
俗话话说的号,没有金刚钻,也不揽那瓷器活;日志分析可以说是所有大小系统的标配了,不知道有多少菜鸟程序员有多喜欢日志,如果没了日志,那自己写的bug想不被别人发现,可就难了;
有了它,就可将bug们统统消化在自己手里。
当然了,作为一个架构师搭建动手搭建一个日志平台也基本是必备技能了,虽然我们说架构师基本不咋写代码了,但是如果需要的时候,还是能扛枪的
大家可以看下架构师要具备的能力:
那些年薪50万,却不写代码的程序员,到底赢在哪?
原来,百万年薪的架构师都是这样使用redis的!
ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash和Kibana。Elasticsearch和Kibana我们上面做过讲解。 Logstash 主要是用来日志的搜集、分析、过滤日志的工具,适用大数据量场景, 一般采用c/s模式,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作, 再一并发往Elasticsearch上做数据分析。
一个完整的集中式日志系统,需要包含以下几个主要特点:
ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用,是目前主流的一种日志分析平台。
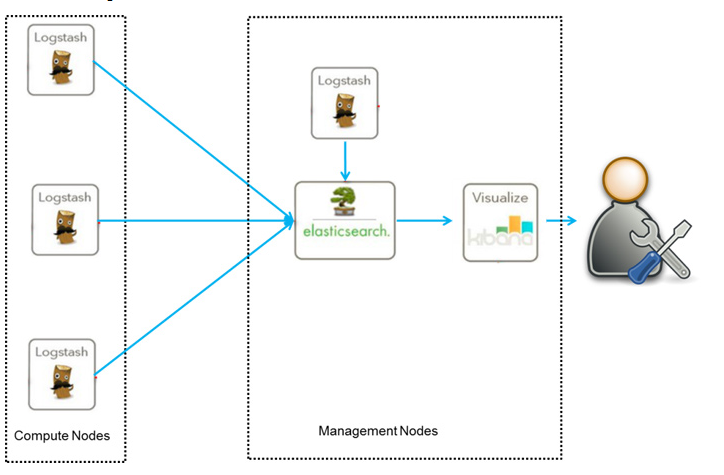
这是最简单的一种ELK部署架构方式, 由Logstash分布于各个节点上搜集相关日志、数据,并经过分析、过滤后发送给远端服务器上的Elasticsearch进行存储。 优点是搭建简单, 易于上手, 缺点是Logstash耗资源较大, 依赖性强, 没有消息队列缓存, 存在数据丢失隐患
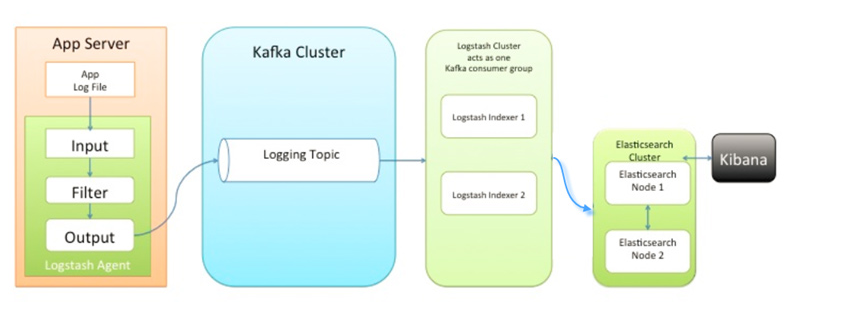
该队列架构引入了KAFKA消息队列, 解决了各采集节点上Logstash资源耗费过大, 数据丢失的问题, 各终端节点上的Logstash Agent 先将数据/日志传递给Kafka, 消息队列再将数据传递给Logstash, Logstash过滤、分析后将数据传递给Elasticsearch存储, 由Kibana将日志和数据呈现给用户。
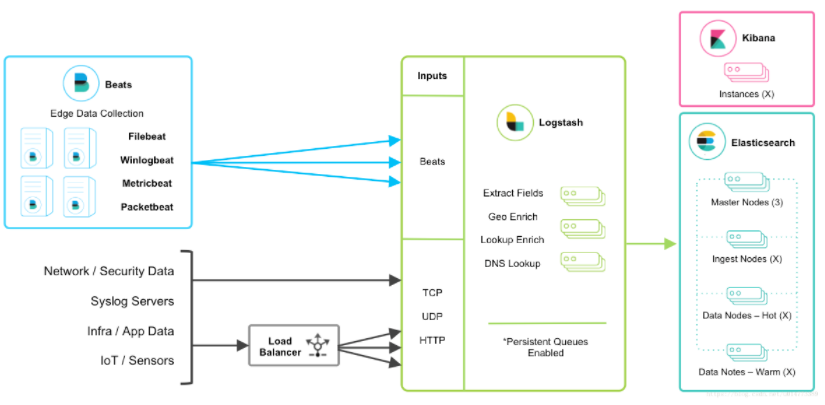
该架构的终端节点采用Beats工具收集发送数据, 更灵活,消耗资源更少,扩展性更强。同时可配置Logstash 和Elasticsearch 集群用于支持大集群系统的运维日志数据监控和查询, 官方也推荐采用此工具, 本章我们采用此架构模式进行配置讲解(如果在生产环境中, 可以再增加kafka消息队列, 实现了beats+消息队列的部署架构 )。
Beats工具包含四种:
1、Packetbeat(搜集网络流量数据)
2、Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
3、Filebeat(搜集文件数据)
4、Winlogbeat(搜集 Windows 事件日志数据)
Filebeat由两个主要组件组成:prospectors 和 harvesters。这两个组件协同工作将文件变动发送到指定的输出中。
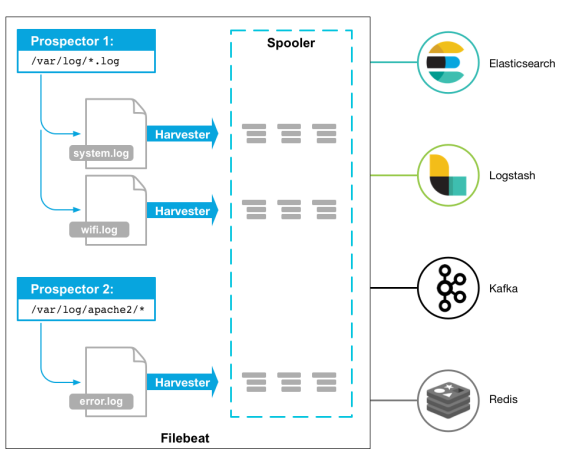
Harvester(收割机):负责读取单个文件内容。每个文件会启动一个Harvester,每个Harvester会逐行读取各个文件,并将文件内容发送到制定输出中。Harvester负责打开和关闭文件,意味在Harvester运行的时候,文件描述符处于打开状态,如果文件在收集中被重命名或者被删除,Filebeat会继续读取此文件。所以在Harvester关闭之前,磁盘不会被释放。默认情况filebeat会保持文件打开的状态,直到达到close_inactive
filebeat会在指定时间内将不再更新的文件句柄关闭,时间从harvester读取最后一行的时间开始计时。若文件句柄被关闭后,文件发生变化,则会启动一个新的harvester。关闭文件句柄的时间不取决于文件的修改时间,若此参数配置不当,则可能发生日志不实时的情况,由scan_frequency参数决定,默认10s。Harvester使用内部时间戳来记录文件最后被收集的时间。例如:设置5m,则在Harvester读取文件的最后一行之后,开始倒计时5分钟,若5分钟内文件无变化,则关闭文件句柄。默认5m】。
Prospector(勘测者):负责管理Harvester并找到所有读取源。
filebeat.prospectors:
- input_type: log
paths:
- /apps/logs/*/info.log
Prospector会找到/apps/logs/*目录下的所有info.log文件,并为每个文件启动一个Harvester。Prospector会检查每个文件,看Harvester是否已经启动,是否需要启动,或者文件是否可以忽略。若Harvester关闭,只有在文件大小发生变化的时候Prospector才会执行检查。只能检测本地的文件。
Filebeat如何记录发送状态:
将文件状态记录在文件中(默认在/var/lib/filebeat/registry)。此状态可以记住Harvester收集文件的偏移量。若连接不上输出设备,如ES等,filebeat会记录发送前的最后一行,并再可以连接的时候继续发送。Filebeat在运行的时候,Prospector状态会被记录在内存中。Filebeat重启的时候,利用registry记录的状态来进行重建,用来还原到重启之前的状态。每个Prospector会为每个找到的文件记录一个状态,对于每个文件,Filebeat存储唯一标识符以检测文件是否先前被收集。
Filebeat如何保证数据发送成功:
Filebeat之所以能保证事件至少被传递到配置的输出一次,没有数据丢失,是因为filebeat将每个事件的传递状态保存在文件中。在未得到输出方确认时,filebeat会尝试一直发送,直到得到回应。若filebeat在传输过程中被关闭,则不会再关闭之前确认所有时事件。任何在filebeat关闭之前未确认的事件,都会在filebeat重启之后重新发送。这可确保至少发送一次,但有可能会重复。可通过设置shutdown_timeout 参数来设置关闭之前的等待事件回应的时间(默认禁用)。
Logstash事件处理有三个阶段:inputs → filters → outputs。是一个接收,处理,转发日志的工具。支持系统日志,webserver日志,错误日志,应用日志等。
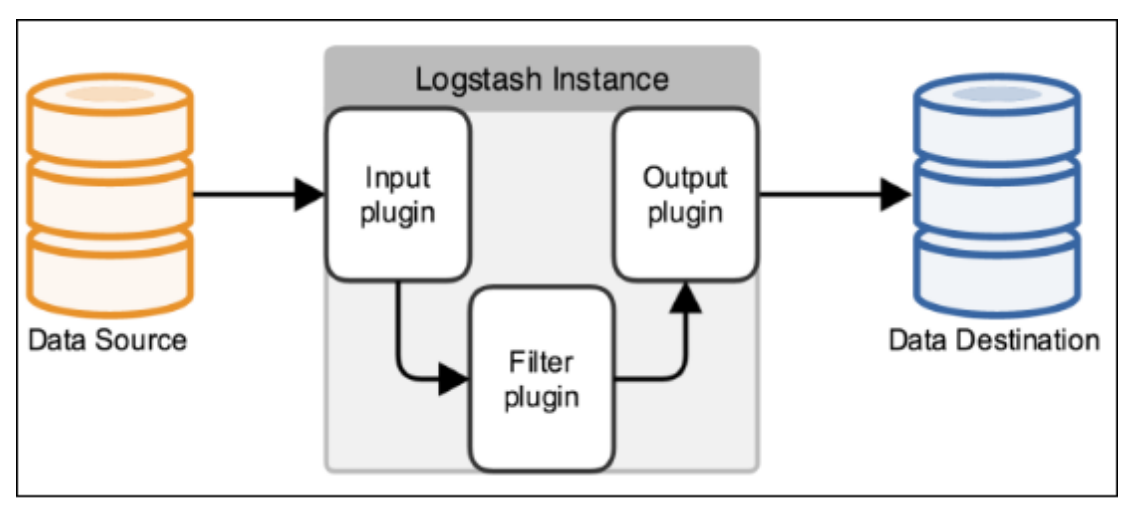
Input:输入数据到logstash。
支持的输入类型:
file:从文件系统的文件中读取,类似于tail -f命令
syslog:在514端口上监听系统日志消息,并根据RFC3164标准进行解析
redis:从redis service中读取
beats:从filebeat中读取
Filters:数据中间处理,对数据进行操作。
一些常用的过滤器为:
grok:解析任意文本数据,Grok 是 Logstash 最重要的插件。它的主要作用就是将文本格式的字符串,转换成为具体的结构化的数据,配合正则表达式使用。内置120多个解析语法。
mutate:对字段进行转换。例如对字段进行删除、替换、修改、重命名等。
drop:丢弃一部分events不进行处理。
clone:拷贝 event,这个过程中也可以添加或移除字段。
geoip:添加地理信息(为前台kibana图形化展示使用)
Outputs:outputs是logstash处理管道的最末端组件。
一个event可以在处理过程中经过多重输出,但是一旦所有的outputs都执行结束,这个event也就完成生命周期。
常见的outputs为:
elasticsearch:可以高效的保存数据,并且能够方便和简单的进行查询。
file:将event数据保存到文件中。
graphite:将event数据发送到图形化组件中,一个很流行的开源存储图形化展示的组件。
Codecs:codecs 是基于数据流的过滤器,它可以作为input,output的一部分配置。
Codecs可以帮助你轻松的分割发送过来已经被序列化的数据。
常见的codecs:
json:使用json格式对数据进行编码/解码。
multiline:将多个事件中数据汇总为一个单一的行。比如:java异常信息和堆栈信息。
在192.168.116.141机器节点上进行安装:
下载解压
下载:
cd /usr/local
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.10.2-linux-x86_64.tar.gz
解压:
tar -xvf logstash-7.10.2-linux-x86_64.tar.gz
创建数据存储与日志记录目录
[root@localhost logstash-7.10.2]# mkdir -p /usr/local/logstash-7.10.2/data
[root@localhost logstash-7.10.2]# mkdir -p /usr/local/logstash-7.10.2/logs
修改配置文件:
vi /usr/local/logstash-7.10.2/config/logstash.yml
配置内容:
# 数据存储路径
path.data: /usr/local/logstash-7.10.2/data
# 监听主机地址
http.host: "192.168.116.141"
# 日志存储路径
path.logs: /usr/local/logstash-7.10.2/logs
#启动监控插件
xpack.monitoring.enabled: true
#Elastic集群地址
xpack.monitoring.elasticsearch.hosts:["http://192.168.116.140:9200","http://192.168.116.140:9201","http://192.168.116.140:9202"]
创建监听配置文件:
vi /usr/local/logstash-7.10.2/config/logstash.conf
配置:
input {
beats {
# 监听端口
port => 5044
}
}
output {
stdout {
# 输出编码插件
codec => rubydebug
}
elasticsearch {
# 集群地址
hosts => ["http://192.168.116.140:9200","http://192.168.116.140:9201","http://192.168.116.140:9202"]
}
}
启动服务:
以root用户身份执行:
## 后台启动方式
nohup /usr/local/logstash-7.10.2/bin/logstash -f /usr/local/logstash-7.10.2/config/logstash.conf &
##
./logstash -f ../config/logstash.conf
成功启动后会显示以下日志:
[2020-10-15T06:57:40,640][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
访问地址: http://192.168.116.141:9600/, 可以看到返回信息:
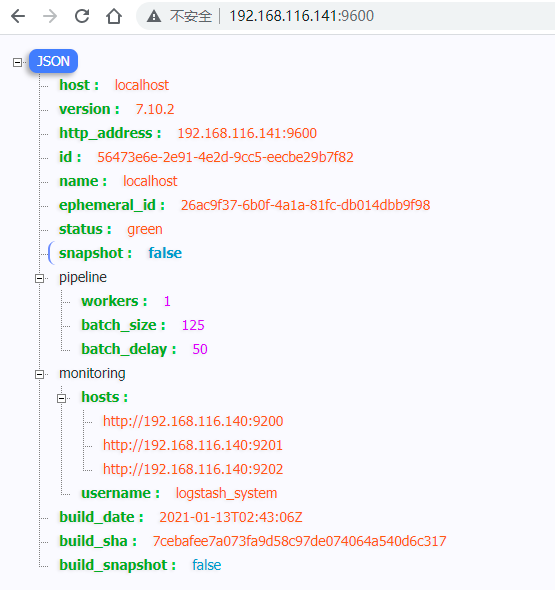
在192.168.116.141机器节点上操作:
下载解压
与ElasticSearch版本一致, 下载7.10.2版本。
cd /usr/local
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.10.2-linux-x86_64.tar.gz
解压:
tar -xvf filebeat-7.10.2-linux-x86_64.tar.gz
修改配置文件
vi /usr/local/filebeat-7.10.2/filebeat.yml
修改内容:
# 需要收集发送的日志文件
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/messages
# 如果需要添加多个日志,只需要添加
- type: log
enabled: true
paths:
- /var/log/test.log
# filebeat 配置模块, 可以加载多个配置
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
# 索引分片数量设置
setup.template.settings:
index.number_of_shards: 2
# kibana 信息配置
setup.kibana:
host: "192.168.116.140:5601"
# logstash 信息配置 (注意只能开启一项output设置, 如果采用logstash, 将output.elasticsearch关闭)
output.logstash:
hosts: ["192.168.116.141:5044"]
# 附加metadata元数据信息
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~
启动服务
## 后台启动
nohup /usr/local/filebeat-7.10.2/filebeat -e -c /usr/local/filebeat-7.10.2/filebeat.yml &
##
./filebeat -e -c filebeat.yml
启动成功后显示日志:
2020-12-15T07:09:33.922-0400 WARN beater/filebeat.go:367 Filebeat is unable to load the Ingest Node pipelines for the configured modules because the Elasticsearch output is not configured/enabled. If you have already loaded the Ingest Node pipelines or are using Logstash pipelines, you can ignore this warning.
2020-12-15T07:09:33.922-0400 INFO crawler/crawler.go:72 Loading Inputs: 1
2020-12-15T07:09:33.923-0400 INFO log/input.go:148 Configured paths: [/var/log/messages]
2020-12-15T07:09:33.923-0400 INFO input/input.go:114 Starting input of type: log; ID: 14056778875720462600
2020-12-15T07:09:33.924-0400 INFO crawler/crawler.go:106 Loading and starting Inputs completed. Enabled inputs: 1
2020-12-15T07:09:33.924-0400 INFO cfgfile/reload.go:150 Config reloader started
我们监听的是/var/log/messages系统日志信息, 当日志发生变化后, filebeat会通过logstash上报到Elasticsearch中。 我们可以查看下集群的全部索引信息:
http://192.168.116.140:9200/_cat/indices?v
可以看到, 已经生成了名为logstash-2021.07.20-000001索引。
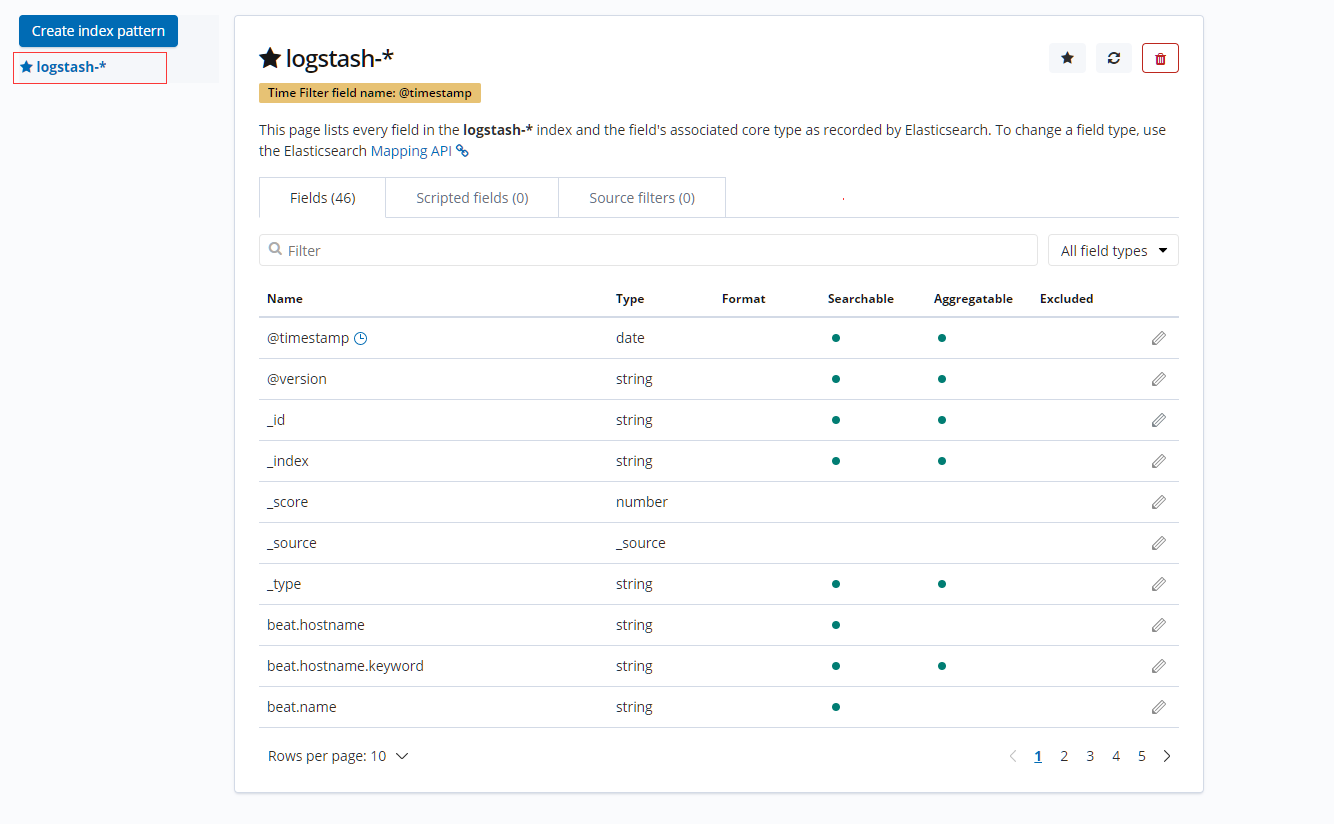
进入Kibana后台, 进行配置:
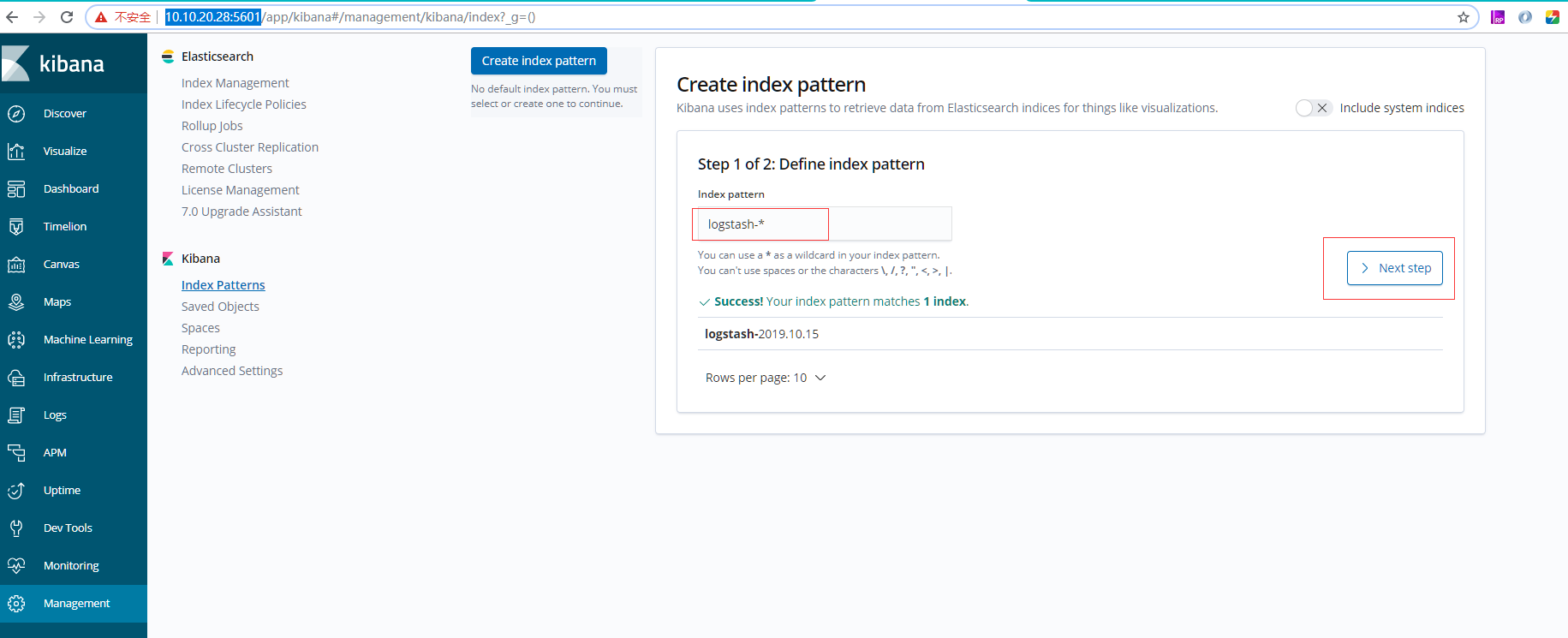
进入【Management】--> 在Index Pattern中输入"logstash-*" --> 点击【next step】, 选择"@timestamp",
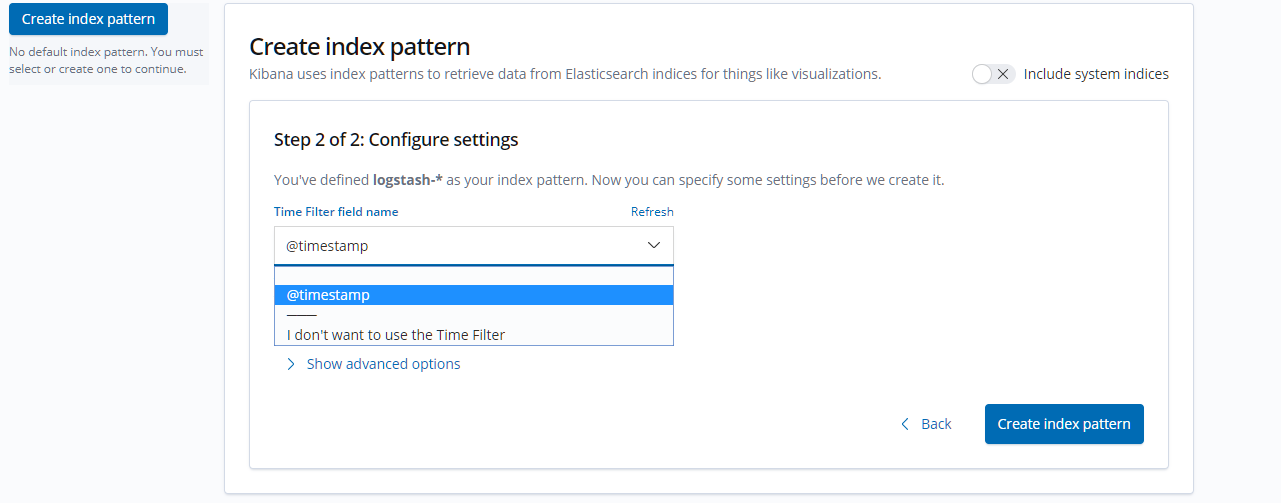
点击【 Create index pattern 】进行创建。
查看数据
进入【Discover】, 可以查看到收集的数据:
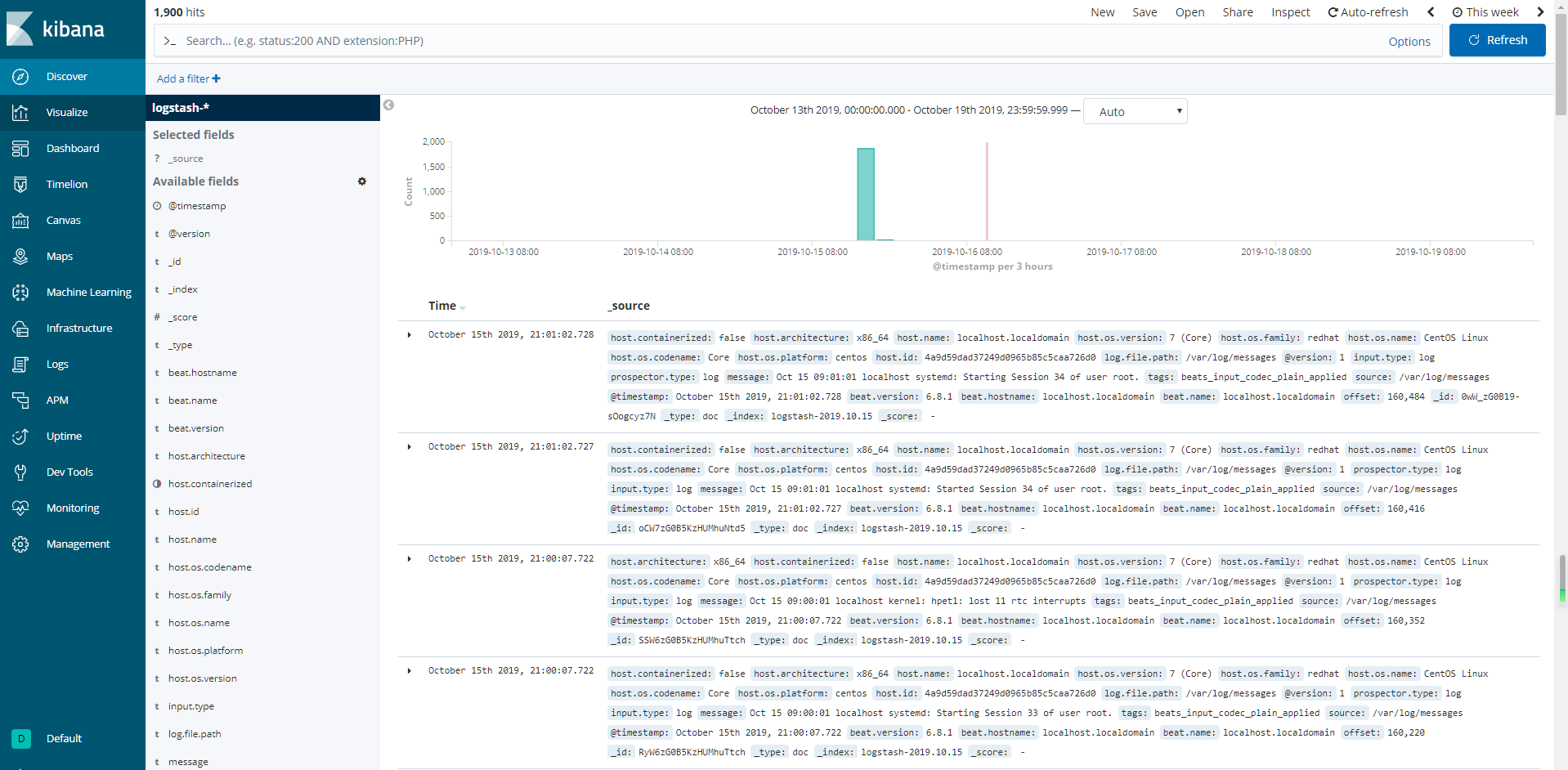
如果没有显示, 可以重新调整Time Range时间范围。
本文由传智教育博学谷 - 狂野架构师教研团队发布
如果本文对您有帮助,欢迎关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力
转载请注明出处!
有没有人得到Logstash在Rails上使用ruby?我的客户告诉我将Logstash用于日志收集器等。我正在使用rubyonrails技术。大部分都快完成了。但要求是将日志记录到logstash中。请让我知道这可能吗? 最佳答案 我为此编写了一个gem-logstasher.它将Rails日志写入一个单独的文件,采用纯json格式,无需任何处理即可由logstash使用。查看我的blog有关如何设置Logstash和Kibana的完整说明 关于ruby-on-rails-Lo
在我的场景中,Logstash收到的系统日志行的“时间戳”是UTC,我们在Elasticsearch输出中使用事件“时间戳”:output{elasticsearch{embedded=>falsehost=>localhostport=>9200protocol=>httpcluster=>'elasticsearch'index=>"syslog-%{+YYYY.MM.dd}"}}我的问题是,在UTC午夜,Logstash在外时区(GMT-4=>America/Montreal)结束前将日志发送到不同的索引,并且索引在20小时(晚上8点)之后没有日志,因为“时间戳”是UTC。我们已
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a
目录0专栏介绍1平面2R机器人概述2运动学建模2.1正运动学模型2.2逆运动学模型2.3机器人运动学仿真3动力学建模3.1计算动能3.2势能计算与动力学方程3.3动力学仿真0专栏介绍?附C++/Python/Matlab全套代码?课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等);局部规划(DWA、APF等);曲线优化(贝塞尔曲线、B样条曲线等)。?详情:图解自动驾驶中的运动规划(MotionPlanning),附几十种规划算法1平面2R机器人概述如图1所示为本文的研究本体——平面2R机器人。对参数进行如下定义:机器人广义坐标
网站的日志分析,是seo优化不可忽视的一门功课,但网站越大,每天产生的日志就越大,大站一天都可以产生几个G的网站日志,如果光靠肉眼去分析,那可能看到猴年马月都看不完,因此借助网站日志分析工具去分析网站日志,那将会使网站日志分析工作变得更简单。下面推荐两款网站日志分析软件。第一款:逆火网站日志分析器逆火网站日志分析器是一款功能全面的网站服务器日志分析软件。通过分析网站的日志文件,不仅能够精准的知道网站的访问量、网站的访问来源,网站的广告点击,访客的地区统计,搜索引擎关键字查询等,还能够一次性分析多个网站的日志文件,让你轻松管理网站。逆火网站日志分析器下载地址:https://pan.baidu.
1.回顾.TransportServicepublicclassTransportServiceextendsAbstractLifecycleComponentTransportService:方法:1publicfinalTextendsTransportResponse>voidsendRequest(finalTransport.Connectionconnection,finalStringaction,finalTransportRequestrequest,finalTransportRequestOptionsoptions,TransportResponseHandlerT>
一、机器人介绍 此处是基于MATLABRVC工具箱,对ABB-IRB-1200型号的微型机械臂进行正逆向运动学分析,并利Simulink工具实现对机械臂进行具有动力学参数的末端轨迹规划仿真,最后根据机械模型设计Simulink-Adams联合仿真。 图1.ABBIRB 1200尺寸参数示意图ABBIRB 1200提供的两种型号广泛适用于各作业,且两者间零部件通用,两种型号的工作范围分别为700 mm 和 900 mm,大有效负载分别为 7 kg 和5 kg。 IRB 1200 能够在狭小空间内能发挥其工作范围与性能优势,具有全新的设计、小型化的体积、高效的性能、易于集成、便捷的接
目录一.大致如下常见问题:(1)找不到程序所依赖的Qt库version`Qt_5'notfound(requiredby(2)CouldnotLoadtheQtplatformplugin"xcb"in""eventhoughitwasfound(3)打包到在不同的linux系统下,或者打包到高版本的相同系统下,运行程序时,直接提示段错误即segmentationfault,或者Illegalinstruction(coredumped)非法指令(4)ldd应用程序或者库,查看运行所依赖的库时,直接报段错误二.问题逐个分析,得出解决方法:(1)找不到程序所依赖的Qt库version`Qt_5'
目录H2数据库入门以及实际开发时的使用1.H2数据库的初识1.1H2数据库介绍1.2为什么要使用嵌入式数据库?1.3嵌入式数据库对比1.3.1性能对比1.4技术选型思考2.H2数据库实战2.1H2数据库下载搭建以及部署2.1.1H2数据库的下载2.1.2数据库启动2.1.2.1windows系统可以在bin目录下执行h2.bat2.1.2.2同理可以通过cmd直接使用命令进行启动:2.1.2.3启动后控制台页面:2.1.3spring整合H2数据库2.1.3.1引入依赖文件2.1.4数据库通过file模式实际保存数据的位置2.2H2数据库操作2.2.1Mysql兼容模式2.2.2Mysql模式
我想使用ruby-prof和JMeter分析Rails应用程序。我对分析特定Controller/操作/或模型方法的建议方法不感兴趣,我想分析完整堆栈,从上到下。所以我运行这样的东西:RAILS_ENV=productionruby-prof-fprof.outscript/server>/dev/null然后我在上面运行我的JMeter测试计划。然而,问题是使用CTRL+C或SIGKILL中断它也会在ruby-prof可以写入任何输出之前杀死它。如何在不中断ruby-prof的情况下停止mongrel服务器? 最佳答案