 人们如今经常谈论元宇宙,总会离不开规模有多大、速度有多快、距离有多远、对企业的影响有多大等问题。那么面向2030年,元宇宙会有哪些发展趋势?会面临哪些机遇和挑战?以下是我们对2030年元宇宙的12个主要预测。
人们如今经常谈论元宇宙,总会离不开规模有多大、速度有多快、距离有多远、对企业的影响有多大等问题。那么面向2030年,元宇宙会有哪些发展趋势?会面临哪些机遇和挑战?以下是我们对2030年元宇宙的12个主要预测。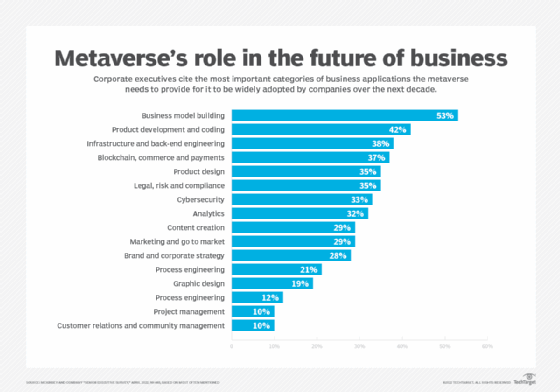
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
3月26日,映宇宙(HK:03700,即“映客”)发布截至2022年12月31日的2022年度业绩财务报告。财报显示,映宇宙2022年的总营收为63.19亿元,较2021年同期的91.76亿元下降31.1%。2022年,映宇宙的经营亏损为4698.7万元,2021年同期则为净利润4.57亿元;期内亏损(净亏损)为1.68亿元,2021年同期的净利润为4.33亿元;非国际财务报告准则经调整净利润为3.88亿元,2021年同期为4.82亿元,同比下降19.6%。 映宇宙在财报中表示,收入减少主要是由于行业竞争加剧,该集团对旗下产品采取更为谨慎的运营策略以应对市场变化。不过,映宇宙的毛利率则有所提升
这个问题在这里已经有了答案:Unabletoinstallgem-Failedtobuildgemnativeextension-cannotloadsuchfile--mkmf(LoadError)(17个答案)关闭9年前。嘿,我正在尝试在一台新的ubuntu机器上安装rails。我安装了ruby和rvm,但出现“无法构建gemnative扩展”错误。这是什么意思?$sudogeminstallrails-v3.2.9(没有sudo表示我没有权限)然后它会输出很多“获取”命令,最终会出现这个错误:Buildingnativeextensions.Thiscouldtakeawhi
我想知道如何从Apple.p12文件中提取key。根据我有限的理解,.p12文件是X504证书和私钥的组合。我看到我遇到的每个.p12文件都有一个X504证书和至少一个key,在某些情况下有两个key。这是因为每个.p12都有一个Apple开发人员key,有些还有一个额外的key(可能是Appleroot授权key)。我只考虑那些具有两个key的.p12文件是有效的。我的目标是区分具有一个key的.p12文件和具有两个key的.p12文件。到目前为止,我已经使用OpenSSL来检查X504文件和任何.p12的key。例如,我有这段代码可以检查目录中的所有.p12文件:Dir.glob(
我需要一个用于大型动态任务集合的调度程序。目前我正在查看resque-scheduler,rufus-scheduler,和clockwork.如果您提供有关选择使用哪一个(或其他替代方案)的建议,我将不胜感激。一些细节:有大量要定期执行的任务(最多100K)。最短执行周期为1h。新任务可能会不时出现。现有任务可能会更改或删除。调度延迟最小化在这里不是关键任务(可扩展性和可持续性最重要)。任务执行不是繁重的操作,可以轻松并行。总结,我需要类似cron的Ruby项目,它可以处理大量动态变化的任务集合。更新:我花了一天时间尝试调度库,现在我想简单总结一下新获得的经验。我已经不再关注Cloc
我正在开发一个类似微论坛的项目,其中一个特殊用户发布一条快速(接近推文大小)的主题消息,订阅者可以用他们自己的类似大小的消息来响应。直截了当,没有任何形式的“挖掘”或投票,只是每个主题消息的响应按时间顺序排列。但预计会有很高的流量。我们想根据它们引起的响应嗡嗡声来标记主题消息,使用0到10的等级。在谷歌上搜索了一段时间的趋势算法和开源社区应用示例,到目前为止已经收集到两个有趣的引用资料,但我还没有完全理解它们:Understandingalgorithmsformeasuringtrends,关于使用基线趋势算法比较维基百科页面浏览量的讨论,在SO上。TheBritneySpearsP
这里是初级程序员,只是想了解Ruby背后的过程sort使用飞船操作符时的方法.希望有人能帮忙。在以下内容中:array=[1,2,3]array.sort{|a,b|ab}...我明白sort一次比较一对数字,然后返回-1如果a属于b之前,0如果它们相等,或者1如果a应该遵循b.但是在降序排序的情况下,像这样:array.sort{|a,b|ba}...到底发生了什么?是否sort还是比较ab然后翻转结果?或者它是在解释return的-1,0和1具有相反的行为?换句话说,为什么要像这样将变量放在block中:array.sort{|b,a|ba}...结果与第一个示例中的排序模式相同?
require'openssl'ifARGV.length==2pkcs12=OpenSSL::PKCS12.new(File.read(ARGV[0]),ARGV[1])ppkcs12.certificateelseputs"Usage:load_cert.rb"end运行它会在Windows上产生错误,但在Linux上不会。错误:OpenSSL::PKCS12::PKCS12Error:PKCS12_parse:macverifyfailurefrom(irb):21:ininitializefrom(irb):21:innewfrom(irb):21fromC:/Ruby192/
一个非常明显的现象,正在发生——元宇宙正在被越来越多的人所推崇,无论是科技巨头,还是资本巨头,几乎都是如此。同时,区块链则正在一点一点地回归理性与客观。对于区块链来讲,这是一个好现象。它告诉我们,人们对于区块链的狂热而激进的认识,正在被一步又一步的校正和纠偏。由此,区块链行业的发展,将会真正进入到一个全新的发展阶段。 同以往人们仅仅只是将区块链看成是一个概念,并以此来获取资本和流量不同。当人们对于区块链的认识变得深入,资本和流量反倒不再是区块链玩家们真正关心的问题。至少从当下情况来看,那些依然还在区块链行业里坚守的玩家们,更多地在坚持长期主义,更多地在寻求区块链与行业结合的正确的方式和方
文章目录概述背景为何要存算分离优势**应用场景**存算分离产品技术流派华为JuiceFSHashDataXSKY概述背景Hadoop一出生就是奔存算一体设计,当时设计思想就是存储不动而计算(code也即是代码程序)动,负责调度Yarn会把计算任务尽量发到要处理数据所在的实例上,这也是与传统集中式存储最大的不同。为何当时Hadoop设计存算一体的耦合?要知道2006年服务器带宽只有100Mb/s~1Gb/s,但是HDD也即是磁盘吞吐量有50MB/s,这样带宽远远不够传输数据,网络瓶颈尤为明显,无奈之举只好把计算任务发到数据所在的位置。众观历史常言道天下分久必合合久必分,随着云计算技术的发展,数据