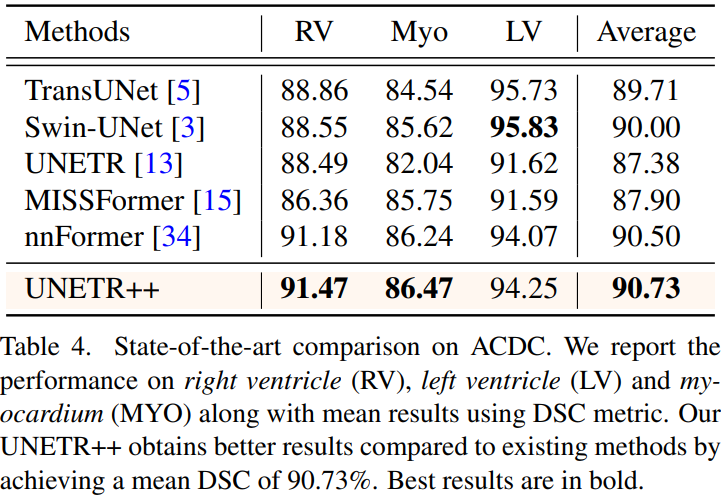
在ACDC数据集中,UNETR++的综合精度比SOTA模型高出0.2%以上。

将EPA模块分别应用在编码器和解码器的精度提升。



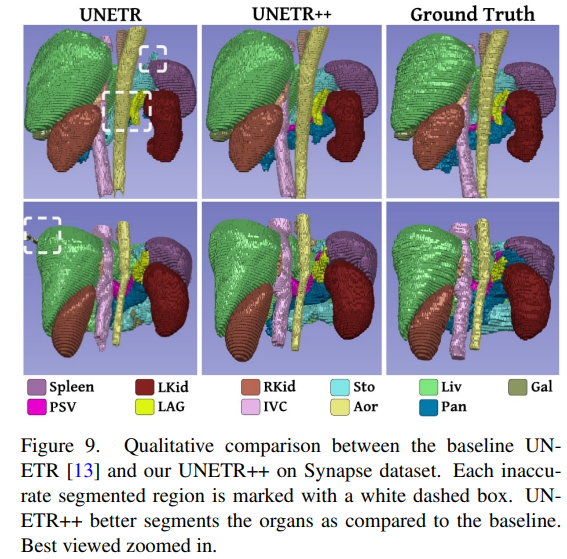
可以很清晰地观察到,无论是小体积还是粘连等复杂场景,UNETR++都能略胜一筹。
本文所提出的UNETR++在三种医学图像分割数据集上均以更少的模型复杂度获得了更高的分割精度,超越了目前所有的医学图像分割SOTA模型。然而,在对于以下两种情况:器官形状模糊以及器官边界不明显,UNETR++也无法很好的分割。这是由于这些困难场景样本远少于正常场景样本,导致模型无法很好地关注到困难样本特征。未来,作者将会在数据预处理阶段使用特定的几何数据增强技术来对这些困难场景进行针对性的优化。
本文提出了一种用于3D医学图象分割的分层方法:UNETR++。通过引入有效的配对注意力(EPA)模块,UNETR++能够丰富空间和通道之间相关依赖的特征。
在配对注意力(EPA)模块中,共享query和key的映射函数权重能够使得空间和通道分支进行更高效地交流特征信息,这可以为双方提供互补的有益特征并且降低参数量。
UNETR++在三个国际著名医学图象分割数据集中均以更少的模型复杂度取得最更高的精度结果。
我有带有Logo图像的公司模型has_attached_file:logo我用他们的Logo创建了许多公司。现在,我需要添加新样式has_attached_file:logo,:styles=>{:small=>"30x15>",:medium=>"155x85>"}我是否应该重新上传所有旧数据以重新生成新样式?我不这么认为……或者有什么rake任务可以重新生成样式吗? 最佳答案 参见Thumbnail-Generation.如果rake任务不适合你,你应该能够在控制台中使用一个片段来调用重新处理!关于相关公司
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit
Unity自动旋转动画1.开门需要门把手先动,门再动2.关门需要门先动,门把手再动3.中途播放过程中不可以再次进行操作觉得太复杂?查看我的文章开关门简易进阶版效果:如果这个门可以直接打开的话,就不需要放置"门把手"如果门把手还有钥匙需要旋转,那就可以把钥匙放在门把手的"门把手",理论上是可以无限套娃的可调整参数有:角度,反向,轴向,速度运行时点击Test进行测试自己写的代码比较垃圾,命名与结构比较拉,高手轻点喷,新手有类似的需求可以拿去做参考上代码usingSystem.Collections;usingSystem.Collections.Generic;usingUnityEngine;u
之前说过10之后的版本没有3dScan了,所以还是9.8的版本或者之前更早的版本。 3d物体扫描需要先下载扫描的APK进行扫面。首先要在手机上装一个扫描程序,扫描现实中的三维物体,然后上传高通官网,在下载成UnityPackage类型让Unity能够使用这个扫描程序可以从高通官网上进行下载,是一个安卓程序。点到Tools往下滑,找到VuforiaObjectScanner下载后解压数据线连接手机,将apk文件拷入手机安装然后刚才解压文件中的Media文件夹打开,两个PDF图打印第一张A4-ObjectScanningTarget.pdf,主要是用来辅助扫描的。好了,接下来就是扫描三维物体。将瓶
我正在尝试使用Ruby2.0.0和Rails4.0.0提供的API从imgur中提取图像。我已尝试按照Ruby2.0.0文档中列出的各种方式构建http请求,但均无济于事。代码如下:require'net/http'require'net/https'defimgurheaders={"Authorization"=>"Client-ID"+my_client_id}path="/3/gallery/image/#{img_id}.json"uri=URI("https://api.imgur.com"+path)request,data=Net::HTTP::Get.new(path
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p
我有一个应用需要发送用户事件邀请。当用户邀请friend(用户)参加事件时,如果尚不存在将用户连接到该事件的新记录,则会创建该记录。我的模型由用户、事件和events_user组成。classEventdefinvite(user_id,*args)user_id.eachdo|u|e=EventsUser.find_or_create_by_event_id_and_user_id(self.id,u)e.save!endendend用法Event.first.invite([1,2,3])我不认为以上是完成我的任务的最有效方法。我设想了一种方法,例如Model.find_or_cr
有这样的事吗?我想在Ruby程序中使用它。 最佳答案 试试这个http://csl.sublevel3.org/jp2a/此外,Imagemagick可能还有一些东西 关于ruby-是否有将图像文件转换为ASCII艺术的命令行程序或库?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/6510445/
我正在使用Dragonfly在Rails3.1应用程序上处理图像。我正在努力通过url将图像分配给模型。我有一个很好的表格:{:multipart=>true}do|f|%>RemovePicture?Dragonfly的文档指出:Dragonfly提供了一个直接从url分配的访问器:@album.cover_image_url='http://some.url/file.jpg'但是当我在控制台中尝试时:=>#ruby-1.9.2-p290>picture.image_url="http://i.imgur.com/QQiMz.jpg"=>"http://i.imgur.com/QQ