文章目录
RAM是Random Access Memory的首字母缩写。它是一种主存储器,用于存储当前正在使用的信息。信息可以是正在处理的数据或程序代码。它是一种读写存储器,这意味着它几乎可以同时存储(写入)和访问(读取)数据。但RAM是易失性或临时性存储器,即当电源被移除时其内容会被擦除。RAM是一种快速存取存储器,因为无论其物理位置如何,它都可以随时随机存储和访问数据。它存储启动设备所需的必要指令和处理器正在使用的数据。它通过在组件之间快速传输数据来提高系统的处理速度。
ROM,Read Only Memory,即只读存储器,也是一种主存储器,但它永久存储数据。它是一种非易失性存储器,即当电源被移除时,其数据内容不会被擦除。顾名思义,它是只读存储器,这意味着数据不能更改,但可以访问任意次数。只能访问数据而不能写入数据。
RAM和ROM都可以简单地视为一张表格,每个格子的内容就是其所存储的信息,而地址线则是寻找对应表格的“身份号码”。RAM可以对表格的内容进行读、写操作,而ROM只能对表格进行读操作,无法进行写操作。
FGPA内部的分布式RAM(DRAM,Distributed RAM)的概念是相对于块RAM(BRAM,Block RAM)来说的。物理上看,BRAM是fpga中固定存在的硬件资源,而DRAM则是使用逻辑单元LUT拼出来的,实际上算是LUT的延伸使用。
BRAM由一定数量固定大小的存储块构成的,使用BRAM不占用额外的逻辑资源,且速度快。但是使用的时候消耗的BRAM资源是其块大小的整数倍。如Xilinx7系列FPGA结构中每个BRAM有36Kbit的容量,既可以作为一个36Kbit的存储器使用,也可以拆分为两个独立的18Kbit存储器使用。反过来相邻两个BRAM可以结合起来实现72Kbit存储器。每个Block RAM都有两套访问存储器所需的地址总线、数据总线及控制信号等信号,因此其既可以作为单端口存储器,也可以作为双端口存储器。需要注意的时访问BRAM需要和时钟同步,异步访问是不支持的。
只有SLICEM里的查找表才可以用做DRAM,利用查找表为电路实现存储器,既可以实现芯片内部存储,又能提高资源利用率。DRAM的特点是可以实现BRAM不能实现的异步访问。不过使用分布式RAM实现大规模的存储器会占用大量的LUT,可用来实现逻辑的查找表就会减少。因此建议仅在需要小规模存储器时,使用这种分布式RAM。
DRAM使用的是没有综合的LUT单元,而BRAM是块RAM,它的大小和位置是固定的。即使你只使用了一点点BRAM,综合后同样会消耗一整块RAM。BRAM是一列一列分布的,这样可能造成用户逻辑模块和BRAM直接的距离较长,延时较长,最终导致性能下降。如果使用到多个BRAM最好合理规划一下布局。
较大的存储应用,建议用BRAM;零星的小应用,可以用DRAM。但这只是个一般原则,具体的使用得看整个设计中资源的冗余度和性能要求。
CLB(可配置逻辑单元,Configurable Logic Block)是FPGA底层的基本逻辑单元,由两个SLICE组成。SLICE的种类有两种:SLICEL与SLICEM:
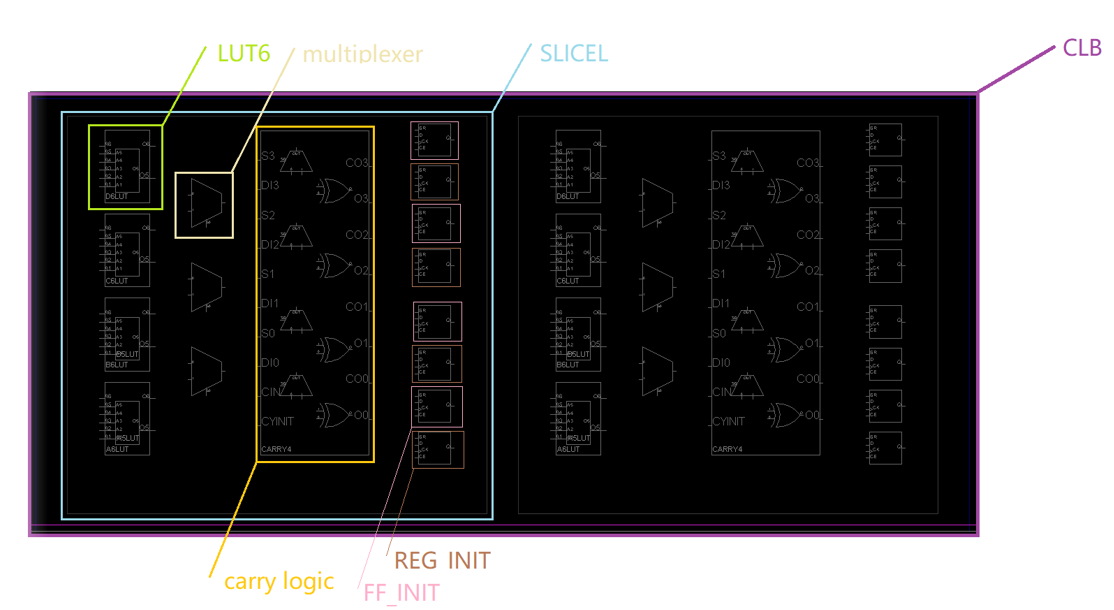
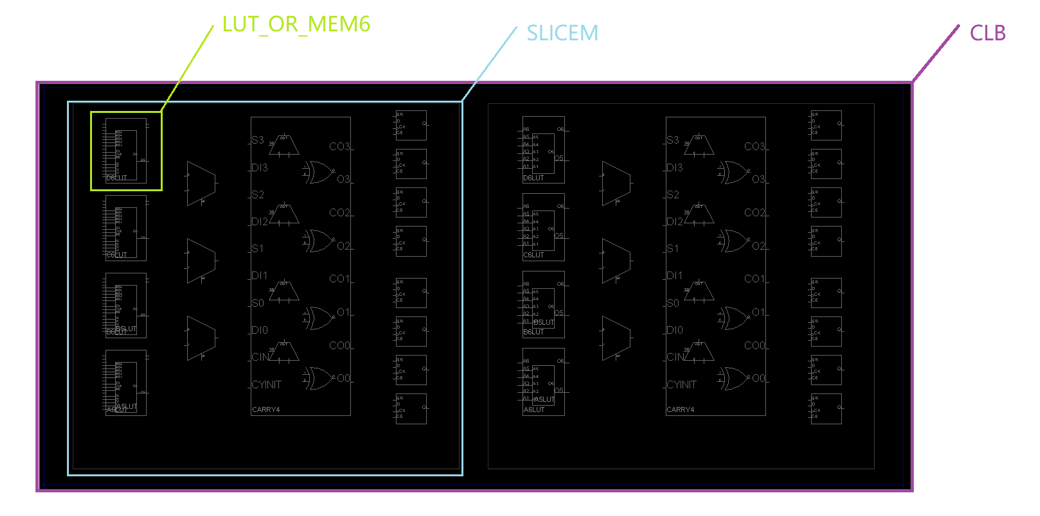
SLICEL与SLICEM的组成大致相同,只有LUT6有区别。我们把两种LUT6放到一起来看看:
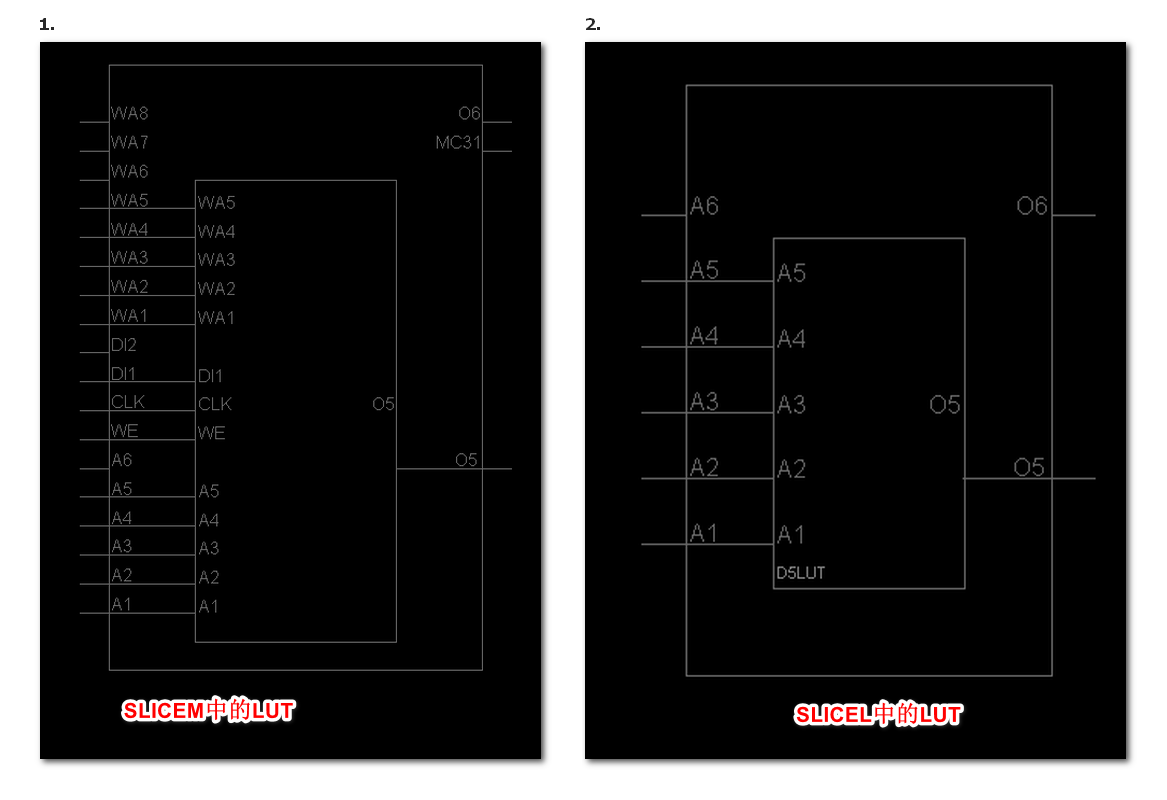
SLICEM中的LUT较SLICEL中的LUT,除了具备读总线A1~A6,还具有WE(写使能)、DI1~DI2(数据写入端口)和WA1~WA8(数据写地址端口),所以SLICEM还具备数据写入功能,这使得其可以作为分布式RAM和移位寄存器使用。
而SLICEL中的LUT只有地址线与输出,所以我们只能将其作为一个ROM使用,从而实现查找表功能。
由于每个SLICEM中均有4个LUT,所以其资源可以实现以下形式的DRAM:
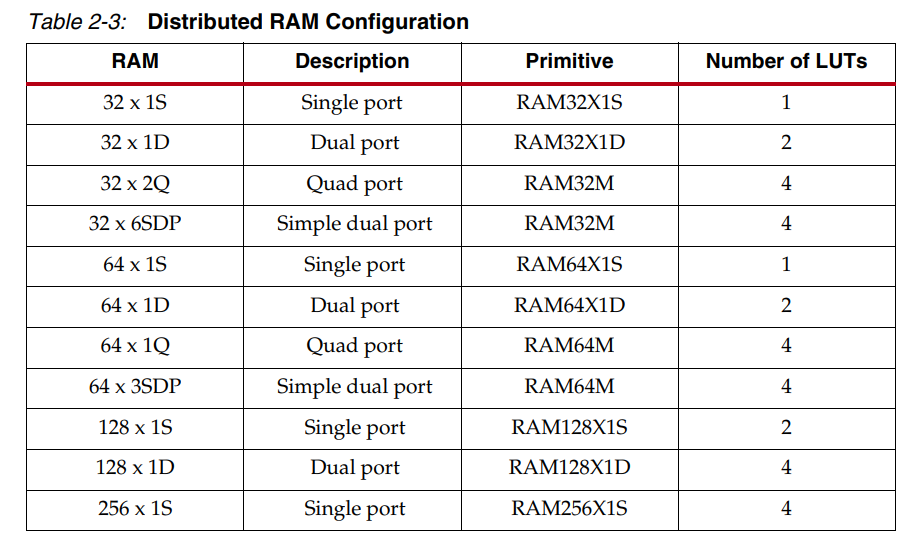
其配置如下:
(一)单口RAM:同步写、异步读,读写操作共用一组地址总线
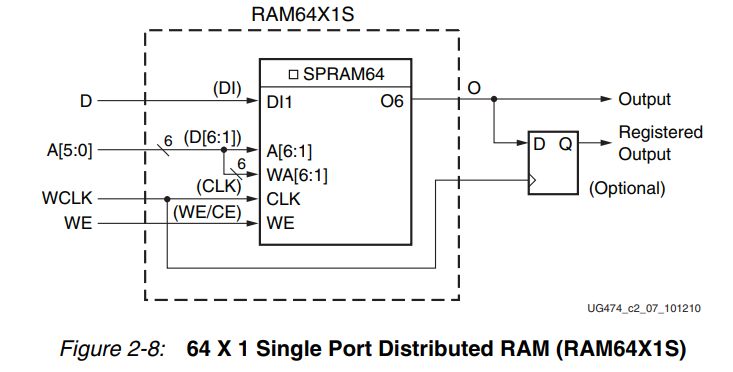
(二)双口RAM:一个端口用于同步写和异步读;一个端口用于异步读取
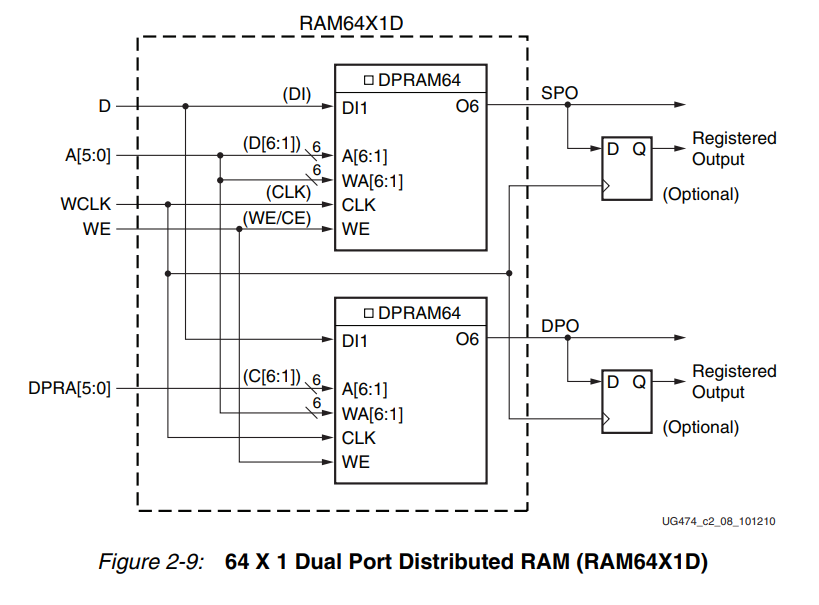
(三)简单双端口:一个用于同步写的端口(从写端口没有数据输出/读端口);一个端口用于异步读取
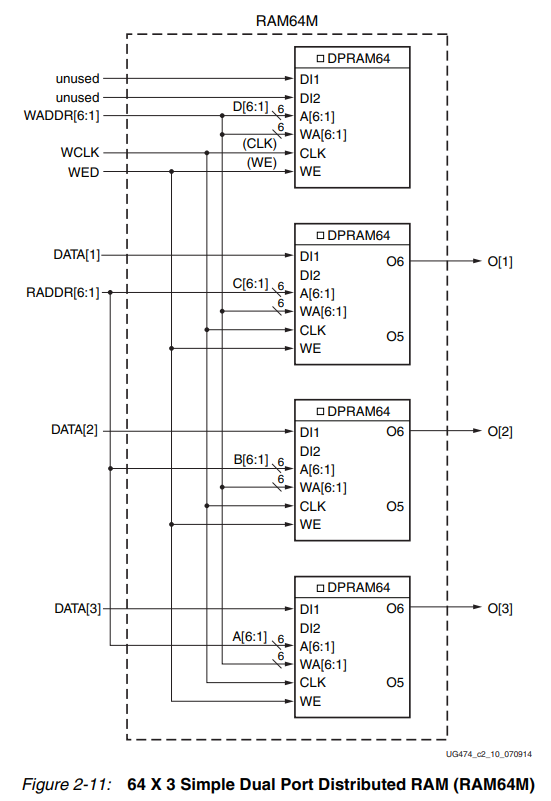
(四)四端口:一个用于同步写和异步读的端口;三个端口用于异步读取
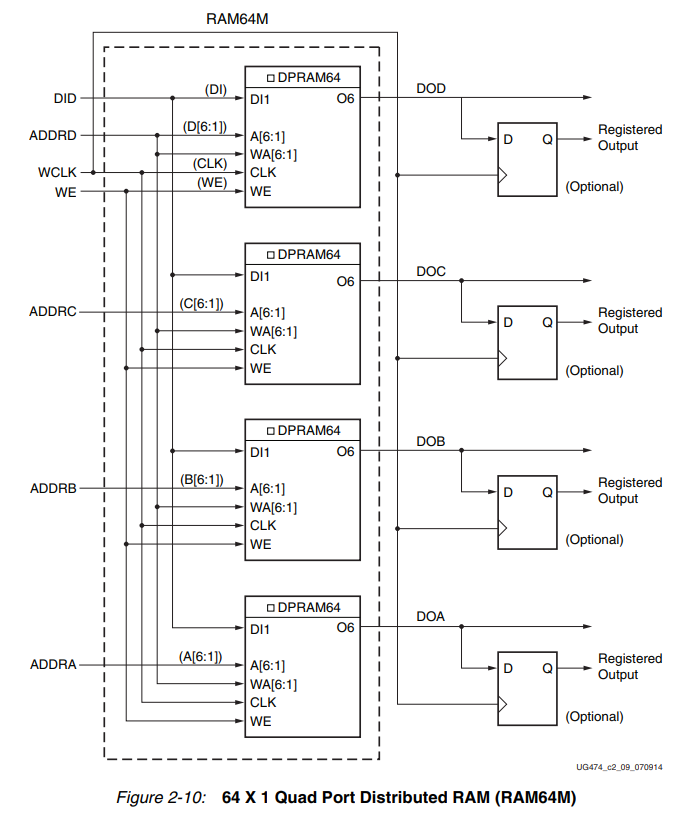
(五)更大深度的实现
此外,可以通过多个LUT6+MUX的方式实现更大深度的DRAM。
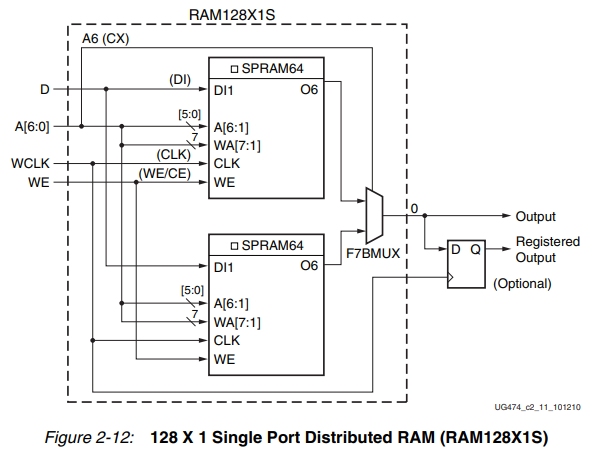
128深度的DRAM,可以通过2个LUT6+1个MUX2实现,两个LUT6分别存储低64bit和高64bit的数据,通过MUX2来进行选取,从而拼接而成实现128深度的单口DRAM。
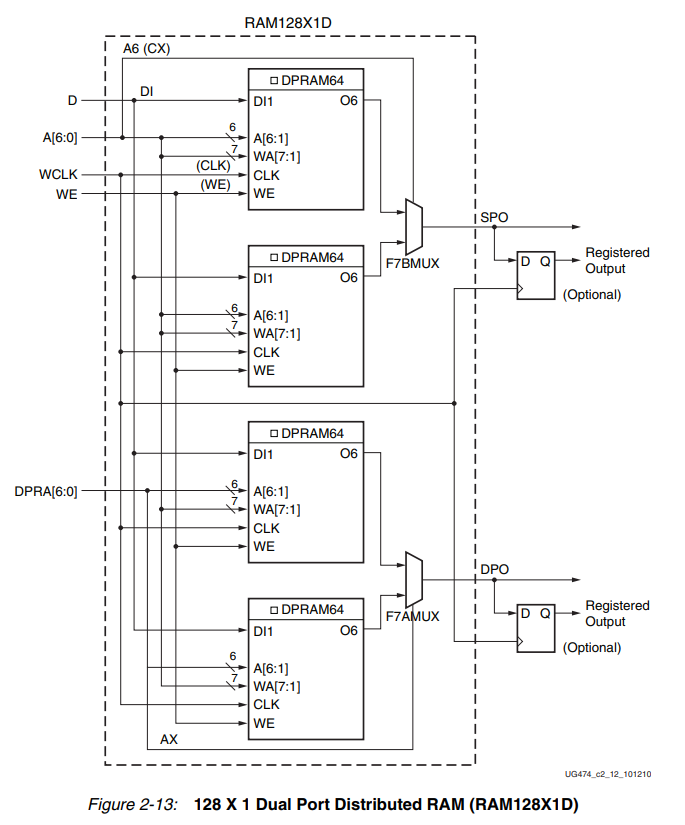
同样的,也可以使用相同的结构实现256深度的DRAM。
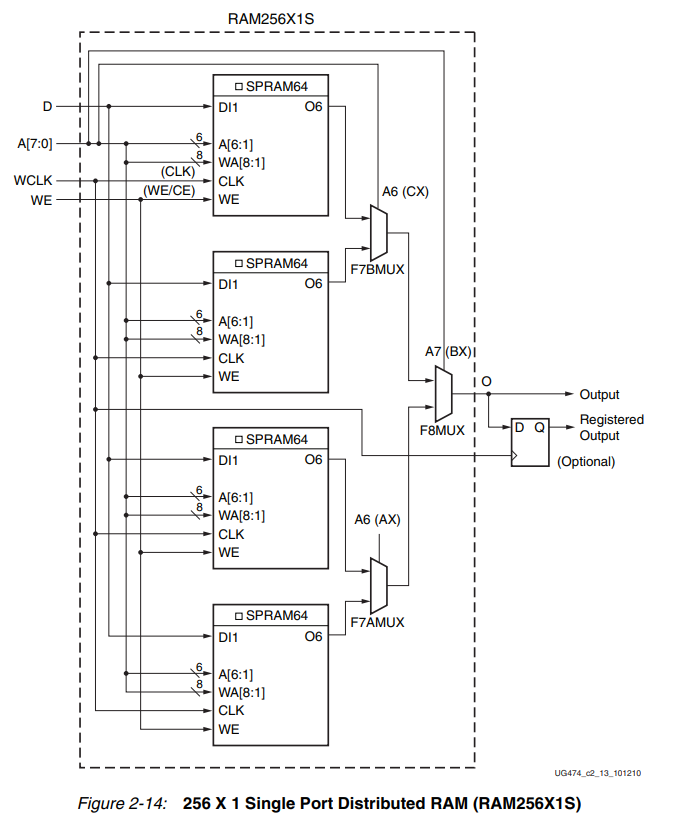
256深度的单口RAM则使用了4个LUT6+2个F7MUX+1个F8MUX,刚好是一个SLICEM里面的最大资源数量,所以单个SLICEM能实现的最大深度DRAM就是256*1的单口DRAM。
DRAM可以使用多种方式来实现,各种方法都有利弊,所以在实际使用过程中应根据需求及开发环境来灵活使用。
推断是指设计者使用符合规范的RTL代码,由综合工具(此文均指xilinx的vivado)自动推断出DRAM结构的方式。
由于推断结果一般较为理想,因此建议采用推断,除非给定用例不受支持,或者无法在性能、面积或功耗方面实现足够的结果。在此类情况下,请尝试其它方法。推断 RAM 时,赛灵思建议您使用 Vivado 工具中提供的 HDL 模板。如前文所述,使用异步复位会给 RAM 推断造成不利影响,应避免使用。
(优点)
(不足)
以下是64深度,6宽度的单端口DRAM的RTL代码实现方式:
module RTL_DRAM(
input wclk, //input clk
input [5:0] addr, //input address
input [5:0] d, //input data
input we, //input write enable
output [5:0] o //output
);
reg [5:0] dram64x6 [63:0] ; //64*6
always@(posedge wclk)
if(we) dram64x6[addr] <= d;
assign o = dram64x6[addr];
endmodule其写操作与时钟同步,而读操作则是异步。
在FPGA上综合的结果如下:
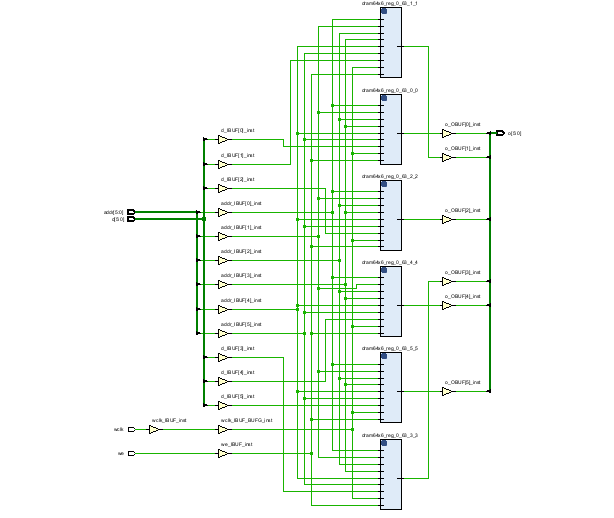
由6个1宽度的64深度RAM级联组成,资源消耗则为6个LUT6,与理论情况一致。
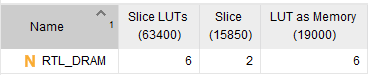
原语是xilinx提供的底层设计元素,类似于嵌入式开发中提供的底层库函数。针对DRAM的实现,xilinx同样提供了数个原语,如:RAM64X1S,RAM16X4S,RAM128X1D等,具体可查阅《UG799,Xilinx 7 Series FPGA and Zynq-7000 All Programmable SoC Libraries Guide for Schematic Designs》。需要注意的是,DRAM原语通常都是固定了位宽、深度和实现方式的,对于某些不符合深度、位宽的DRAM实现,则需要找更小的原语来实现。例如,原语无法直接实现64深度6位宽的单端口DRAM,只能通过6个64深度1位宽的单端口DRAM--RAM64X1S来实现。
(优点)
(不足)
以下是64深度,6宽度的单端口DRAM的原语实现方式:
module PRIMATE_DRAM(
input wclk, //input clk
input [5:0] addr, //input address
input [5:0] d, //input data
input we, //input write enable
output [5:0] o //output
);
RAM64X1S #(
.INIT(64'h0000000000000000) // Initial contents of RAM
) RAM64X1S_inst0 (
.A0 (addr[0]), // Address[0] input bit
.A1 (addr[1]), // Address[1] input bit
.A2 (addr[2]), // Address[2] input bit
.A3 (addr[3]), // Address[3] input bit
.A4 (addr[4]), // Address[4] input bit
.A5 (addr[5]), // Address[5] input bit
.D (d[0]), // 1-bit data input
.O (o[0]), // 1-bit data output
.WCLK (wclk), // Write clock input
.WE (we) // Write enable input
);
RAM64X1S #(
.INIT(64'h0000000000000000) // Initial contents of RAM
) RAM64X1S_inst1 (
.A0 (addr[0]), // Address[0] input bit
.A1 (addr[1]), // Address[1] input bit
.A2 (addr[2]), // Address[2] input bit
.A3 (addr[3]), // Address[3] input bit
.A4 (addr[4]), // Address[4] input bit
.A5 (addr[5]), // Address[5] input bit
.D (d[1]), // 1-bit data input
.O (o[1]), // 1-bit data output
.WCLK (wclk), // Write clock input
.WE (we) // Write enable input
);
RAM64X1S #(
.INIT(64'h0000000000000000) // Initial contents of RAM
) RAM64X1S_inst2 (
.A0 (addr[0]), // Address[0] input bit
.A1 (addr[1]), // Address[1] input bit
.A2 (addr[2]), // Address[2] input bit
.A3 (addr[3]), // Address[3] input bit
.A4 (addr[4]), // Address[4] input bit
.A5 (addr[5]), // Address[5] input bit
.D (d[2]), // 1-bit data input
.O (o[2]), // 1-bit data output
.WCLK (wclk), // Write clock input
.WE (we) // Write enable input
);
RAM64X1S #(
.INIT(64'h0000000000000000) // Initial contents of RAM
) RAM64X1S_inst3 (
.A0 (addr[0]), // Address[0] input bit
.A1 (addr[1]), // Address[1] input bit
.A2 (addr[2]), // Address[2] input bit
.A3 (addr[3]), // Address[3] input bit
.A4 (addr[4]), // Address[4] input bit
.A5 (addr[5]), // Address[5] input bit
.D (d[3]), // 1-bit data input
.O (o[3]), // 1-bit data output
.WCLK (wclk), // Write clock input
.WE (we) // Write enable input
);
RAM64X1S #(
.INIT(64'h0000000000000000) // Initial contents of RAM
) RAM64X1S_inst4 (
.A0 (addr[0]), // Address[0] input bit
.A1 (addr[1]), // Address[1] input bit
.A2 (addr[2]), // Address[2] input bit
.A3 (addr[3]), // Address[3] input bit
.A4 (addr[4]), // Address[4] input bit
.A5 (addr[5]), // Address[5] input bit
.D (d[4]), // 1-bit data input
.O (o[4]), // 1-bit data output
.WCLK (wclk), // Write clock input
.WE (we) // Write enable input
);
RAM64X1S #(
.INIT(64'h0000000000000000) // Initial contents of RAM
) RAM64X1S_inst5 (
.A0 (addr[0]), // Address[0] input bit
.A1 (addr[1]), // Address[1] input bit
.A2 (addr[2]), // Address[2] input bit
.A3 (addr[3]), // Address[3] input bit
.A4 (addr[4]), // Address[4] input bit
.A5 (addr[5]), // Address[5] input bit
.D (d[5]), // 1-bit data input
.O (o[5]), // 1-bit data output
.WCLK (wclk), // Write clock input
.WE (we) // Write enable input
);
endmodule综合结果与推断的结果基本一致。
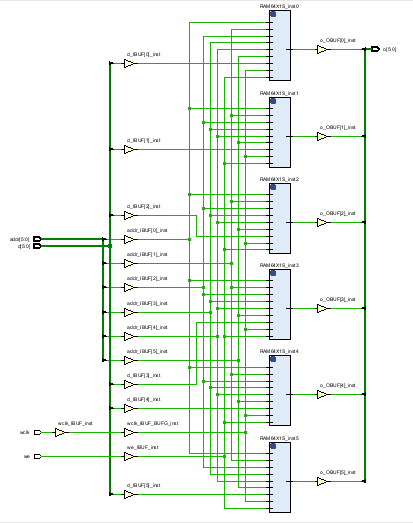
资源使用情况也与推断的结果一致--由6个1宽度的64深度RAM级联组成,资源消耗则为6个LUT6,与理论情况一致。

可以看到采用原语的DRAM开发方式,需要对基础原语进行多次例化,虽然可以借用generate语法,但是仍然很麻烦。
XILINX还提供了DRAM的IP供开发者使用,采用IP的开发方式,GUI程度高,开发简单,但是由于定制程度高,所以可移植性也一般。
(优点)
(不足)
DRAM的IP核全称为Distributed Memory Generator,其使用较为简单,接下来我们采用IP核配置一个64深度的6位宽单端口DRAM,配置过程如下:
(第一页)

(第二页)
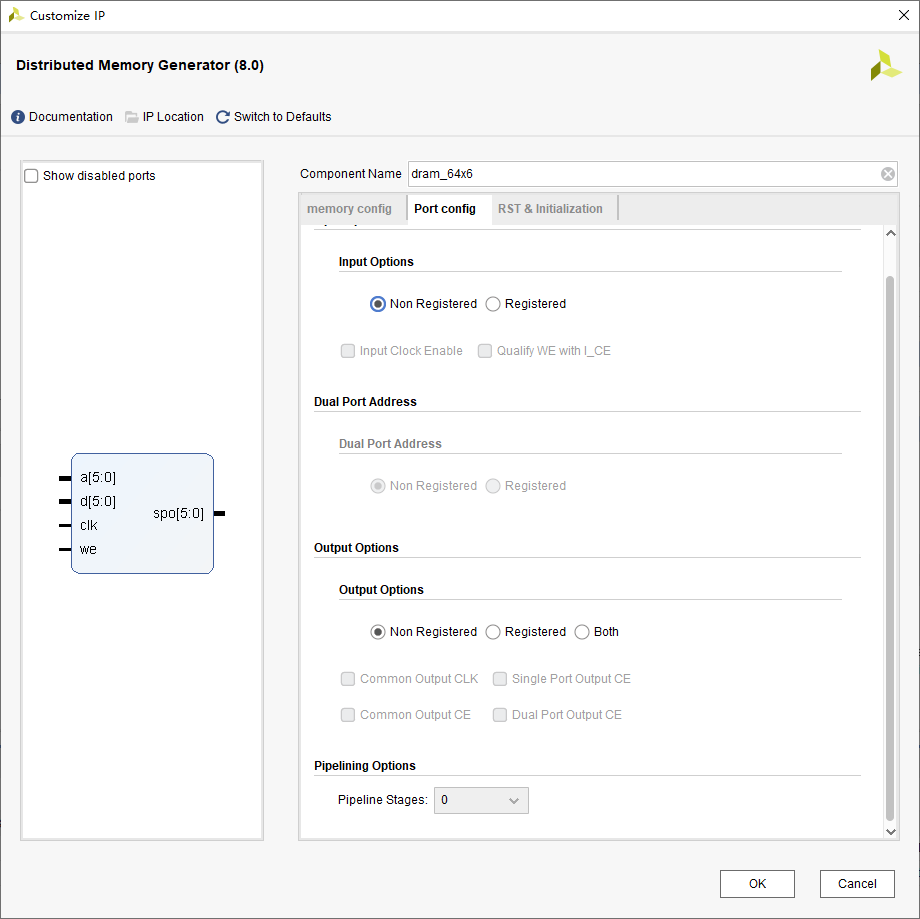
(第三页)
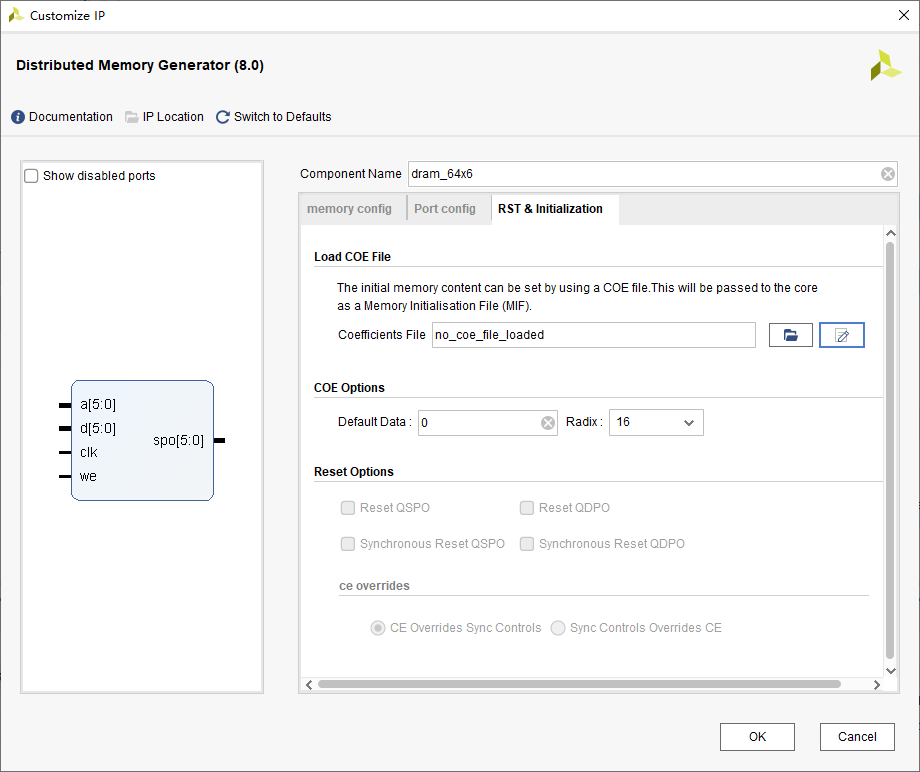
接下来综合,再根据veo文件提供的例化模板,编写RTL对IP核进行例化:
module IP_DRAM(
input wclk, //input clk
input [5:0] addr, //input address
input [5:0] d, //input data
input we, //input write enable
output [5:0] o //output
);
//例化DRAM IP核
dram_64x6 dram_64x6_inst (
.a (addr), // input wire [5 : 0] a
.d (d), // input wire [5 : 0] d
.clk (wclk), // input wire clk
.we (we), // input wire we
.spo (o) // output wire [5 : 0] spo
);
endmodule综合结果,资源消耗均与上述两种方法一致。
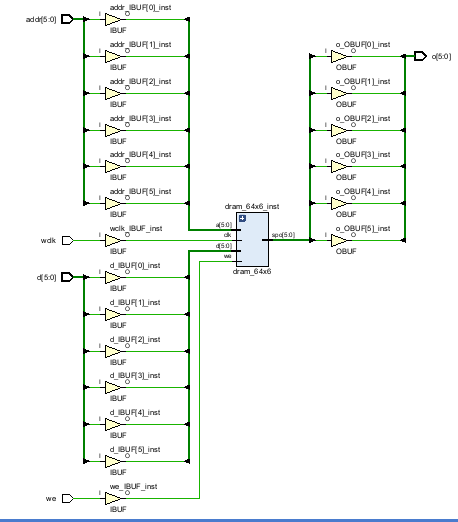

我们将三种实现DRAM的模块例化到同一个顶层文件,再编写testbench对其仿真,实现功能:先往地址0-63写入数据0-63,再从地址0-63读出数据,观察写、读数据是否一致。
顶层文件:
module test(
input wclk, //input clk
input [5:0] addr, //input address
input [5:0] d, //input data
input we, //input write enable
output [5:0] o_rtl,
output [5:0] o_primate,
output [5:0] o_ip
);
//例化RTL型
RTL_DRAM RTL_DRAM_inst(
.wclk (wclk ), //input clk
.addr (addr ), //input address
.d (d ), //input data
.we (we ), //input write enable
.o (o_rtl ) //output
);
//例化原语型
PRIMATE_DRAM PRIMATE_DRAM_inst(
.wclk (wclk ), //input clk
.addr (addr ), //input address
.d (d ), //input data
.we (we ), //input write enable
.o (o_primate) //output
);
//例化IP型
IP_DRAM IP_DRAM_inst(
.wclk (wclk ), //input clk
.addr (addr ), //input address
.d (d ), //input data
.we (we ), //input write enable
.o (o_ip ) //output
);
endmoduletestbench:
`timescale 1ns / 1ns
module tb_test();
reg wclk; //input clk
reg [5:0] addr; //input address
reg [5:0] d; //input data
reg we; //input write enable
wire [5:0] o_rtl;
wire [5:0] o_primate;
wire [5:0] o_ip;
//例化test模块
test test_inst(
.wclk (wclk ), //input clk
.addr (addr ), //input address
.d (d ), //input data
.we (we ), //input write enable
.o_rtl (o_rtl ), //output
.o_primate (o_primate ), //output
.o_ip (o_ip ) //output
);
initial begin
wclk =0;
we =1;
d = 0;
addr = 0;
wait(d == 6'd63);#10 we =0;
end
always #5 wclk = ~wclk;
always @(posedge wclk)begin
d <= d+1;
addr <= addr+1;
end
endmodule仿真结果如下:与设想情况一致。
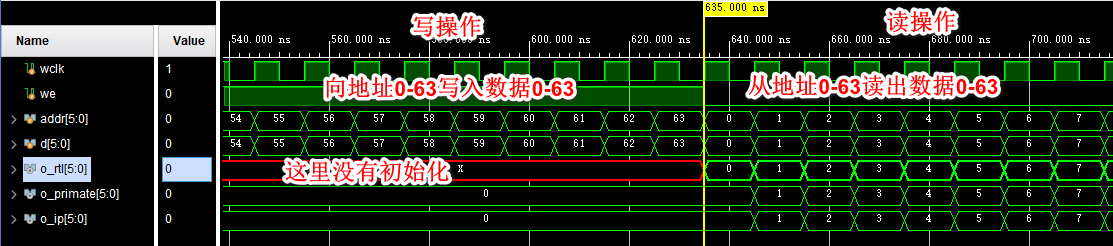
分布式RAM提供了对非常小的数组使用存储元素和对较大数组使用BRAM之间的权衡。建议尽可能地使用RTL方式推断内存,以提供最大的灵活性。分布式RAM也可以通过原语实例化或使用IP来生成。
一般来说,分布式RAM应该用于所有深度为64位或更少的情况,除非设备缺少SLICEM或逻辑资源。因为分布式RAM在资源、性能和功能方面更高效。
对于大于64位但小于或等于128位的深度,使用最佳资源的决定取决于以下因素:
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
您将如何构建一个简单的Sinatra应用程序?我正在制作,我希望该应用具有以下功能:“应用程序”更像是一个包含所有信息的管理仪表板。然后另一个应用程序将通过REST访问信息。我还没有创建仪表板,只是从数据库中获取东西session和身份验证(尚未实现)您可以上传图片,其他应用可以显示这些图片我已经使用RSpec创建了一个测试文件通过Prawn生成报告目前的设置是这样的:app.rbtest_app.rb因为我实际上只有应用程序和测试文件。到目前为止,我已经将Datamapper用于ORM,将SQLite用于数据库。这是我的第一个Ruby/Sinatra项目,所以欢迎任何和所有建议-我应
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
我想编写一个ruby脚本来递归复制目录结构,但排除某些文件类型。因此,给定以下目录结构:folder1folder2file1.txtfile2.txtfile3.csfile4.htmlfolder2folder3file4.dll我想复制这个结构,但不包含.txt和.cs文件。因此,生成的目录结构应如下所示:folder1folder2file4.htmlfolder2folder3file4.dll 最佳答案 您可以使用查找模块。这是一个代码片段:require"find"ignored_extensions=[".cs"