文章目录
在实际Python项目开发中,不同的项目可能需要导入的第三方库不一样,所以我们对每个不同需求的项目都建立一个对应的虚拟环境很有必要。而且如果每个项目都有自己的环境,我们在用Pyinstaller把项目脚本打包成.exe可执行文件时可以大大缩小.exe文件的占用内存大小,同时也便于我们管理各个环境,使它们之间相互不受影响,不至于我们反复重装Anaconda和配置环境变量。
#创建名为env_name的虚拟环境,不指定Python版本(默认安装最新版本的Python)
conda create -n env_name
#创建名为env_name的虚拟环境,并指定Python版本为3.6.5
conda create -n env_name python=3.6.5
conda create -n py383 python=3.8.3
win + R,输入cmd,并按Enter
在打开的命令行窗口中输入conda create -n py383 python=3.8.3,并按Enter
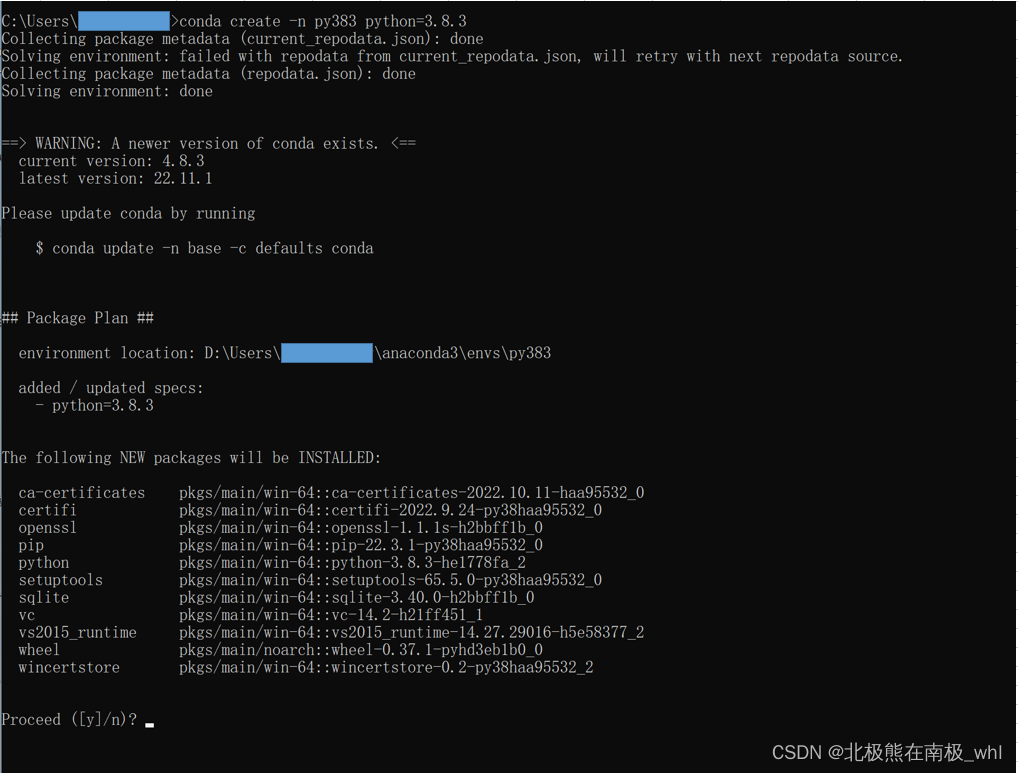
输入y,并按Enter

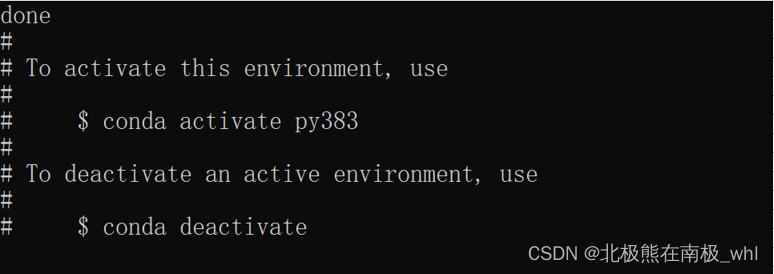
安装成功后如下图所示:
conda安装包路径是:
xxxxxx\Anaconda3\pkgs
pip安装包路径在虚拟环境下是:
xxxxxx\Anaconda3\envs\env_name\Lib\site-packages
(1)由于conda默认安装的包的位置在xxxxxx\Anaconda3\pkgs,所以所有的虚拟环境所需要的包都安装在这个路径下,且每种类型的python包只安装一次,即有可能多个虚拟环境共享同一个包。
(2)而pip在某个虚拟环境(env_name)下的默认安装路径是xxxxxx\Anaconda3\envs\env_name\Lib\site-packages,即每个虚拟环境所需要的包都单独安装在每个虚拟环境的目录下,即使该python包在其他虚拟环境下安装过,也会在当前虚拟环境中再安装一次,也就是说每个虚拟环境需要的python包互不干扰,没有联系。
(1)conda:
conda install --channel https://pypi.tuna.tsinghua.edu.cn/simple package=version
(2)pip:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple package==version
阿里云:
http://mirrors.aliyun.com/pypi/simple
中国科学技术大学:
https://pypi.mirrors.ustc.edu.cn/simple
豆瓣:
http://pypi.douban.com/simple
清华大学:
https://pypi.tuna.tsinghua.edu.cn/simple
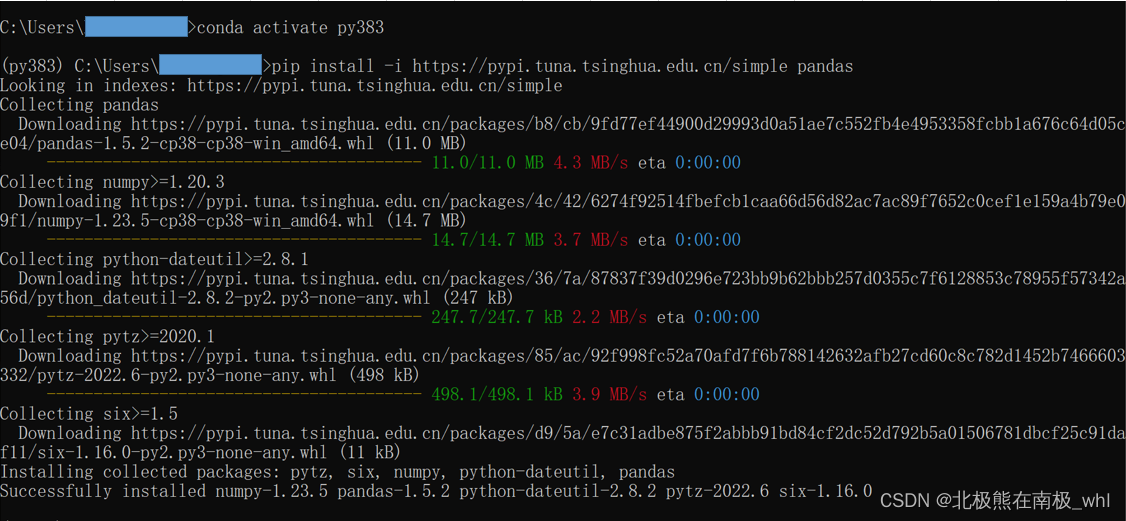
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas
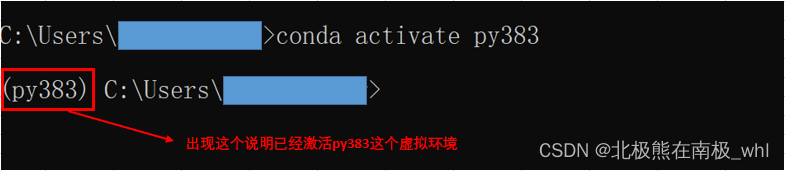
安装之前需要先激活虚拟环境,使用conda activate env_name(其中env_name为要激活的虚拟环境的名字,以py383为例)
在py383虚拟环境下安装pandas,如下:
conda activate py383
conda deactivate

注意要想删除某个虚拟环境,进行删除操作之前必须将其关闭
conda remove -n py383 --all 或者conda remove --name py383 --all
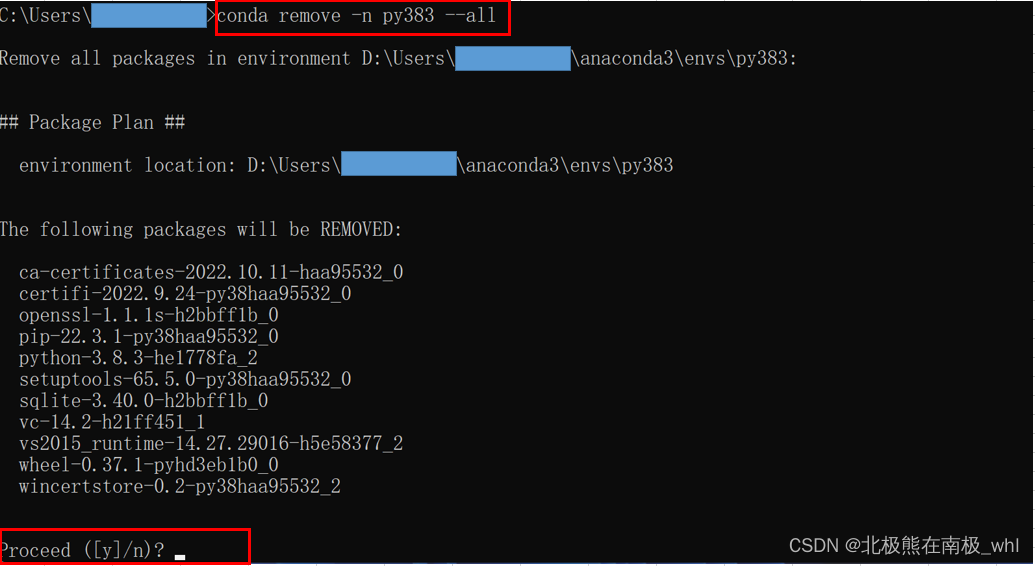
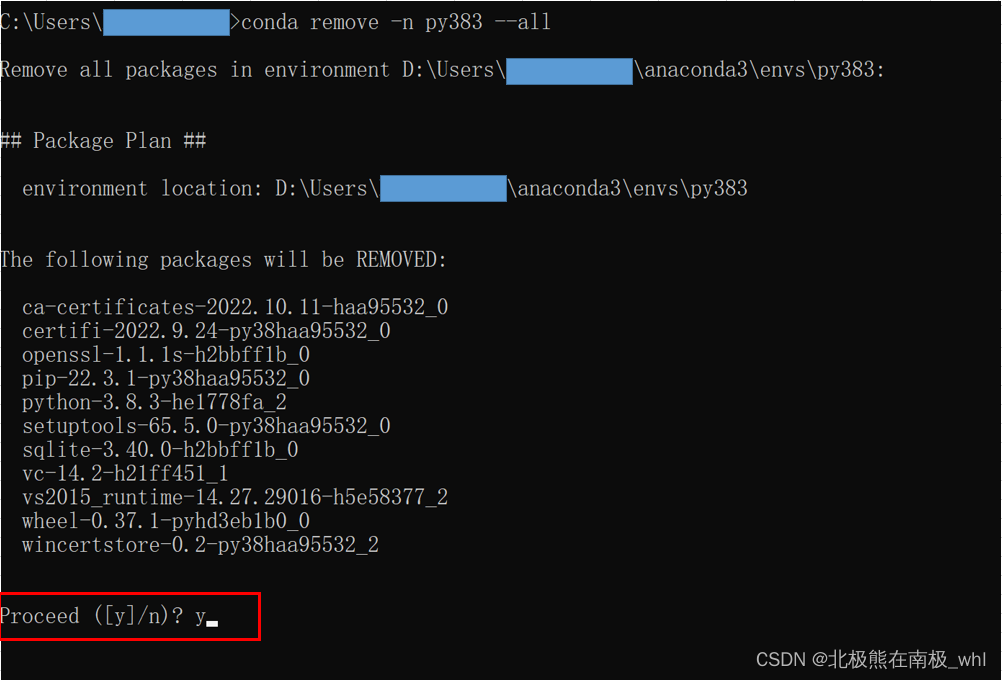
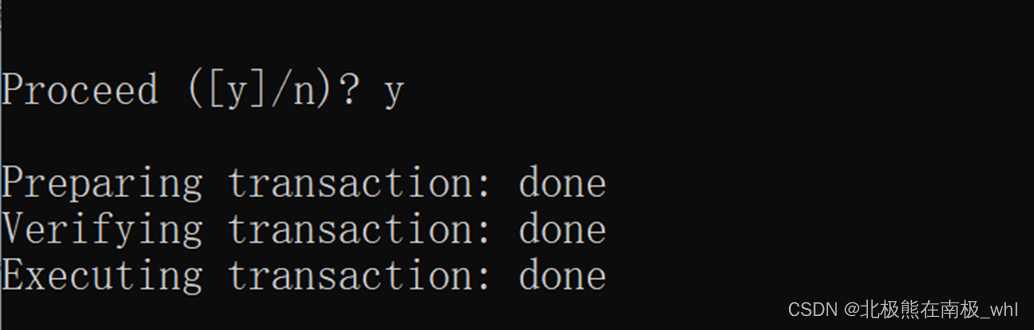
输入y,并按Enter,如下图:
conda --version或者conda -V

pip --version或者pip -V

conda env list或者conda info --envs
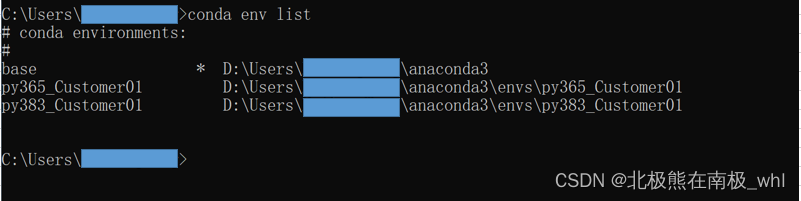
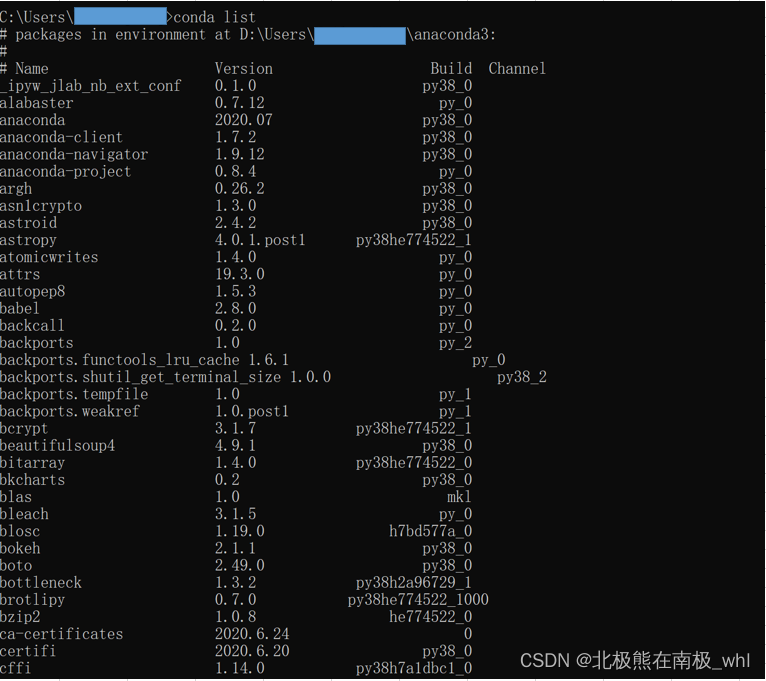
conda list
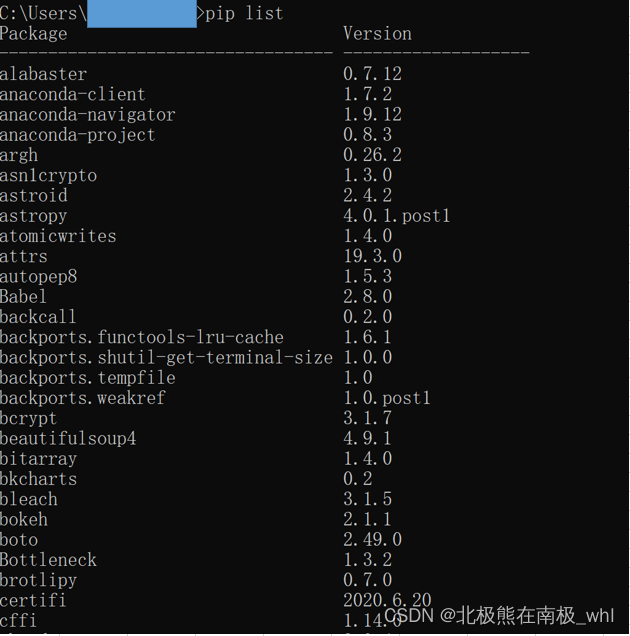
pip list
本文主要通过一些windows下的cmd命令行模式讲解了Anaconda创建虚拟环境的一些命令,以及常用的conda和pip命令等;并用一些实例操纵演示这些命令的使用方式,希望通过这篇博文的讲解,能够对初学者有所帮助,本人才疏学浅,欢迎批评指定,谢谢!
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
出于纯粹的兴趣,我很好奇如何按顺序创建PI,而不是在过程结果之后生成数字,而是让数字在过程本身生成时显示。如果是这种情况,那么数字可以自行产生,我可以对以前看到的数字实现垃圾收集,从而创建一个无限系列。结果只是在Pi系列之后每秒生成一个数字。这是我通过互联网筛选的结果:这是流行的计算机友好算法,类机器算法:defarccot(x,unity)xpow=unity/xn=1sign=1sum=0loopdoterm=xpow/nbreakifterm==0sum+=sign*(xpow/n)xpow/=x*xn+=2sign=-signendsumenddefcalc_pi(digits
我正在尝试设置一个puppet节点,但rubygems似乎不正常。如果我通过它自己的二进制文件(/usr/lib/ruby/gems/1.8/gems/facter-1.5.8/bin/facter)在cli上运行facter,它工作正常,但如果我通过由rubygems(/usr/bin/facter)安装的二进制文件,它抛出:/usr/lib/ruby/1.8/facter/uptime.rb:11:undefinedmethod`get_uptime'forFacter::Util::Uptime:Module(NoMethodError)from/usr/lib/ruby
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我想了解Ruby方法methods()是如何工作的。我尝试使用“ruby方法”在Google上搜索,但这不是我需要的。我也看过ruby-doc.org,但我没有找到这种方法。你能详细解释一下它是如何工作的或者给我一个链接吗?更新我用methods()方法做了实验,得到了这样的结果:'labrat'代码classFirstdeffirst_instance_mymethodenddefself.first_class_mymethodendendclassSecond使用类#returnsavailablemethodslistforclassandancestorsputsSeco
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta