 论文地址:https://arxiv.org/abs/2302.14115Vid2Seq架构用特殊的时间标记增强了语言模型,使其能够在同一输出序列中无缝预测事件边界和文本描述。为了对这个统一的模型进行预训练,研究者通过将转录的语音的句子边界重新表述为伪事件边界,并将转录的语音句子作为伪事件的标注,来利用未标记的旁白视频。
论文地址:https://arxiv.org/abs/2302.14115Vid2Seq架构用特殊的时间标记增强了语言模型,使其能够在同一输出序列中无缝预测事件边界和文本描述。为了对这个统一的模型进行预训练,研究者通过将转录的语音的句子边界重新表述为伪事件边界,并将转录的语音句子作为伪事件的标注,来利用未标记的旁白视频。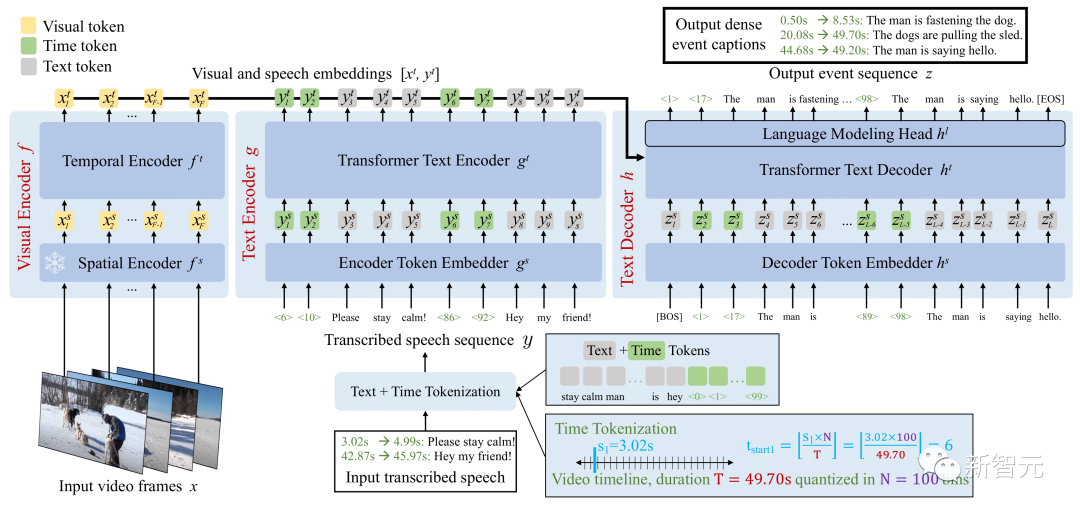 Vid2Seq模型概述由此产生的Vid2Seq模型在数以百万计的旁白视频上进行了预训练,提高了各种密集视频标注基准的技术水平,包括YouCook2、ViTT和ActivityNet Captions。Vid2Seq还能很好地适用于few-shot的密集视频标注设置、视频段落标注任务和标准视频标注任务。
Vid2Seq模型概述由此产生的Vid2Seq模型在数以百万计的旁白视频上进行了预训练,提高了各种密集视频标注基准的技术水平,包括YouCook2、ViTT和ActivityNet Captions。Vid2Seq还能很好地适用于few-shot的密集视频标注设置、视频段落标注任务和标准视频标注任务。


 下一个例子有关于烹饪食谱中的一系列指令,是Vid2Seq对YouCook2验证集的密集事件标注预测的例子:
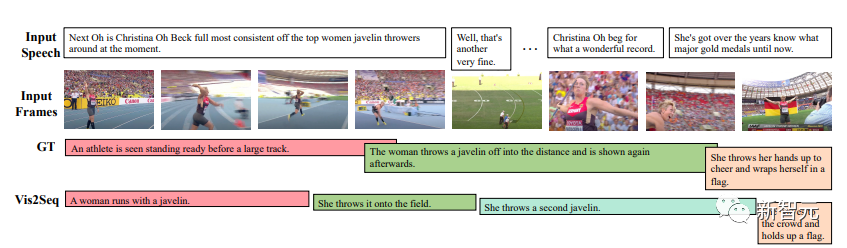
下一个例子有关于烹饪食谱中的一系列指令,是Vid2Seq对YouCook2验证集的密集事件标注预测的例子: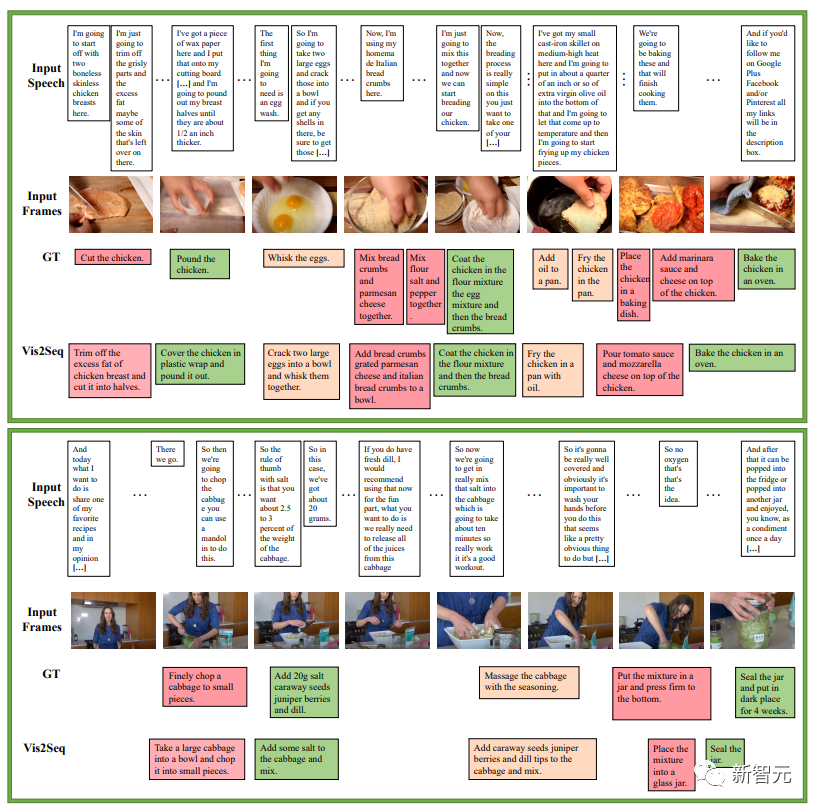 接下来是Vid2Seq对ActivityNet Captions验证集的密集事件标注预测的例子,在所有这些视频中,都没有转录的语音。不过还是会有失败的案例,比如下面标红的这个画面,Vid2Seq说是一个人对着镜头脱帽致敬。
接下来是Vid2Seq对ActivityNet Captions验证集的密集事件标注预测的例子,在所有这些视频中,都没有转录的语音。不过还是会有失败的案例,比如下面标红的这个画面,Vid2Seq说是一个人对着镜头脱帽致敬。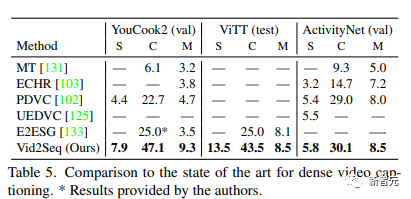 Vid2Seq在YouCook2和ActivityNet Captions上的SODA指标比PDVC和UEDVC分别提高了3.5和0.3分。且E2ESG在Wikihow上使用域内纯文本预训练,而Vid2Seq优于这一方法。这些结果表明,预训练的Vid2Seq模型具有很强的密集事件标注能力。表6评估了密集视频标注模型的事件定位性能。与YouCook2和ViTT相比,Vid2Seq在处理密集视频标注作为单一序列生成任务时更胜一筹。
Vid2Seq在YouCook2和ActivityNet Captions上的SODA指标比PDVC和UEDVC分别提高了3.5和0.3分。且E2ESG在Wikihow上使用域内纯文本预训练,而Vid2Seq优于这一方法。这些结果表明,预训练的Vid2Seq模型具有很强的密集事件标注能力。表6评估了密集视频标注模型的事件定位性能。与YouCook2和ViTT相比,Vid2Seq在处理密集视频标注作为单一序列生成任务时更胜一筹。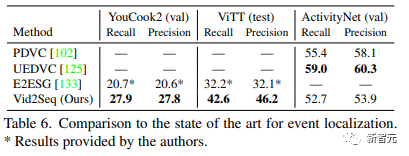 然而,与PDVC和UEDVC相比,Vid2Seq在ActivityNet Captions上表现不佳。与这两种方法相比,Vid2Seq整合了较少的关于时间定位的先验知识,而另两种方法包括特定的任务组件,如事件计数器或单独为定位子任务训练一个模型。
然而,与PDVC和UEDVC相比,Vid2Seq在ActivityNet Captions上表现不佳。与这两种方法相比,Vid2Seq整合了较少的关于时间定位的先验知识,而另两种方法包括特定的任务组件,如事件计数器或单独为定位子任务训练一个模型。 Antoine Yang是法国国立计算机及自动化研究院Inria和巴黎高等师范学校École Normale Supérieure的WILLOW团队的三年级博士生,导师为Antoine Miech, Josef Sivic, Ivan Laptev和Cordelia Schmid。目前的研究重点是学习用于视频理解的视觉语言模型。他于2019年在华为诺亚方舟实验室实习,在2020年获得了巴黎综合理工学院的工程学位和巴黎萨克雷国立大学的数学、视觉和学习硕士学位,2022年在谷歌研究院实习。
Antoine Yang是法国国立计算机及自动化研究院Inria和巴黎高等师范学校École Normale Supérieure的WILLOW团队的三年级博士生,导师为Antoine Miech, Josef Sivic, Ivan Laptev和Cordelia Schmid。目前的研究重点是学习用于视频理解的视觉语言模型。他于2019年在华为诺亚方舟实验室实习,在2020年获得了巴黎综合理工学院的工程学位和巴黎萨克雷国立大学的数学、视觉和学习硕士学位,2022年在谷歌研究院实习。 华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
动漫制作技巧是很多新人想了解的问题,今天小编就来解答与大家分享一下动漫制作流程,为了帮助有兴趣的同学理解,大多数人会选择动漫培训机构,那么今天小编就带大家来看看动漫制作要掌握哪些技巧?一、动漫作品首先完成草图设计和原型制作。设计草图要有目的、有对象、有步骤、要形象、要简单、符合实际。设计图要一致性,以保证制作的顺利进行。二、原型制作是根据设计图纸和制作材料,可以是手绘也可以是3d软件创建。在此步骤中,要注意的问题是色彩和平面布局。三、动漫制作制作完成后,加工成型。完成不同的表现形式后,就要对设计稿进行加工处理,使加工的难易度降低,并得到一些基本准确的概念,以便于后续的大样、准确的尺寸制定。四、
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
目前我正在使用这个正则表达式从YoutubeURL中提取视频ID:url.match(/v=([^&]*)/)[1]我怎样才能改变它,以便它也可以从这个没有v参数的YoutubeURL获取视频ID:http://www.youtube.com/user/SHAYTARDS#p/u/9/Xc81AajGUMU感谢阅读。编辑:我正在使用ruby1.8.7 最佳答案 对于Ruby1.8.7,这就可以了。url_1='http://www.youtube.com/watch?v=8WVTOUh53QY&feature=feedf'url
所有题目均有五种语言实现。C实现目录、C++实现目录、Python实现目录、Java实现目录、JavaScript实现目录题目n行m列的矩阵,每个位置上有一个元素你可以上下左右行走,代价是前后两个位置元素值差的绝对值.另外,你最多可以使用一次传送阵(只能从一个数跳到另外一个相同的数)求从走上角走到右下角最少需要多少时间。输入描述:第一行两个整数n,m,分别代表矩阵的行和列。后面n行,每行m个整数,分别代表矩阵中的元素。输出描述:一个整数,表示最少需要多少时间。
我正在使用RABL输出Sunspot/SOLR结果集,搜索结果对象由多种模型类型组成。目前在rablView中我有:objectfalsechild@search.results=>:resultsdoattribute:id,:resource,:upccodeattribute:display_description=>:descriptioncode:start_datedo|r|r.utc_start_date.to_iendcode:end_datedo|r|r.utc_end_date.to_iendendchild@search=>:statsdoattribute:to
昨晚看到IDEA官推宣布IntelliJIDEA2023.1正式发布了。简单看了一下,发现这次的新版本包含了许多改进,进一步优化了用户体验,提高了便捷性。至于是否升级最新版本完全是个人意愿,如果觉得新版本没有让自己感兴趣的改进,完全就不用升级,影响不大。软件的版本迭代非常正常,正确看待即可,不持续改进就会慢慢被淘汰!根据官方介绍:IntelliJIDEA2023.1针对新的用户界面进行了大量重构,这些改进都是基于收到的宝贵反馈而实现的。官方还实施了性能增强措施,使得Maven导入更快,并且在打开项目时IDE功能更早地可用。由于后台提交检查,新版本提供了简化的提交流程。IntelliJIDEA
目录1. 研究范围定义2. 流程中台市场分析3. 厂商评估:微宏科技4. 入选证书 1. 研究范围定义近年来,随着外部市场环境快速变化、客户需求愈发多样,企业逐渐意识到,自身业务需要更加敏捷、高效,具备根据市场需求快速迭代的能力。业务流程的自动化能够帮助企业实现业务的敏捷高效,因此受到越来越多企业的关注。企业的“自动化武器库”品类丰富,包括低/零代码平台、RPA、BPM、AI等。企业可以使用多项自动化工具,但结果往往是各项自动化工具处于各自的“自动化烟囱”之中,仅能实现碎片式自动化。例如,某企业的IT团队可能在使用低代码平台、财务团队可能在使用RPA、呼叫中心则可能在使用聊天机器人。自动
自从2019年OpenApplicationModel诞生以来,KubeVela已经经历了几十个版本的变化,并向现代应用程序交付先进功能的方向不断发展。最近,KubeVela完成了向CNCF孵化项目的晋升,标志着社区的发展来到一个新的里程碑。今天,KubeVela社区内活跃着大量来自全球的开发者,共同推动KubeVela项目的落地和发展。在即将开幕的KubeCon+CloudNatvieConEurope2023上,我们惊喜地发现,连续3天,KubeVela项目的贡献者、企业用户和来自阿里云的核心维护者,将从不同角度展对KubeVela项目的分享。让我们先睹为快!🎙️BuildingaPlat