文章目录
ES相关度评分算法靠三个部分来依次实现,没有先后顺序,是一个逐层推进的逻辑
boolean根据搜索条件过滤doc的国车过是不做相关度分数计算的,只是为了标记出来哪些doc是符合搜索条件要求的
了解文档分词处理的都听过TFIDF模型,TF词频,IDF逆文本频率,说白了就是单词term出现了再所有文档中出现了多少次,出现越多,说明这个单词越没有标识度,越不重要,和文档的相关度分数越低
比如下面多个文章ABC中出现多次吃饭,一个文章C中出现一次原子弹,那肯定原子弹肯定对文章C很重要 很有标识度,原子弹这个单词对C来说 权重很高,这就是TFIDF模型
文章DOC A :{ 吃饭, 喝酒, 喝茶}
文章DOC B: {吃饭,原子弹}
文章DOC C:{吃饭, 喝酒}

VSM这个就更为专业
Document = {term1, term2, …… ,termN}
Document Vector = {weight1, weight2, …… ,weightN}
先构造 index:testquery, 然后构造mapping结构, 插入测试数据
#构建 库index testquer
put /testquery
#构建mapping结构
put /testquery/_mapping
{
"properties" : {
"address" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
},
"copy_to" : [
"info"
]
},
"age" : {
"type" : "long"
},
"area" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"city" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"content" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"deptName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
},
"fielddata" : true
},
"empId" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"info" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"mobile" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
},
"copy_to" : [
"info"
]
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
},
"copy_to" : [
"info"
]
},
"provice" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
},
"fielddata" : true
},
"salary" : {
"type" : "long"
},
"sex" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"addtime" : {
"type":"date",
//时间格式 epoch_millis表示毫秒
"format":"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
插入测试数据
put /testquery/_bulk
{"index":{"_id": 1},"addtime":"1658041203000"}
{"empId" : "111","name" : "员工1","age" : 20,"sex" : "男","mobile" : "19000001111","salary":1333,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"光谷大道","address":"湖北省武汉市洪山区光谷大厦","content" : "i like to write best elasticsearch article", "addtime":"1658140003000"}
{"index":{"_id": 2}}
{"empId" : "222","name" : "员工2","age" : 25,"sex" : "男","mobile" : "19000002222","salary":15963,"deptName" : "销售部","provice" : "湖北省","city":"武汉","area":"江汉区","address" : "湖北省武汉市江汉路","content" : "i think java is the best programming language"}
{"index":{"_id": 3},"addtime":"1658040045600"}
{ "empId" : "333","name" : "员工3","age" : 30,"sex" : "男","mobile" : "19000003333","salary":20000,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"经济技术开发区","address" : "湖北省武汉市经济开发区","content" : "i am only an elasticsearch beginner"}
{"index":{"_id": 4},"addtime":"1658040012000"}
{"empId" : "444","name" : "员工4","age" : 20,"sex" : "女","mobile" : "19000004444","salary":5600,"deptName" : "销售部","provice" : "湖北省","city":"武汉","area":"沌口开发区","address" : "湖北省武汉市沌口开发区","content" : "elasticsearch and hadoop are all very good solution, i am a beginner"}
{"index":{"_id": 5},"addtime":"1658040593000"}
{ "empId" : "555","name" : "员工5","age" : 20,"sex" : "男","mobile" : "19000005555","salary":9665,"deptName" : "测试部","provice" : "湖北省","city":"高新开发区","area":"武汉","address" : "湖北省武汉市东湖隧道","content" : "spark is best big data solution based on scala ,an programming language similar to java"}
{"index":{"_id": 6},"addtime":"1658043403000"}
{"empId" : "666","name" : "员工6","age" : 30,"sex" : "女","mobile" : "19000006666","salary":30000,"deptName" : "技术部","provice" : "武汉市","city":"湖北省","area":"江汉区","address" : "湖北省武汉市江汉路","content" : "i like java developer","addtime":"1658041003000"}
{"index":{"_id": 7}}
{"empId" : "777","name" : "员工7","age" : 60,"sex" : "女","mobile" : "19000007777","salary":52130,"deptName" : "测试部","provice" : "湖北省","city":"黄冈市","area":"边城区","address" : "湖北省黄冈市边城区","content" : "i like elasticsearch developer","addtime":"1658040008000"}
{"index":{"_id": 8}}
{"empId" : "888","name" : "员工8","age" : 19,"sex" : "女","mobile" : "19000008888","salary":60000,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"汉阳区","address" : "湖北省武汉市江汉大学","content" : "i like spark language","addtime":"1656040003000"}
{"index":{"_id": 9}}
{"empId" : "999","name" : "员工9","age" : 40,"sex" : "男","mobile" : "19000009999","salary":23000,"deptName" : "销售部","provice" : "河南省","city":"郑州市","area":"二七区","address" : "河南省郑州市郑州大学","content" : "i like java developer","addtime":"1608040003000"}
{"index":{"_id": 10}}
{"empId" : "101010","name" : "张湖北","age" : 35,"sex" : "男","mobile" : "19000001010","salary":18000,"deptName" : "测试部","provice" : "湖北省","city":"武汉","area":"高新开发区","address" : "湖北省武汉市东湖高新","content" : "i like java developer i also like elasticsearch","addtime":"1654040003000"}
{"index":{"_id": 11}}
{"empId" : "111111","name" : "王河南","age" : 61,"sex" : "男","mobile" : "19000001011","salary":10000,"deptName" : "销售部",,"provice" : "河南省","city":"开封市","area":"金明区","address" : "河南省开封市河南大学","content" : "i am not like java ","addtime":"1658740003000"}
{"index":{"_id": 12}}
{"empId" : "121212","name" : "张大学","age" : 26,"sex" : "女","mobile" : "19000001012","salary":1321,"deptName" : "测试部",,"provice" : "河南省","city":"开封市","area":"金明区","address" : "河南省开封市河南大学","content" : "i am java developer thing java is good","addtime":"165704003000"}
{"index":{"_id": 13}}
{"empId" : "131313","name" : "李江汉","age" : 36,"sex" : "男","mobile" : "19000001013","salary":1125,"deptName" : "销售部","provice" : "河南省","city":"郑州市","area":"二七区","address" : "河南省郑州市二七区","content" : "i like java and java is very best i like it do you like java ","addtime":"1658140003000"}
{"index":{"_id": 14}}
{"empId" : "141414","name" : "王技术","age" : 45,"sex" : "女","mobile" : "19000001014","salary":6222,"deptName" : "测试部",,"provice" : "河南省","city":"郑州市","area":"金水区","address" : "河南省郑州市金水区","content" : "i like c++","addtime":"1656040003000"}
{"index":{"_id": 15}}
{"empId" : "151515","name" : "张测试","age" : 18,"sex" : "男","mobile" : "19000001015","salary":20000,"deptName" : "技术部",,"provice" : "河南省","city":"郑州市","area":"高新开发区","address" : "河南省郑州高新开发区","content" : "i think spark is good","addtime":"1658040003000"}
设置boost查询条件权重可以实现影响搜索结果评分的目的,比如 查询条件后面加上boost,实现当前条件关联度倍增的效果
#不加boost条件查询
get /testquery/_search
{
"query":{
"bool": {
"should": [
{
"match": {
"provice.keyword": "湖北省"
}
},
{
"match": {
"address": "开发区"
}
}
]
}
}
}
不加条件查询结果

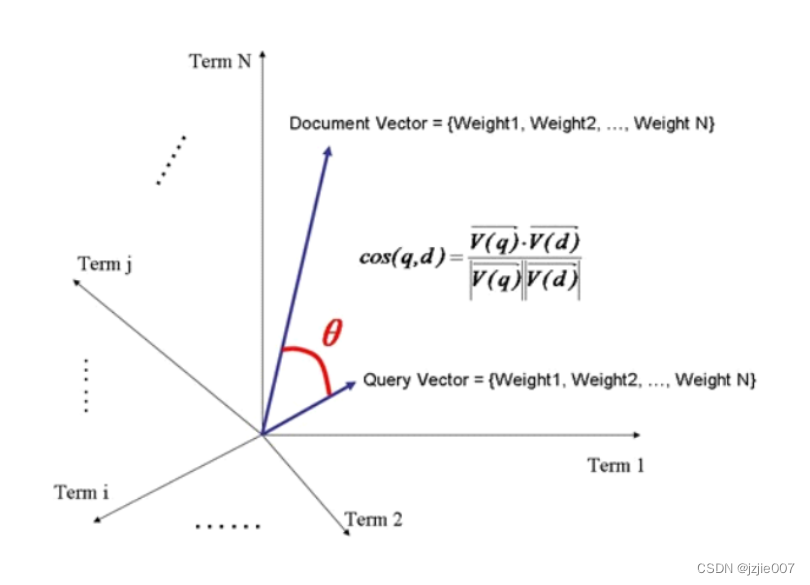
现在给 address地址 加权重boost,认为address包含开发的排名更优先
然后员工4 中address包含开发,分数直接飙升到 12.44
员工1中address并没有开发 两个字,所以address 的 boost对员工1的分数没有影响依旧是 0.344分
设置negative boost 削弱查询条件的权重 可以实现影响搜索结果评分的目的,削弱查询条件对分数的影响
#设置 negative_boost 权重为 1 看下结果
get /testquery/_search
{
"query":{
"boosting": {
"positive": {
"match": {
"provice.keyword": "湖北省"
}
},
"negative": {
"match": {
"deptName.keyword": "销售部"
}
},
"negative_boost": 1
}
}
}
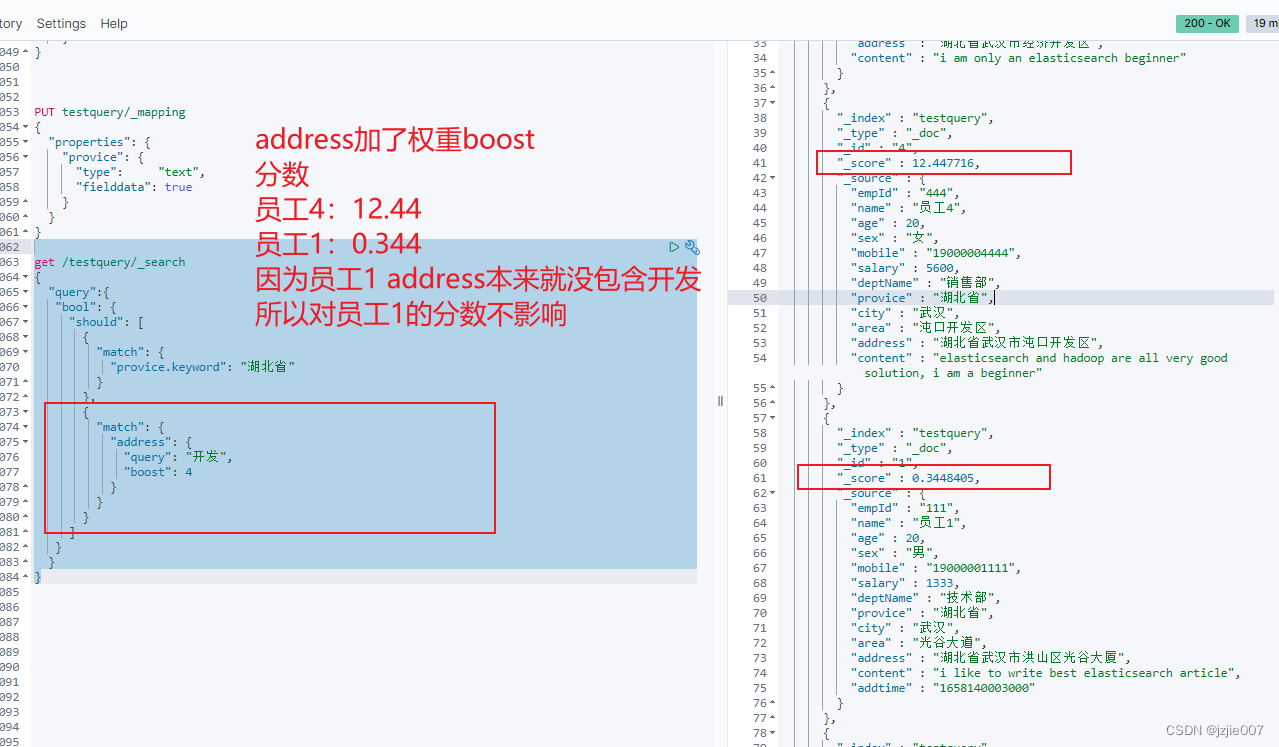
设置 negative_boost 权重为 1 看下结果
员工1:0.344 湖北省技术部
员工2:0.344 湖北省销售部
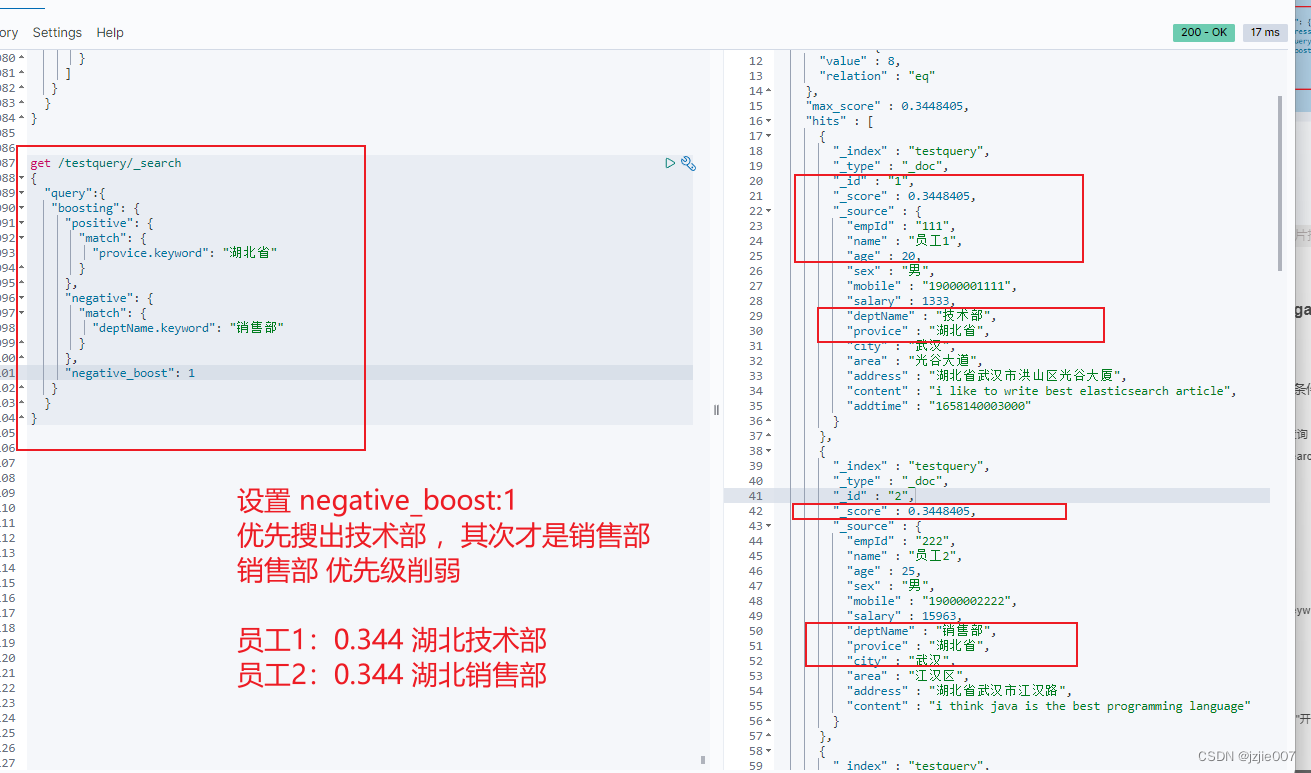
现在 negative_boost修改为 0.2 看下结果
员工1:0.344 湖北技术部 不受影响,因为他的部门deptname不是销售部,所以削弱销售部的权重不影响他
员工2:0.068 湖北销售部 受影响,分数明显降低,相关度降低
场景:
现在我想把 相关度分数和 文章的浏览量关联起来, 浏览量越大,分数越高,怎么实现
分数算法有几个关键点
至此 我们已经学习了 ES相关度分数评分算法分析, 也了解了 ES 实现相关度分析底层原理 使用 boolean模型,TFIDF,VSM空间向量模型计算相关度,也会使用 boost, negativeboost 来增加,削弱 查询条件权重 等等
下一篇我们着重讲解下 如何实现自定义算法 function score ES相关度分数评分优化及FunctionScore 自定义相关度分数算法
我正在尝试从Postgresql表(table1)中获取数据,该表由另一个相关表(property)的字段(table2)过滤。在纯SQL中,我会这样编写查询:SELECT*FROMtable1JOINtable2USING(table2_id)WHEREtable2.propertyLIKE'query%'这工作正常:scope:my_scope,->(query){includes(:table2).where("table2.property":query)}但我真正需要的是使用LIKE运算符进行过滤,而不是严格相等。然而,这是行不通的:scope:my_scope,->(que
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我正在尝试按Rails相关模型中的字段进行排序。我研究的所有解决方案都没有解决如果相关模型被另一个参数过滤?元素模型classItem相关模型:classPriority我正在使用where子句检索项目:@items=Item.where('company_id=?andapproved=?',@company.id,true).all我需要按相关表格中的“位置”列进行排序。问题在于,在优先级模型中,一个项目可能会被多家公司列出。因此,这些职位取决于他们拥有的company_id。当我显示项目时,它是针对一个公司的,按公司内的职位排序。完成此任务的正确方法是什么?感谢您的帮助。PS-我
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a
假设您有一个可执行文件foo.rb,其库bar.rb的布局如下:/bin/foo.rb/lib/bar.rb在foo.rb的header中放置以下要求以在bar.rb中引入功能:requireFile.dirname(__FILE__)+"../lib/bar.rb"只要对foo.rb的所有调用都是直接的,这就可以正常工作。如果你把$HOME/project和符号链接(symboliclink)foo.rb放入$HOME/usr/bin,然后__FILE__解析为$HOME/usr/bin/foo.rb,因此无法找到bar.rb关于foo.rb的目录名.我意识到像rubygems这
目录0专栏介绍1平面2R机器人概述2运动学建模2.1正运动学模型2.2逆运动学模型2.3机器人运动学仿真3动力学建模3.1计算动能3.2势能计算与动力学方程3.3动力学仿真0专栏介绍?附C++/Python/Matlab全套代码?课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等);局部规划(DWA、APF等);曲线优化(贝塞尔曲线、B样条曲线等)。?详情:图解自动驾驶中的运动规划(MotionPlanning),附几十种规划算法1平面2R机器人概述如图1所示为本文的研究本体——平面2R机器人。对参数进行如下定义:机器人广义坐标
术语中文解释Ability原子化服务帮助用户完成任务的原子化服务,和用户的意图进行关联。Fulfillment服务履行通过图标,卡片,语音等形式呈现用户意图。开发者通过接口的方式,处理用户意图,返回内容。Intent意图用于表达用户想要达成的目标或完成的任务。HUAWEIAssistant智能助手“无微不智”的个人助手,通过不断的学习用户的使用习惯,不断的为用户提供贴心的精准的便捷的个性化服务。AISearch全局搜索用户可快速搜索关键词,与之匹配的原子化服务则会出现在搜索结果中。SmartService智慧服务用户订阅原子化服务,在到达特定触发条件(时间、地点、事件)后,卡片推送至用户智能助
网站的日志分析,是seo优化不可忽视的一门功课,但网站越大,每天产生的日志就越大,大站一天都可以产生几个G的网站日志,如果光靠肉眼去分析,那可能看到猴年马月都看不完,因此借助网站日志分析工具去分析网站日志,那将会使网站日志分析工作变得更简单。下面推荐两款网站日志分析软件。第一款:逆火网站日志分析器逆火网站日志分析器是一款功能全面的网站服务器日志分析软件。通过分析网站的日志文件,不仅能够精准的知道网站的访问量、网站的访问来源,网站的广告点击,访客的地区统计,搜索引擎关键字查询等,还能够一次性分析多个网站的日志文件,让你轻松管理网站。逆火网站日志分析器下载地址:https://pan.baidu.