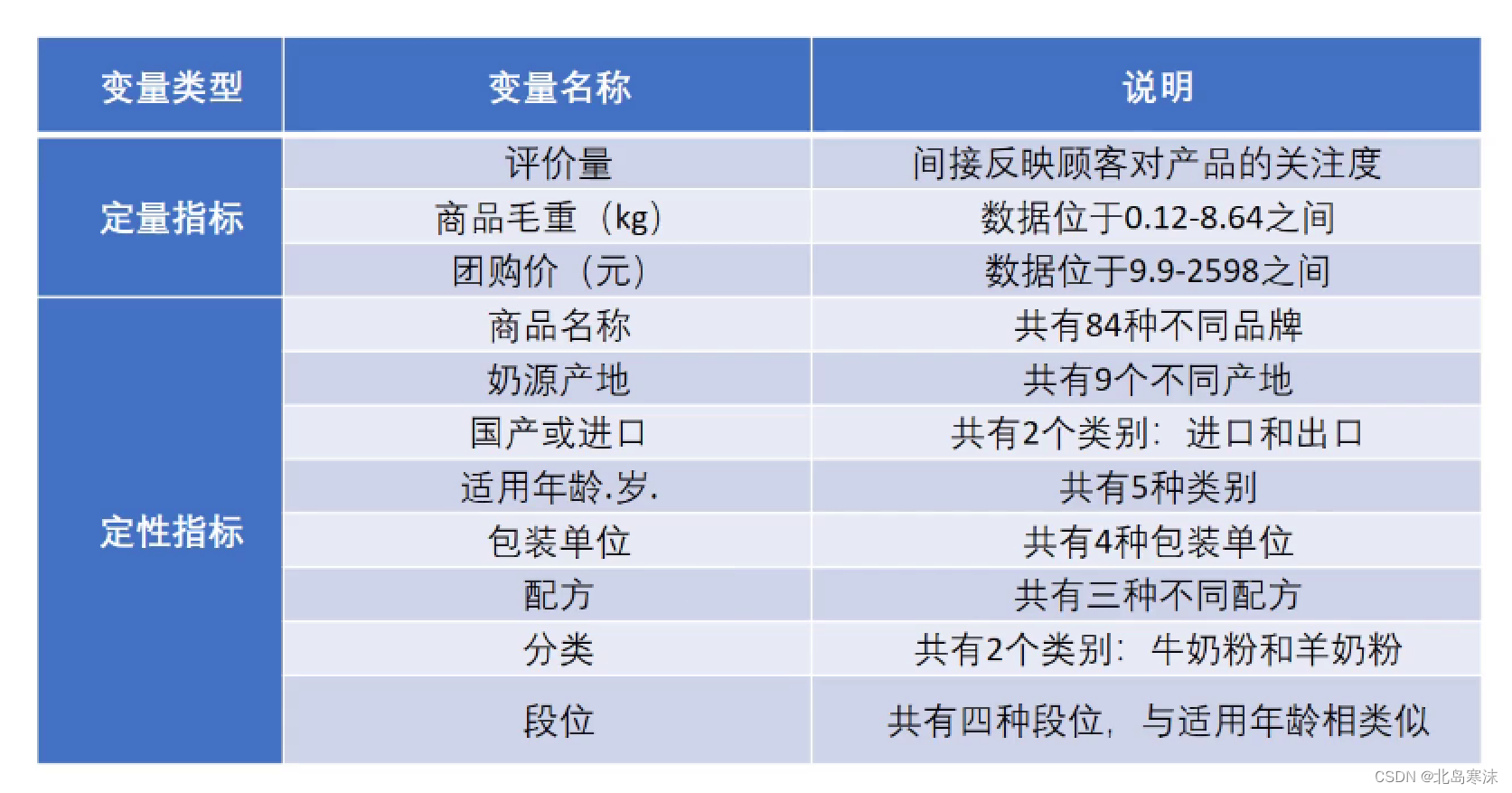
多元线性回归分析
回归分析的地位:数据分析中最基础也是最重要的分析工作,绝大多数的数据分析问题都可以使用回归的思想来解决。
回归分析的任务:通过研究自变量和因变量的相关关系,尝试用自变量来解释因变量的形成机制,从而达到通过自变量去预测因变量的目的。具体如下:
备注:
①相关性和因果性的关系:相关性容易和因果性弄混淆。在绝大多数情况下,我们都没有能力去探究严格的因果关系,所以只能退而求其次研究相关关系。
②解释变量与被解释变量:自变量也称为解释变量;因变量也称为被解释变量。
③统一量纲的处理:根据回归系数比较不同自变量的相对重要性时首先需要统一量纲,进行标准化回归。
常见的回归分析类型:线性回归、0-1回归、定序回归、计数回归和生存回归。这些类型的划分依据是因变量的类型。
| 回归类型 | 因变量类型 | 求解模型 |
|---|---|---|
| 线性回归 | 连续数值型变量 | 普通最小二乘法(OLS)、广义最小二乘法(GLS) |
| 0-1回归 | 二值变量 | 逻辑斯蒂回归 |
| 定序回归 | 定序变量 | Probit回归 |
| 计数回归 | 计数变量 | 泊松回归 |
| 生存回归 | 定序变量 | Cox等比例风险回归 |
备注:生存变量是指经过截断后的寿命数据。
回归分析的数据要求:样本数要不少于自变量个数才能进行回归分析。
建模比赛中常考的数据类型:建模比赛中最常用到的是横截面数据和时间序列数据;面板数据更加复杂,属于计量经济学中的模型内容。
不同数据类型的求解模型:横截面数据往往可以使用回归模型进行建模;时间序列数据往往需要我们进行预测,可选的模型较多
一元回归模型和多元回归模型:只有一个自变量的回归模型称为一元回归模型,有多个自变量的回归模型称为多元回归模型。
回归模型与拟合模型的区别:
对线性的理解:只要能够通过一定的转换将自变量和因变量转换成线性关系都可以认为是线性模型。因此下图中的四个表达式都可以认为是线性模型。
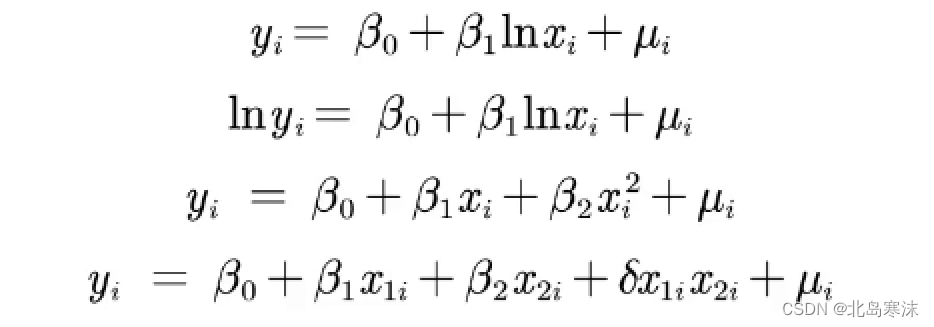
数据转换使用的软件:数据转换在数据预处理步骤完成,使用Excel、Matlab或Stata都可以对数据进行预处理。
回归系数的解释:
内生性的相关概念:
控制模型内生性的方法:严格外生性的条件非常苛刻,因为解释变量一般非常多,因此实际使用时需要弱化条件,将解释变量分为核心解释变量和控制变量。
在实际应用中,只需要保证核心解释变量与扰动项不相关即可。
何时需要对变量取对数预处理:取对数意味着被解释变量对解释变量的弹性,也就是百分比的变化而不是数值的变化。取对数没有固定的规则,但是有一些经验法则。
取对数的作用:
四类模型回归系数的解释:
虚拟变量:
自变量的交互效应:自变量的乘积作为一个新的自变量,表示因变量受到一个自变量和另一个自变量的共同影响。
Stata是进行多元线性回归分析最好用的软件之一。
Stata导入数据:文件→导入→Excel表格→确定。
Stata清空数据:使用clear命令。
Stata保存代码:新建一个do-file编辑器→在编辑器中输入代码→保存do文件。
Stata数据的描述性统计:
summarize 变量名1 变量名2....定量数据的描述性统计结果: 定量数据的描述性统计结果中包含每一个变量对应的样本数、均值、标准差、最大值和最小值。
tabulate 变量名,gen(虚拟变量名)定性数据的描述性统计:每次只能对一个定性变量进行描述性统计并生成指定名称的虚拟变量。描述性统计的结果是各个类别的频数和频率。
备注:
①频数饼状图的绘制:在得到某个定性数据的频数后,最好使用Excel绘制一张频数统计饼状图,这样使得得到的结果更加直观。
②总体描述性结果表格:在对所有变量都进行描述性统计后,最好绘制一张结果汇总分析表格,表格的样式可以如下图所示:
Stata进行回归分析:
regress 因变量 自变量1,自变量2...回归结果分析:
拟合优度的分析:
模型联合显著性:只有当对应的P值小于0.05才能认为该回归模型是显著的,才能够使用该模型。
回归系数表:回归系数表中记录了各个自变量对应的回归系数及它们对应的显著性检验P值,只有检验P值小于0.05的自变量才是显著的,需要进行分析。
Stata回归分析结果表格的docx保存:
首先需要再Stata中使用下列的命令安装第三方插件:ssc install reg2docx
在回归regress语句的下一条语句使用,首先保存模型结果:est store 模型名
最后将模型结果导出到一个文本文档中(docx):reg2docx 模型名 using docx文件名名,replace
标准化回归:
regress 因变量 自变量1,自变量2... ,beta,标准化回归结果中会给出标准化回归系数,球型扰动项:之前讨论的多元线性回归模型中,我们都假设扰动项属于球型扰动项,也就是需要满足“同方差”和“无自相关”两个条件。但是实际问题中的扰动项不满足“同方差”性质,所以存在异方差问题;不满足“无自相关”性质,所以存在自相关问题。
异方差带来的危害:
异方差的检验:
1.残差图检验法:可以用Stata自带的残差图函数来直观检验异方差,但是可能不够准确。使用残差图检验之前需要首先进行回归分析。
残差图异方差检验语法:
rvfplot:作出残差和拟合值关系的散点图。如果拟合值较小时残差波动小,拟合值变大时残差波动也变大则可以判定存在异方差现象。rvpplot x:作出残差和自变量x关系的散点图。如果自变量很小时残差波动很大,自变量变大时残差波动减小,则说明存在异方差现象。补充:
…
1.图像绘制完成的保存语法:graph export 保存文件名,replace
保存的文件和当前的Stata文件在同一个文件夹中。
其中的replace表示如果存在同名的图像,则进行替换。
…
2.绘制概率密度函数图的语法:kdensity 变量名
作用:用于判断某一个变量的值的分布情况。
…
3.获取某变量分布情况的统计表格:summarize 变量名,d
作用:可以求出在不同的百分数处对应的元素。
2.BP检验法:
estat hettest,rhs iid3.怀特检验:
estat imtest,white异方差问题的解决方法:
这是最简单也是目前最通用的方法,同时也是推荐在大多数情况下使用的方法。
Stata语法:regress 因变量 自变量1,自变量2... ,robust
不推荐这种方法,因为由于我们不知道扰动项真实的协方差矩阵,因此只能通过样本数据来估计,这样得到的结果不稳健,存在偶然性。
多重共线性的概念:自变量之间存在较为严重的线性相关性。
完全多重共线性的相关概念:
多重共线性带来的问题:
多重共线性的检验:可以通过计算方差膨胀因子进行多重共线性检验。
estat vif(在回归分析后使用)多重共线性的处理:
逐步回归法的概述:逐步回归可以用于解决多重共线性问题。逐步回归可以分为向前逐步回归和向后逐步回归两种具体算法。
向前逐步回归法:
stepwise regress y x1,x2... ,pe(显著性水平)向后逐步回归法:
具体步骤:先把所有自变量放入模型,之后尝试将其中一个自变量从模型中剔除,看整个模型解释因变量的变异是否有显著变化,最后把最没用解释力的那个自变量剔除,直到没有自变量符合剔除的条件。
存在的问题:一开始把所有变量都引入回归方程,这样计算量非常大。不过,这个缺点随着计算机能力的提升已经不太影响了。因此更加推荐使用这种方法进行逐步回归。
Stata语法:stepwise regress y,x1,x2... ,pr(显著性水平)
注意事项:
①避免完全多重共线性:Stata进行逐步回归时要求各个自变量之间不能存在完全多重共线性,这一点与使用Stata直接进行回归不同。
②显著性值会影响筛选的变量个数:显著性水平越高,筛选出的变量越多;显著性水平越低,筛选出的变量越少。
③向前逐步回归和向后逐步回归的结果可能不同。
④慎重使用逐步回归法。因为剔除了自变量后可能会产生新的如内生性问题。(数模比赛中也可以不考虑内生性)
⑤最好的变量筛选方法:如果可能,最好把每一种情况都尝试一次,如果不考虑效率的话这是最好的筛选方法。
我希望将Favorite模型添加到我的User和Link模型。业务逻辑用户可以有多个链接(即可以添加多个链接)用户可以收藏多个链接(他们自己的或其他用户的)一个链接可以被多个用户收藏,但只有一个所有者我对如何为这种关联建模以及在模型就位后如何创建用户收藏夹感到困惑?classUser 最佳答案 下面的数据模型怎么样:classUser:destroyhas_many:favorite_links,:through=>:favorites,:source=>:linkendclassLink:destroyhas_many:favor
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/
ruby中有这样的东西吗?send(+,1,2)我想让这段代码看起来不那么冗余ifop=="+"returnarg1+arg2elsifop=="-"returnarg1-arg2elsifop=="*"returnarg1*arg2elsifop=="/"returnarg1/arg2 最佳答案 是的,只需像这样使用send(或者更好的是public_send):arg1.public_send(op,arg2)这是可行的,因为Ruby中的大多数运算符(包括+、-、*、/、andmore)只需调用方法。所以1+2与1.+(2)相同
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
文章目录1、自相关函数ACF2、偏自相关函数PACF3、ARIMA(p,d,q)的阶数判断4、代码实现1、引入所需依赖2、数据读取与处理3、一阶差分与绘图4、ACF5、PACF1、自相关函数ACF自相关函数反映了同一序列在不同时序的取值之间的相关性。公式:ACF(k)=ρk=Cov(yt,yt−k)Var(yt)ACF(k)=\rho_{k}=\frac{Cov(y_{t},y_{t-k})}{Var(y_{t})}ACF(k)=ρk=Var(yt)Cov(yt,yt−k)其中分子用于求协方差矩阵,分母用于计算样本方差。求出的ACF值为[-1,1]。但对于一个平稳的AR模型,求出其滞
目录0专栏介绍1平面2R机器人概述2运动学建模2.1正运动学模型2.2逆运动学模型2.3机器人运动学仿真3动力学建模3.1计算动能3.2势能计算与动力学方程3.3动力学仿真0专栏介绍?附C++/Python/Matlab全套代码?课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等);局部规划(DWA、APF等);曲线优化(贝塞尔曲线、B样条曲线等)。?详情:图解自动驾驶中的运动规划(MotionPlanning),附几十种规划算法1平面2R机器人概述如图1所示为本文的研究本体——平面2R机器人。对参数进行如下定义:机器人广义坐标