CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理

标题:UPRISE:改进零样本评估的通用提示检索
作者:Daixuan Cheng, Shaohan Huang, Junyu Bi, Yuefeng Zhan, Jianfeng Liu
文章链接:https://arxiv.org/abs/2303.08518
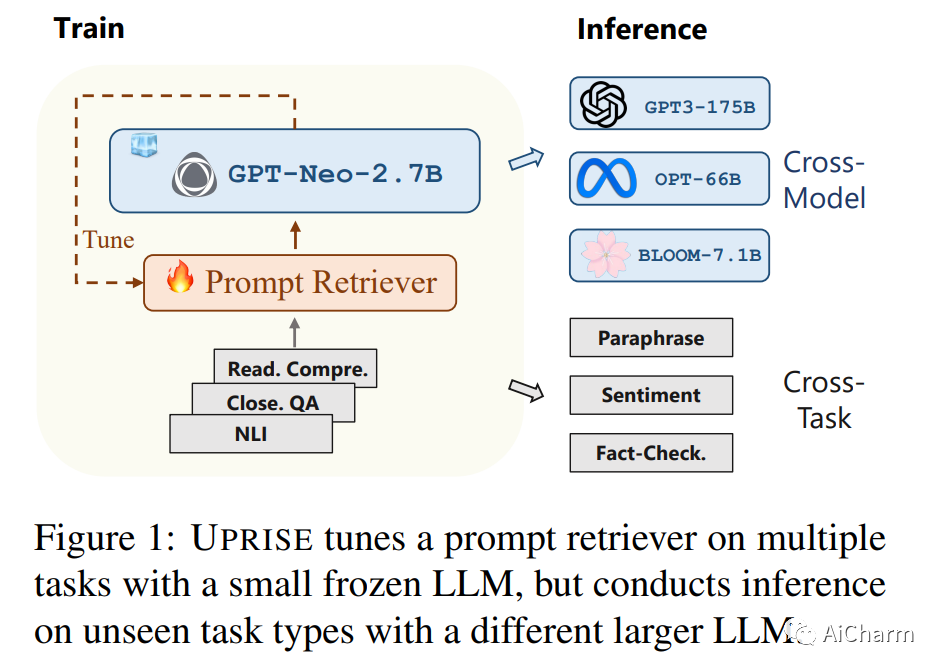
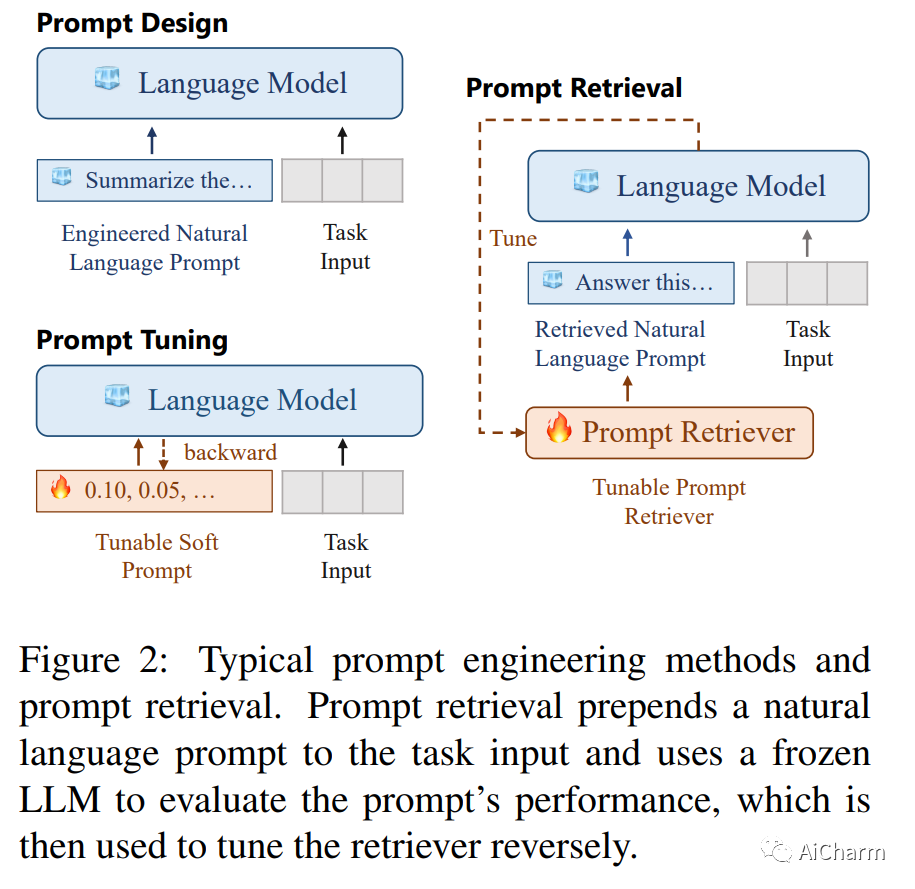

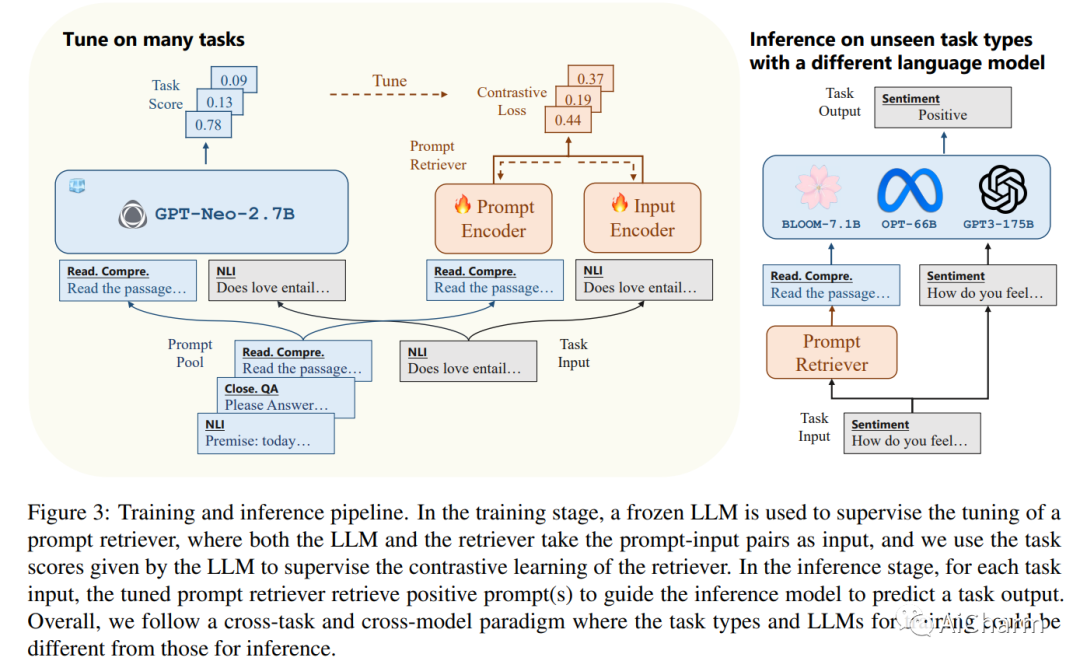
大型语言模型 (LLM) 因其令人印象深刻的能力而广受欢迎,但对特定于模型的微调或特定于任务的提示工程的需求可能会阻碍它们的泛化。我们提出了 UPRISE(用于改进零样本评估的通用提示检索),它调整了一个轻量级且多功能的检索器,该检索器可以自动检索给定零样本任务输入的提示。具体来说,我们展示了跨任务和跨模型场景中的普遍性:检索器针对不同的任务集进行了调整,但在未见过的任务类型上进行了测试;我们使用小型冻结 LLM GPT-Neo-2.7B 来调整检索器,但在规模大得多的不同 LLM 上测试检索器,例如 BLOOM-7.1B、OPT-66B 和 GPT3-175B。此外,我们表明 UPRISE 减轻了我们使用 ChatGPT 进行的实验中的幻觉问题,表明它有可能改善最强大的 LLM。
标题:有效缩放 Transformer 推理
作者:Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury
文章链接:https://arxiv.org/abs/2211.05102




我们研究了 Transformer 模型的高效生成推理问题,在其最具挑战性的设置之一:大型深度模型,具有严格的延迟目标和长序列长度。更好地理解基于 Transformer 的大型模型推理的工程权衡非常重要,因为这些模型的用例在整个应用领域都在迅速增长。我们开发了一个简单的推理效率分析模型,以根据应用要求选择针对 TPU v4 切片优化的最佳多维分区技术。我们将这些与一套低级优化相结合,以在超过 FasterTransformer 基准测试套件的 500B+ 参数模型上实现延迟和模型 FLOPS 利用率 (MFU) 权衡的新帕累托边界。我们进一步表明,通过适当的分区,多查询注意的较低内存需求(即多个查询头共享单个键/值头)可以将上下文长度扩展到 32 倍。最后,我们在生成期间实现了每个令牌 29 毫秒的低批量延迟(使用 int8 权重量化),在输入令牌的大批量处理期间实现了 76% 的 MFU,同时支持长 2048 令牌上下文长度PaLM 540B参数型号。
标题:具有快速调整功能的转向原型,可实现免排练的持续学习
作者:Zhuowei Li, Long Zhao, Zizhao Zhang, Han Zhang, Di Liu, Ting Liu, Dimitris N. Metaxas
文章链接:https://palm-e.github.io/assets/palm-e.pdf
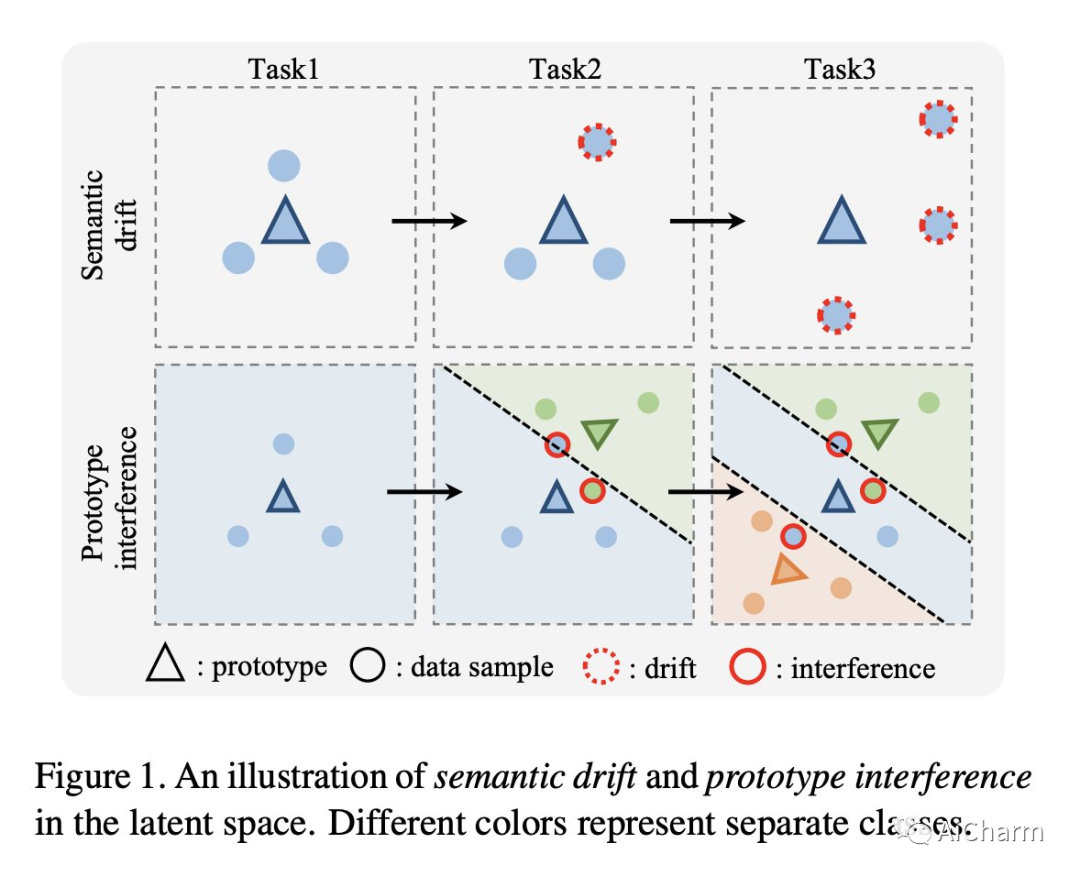
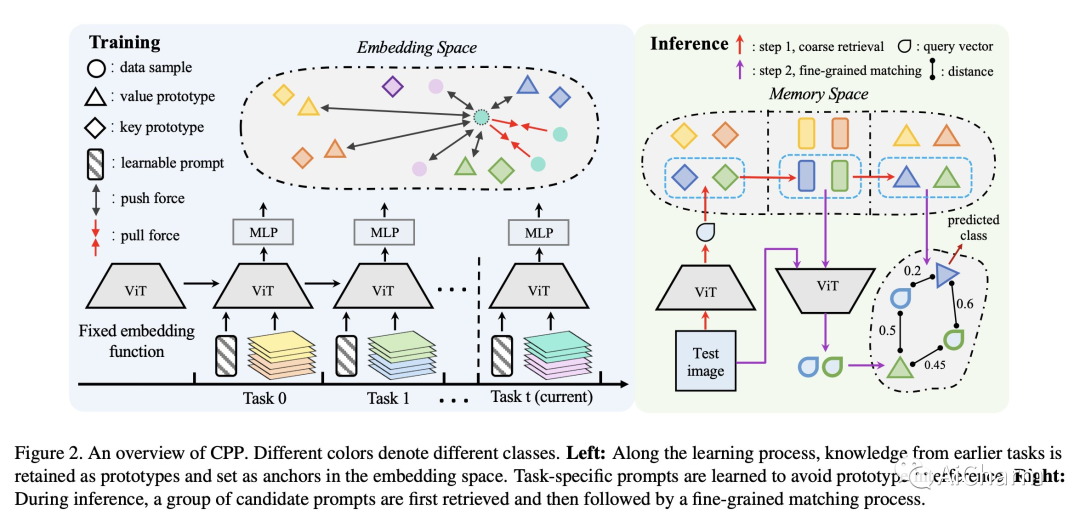
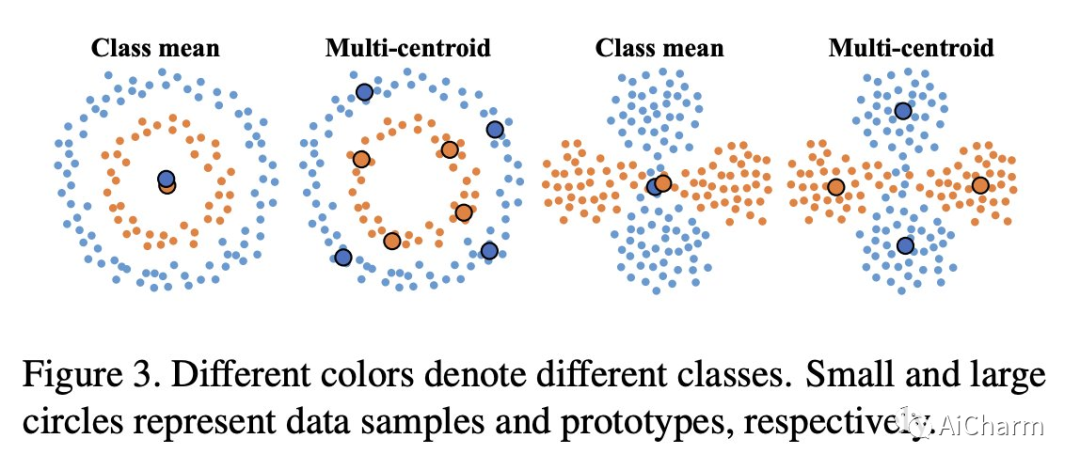
原型作为类嵌入的表示,已被探索用于减少内存占用或减轻持续学习场景的遗忘。然而,基于原型的方法仍然会因语义漂移和原型干扰而导致性能突然下降。在这项研究中,我们提出了对比原型提示 (CPP),并表明特定于任务的提示调整在针对对比学习目标进行优化时,可以有效地解决这两个障碍并显着提高原型的效力。我们的实验表明,CPP 在四个具有挑战性的类增量学习基准测试中表现出色,与最先进的方法相比,绝对改进了 4% 到 6%。此外,CPP 不需要排练缓冲区,它在很大程度上弥合了持续学习和离线联合学习之间的性能差距,展示了在 Transformer 架构下持续学习系统的有前途的设计方案。
标题:从扩散模型中删除概念
作者:Rohit Gandikota, Joanna Materzynska, Jaden Fiotto-Kaufman, David Bau
文章链接:https://arxiv.org/abs/2303.07345
项目代码:https://erasing.baulab.info/

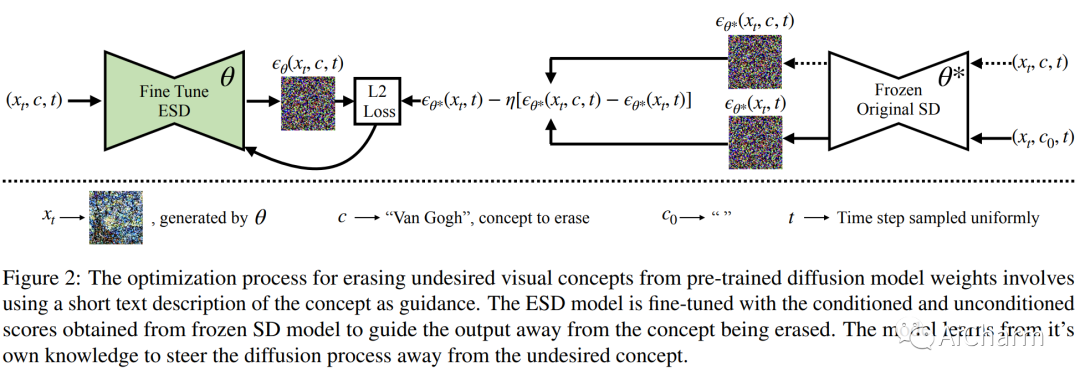
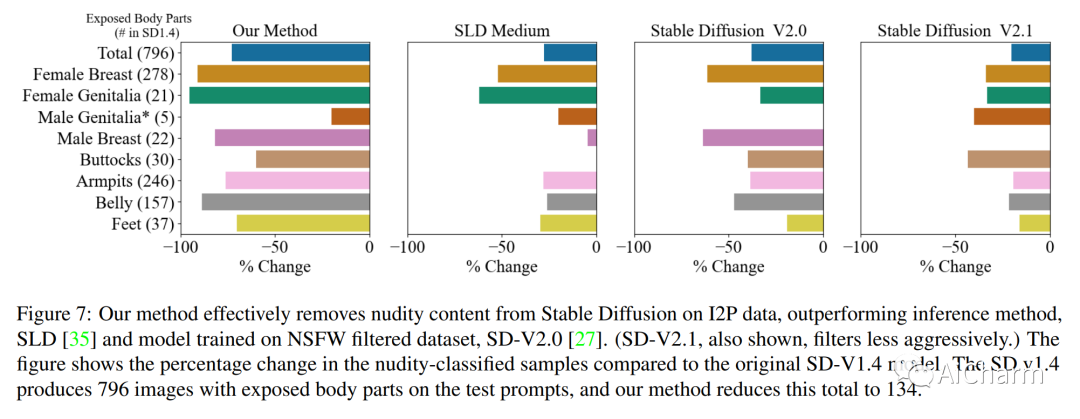
受文本到图像扩散的最新进展的推动,我们研究了模型权重中特定概念的擦除。尽管 Stable Diffusion 在制作明确或逼真的艺术作品方面显示出希望,但它引起了人们对其滥用可能性的担忧。我们提出了一种微调方法,可以从预训练的扩散模型中删除视觉概念,只给出风格的名称并使用负指导作为老师。我们将我们的方法与以前的方法进行了基准测试,这些方法删除了露骨的色情内容并证明了其有效性,其性能与安全潜在扩散和审查培训相当。为了评估艺术风格的移除,我们进行了从网络中删除五位现代艺术家的实验,并进行了一项用户研究以评估人类对删除风格的感知。与以前的方法不同,我们的方法可以从扩散模型中永久删除概念,而不是在推理时修改输出,因此即使用户可以访问模型权重也无法规避
标题:ViperGPT:通过 Python 执行进行推理的视觉推理
作者:Dídac Surís, Sachit Menon, Carl Vondrick
文章链接:https://arxiv.org/abs/2303.08128
项目代码:https://github.com/cvlab-columbia/viper

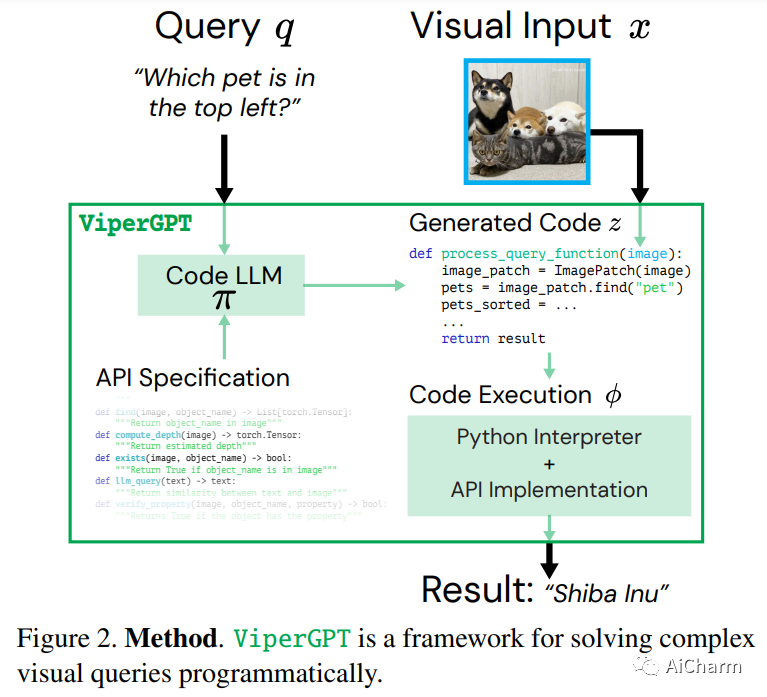

回答视觉查询是一项复杂的任务,需要视觉处理和推理。端到端模型是这项任务的主要方法,没有明确区分这两者,限制了可解释性和泛化性。学习模块化程序是一种很有前途的选择,但由于难以同时学习程序和模块,因此已被证明具有挑战性。我们介绍了 ViperGPT,这是一个利用代码生成模型将视觉和语言模型组合成子例程以生成任何查询结果的框架。ViperGPT 利用提供的 API 访问可用模块,并通过生成稍后执行的 Python 代码来组合它们。这种简单的方法不需要进一步的培训,并在各种复杂的视觉任务中取得了最先进的结果。
标题:FreeNeRF:使用自由频率正则化改进小样本神经渲染
作者:Jiawei Yang, Marco Pavone, Yue Wang
文章链接:https://arxiv.org/abs/2303.07418
项目代码:https://github.com/Jiawei-Yang/FreeNeRF

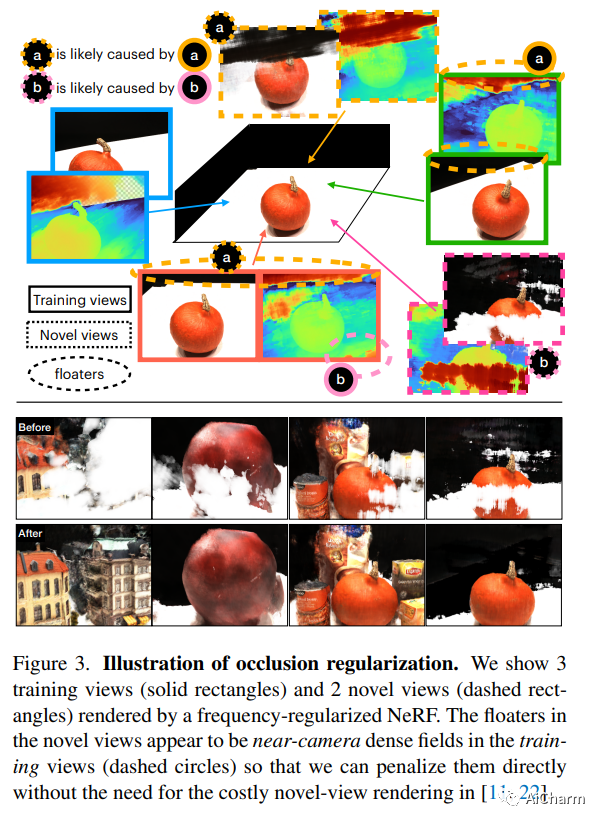
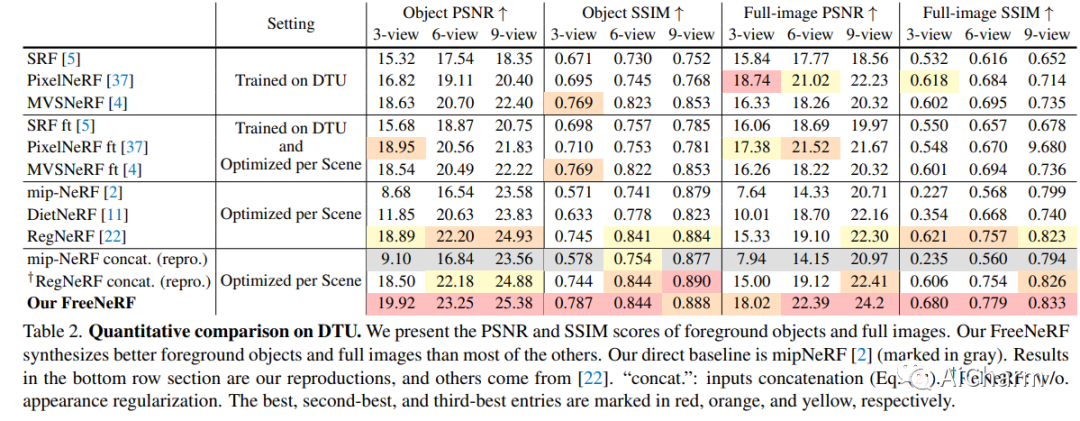
标题:LERF:语言嵌入辐射场
作者:Justin Kerr, Chung Min Kim, Ken Goldberg, Angjoo Kanazawa, Matthew Tancik
文章链接:https://arxiv.org/abs/2303.09553
项目代码:https://www.lerf.io/

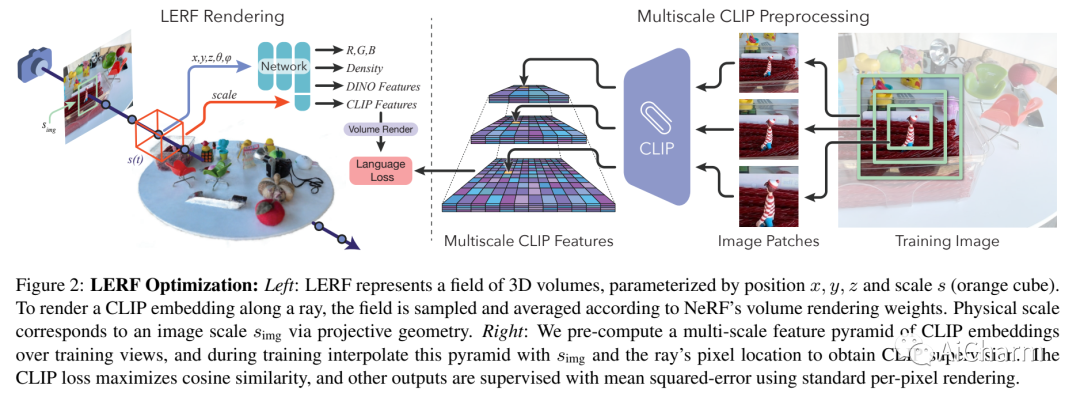
人类使用自然语言来描述物理世界,以指代基于大量属性的特定 3D 位置:视觉外观、语义、抽象关联或可操作的可供性。在这项工作中,我们提出了语言嵌入辐射场 (LERF),这是一种将语言嵌入从现成模型(如 CLIP)嵌入到 NeRF 中的方法,它可以在 3D 中实现这些类型的开放式语言查询。LERF 通过沿训练射线的体积渲染 CLIP 嵌入来学习 NeRF 内部的密集、多尺度语言场,跨训练视图监督这些嵌入以提供多视图一致性并平滑底层语言场。优化后,LERF 可以实时交互地为广泛的语言提示提取 3D 相关图,这在机器人技术、理解视觉语言模型以及与 3D 场景交互方面具有潜在的用例。LERF 在不依赖区域提议或掩码的情况下,支持对提取的 3D CLIP 嵌入进行像素对齐、零样本查询,支持跨卷分层的长尾开放词汇查询。
标题:视觉和语言模型的统一视觉关系检测
作者:Long Zhao, Liangzhe Yuan, Boqing Gong, Yin Cui, Florian Schroff, Ming-Hsuan Yang, Hartwig Adam, Ting Liu
文章链接:https://arxiv.org/abs/2303.08998
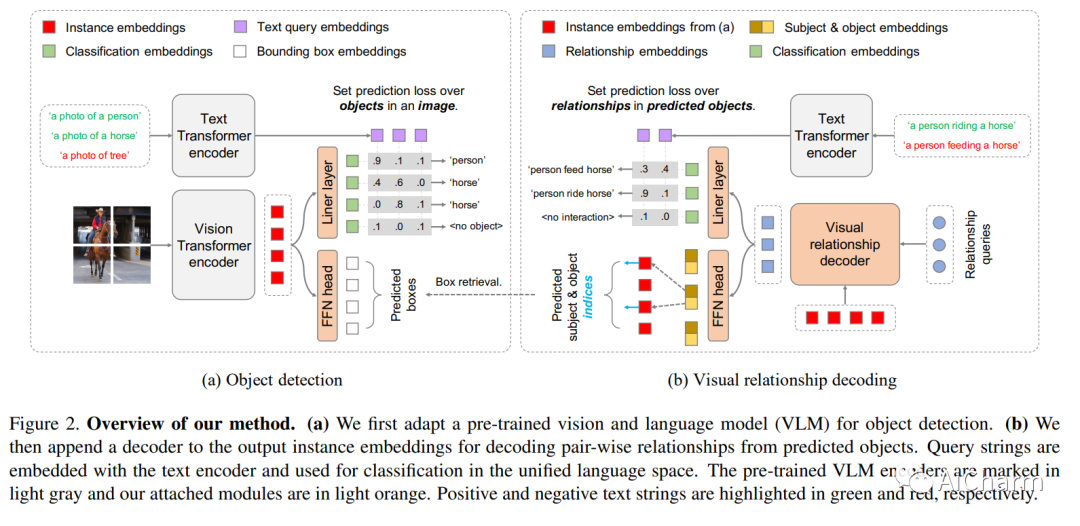
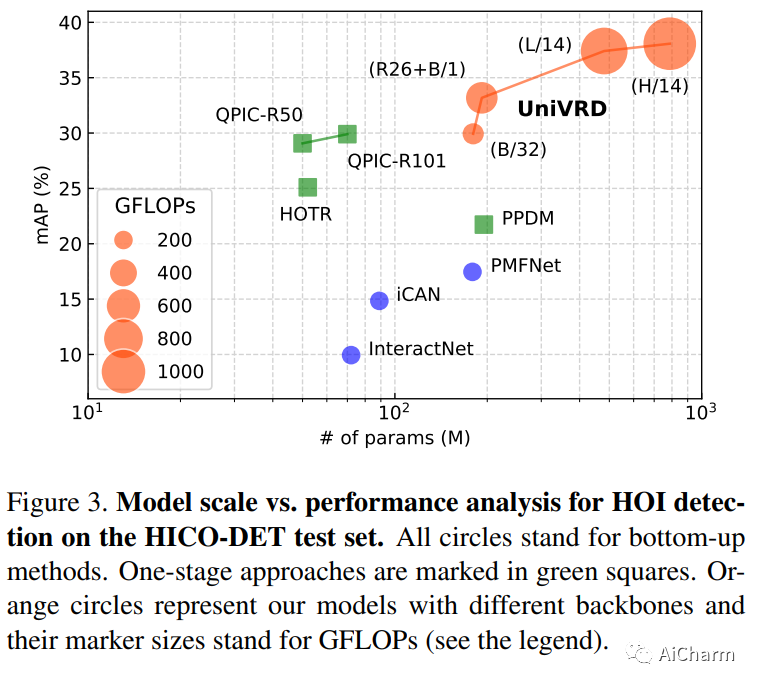

这项工作的重点是训练一个单一的视觉关系检测器来预测来自多个数据集的标签空间的联合。由于分类不一致,合并跨越不同数据集的标签可能具有挑战性。当在对象对之间引入二阶视觉语义时,视觉关系检测中的问题会加剧。为了应对这一挑战,我们提出了 UniVRD,这是一种利用视觉和语言模型 (VLM) 进行统一视觉关系检测的新型自下而上方法。VLM 提供对齐良好的图像和文本嵌入,其中相似的关系被优化为彼此接近以实现语义统一。我们自下而上的设计使模型能够享受到对象检测和视觉关系数据集训练的好处。人机交互检测和场景图生成的实证结果证明了我们模型的竞争性能。UniVRD 在 HICO-DET 上实现了 38.07 mAP,比目前最好的自底向上 HOI 检测器相对高出 60%。更重要的是,我们展示了我们的统一检测器在 mAP 中的性能与特定于数据集的模型一样好,并且在我们扩展模型时实现了进一步的改进。
标题:FateZero:融合注意力以进行基于文本的零镜头视频编辑
作者:Chenyang Qi, Xiaodong Cun, Yong Zhang, Chenyang Lei
文章链接:https://arxiv.org/abs/2303.08998
项目代码:https://github.com/chenyangqiqi/fatezero

基于扩散的生成模型在基于文本的图像生成中取得了显着的成功。然而,由于它在生成过程中包含巨大的随机性,因此将此类模型应用于现实世界的视觉内容编辑仍然具有挑战性,尤其是在视频中。在本文中,我们提出了 FateZero,这是一种针对真实世界视频的基于文本的零镜头编辑方法,无需按提示训练或使用特定掩码。为了一致地编辑视频,我们提出了几种基于预训练模型的技术。首先,与直接的 DDIM 反演技术相比,我们的方法在反演期间捕获中间注意力图,从而有效地保留结构和运动信息。这些地图在编辑过程中直接融合,而不是在去噪过程中生成。为了进一步减少源视频的语义泄漏,我们随后将自注意力与通过源提示中的交叉注意力特征获得的混合掩码融合在一起。此外,我们通过引入时空注意力来确保帧的一致性,从而对 UNet 降噪中的自注意力机制进行了改革。简而言之,我们的方法是第一个展示零镜头文本驱动视频风格和来自训练有素的文本到图像模型的局部属性编辑能力的方法。我们还有更好的基于文本到视频模型的零样本形状感知编辑能力。广泛的实验证明了我们比以前的作品更优越的时间一致性和编辑能力。
标题:用于联合主题和文本条件图像生成的统一多模态潜在扩散
文章链接:https://arxiv.org/abs/2303.09319
摘要:
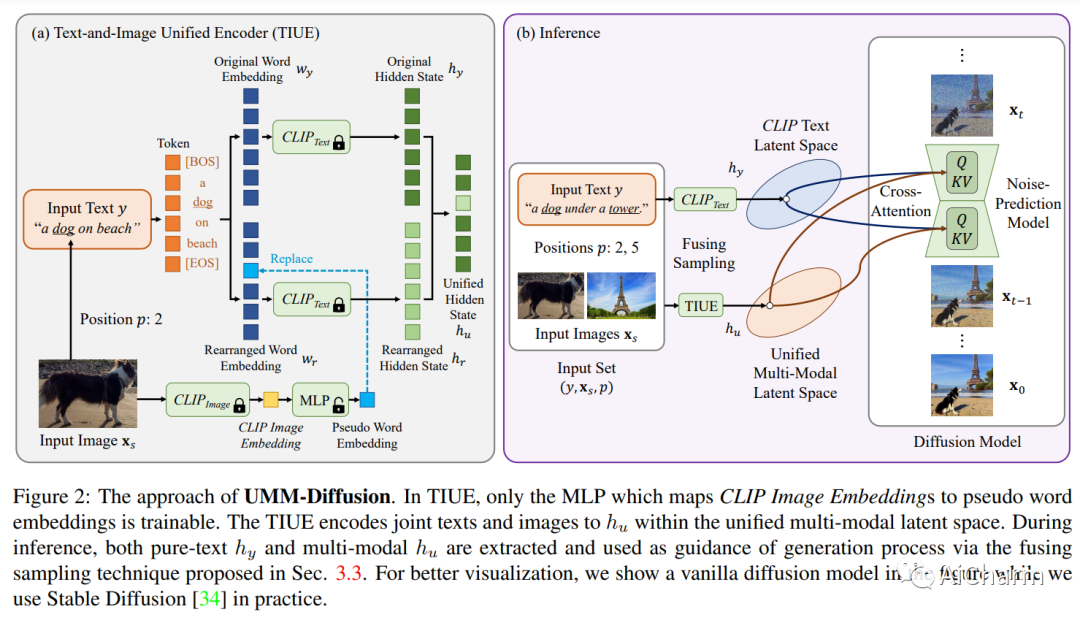
如今,通过使用扩散模型,语言引导的图像生成取得了巨大的成功。然而,文本可能不够详细以描述高度具体的主题,例如特定的狗或特定的汽车,这使得纯文本到图像的生成不够准确,无法满足用户需求。在这项工作中,我们提出了一种新颖的统一多模态潜在扩散(UMM-Diffusion),它将包含指定主题的联合文本和图像作为输入序列,并生成带有主题的自定义图像。更具体地说,输入文本和图像都被编码到一个统一的多模态潜在空间中,其中输入图像被学习投影到伪词嵌入,并可以进一步与文本结合以指导图像生成。此外,为了消除输入图像的不相关部分,如背景或光照,我们提出了一种新的图像生成器使用的扩散模型采样技术,该技术融合了多模态输入和纯文本输入引导的结果。通过利用大规模预训练的文本到图像生成器和设计的图像编码器,我们的方法能够从输入文本和图像的两个方面生成具有复杂语义的高质量图像。
标题:MeshDiffusion:基于分数的生成 3D 网格建模
文章链接:https://arxiv.org/abs/2303.08133


摘要:
我们考虑生成逼真的 3D 形状的任务,这对于自动场景生成和物理模拟等各种应用非常有用。与体素和点云等其他 3D 表示相比,网格在实践中更受欢迎,因为 (1) 它们可以轻松随意地操纵形状以进行重新照明和模拟,以及 (2) 它们可以充分利用现代图形管道的强大功能主要针对网格进行了优化。以前用于生成网格的可扩展方法通常依赖于次优的后处理,并且它们往往会产生过于光滑或嘈杂的表面,而没有细粒度的几何细节。为了克服这些缺点,我们利用网格的图形结构,使用一种简单但非常有效的生成建模方法来生成 3D 网格。具体来说,我们用可变形四面体网格表示网格,然后在这种直接参数化上训练扩散模型。我们展示了我们的模型在多个生成任务上的有效性。3.Mesh Strikes Back: Fast and Efficient Human Reconstruction from RGB videos
标题:Mesh Strikes Back:从 RGB 视频快速高效地重建人体
文章链接:https://arxiv.org/abs/2303.0880


摘要:
由于服装、遮挡、纹理不连续性和锐度以及特定于帧的姿势变化,单眼 RGB 视频的人体重建和合成是一个具有挑战性的问题。许多方法采用延迟渲染、NeRF 和隐式方法来表示穿着衣服的人,前提是基于网格的表示不能单独从 RGB、轮廓和关键点捕获复杂的衣服和纹理。我们通过优化 SMPL+D 网格和仅使用 RGB 图像、二进制轮廓和稀疏 2D 关键点的高效多分辨率纹理表示,为这一基本前提提供了一个反观点。实验结果表明,与视觉船体、基于网格的方法相比,我们的方法更能够捕获几何细节。与基于 NeRF 的方法相比,我们展示了具有竞争力的新视图合成和新姿势合成的改进,后者引入了明显的、不需要的伪影。通过将解决方案空间限制为结合可微分渲染的 SMPL+D 模型,我们在计算、训练时间(高达 24 倍)和推理时间(高达 192 倍)方面获得了显着的加速。因此,我们的方法可以按原样使用,也可以作为对基于 NeRF 的方法的快速初始化。
更多Ai资讯:公主号AiCharm
文章目录前言1.AI的发展历程2.我是如何接触到人工智能的概念和产品的3.对于ChatGPT的一点看法4.AI对大学毕业生的职业发展的利与弊5.对于AI的思考和问题前言随着ChatGPT的爆火,生成式AI,大模型的人工智能被越来越多的人注意到,同时他也带来了许多问题。本文将对几方面进行探讨。1.AI的发展历程远古时期在公元前第一个千禧年,中国,印度和希腊哲学家都提出了一些推理的研究理论,比如亚里士多德(Aristotle)进行了演绎推理三段论的完整分析,欧几里得(Euclid)所著Elements是一种形式推理的模型,MuḥammadibnMūsāal-Khwārizmī,发明了代数学,即我们
目录1古彝文与古典保护2古文识别的挑战2.1西文与汉文OCR2.2古彝文识别难点3合合信息:古彝文保护新思路3.1图像矫正3.2图像增强3.3语义理解3.4工程技巧4总结1古彝文与古典保护彝文指的是云南、贵州、四川等地的彝族人使用的文字,区别于现代意义上的彝文,古彝文指的是在民间流通使用的原生态彝文,多达87046字。古彝文的起源距今至少数千年,是世界上最古老的文字之一。对古彝文字集研究有助于理解尚未被翻译成汉文、用字尚未规范化的古籍,更深层、透彻地作用于传统文化保护。古彝文字义对照图(网络资料+邵文苑供图)古籍是不可再生的宝贵资源,应当得到妥善保护。中国的古籍在历史上迭经水火兵燹等自然灾害、
作者|Harper审核 |gongyouliu编辑|auroral-L机器学习的商业应用上期给大家介绍了机器学习的概念,但是理解机器学习最好方法之一,就是了解其在具体商业世界中的各种应用。在道格’罗斯的这本《认识AI,人工智能赋能商业》中,介绍了几类机器学习的商业应用,在这里我给大家归纳一下。第一,数据安全,为了避免被发现,制造恶意软件的人会不断更改代码,通常为2%~10%的修改,但是通过机器学习,安全软件可以适应这一小部分变化,并准确识别新创建的恶意软件。它还可以寻找访问方式的模式,以识别可能的安全威胁。第二,投资。机器学习使得计算机能够处理大量的财务数据,并利用其发现的规律预测市场及每只股
ChatGPT提出了"机器学习"这个术语,他开发了一个西洋跳棋程序,可以从错误中吸取教训,经过学习后,甚至比编写程序的人棋力更强
一、知识框架二、练习题调节一个装瓶机使其对每个瓶子的灌装量均值为μ盎司,通过观察这台装瓶机对每个瓶子的灌装量服从标准差σ=1.0盎司的正态分布。随机抽取这台机器灌装的9个瓶子组成一个样本,并测定每个瓶子的灌装量。试确定样本均值偏离总体均值不超过0.3盎司的概率。解:设每个瓶子的灌装量为X,X为样本均值,样本容量为n。由于总体X服从正态分布,样本均值X也服从正态分布,且均值相同,标准差为所以三、简述题1什么是统计量?为什么要引进统计量?统计量中为什么不含任何未知参数?答:(1)统计量的定义:设X1,X2,…,Xn是从总体X中抽取的容量为n的一个样本,如果由此样本构造一个函数T(X1,X2,…,X
很难说出这里要问什么。这个问题模棱两可、含糊不清、不完整、过于宽泛或夸夸其谈,无法以目前的形式得到合理的回答。如需帮助澄清此问题以便重新打开,visitthehelpcenter.关闭11年前。在电视上我看到了一些有趣的机器人。这些有一些二极管、太阳能收集器和一些马达。二极管决定光的位置,因此它们将机器人转向为它提供光的方向。它有点跟随光。现在,基于此,我想知道一些简单的AI。有没有办法编写一个可以从用户交互中学习的引擎?作为初学者,只学习和记住用户在页面上的session就足够了。感谢任何帮助。
插件网址指路:A*PathfindingProjecthttps://arongranberg.com/astar/download3D如何简单的使用参见:A*Pathfinding插件(3D)_作孽就得先起床的博客-CSDN博客将下载好的插件导入后如何进行操作?新建一个空的CreatEmpty给它另取个名字接着添加组件接着输"path"选择第一个“Pathfinder” 选择后点击“Graphs”(图)选择第一个在打开时可能会发生折叠,点开“GridGraph”就好下面开始操作:1、勾选‘2D’2、到场景中调整覆盖区域大小,限制Ai追踪的范围 也可用边框的这里进行调整3、勾选“Use2DPh
关注公众号,发现CV技术之美本文分享论文『VideoMAE:MaskedAutoencodersareData-EfficientLearnersforSelf-SupervisedVideoPre-Training』,由南大王利民团队提出第一个VideoMAE框架,使用超高maskingratio(90%-95%),性能SOTA,代码已开源!详细信息如下:论文链接:https://arxiv.org/abs/2203.12602项目链接:https://github.com/MCG-NJU/VideoMAE 01 摘要为了在相对较小的数据集上实现卓越的性能,通常需要在超大规模数据
这几年AI绘画非常的流行,相信大家平时在浏览社交平台时,也经常看见别人发布出来的绘图作品。AI绘画不仅可以帮助许多没有绘画基础的朋友可以画出自己的作品,而且可玩性也非常的高。那大家想体验一下AI绘画的乐趣吗?如果想的话就接着看下去吧,我来告诉你智能AI绘画免费软件有哪些。推荐软件一:Styler手机端推荐理由:Styler是我个人比较喜欢使用的软件,它拥有漫画脸、卡通艺术滤镜、视频变漫画等多种特效可以使用,而且软件的AI绘图功能使用了前沿的技术,绘画出来的内容符合逻辑,不会产生太大的违和感。使用体验感:①它支持上传参考图给AI学习模仿,可以帮助大家绘画出自己想要的图案。②这个软件使用了前沿的技