2023 年 3 月 12 日,Flink Table Store 项目顺利通过投票,正式进入 Apache 软件基金会 (ASF) 的孵化器,改名为 Apache Paimon (incubating)。
随着 Apache Flink 技术社区的不断成熟和发展,越来越多企业开始利用 Flink 进行流式数据处理,从而提升数据时效性价值,获取业务实时化效果。与此同时,在大数据领域数据湖架构也日益成为新的技术趋势,越来越多企业开始采用 Lakehouse 架构,基于 DataLake 构建新一代 Data Warehouse。因此,Flink 社区希望能够将 Flink 的 Streaming 实时计算能力和 Lakehouse 新架构优势进一步结合,推出新一代的 Streaming Lakehouse 技术,促进数据在数据湖上真正实时流动起来,并为用户提供实时离线一体化的开发体验。
但目前业界主流数据湖存储格式项目都是面向 Batch 场景设计的,在数据更新处理时效性上无法满足 Streaming Lakehouse 的需求,因此 Flink 社区在一年多前内部孵化了 Flink Table Store (简称 FTS )子项目,一个真正面向 Streaming 以及 Realtime 的数据湖存储项目, 截止目前已经发布了 3 个版本,并得到了大量用户的积极反馈和多家公司的积极贡献。为了让 Flink Table Store 能够有更大的发展空间和生态体系,Flink PMC 经过讨论决定将其捐赠 ASF 进行独立孵化。
截止目前,包括 阿里云,字节跳动、Confluent、同程旅行、Bilibili 等多家公司参与到 Apache Paimon 的贡献,未来希望能够有更多对新一代流式数据湖存储感兴趣的开发者加入 Paimon 社区,一起打造新一代的流式湖仓新架构。
Apache Paimon (incubating) 是一项流式数据湖存储技术,可以为用户提供高吞吐、低延迟的数据摄入、流式订阅以及实时查询能力。Paimon 采用开放的数据格式和技术理念,可以与 Apache Flink / Spark / Trino 等诸多业界主流计算引擎进行对接,共同推进 Streaming Lakehouse 架构的普及和发展。
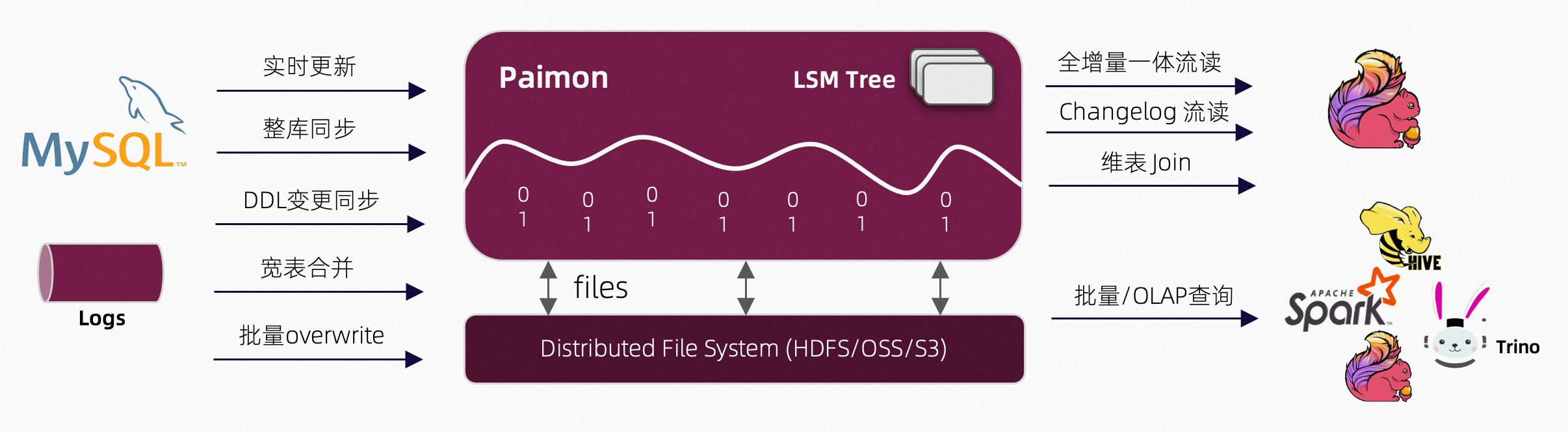
Paimon 以湖存储的方式基于分布式文件系统管理元数据,并采用开放的 ORC、Parquet、Avro 文件格式,支持各大主流计算引擎,包括 Flink、Spark、Hive、Trino、Presto。未来会对接更多引擎,包括 Doris 和 Starrocks。
得益于 LSM 数据结构的追加写能力,Paimon 在大规模的更新数据输入的场景中提供了出色的性能。
Paimon 创新的结合了 湖存储 + LSM + 列式格式 (ORC, Parquet),为湖存储带来大规模实时更新能力,Paimon 的 LSM 的文件组织结构如下:
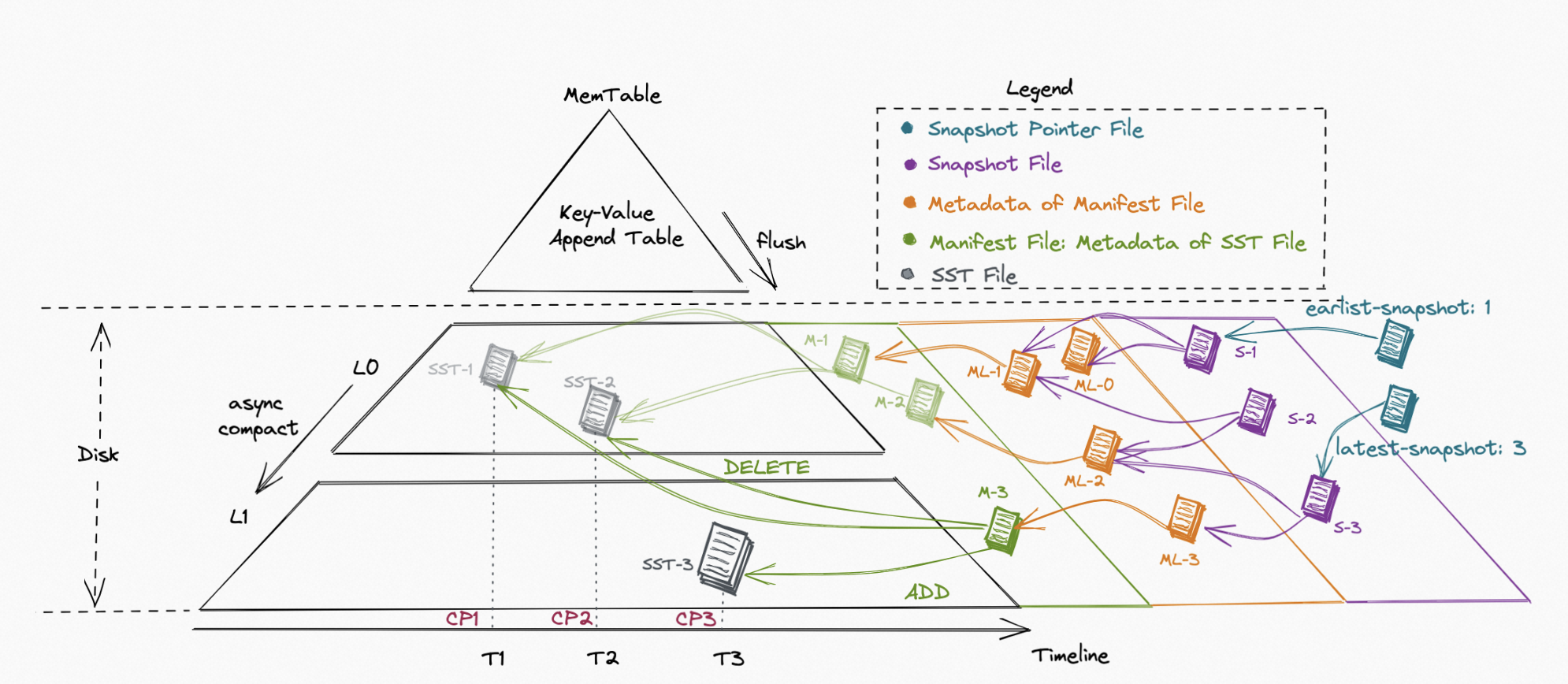
在最新的版本中,Paimon 集成了 Flink CDC,通过 Flink DataStream 提供了两个核心能力:
通过与 Flink CDC 的整合,Paimon 可以让的业务数据简单高效的流入数据湖中。
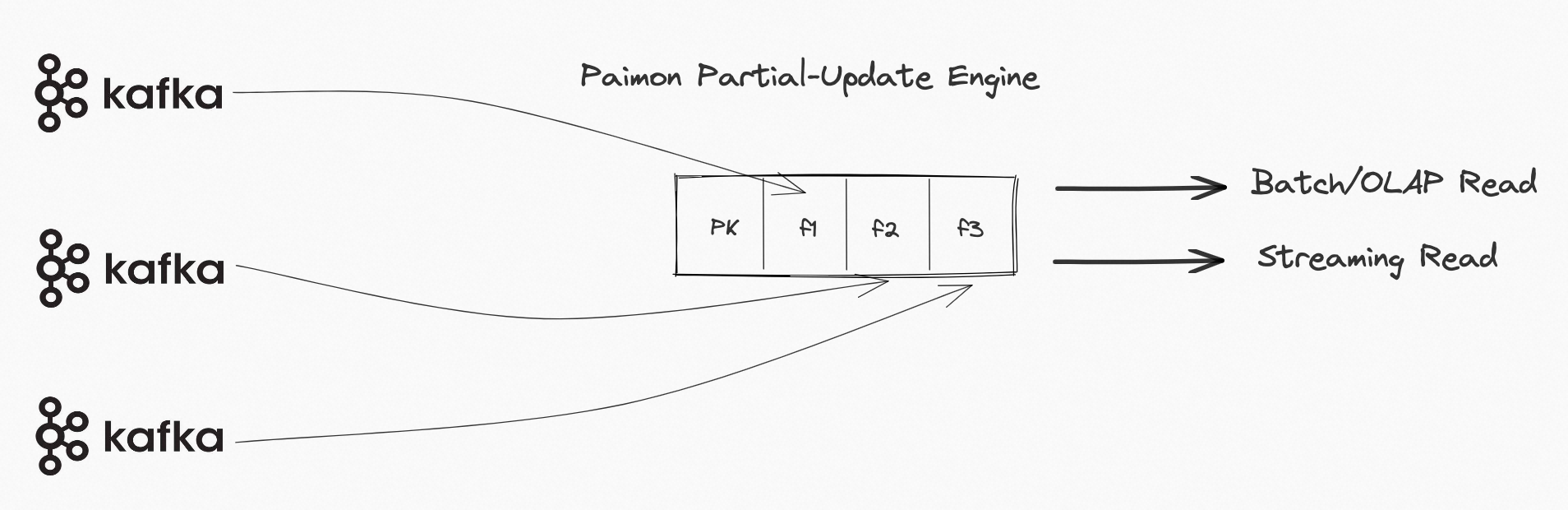
在数据仓库的业务场景下,经常会用到宽表数据模型,宽表模型通常是指将业务主体相关的指标、维表、属性关联在一起的模型表,也可以泛指将多个事实表和多个维度表相关联到一起形成的宽表。
Paimon 的 Partial-Update 合并引擎可以根据相同的主键实时合并多条流,形成 Paimon 的一张大宽表,依靠 LSM 的延迟 Compaction 机制,以较低的成本完成合并。合并后的表可以提供批读和流读:
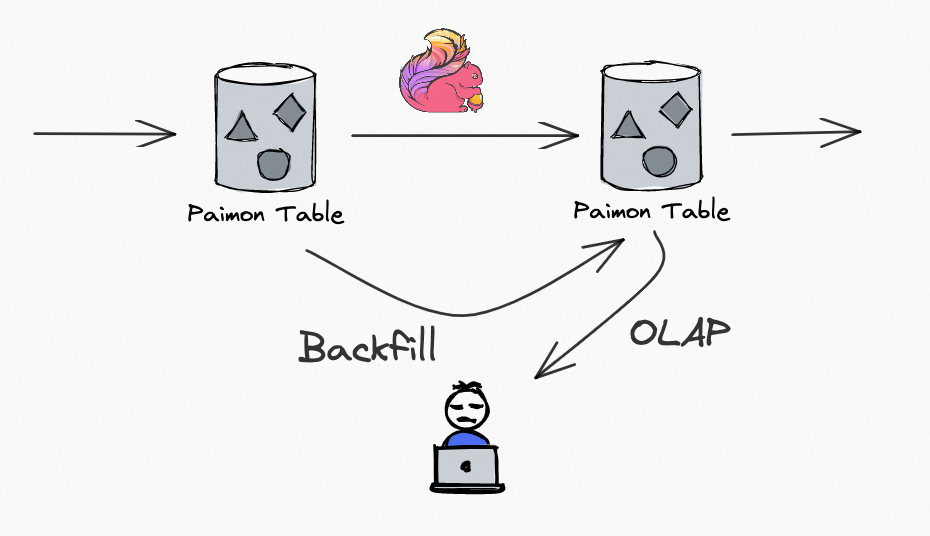
Paimon 作为一个流批一体的数据湖存储,提供流写流读、批写批读,你使用 Paimon 来构建 Streaming Pipeline,并且数据沉淀到存储中。
在 Flink Streaming 作业实时更新的同时,可以 OLAP 查询各个 Paimon 表的历史和实时数据,并且也可以通过 Batch SQL,对之前的分区 Backfill,批读批写。
不管输入如何更新,或者业务要求如何合并 (比如 partial-update),使用 Paimon 的 Changelog 生成功能,总是能够在流读时获取完全正确的变更日志。
当面对主键表时,为什么你需要完整的 Changelog:
你可以使用 Lookup 来实时生成 Changelog:
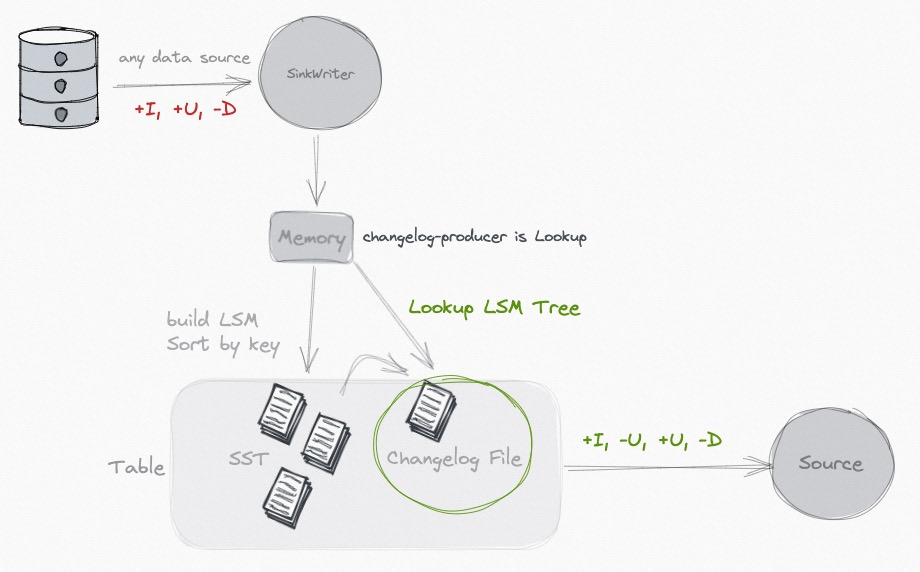
如果你觉得成本过大,你也可以解耦 Commit 和 Changelog 生成,通过 Full-Compaction 和对应较大的时延,以非常低的成本生成 Changelog。
Flink Table Store 已经发布了三个版本,我们计划在 4 月份发布 Paimon 0.4 版本,请您保持对 Paimon 的关注。
Paimon 将长期投入实时性、生态和数仓完整性的研发上,构建更好的 Streaming LakeHouse。
如果您有其他需求,请联系我们。
作者简介:王峰 (莫问) Apache Flink 中文社区发起人、阿里巴巴开源大数据平台负责人,PPMC Member of Apache Paimon
李劲松 (之信) 阿里巴巴开源大数据表存储负责人,Founder of Apache Paimon, PMC Member of Apache Flink
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
最近,当我启动我的Rails服务器时,我收到了一长串警告。虽然它不影响我的应用程序,但我想知道如何解决这些警告。我的估计是imagemagick以某种方式被调用了两次?当我在警告前后检查我的git日志时。我想知道如何解决这个问题。-bcrypt-ruby(3.1.2)-better_errors(1.0.1)+bcrypt(3.1.7)+bcrypt-ruby(3.1.5)-bcrypt(>=3.1.3)+better_errors(1.1.0)bcrypt和imagemagick有关系吗?/Users/rbchris/.rbenv/versions/2.0.0-p247/lib/ru
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
说在前面这部分我本来是合为一篇来写的,因为目的是一样的,都是通过独立按键来控制LED闪灭本质上是起到开关的作用,即调用函数和中断函数。但是写一篇太累了,我还是决定分为两篇写,这篇是调用函数篇。在本篇中你主要看到这些东西!!!1.调用函数的方法(主要讲语法和格式)2.独立按键如何控制LED亮灭3.程序中的一些细节(软件消抖等)1.调用函数的方法思路还是比较清晰地,就是通过按下按键来控制LED闪灭,即每按下一次,LED取反一次。重要的是,把按键与LED联系在一起。我打算用K1来作为开关,看了一下开发板原理图,K1连接的是单片机的P31口,当按下K1时,P31是与GND相连的,也就是说,当我按下去时
我想用Capistrano启动sidekiq。下面是代码namespace:sidekiqdotask:startdorun"cd#{current_path}&&bundleexecsidekiq-c10-eproduction-Llog/sidekiq.log&"pcapture("psaux|grepsidekiq|awk'{print$2}'|sed-n1p").strip!endend它执行成功但sidekiq仍然没有在服务器上启动。输出:$capsidekiq:starttriggeringloadcallbacks*2014-06-0315:03:01executing`
我有一个正在升级到Rails3的Rails2.3.5应用程序。我做了所有我需要做的升级以及当我使用启动Rails服务器时要做的事情railsserver它给了我这个PleaseswitchtoRuby1.9'sstandardCSVlibrary.It'sFasterCSVplussupportforRuby1.9'sm17nencodingengine.我正在使用ruby-1.9.2-p0并安装了fastercsv(1.5.3)gem。在puts语句的帮助下,我能够追踪到错误发生的位置。我发现执行在这一行停止了Bundler.require(:default,Rails.env)if
电脑启动出现显示器黑屏是一个相当常见的问题。如果您遇到了这个问题,不要惊慌,因为它有很多可能的原因,可以采取一些简单的措施来解决它。在本文中,小编将介绍下面4种常见的电脑启动后显示器黑屏的原因,排查这些原因,快速解决! 演示机型:联想Ideapad700-15ISK-ISE系统版本:Windows10一、显示器问题如果出现电脑启动后显示器黑屏的情况。那么首先您需要检查一下显示器是否正常工作。您可以通过更换另一个显示器或将当前显示器连接到另一台计算机来检查显示器是否存在问题。如果问题仍然存在,那么您可以排除显示器故障的可能性。 二、显卡问题如果您的电脑配备了独立显卡,那么显卡故障也可能是导致电脑
plsql连接Oracle超时,完犊子了肯定是服务器断电了。得马上检查Oracle服务器状态1、检查数据库是否启动su-oracle切换到Oracle用户,输入sqlplus/assysdba显示连接状态。如果末尾显示的状态是Connectedtoanidleinstance.证明未启动2、启动数据库startup启动数据库,末尾出现Databaseopened说明数据库启动成功3、查看数据库监听是否正常先quit;断开Oracle连接,使用lsnrctlstatus查看监听状态,如果出现TNS-开头的Nolistener、Connectionrefused等错误,说明监听未启动4、启动数据库
当Rails启动时,它会预加载所有依赖项(gems),这会导致启动时间非常缓慢。在我正在处理的一个中型项目中,Rails的启动时间为10-15秒,具体取决于机器。虽然这在生产中不是问题,但在开发中却是一个巨大的痛苦。特别是在工作TDD/BDD时。有加速测试的解决方案(如spork),但它们会引入自己的问题。我的问题是:为什么不在每个代码文件中要求所需的依赖项,而不是在启动时预加载所有内容?手动要求的缺点是什么?额外的代码行? 最佳答案 Rails不是PHP。一些资源是自动加载的,但是您可能需要的所有资源都在启动/初始化时加载,因为最
我有一个作为守护程序运行的Sinatra应用程序,使用Apache端口转发在端口80和端口7655之间进行调解。这在过去一直运行良好。今天,不太好。我不明白为什么。问题:sudorubymy_process.rb返回:/var/lib/gems/1.9.1/gems/eventmachine-1.0.0/lib/eventmachine.rb:526:in`start_tcp_server':noacceptor(portisinuseorrequiresrootprivileges)(RuntimeError)尝试过:更新所有系统包,更新所有gem。没有帮助(除了来自eventm