作者:禅与计算机程序设计艺术1.简介ApacheSpark™作为世界上最流行的开源大数据计算框架之一,在近几年越来越受到大家的关注。基于Spark的分布式计算能力和速度的突飞猛进,使其成为许多企业应用中不可或缺的一环。但Spark本身所提供的高级特性如:SQL、Streaming等也带来了一些新的复杂性。为了更好的理解SparkStreaming,以及如何在实际生产环境中应用SparkStreaming,作者不得不花费不少心思研究。因此他着手撰写一本《SparkStreaming实战》。这本书将系统地介绍SparkStreaming的概念、原理和特性,并通过真实案例加深读者对其核心概念和功能的
我正在尝试使用SpringBoot和SpringData进行作业。我有两个实体组织和位置。1.组织publicclassOrganization{privateLongid;privateStringname;privateLocationlocation;}publicclassLocation{privateDoublelattitude;privateDoublelongitude;}我的数据库表就像:CREATETABLEorganization(idintprimarykey,organization_namevarchar(255),organization_location_la
源算子DataSource概述内置DataSource基于集合构建基于文件构建基于Socket构建自定义DataSourceSourceFunctionRichSourceFunction常见连接器第三方系统连接器FileSource连接器DataGenSource连接器KafkaSource连接器RabbitMQSource连接器MongoDBSource连接器概述Flink中的DataSource(数据源、源算子)用于定义数据输入的来源。数据源是Flink作业的起点,它可以从各种数据来源获取数据,例如文件系统、消息队列、数据库等。将数据源添加到Flink执行环境中,从而创建一个数据流。然后
文章目录前言解决方案前言最近在学习elasticsearch时在购买的阿里云linux服务器进行docker安装运行时报错解决方案我这里是把dockerrun--nameelasticsearch-p9200:9200-p9300:9300\-e"discovery.type=single-node"\-eES_JAVA_OPTS="-Xms64m-Xmx512m"\-v/mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml\-v/mydata/elasti
PHPWarning'yii\base\ErrorException'withmessage'file_get_contents(https://img12.360buyimg.com/n5/s1200x800_jfs/t1/69307/10/5911/292411/5d3e610cEce4e6f5a/b69fbf56874af00d.jpg):failedtoopenstream:HTTPrequestfailed!HTTP/1.1404NotFound上面问题很多种处理方案;比如使用curl等可以参考其他使用产景定时任务脚本中存在一个批量遍历去请求图片的接口;特别是脚本中,一定的要兼容好,
为了SparkStreaming应用能在生产中稳定、有效的执行,每批次数据处理时间(批处理时间)必须非常接近批次调度的时间间隔(批调度间隔),并且要一直低于批调度间隔。如果批处理时间一直高于批调度间隔,调度延迟就会一直增长并且不会恢复。最终,SparkStreaming应用会变得不再稳定。另一方面,如果批处理时间长时间远小于批调度间隔,就会浪费集群资源。 当SparkStreaming与Kafka使用DirectAPI集群时,我们可以很方便的去控制最大数据摄入量--通过一个被称作spark.streaming.kafka.maxRatePerPartition的参
51单片机的运行内存分前128字节和后128字节。前面128个字节好像cpu里的寄存器,读写非常快。后面的128字节只能用指针访问。单片机可以外扩运行内存条,外扩的这部分内存叫xdata。我对单片机运行机制的理解就像搭建积木。以乐高积木举例:单片机是玩家,code区是说明书,data是积木块,单片机看着说明书把积木块拼装成汽车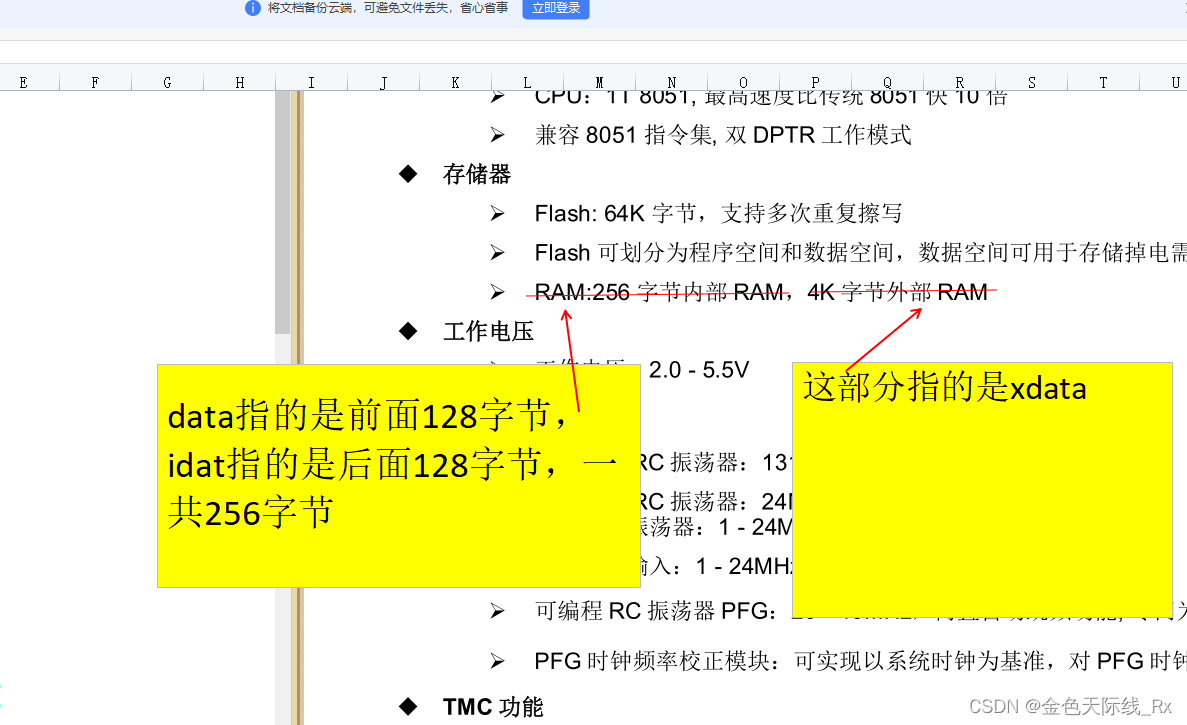区,和data(数据)区,code区在运行的时
2023年11月6日,周一下午目录POD类型的定义标量类型POD类型的特点POD类型的例子整数类型:C风格的结构体:数组:C风格的字符串:std::array:使用memcpy对POD类型进行复制把POD类型存储到文件中,并从文件中再次读取POD类型的定义只包含标量类型(如整数、浮点数、指针等)或者其他POD类型的成员。没有用户自定义的构造函数、析构函数或拷贝控制成员没有虚函数或虚继承可以通过 memset 和 memcpy 进行内存的简单复制和初始化。这些标准在C++03标准中被定义。根据这个定义,POD类型可以被视为简单的、平凡的数据类型,可以进行一些底层的操作,如内存复制、比较和序列化等
我无法安装compass。我想在我的项目上安装compass,所以当我尝试更新时,我得到了这个:c:\wamp\www\danjasnowski.com>geminstallcompassERROR:Couldnotfindavalidgem'compass'(>=0),hereiswhy:Unabletodownloaddatafromhttps://rubygems.org/-SSL_connectreturned=1errno=0state=SSLv3readservercertificateB:certificateverifyfailed(https://api.rubyge
之前介绍过关于抓包工具charles的详细使用方法,链接:https://mp.csdn.net/mp_blog/creation/editor/100563263。但觉得还是不够方便,今天来简单介绍下可以直接安装在移动端的APP抓包工具。1.关于ios端Stream工具的使用1.1stream直接在appstore下载即可打开页面1.2Stream的基本介绍和使用1、构建请求我们先从构建请求说起,构建请求,包含了接口的八种方式,在这里,再温习一下,这八种请求方式的用途:(1)Get向特定资源发出请求(请求指定页面信息,并返回实体主体);(2)Post向指定资源提交数据进行处理请求(提交表单、