
牛牛开始更新数据结构的知识了.本专栏后续会分享用c语言实现顺序表,链表,二叉树,栈和队列,排序算法等相关知识,欢迎友友们互相学习,可以私信互相讨论哦!
🎈个人主页:🎈 :✨✨✨初阶牛✨✨✨
🐻推荐专栏: 🍔🍟🌯 c语言初阶
🔑个人信条: 🌵知行合一
🍉本篇简介:>:讲解数据结构的入门知识,时间复杂度与空间复杂度,以及一些对学习数据结构的建议.
金句分享:
✨最快的脚步不是冲刺,而是坚持!✨
目录
数据结构+算法=程序.
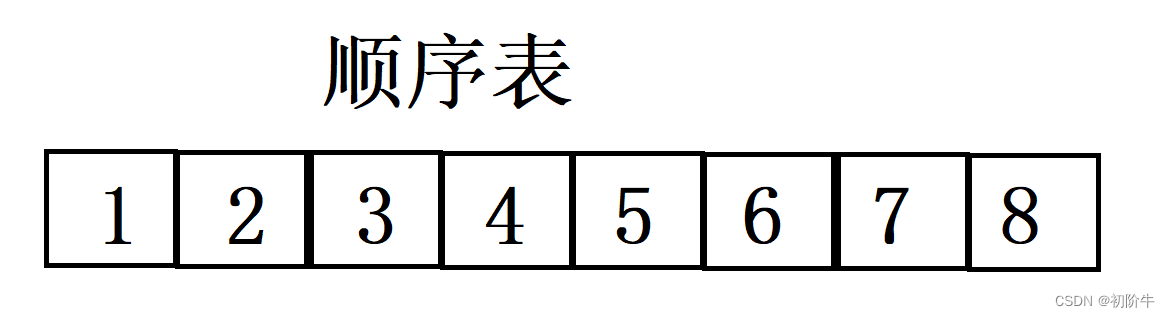
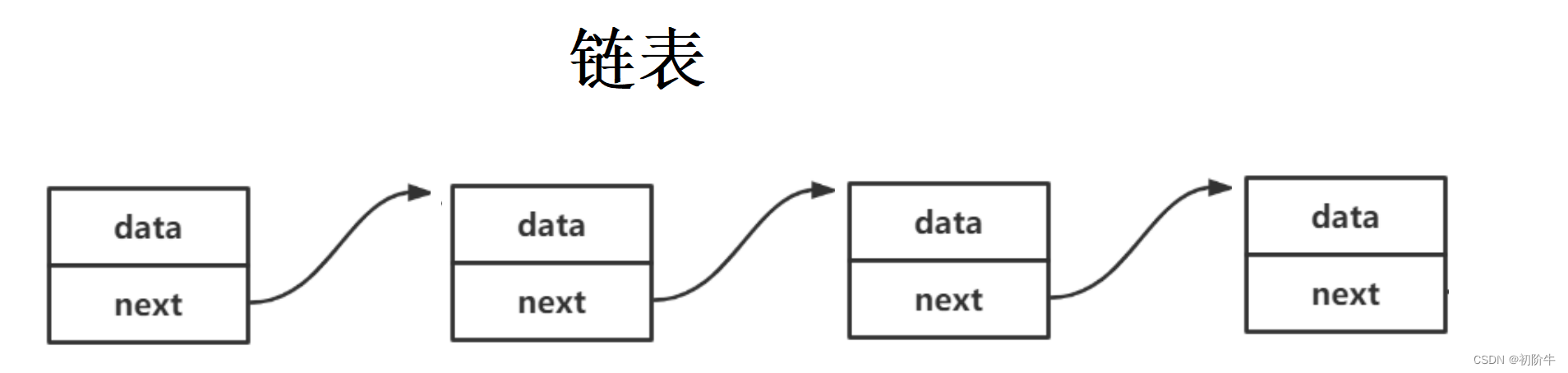
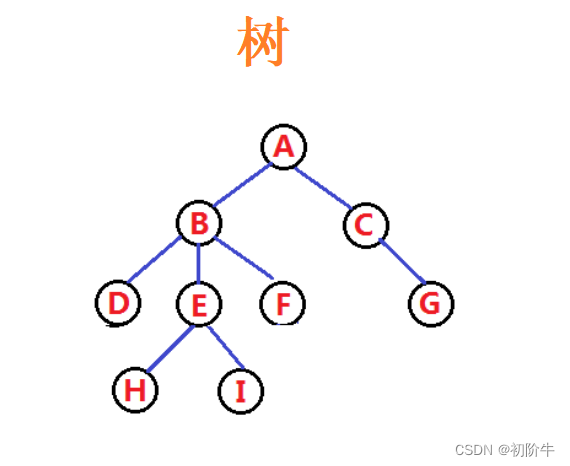
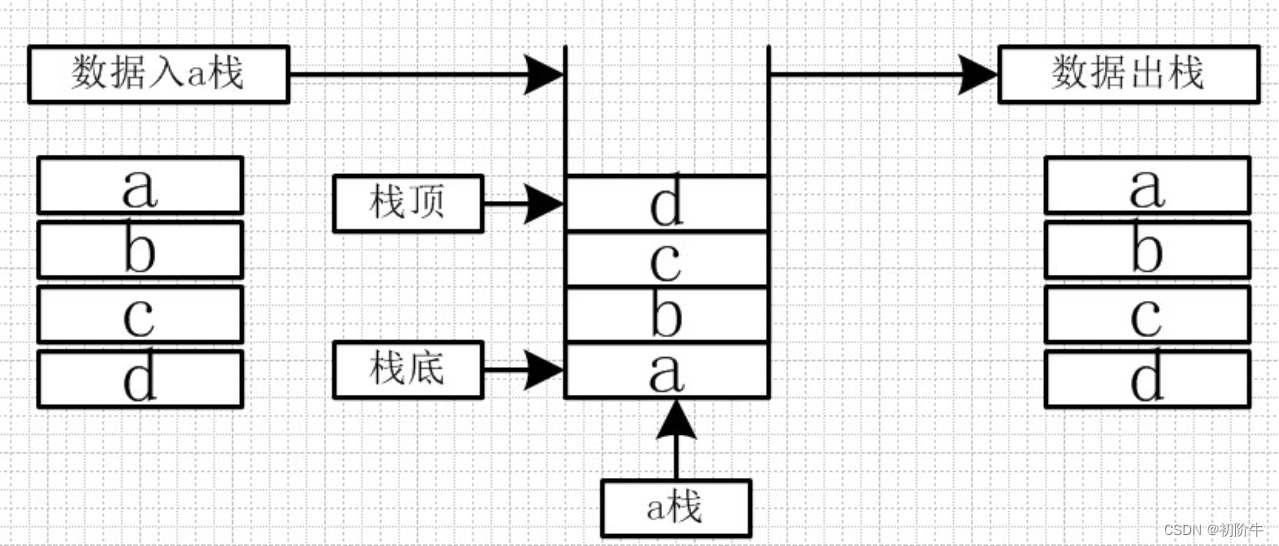
数据结构(Data Structure):是计算机存储、组织数据的方式,指相互之间存在一种或多种特定关系的数据元素的集合。
例如后面会提到的顺序表,链表这些线性数据结构,还有后面的二叉树树形数据结构等.
算法(Algorithm):就是定义良好的计算过程,他取一个或一组的值为输入,并产生出一个或一组值作为输出。简单来说算法就是一系列的计算步骤,用来将输入数据转化成输出结果.
例如:排序算法.
数据结构与算法对于一个程序员是很重要的,不论对你思考问题的方式还是对你编程的思维都会有很大的好处。同时在找工作时算法也是一个重要考点之一.
1.多多练习代码.

数据结构的学习并不简单,需要多锻炼代码能力,最怕偷懒,很多时候头脑虽然理解了,但是动起手来写代码会忽略很多细节,导致程序出错,不能光有思路,而代码能力却实现不了就很尴尬了.
2.多画图(这个强烈推荐)
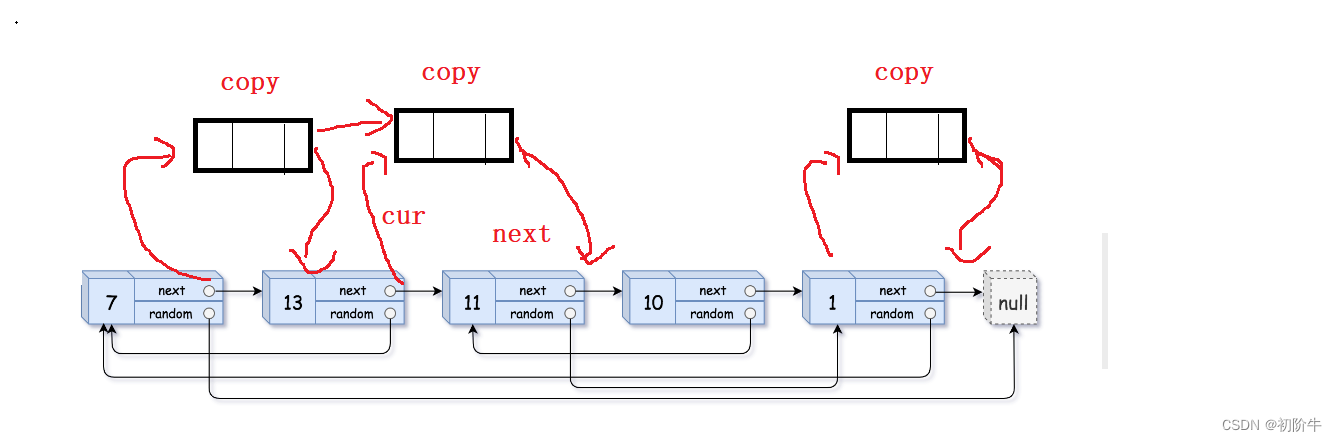
除了代码能力需要锻炼以外,很重要的一点是要有思路,通过画图辅助,可以很好地帮助我们找到思路和理解数据结构中的很多思想,切忌上来就开始码代码,这样对于简单的问题可能可以解决,但是对于稍微复杂的问题可能会让你头痛(大佬除外😂😂),很容易被绕进去,陷入痛苦的调试找bug环节.
画图会让提供给我们清晰的思路,同时,即使出现了bug,也可以很快的找到,清晰可见.写代码只是用于实现思路,思路清晰,代码写起来并不困难.
3.刷题
刷题会锻炼我们的思考能力,解题是一种很灵活的事情.一方面可以巩固我们学的基础知识,另一方面可以拓展思维.
最后,坚持学习才是最重要的.

对于一个问题,可以有很多解法,那怎样衡量一个算法的好坏呢?
比谁的代码更简洁吗?
算法的效率主要考虑两点:1.时间复杂度. 2.空间复杂度
一个算法在编译生成可执行文件后,运行时会耗费时间资源和空间(内存)资源 。
从时间和空间两个维度来衡量一个算法的好坏是比较合理的,这就是时间复杂度和空间复杂度。
时间复杂度主要衡量一个算法的运行快慢,而空间复杂度主要衡量一个算法运行所需要的额外空间。在计算机发展的早期,计算机的存储容量很小。所以对空间复杂度很是在乎。但是经过计算机行业的迅速发展,计算机的存储容量已经达到了很高的程度。所以我们如今已经不需要再特别关注一个算法的空间复杂度。
时间复杂度的定义:在计算机科学中,算法的时间复杂度是一个函数,它定量描述了该算法的运行时间。一个算法执行所耗费的时间.
但是从理论上说,这个只有将代码进行测试,并统计时间才能知道.并不能通过计算得到.
但对于每一个算法,我们都去跑一下,这未免显得有些麻烦,我们可以通过算法中的代码估计运行大概的时间,看看属于哪一个量级来衡量它的效率.
算法中的基本操作的执行次数,为算法的时间复杂度。
即:找到某条基本语句与问题规模N之间的数学表达式,就是算出了该算法的时间复杂度
理论不是很理解的话,我们来点实际的,找几段代码算算吧!
🌰小试牛刀
你能算出在test1中++count语句最终被执行了多少次吗?
void test1(int N)
{
int count = 0;
//1
for (int i = 0; i < N; i++)
{
for (int j = 0; j < N; j++)
{
++count;
}
}
//2
for (int k = 0; k < N; k*=2)
{
++count;
}
//3
for (int k = 0; k < 2 * N; k++)
{
++count;
}
//4
int a = 100;
while (a--)
{
++count;
}
printf("%d\n", count);
}
答案:
1: N * N
2: log2 N
3. 2*N
4. 100
则我们可以抽象出这样的数学公式:
test(N)=N2 +log2 N+2N+100
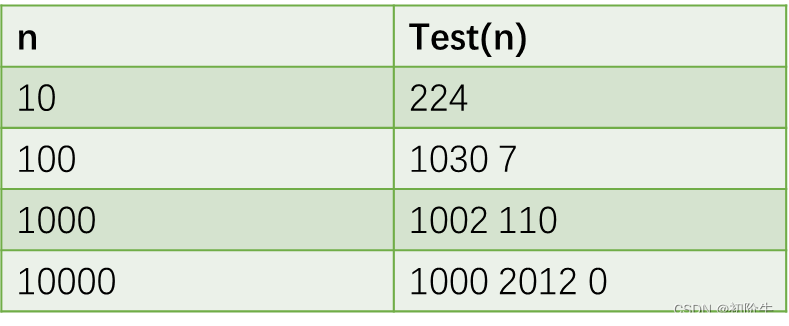
计算机的运行速度是很快的,对于时间复杂度的计算,没有必要追求那么精确,对于那些对结果影响不大的项,我们可以忽略不计.如果我们只保留N2这一起决定因素的项.
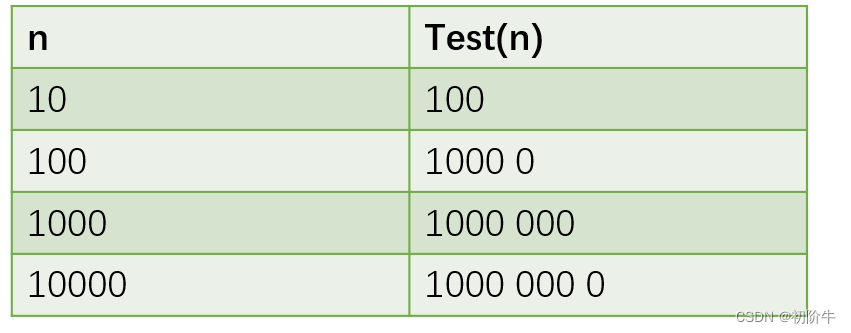
大O阶方法计算方法:
使用大O的渐进表示法以后,test1的时间复杂度为:
| (O)N ^ 2 |
即使是100N系数也应当去掉,因为当数据足够大的时候100的影响并不大.
只要是常数,都应当是1.
也许你会认为100很大或者100000很大.但是,要看和谁比,如果是和10亿比呢?一万亿比呢?
那我们打个比方:
你觉得你们学校大吗?还行.
你所在的城市大吗?算大吧!
你觉得我们的祖国大吗?地大物博,确实大.
但是,与太阳系相比呢?与银河系相比呢?这就显得很渺小了,沧海之一粟罢了.
所以当数据量足够大的时候,常数项和那些影响不大的忽略不计.

例1:
// 计算Test2的时间复杂度?
void Test2(int N)
{
int count = 0;
for (int i = 0; i < 2 * N ; i++)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n", count);
}
例2:
// 计算Test3的时间复杂度?
void Test3(int N, int M)
{
int count = 0;
for (int i = 0; k < M; i++)
{
++count;
}
for (int i = 0; i < N ; i++)
{
++count;
}
printf("%d\n", count);
}
例3:
// 计算Test4的时间复杂度?
void Test4(int N)
{
int count = 0;
for (int i = 0; i < 10000; i++)
{
++count;
}
printf("%d\n", count);
}
答案:
这三个例子的时间复杂度还是很好计算的.
例1:
2N+10用大O表示法表示时间复杂度为O(N).
例2:
基本操作执行了M+N次,有两个未知数M和N,时间复杂度为 O(N+M)
如果m和n相等则可以表示为O(N),如果一方远大于另一方,则可以用大的一方表示,记住是远大于,即不在一个量级.
例3:
基本操作语句被执行了常数次.这用大O表示法表示时间复杂度为O(1).
那试着分析TargetNum函数的时间复杂度.
TargetNum函数是用于在一个数组中查找目标值的函数,找到了就返回目标值的地址,没找到就返回NULL.
int* TargetNum(int* arr,int n, int num)
{
for (int i = 0; i < n; i++)
{
if (arr[i] == num)//找到目标数字则返回数字的地址
{
return arr + i;
}
}
return NULL;
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int sz = sizeof(arr) / sizeof(arr[0]);
int num = 0;
scanf("%d", &num);
int*ret =TargetNum(arr, sz, num);
if (ret == NULL)
{
printf("该目标值不存在");
}
printf("%d ", *(ret));
if (ret + 1 <= &arr[sz - 1])
{
printf("%d ", *(ret + 1));
}
}
此时就让人有些疑惑了,这个函数的时间复杂度似乎不是固定的.在1~n的范围之间的那如何确定它的时间复杂度呢?

分析一下:
最好情况时(第一个数就是目标值): O(1).
平均情况时:O(n/2).
最坏情况时:O(n).
那我们选择哪种情况比较合理呢?
那我们讲一个小故事吧.
假如你是一名高中生,你刚经历期末考试,晚上,老师只公布了部分答案.
你可以确保自己可以拿到60分,有剩余的40分中,你按照以往的每次考试的经验来看,不出意外20分是可以拿到的.
此时回到家中,老爸问你能考多少分?考多少分老爸就奖励你多少钱,嘿嘿.🍭🍭🍭
你会说80(平均情况)分吗?还是会选择100分(最好情况)呢?
万一食言了呢?
咱一般都会选择最坏的情况,那样即使出现了意外,我们也没有说错,而不出意外时,无论是平均还是最好情况,我们都会比较高兴的.
这里牛牛也想告诉大家,结局未定之前,不要过分高看自己,降低期望,当然也不要自卑,继续努力,继续前行,保持对生活的热爱,生活也会拥抱你的!🍭🍭🍭
回到正题,此时我们会选择最坏的情况作为时间复杂度,即TargetNum函数的时间复杂度是O(n).
大家还记得c语言时学的冒泡排序吗?
// 计算BubbleSort的时间复杂度?
void BubbleSort(int* a, int n)
{
assert(a);
for (size_t end = n; end > 0; --end)
{
int exchange = 0;
for (size_t i = 1; i < end; ++i)
{
if (a[i-1] > a[i])
{
Swap(&a[i-1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
break;
}
}
那么最好情况和最坏情况时的时间复杂度分别是多少呢?
对于冒泡排序不熟悉的友友们可能会以为最好的情况时O(0)或者O(1).
首先呢,没有O(0)这一说法,这几乎不可能,其次这里最好的情况也不是O(1),为什么呢?
如果数组有序,那不就不需要排序吗?那不就是O(1)吗?
其实,即使数组有序,我们也需要循环遍历一遍这个数组,才能知道有序,计算机不是人哦,他不能看一眼就知道有序,而且就算是人,当数据量比较大的时候人一眼也看不出来是否有序吧!
总结:
最好情况:O(N)
最坏情况:O(N2)
int BinarySearch(int* a, int n, int x)
{
assert(a);
int begin = 0;
int end = n-1;
while (begin <= end)
{
int mid = (begin+end)/2;//找到中间值
if (a[mid] < x)//如果该值比中间值大,则直接从中间值的后半部分里面找
{
begin = mid+1;
}
else if (a[mid] > x)//如果该值比中间值小,则直接从中间值的前半部分里面找
{
end = mid-1;
}
else//找到了
return mid;
}
//没找到返回-1,这里设置为-1也许有些不合理,可以使用逻辑值.
return -1;
}
判断一次(与中间值比较),就可以去掉一半的值.即该算法一次N的值就会等于N/2.
不难得出该算法的时间复杂度是O(logn2).
补充知识:logn2经常省略写成log2甚至lg2
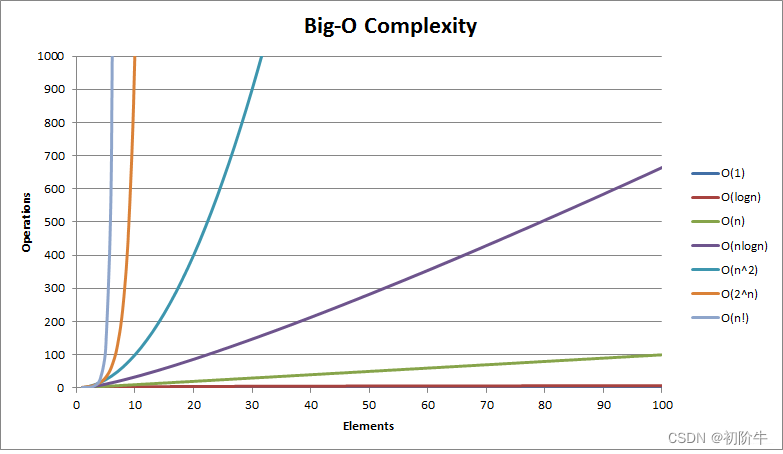
"二分查找"看起来平平无奇,但其实是个隐藏的大佬啊!
大家知道这些量级的差距有多大吗?log2是很可怕的量级,速度极快.
看图感受一下吧!
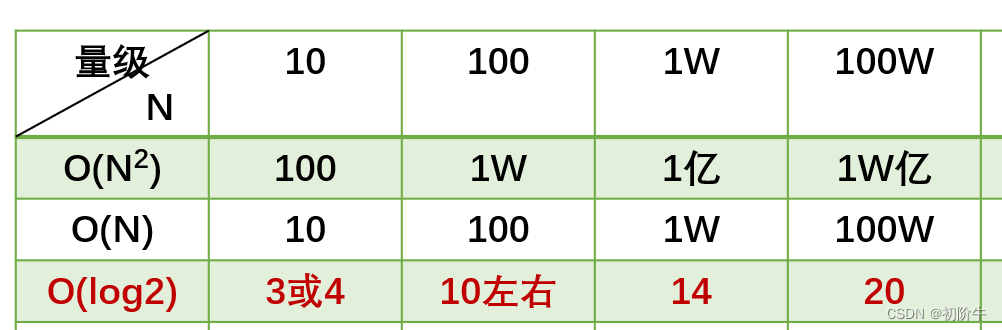
友友们感受到二分查找的厉害了吧!
遗憾的是,二分查找的前提是数据得是有序的,否则他无法实现一次排除一半.而数据往往是无序的,并且有些特殊的数据还不允许排序,排序会破坏数据的.
这也就让二分查找无计可施了,纸老虎罢了.😂😂😂
// 计算阶乘递归Fac的时间复杂度?
int Fac(int N)
{
if(0 == N)//递归的结束条件
{
return 1;
}
return Fac(N-1)*N;
}
递归的时间复杂度计算主要是根据其递归的层数来决定.
该算法每次递归N就-1,则递归的次数为N.
故算法的时间复杂度为:O(N).
// 计算斐波那契递归Fib的时间复杂度?
int Fib(int N)
{
if(N < 3)
return 1;
return Fib(N-1) + Fib(N-2);
}
此算法,每次经过递归都需要再递归2 * N次.
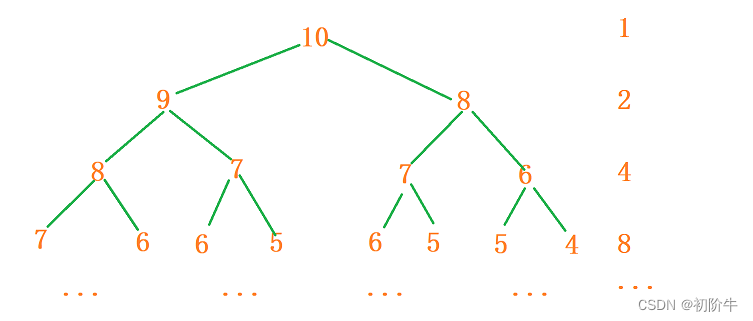
则此算法的时间复杂度为O(2n).
大O的渐进表示法:
空间复杂度并不是重点,现如今,一般情况下我们的时间的价值比空间的价值要高的多.
定义:
空间复杂度也是一个数学表达式,是对一个算法在运行过程中临时占用存储空间大小的量度 。
空间复杂度不是程序占用了多少bytes的空间,因为这个也没太大意义,所以空间复杂度算的是变量的个数。
空间复杂度计算规则基本跟实践复杂度类似,也使用大O渐进表示法。
注意:函数运行时所需要的栈空间(存储参数、局部变量、一些寄存器信息等)在编译期间已经确定好了,因此空间复杂度主要通过函数在运行时候显式申请的额外空间来确定
例题:
还是拿冒泡排序来举例吧!
void BubbleSort(int* a, int n)
{
assert(a);
for (size_t end = n; end > 0; --end)
{
int exchange = 0;
for (size_t i = 1; i < end; ++i)
{
if (a[i-1] > a[i])
{
Swap(&a[i-1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
break;
}
}
为了实现冒泡排序我们定义了int exchange = 0;以及Swap(&a[i-1], &a[i]);函数中的int tmp.
这项常数个临时变量,故空间复杂度为O(1).
例2:
int Fac(int N)
{
if(0 == N)//递归的结束条件
{
return 1;
}
return Fac(N-1)*N;
}
同样递归的空间复杂度由开辟的栈帧个数(每次递归开辟一次栈帧)决定,开辟了N个栈帧,每个栈帧使用了常数个空间。空间复杂度为O(N).
好了,数据结构的初步认识就到这里啦!后续牛牛会继续更新数据结构的相关知识.
如果文章对大家有用的话记得一键三连哦!💗💗💗
如果文章中有部分错误之处,可以私信牛牛,互相讨论哦!!!

我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我正在尝试在Rails上安装ruby,到目前为止一切都已安装,但是当我尝试使用rakedb:create创建数据库时,我收到一个奇怪的错误:dyld:lazysymbolbindingfailed:Symbolnotfound:_mysql_get_client_infoReferencedfrom:/Library/Ruby/Gems/1.8/gems/mysql2-0.3.11/lib/mysql2/mysql2.bundleExpectedin:flatnamespacedyld:Symbolnotfound:_mysql_get_client_infoReferencedf
文章目录1.开发板选择*用到的资源2.串口通信(个人理解)3.代码分析(注释比较详细)1.主函数2.串口1配置3.串口2配置以及中断函数4.注意问题5.源码链接1.开发板选择我用的是STM32F103RCT6的板子,不过代码大概在F103系列的板子上都可以运行,我试过在野火103的霸道板上也可以,主要看一下串口对应的引脚一不一样就行了,不一样的就更改一下。*用到的资源keil5软件这里用到了两个串口资源,采集数据一个,串口通信一个,板子对应引脚如下:串口1,TX:PA9,RX:PA10串口2,TX:PA2,RX:PA32.串口通信(个人理解)我就从串口采集传感器数据这个过程说一下我自己的理解,