爬虫:spider,网络蜘蛛
基于http请求发送和获取请求
模拟发送http请求,从别人的服务端获取数据爬虫其实算是擦边的行为,遵守规则的爬,不会违法。(在这里忠告各位玩家,一定要做遵纪守法的好公民,牢饭不香,缝纫机不好踩。)
那么爬虫的规则是什么呢?>>> 爬虫协议
爬虫协议:每个网站的根路径下都有robots.txt,这个文件规定了:该网站能爬的和不能爬的数据
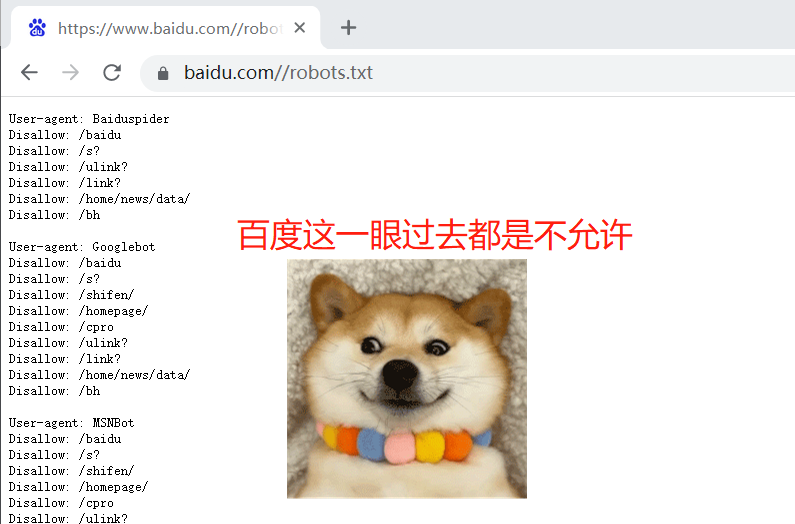
通过对站内和站外的优化来提高搜索引擎对网站的友好度,并提高网站的排名通过付费的手段。模拟发送http请求的模块
不仅爬虫用它,后期调用第三方接口,也会用到它
可以做长链接短链接的转换
pip3 install requests
本质是封装了内置模块urlib3
import requests
res = requests.get('https://www.cnblogs.com/liuqingzheng/p/16005866.html')
print(res.text) # 响应体中的文本内容
print(res.__dict__.keys())
'''
dict_keys([
'_content', '_content_consumed', '_next', 'status_code',
'headers', 'raw', 'url', 'encoding','history',
'reason', 'cookies', 'elapsed',
'request', 'connection'
])
'''
res=requests.get('https://www.baidu.com/s?wd=%E7%BE%8E%E5%A5%B3')
print(res.text)
res = requests.get('https://www.baidu.com/s', params={
'wd': '美女',
'name': 'lqz'
})
print(res.text)
‘美女’被编码后 >>> E7%BE%8E%E5%A5%B3
from urllib import parse
res = parse.quote('美女')
print(res) # E7%BE%8E%E5%A5%B3
res = parse.unquote('%E7%BE%8E%E5%A5%B3')
print(res) # 美女
http请求,有请求头,有些网站就是通过请求头来做反扒
User-Agent:
referer:上次访问的地址
cookie:认证后的cookie,就相当于登录了
header
# header={
# # 客户端类型
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'
# }
# res=requests.get('https://dig.chouti.com/',headers=header)
# print(res.text
# 4 请求中携带cookie#
## 方式一:直接带在请求头中
#模拟点赞
# data={
# 'linkId':'36996038'
# }
# header={
# # 客户端类型
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36',
# #携带cookie
# 'Cookie':'deviceId=web.eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJqaWQiOiI3MzAyZDQ5Yy1mMmUwLTRkZGItOTZlZi1hZGFmZTkwMDBhMTEiLCJleHBpcmUiOiIxNjYxNjU0MjYwNDk4In0.4Y4LLlAEWzBuPRK2_z7mBqz4Tw5h1WeqibvkBG6GM3I; __snaker__id=ozS67xizRqJGq819; YD00000980905869%3AWM_TID=M%2BzgJgGYDW5FVFVAVQbFGXQ654xCRHj8; _9755xjdesxxd_=32; Hm_lvt_03b2668f8e8699e91d479d62bc7630f1=1666756750,1669172745; gdxidpyhxdE=W7WrUDABQTf1nd8a6mtt5TQ1fz0brhRweB%5CEJfQeiU61%5C1WnXIUkZH%2FrE4GnKkGDX767Jhco%2B7xUMCiiSlj4h%2BRqcaNohAkeHsmj3GCp2%2Fcj4HmXsMVPPGClgf5AbhAiztHgnbAz1Xt%5CIW9DMZ6nLg9QSBQbbeJSBiUGK1RxzomMYSU5%3A1669174630494; YD00000980905869%3AWM_NI=OP403nvDkmWQPgvYedeJvYJTN18%2FWgzQ2wM3g3aA3Xov4UKwq1bx3njEg2pVCcbCfP9dl1RnAZm5b9KL2cYY9eA0DkeJo1zfCWViwVZUm303JyNdJVAEOJ1%2FH%2BJFZxYgMVI%3D; YD00000980905869%3AWM_NIKE=9ca17ae2e6ffcda170e2e6ee92bb45a398f8d1b34ab5a88bb7c54e839b8aacc1528bb8ad89d45cb48ae1aac22af0fea7c3b92a8d90fcd1b266b69ca58ed65b94b9babae870a796babac9608eeff8d0d66dba8ffe98d039a5edafa2b254adaafcb6ca7db3efae99b266aa9ba9d3f35e81bdaea4e55cfbbca4d2d1668386a3d6e1338994fe84dc53fbbb8fd1c761a796a1d2f96e81899a8af65e9a8ba3d4b3398aa78285c95e839b81abb4258cf586a7d9749bb983b7cc37e2a3; token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJqaWQiOiJjZHVfNTMyMDcwNzg0NjAiLCJleHBpcmUiOiIxNjcxNzY1NzQ3NjczIn0.50e-ROweqV0uSd3-Og9L7eY5sAemPZOK_hRhmAzsQUk; Hm_lpvt_03b2668f8e8699e91d479d62bc7630f1=1669173865'
# }
# res=requests.post('https://dig.chouti.com/link/vote',data=data,headers=header)
# print(res.text)
## 方式二:通过cookie参数:因为cookie很特殊,一般都需要携带,模块把cookie单独抽取成一个参数,是字典类型,以后可以通过参数传入
data={
'linkId':'36996038'
}
header={
# 客户端类型
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36',
}
res=requests.post('https://dig.chouti.com/link/vote',data=data,headers=header,cookies={'key':'value'})
print(res.text)
# 部署项目出现的可能的问题
-路径问题:ngxin,uwsgi。。。
-数据库用户名密码问题
-前端发送ajax请求问题
-浏览器中访问一下banner接口
-nginx 8080
-安全组 80 8080 3306
-转到uwsgi的8888,视图类
-虚拟环境真实环境都要装uwsgi
-启动uwsgi是在虚拟环境中启动的
###6 发送post请求
# data = {
# 'username': '616564099@qq.com',
# 'password': 'lqz123',
# 'captcha': 'cccc',
# 'remember': 1,
# 'ref': 'http://www.aa7a.cn/',
# 'act': 'act_login'
# }
# res = requests.post('http://www.aa7a.cn/user.php', data=data)
# print(res.text)
# print(res.cookies) # 响应头中得cookie,如果正常登录,这个cookie 就是登录后的cookie RequestsCookieJar:当成字典
#
# # 访问首页,携带cookie,
# # res2 = requests.get('http://www.aa7a.cn/', cookies=res.cookies)
# res2 = requests.get('http://www.aa7a.cn/')
# print('616564099@qq.com' in res2.text)
## 6.2 post请求携带数据 data={} ,json={} drf后端,打印 request.data
# data=字典是使用默认编码格式:urlencoded
# json=字典是使用json 编码格式
# res = requests.post('http://www.aa7a.cn/user.php', json={})
## 6.4 request.session的使用:当request使用,但是它能自动维护cookie
# session=requests.session()
# data = {
# 'username': '616564099@qq.com',
# 'password': 'lqz123',
# 'captcha': 'cccc',
# 'remember': 1,
# 'ref': 'http://www.aa7a.cn/',
# 'act': 'act_login'
# }
# res = session.post('http://www.aa7a.cn/user.php', data=data)
# res2 = session.get('http://www.aa7a.cn/')
# print('616564099@qq.com' in res2.text)
# Response对象,有很多属性和方法
-text
-cookies
import requests
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36',
}
respone = requests.get('https://www.jianshu.com', params={'name': 'lqz', 'age': 19},headers=header)
# respone属性
print(respone.text) # 响应体的文本内容
print(respone.content) # 响应体的二进制内容
print(respone.status_code) # 响应状态码
print(respone.headers) # 响应头
print(respone.cookies) # 响应cookie
print(respone.cookies.get_dict()) # cookieJar对象,获得到真正的字段
print(respone.cookies.items()) # 获得cookie的所有key和value值
print(respone.url) # 请求地址
print(respone.history) # 访问这个地址,可能会重定向,放了它冲定向的地址
print(respone.encoding) # 页面编码
###8 获取二进制数据 :图片,视频
#
# res = requests.get(
# 'https://upload.jianshu.io/admin_banners/web_images/5067/5c739c1fd87cbe1352a16f575d2df32a43bea438.jpg')
# with open('美女.jpg', 'wb') as f:
# f.write(res.content)
# 一段一段写
res=requests.get('https://vd3.bdstatic.com/mda-mk21ctb1n2ke6m6m/sc/cae_h264/1635901956459502309/mda-mk21ctb1n2ke6m6m.mp4')
with open('美女.mp4', 'wb') as f:
for line in res.iter_content():
f.write(line)
# 前后分离后,后端给的数据,都是json格式,
# 解析json格式
res = requests.get(
'https://api.map.baidu.com/place/v2/search?ak=6E823f587c95f0148c19993539b99295®ion=%E4%B8%8A%E6%B5%B7&query=%E8%82%AF%E5%BE%B7%E5%9F%BA&output=json')
print(res.text)
print(type(res.text))
print(res.json()['results'][0]['name'])
print(type(res.json()))
前言程序使用一段时间后会遇到HTTPError403:Forbidden错误。因为在短时间内直接使用Get获取大量数据,会被服务器认为在对它进行攻击,所以拒绝我们的请求,自动把电脑IP封了。解决这个问题有两种方法。一是将请求加以包装,变成浏览器请求模式,而不再是“赤裸裸”的请求。但有时服务器是根据同一IP的请求频率来判断的,即使伪装成不同浏览器。由于是同一IP访问,还是会被封。所以就有了第二种方法,就是降低请求频率。具体说来也有两种方法。一种是在每次请求时暂停短暂时间,从而降低请求频率。第二种是使用不同的IP进行访问。显然第一种方法不是最佳选择。因为我们并不希望下载太慢,尤其是在请求次数很多时
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。您对使用Ruby编写网络爬虫有何建议?有比mechanize更好的库吗?
大家好,我是辣条。现在短视频可谓是一骑绝尘,吃饭的时候、休息的时候、躺在床上都在刷短视频,今天给大家带来python爬虫进阶:美拍视频地址加密解析。短视频js逆向解析抓取目标工具使用重点学习内容项目思路解析抓取目标目标网址:美拍视频工具使用开发环境:win10、python3.7开发工具:pycharm、Chrome工具包:requests、xpath、base64重点学习内容爬虫采集数据的解析过程js代码调试技巧js逆向解析代码Python代码的转换项目思路解析进入到网站的首页挑选你感兴趣的分类根据首页地址获取到进入详情页面的超链接的跳转地址找到对应加密的视频播放地址数据这个数据是静态的网页
本代码详情及用法已上传到Github上:https://github.com/edisonwong520/zhihuSpider如果觉得有用的,欢迎Star收藏,感谢~本人菜鸟一名,闲来无事写来玩玩,有问题请多多指教~Github个人主页主页上还有别的一些小工具~介绍知乎爬虫:爬指定问题的所有答案(包括点赞数、图片数、评论数),以及每一个答案下的精选评论、普通评论Awebspiderwhichcangrepalltheanswers,commentsandthumbupnumbersetc…ofaspecificquestioninZhihu.仅供学习交流,严禁用于商业用途,请于24小时内删除
本篇文章给大家谈谈抖音开放api接口,以及抖音开放api接口对应的知识点,希望对各位有所帮助,不要忘了收藏本文章喔。当用户打开抖音,在默认推荐页中,就会被推送到带有POI链接的视频。这类视频通常分为两类。一、商户POI的打卡类视频第一种是标记有点击POI链接跳转至商户的POI聚合页。(注意,这里跳转的并不是商户的企业号页面。)如图:二、城市类视频第二种包含POI信息的视频为“城市类”视频,点击POI则会进入城市的聚合页。在城市聚合页中,除抖音开放api接口poi了大量的基于POI所聚合的视频外,系统还会为用户推荐当地商户,包括:必体验、吃什么、玩什么、住哪里四大类。item_get获得抖音商
我正在阅读thisspecification这是网络服务器和搜索引擎爬虫之间的协议(protocol),允许动态创建的内容对爬虫可见。那里指出,为了让爬虫索引html5应用程序,必须在URL中使用#!实现路由。在Angularhtml5mode(true)中,我们去掉了URL的散列部分。我想知道这是否会阻止抓取工具将我的网站编入索引。 最佳答案 简短回答-不,html5mode不会弄乱您的索引,但请继续阅读。重要说明:Google和Bing都可以在没有HTML快照的情况下抓取基于AJAX的内容我知道,您链接到的文档另有说明,但大约一
前言爬虫获取m3u8视频资源的步骤目前所要作的流程处理先把m3u8里下载链接批量提取.png把这几百个切片链接先批量下载.png再批量改文件后缀为.ts再按照m3u8文件提取所有不规则链接文件的【顺序】.png然后改切片的文件名为0001,0002,0003......顺序.png然后用ffmpeg或者moviepy或者其他工具合并就行.png看起来也没有那么麻烦…(流汗黄豆)开始操作目前已有材料:爬下来的网页源码和从中获取的m3u8文件把.m3u8改成.txt格式便于操作批量正则提取和下载写脚本从原来的m3u8文件中正则表达提取出所有干净的下载链接,将其放到另外一个.txt文件;并且从中下载
当一个从未接触过多线程程序的PHP开发人员开始学习golang和channel时,可能会发生这种情况。我正在进行围棋之旅的最后一个练习,[Exercise:WebCrawler](在此之前,我对其他练习没有任何问题)虽然我正在尝试编写尽可能简单的代码,我的Crawl方法如下所示:funcCrawl(urlstring,depthint,fetcherFetcher){//kickoffcrawlingbypassinginitialUrltoaJobqueueQueuegorun说我不应该写任何go代码然后返回PHP:fatalerror:allgoroutinesareasleep-
我构建了一个网络爬虫,提供一些有关其发现的http信息。爬虫作为goroutine运行,martini运行web服务器。过了一会儿,我开始得到2014/08/0110:23:51http:Accepterror:accepttcp[::]:3000:toomanyopenfiles;retryingin1s.我读到我应该尝试增加最大打开文件数我只是这个配置级别的新手并且不知道如何做到这一点。我在Ubuntu14.04上运行它。请问如何更改martini服务器的最大打开文件数,谢谢。 最佳答案 确保不要忘记关闭从http.Get获得的
前言 前短时间,为了验证公司的验证码功能存在安全漏洞,写了一个爬虫程序抓取官网图库,然后通过二值分析,破解验证码进入系统刷单。其中,整个环节里关键的第一步就是拿到数据--Python爬虫技。 今天,我打算把爬虫经验分享一下,因为不能泄露公司核心信息,所以我随便找了一个第三方网站——《懂车帝》做演示。为了展示Selenium效果,网站需满足:需要动态加载(下拉)才能获取完整(或更多)数据的网页,如:淘宝,京东,拼多多的商品也都可以。 通过本篇,你将学会通过Selenium自动化加载HTML的技巧,并利用BeautifulSoup解析静态的HTML页面,还有使用xlwt插