目录
Experimence Replay Buffer经验回放缓存
 参数
参数Batch_Size*iteration=一个epoch的数据总量
常用于强化学习,指一个epoch中跑完一个样本
一个epoch就是跑一遍完整的训练数据。
epoch的次数过多,容易造成过拟合,次数过少,容易使训练的参数达不到最优
根据Replay中数据数量,成比例地修改更新次数。Don't Decay the Learning Rate, Increase the Batch Size. ICLR. 2018 。,经过验证,DRL也适用。
replay_max = 'the maximum capacity of replay buffer'
replay_len = len(ReplayBuffer)
k = 1 + replay_len / replay_max
batch_size = int(k * basic_batch_size)
epoch = int(k * basic_epoch)
batch_size为GPU对2的幂次的batch可以发挥更佳的性能,因此设置成16、32、64、128…时往往要比设置为整10、整100的倍数时表现更优
相对于正常数据集,
如果Batch_Size过小,训练数据就会非常难收敛,从而导致欠拟合。
增大Batch_Size,相对处理速度会变快,同时所需内存容量增加。
一般在Batchsize增加的同时,需要对所有样本的训练次数(epoch)增加,以达到最好的结果。
因此需要寻找一个合适的Batchsize值,在模型总体效率和内存容量之间做到最好的平衡。
我在设置BatchSize的时候,首先选择大点的BatchSize把GPU占满,观察Loss收敛的情况,如果不收敛,或者收敛效果不好则降低BatchSize,一般常用16,32,64等。
对训练影响较大,通常~
,具体多大需要调参
在简单的任务中(训练步数小于1e6),对于探索能力强的DRL算法,通常在缓存被放满前就训练到收敛了,不需要删除任何记忆。
过大的记忆也会拖慢训练速度,我一般会先从默认值 2 ** 17 ~ 2 ** 20 开始尝试,如果环境的随机因素大,我会同步增加记忆容量 与 batch size、网络更新次数,直到逼近服务器的内存、显存上限(放在显存训练更快)
每轮训练结束后需要通过梯度下降更新参数,更新次数为本轮训练的步数。若希望每轮训练结束后,将记忆中的所有数据都被拿出来训练,则:
记忆容量 memories_size = 本轮训练的步数 * batch_size ~= S * batch_size max_step = S * 10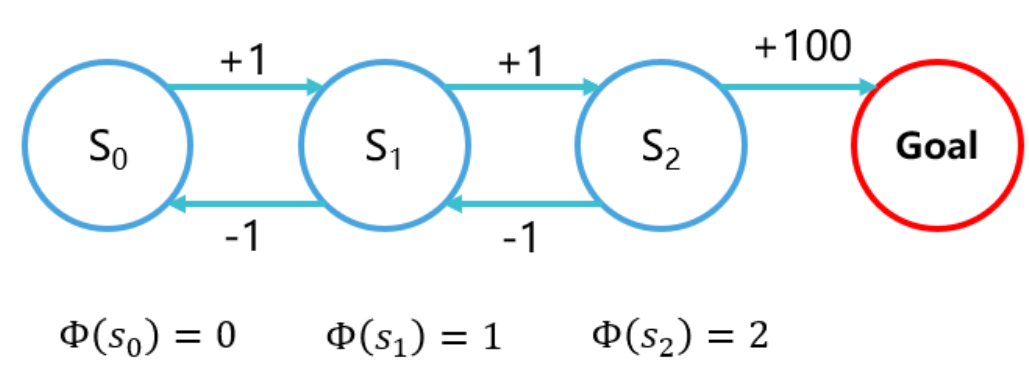
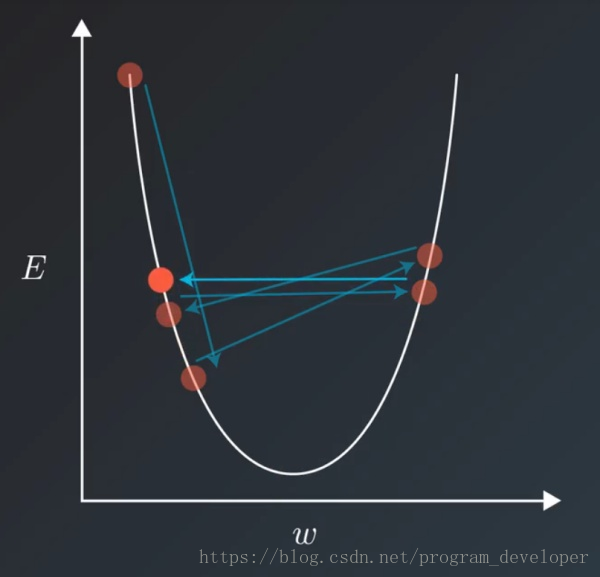
【dropout、batch normalization】在DL中得到广泛地使用,可惜不适合DRL。
希望你的智能体每做出一步,至少需要考虑接下来多少步的reward?
如果我希望考虑接下来的t 步,那么我让第t步的reward占现在这一步的Q值的 0.1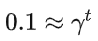
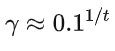 相当于往后考虑100时间步
相当于往后考虑100时间步
gamma绝对不能选择1.0。尽管有时候在入门DRl任务选择gamma=1.0 甚至能训练得更快,但是gamma等于或过于接近1会有“Q值过大”的风险。一般选择0.99,在某些任务上需要调整。详见《Reinforcement Learning An Introduction - Richard S. Sutton》的 Chapter 12 Eligibility Traces。
过大、过深的神经网络不适合DRL:
深度学习可以在整个训练结束后再使用训练好的模型。而强化学习需要在几秒钟的训练后马上使用刚训好的模型。这导致DRL只能用比较浅的网络来保证快速拟合(10层以下)
并且强化学习的训练数据不如有监督学习那么稳定,无法划分出训练集测试集去避免过拟合,因此DRL也不能用太宽的网络(超过1024),避免参数过度冗余导致过拟合。
经过大量实验,DRL绝对不能直接使用批归一化,如果非要用,那么就要修改Batch Normalization的动量项超参数。详见 曾伊言:强化学习需要批归一化(Batch Norm)吗?
如果非要用,那么也要选择非常小的 dropout rate(0~0.2),而且要注意在使用的时候关掉dropout。
将输出误差反向传播给网络参数,以此来拟合样本的输出。
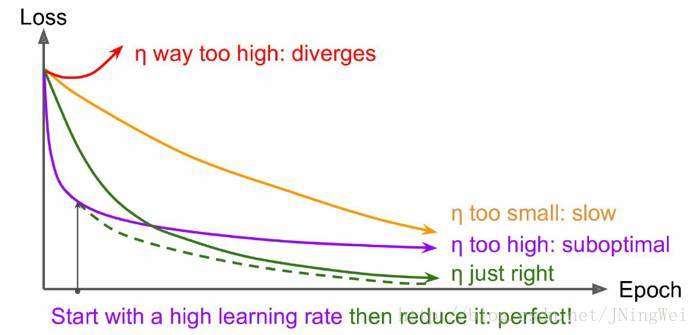
本质上是最优化的一个过程,逐步趋向于最优解。但是每一次更新参数利用多少误差,就需要lr控制。
学习率越大,输出误差对参数的影响就越大,参数更新的就越快,但同时受到异常数据的影响也就越大,很容易发散。
可以看出,最理想的学习率不是固定值,而是一个随着训练次数衰减的变化的值,也就是在训练初期,学习率比较大,随着训练的进行,学习率不断减小,直到模型收敛。
在这三种方法中,最常用的是指数衰减,实践证明,它也是最有效的。
(例如:随着迭代轮数的增加学习率自动发生衰减,每过5个epochs将学习率乘以0.9998。)
tensorflow中它的数学表达式为:
decayed_lr = lr0*(decay_rate^(global_steps/decay_steps)
参数解释:
decayed_lr:衰减后的学习率,也就是当前训练不使用的真实学习率
lr0: 初始学习率
decay_rate: 衰减率,每次衰减的比例
global_steps:当前训练步数
decay_steps:衰减步数,每隔多少步衰减一次。
刚开始训练时,学习率以 0.01 ~ 0.001 为宜, 接近训练结束的时候,学习速率的衰减应该在100倍以上。按照这个经验去设置相关参数,对于模型的精度会有很大帮助。
如果是 迁移学习 ,由于模型已在原始数据上收敛,此时应设置较小学习率 () 在新数据上进行 微调 。
如何选择Q值最大以外的动作:
每次都从 已经被强化学习算法加强过的Q值中,选择Q值最大的那个动作去执行。为了探索,有很小的概率 epslion 随机地执行某个动作。
epslion-Greedy保证了Replay可以收集到足够丰富的训练数据。超参数 执行随机动作的概率 epslion我一般选择 0.1,然后根据任务需要什么程度的探索强度再修改。
如果离散动作很多,我会尽可能选择大一点的 epslion
在离散动作中,探索衰减表现为逐步减小执行随机动作的概率 在连续动作中,探索衰减表现为逐步减小探索噪声的方差,退火同理。
探索衰减一定会有很好的效果,但这种“效果好”建立在人肉搜索出衰减超参数的基础之上。成熟的DRL算法会自己去调整自己的探索强度。比较两者的调参总时间,依然是使用成熟的DRL算法耗时更短。
对于轨迹(trajectory)来说,采集多少样本合适呢?以Q-learning为例子我们分析,每个epoch收集 m mm 个sample, 通过构造经验结构以及强阿虎学习的值函数,得到值函数为: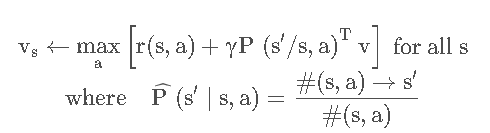
通过先抽样后计算的方式,样本的个数大约为: 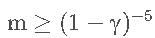
也就是说: 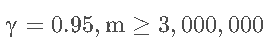
大多数算法还是随着样本增大normalization score也增大
Deep RL之所以受欢迎,是因为它是机器学习ML中唯一可以用测试集训练的领域。
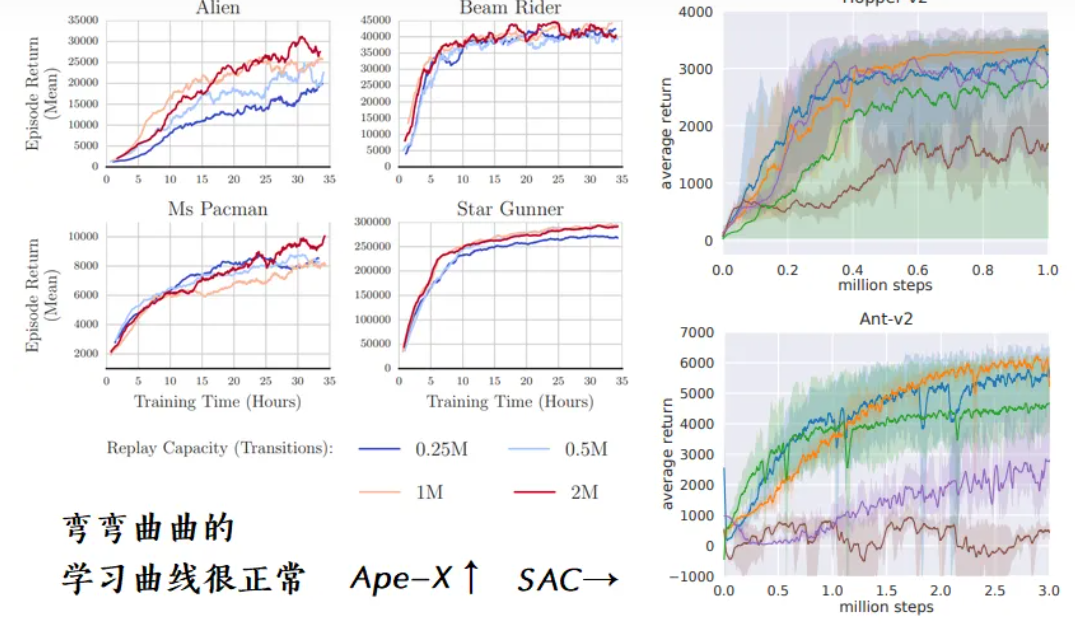
大部分情况下,算法越训练越差能避免,但也可以不理会。因为DRL只需要根据学习曲线保存性能最好的策略即可(前提是对每个策略的实际性能评估足够准确)
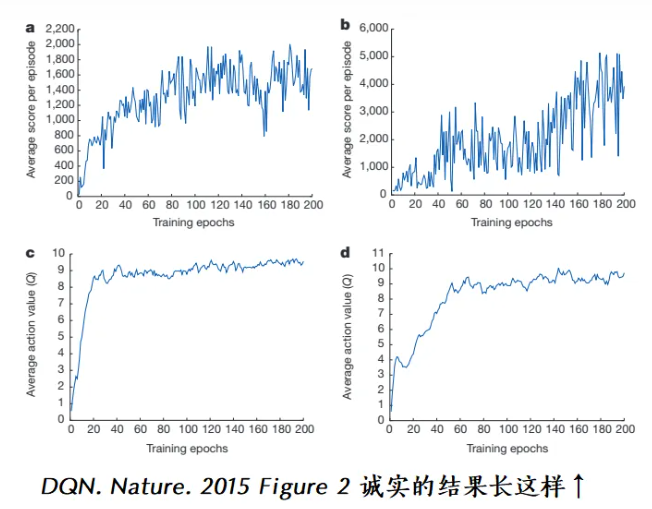
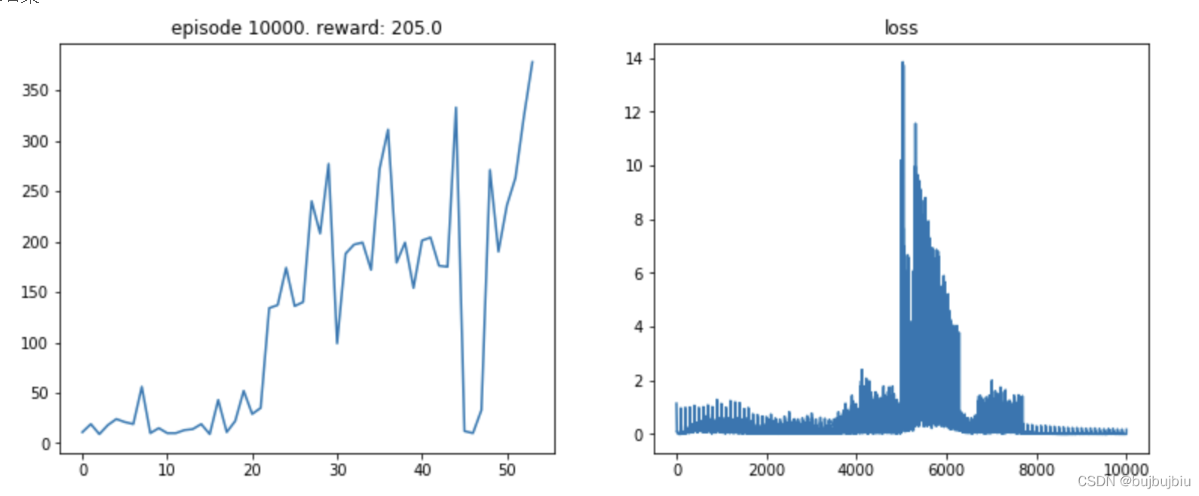
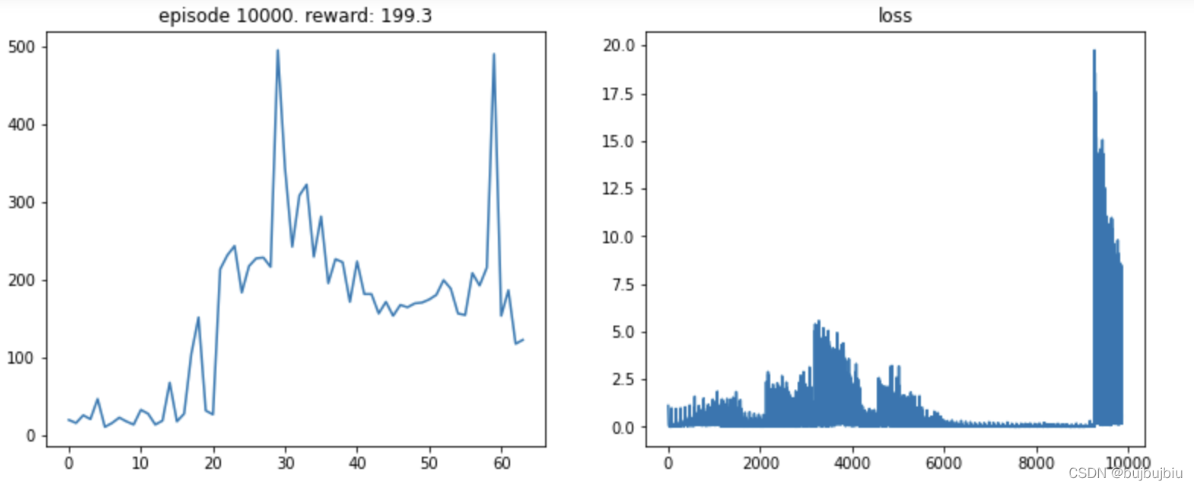
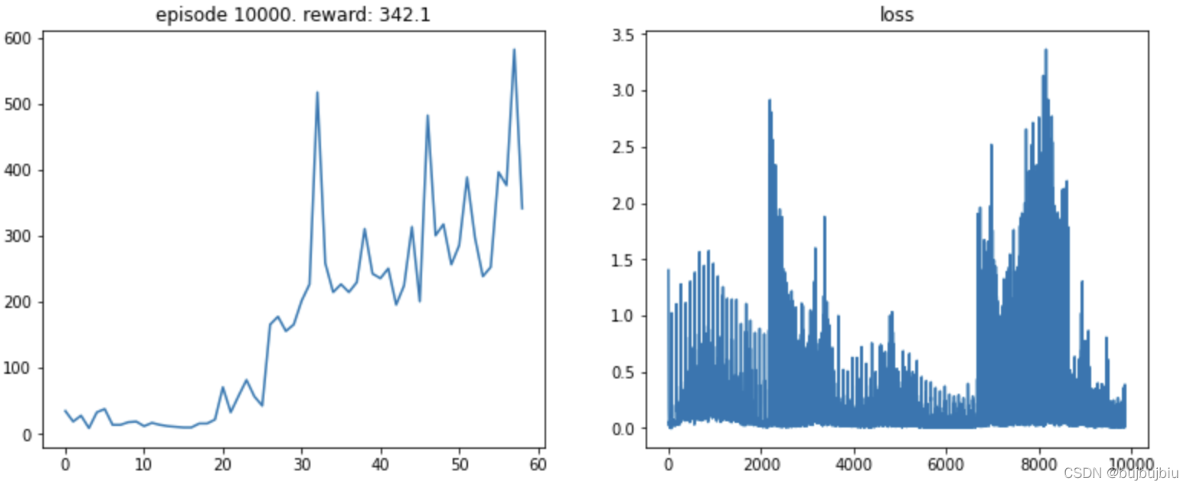
如下图,波动过大的曲线,不利于我们评估DRL算法。
先弄清楚造成波动的原因,然后采用对应的解决方案:
可以通过适当降低学习率(learning rate)来实现。但是,降低学习率又会延长训练所需的时间。
理想情况下 曲线 应该是 滑梯式下降 [绿线]:
[红线]: [紫线]: [黄线]: 若agent与环境互动,则为On-policy(此时因为agent亲身参与,所以互动时的policy和目标的policy一致);若agent看别的agent与环境互动,自己不参与互动,则为Off-policy(此时因为互动的和目标优化的是两个agent,所以他们的policy不一致)。
On-policy:采样所用的policy和目标policy一致,采样后进行学习,学习后目标policy更新,此时需要把采样的policy同步更新以保持和目标policy一致,这也就导致了需要重新采样。
Off-policy:采样的policy和目标的policy不一样,所以你目标的policy随便更新,采样后的数据可以用很多次也可以参考。
监督学习中通常利用已知(已标记)的数据进行学习,其本质是从数据中总结规律,这和人从学1+1=2基本原理一致,强化学习的过程也是如此,仍然是从数据中学习,只不过强化学习中学习的数据是一系列的轨迹{< s 0 , a 0 , r 0 , s 1 > < s 1 , a 1 , r 1 , s 2 > , . . . , < s n − 1 , a n − 1 , r n − 1 , s n >
on-policy直接了当,速度快,但不一定找到最优策略。
off-policy曲折,收敛慢,但采样效率高,是更为强大和通用。
DQN时序差分离线控制算法,off-line 训练的话不会考虑终止状态这种东西。每轮学习都是从memory里抽取记录来学的。
是第一个将深度学习模型与强化学习结合在一起从而成功地直接从高维的输入学习控制策略。
在实践中,DQN将最近的四帧画面当作输入进行训练,因此DQN无法记住四帧之前的内容。换言之,任何需要超过四帧记忆的游戏都将表现为非MDP问题,因为游戏未来的状态(和奖励)不仅仅取决于DQN当前的输入。游戏不再是MDP问题,而是部分可观察的MDP。现实世界中,任务往往不具有完整的信息,且有噪声,因此是部分可观察的。
MDP:Markov decision process
Fully Observable Environments全部可观
又被称之为“无后效性”,即系统的下个状态只与当前状态信息有关,而与更早之前的状态无关
POMDP:partially observable Markov decision process
Partially Observable Environments部分可观
比如在扑克游戏中,只能看到公开的牌面,看不到其他人隐藏的牌。
深度强化学习——DQN_草帽B-O-Y的博客-CSDN博客_dqn
DRQN论文解读_greenmoss的博客-CSDN博客_drqn
离线强化学习(Offline RL)系列1:离线强化学习原理入门_旺财搬砖记的博客-CSDN博客_离线强化学习
离线强化学习(Offline RL)系列4:(数据集) 经验样本复杂度(Sample Complexity)对模型收敛的影响分析_旺财搬砖记的博客-CSDN博客_distribution shift
DQN及其变种(DDQN,Dueling DQN,优先回放)代码实现及结果_bujbujbiu的博客-CSDN博客_ddqn代码
3.1 学习率(learning rate)的选择_追蜗牛的coder的博客-CSDN博客_learning rate
权重衰减(weight decay)与学习率衰减(learning rate decay)_Microstrong0305的博客-CSDN博客_weight decay
我安装了ruby、yeoman,当我运行我的项目时,出现了这个错误:Warning:Running"compass:dist"(compass)taskWarning:YouneedtohaveRubyandCompassinstalledthistasktowork.Moreinfo:https://github.com/gruUse--forcetocontinue.Use--forcetocontinue.我有进入可变session目标的路径,但它不起作用。谁能帮帮我? 最佳答案 我必须运行这个:geminstallcom
文章目录一、项目场景二、基本模块原理与调试方法分析——信源部分:三、信号处理部分和显示部分:四、基本的通信链路搭建:四、特殊模块:interpretedMATLABfunction:五、总结和坑点提醒一、项目场景 最近一个任务是使用simulink搭建一个MIMO串扰消除的链路,并用实际收到的数据进行测试,在搭建的过程中也遇到了不少的问题(当然这比vivado里面的debug好不知道多少倍)。准备趁着这个机会,先以一个很基本的通信链路对simulink基础和相关的debug方法进行总结。 在本篇中,主要记录simulink的基本原理和基本的SISO通信传输链路(QPSK方式),计划在下篇记
我不是Ruby专家,但想弄清楚发生了什么,因为我试图让指南针在节点应用程序中工作,但我的Ruby似乎坏了。打字:ruby--version让我:ruby2.1.1p76(2014-02-24revision45161)[x86_64-darwin13.0]我安装了Homebrew,之前遇到过Ruby版本的问题,但它似乎已安装并且可以正常工作。但是,当我使用gem输入请求时,出现此错误:$gem-hErrorloadingRubyGemsplugin"/Users/user_dir/.rvm/gems/ruby-2.1.1@global/gems/executable-hooks-1.3
在神经网络方面,我完全是个初学者。我整天都在与ruby-fann和ai4r搏斗,不幸的是我没有任何东西可以展示,所以我想我会来到StackOverflow并询问这里的知识渊博的人。我有一组样本——每天都有一个数据点,但它们不符合我能够找出的任何明确模式(我尝试了几次回归)。不过,我认为看看是否有任何方法可以仅从日期预测future的数据会很好,而且我认为神经网络将是生成希望表达这种关系的函数的好方法.日期是DateTime对象,数据点是十进制数,例如7.68。我一直在将DateTime对象转换为float,然后除以10,000,000,000得到一个介于0和1之间的数字,我一直在将
我正在尝试训练一个前馈网络来使用Ruby库AI4R执行异或运算。然而,当我在训练后评估XOR时。我没有得到正确的输出。有没有人以前使用过这个库并得到它来学习异或运算。我使用了两个输入神经元,一个隐藏层中的三个神经元,一个输出层,正如我看到的预计算XOR前馈神经网络就像这样。require"rubygems"require"ai4r"#Createthenetworkwith:#2inputs#1hiddenlayerwith3neurons#1outputsnet=Ai4r::NeuralNetwork::Backpropagation.new([2,3,1])example=[[0,
关于yolov5训练时参数workers和batch-size的理解yolov5训练命令workers和batch-size参数的理解两个参数的调优总结yolov5训练命令python.\train.py--datamy.yaml--workers8--batch-size32--epochs100yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了。这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字。workers和batch-size参数的理解一般训练主要需要调整的参数是这两个:workers指数据装载时cpu所使
我正在尝试安装bootstrap-sass并收到以下错误。我试过旧版本的sass,但bundler一直在安装3.3.0。WARN:UnresolvedspecsduringGem::Specification.reset:sass(~>3.2)WARN:Clearingoutunresolvedspecs.Pleasereportabugifthiscausesproblems./Library/Ruby/Gems/2.0.0/gems/compass-0.12.2/lib/compass/sass_extensions/monkey_patches/browser_support.r
1.深度优先搜索(DFS)深度优先遍历主要思路是从图中一个未访问的顶点V开始,沿着一条路一直走到底,然后从这条路尽头的节点回退到上一个节点,再从另一条路开始走到底…,不断递归重复此过程,直到所有的顶点都遍历完成。例题P1605迷宫题目描述给定一个N×MN\timesMN×M方格的迷宫,迷宫里有TTT处障碍,障碍处不可通过。在迷宫中移动有上下左右四种方式,每次只能移动一个方格。数据保证起点上没有障碍。给定起点坐标和终点坐标,每个方格最多经过一次,问有多少种从起点坐标到终点坐标的方案。输入格式第一行为三个正整数N,M,TN,M,TN,M,T,分别表示迷宫的长宽和障碍总数。第二行为四个正整数SX,S
目录配置模拟模拟类型与实例期望录制-回放-验证指定调用计数验证指定自定义结果验证调用参数联级模拟部分模拟模拟未实现的类其他伪装伪装方法及类伪装未实现类本文主要内容如何在SpringBoot中配置使用JMockit如何mock/faking依赖的对象如何对行为mock如何VerificationJMockit之所以强大,是因其使用了javaagent对类的字节码做了修改,在JVM的所有mock工具中,它是功能最强大的。同时注解又是最少的。配置在SpringBoot项目中使用JMockit隔离代码做单元测试,需要做以下配置引入JMockit依赖。dependencies>dependency>gr
几年前,我从一些Rails初学者指南开始学习Ruby/Rails。那时我已经学习了Rails的基础知识,例如模型和路由的一些约定优于配置,以及如何使用helpers等。但是,我并没有坚持多久,因为此后不久我发现了Sinatra,并决定我个人更喜欢它。不过,我最终真的爱上了Ruby,从那以后我写了很多Ruby,几乎没有一个是针对任何Rails项目的。然而,事实证明大部分可用的Ruby工作都是针对Rails应用程序的。所以我现在想再尝试一下Rails。现在,该引用资料很棒并且有很多有用的信息,但我只查看了我需要的特定内容的引用资料,而没有记住。但我不太可能在引用资料中看到像script/c