目录
在linux中 fork 函数时非常重要的函数,它从已存在进程中创建一个新进程。新进程为子进程,而原进程为父进程。
进程调用 fork ,当控制转移到内核中的 fork 代码后,内核会做如下工作:
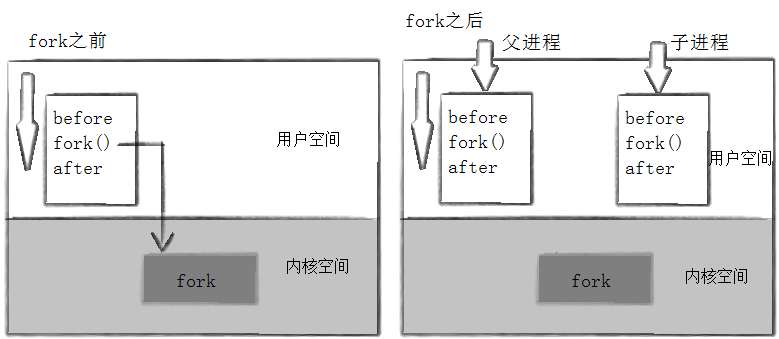
当一个进程调用 fork 之后,就有两个二进制代码相同的进程。而且它们都运行到相同的地方。但每个进程都将可以开始它们自己的旅程。即 fork 之前父进程独立执行, fork 之后,父子两个执行流分别执行。注意, fork 之后,谁先执行完全由调度器决定。
通常,父子代码共享,父子再不写入时,数据也是共享的,当任意一方试图写入,便以写时拷贝的方式各自一份副本。具体见下图:

进程退出共有以下三种场景:
当进程正常执行完后,会返回退出码。一般而言,当结果正确,退出码为 0 ,当结果不正确,退出码为 非 0 值,比如 1、2、3、4... ,分别对应不同的错误原因,供用户进行进程退出健康状态的判断。
使用如下代码进程举例说明:
1 #include <stdio.h>
2 #include <assert.h>
3 #include <unistd.h>
4
5
6 int add_to_top(int top)
7 {
8 int sum = 0;
9 for(int i = 0; i < top; ++i)
10 {
11 sum += i;
12 }
13 return sum;
14 }
15
16 int main()
17 {
18 int result = add_to_top(100);
19 if(result == 5050) return 0;//结果正确
20 else return 1;//结果不正确
21 }

计算从 1 到 100 的累加,如果结果等于 5050 ,则说明结果正确,正常返回 0,否则说明结果不正确,返回 1 。
查看进程返回结果的指令:
echo $?
根据我们自己所写的代码,返回值为 1 ,说明结果错误。
补充说明:
之后再输入 echo $? 后,显示的结果就都是 0 了:
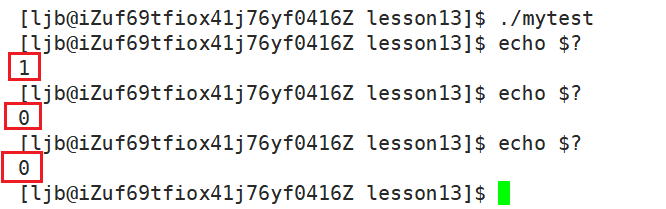
这时因为 $? 只会保留最近一次执行的进程的退出码。
关于C语言提供的进程退出码所代表的含义我们可以通过函数 strerror 来获取:
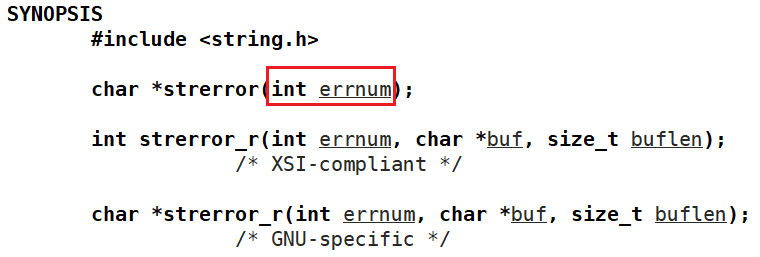
其中 errnum 为退出码。
我们编写如下代码来查看这些退出码的含义:
int main()
{
for(int i = 0; i < 140; ++i)
{
printf("%d : %s\n", i, strerror(i));
}
return 0;
}
由于输出结果较长,这里就不再全部放出,我截取了其中一部分:

观察到:如果返回值为 0,说明进程成功,如果返回值为 2, 说明没有这个文件或目录。
但是并不是所有指令的退出码都是根据C语言提供的进程退出码为基准的,比如:
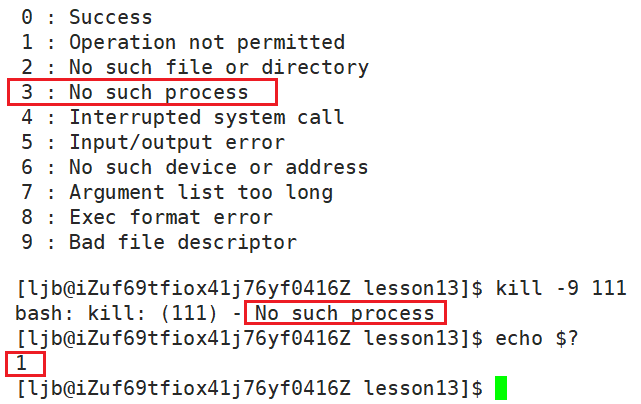
我们使用 kill -9 指令来杀死一个不存在的进程时所报的错误如果按照C语言的标准,退出码应该为3,但实际上退出码是 1 。
我们也可以自己来定义进程退出码的含义:

当一个进程退出时,OS中就少了一个进程,就要释放该进程对应的内核数据结构 + 代码和数据。
进程正常退出有三种方式:
众所周知,只有 main 函数 return 才标志进程退出,其他函数 return 仅仅代表函数返回,这说明进程执行的本质是 main 执行流执行。
前面的内容已经介绍过 return 退出的方式,接下来讲解 exit 函数退出的方式:
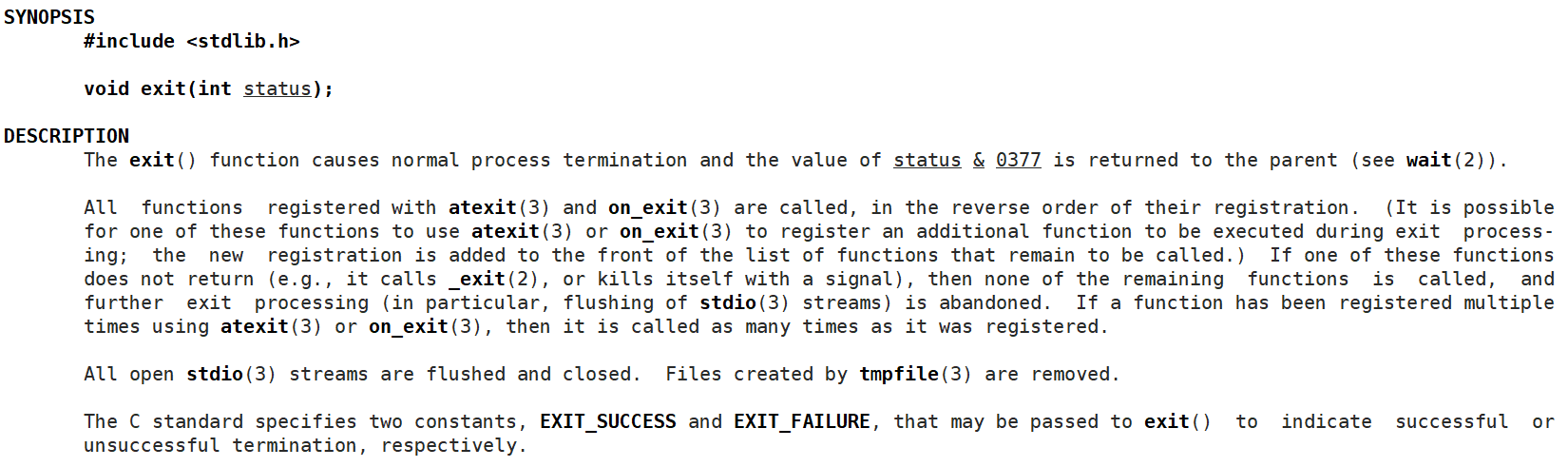
编写如下代码:
使用指令 echo $? 查看进程退出码:

看到退出码为我们自己写入的 123 。由此我们得知函数 exit(int code) 中的参数 code 代表的就是进程退出码。在代码的任意地方调用 exit 函数都表示进程退出。
函数 exit 为C标准库函数,除此之外还有一个 _exit 函数,该函数为系统调用。
其用法与 exit 相同。
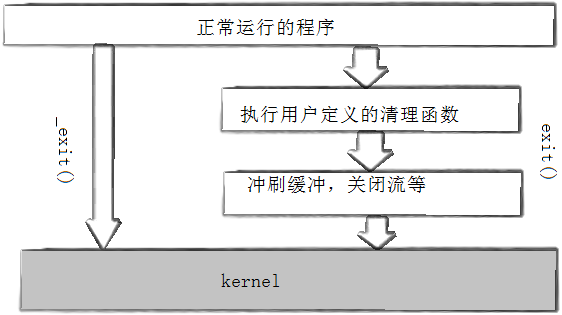
exit 与 _exit 的区别在于,exit 中封装了 _exit, exit最后也会调用_exit, 但在调用_exit之前,还做了其他工作:
进程等待就是通过系统调用,获取子进程退出码或者退出信号的方式,顺便释放内存。
等待进程有两种方式,分别为 wait 与 waitpid 。

返回值:成功返回被等待进程pid,失败返回-1。
参数:输出型参数,获取子进程退出状态,不关心则可以设置成为NULL。
编写如下代码:
1 #include <stdio.h>
2 #include <string.h>
3 #include <stdlib.h>
4 #include <unistd.h>
5 #include <sys/wait.h>
6 #include <sys/types.h>
7
8 int main()
9 {
10 pid_t id = fork();
11 if(id == 0)
12 {
13 //子进程
14 int cnt = 5;
15 while(cnt)
16 {
17 printf("子进程,剩余%dS, pid: %d, ppid: %d\n", cnt--, getpid(), getppid());
18 sleep(1);
19 }
20 exit(0);
21 }
22
23 //父进程
24 sleep(10);
25 pid_t ret_id = wait(NULL);
26 printf("父进程,等待子进程成功, pid: %d, ppid: %d, ret_id: %d\n", getpid(), getppid(), ret_id);
27 sleep(5);
28
29 return 0;
30 }

在命令行输入
while :; do ps ajx | head -1 && ps ajx | grep mytest | grep -v grep; sleep 1; echo "--------------"; done
运行观察结果:

可以观察到 mytest 进程的三个阶段,第一阶段,父子进程都在运行。第二阶段,子进程变为僵尸进程,父进程继续运行。第三阶段,经过等待,僵尸进程被回收,父进程继续运行。

函数 pid_ t waitpid(pid_t pid, int *status, int options);
1、返回值:
2、参数:
其中,waitpid函数的参数 status 是一个输出型参数,用于获取子进程的状态,即子进程的信号 + 退出码。我们可以把 status 看作位图:

整数 status 有 32 个比特位,我们只使用其中低 16 个比特位。
低16位中的次低 8 位代表退出状态,也成为退出码,低 7 位代表进程退出时收到的信号,如果为 0 ,就说明没有收到退出信号,为正常退出,如果信号不为 0 ,就说明进程是异常退出。只有在正常退出时,我们才会关注退出码。至于 core dump 以后再讲。
编写如下代码进行说明:
1 #include <stdio.h>
2 #include <string.h>
3 #include <stdlib.h>
4 #include <unistd.h>
5 #include <sys/wait.h>
6 #include <sys/types.h>
7
8 int main()
9 {
10 pid_t id = fork();
11 if(id == 0)
12 {
13 //子进程
14 int cnt = 5;
15 while(cnt)
16 {
17 printf("子进程,剩余%dS, pid: %d, ppid: %d\n", cnt--, getpid(), getppid());
18 sleep(1);
19 }
20 exit(123);
21 }
22
23 //父进程
24 int status = 0;
25 pid_t ret_id = waitpid(id, &status, 0);
26 printf("父进程,等待子进程成功, pid: %d, ppid: %d, ret_id: %d, child exit code: %d, child exit signal: %d\n", getpid(), getppid(), ret_id, (status>>8)&0xFF, status & 0x7F);
28
29 return 0;
30 }

运行结果如下:

子进程的信号为 0 ,退出码为 123 。符合我们的预期。
对于status,除了我们自己按位操作以外,也可以使用库提供的宏来替换:
WIFEXITED(status) :若为正常终止子进程返回的状态,则为真。(查看进程是否是正常退出)
WEXITSTATUS(status) :若WIFEXITED非零,提取子进程退出码。(查看进程的退出码)

我们知道子进程拥有自己的PCB结构 task_struct ,在task_struct中存在两个变量,分别为 int exit_code 与 int exit_signal 。当子进程退出时,OS会把退出码填写到 exit_code 中,把退出信号填写到 exit_signal 中,并维护子进程的 task_struct ,此时子进程的状态就是僵尸状态。通过 wait 或者 waitpid 系统调用可以访问到该内核数据结构,并把退出信息以上面所讲过的格式存放在 status 中,顺便释放该数据结构占用的内存空间。
了解了以上知识后,我们应该有一个疑问,父进程在等待子进程退出,并回收子进程。那么如果子进程一直都没有退出,父进程又在做什么呢?
默认情况下,在子进程没有退出的时候,父进程只能一直在调用 wait 或 waitpid 进行等待,我们称之为阻塞等待。关于阻塞的内容可以参考文章《进程概念》。

当子进程退出时,通过 parent 指针找到父进程,并把父进程放到运行队列中,继续执行 wait 或 waitpid 指令。
如果不想让父进程阻塞等待,则可以通过设置 waitpid 系统调用的参数 options 为 WNOHANG 来实现非阻塞轮询。
非阻塞轮询有三种结果:
1 #include <stdio.h>
2 #include <string.h>
3 #include <stdlib.h>
4 #include <unistd.h>
5 #include <sys/wait.h>
6 #include <sys/types.h>
7
8 int main()
9 {
10 pid_t id = fork();
11 if(id == 0)
12 {
13 //子进程
14 while(1)
15 {
16 printf("子进程, pid: %d, ppid: %d\n", getpid(), getppid());
17 sleep(1);
18 }
19 exit(0);
20 }
21 //父进程
22 while(1)
23 {
24
25 int status = 0;
26 pid_t ret_id = waitpid(id, &status, WNOHANG);
27 if(ret_id < 0)
28 {
29 printf("waitpid error!\n");
30 exit(1);
31 }
32 else if(ret_id == 0)
33 {
34 printf("子进程没退出,处理其他事情。。\n");
35 sleep(1);
36 continue;
37 }
38 else
39 {
40 printf("父进程,等待子进程成功, pid: %d, ppid: %d, ret_id: %d, child exit code: %d, child exit signal: %d\n", \
41 getpid(), getppid(), ret_id, (status>>8)&0xFF, status & 0x7F);
42 break;
43 }
44
45 }
46 return 0;
47 }
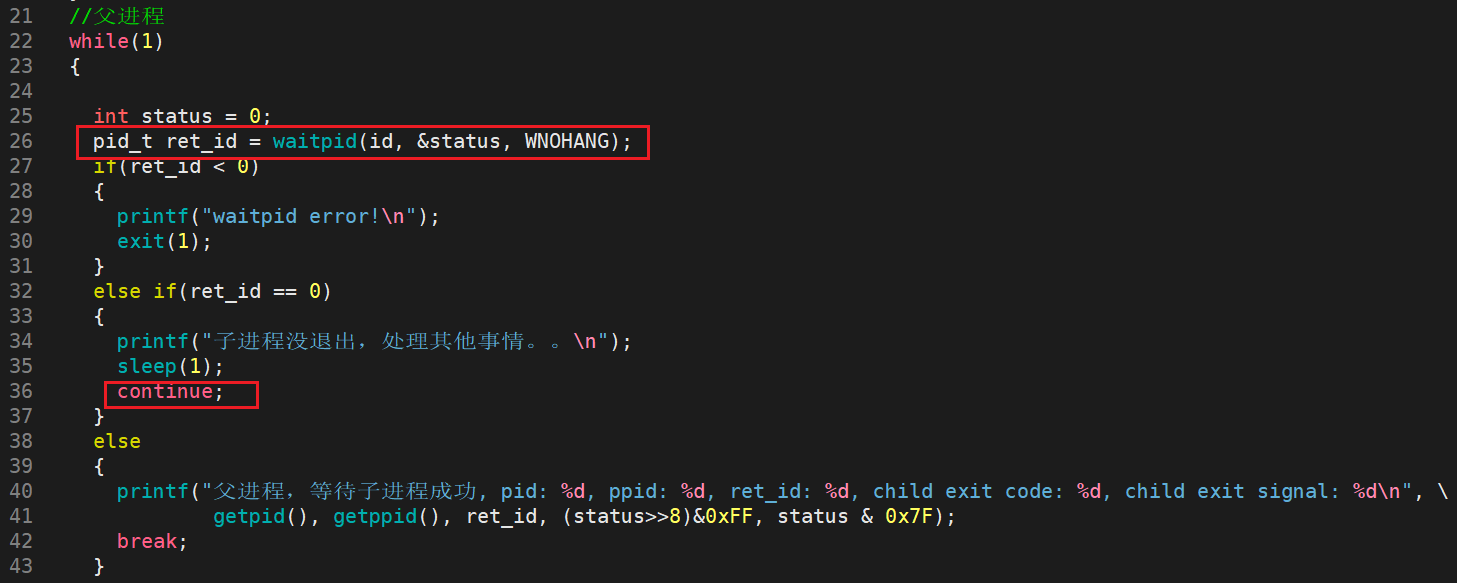
运行观察结果:

这就叫做父进程的非阻塞状态。
下面我们来写一个完整的父进程非阻塞代码:
1 #include <stdio.h>
2 #include <string.h>
3 #include <stdlib.h>
4 #include <unistd.h>
5 #include <sys/wait.h>
6 #include <sys/types.h>
7
8 #define TASK_NUM 10
9
10 //预设任务
11 void sync_dick()
12 {
13 printf("刷新数据\n");
14 }
15
16 void sync_log()
17 {
18 printf("同步日志\n");
19 }
20
21 void net_send()
22 {
23 printf("网络发送\n");
24 }
25
26 //要保存的任务
27 typedef void (*func_t)();
28 func_t other_task[TASK_NUM] = {NULL};
29
30
31 int LoadTask(func_t func)
32 {
33 int i = 0;
34 for(; i < TASK_NUM; ++i)
35 {
36 if(other_task[i] == NULL) break;
37 }
38 if(i == TASK_NUM) return -1;
39 else other_task[i] = func;
40
41 return 0;
42 }
43
44
45 void InitTask()
46 {
47 for(int i = 0; i < TASK_NUM; ++i) other_task[i] = NULL;
48 LoadTask(sync_dick);
49 LoadTask(sync_log);
50 LoadTask(net_send);
51 }
52
53 void RunTask()
54 {
55 for(int i = 0; i <TASK_NUM; ++i)
56 {
57 if(other_task[i] == NULL) continue;
58 other_task[i]();
59 }
60 }
61
62 int main()
63 {
64 pid_t id = fork();
65 if(id == 0)
66 {
67 //子进程
68 int cnt = 5;
69 while(cnt--)
70 {
71 printf("子进程, pid: %d, ppid: %d\n", getpid(), getppid());
72 sleep(1);
73 }
74 exit(123);
75 }
76 //父进程
77 InitTask();
78 while(1)
79 {
80
81 int status = 0;
82 pid_t ret_id = waitpid(id, &status, WNOHANG);
83 if(ret_id < 0)
84 {
85 printf("waitpid error!\n");
86 exit(1);
87 }
88 else if(ret_id == 0)
89 {
90 RunTask();
91 sleep(1);
92 continue;
93 }
94 else
95 {
96 if(WIFEXITED(status))
97 {
98 printf("wait success, child exit code: %d\n", WEXITSTATUS(status));
99 }
100 else
101 {
102 printf("wait success, child exit code: %d\n", status & 0x7F);
103 }
104 // printf("父进程,等待子进程成功, pid: %d, ppid: %d, ret_id: %d, child exit code: %d, child exit signal: %d\n", \
105 // getpid(), getppid(), ret_id, (status >> 8) & 0xFF , status & 0x7F);
106 break;
107 }
108
109 }
110 return 0;
111 }创建子进程无非就两种目的:
为了让子进程执行全新的程序代码,就需要进行程序替换。
用 fork 创建子进程后执行的是和父进程相同的程序(但有可能执行不同的代码分支),子进程往往要调用一种 exec 函数以执行另一个程序。当进程调用一种 exec 函数时,该进程的用户空间代码和数据完全被新程序替换,从新程序的启动例程开始执行。调用 exec 并不创建新进程,所以调用 exec 前后该进程的 id 并未改变。
程序原本存放在磁盘中,当调用 exec 函数时,被加载到了内存中。所以程序替换就相当于程序加载器,我们平常说程序被加载到内存中,其实就是调用了 exec 。在创建进程的时候,是先创建的进程数据结构PCB,再把代码和数据加载到内存的。
程序替换的接口函数:
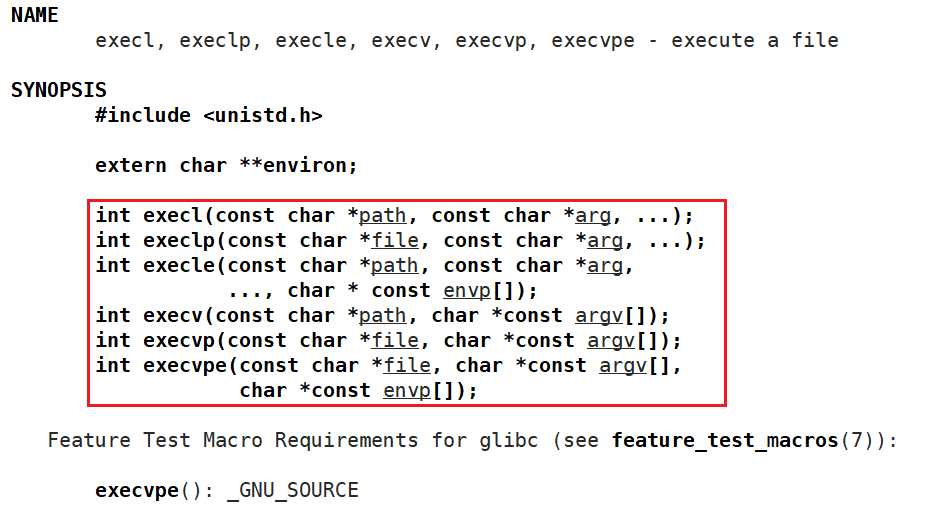
int execl(const char *path, const char *arg, ...);函数参数列表中的 "..." 为可变参数。可以让我们给C函数传递任意个数个参数。 path 为程序路径, arg 为命令 + 命令参数,最后一定要以 NULL 为结尾。
编写如下代码进行解释说明:
1 #include <unistd.h>
2 #include <stdio.h>
3 #include <stdlib.h>
4
5 int main()
6 {
7 printf("hello world\n");
8 printf("hello world\n");
9 printf("hello world\n");
10 printf("hello world\n");
11
12 execl("/bin/ls", "ls", "-a", "-l", NULL);
13
14 printf("can you see me\n");
15 printf("can you see me\n");
16 printf("can you see me\n");
17 printf("can you see me\n");
18 return 0;
19 }
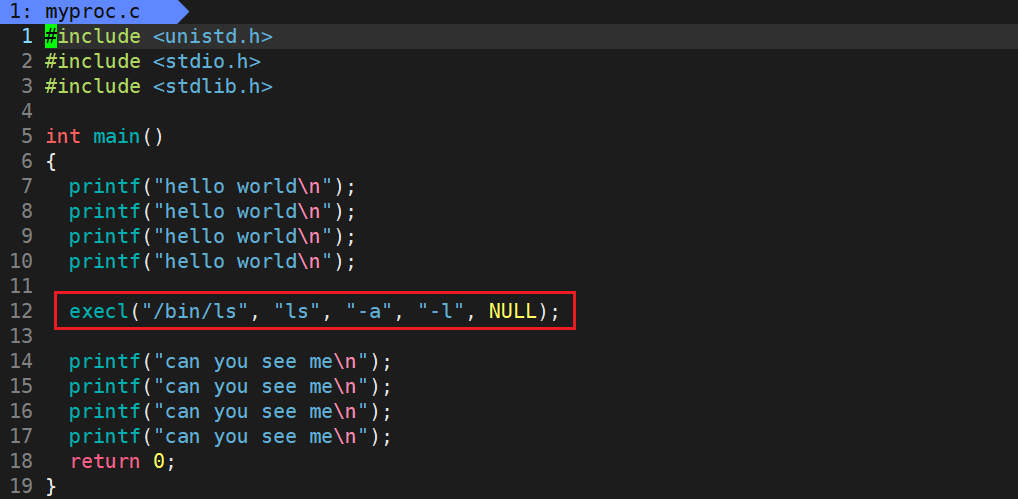
需要注意的是,命令参数一定要以 NULL 为结尾。
运行程序观察结果:

可以看到 execl 函数后,执行程序替换,新的代码和数据就被加载进内存了,后续的代码属于老代码,直接被替换掉,没机会再执行了。程序替换是整体替换,不能局部替换。
进程替换只会影响调用 execl 的进程,不会影响其他进程,包括父进程,因为进程具有独立性。换句话说,子进程加载新程序的时候,是需要进行程序替换的,发生代码的写时拷贝。
补充内容:
我们知道 execl 是一个函数,也有可能调用失败。如果程序替换失败,进程会继续执行老代码,并且 execl 一定会有返回值。反之,如果程序替换成功,则 execl 一定没有返回值。只要 execl 有返回值,则程序替换一定失败了。
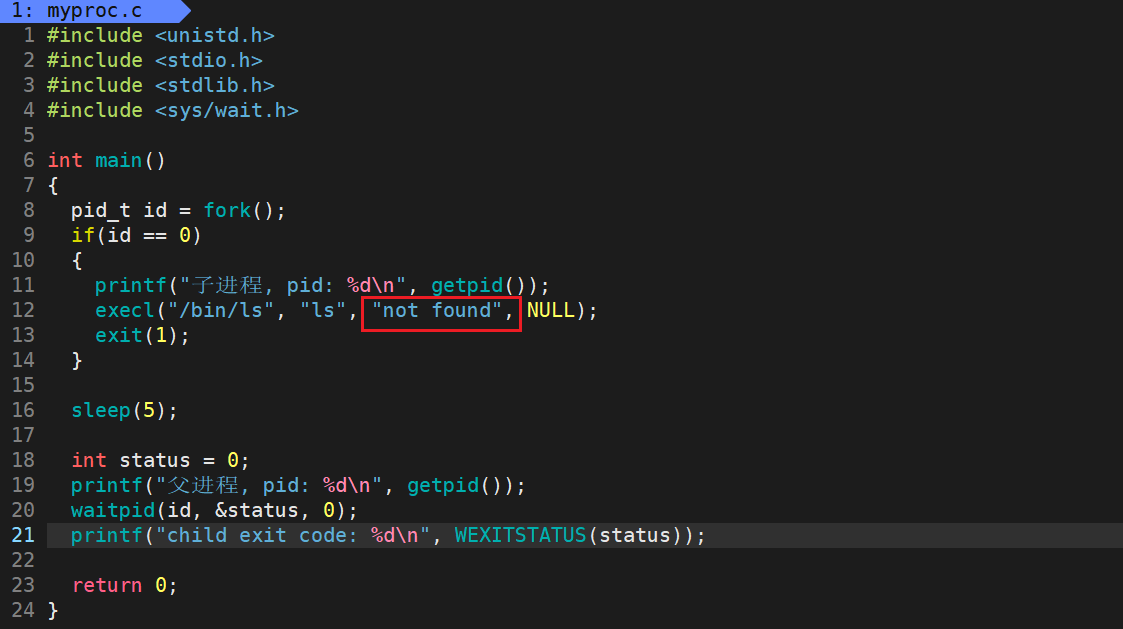
如果程序替换成功,新程序的退出码会返回给子进程,同样可以被父进程拿到:
1 #include <unistd.h>
2 #include <stdio.h>
3 #include <stdlib.h>
4 #include <sys/wait.h>
5
6 int main()
7 {
8 pid_t id = fork();
9 if(id == 0)
10 {
11 printf("子进程, pid: %d\n", getpid());
12 execl("/bin/ls", "ls", "not found", NULL);
13 exit(1);
14 }
15
16 sleep(5);
17
18 int status = 0;
19 printf("父进程, pid: %d\n", getpid());
20 waitpid(id, &status, 0);
21 printf("child exit code: %d\n", WEXITSTATUS(status));
22
23 return 0;
24 } 因为 ls 指令没有 "not found" 命令选项,所以新程序一定会返回对应的退出码给子进程,并最终被父进程获取:

int execv(const char *path, char *const argv[]);函数参数列表中, path 为程序路径, argv 数组内存放 命令 + 命令参数。 execl 与 execv 只在传参形式上有所不同。
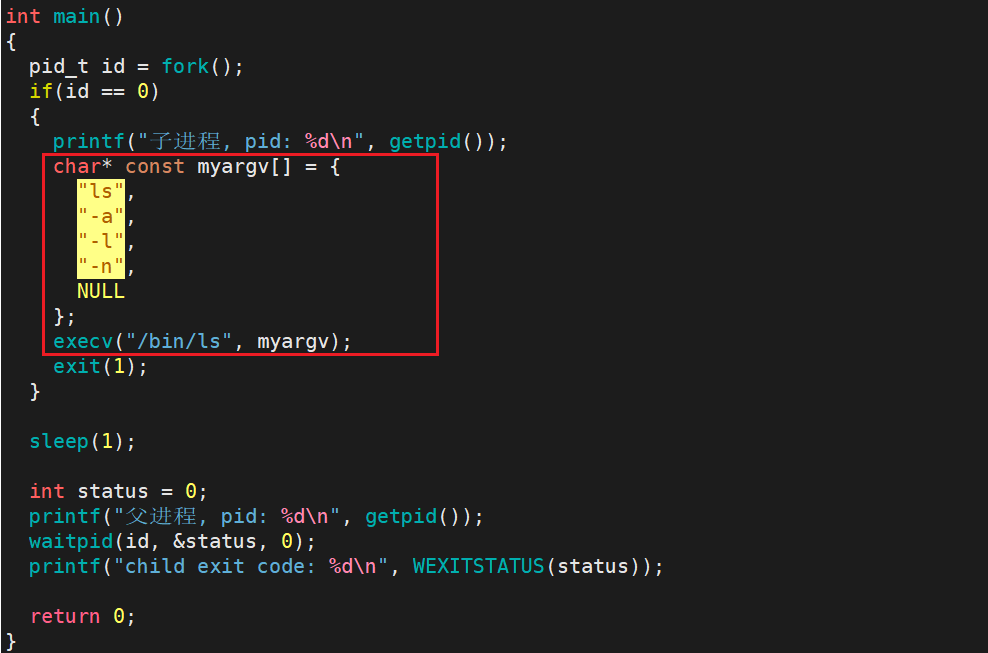
观察结果:
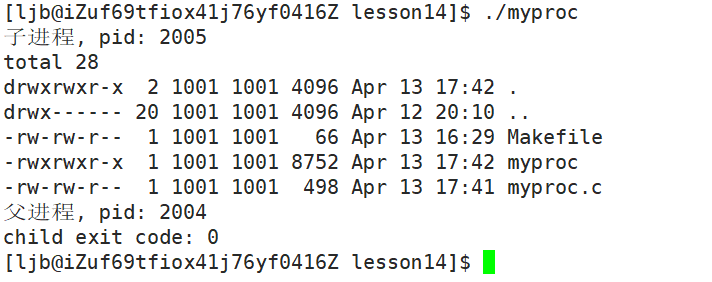
int execlp(const char *file, const char *arg, ...);函数参数列表中, file 为程序名, arg 为命令 + 命令参数, "..." 为可变参数。除了 file 外,其他用法与 execl 相同。
当我们执行指定程序的时候,只需要指定程序名即可,系统会自动在环境变量 PATH 中进行查找。
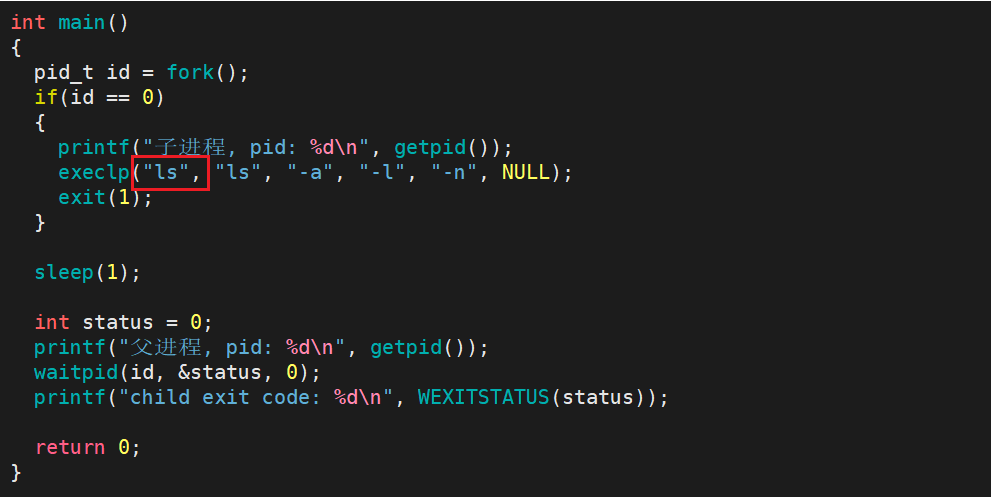
查看运行结果:
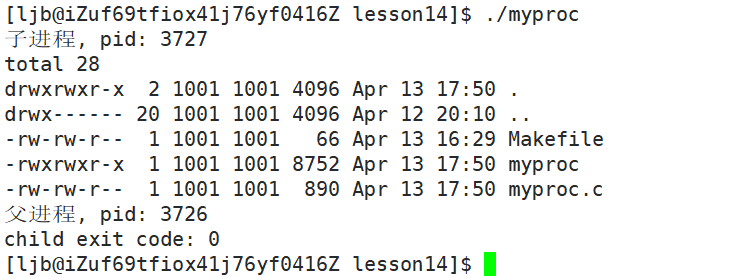
int execvp(const char *file, char *const argv[]);函数参数列表中, file 为程序名, argv 数组内存放命令 + 命令参数。

int execle(const char *path, const char *arg,
..., char * const envp[]);
execle 的函数参数列表中,比 execl 多了一个 envp , envp 为自定义环境变量。
我们在当前目录的子目录 exec 里再编写一个可执行文件 otherproc :
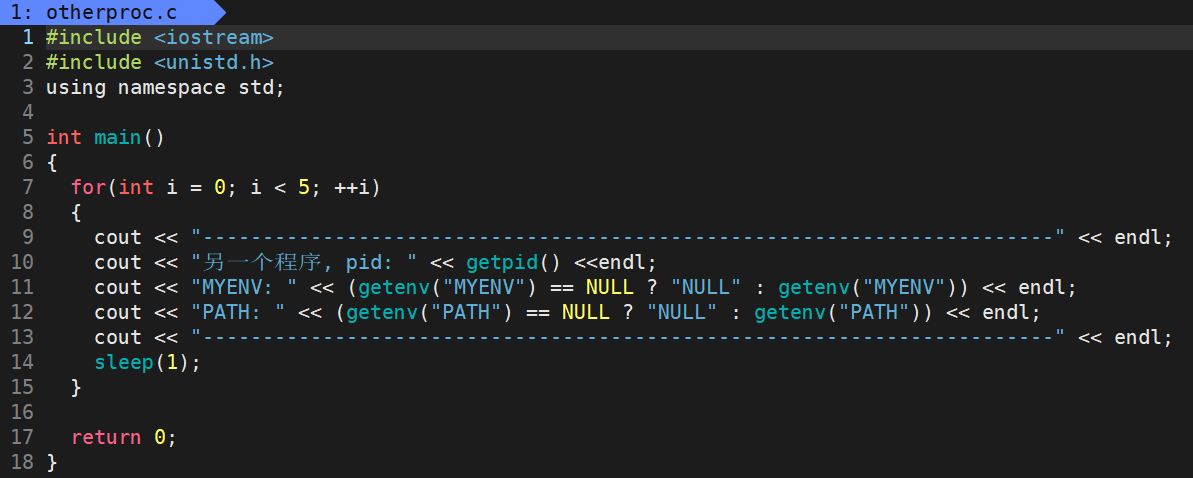
观察运行结果:

可以发现该子进程没有环境变量 MYENV 。
现在我们接着编写之前的 myproc 程序:

在 myproc 中使用 execle 函数调用 otherproc 程序,并给该程序传递环境变量 MYENV 。
运行并观察结果:

发现 otherproc 进程中已经有了环境变量 MYENV ,但是 PATH 却没有了。这是因为函数 execle 传递环境变量表是覆盖式传递的,老的环境变量表被全部清空了,只保留我们传递的自定义环境变量。
如果我们想在原有环境变量的基础上给进程添加环境变量,则可以使用函数 putenv :
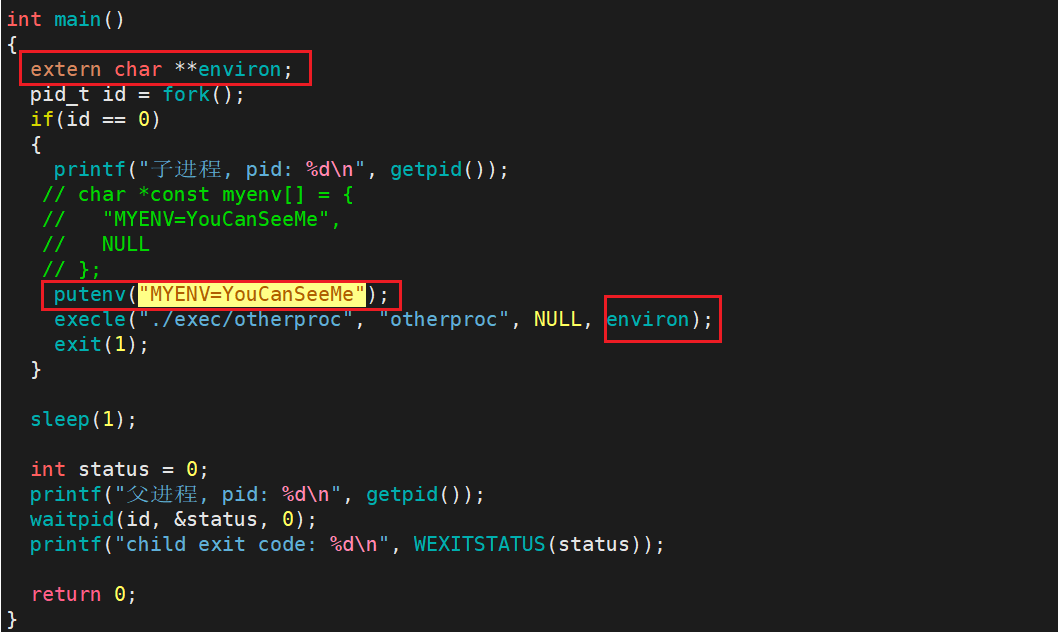
运行观察结果:

此时就可以得到预期的结果了。
因为所有的进程都是 bash 的子进程,而 bash 执行所有的指令都可以直接通过 exec 来执行,如果需要把环境变量交给子进程,只需要调用 execle 就可以了。因此,我们成环境变量具有全局属性。
这些函数原型看起来很容易混,但只要掌握了规律就很好记。

事实上,只有 execve 是真正的系统调用,其它函数都是 execve 的封装,最终都要调用 execve 。
关于进程控制的相关内容就讲到这里,希望同学们多多支持,如果有不对的地方欢迎大佬指正,谢谢!
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我正在编写一个gem,我必须在其中fork两个启动两个webrick服务器的进程。我想通过基类的类方法启动这个服务器,因为应该只有这两个服务器在运行,而不是多个。在运行时,我想调用这两个服务器上的一些方法来更改变量。我的问题是,我无法通过基类的类方法访问fork的实例变量。此外,我不能在我的基类中使用线程,因为在幕后我正在使用另一个不是线程安全的库。所以我必须将每个服务器派生到它自己的进程。我用类变量试过了,比如@@server。但是当我试图通过基类访问这个变量时,它是nil。我读到在Ruby中不可能在分支之间共享类变量,对吗?那么,还有其他解决办法吗?我考虑过使用单例,但我不确定这是
当我在Rails控制台中按向上或向左箭头时,出现此错误:irb(main):001:0>/Users/me/.rvm/gems/ruby-2.0.0-p247/gems/rb-readline-0.4.2/lib/rbreadline.rb:4269:in`blockin_rl_dispatch_subseq':invalidbytesequenceinUTF-8(ArgumentError)我使用rvm来管理我的ruby安装。我正在使用=>ruby-2.0.0-p247[x86_64]我使用bundle来管理我的gem,并且我有rb-readline(0.4.2)(人们推荐的最少
我正在使用Ruby2.1.1和Rails4.1.0.rc1。当执行railsc时,它被锁定了。使用Ctrl-C停止,我得到以下错误日志:~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.2/lib/spring/client/run.rb:47:in`gets':Interruptfrom~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.2/lib/spring/client/run.rb:47:in`verify_server_version'from~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.
我将我的Rails应用程序部署到OpenShift,它运行良好,但我无法在生产服务器上运行“Rails控制台”。它给了我这个错误。我该如何解决这个问题?我尝试更新rubygems,但它也给出了权限被拒绝的错误,我也无法做到。railsc错误:Warning:You'reusingRubygems1.8.24withSpring.UpgradetoatleastRubygems2.1.0andrun`gempristine--all`forbetterstartupperformance./opt/rh/ruby193/root/usr/share/rubygems/rubygems
说在前面这部分我本来是合为一篇来写的,因为目的是一样的,都是通过独立按键来控制LED闪灭本质上是起到开关的作用,即调用函数和中断函数。但是写一篇太累了,我还是决定分为两篇写,这篇是调用函数篇。在本篇中你主要看到这些东西!!!1.调用函数的方法(主要讲语法和格式)2.独立按键如何控制LED亮灭3.程序中的一些细节(软件消抖等)1.调用函数的方法思路还是比较清晰地,就是通过按下按键来控制LED闪灭,即每按下一次,LED取反一次。重要的是,把按键与LED联系在一起。我打算用K1来作为开关,看了一下开发板原理图,K1连接的是单片机的P31口,当按下K1时,P31是与GND相连的,也就是说,当我按下去时
在我的Character模型中,我添加了:字符.rbbefore_savedoself.profile_picture_url=asset_path('icon.png')end但是,对于数据库中已存在的所有角色,它们的profile_picture_url为nil。因此,我想进入控制台并遍历所有这些并进行设置。在我试过的控制台中:Character.find_eachdo|c|c.profile_picture_url=asset_path('icon.png')end但这给出了错误:NoMethodError:undefinedmethod`asset_path'formain:O
我正在尝试使用以下代码通过将ffmpeg实用程序作为子进程运行并获取其输出并解析它来确定视频分辨率:IO.popen'ffmpeg-i'+path_to_filedo|ffmpegIO|#myparsegoeshereend...但是ffmpeg输出仍然连接到标准输出并且ffmepgIO.readlines是空的。ffmpeg实用程序是否需要一些特殊处理?或者还有其他方法可以获得ffmpeg输出吗?我在WinXP和FedoraLinux下测试了这段代码-结果是一样的。 最佳答案 要跟进mouviciel的评论,您需要使用类似pope
我目前正在用Ruby编写一个项目,它使用ActiveRecordgem进行数据库交互,我正在尝试使用ActiveRecord::Base.logger记录所有数据库事件具有以下代码的属性ActiveRecord::Base.logger=Logger.new(File.open('logs/database.log','a'))这适用于迁移等(出于某种原因似乎需要启用日志记录,因为它在禁用时会出现NilClass错误)但是当我尝试运行包含调用ActiveRecord对象的线程守护程序的项目时脚本失败并出现以下错误/System/Library/Frameworks/Ruby.frame
当我进入Rails控制台时,我已将pry设置为加载代替irb。我找不到该页面或不记得如何将其恢复为默认行为,因为它似乎干扰了我的Rubymine调试器。有什么建议吗? 最佳答案 我刚发现问题,pry-railsgem。忘记了它的目的是让“railsconsole”打开pry。 关于ruby-on-rails-带有Pry的Rails控制台,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/question