🍓系列专栏:蓝桥杯
🍉个人主页:个人主页
目录
算法工具推荐:
还在为数据结构发愁吗?这款可视化工具,帮助你更好的了解其数据结构数据结构和算法动态可视化 (Chinese) - VisuAlgo
冒泡排序(Bubble Sorting)的基本思想是:通过对待排序序列从前向后(从下标较小的元素开始),依次比较相邻元素的值,若发现逆序则交换,使值较大的元素逐渐从前移向后部,就象水底下的气泡一样逐渐向 上冒。
思想:
我们要把相邻的元素两两比较,当一个元素大于右侧相邻元素时,交换它们的位置;当一个元素小于右侧相邻元素时,位置不变
动图演示:
代码1:
import java.util.Arrays;
public class bubble {
public static void main(String[] args) {
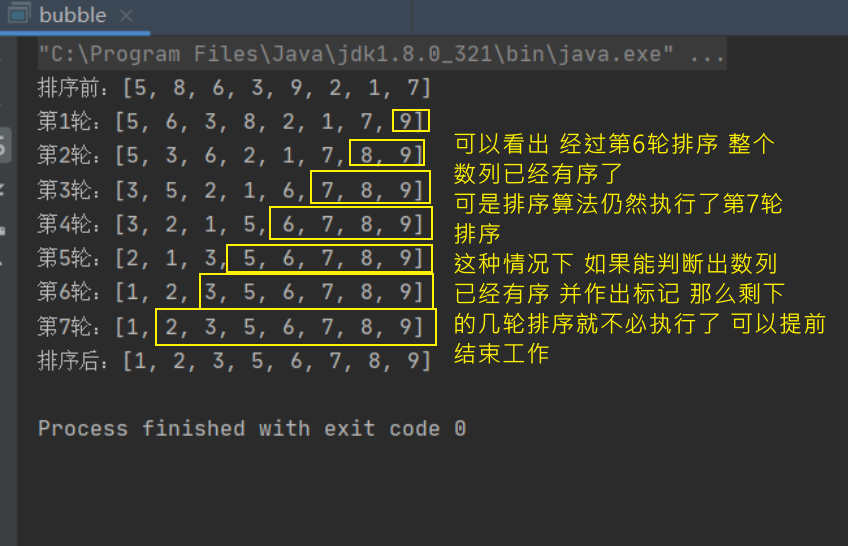
int arr[]={5,8,6,3,9,2,1,7};
System.out.println("排序前:"+Arrays.toString(arr));
BubbleSort(arr);
System.out.println("排序后:"+Arrays.toString(arr));
}
private static void BubbleSort(int[] arr) {
int temp=0; //临时存储变量
int n=0; //统计排序次数
for (int i = 1; i < arr.length; i++) {
n++;
for (int j = 0; j < arr.length-i; j++) {
if (arr[j]>arr[j+1]){
temp=arr[j+1];
arr[j+1]=arr[j];
arr[j]=temp;
}
}
System.out.println("第"+n+"轮:"+Arrays.toString(arr));
}
}
}
优化:
因为排序的过程中,各元素不断接近自己的位置,如果一趟比较下来没有进行过交换,就说明序列有序,因此要在排序过程中设置一个标志flag判断元素是否进行过交换。从而减少不必要的比较。
代码2(第一次优化):
import java.util.Arrays;
public class bubble {
public static void main(String[] args) {
int arr[]={5,8,6,3,9,2,1,7};
System.out.println("排序前:"+Arrays.toString(arr));
BubbleSort(arr);
System.out.println("排序后:"+Arrays.toString(arr));
}
private static void BubbleSort(int[] arr) {
int temp=0; //临时存储变量
int n=0; //统计排序次数
for (int i = 1; i < arr.length; i++) {
n++;
boolean flag=true;
for (int j = 0; j < arr.length-i; j++) {
if (arr[j]>arr[j+1]){
temp=arr[j+1];
arr[j+1]=arr[j];
arr[j]=temp;
flag=false;
}
}
if (flag==true){
break;
}
System.out.println("第"+n+"轮:"+Arrays.toString(arr));
}
}
}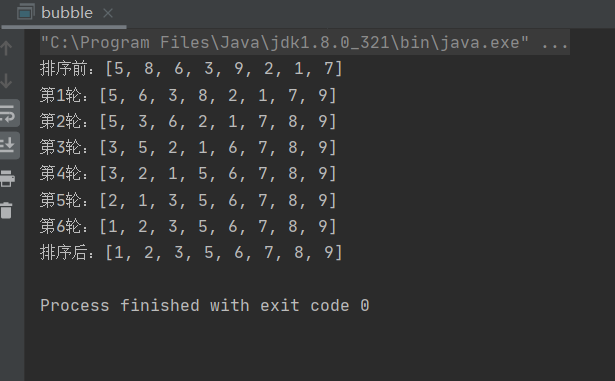
与第1版代码相比,第2版代码做了小小的改动,利用布尔变量flag作为标记。如果在本轮排序中,元素有交换,则说明数列无序;如果没有元素交换,则说明数列已然有序,然后直接跳出大循环。
这只是冒泡序优化的第一步,我们还可以进一步来提开它的性能。为了说明问题,这次以一个新的数列为例。
为了说明问题,这次以一个新的数列为例
arr={3,4,2,1,5,6,7,8}
import java.util.Arrays;
public class bubble {
public static void main(String[] args) {
int arr[]={3,4,2,1,5,6,7,8};
System.out.println("排序前:"+Arrays.toString(arr));
BubbleSort(arr);
System.out.println("排序后:"+Arrays.toString(arr));
}
private static void BubbleSort(int[] arr) {
int temp=0; //临时存储变量
int n=0; //统计排序次数
for (int i = 1; i < arr.length; i++) {
n++;
boolean flag=true;
for (int j = 0; j < arr.length-i; j++) {
System.out.println("排序:"+Arrays.toString(arr));
if (arr[j]>arr[j+1]){
temp=arr[j+1];
arr[j+1]=arr[j];
arr[j]=temp;
flag=false;
}
}
if (flag==true){
break;
}
System.out.println("第"+n+"轮:"+Arrays.toString(arr));
}
}
}
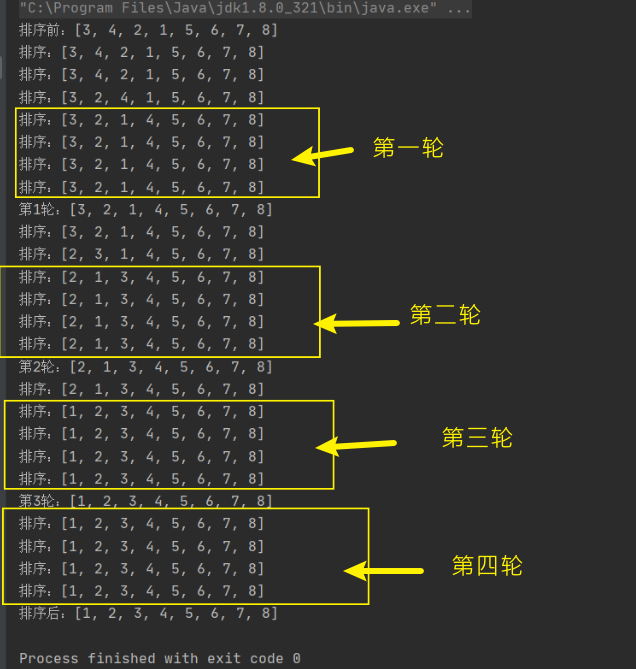
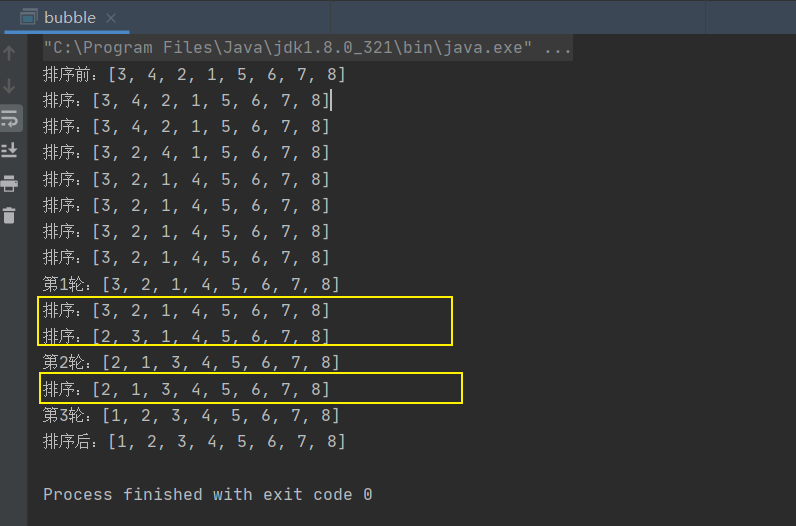
第一轮中:
元素4和5比较,发现4小于5,所以位置不变。
元素5和6比较,发现5小于6,所以位置不变。
元素6和7比较,发现6小于7,所以位置不变。
元素7和8比较,发现7小于8,所以位置不变。
第二轮中:
元素3和4比较,发现3小于4,所以位置不变。
元素4和5比较,发现4小于5,所以位置不变。
元素5和6比较,发现5小于6,所位位置不变。
元素6和7比较,发现6小于7,所以位置不变。
元素7和8比较,发现7小于8,所以位置不变。
.................................................................
按照现有的逻辑,有序区的长度和排序的轮数是相等的。例如第1轮排序过后的有序区长度是1,第2轮排序过后的有序区长度是2....
实际上,数列真正的有序区可能会大于这个长度,如上述例子中在第2轮排序时,后面的5个元素实际上都已经属于有序区了。因此后面的多次元素比较是没有意义的。
那么,该如何避免这种情况呢?我们可以在每一轮排序后, 记录下来最后一次元素交换的位置,该位置即为无序数列的边界,再往后就是有序区了。
代码3:
import java.util.Arrays;
public class bubble {
public static void main(String[] args) {
int arr[]={3,4,2,1,5,6,7,8};
System.out.println("排序前:"+Arrays.toString(arr));
BubbleSort(arr);
System.out.println("排序后:"+Arrays.toString(arr));
}
private static void BubbleSort(int[] arr) {
int temp=0; //临时存储变量
int n=0; //统计排序次数
int lastIndex= 0;//记录最后一次交换的位置
int sortBorder= arr.length-1;//无序数列的边界
for (int i = 1; i < arr.length; i++) {
n++;
boolean flag=true;
for (int j = 0; j < sortBorder; j++) {
System.out.println("排序:"+Arrays.toString(arr));
if (arr[j]>arr[j+1]){
temp=arr[j+1];
arr[j+1]=arr[j];
arr[j]=temp;
lastIndex=j;
flag=false;
}
}
sortBorder=lastIndex;
if (flag==true){
break;
}
System.out.println("第"+n+"轮:"+Arrays.toString(arr));
}
}
}
基本介绍:
选择式排序也属于内部排序法,是从欲排序的数据中,按指定的规则选出某一元素,再依规定交换位置后达到排序的目的。
思想:
选择排序 (select sorting) 也是一种简单的排序方法。它的基本思想是: 第一次从 arr[0]~arr[n-1]中选取最小值,与arr[0]交换,第二次从 ar[1]~arr[n-1]中选取最小值,与 arr[1]交换,第三次从 ar[2]~arr[n-1]中选取最小值,与 arr[2]交换,.................,第 i 次从arr[i-1]~arr[n-1]中选取最小值,与 arr[i-1]交换,.............,第n-1 次从arr[n-2] ~ arr [n-1]中选取最小值,与 arr[n-2]交换,总共通过 n-1 次,得到一个按排序码从小到大排列的有序序列。
//普通选择排序
public static void sort1(int[] array){
int count = 0;//统计运行次数
int cnt = 0; //交换次数
for(int i=0;i<array.length-1;i++) {
int min=array[i];
int minIndex=i;
count++;
for(int j=i+1;j<array.length;j++){
if(min>array[j]) {
min=array[j];
minIndex=j;
}
}
if(minIndex!=i){
cnt++;
array[minIndex]=array[i];
array[i]=min;
}
}
System.out.println(Arrays.toString(array));
System.out.println("运行次数:"+count+"次 交换次数:"+cnt);
}
import java.util.Arrays;
import java.util.Random;
/**
* 选择排序优化
*/
class SelectionSort2 {
public static void main(String[] args) {
//产生一个随机数组
Random r = new Random();
int arr[] = new int[2000];
for(int i=0;i<arr.length;i++){
arr[i] =r.nextInt(1000);
}
//因为本优化版本每次循环找出最大以及最小值,所以执行执行:arr.length/2
int ArrLength = (arr.length/2);
int temp1,temp2;
long count = 0;
//记录开始时间
long startStamp = System.currentTimeMillis();
//算法开始
for(int j=0;j<ArrLength;j++){
int minIndex = j;
int maxIndex= j;
for(int i=j;i<arr.length-j;i++){
if (arr[minIndex] > arr[i]) {
minIndex = i;
}
if (arr[maxIndex] < arr[i]) {
maxIndex= i;
}
count++;
}
temp1 = arr[minIndex];
arr[minIndex] = arr[j];
arr[j] = temp1;
if(j!=maxIndex) { //maxIndex不能再原本的minIndex位置上
temp2 = arr[maxIndex];
arr[maxIndex] = arr[arr.length - j - 1];
}else{
temp2 = arr[minIndex];
arr[minIndex] = arr[arr.length - j - 1];
}
arr[arr.length - j - 1] = temp2;
}
//计算算法结束时间
long endStamp = System.currentTimeMillis();
System.out.println("用时总长:"+(endStamp-startStamp));
System.out.println("循环次数:"+count);
System.out.println(Arrays.toString(arr));
}
}
插入排序(Insertion Sorting)的基本思想是:把n个待排序的元素看成为一个有序表和一个无序表,开始时有序表中只包含一个元素,无序表中包含有n -1 个元素,排序过程中每次从无序表中取出第一个元素,把它的排序码依次与有序表元素的排序码进行比较,将它插入到有序表中的适当位置,使之成为新的有序表。
Java实现插入排序的代码如下:
public static void insertionSort(int[] arr) {
for (int i = 1; i < arr.length; i++) {
int key = arr[i];
int j = i - 1;
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j];
j--;
}
arr[j + 1] = key;
}
}上面的代码使用了两重循环,外层循环枚举未排序部分的元素,内层循环在已排序部分中找到适当的位置并进行插入。
这段代码的时间复杂度为O(n^2),空间复杂度为O(1)。
《经典算法的起源》是一本计算机算法方面的科普性书籍,作者以通俗易懂、引人入胜的叙述方式介绍各种算法思想,避免使用一些过于严谨的专业术语。比如,用“大海捞针”来形容一种搜索算法就非常形象,顾名思义,广大读者更容易理解该搜索策略。本书适合对计算机知识有兴趣的初中生、高中生或其他相关人员阅读。计算机专业一、二年级的大学生阅读此书,也会对相关知识的起源有深刻的印象。
本书的目的是向非专业人士介绍算法,使读者理解算法如何运作,而不是阐述算法在生活中的作用。有些书籍在某些方面做了杰出工作,如介绍如何改善大数据的处理,讨论将人工智能和计算设备融入日常生活对人类生存条件的改变。本书对“发生什么”不感兴趣,对“如何发生”感兴趣。为此,本书给出一些真实的算法,不仅描述它们做什么,更重要的是关注它们如何运作。本书将提供详细的解释说明,而非粗略的介绍。

本书由机械工业出版社提供
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
我需要用任何语言编写一个算法,根据3个因素对数组进行排序。我以度假村为例(如Hipmunk)。假设我想去度假。我想要最便宜的地方、最好的评论和最多的景点。但是,显然我找不到在所有3个中都排名第一的方法。Example(assumingthereare20importantattractions):ResortA:$150/night...98/100infavorablereviews...18of20attractionsResortB:$99/night...85/100infavorablereviews...12of20attractionsResortC:$120/night
我正在尝试按Rails相关模型中的字段进行排序。我研究的所有解决方案都没有解决如果相关模型被另一个参数过滤?元素模型classItem相关模型:classPriority我正在使用where子句检索项目:@items=Item.where('company_id=?andapproved=?',@company.id,true).all我需要按相关表格中的“位置”列进行排序。问题在于,在优先级模型中,一个项目可能会被多家公司列出。因此,这些职位取决于他们拥有的company_id。当我显示项目时,它是针对一个公司的,按公司内的职位排序。完成此任务的正确方法是什么?感谢您的帮助。PS-我
我正在构建一个小部件来显示奥运会的奖牌数。我有一个“国家”对象的集合,其中每个对象都有一个“名称”属性,以及奖牌计数的“金”、“银”、“铜”。列表应该排序:1.首先是奖牌总数2.如果奖牌相同,按类型分割(金>银>铜,即2金>1金+1银)3.如果奖牌和类型相同,则按字母顺序子排序我正在用ruby做这件事,但我想语言并不重要。我确实找到了一个解决方案,但如果感觉必须有更优雅的方法来实现它。这是我做的:使用加权奖牌总数创建一个虚拟属性。因此,如果他们有2个金牌和1个银牌,加权总数将为“3.020100”。1金1银1铜为“3.010101”由于我们希望将奖牌数排序为最高的,因此列表按降序排
例如,假设我有一个名为Products的模型,并且在ProductsController中,我有以下代码用于product_listView以显示已排序的产品。@products=Product.order(params[:order_by])让我们想象一下,在product_listView中,用户可以使用下拉菜单按价格、评级、重量等进行排序。数据库中的产品不会经常更改。我很难理解的是,每次用户选择新的order_by过滤器时,rails是否必须查询,或者rails是否能够以某种方式缓存事件记录以在服务器端重新排序?有没有一种方法可以编写它,以便在用户排序时rails不会重新查询结果
我有一个对象如下:[{:id=>2,:fname=>"Ron",:lname=>"XXXXX",:photo=>"XXX"},{:id=>3,:fname=>"Dain",:lname=>"XXXX",:photo=>"XXXXXXX"},{:id=>1,:fname=>"Bob",:lname=>"XXXXXX",:photo=>"XXXX"}]我想按fname排序,不区分大小写,所以它会导致编号:1,3,2我该如何排序?我正在尝试:@people.sort!{|x,y|y[:fname]x[:fname]}但这没有任何效果。 最佳答案
有人可以告诉我如何根据自定义字符串对嵌套数组进行排序吗?比如有没有办法排序:[['Red','Blue'],['Green','Orange'],['Purple','Yellow']]“橙色”、“黄色”,然后是“蓝色”?最终结果如下所示:[['Green','Orange'],['Purple','Yellow'],['Red','Blue']]它不是按字母顺序排序的。我很想知道我是否可以定义要排序的值以实现上述目标。 最佳答案 sort_by对于这种排序总是非常方便:a=[['Red','Blue'],['Green','Ora
我有以下现有的Dog对象数组,它们按age属性排序:classDogattr_accessor:agedefinitialize(age)@age=ageendenddogs=[Dog.new(1),Dog.new(4),Dog.new(10)]我现在想插入一条新的狗记录,并将它放在数组中的正确位置。假设我想插入这个对象:another_dog=Dog.new(8)我想把它插入到数组中,让它成为数组中的第三项。这是一个人为的示例,旨在演示我特别想如何将一个项目插入到现有的有序数组中。我意识到我可以创建一个全新的数组并重新对所有对象进行排序,但这不是我的目标。谢谢!
我有一个这样的哈希{55=>{:value=>61,:rating=>-147},89=>{:value=>72,:rating=>-175},78=>{:value=>64,:rating=>-155},84=>{:value=>90,:rating=>-220},95=>{:value=>39,:rating=>-92},46=>{:value=>97,:rating=>-237},52=>{:value=>73,:rating=>-177},64=>{:value=>69,:rating=>-167},86=>{:value=>68,:rating=>-165},53=>{:va
如何在ruby中先根据值然后根据键对散列进行排序?例如h={4=>5,2=>5,7=>1}将排序为[[7,1],[2,5],[4,5]]我可以根据值进行排序h.sort{|x,y|x[1]y[1]}但我不知道如何根据值进行排序,然后在值相同时键入 最佳答案 h.sort_by{|k,v|[v,k]}这使用了Array的事实混入Comparable并定义逐元素。注意上面等价于h.sort_by{|el|el.reverse}相当于h.sort_by(&:reverse)这可能会或可能不会更具可读性。如果你知道Hashes一般都是先