开源地址:
https://github.com/fundamentalvision/deformable-detr
超级小白,摸索了几天,感谢批评指正!!!
一、数据集准备
1.下载数据集:
train_2017:
http://images.cocodataset.org/zips/train2017.zip
val_2017:
http://images.cocodataset.org/zips/val2017.zip
2.下载标注文件(instances_train2017.json instances_val2017.json)
http://images.cocodataset.org/annotations/annotations_trainval2017.zip
3.数据集文件夹
二、环境配置(命令)
1. 创建python环境:
conda create -n deformable_detr python=3.7 pip
2. 激活环境:
conda activate deformable_detr
PyTorch>=1.5.1, torchvision>=0.6.1,自行配置,不赘述

3. 安装必要的包:
pip install -r requirements.txt
4. 编译cuda操作:
cd ./models/ops
sh ./make.sh
编译成功后可 pip list 结果如下:
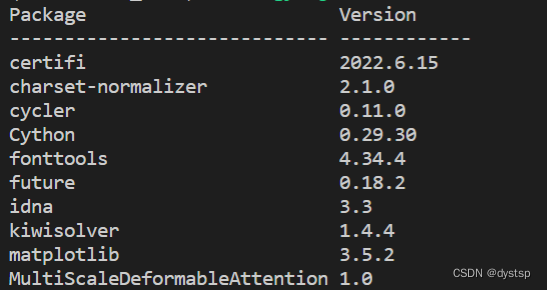
有 MultiScaleDeformableAttention 包
5. 测试 python test.py (可省略):
运行test.py的时间太长,我直接Kill了
6. 运行 python main.py
也可以使用官方给的命令:
GPUS_PER_NODE=8 ./tools/run_dist_launch.sh 8 ./configs/r50_deformable_detr.sh
进行修改,如两张卡进行训练:
GPUS_PER_NODE=2 ./tools/run_dist_launch.sh 2 ./configs/r50_deformable_detr.sh
(我的环境是Linux,此处会出现chmod文件权限问题,百度即可自行解决,用到了chmod 777)
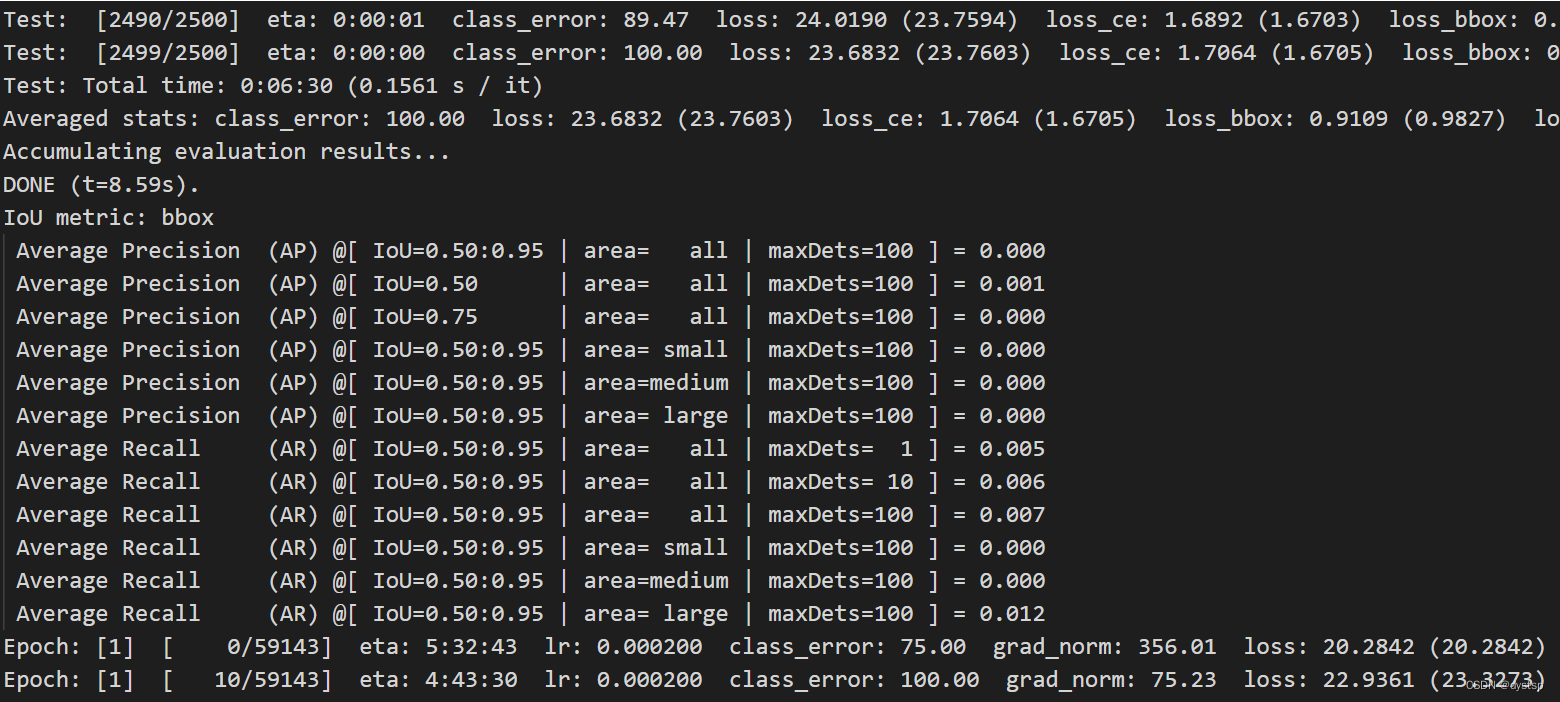
7. 训练过程:训练Epoch:[0] 结束后会进行Test,然后接着Epoch:[1]训练
三、预测
由于训练时间太长,我直接Kill了,使用官方给的权重进行预测
1. 下载权重文件:r50_deformable_detr-checkpoint.pth
如图点击model下载(需要梯子)
https://drive.google.com/file/d/1nDWZWHuRwtwGden77NLM9JoWe-YisJnA/view

2. 待预测图片及其位置:
(我自己从COCO数据集随机复制的几张图片)
3. 运行如下代码 predict.py(代码非原创,参考网上修改):
import cv2
from PIL import Image
import numpy as np
import os
import time
import torch
from torch import nn
import torchvision.transforms as T
from main import get_args_parser as get_main_args_parser
from models import build_model
torch.set_grad_enabled(False)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("[INFO] 当前使用{}做推断".format(device))
# 图像数据处理
transform = T.Compose([
T.Resize(800),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# plot box by opencv
def plot_result(pil_img, prob, boxes, save_name=None, imshow=False, imwrite=False):
opencvImage = cv2.cvtColor(np.array(pil_img), cv2.COLOR_RGB2BGR)
LABEL =['N/A', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A',
'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse',
'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack',
'umbrella', 'N/A', 'N/A', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis',
'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove',
'skateboard', 'surfboard', 'tennis racket', 'bottle', 'N/A', 'wine glass',
'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich',
'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake',
'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table', 'N/A',
'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard',
'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A',
'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush']
for p, (xmin, ymin, xmax, ymax) in zip(prob, boxes):
cl = p.argmax()
label_text = '{}: {}%'.format(LABEL[cl], round(p[cl] * 100, 2))
cv2.rectangle(opencvImage, (int(xmin), int(ymin)), (int(xmax), int(ymax)), (255, 255, 0), 2)
cv2.putText(opencvImage, label_text, (int(xmin) + 10, int(ymin) + 30), cv2.FONT_HERSHEY_SIMPLEX, 1,
(255, 255, 0), 2)
if imshow:
cv2.imshow('detect', opencvImage)
cv2.waitKey(0)
if imwrite:
if not os.path.exists("./result/pred"):
os.makedirs('./result/pred')
cv2.imwrite('./result/pred/{}'.format(save_name), opencvImage)
# 将xywh转xyxy
def box_cxcywh_to_xyxy(x):
x_c, y_c, w, h = x.unbind(1)
b = [(x_c - 0.5 * w), (y_c - 0.5 * h),
(x_c + 0.5 * w), (y_c + 0.5 * h)]
return torch.stack(b, dim=1)
def rescale_bboxes(out_bbox, size):
img_w, img_h = size
b = box_cxcywh_to_xyxy(out_bbox)
b = b.cpu().numpy()
b = b * np.array([img_w, img_h, img_w, img_h], dtype=np.float32)
return b
def load_model(model_path , args):
model, _, _ = build_model(args)
model.cuda()
model.eval()
state_dict = torch.load(model_path) # <-----------修改加载模型的路径
model.load_state_dict(state_dict["model"])
model.to(device)
print("load model sucess")
return model
# 图像的推断
def detect(im, model, transform, prob_threshold=0.7):
# mean-std normalize the input image (batch-size: 1)
img = transform(im).unsqueeze(0)
# propagate through the model
img = img.to(device)
start = time.time()
outputs = model(img)
# keep only predictions with 0.7+ confidence
print(outputs['pred_logits'].softmax(-1)[0, :, :-1])
probas = outputs['pred_logits'].softmax(-1)[0, :, :-1]
keep = probas.max(-1).values > prob_threshold
probas = probas.cpu().detach().numpy()
keep = keep.cpu().detach().numpy()
# convert boxes from [0; 1] to image scales
bboxes_scaled = rescale_bboxes(outputs['pred_boxes'][0, keep], im.size)
end = time.time()
return probas[keep], bboxes_scaled, end - start
if __name__ == "__main__":
main_args = get_main_args_parser().parse_args()
# 加载模型
dfdetr = load_model('DDETR/r50_deformable_detr-checkpoint.pth',main_args) # <--修改为自己加载模型的路径
files = os.listdir("DDETR/data/coco/mytestdata/") # <--修改为待预测图片所在文件夹路径
cn = 0
waste=0
for file in files:
img_path = os.path.join("DDETR/data/coco/mytestdata/", file) # <--修改为待预测图片所在文件夹路径
im = Image.open(img_path)
scores, boxes, waste_time = detect(im, dfdetr, transform)
plot_result(im, scores, boxes, save_name=file, imshow=False, imwrite=True)
print("{} [INFO] {} time: {} done!!!".format(cn,file, waste_time))
cn+=1
waste+=waste_time
waste_avg = waste/cn
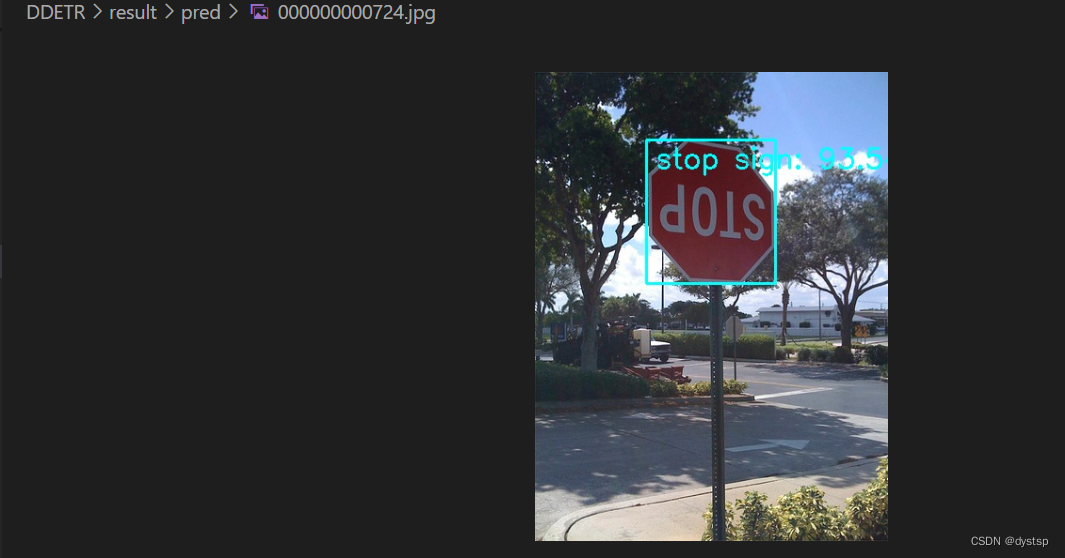
print(waste_avg)4. 预测结果及预览:
使用Deformable DETR进行预测:
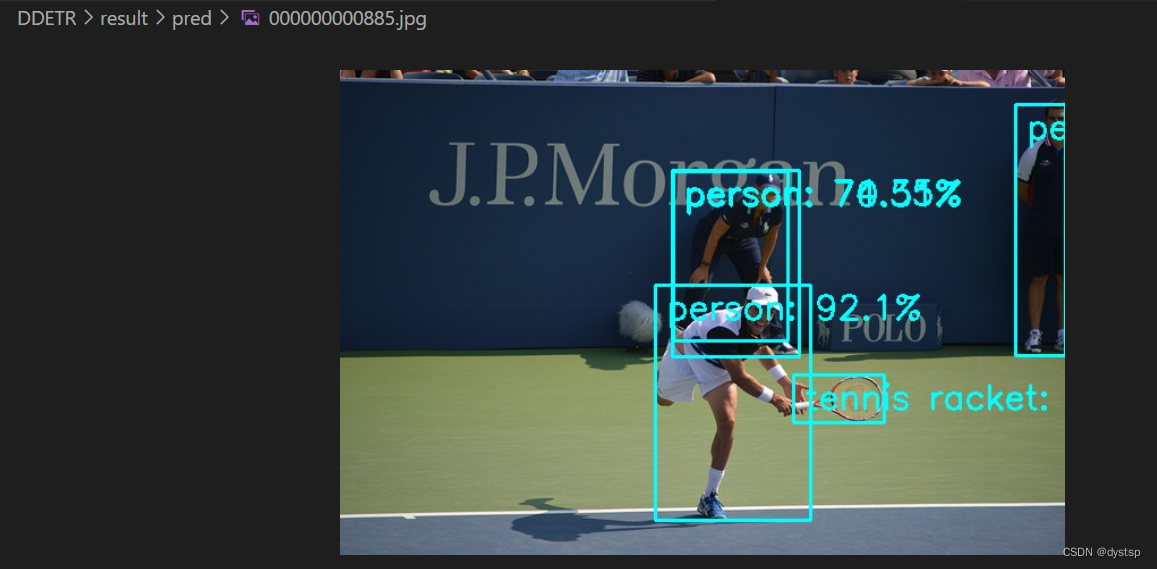
参考:
https://www.jianshu.com/p/b364534fd0a7
Windows下运行Deformable-DETR_harold_du的博客-CSDN博客_deformable detr
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
在神经网络方面,我完全是个初学者。我整天都在与ruby-fann和ai4r搏斗,不幸的是我没有任何东西可以展示,所以我想我会来到StackOverflow并询问这里的知识渊博的人。我有一组样本——每天都有一个数据点,但它们不符合我能够找出的任何明确模式(我尝试了几次回归)。不过,我认为看看是否有任何方法可以仅从日期预测future的数据会很好,而且我认为神经网络将是生成希望表达这种关系的函数的好方法.日期是DateTime对象,数据点是十进制数,例如7.68。我一直在将DateTime对象转换为float,然后除以10,000,000,000得到一个介于0和1之间的数字,我一直在将
我正在尝试训练一个前馈网络来使用Ruby库AI4R执行异或运算。然而,当我在训练后评估XOR时。我没有得到正确的输出。有没有人以前使用过这个库并得到它来学习异或运算。我使用了两个输入神经元,一个隐藏层中的三个神经元,一个输出层,正如我看到的预计算XOR前馈神经网络就像这样。require"rubygems"require"ai4r"#Createthenetworkwith:#2inputs#1hiddenlayerwith3neurons#1outputsnet=Ai4r::NeuralNetwork::Backpropagation.new([2,3,1])example=[[0,
最近在工作中,看到一些新手测试同学,对接口测试存在很多疑问,甚至包括一些从事软件测试3,5年的同学,在聊到接口时,也是一知半解;今天借着这个机会,对接口测试做个实战教学,顺便总结一下经验,分享给大家。计划拆分成4个模块跟大家做一个分享,(接口测试、接口基础知识、接口自动化、接口进阶)感兴趣的小伙伴记得关注,希望对你的日常工作和求职面试,带来一些帮助。注:文章较长有5000多字,希望小伙伴们认真看完,当然有些内容对小白同学不是太友好,如果你需要详细了解其中的一些概念或者名词,请在文章之后留言,后续我将针对大家的疑问,整理输出一些大家感兴趣的文章。随着开发模式的迭代更新,前后端分离已不是新的概念,
关于yolov5训练时参数workers和batch-size的理解yolov5训练命令workers和batch-size参数的理解两个参数的调优总结yolov5训练命令python.\train.py--datamy.yaml--workers8--batch-size32--epochs100yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了。这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字。workers和batch-size参数的理解一般训练主要需要调整的参数是这两个:workers指数据装载时cpu所使
1.深度优先搜索(DFS)深度优先遍历主要思路是从图中一个未访问的顶点V开始,沿着一条路一直走到底,然后从这条路尽头的节点回退到上一个节点,再从另一条路开始走到底…,不断递归重复此过程,直到所有的顶点都遍历完成。例题P1605迷宫题目描述给定一个N×MN\timesMN×M方格的迷宫,迷宫里有TTT处障碍,障碍处不可通过。在迷宫中移动有上下左右四种方式,每次只能移动一个方格。数据保证起点上没有障碍。给定起点坐标和终点坐标,每个方格最多经过一次,问有多少种从起点坐标到终点坐标的方案。输入格式第一行为三个正整数N,M,TN,M,TN,M,T,分别表示迷宫的长宽和障碍总数。第二行为四个正整数SX,S
目录FIFO一.自定义同步FIFO1.1代码设计1.2Testbech1.3行为仿真***学习位宽计算函数$clog2()***$clog2()系统函数使用,可以不关注***分布式资源或者BLOCKBRAM二.异步FIFO2.1在FIFO判满的时候有两种方式:2.2异步FIFO为什么要使用格雷码2.2.1介绍格雷码2.2.2格雷码在异步FIFO中的应用2.2.2格雷码判满2.4二进制与格雷码之间的转换2.4.1二进制码转换为格雷码的方法2.4.2格雷码转换为二进制码的方法2.3实现框图2.5实现及仿真代码2.6仿真图验证2.7结论FIFO 这篇更多的是记录FIFO学习,参考了众多优秀的文章,
运行有问题或需要源码请点赞关注收藏后评论区留言一、利用ContentResolver读写联系人在实际开发中,普通App很少会开放数据接口给其他应用访问。内容组件能够派上用场的情况往往是App想要访问系统应用的通讯数据,比如查看联系人,短信,通话记录等等,以及对这些通讯数据及逆行增删改查。首先要给AndroidMaifest.xml中添加响应的权限配置 下面是往手机通讯录添加联系人信息的例子效果如下分成三个步骤先查出联系人的基本信息,然后查询联系人号码,再查询联系人邮箱代码 ContactAddActivity类packagecom.example.chapter07;importandroid
查看原文>>>基于”PLUS模型+“生态系统服务多情景模拟预测实践技术应用目录第一章、理论基础与软件讲解第二章、数据获取与制备第三章、土地利用格局模拟第四章、生态系统服务评估第五章、时空变化及驱动机制分析第六章、论文撰写技巧及案例分析基于ArcGISPro、Python、USLE、INVEST模型等多技术融合的生态系统服务构建生态安全格局基于生态系统服务(InVEST模型)的人类活动、重大工程生态成效评估、论文写作等具体应用基于ArcGISPro、R、INVEST等多技术融合下生态系统服务权衡与协同动态分析实践应用 本文从数据、方法、实践三方面对生态系统服务多情景预测进行讲解。内容涵盖多
📝学技术、更要掌握学习的方法,一起学习,让进步发生👩🏻作者:一只IT攻城狮。💐学习建议:1、养成习惯,学习java的任何一个技术,都可以先去官网先看看,更准确、更专业。💐学习建议:2、然后记住每个技术最关键的特性(通常一句话或者几个字),从主线入手,由浅入深学习。❤️《SpringCloud入门实战系列》解锁SpringCloud主流组件入门应用及关键特性。带你了解SpringCloud主流组件,是如何一战解决微服务诸多难题的。项目demo:源码地址👉🏻SpringCloud入门实战系列不迷路👈🏻:SpringCloud入门实战(一)什么是SpringCloud?SpringCloud入门实战