1.资格获取首先我们需要登录百度翻译开放平台,获取开发者资格:访问百度翻译开放平台然后进行注册(如果有百度账号的话可以直接登录)注册成功后点击“产品服务”:跳转到通用文本API界面:在页面底部点击“立即使用”即可选择服务进行使用通用文本API有三种服务可供选择:个人用户可以使用前两种,高级版的使用需要个人认证(实名认证)2.简单使用点击“管理控制台”,打开“开发者信息”界面:即可看到你的APPID和密钥信息,在调用接口的时候需要用到;点击“我的服务”中的通用文本翻译,即可看到服务使用情况及明细如果对于翻译的术语有特殊要求,可以点击“我的语料库”,并新建术语库:这样我们设置的术语即可干预翻译结果
文章目录一、百度地图--作者前言二、百度地图如何使用第一步:进入官网第二步:进入开发文档第三步:申请百度开发者密钥获取账户和密钥第四步:插入百度地图4.1申请密钥=>已完成4.2准备页面4.3创建容器和创建地图实例以及相关设置三、百度地图添加控件(基本控件)鼠标滚轮添加控件marker标注(需要掌握)1、地图添加标注marker效果2、更改地图标注marker样式--定义标注图标效果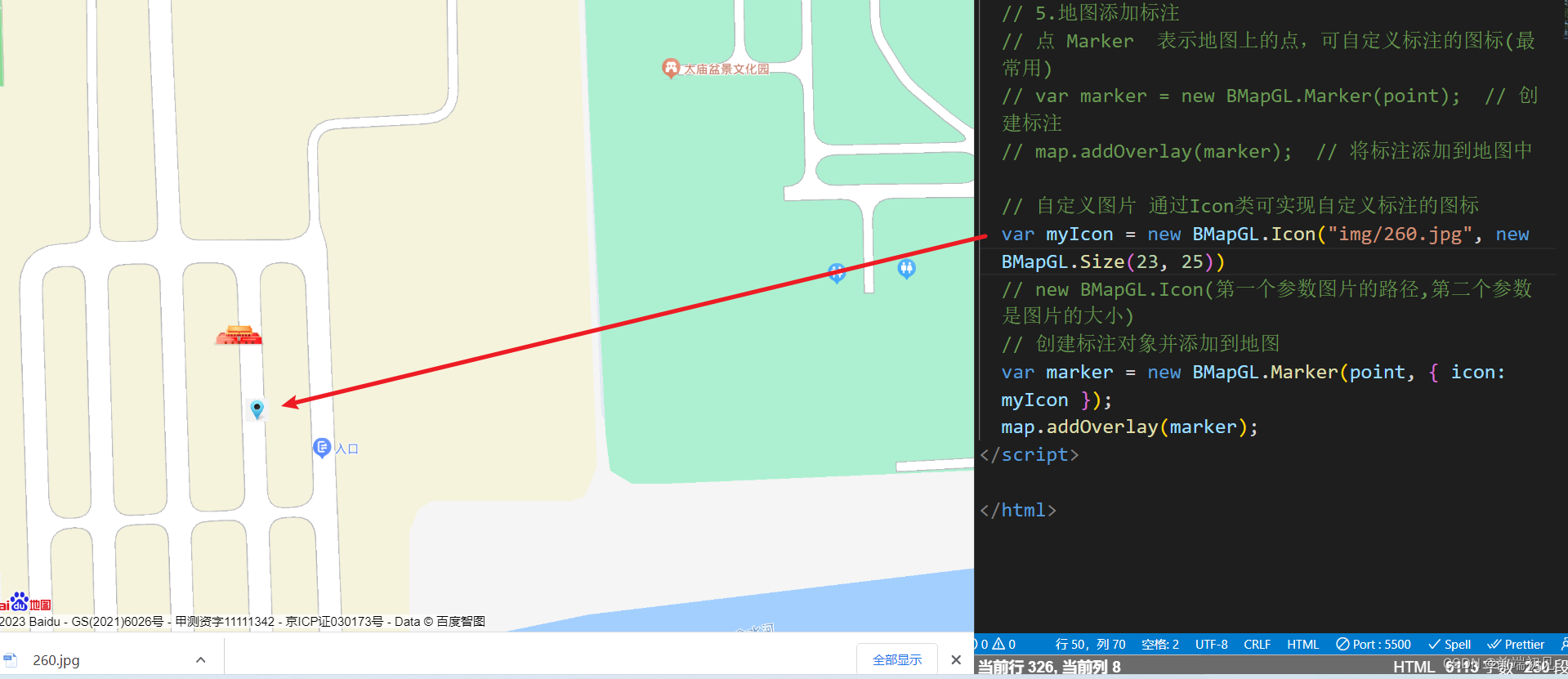2、标注添加监听事件还在更新中,可以
我在正确初始化NumPyCAPI时遇到问题。我想我已经将问题隔离到从不同的翻译单元调用import_array,但我不知道为什么这很重要。最小工作示例:header1.hpp#ifndefHEADER1_HPP#defineHEADER1_HPP#include#include#includevoidinitialize();#endiffile1.cpp#include"header1.hpp"void*wrap_import_array(){import_array();return(void*)1;}voidinitialize(){wrap_import_array();}fi
百度文心一言接入使用(中国版ChatGPT)一、百度文心一言API二、使用步骤1、接口2、请求参数3、请求参数示例4、接口返回示例三、如何获取appKey和uid1、申请appKey:2、获取appKey和uid四、重要说明一、百度文心一言API基于百度文心一言语言大模型的智能文本对话AI机器人API,支持聊天对话、行业咨询、语言学习、代码编写等功能.二、使用步骤1、接口重要提示:建议使用https协议,当https协议无法使用时再尝试使用http协议请求方式:POSThttps://luckycola.com.cn/ai/openwxyy2、请求参数序号参数是否必须说明1ques是你的问题2
【后台管理员功能】系统设置:设置网站简介、关于我们、联系我们、加入我们、法律声明广告管理:设置小程序首页轮播图广告和链接留言列表:所有用户留言信息列表,支持删除会员列表:查看所有注册会员信息,支持删除资讯分类:录入、修改、查看、删除资讯分类录入资讯:录入资讯标题、内容等信息管理资讯:查看已录入资讯列表,支持删除和修改资讯评论列表:所有用户的评论信息列表资讯评论管理:支持对评论信息审核,删除;审核后的信息用户才可见图片分类:录入、修改、查看、删除图片分类录入图片:录入图片标题、内容等信息管理图片:查看已录入图片列表,支持删除和修改图片评论列表:所有用户的评论信息列表图片评论管理:支持对评论信息审
我如何确保setup.py编译项目PO文件并在创建sdist时包含它们。这是一个Django应用程序,生成MO文件的手动过程是在应用程序的根目录中运行以下命令:django-admincompilemessages(这意味着比setup.py更深一层)我想避免每次都手动编译MO文件。而且我根本不想将它们存储在存储库中。 最佳答案 我的简单解决方案(从Trac那里得到了一些想法):#!/usr/bin/envpythonfromsetuptoolsimportsetup,find_packagesfromsetuptools.comm
这段特殊的代码在Linux上运行良好,但在Windows上运行不佳:locale.setlocale(locale.LC_ALL,'')gettext.bindtextdomain('exposong',LOCALE_PATH)gettext.textdomain('exposong')代码来自here即使我在locale.setlocale中指定了语言环境(我尝试了不同的格式)它也不起作用。一个问题可能是环境变量中没有设置语言环境(但我使用的是德语Windows版本;在XP和Vista上测试过)。如果我在命令行上执行"SetLang=de_DE",一切都会按预期进行。有什么想法吗?
以下代码无效fromdjango.utils.translationimportgettext_lazyas_stringtest=_("Firststring")stringtest=stringtest+_("Secondstring")printstringtest我得到以下异常:cannotconcatenate'str'and'__proxy__'objects真的不可能给自己附加一个“翻译”的字符串吗? 最佳答案 你不能连接你的两个字符串,而是创建一个新字符串(这已经是你的+操作的情况,因为字符串是不可变的):fromd
AI智能对比🍸前言🍺概念类对比🍵讯飞🍵百度AI🍵chatGPT🍹功能类对比☕讯飞☕百度AI☕chatGPT🥃可输入字数对比🥤百度AI🥤讯飞🥤chatGPT🍻总结主页传送门:📀传送🍸前言 俗话说,货比三家,今天就来多角度对比下讯飞星火大模型,百度AI和chatGPT三者的智能程度🍺概念类对比 就GPT而言,描述的越详细得到的答案基本上越准确,相对概念类而言,符合国人诉求的是百度AI讯飞星火相对比较简单,就是基本的介绍。以AIGC是什么问题为例:🍵讯飞🍵百度AI🍵chatGPT详细的描述:🍹功能类对比 以vue中如何给路由定义个默认的页面问题为例☕讯飞 在路由配置文件中添加一个重定向规则,
提示:根据你的显卡类型安装对应CUDA版本。Turing(图灵)和Ampere(安培)是Nvidia两种高级GPU架构图灵GPU(12nm制造工艺):RTX20系列和GTX16系列安培GPU(8nm制造工艺):RTX30系列,包括GeForceRTX3090、RTX3080、RTX3070等文章目录前言一、进入飞桨官网二、安装CUDA1.CUDA下载地址2.CUDA环境变量二、安装cuDNN1.cuDNN下载地址2.cuDNN文件拷贝至CUDA对应文件中总结前言随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了国内百度旗下paddlepaddle(飞