import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline 我们可以通过shape属性知道数据集的大小,如行和列的总数,如下所示,该属性显示一个有891行和12列的元组。为了找到变量的数据类型,我们有info方法,它可以返回变量、数据类型、内存使用量和关于每个变量的缺失值,Age只有714,Cabin只有 204,不是891,因此他们需要被填充,在接下来我们对其进行可视化并处理缺失值。
我们可以通过shape属性知道数据集的大小,如行和列的总数,如下所示,该属性显示一个有891行和12列的元组。为了找到变量的数据类型,我们有info方法,它可以返回变量、数据类型、内存使用量和关于每个变量的缺失值,Age只有714,Cabin只有 204,不是891,因此他们需要被填充,在接下来我们对其进行可视化并处理缺失值。df.shape(891, 12)df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KBdf.isnull().sum()PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64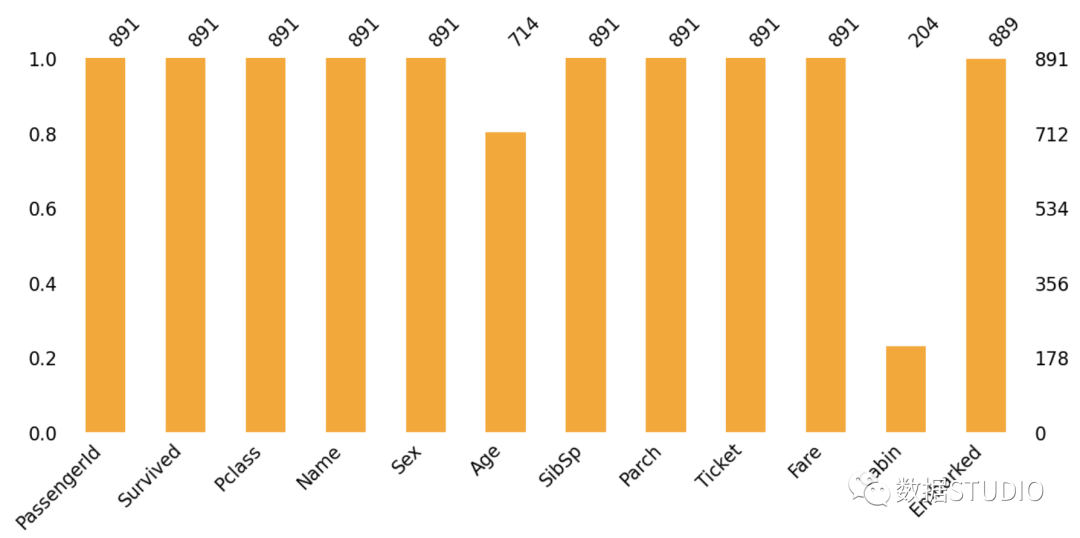 现在来处理缺失的 "Age" 值,"Age" 的数据类型是数字(Float),一般来说,缺失的数字列会用它们的平均值或中位数或任何基于我们直觉的值来填补,无论哪种都是最好的。在更新空值之前,检查一下基于 "Pclass" 和 "Sex" 列的均值和中值。下图显示了基于 "Pclass" 和 "Sex" 分组的平均数和中位数。这里我们可以看到平均数和中位数都非常接近,所以更好的选择是继续使用中位数。
现在来处理缺失的 "Age" 值,"Age" 的数据类型是数字(Float),一般来说,缺失的数字列会用它们的平均值或中位数或任何基于我们直觉的值来填补,无论哪种都是最好的。在更新空值之前,检查一下基于 "Pclass" 和 "Sex" 列的均值和中值。下图显示了基于 "Pclass" 和 "Sex" 分组的平均数和中位数。这里我们可以看到平均数和中位数都非常接近,所以更好的选择是继续使用中位数。df.groupby(["Pclass", "Sex"])["Age"].mean()Pclass Sex
1 female 34.611765
male 41.281386
2 female 28.722973
male 30.740707
3 female 21.750000
male 26.507589
Name: Age, dtype: float64df.groupby(["Pclass", "Sex"])["Age"].median()Pclass Sex
1 female 35.0
male 40.0
2 female 28.0
male 30.0
3 female 21.5
male 25.0
Name: Age, dtype: float64# Fillin the age values for Pclass =1 for male and Female
df.loc[df.Age.isnull() & (df.Sex == "male") & (df.Pclass == 1), "Age"] = 37
df.loc[df.Age.isnull() & (df.Sex == "female") & (df.Pclass == 1), "Age"] = 35.5
# Fillin the age values for Pclass =2 for male and Female
df.loc[df.Age.isnull() & (df.Sex == "male") & (df.Pclass == 2), "Age"] = 29.0
df.loc[df.Age.isnull() & (df.Sex == "female") & (df.Pclass == 2), "Age"] = 28.5
# Fillin the age values for Pclass =2 for male and Female
df.loc[df.Age.isnull() & (df.Sex == "male") & (df.Pclass == 3), "Age"] = 25
df.loc[df.Age.isnull() & (df.Sex == "female") & (df.Pclass == 3), "Age"] = 22df.drop(columns="Cabin", inplace=True)
ms.bar(df, color="orange", inline=True)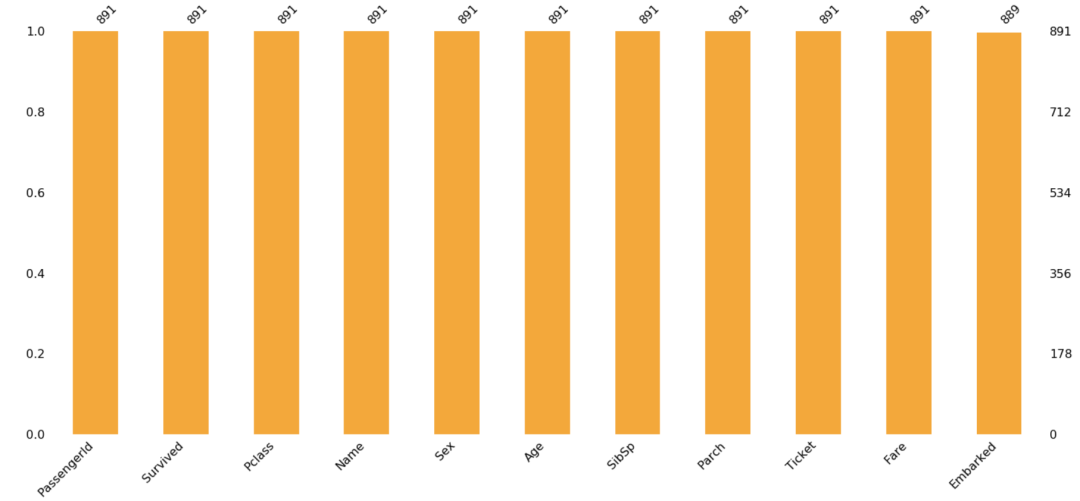 数据处理部分已经完成。现在可以利用这些干净的数据,对其进行分析。在进一步进行之前,了解每一列所代表的内容。下面描述了每一列含义,这些字段很简单,不言自明。PassengerId:只是一个序列号Survived: 0 = No, 1 = Yespclass: Ticket class 1 = 1st, 2 = 2nd, 3 = 3rdsibsp: # 在泰坦尼克号上的兄弟姐妹/配偶的数量parch: # 泰坦尼克号上的父母/子女的数量ticket: Ticket numbercabin: Cabin numberembarked: Port of Embarkation C = Cherbourg, Q = Queenstown, S = Southampton现在我们对数据集有了一个概念,但我们想从数据集中定义的问题陈述是什么?它可以是像幸存的总人数或他们旅行的班级,或有多少人有兄弟姐妹或配偶,父母-子女,等等。接下来用seaborn来绘图。变量识别仅仅重申我们在统计学章节中讨论过的内容,我们有两种变量分类和数字,这些变量又进一步细分为序数和名义,以及数字变量的连续和离散,如图所示。
数据处理部分已经完成。现在可以利用这些干净的数据,对其进行分析。在进一步进行之前,了解每一列所代表的内容。下面描述了每一列含义,这些字段很简单,不言自明。PassengerId:只是一个序列号Survived: 0 = No, 1 = Yespclass: Ticket class 1 = 1st, 2 = 2nd, 3 = 3rdsibsp: # 在泰坦尼克号上的兄弟姐妹/配偶的数量parch: # 泰坦尼克号上的父母/子女的数量ticket: Ticket numbercabin: Cabin numberembarked: Port of Embarkation C = Cherbourg, Q = Queenstown, S = Southampton现在我们对数据集有了一个概念,但我们想从数据集中定义的问题陈述是什么?它可以是像幸存的总人数或他们旅行的班级,或有多少人有兄弟姐妹或配偶,父母-子女,等等。接下来用seaborn来绘图。变量识别仅仅重申我们在统计学章节中讨论过的内容,我们有两种变量分类和数字,这些变量又进一步细分为序数和名义,以及数字变量的连续和离散,如图所示。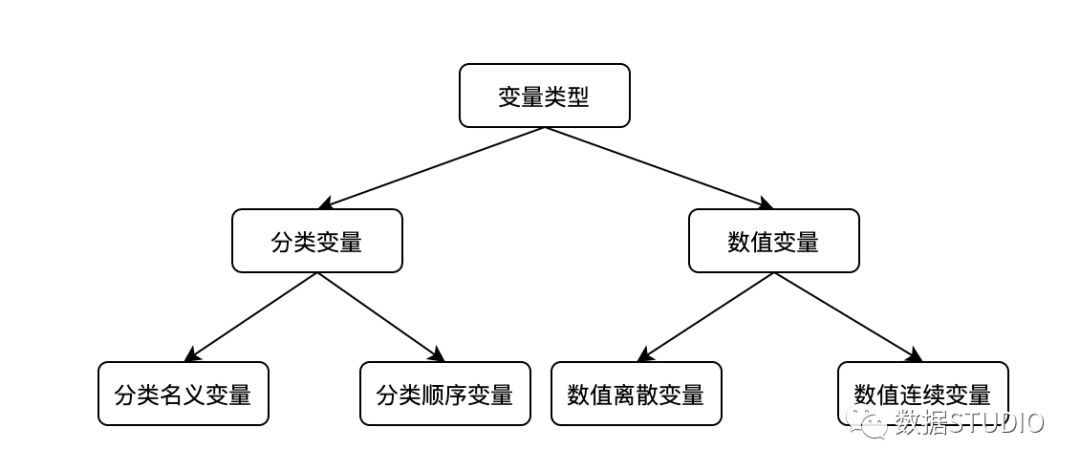 分类名义变量顺序变量的定义与分类变量类似;这里需要提到的是,它没有任何特定的顺序。一个例子是我们不能在这里假设男性大于女性。我们不能假设一个类别大于或小于其他类别,而且它们没有任何特定的顺序。分类顺序变量分类的、序数的变量可以按特定的顺序排列。一个例子是,如果你被要求填写餐厅的食物和服务的反馈,这可能是诸如美味、好、更好、更差和最差。这有一个从正到负的特定顺序,或者另一个例子是指一个班级的成绩。数值连续变量数字连续变量有无限的值。这方面的例子可以是股票价格、身高、体重、年龄,等等。这些值没有任何有限的区间。数值离散变量数值离散型变量有有限的值。一个例子是你有多少辆汽车或你有多少个孩子。它有一个确定的值,要么是0,1,2,等等。我们不可能有1.24辆汽车或1.05个孩子。在泰坦尼克号数据集中有哪些不同的变量,并直观地看到它们的数据类型表示。我们可以看到这些变量的单独表示。Name:分类名义变量。Surviver:分类名义变量。Pclass:分类顺序变量。Sex:分类名义变量。Embark:分类名义变量。Age:数值连续变量。SibSp:数值离散变量。Parch:数值离散变量。Fare:数值连续变量。单变量分析单变量分析是关于一个单一的变量。使用seaborn,我们可以将一些最重要的图示可视化。我们把船上幸存的乘客总数可视化。可以使用计数图的方法,如图所示。我们可以看到891人中只有350多人幸存下来。
分类名义变量顺序变量的定义与分类变量类似;这里需要提到的是,它没有任何特定的顺序。一个例子是我们不能在这里假设男性大于女性。我们不能假设一个类别大于或小于其他类别,而且它们没有任何特定的顺序。分类顺序变量分类的、序数的变量可以按特定的顺序排列。一个例子是,如果你被要求填写餐厅的食物和服务的反馈,这可能是诸如美味、好、更好、更差和最差。这有一个从正到负的特定顺序,或者另一个例子是指一个班级的成绩。数值连续变量数字连续变量有无限的值。这方面的例子可以是股票价格、身高、体重、年龄,等等。这些值没有任何有限的区间。数值离散变量数值离散型变量有有限的值。一个例子是你有多少辆汽车或你有多少个孩子。它有一个确定的值,要么是0,1,2,等等。我们不可能有1.24辆汽车或1.05个孩子。在泰坦尼克号数据集中有哪些不同的变量,并直观地看到它们的数据类型表示。我们可以看到这些变量的单独表示。Name:分类名义变量。Surviver:分类名义变量。Pclass:分类顺序变量。Sex:分类名义变量。Embark:分类名义变量。Age:数值连续变量。SibSp:数值离散变量。Parch:数值离散变量。Fare:数值连续变量。单变量分析单变量分析是关于一个单一的变量。使用seaborn,我们可以将一些最重要的图示可视化。我们把船上幸存的乘客总数可视化。可以使用计数图的方法,如图所示。我们可以看到891人中只有350多人幸存下来。sns.countplot(x="Survived", data=df)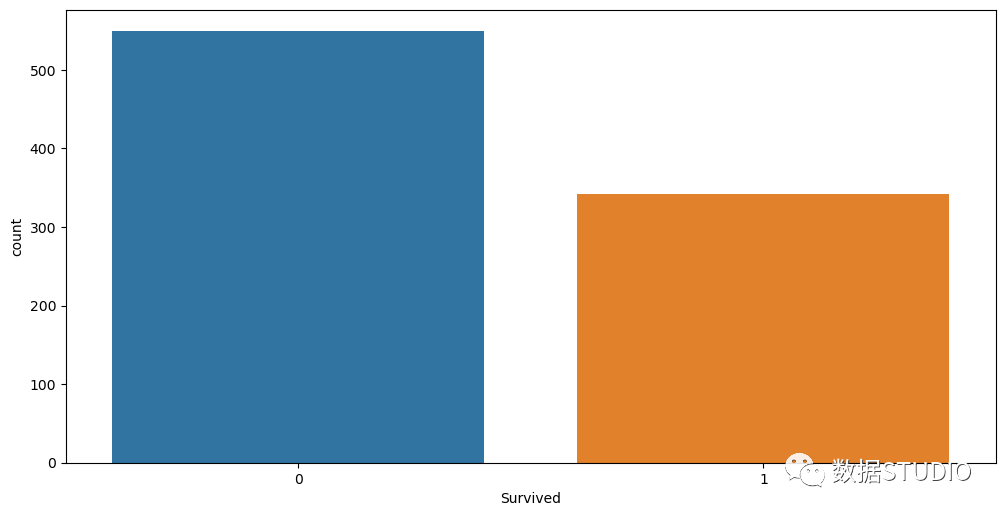 "Embarked"变量是分类类型的,它表示在不同港口上船的人数。我们可以用countplot方法绘制,如下图所示。
"Embarked"变量是分类类型的,它表示在不同港口上船的人数。我们可以用countplot方法绘制,如下图所示。sns.set_style("whitegrid")
sns.countplot(x="Embarked", data=df)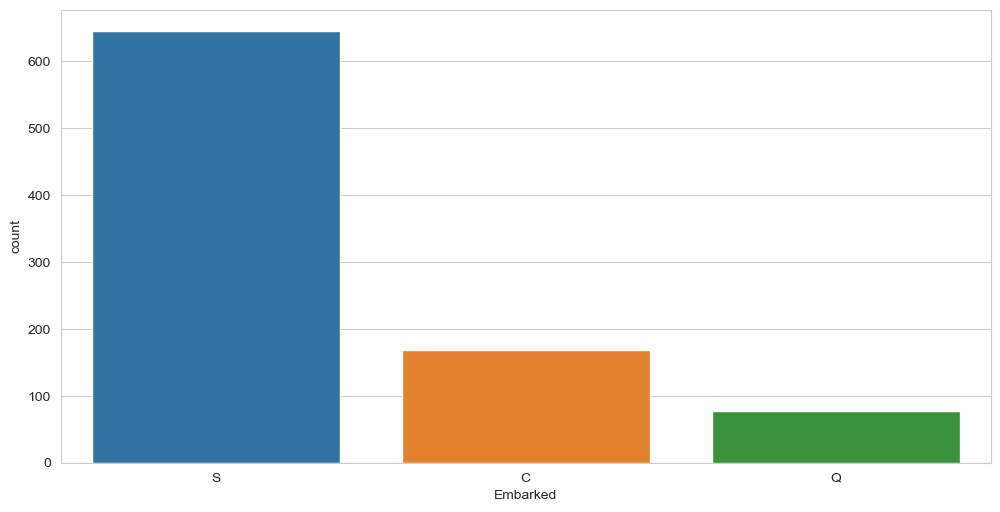 另一个分类变量是Sex(性别);我们也可以绘制它,如下图所示。
另一个分类变量是Sex(性别);我们也可以绘制它,如下图所示。sns.countplot(x="Sex", data=df)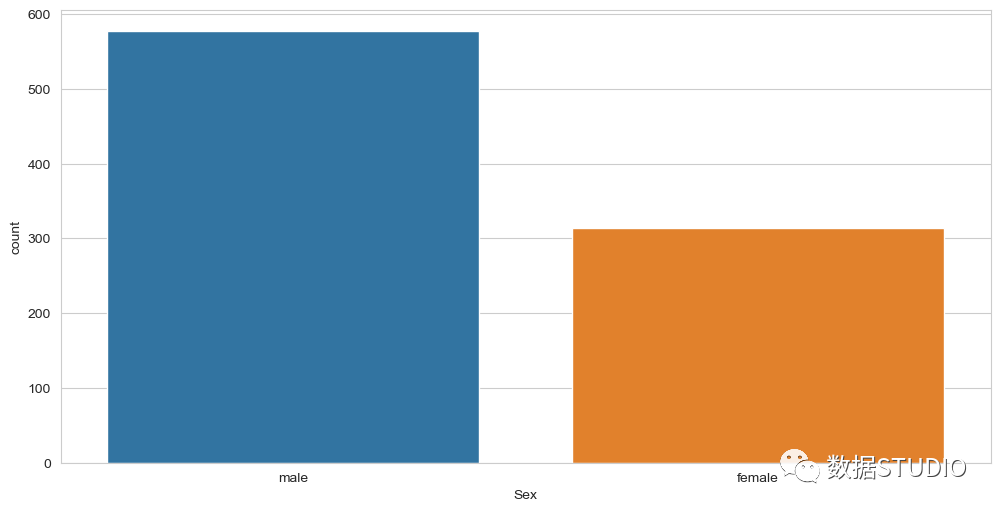 我们也可以对数字变量使用countplot方法。我们可以绘制'SibSp'(配偶和兄弟姐妹)变量,如图所示,它显示600人是单独旅行,200人以上有1个兄弟姐妹或配偶,以此类推。
我们也可以对数字变量使用countplot方法。我们可以绘制'SibSp'(配偶和兄弟姐妹)变量,如图所示,它显示600人是单独旅行,200人以上有1个兄弟姐妹或配偶,以此类推。sns.countplot(x="SibSp", data=df)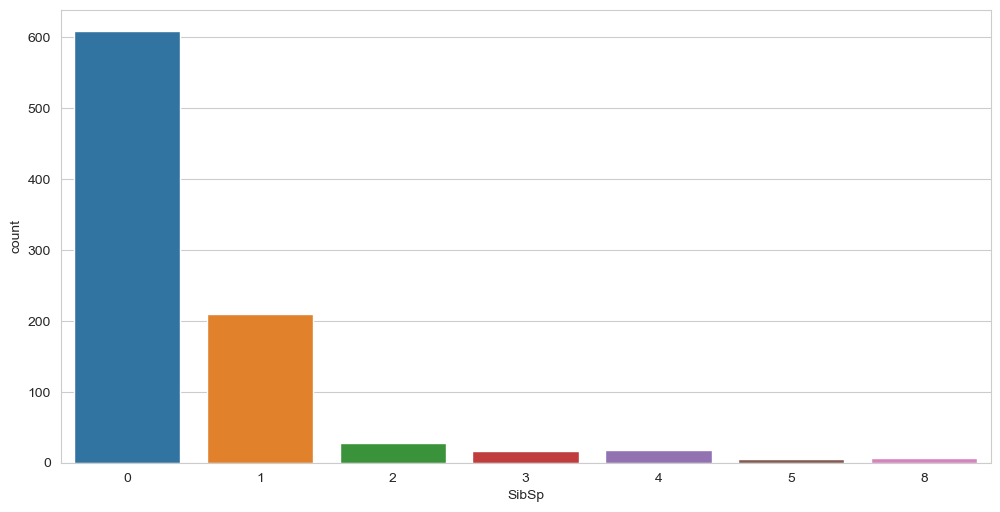 双变量分析到现在为止,我们已经学习了单变量的分析,称为单变量分析,而双变量分析是用来寻找两个变量之间的关系。为此寻找'Fare'和'Age'变量之间的关系,我们可以使用relplot方法,如图所示。
双变量分析到现在为止,我们已经学习了单变量的分析,称为单变量分析,而双变量分析是用来寻找两个变量之间的关系。为此寻找'Fare'和'Age'变量之间的关系,我们可以使用relplot方法,如图所示。sns.set_style("darkgrid")
g = sns.relplot("Age", "Fare", data=df)
g.fig.set_figwidth(12)
g.fig.set_figheight(6)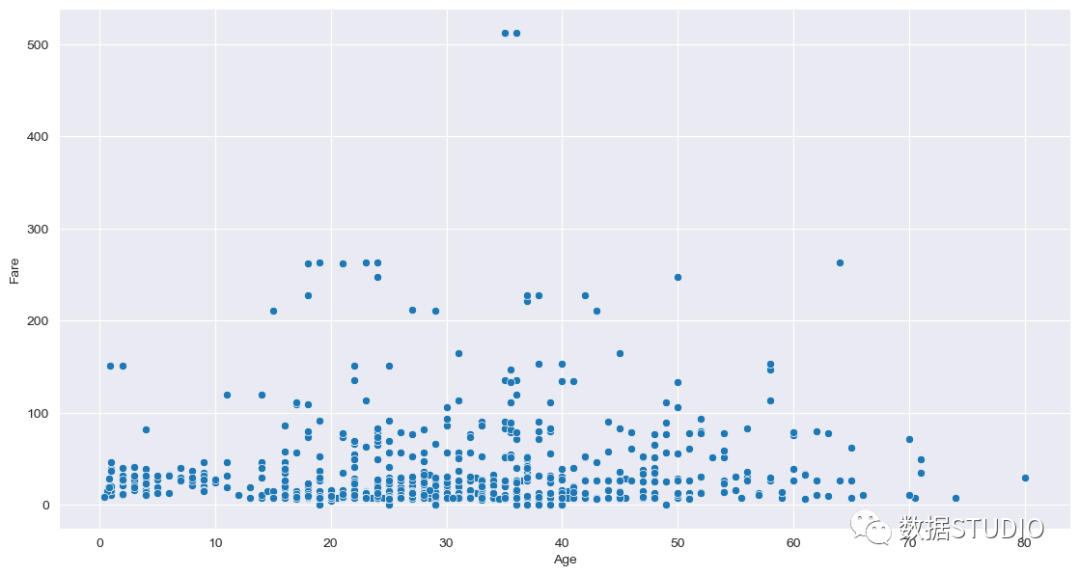 我们可以看到年龄范围从0到80,大部分票价都落在0到100的范围内,同时,38岁的人有一个500以上的票价的离群值。很少有变量落在200到300的范围内。不同的双变量图是散点图、热图、线图和柱状图。散点图散点图是统计可视化的骨干。它用一团数据点描述了两个变量之间的联合分布。这一点我们已经在上图中比较了 "Fare"和 "Age"的例子。线形图在seaborn中,线状图可以通过relplot方法完成,通过设置参数kind='line',如下图所示。
我们可以看到年龄范围从0到80,大部分票价都落在0到100的范围内,同时,38岁的人有一个500以上的票价的离群值。很少有变量落在200到300的范围内。不同的双变量图是散点图、热图、线图和柱状图。散点图散点图是统计可视化的骨干。它用一团数据点描述了两个变量之间的联合分布。这一点我们已经在上图中比较了 "Fare"和 "Age"的例子。线形图在seaborn中,线状图可以通过relplot方法完成,通过设置参数kind='line',如下图所示。sns.relplot("Age", "Fare", kind="line", data=df)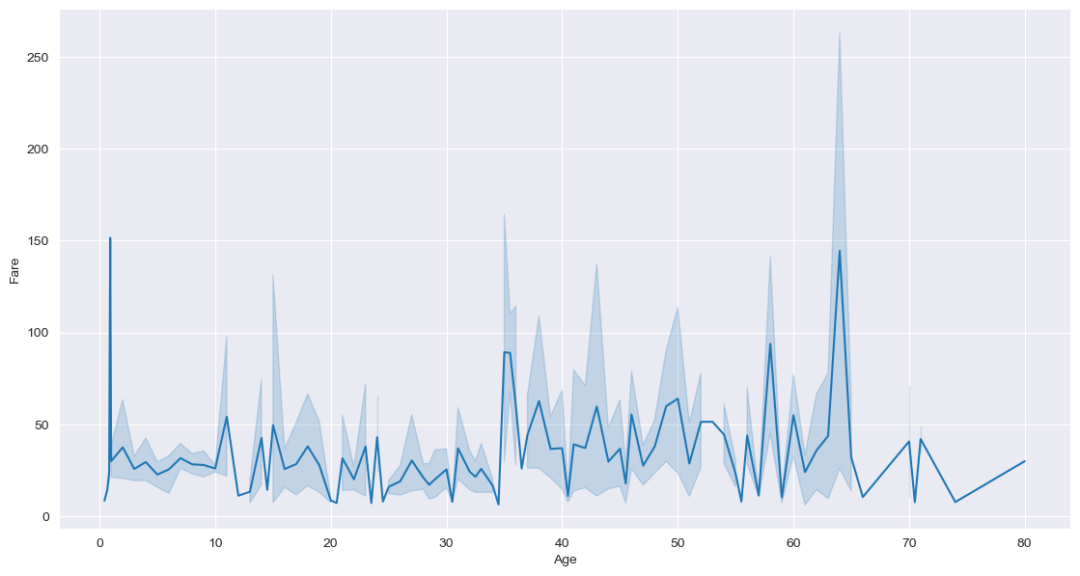 热图使用热图法,我们可以用二维的形式来表示数据。数据值在图中被表示为颜色,同时还有变量之间的数字相关性。在这里使用泰坦尼克号数据集,我们试图表示变量之间是否有任何相关性。下图显示,这些变量之间没有太大的相关性,而且它们是相互独立的。
热图使用热图法,我们可以用二维的形式来表示数据。数据值在图中被表示为颜色,同时还有变量之间的数字相关性。在这里使用泰坦尼克号数据集,我们试图表示变量之间是否有任何相关性。下图显示,这些变量之间没有太大的相关性,而且它们是相互独立的。corr = df.corr()
sns.heatmap(corr, annot=True)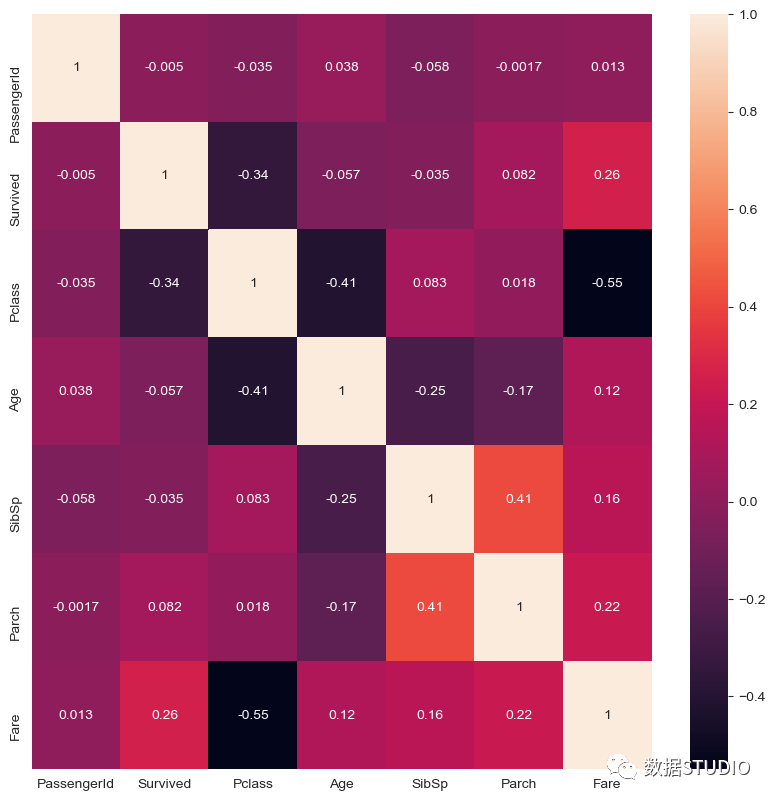 柱状图柱状图是最常见的一种图表类型。它显示了数字变量和分类变量之间的关系,如图所示。从图中我们可以看出,第1类乘客的生存率更高。
柱状图柱状图是最常见的一种图表类型。它显示了数字变量和分类变量之间的关系,如图所示。从图中我们可以看出,第1类乘客的生存率更高。sns.barplot(x="Pclass", y="Survived", data=df, ci=None)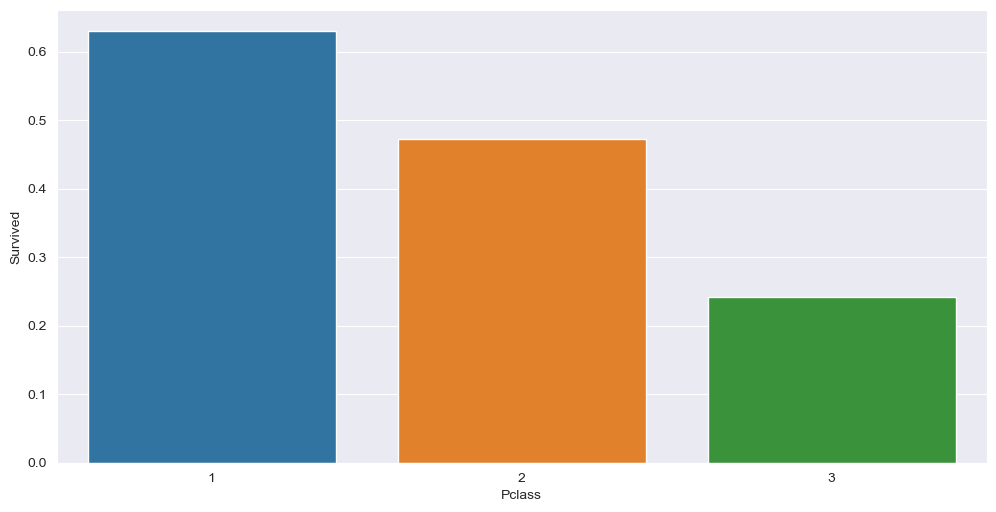 多变量分析多变量分析同时使用两个以上的变量。通常我们可以看到,更多的变量可以是多维的,如下图所示。这里我们将性别及他们的存活率与他们所乘坐的客运等级一起绘制出来。我们可以看到,与男性相比,女性乘客的存活率更高,而且Pclass 1和Pclass 2的存活率也更高。
多变量分析多变量分析同时使用两个以上的变量。通常我们可以看到,更多的变量可以是多维的,如下图所示。这里我们将性别及他们的存活率与他们所乘坐的客运等级一起绘制出来。我们可以看到,与男性相比,女性乘客的存活率更高,而且Pclass 1和Pclass 2的存活率也更高。sns.barplot(x="Sex", y="Survived", hue="Pclass", data=df, ci=None)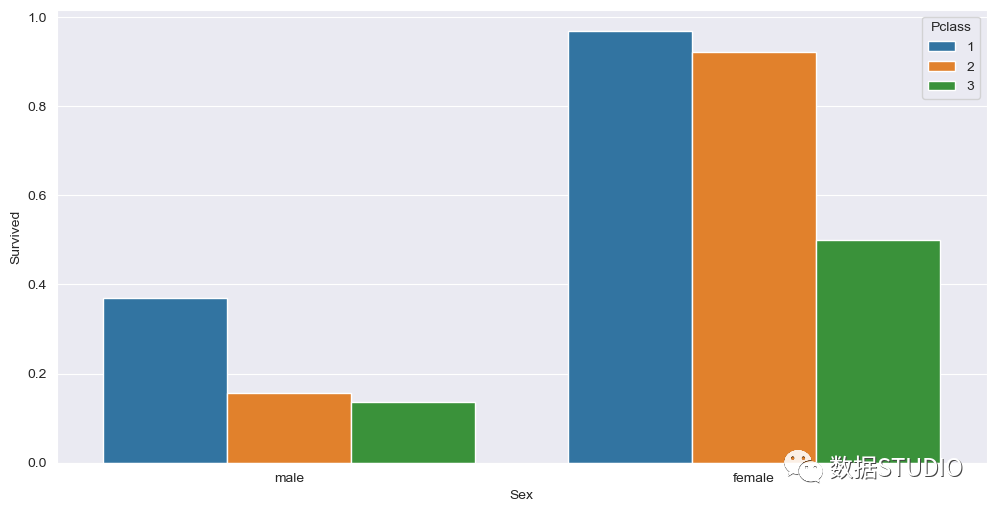 我们还可以画一个散点图来表示多变量分析,如下图所示,它显示了"Age"和 "Fare"以及他们的 "Survived"。这里我们可以描述出,与低票价相比,高票价的人存活率更高,也就是说,Pclass 1和Pclass 2比Pclass 3存活率更高。有时单变量和双变量分析并不能提供太多的信息,所以这里我们可以使用多变量分析。
我们还可以画一个散点图来表示多变量分析,如下图所示,它显示了"Age"和 "Fare"以及他们的 "Survived"。这里我们可以描述出,与低票价相比,高票价的人存活率更高,也就是说,Pclass 1和Pclass 2比Pclass 3存活率更高。有时单变量和双变量分析并不能提供太多的信息,所以这里我们可以使用多变量分析。sns.relplot(x="Age", y="Fare", hue="Survived", data=df)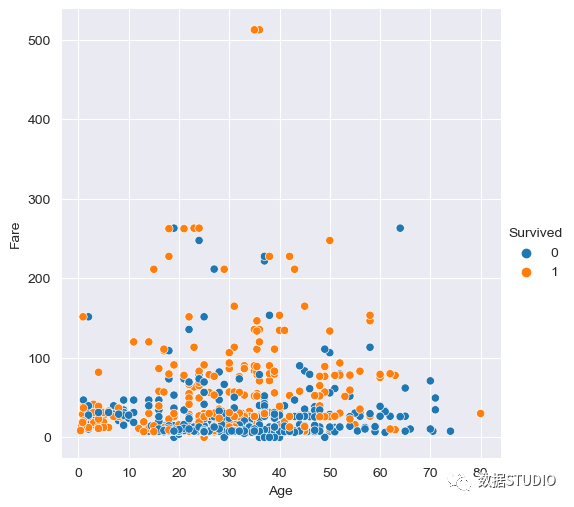 处理离群点离群点大多可能是数据中的一个错误,如打字错误、季节性趋势等。在这种情况下,在计算汇总统计或从数据中得出见解之前,应该将其从数据集中纠正或删除,否则会导致不正确的分析。假设你有一个美国不同州的披萨价格数据集,如下图所示。
处理离群点离群点大多可能是数据中的一个错误,如打字错误、季节性趋势等。在这种情况下,在计算汇总统计或从数据中得出见解之前,应该将其从数据集中纠正或删除,否则会导致不正确的分析。假设你有一个美国不同州的披萨价格数据集,如下图所示。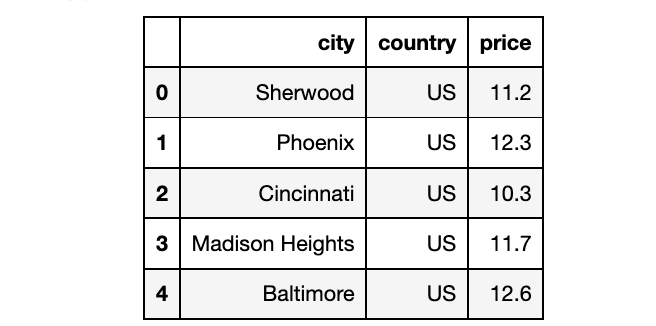 我们可以计算变量的长度,也可以用箱形图直观地看到异常值,如下图所示。
我们可以计算变量的长度,也可以用箱形图直观地看到异常值,如下图所示。sns.boxplot("price", data=df)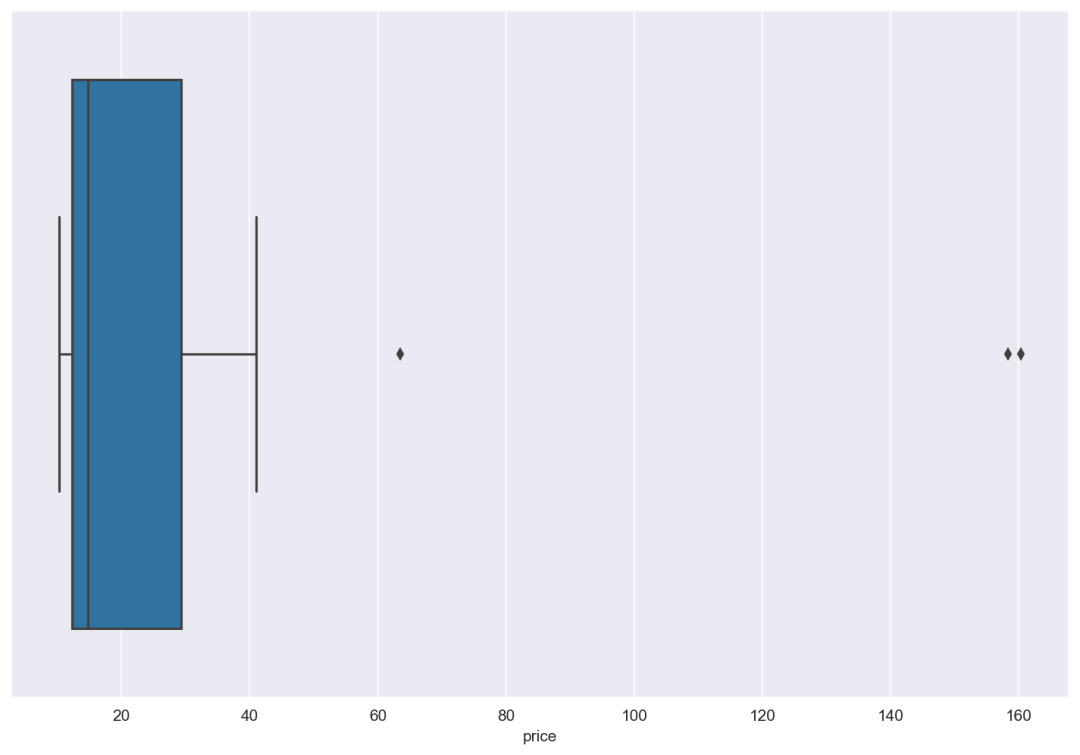 我们可以看到我们有3个离群点。现在如果我们计算价格的平均值,我们得到的数值是35.12。由于存在离群点,我们可以把它们丢掉,如下所示,再次计算平均值,这里我们可以看到平均值是16.67,几乎是有离群点的数值的一半。所以在数据分析过程中,去除离群值是很重要的。
我们可以看到我们有3个离群点。现在如果我们计算价格的平均值,我们得到的数值是35.12。由于存在离群点,我们可以把它们丢掉,如下所示,再次计算平均值,这里我们可以看到平均值是16.67,几乎是有离群点的数值的一半。所以在数据分析过程中,去除离群值是很重要的。df.drop(df[df.price == 160.32].index, inplace=True)
df.drop(df[df.price == 63.43].index, inplace=True)
df.drop(df[df.price == 158.38].index, inplace=True)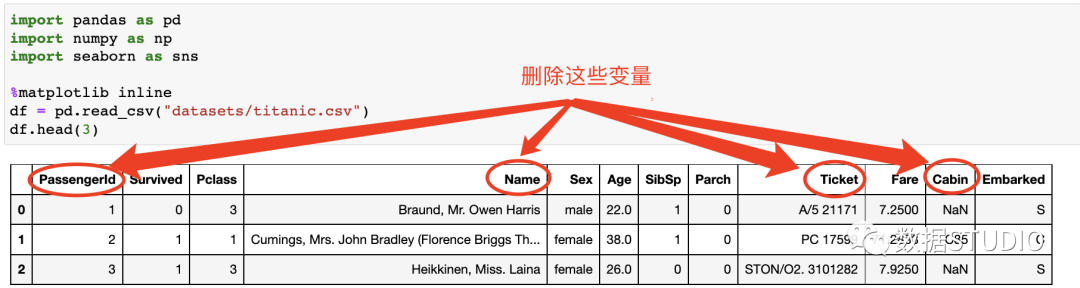 我们可以使用删除法,删除 "Passengerid"、"Name"、"Cabin "和 "Ticket "这几列,如下图所示。
我们可以使用删除法,删除 "Passengerid"、"Name"、"Cabin "和 "Ticket "这几列,如下图所示。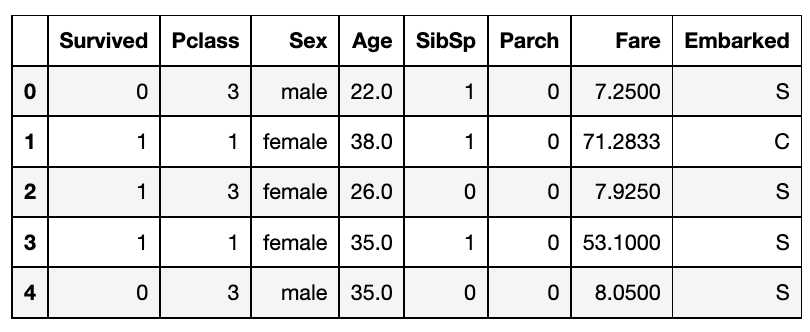 在上图中,我们可以看到这些列被删除了,很好,但是这里有一个问题。ML算法只理解数字,但是我们这里有两个类别列'Sex'和'Embarked',它们是对象(字符串)类型。性别列有男性和女性两个类别,而对于Embarked,我们有S、C和Q值。
在上图中,我们可以看到这些列被删除了,很好,但是这里有一个问题。ML算法只理解数字,但是我们这里有两个类别列'Sex'和'Embarked',它们是对象(字符串)类型。性别列有男性和女性两个类别,而对于Embarked,我们有S、C和Q值。df_main["Sex"].value_counts()male 577
female 314
Name: Sex, dtype: int64df_main["Embarked"].value_counts()S 644
C 168
Q 77
Name: Embarked, dtype: int64df_main.loc[df_main["Sex"] == "male", "Sex"] = 1
df_main.loc[df_main["Sex"] == "female", "Sex"] = 0
df_main.loc[df_main["Embarked"] == "S", "Embarked"] = 0
df_main.loc[df_main["Embarked"] == "Q", "Embarked"] = 1
df_main.loc[df_main["Embarked"] == "C", "Embarked"] = 2
df_main.head()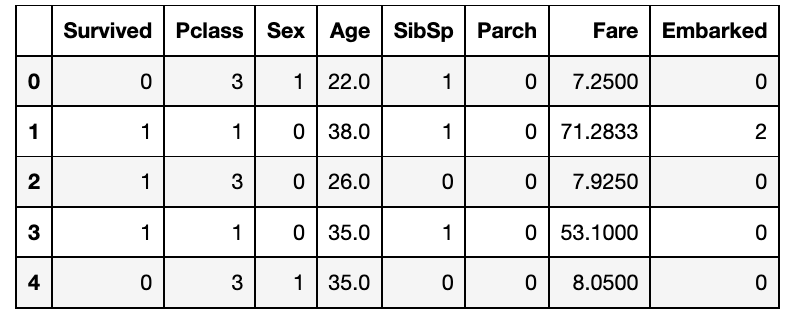 现在我们可以将数据集的信息特征和目标进行划分。X变量就像一个带有行和列的矩阵,称为特征,而y变量是目标。
现在我们可以将数据集的信息特征和目标进行划分。X变量就像一个带有行和列的矩阵,称为特征,而y变量是目标。X = df_main.drop(columns="Survived")
X.head()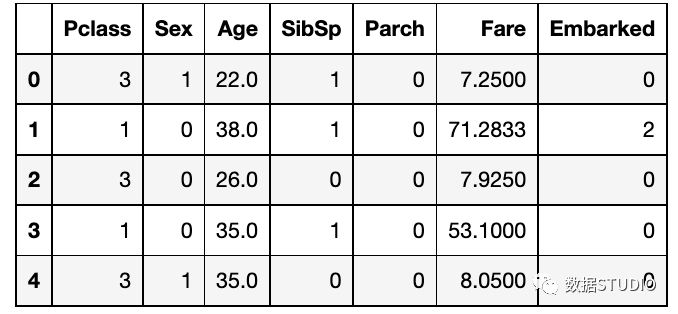 总结本文的内容是关于对数据集进行特别分析,并试图找到关于数据的洞察力。我们做了处理缺失值、异常值的工作,并将单变量、双变量和多变量的分析可视化。探索性数据分析是数据分析中最核心和最重要的概念之一。
总结本文的内容是关于对数据集进行特别分析,并试图找到关于数据的洞察力。我们做了处理缺失值、异常值的工作,并将单变量、双变量和多变量的分析可视化。探索性数据分析是数据分析中最核心和最重要的概念之一。 我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我正在尝试在Rails上安装ruby,到目前为止一切都已安装,但是当我尝试使用rakedb:create创建数据库时,我收到一个奇怪的错误:dyld:lazysymbolbindingfailed:Symbolnotfound:_mysql_get_client_infoReferencedfrom:/Library/Ruby/Gems/1.8/gems/mysql2-0.3.11/lib/mysql2/mysql2.bundleExpectedin:flatnamespacedyld:Symbolnotfound:_mysql_get_client_infoReferencedf
文章目录1.开发板选择*用到的资源2.串口通信(个人理解)3.代码分析(注释比较详细)1.主函数2.串口1配置3.串口2配置以及中断函数4.注意问题5.源码链接1.开发板选择我用的是STM32F103RCT6的板子,不过代码大概在F103系列的板子上都可以运行,我试过在野火103的霸道板上也可以,主要看一下串口对应的引脚一不一样就行了,不一样的就更改一下。*用到的资源keil5软件这里用到了两个串口资源,采集数据一个,串口通信一个,板子对应引脚如下:串口1,TX:PA9,RX:PA10串口2,TX:PA2,RX:PA32.串口通信(个人理解)我就从串口采集传感器数据这个过程说一下我自己的理解,
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
前言一般来说,前端根据后台返回code码展示对应内容只需要在前台判断code值展示对应的内容即可,但要是匹配的code码比较多或者多个页面用到时,为了便于后期维护,后台就会使用字典表让前端匹配,下面我将在微信小程序中通过wxs的方法实现这个操作。为什么要使用wxs?{{method(a,b)}}可以看到,上述代码是一个调用方法传值的操作,在vue中很常见,多用于数据之间的转换,但由于微信小程序诸多限制的原因,你并不能优雅的这样操作,可能有人会说,为什么不用if判断实现呢?但是if判断的局限性在于如果存在数据量过大时,大量重复性操作和if判断会让你的代码显得异常冗余。wxswxs相当于是一个独立