项目中使用了阿里的 Druid 数据库,刚开始很正常,后来发现出现了问题,问题如下:
org.springframework.transaction.CannotCreateTransactionException: Could not open JDBC Connection for transaction; nested exception is com.alibaba.druid.pool.DataSourceClosedException: dataSource already closed at Fri Jul 08 16:14:13 GMT+08:00 2022
at org.springframework.jdbc.datasource.DataSourceTransactionManager.doBegin(DataSourceTransactionManager.java:309)
at org.springframework.transaction.support.AbstractPlatformTransactionManager.startTransaction(AbstractPlatformTransactionManager.java:400)
at org.springframework.transaction.support.AbstractPlatformTransactionManager.getTransaction(AbstractPlatformTransactionManager.java:373)
at org.springframework.transaction.interceptor.TransactionAspectSupport.createTransactionIfNecessary(TransactionAspectSupport.java:595)
at org.springframework.transaction.interceptor.TransactionAspectSupport.invokeWithinTransaction(TransactionAspectSupport.java:382)
at org.springframework.transaction.interceptor.TransactionInterceptor.invoke(TransactionInterceptor.java:119)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:186)
at org.springframework.aop.framework.CglibAopProxy$CglibMethodInvocation.proceed(CglibAopProxy.java:753)
at org.springframework.aop.framework.CglibAopProxy$DynamicAdvisedInterceptor.intercept(CglibAopProxy.java:698)
at java.base/java.util.TimerThread.mainLoop(Timer.java:566)
at java.base/java.util.TimerThread.run(Timer.java:516)
Caused by: com.alibaba.druid.pool.DataSourceClosedException: dataSource already closed at Fri Jul 08 16:14:13 GMT+08:00 2022
at com.alibaba.druid.pool.DruidDataSource.getConnectionInternal(DruidDataSource.java:1113)
at com.alibaba.druid.pool.DruidDataSource.getConnectionDirect(DruidDataSource.java:1017)
at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:997)
at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:987)
at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:103)
at org.springframework.jdbc.datasource.DataSourceTransactionManager.doBegin(DataSourceTransactionManager.java:265)
... 13 common frames omitted
日志比较多,重点有以下几个:
Could not open JDBC Connection for transaction; nested exception is com.alibaba.druid.pool.DataSourceClosedException: dataSource already closed at Fri Jul 08 16:14:13 GMT+08:00 2022
Caused by: com.alibaba.druid.pool.DataSourceClosedException: dataSource already closed at Fri Jul 08 16:14:13 GMT+08:00 2022
其他的我们截图看看:
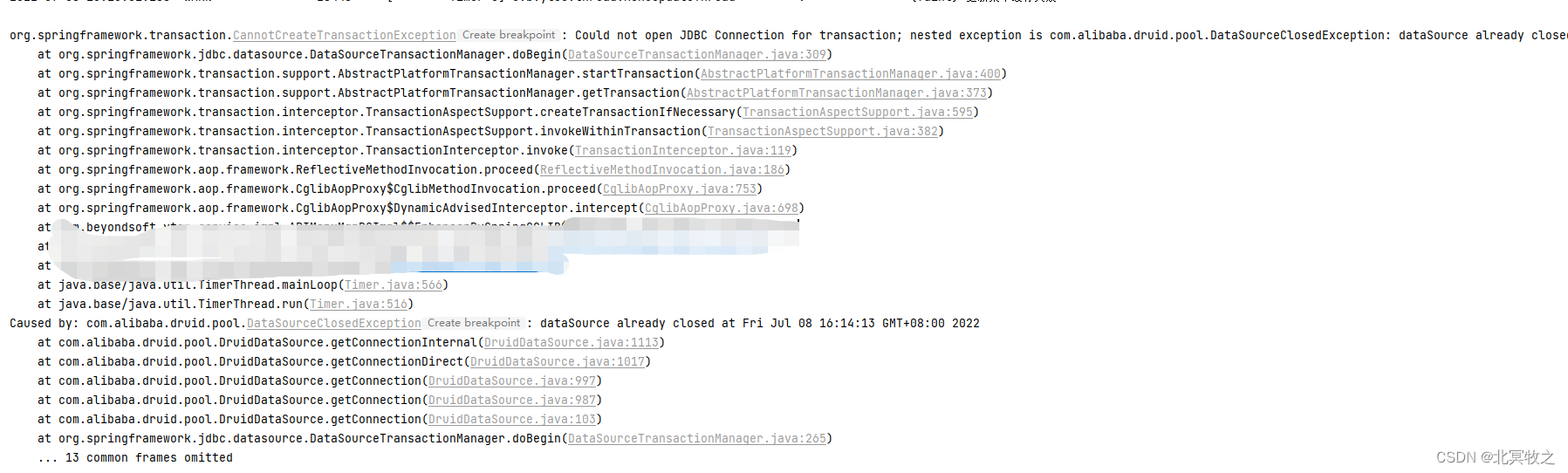
上图打码的地方是公司的dao层查数据库的代码。
意思很明白了,就是因为在进行查询的时候,连接已经关闭了,而且会一直刷出这样的日志。
综合网上大家的意见,可能原因主要有以下几点:
你可能使用了异步线程去访问数据库,异步线程是不由spring管理也就是说,spring可以在异步线程未执行完就会进行容器关闭 当异步线程执行到获取数据库的时候就会报错
博主给的答案是:
怎么才能彻底消除这个错误没有找到完美的解决方法,只要DataSource不进行重新注册,或者重新注册后再刷新相关的DAO引用的实例可暂时不出现这个问题了
参考:Druid连接池自动关闭
其实这个答案和上面一个的说法一致,不过这个给出了解决方案:
多线程批量处理的时候只需要在service方法上加上@transactional(rollbackFor = Exception.class)就行了,mybatis就不会每次执行完sql后closing sql session了
是否在定时器中手动获取了 DataSource,然后使用后关闭了或者用完后长期不再用被连接池自动关闭了?
答案是:发现不修改代码的时候,不会发生异常,修改代码之后触发热加载,然后就中断了链接,所以就报出那个错误。
这是网友的答案。
应该就是长时间不用,Druid自动关闭的问题。
这也是网友给出的可能性答案。
下面的也是网友的答案:
如果使用 jfinal 提供的 ActiveRecord 或者 Db + Record 操作数据库就不会出现此问题,自行得到 DataSource 或 Connection 的代码就需要开发者自己管理好这两个对象。
这个我没有尝试。
.setTestOnBorrow(false)
.setTestOnReturn(false)都改成 true。有网友说这个答案。
我试了试,没有什么卵用。
最终我发现可能的原因是:
我这项目启动的时候会有 @PostConstruct 注解初始化 redis 数据,通过多线程方式去处理,然后还会有定时任务定时刷新。而项目中有热部署,只要改动代码之后就会自动重启项目,然后就会出现了上述的错误。
如果我改动了代码,不让它热部署启动,我手动重启,或者先关闭项目然后再启动,就不会报这个错误了。
所以,我这边最终的原因就是热部署的问题,我的热部署不是使用的devtools,而是idea上有一个配置,改动配置之后就会热部署,但是我忘记改动哪个地方了。以后想起来了,再来修改文章。
我们同一套代码,都是Git上最新代码,但是我同事的代码就会报上面这个错误,我的就好的,他的没有热部署。最终发现的原因竟然是:
package com.xxx.common.util;
import com.xxx.common.file.SftpAuthority;
import com.xxx.ytec.common.file.SftpService;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.core.annotation.Order;
import org.springframework.stereotype.Component;
@Component
@Order(1)
public class FileCommandLineRunner implements CommandLineRunner {
private static final Logger LOGGER = LoggerFactory.getLogger(FileCommandLineRunner.class);
@Autowired
private SftpService sftpService;
@Override
public void run(String... args) throws Exception {
LOGGER.info("---------FileCommandLineRunner下载文件开始---------");
SftpAuthority root = new SftpAuthority("root", "192.168.0.100", 22);
root.setPassword("123456");
sftpService.createChannel(root);
sftpService.downloadFile(root, "/xxx/file/Data.csv", "C:\\Users\\Data.csv");
LOGGER.info("---------FileCommandLineRunner下载文件成功---------");
}
}因为这一套代码,他那里报了我们上面说的错,这个代码怎么与数据源连接有关呢?这个代码就是在项目启动的时候自动执行里面的代码,里面的逻辑就是通过sftp从服务器上下载文件的。
现在他的报错如下:
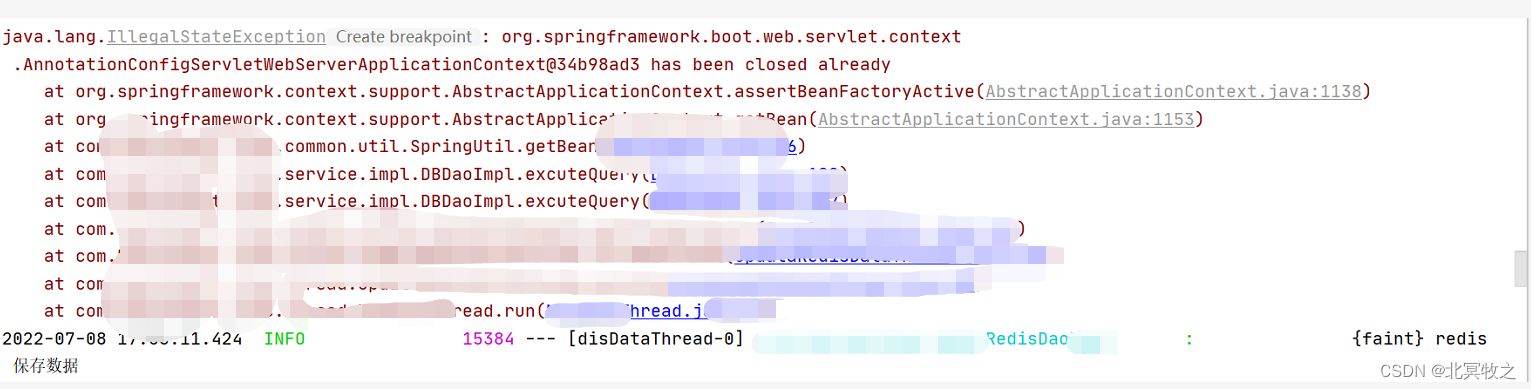
这个问题是很奇怪的,在我的电脑上没问题,在他那就会报错,只好把这个代码注释掉了。本来这个代码是我写给他测试下载文件的,也不会用到。
问题不算完美解决,暂时先这样吧!
我正在探索Sinatra,我想使用session,但我不想将它们存储在Cookie中,我发现Rack::Session::Pool效果很好。现在我希望session在一定持续时间后过期,但我不明白如何实例化Rack::Session::Pool并且他们在Sinatra中使用它。有什么线索吗? 最佳答案 Sinatra非常强大,TheWickedFlea的技巧没有奏效,但这个确实奏效了:useRack::Session::Pool,:domain=>'example.com',:expire_after=>60*60*24*365谢谢
我有一个使用enable:sessions构建的Sinatrawebapp,我使用session[:mything]访问我的session数据。我现在想在服务器端存储数据(即使用基于数据库的session),但我不知道如何使用Rack::Session::Pool,这似乎是我需要使用的东西。我如何着手转换我的网络应用程序以与Pool一起使用?我知道我需要添加行useRack::Session::Pool接下来会发生什么?—提前致谢!编辑:这是一个使用基于cookie的session的示例:require'rubygems'require'sinatra'enable:sessionsg
SpringCloudAlibaba全集文章目录:零、手把手教你搭建SpringCloudAlibaba项目一、手把手教你搭建SpringCloudAlibaba之生产者与消费者二、手把手教你搭建SpringCloudAlibaba之Nacos服务注册中心三、手把手教你搭建SpringCloudAlibaba之Nacos服务配置中心四、手把手教你搭建SpringCloudAlibaba之Nacos服务集群配置五、手把手教你搭建SpringCloudAlibaba之Nacos服务持久化配置六、手把手教你搭建SpringCloudAlibaba之Sentinel实现流量实时监控七、手把手教你搭
Rack::Session::Pool有哪些不同的用例?和Rack::Session::Cookie?据我了解(如果我错了请纠正我):Cookie将所有session键值对直接存储在cookie中(编码)Pool仅在cookie中存储一个id,并在@pool中维护session哈希的其余部分那么:选择一个而不是另一个的含义/原因是什么?什么是@pool?为什么Pool需要公开与Cookie不同的公共(public)接口(interface)?为什么文档如此缺乏? 最佳答案 你是对的,Session::Cookie在cookie中编码
在我们的Rails应用程序中,我们需要根据请求的子域使用不同的数据库(每个国家/地区使用不同的数据库)。现在我们正在做类似于thisquestion中推荐的事情.也就是说,在每个请求上调用ActiveRecord::Base.establish_connection。但是itseemsActiveRecord::Base.establish_connection删除当前连接池并在每次调用时建立一个新连接。我做了这个快速基准测试,看看每次调用establish_connection和已经建立连接之间是否有任何显着差异:require'benchmark/ips'$config=Rails
简介Nacos/nɑ:kəʊs/是DynamicNamingandConfigurationService的首字母简称,一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。Nacos提供简单的鉴权实现,为防止业务错用的弱鉴权体系,不是防止恶意攻击的强鉴权体系。一、漏洞原理Nacos服务管理平台因默认密钥导致的认证绕过漏洞。在默认配置为未修改的情况下,攻击者可以构造用户token进入后台,导致系统被攻击与控制。许多Nacos用户只开启了鉴权,但没有修改默认密钥,导致Nacos系统仍存在被入侵的风险。V1.4.2V2.2.0大致讲一下相关的内容:1、Nacos鉴权原理Nacos支持基于
我尝试使用sync.Pool来重用[]byte。但事实证明它比make慢。代码:packagemainimport("sync""testing")funcBenchmarkMakeStack(b*testing.B){forN:=0;N结果:$gotestpool_test.go-bench=.-benchmemBenchmarkMakeStack-420000000000.29ns/op0B/op0allocs/opBenchmarkBytePool-410000000017.2ns/op0B/op0allocs/op根据Go文档,sync.Pool应该更快,但我的测试显示并非如此
你好,我是全新的(和一般的并发编程:()并试图将缓慢的计算分配给工作池。http://play.golang.org/p/lTv4Tm75A4funcmain(){test:=[]int{1,2,3,4,5,6,7,8,9,10}answer:=getSmallestMultiple(test)fmt.Println(answer)}我试图找到能被test中的所有数字整除的最小数字。我创建了一个工作池并向他们发送值,直到其中一个goroutine找到一个可以除以test中所有数字的数字forw:=0;w尽管我启动了多少worker,但程序似乎以相同的速度运行。我已经尝试了很多worke
我想知道是否可以将sync.Pool与数组或slice一起使用?例如,sync.Pool是否可以在每秒处理数万个请求时加快以下速度?这个例子只是为了更好地理解Go。//HandlerthatusesGenerateArrayfuncok(whttp.ResponseWriter,r*http.Request){varres[100000]uint64fibonacci.GenerateArray(&res)fmt.Fprintf(w,"OK")}funcGenerateArray(data*[100000]uint64){varstartuint16=1000varcounteruin
我看到了issue在Github上说sync.Pool应该仅与指针类型一起使用,例如:varTPool=sync.Pool{New:func()interface{}{returnnew(T)},}有意义吗?returnT{}怎么样,哪个是更好的选择,为什么? 最佳答案 sync.Pool的全部意义在于避免(昂贵的)分配。大型缓冲区等。您分配一些缓冲区,它们保留在内存中,可供重用。因此使用指针。但在这里,您将在每一步都复制值,从而违背了目的。(假设您的T是一个“普通”结构,而不是像SliceHeader这样的东西)