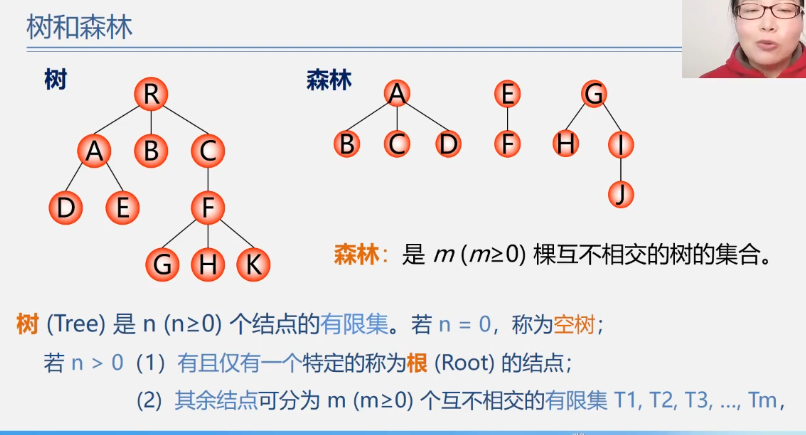
双亲表示法
实现:定义结构数组,存放树的结点,每个结点含两个域
特点:找双亲容易,找孩子难。
C语言的类型描述:
typedef struct PTNode{
TElemType data;
int parent;//双亲位置域
}PTNode;
/*树的结构*/
#define MAX_TREE_SIZE 100
typedef struct{
PTNode nodes[MAX_TREE_SIZE];
int r,n; //根结点的位置和结点数
}
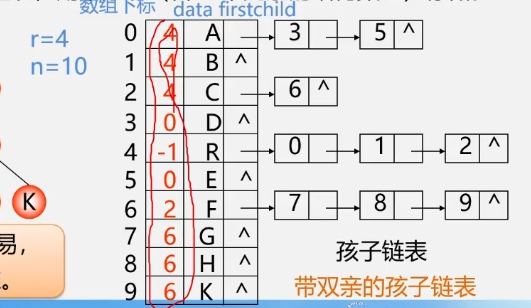
孩子链表法
实现:把每个结点的孩子结点排列起来,看成是一个线性表,用单链表存储,则n个结点有n个孩子链表(叶子的孩子链表为空)。而n个头指针又组成一个线性表,用顺序表(含n个元素的结构数组)存储。
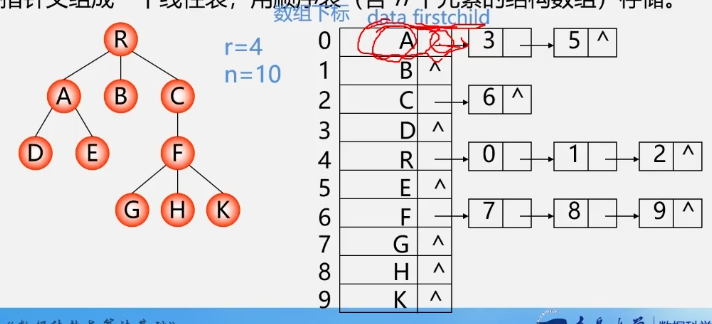

C语言的类型描述:
#define MAX_TREE_SIZE 100
typedef struct CTNode{
int child
struct CTNode *next;
}*ChildPtr;
typedef struct{
TElemType data;
ChildPtr firstchild;//孩子链表头指针
}CTBox;
/*树结构*/
typedef struct{
CTBox nodes[#define MAX_TREE_SIZE];
int n,r;//根结点的位置和结点数
}CTree;
特点:找孩子容易,找双亲难。
可以添加一个属性。
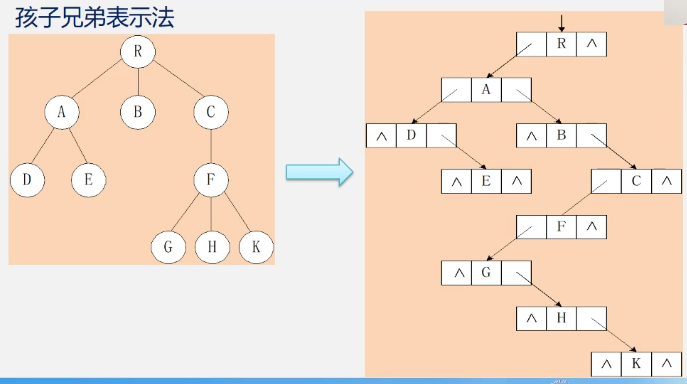
孩子兄弟表示法(二叉树表示法,二叉链表表示法)
实现:用二叉链表作树的存储结构,链表中每一个结点的两个指针域分别指向其第一个孩子结点和下一个兄弟结点。
C语言类型描述:
typedef struct CSNode{
ElemType data;
struct CSNode *firstchild,*nextsibing;
}CSNode,*CSTree;
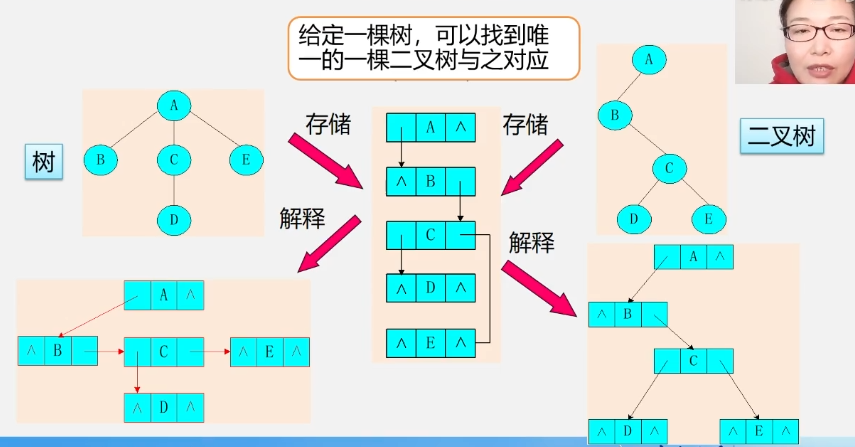
由于树和二叉树都可以用二叉链表作为存储结构,则以二叉链表作媒介可以导出树与二叉树之间的一个对应关系。
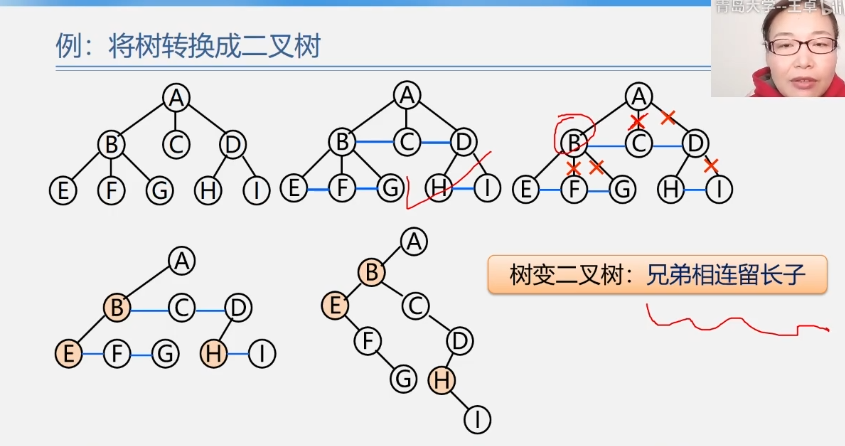
将树转换成二叉树
加线:在兄弟之间加一条线;
抹线:对每一个结点,除了其左孩子外,去除其与其余孩子之间的关系;
旋转:以树的根结点为轴心,将整树顺时针转45度;
树变二叉树:兄弟相连留长子
将二叉树转换成树
加线:若p结点是双亲结点的左孩子,则将p的右孩子,右孩子的右孩子……沿分支找到的所有右孩子,都与p的双亲用线连起来;
抹线:抹掉原二叉树中双亲与右孩子之间的连线;
调整:将结点按层次排列,形成树结构;
二叉树变树:左孩右右连双亲,去掉原来右孩线。
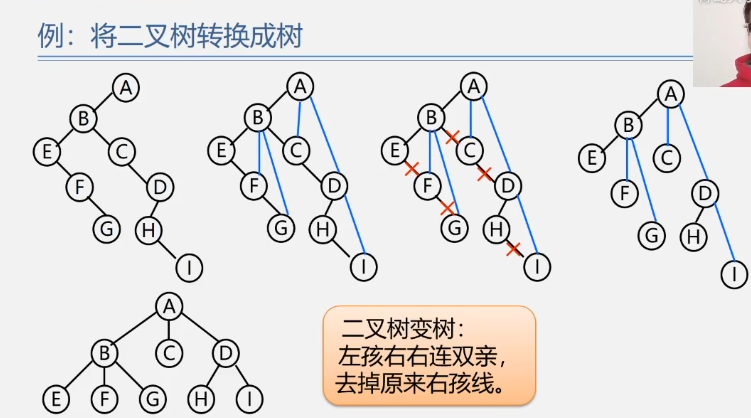
森林转换成二叉树(二叉树与多棵树之间的关系)
将各棵树分别转换成二叉树;
将每棵树的根结点用线相连;
以第一颗树根结点为二叉树的根,再以根结点为轴心,顺时针旋转,构成二叉树型结构;
森林变二叉树:树变二叉根相连。
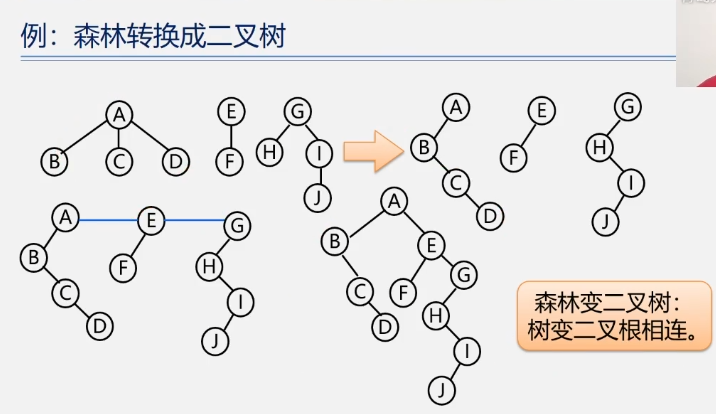
二叉树转换成森林
抹线:将二叉树中根结点与其右孩子的连线,及沿右分支搜索到的所有右孩子间连线全部抹掉,使之变成孤立的二叉树;
还原:将孤立的二叉树还原成树;
二叉树变森林:去掉全部右孩线,孤立二叉再还原。
树的遍历(三种方式)
先根(次序)遍历:
若树不空,则先访问根结点,然后依次先根遍历各棵子树。
后根(次序)遍历:
若树不空,先依次后根遍历各棵子树,然后访问根结点。
按层次遍历:
若树不空,则自上而下自左至右访问树中每一个结点。

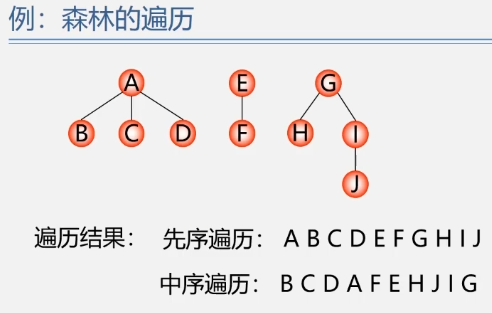
森林的遍历
将森林看作由三部分构成:
森林中第一棵树的根结点;
森林中第一棵树的子树森林;
森林中其它树构成的森林;
先序遍历:
若森林不空,则:
即:依次从左至右对森林中的每一棵树进行先根遍历。
中序遍历:
若森林不空,则:
即:依次从左至右对森林中的每一棵树进行后根遍历。
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。要求我们推荐或查找工具、库或最喜欢的场外资源的问题对于StackOverflow来说是偏离主题的,因为它们往往会吸引自以为是的答案和垃圾邮件。相反,describetheproblem以及迄今为止为解决该问题所做的工作。关闭9年前。Improvethisquestion我很难找到在ruby中使用的树数据结构。我可以研究一些众所周知的吗?我的要求很简单。我想创建一棵树(或者可能是一个图)并找到一些节点之间的距离。例如,我可能有一个像下面这样的树/图A/\B-----C/\\DEF我希望能够找到根节点
随机森林1.使用Boston数据集进行随机森林模型构建2.数据集划分3.构建自变量与因变量之间的公式4.模型训练5.寻找合适的ntree6.查看变量重要性并绘图展示7.偏依赖图:PartialDependencePlot(PDP图)8.训练集预测结果1.使用Boston数据集进行随机森林模型构建library(rio)library(ggplot2)library(magrittr)library(randomForest)library(tidyverse)library(skimr)library(DataExplorer)library(caret)library(varSelRF)li
感谢此站点上聪明人的帮助,我现在在我的模块中有一个很好的One2many字段,它允许我添加多个订单行,就像在销售模块中一样。它工作得很好,但现在为了方便起见,我希望能够在我的树和日历View中看到One2many字段中的某个字段。但是,当我尝试使用下面描述的方法显示该字段时,我得到的只是记录数。特别是,我希望它显示添加到订单行的所有产品。相关代码如下:模型.py#-*-coding:utf-8-*-fromodooimportmodels,fields,apifromodoo.addonsimportdecimal_precisionasdpclassmymodule_base(mod
参考书目:深入浅出Python量化交易实战在机器学习里面的X叫做特征变量,在统计学里面叫做协变量也叫自变量,在量化投资里面则叫做因子,所谓多因子就是有很多的特征变量。本次带来的就是多因子模型,并且使用的是机器学习的强大的非线性模型,集成学习里面的随机森林和LGBM模型,带来因子的选择策略和股票的选择策略。由于股票数据的获取都需要第三方库或者是专业的量化投资框架,很多第三方库某些功能需要收费(Tushare),而免费的一些库(证券宝)获取的数据特征变量又没那么多。所以这里是用聚宽量化投资框架,是可以免费使用一些功能的(只需要注册一个账号)。这里获取数据就采用聚宽平台的功能了。数据获取本次使用
随机森林模型介绍:随机森林模型不仅在预测问题上有着广泛的应用,在特征选择中也有常用。随机森林是以决策树为基学习器的集成学习算法。随机森林非常简单,易于实现,计算开销也很小,更令人惊奇的是它在分类和回归上表现出了十分惊人的性能。随机森林模型在拟合数据后,会对数据属性列,有一个变量重要性的度量,在sklearn中即为随机森林模型的feature_importances_参数,这个参数返回一个numpy数组对象,对应为随机森林模型认为训练特征的重要程度,float类型,和为1,特征重要性度数组中,数值越大的属性列对于预测的准确性更加重要。随机森林(RF)简介:只要了解决策树的算法,那么随机森林是相当
作者:韩信子@ShowMeAI教程地址:https://www.showmeai.tech/tutorials/34本文地址:https://www.showmeai.tech/article-detail/191声明:版权所有,转载请联系平台与作者并注明出处引言随机森林是一种由决策树构成的(并行)集成算法,属于Bagging类型,通过组合多个弱分类器,最终结果通过投票或取均值,使得整体模型的结果具有较高的精确度和泛化性能,同时也有很好的稳定性,广泛应用在各种业务场景中。随机森林有如此优良的表现,主要归功于「随机」和「森林」,一个使它具有抗过拟合能力,一个使它更加精准。我们会在下文中做更详细的
目录序言 1. 树概念及结构1.1 树的概念1.2树的相关概念1.3树的表示1.4树在实际中的运用(表示文件系统的目录树结构)2. 二叉树概念及结构2.1 概念2.2 现实中的二叉树2.3 数据结构中的二叉树2.4 特殊的二叉树2.5二叉树的存储结构2.6 二叉树的性质2.7 二叉树的存储结构2.7.1 顺序存储2.7.2 链式存储 3. 二叉树的顺序结构及实现3.1二叉树的顺序结构4. 二叉树链式结构的实现4.1 二叉树链式结构的遍历 序言 hello✨,大家好呀,这里是原来💖💛💙,随着文章篇幅越来越多可能有很多小伙伴们找不到自己想要看的文章,所以我就出来啦,下面附带各文章链接哈。
我实现了一种实验性OOP语言,现在使用Storagebenchmark对垃圾收集进行基准测试.现在我想检查/打印以下小深度基准(n=2、3、4、..)。树(有4个子节点的森林)由buildTreeDepth方法生成。代码如下:importjava.util.Arrays;publicfinalclassStorageSimple{privateintcount;privateintseed=74755;publicintrandomNext(){seed=((seed*1309)+13849)&65535;returnseed;}privateObjectbuildTreeDepth(
?♂️个人主页:@艾派森的个人主页✍?作者简介:Python学习者?希望大家多多支持,我们一起进步!?如果文章对你有帮助的话,欢迎评论?点赞??收藏?加关注+目录1.项目背景2.项目简介2.1研究目的及意义
IBMSPSS产品系列最主要的两款软件为IBMSPSSStatistics和IBMSPSSModeler。IBMSPSSStatistics主要用于统计分析,如均值比较、方差分析、相关分析、回归分析、聚类分析、因子分析、非参数检验等等。一般应用于数据量较小的分析,比如在学校的时候用的多,一般直接录入数据或导入Excel数据进行分析。IBMSPSSModeler主要用于数据挖掘,比如各种、各种决策树算法、神经网络算法、贝叶斯算法等等。目的就是通过对数据的整理、建模,挖掘出相关结果,指导管理实际。主要应用于数据量大的分析,或者连接至数据库进行分析。今天主要介绍使用IBMSPSSModeler进行随