为什么会产生出Mel 这种尺度的机制呢?
人耳朵具有特殊的功能,可以使得人耳朵在嘈杂的环境中,以及各种变异情况下仍能正常的分辨出各种语音;
其中,耳蜗有关键作用;
耳蜗实质上的作用相当于一个滤波器组,耳蜗的滤波作用是在对数频率尺度上进行的,在1000HZ以下为线性尺度,1K HZ以上为对数尺度,使得人耳对低频信号敏感,高频信号不敏感;
也就是说,当初产生这种机制主要是为了模拟,人耳朵的听觉机制;
根据这一原则,从而研制出来了Mel频率滤波器组,
所以,Mel滤波器组的在靠近低频出越密集,越靠近高频出,滤波器越稀疏;
例如,人们可以比较容易地发现500和1000Hz的区别,但很难发现7500和8000Hz的区别。
M e l ( f ) = 2595 ∗ l o g 10 ( 1 + f 700 ) , Mel(f) = 2595* log_{10}(1+ \frac{f}{700} ), Mel(f)=2595∗log10(1+700f),
f = 700 ( 1 0 m 2595 − 1 ) . f=700(10^\frac{m}{2595} −1). f=700(102595m−1).
M 被称作 Mel 频率;
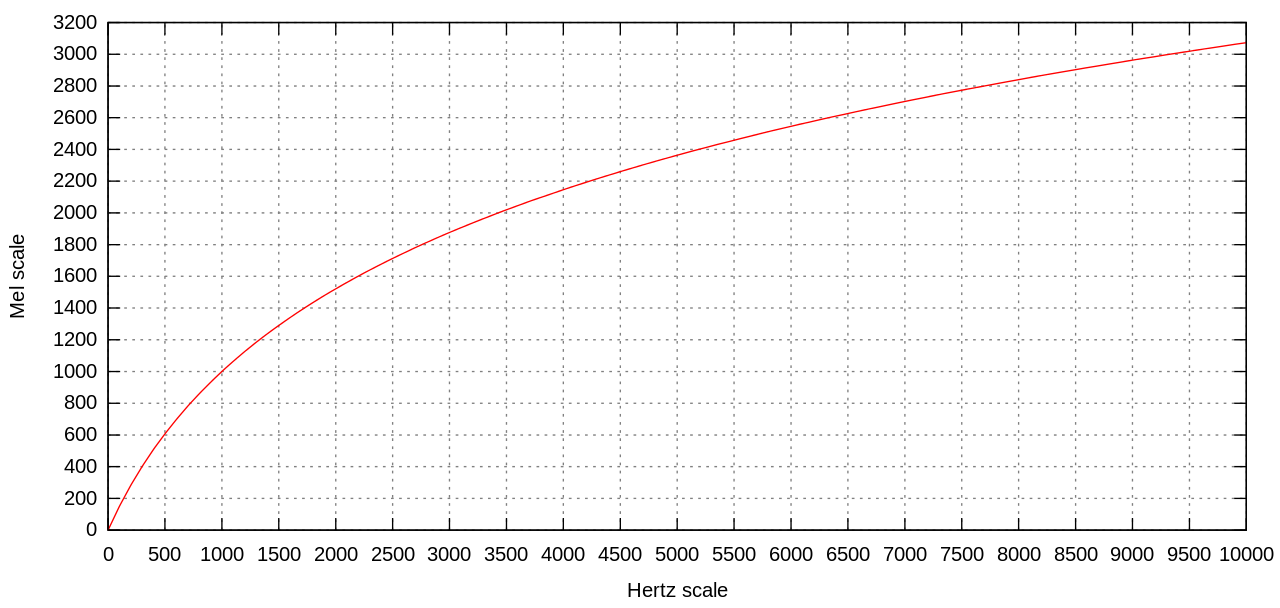
观察上图:
从Hz到mel的映射图,由于它们是log的关系,
当频率较小时,mel随Hz变化较快;
当频率很大时,mel的上升很缓慢,曲线的斜率很小。
这说明了人耳对低频音调的感知较灵敏,在高频时人耳是很迟钝的,梅尔标度滤波器组启发于此, 从而 梅尔滤波器 的 分布情况 受启发于此。
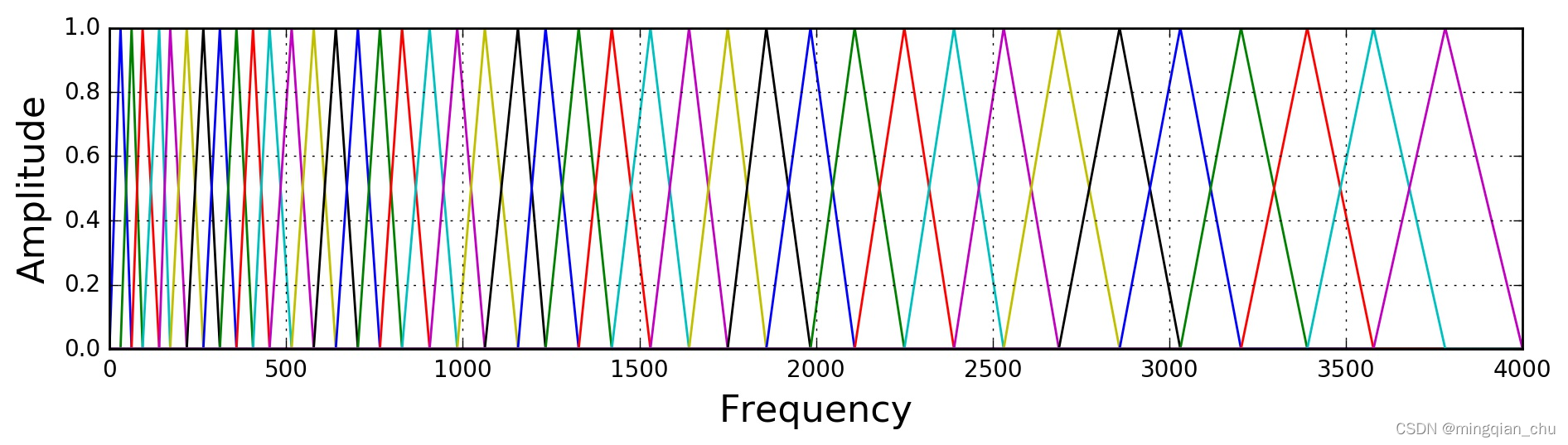
如上图所示,40个三角滤波器组成滤波器组,低频处滤波器密集,门限值大,高频处滤波器稀疏,门限值低。恰好对应了频率越高人耳越迟钝这一客观规律。上图所示的滤波器形式叫做等面积梅尔滤波器(Mel-filter bank with same bank area),在人声领域(语音识别,说话人辨认)等领域应用广泛,但是如果用到非人声领域,就会丢掉很多高频信息。
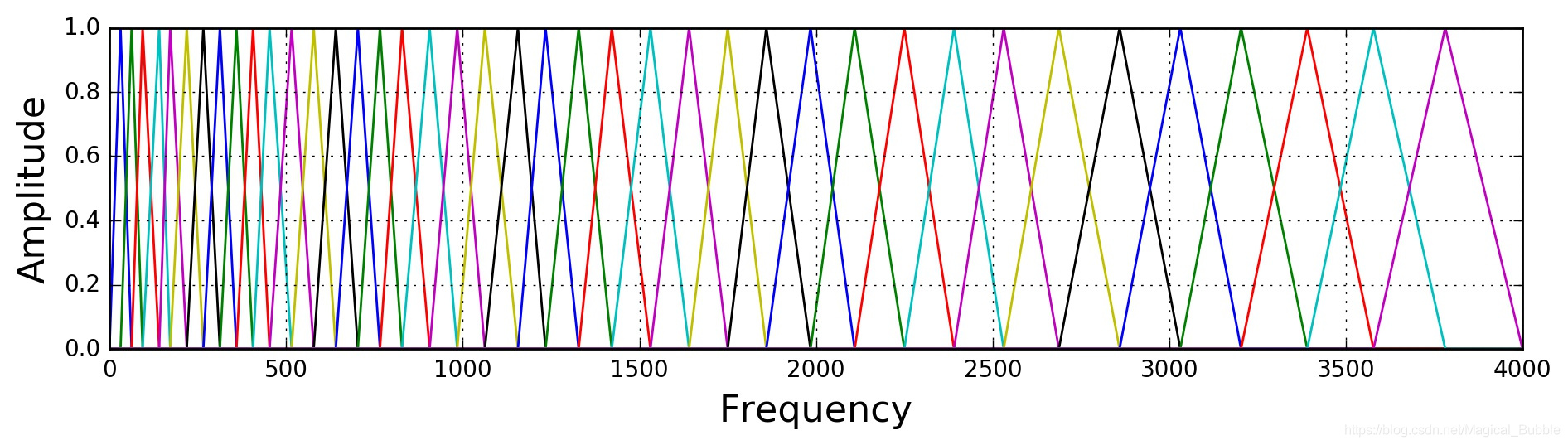
如上图所示,如果用到非人声领域,这时常用的是等高梅尔滤波器(Mel-filter bank with same bank height):
梅尔频率与实际频率的关系如下:
F m e l ( f ) = 2595 ∗ l o g 10 ( 1 + f 700 ) , F_{mel}(f) = 2595* log_{10}(1+ \frac{f}{700} ), Fmel(f)=2595∗log10(1+700f),
f
=
700
(
1
0
m
2595
−
1
)
.
f=700(10^\frac{m}{2595} −1).
f=700(102595m−1).
F
m
e
l
(
f
)
F_{mel}(f)
Fmel(f) j简写成m, 是以Mel为单位的感知频率,
f
f
f是以Hz为单位的实际频率;
注意, 如果对数以e为底, 则系数的取值为1125
Mel滤波器组就是一系列的三角形滤波器,通常有40个或80个,在中心频率点响应值为1,在两边的滤波器中心点衰减到0,如下图:
具体公式可以写为:
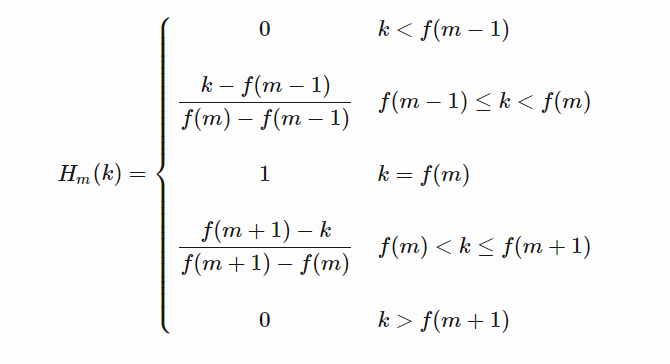
注意,log mel-filter bank outputs和“FBANK features说的是同一个东西,
他们本质上都指的是经过 Mel filter, Mel 滤波器的输出 ;
最后在能量谱上应用Mel滤波器组,其公式为:
Y t ( m ) = ∑ k = 1 N H m ( k ) ∣ X t ( k ) ∣ 2 Y_t(m) = \sum^{N}_{k=1} H_{m}(k)|X_{t}(k)|^2 Yt(m)=k=1∑NHm(k)∣Xt(k)∣2
其中,k表示FFT变换后的编号,m表示mel滤波器的编号。
low_freq_mel = 0
high_freq_mel = 2595 * np.log10(1 + (sample_rate / 2) / 700)
print(low_freq_mel, high_freq_mel)
0 2146.06452750619
nfilt = 40
mel_points = np.linspace(low_freq_mel, high_freq_mel, nfilt + 2) # 所有的mel中心点,为了方便后面计算mel滤波器组,左右两边各补一个中心点
hz_points = 700 * (10 ** (mel_points / 2595) - 1)
fbank = np.zeros((nfilt, int(NFFT / 2 + 1))) # 各个mel滤波器在能量谱对应点的取值
bin = (hz_points / (sample_rate / 2)) * (NFFT / 2) # 各个mel滤波器中心点对应FFT的区域编码,找到有值的位置
for i in range(1, nfilt + 1):
left = int(bin[i-1])
center = int(bin[i])
right = int(bin[i+1])
for j in range(left, center):
fbank[i-1, j+1] = (j + 1 - bin[i-1]) / (bin[i] - bin[i-1])
for j in range(center, right):
fbank[i-1, j+1] = (bin[i+1] - (j + 1)) / (bin[i+1] - bin[i])
print(fbank)
[[0. 0.46952675 0.93905351 … 0. 0. 0. ]
[0. 0. 0. … 0. 0. 0. ]
[0. 0. 0. … 0. 0. 0. ]
…
[0. 0. 0. … 0. 0. 0. ]
[0. 0. 0. … 0. 0. 0. ]
[0. 0. 0. … 0.14650797 0.07325398 0. ]]
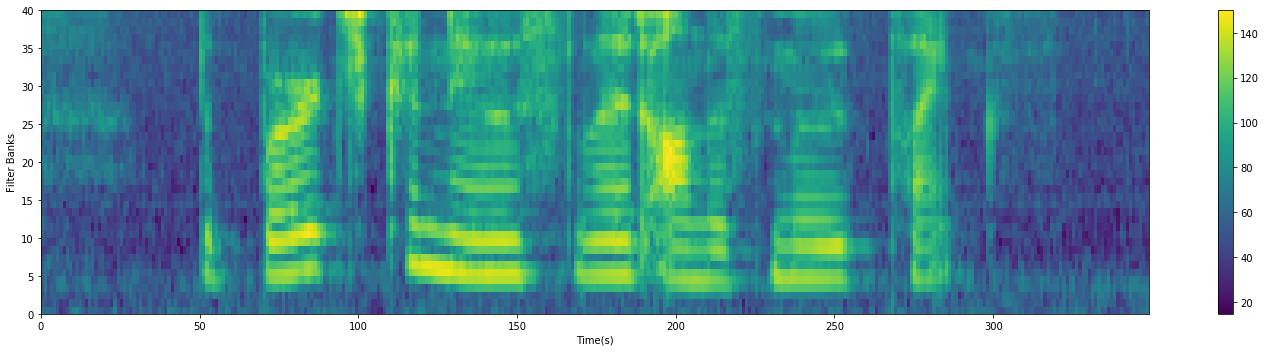
filter_banks = np.dot(pow_frames, fbank.T)
filter_banks = np.where(filter_banks == 0, np.finfo(float).eps, filter_banks)
filter_banks = 20 * np.log10(filter_banks) # dB
print(filter_banks.shape)
(349, 40)
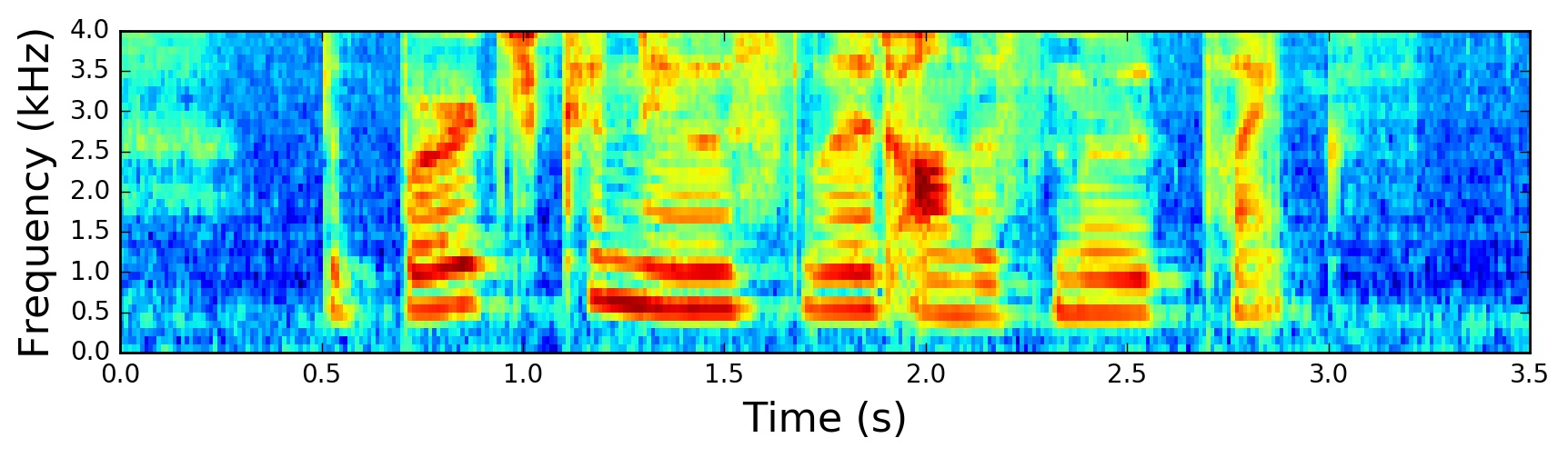
plot_spectrogram(filter_banks.T, 'Filter Banks')
在语音的频谱范围内设置若干带通滤波器 H m ( k ) H_m(k) Hm(k), 1 ≤ m ≤ M 1≤m≤M 1≤m≤M,M为滤波器的个数(M一般取24)。
每个滤波器具有三角滤波特性,其中心频率为 f ( m ) f(m) f(m), 1 ≤ m ≤ M 1≤m≤M 1≤m≤M。
在Mel频率范围内,这些滤波器是等带宽的。
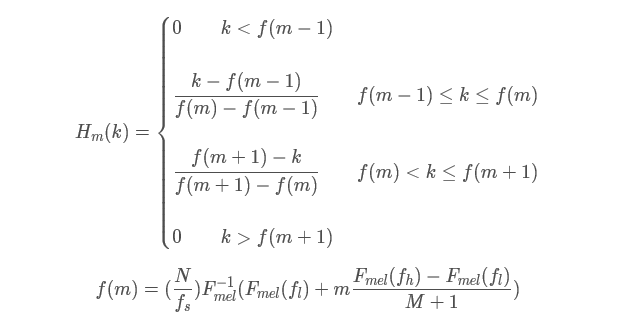
f l f_{l} fl为滤波器频率范围内的最低频率,
f
h
f_{h}
fh为滤波器频率范围内的最高频率,
N为DFT(或FFT)时的长度,
f
s
f_{s}
fs为采样频率,
F
m
e
l
F_{mel}
Fmel的逆函数:
F
m
e
l
−
1
(
m
)
=
700
(
1
0
m
2595
−
1
)
.
F^{-1}_{mel}(m) =700(10^\frac{m}{2595} −1).
Fmel−1(m)=700(102595m−1).
以M=6(6个滤波器)为例, f l f_{l} fl, f h f_{h} fh, f s f_{s} fs、 N N N、 M M M的值一旦确定就固定不变。
将Mel 频率尺度上的
F
m
e
l
(
f
l
)
F_{mel}(f_l)
Fmel(fl)至
F
m
e
l
(
f
h
)
F_{mel}(f_h)
Fmel(fh)
的Mel频率范围均分为M+1=7段,
产生M+2=8个Mel频率值。

分别求出这M+2=8个Mel频率对应的实际频率值,即:
F m e l − 1 ( F m e l ( f l ) + i F m e l ( f h ) − F m e l ( f l ) M + 1 ) F^{-1}_{mel}(F_{mel}(f_l)+i\cfrac{F_{mel}(f_h)-F_{mel}(f_l)}{M+1}) Fmel−1(Fmel(fl)+iM+1Fmel(fh)−Fmel(fl))
0 ≤ i ≤ 8 0≤i≤8 0≤i≤8
分别求出这M+2=8个实际频率值对应的FFT点数
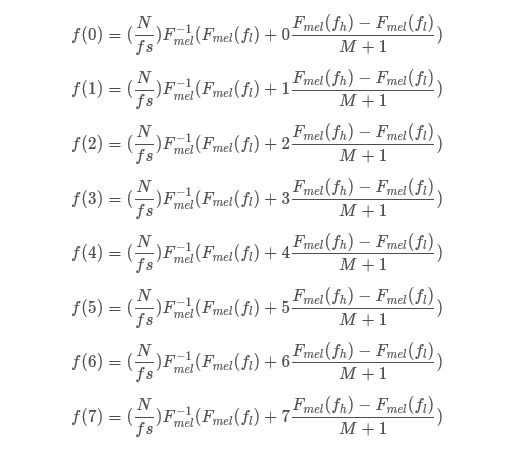
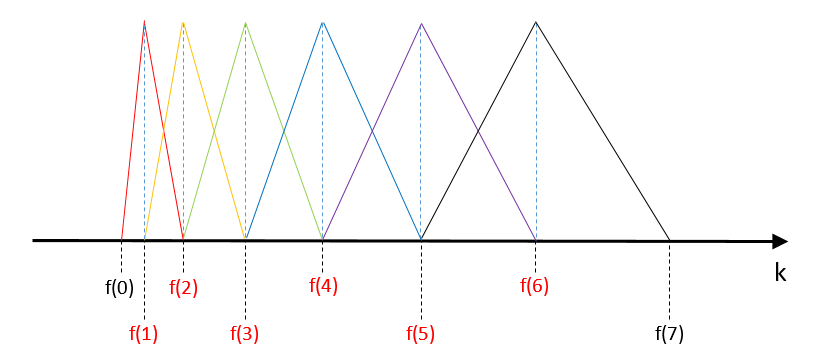
f(1)、f(2)、f(3)、f(4)、f(5)、f(6)分别为第1,2,3,4,5,6个滤波器的中心频率对应的FFT点数(向上取整),设计M=6个滤波器。
当 f(m-1)<k<f(m) 即 f(0)<k<f(1) 时,画红色三角形的左半部分;
当 f(m)<k<f(m+1) 即 f(1)<k<f(2) 时,画红色三角形的右半部分;
当 f(m-1)<k<f(m) 即 f(1)<k<f(2) 时,画黄色三角形的左半部分
当 f(m)<k<f(m+1) 即 f(2)<k<f(3) 时,画黄色三角形的右半部分
当 f(m-1)<k<f(m) 即 f(2)<k<f(3) 时,画绿色三角形的左半部分
当 f(m)<k<f(m+1) 即 f(3)<k<f(4) 时,画绿色三角形的右半部分
当 f(m-1)<k<f(m) 即 f(3)<k<f(4) 时,画蓝色三角形的左半部分
当 f(m)<k<f(m+1) 即 f(4)<k<f(5) 时,画蓝色三角形的右半部分
当 f(m-1)<k<f(m) 即 f(4)<k<f(5) 时,画紫色三角形的左半部分
当 f(m) <k<f(m+1) 即 f(5)<k<f(6) 时,画紫色三角形的右半部分
当 f(m-1)<k<f(m) 即 f(5)<k<f(6) 时,画黑色三角形的左半部分
当 f(m)<k<f(m+1) 即 f(6)<k<f(7) 时,画黑色三角形的右半部分
原始的Mel 滤波器,实现过程如下:
主要有分为三步:
映射到Mel 尺度上的原因,该Mel尺度的频率是拟合了人耳的线性变换,
将上述步骤一中, (K + 2) 个Mel 频率点 映射到(K + 2) 普通频率HZ上 h ( i ) h(i) h(i)
将步骤二中, (K + 2) 个普通频率取整到最接近的 frequency bin 频率上 f ( i ) f(i) f(i); 此时得到的 f ( i ) f(i) f(i) 即是各个滤波器的中心频率, 生成三角滤波器;
采用python中librosa库,发现从Hz频率到Mel频率有两种转换方式,而默认的方式并不是按照我们熟知的公式进行转换的,
因此详细研究了一下python中librosa库中与mel频谱有关的源代码。
这里我们主要关注数学表达,数学表达搞清后写代码自然不是难事。
通常情况下,hz频率f ff与mel频谱m mm通过如下公式转换
m = 2595 l g ( 1 + f / 700 ) , m=2595lg(1+ f/700), m=2595lg(1+f/700),
f = 700 ( 1 0 2595 m − 1 ) . f=700(10^{\frac{2595}{m}} −1). f=700(10m2595−1).
求出 Mel 滤波器中,对应的等间隔的Mel频率:
假如有10个Mel滤波器
(在实际应用中通常一组Mel滤波器组有26个滤波器。)
首先要选择一个最高频率和最低频率,通常最高频率为8000Hz,最低频率为300Hz。
使用从频率转换为Mel频率的公式将300Hz转换为401.25Mels,8000Hz转换为2834.99Mels,
由于有10个滤波器,每个滤波器针对两个频率的样点,样点之间会进行重叠处理,因此需要12个点,意味着需要在401.25和2834.99之间再线性间隔出10个附加点,如:
m(i)=401.25,622.50,843.75,1065.00,1286.25,1507.50,1728.74,1949.99,2171.24,2392.49,2613.74,2834.99
现在使用从Mel频率转换为频率的公式将它们转换回赫兹:
def hz2mel(hz):
'''把频率hz转化为梅尔频率'''
return 2595 * numpy.log10(1 + hz / 700.0)
def mel2hz(mel):
'''把梅尔频率转化为hz'''
return 700 * (10 ** (mel / 2595.0) - 1)
h(i)=300,517.33,781.90,1103.97,1496.04,1973.32,2554.33,3261.62,4122.63,5170.76,6446.70,8000
将频率映射到最接近的DFT频率
其中 257 = N , N取值为 DFT 长度中的有效保留值,
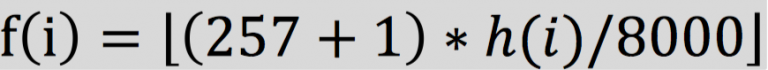
此时得到的 f(i), 便是 Mel 滤波器组中 各个滤波器的中心频率;
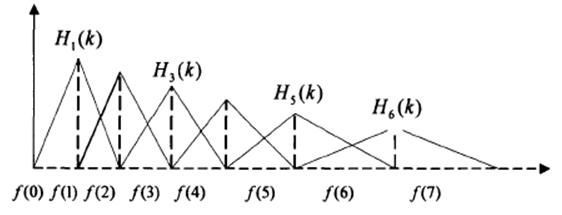
在得到各个滤波器的中心频率后, 便可知 各个滤波器对应的频率响应;
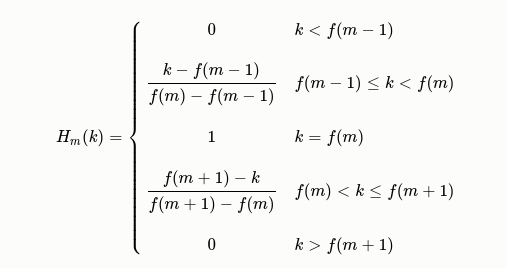
将功率谱形成的语谱图通过 Mel 滤波器组,便得到 Mel Spectrogram;
如下图,函数输入为(frequencies,htk)frequencies为待转化的频率,htk为是否用HTK formula进行转化,默认htk=False。
官方文档是这么解释的:htk,bool,
If True, use HTK formula to convert Hz to mel.
Otherwise (False), use Slaney’s Auditory Toolbox.
那么这里的Slaney’s Auditory Toolbox是怎么计算mel频率的呢?
根据代码来看是这样:
对于小于1000Hz的频率,进行线性转化, m = 3 f 200 m=\frac{3f}{200} m=2003f
对于大于(等于)1000Hz的频率,对数转化, m = 15 + l n f 1000 l n 6.4 27 m=15+\frac{ln\frac{f}{1000}}{\frac{ln6.4}{27}} m=15+27ln6.4ln1000f,
其中, 15是因为15 = 3 ∗ 1000 200 \frac{3*1000}{200} 2003∗1000,
至于6.4和27怎么来的我也不太清楚……
// An highlighted block
def hz_to_mel(frequencies, htk=False):
"""Convert Hz to Mels
Examples
--------
>>> librosa.hz_to_mel(60)
0.9
>>> librosa.hz_to_mel([110, 220, 440])
array([ 1.65, 3.3 , 6.6 ])
Parameters
----------
frequencies : number or np.ndarray [shape=(n,)] , float
scalar or array of frequencies
htk : bool
use HTK formula instead of Slaney
Returns
-------
mels : number or np.ndarray [shape=(n,)]
input frequencies in Mels
See Also
--------
mel_to_hz
"""
frequencies = np.asanyarray(frequencies)
if htk:
return 2595.0 * np.log10(1.0 + frequencies / 700.0)
# Fill in the linear part
f_min = 0.0
f_sp = 200.0 / 3
mels = (frequencies - f_min) / f_sp
# Fill in the log-scale part
min_log_hz = 1000.0 # beginning of log region (Hz)
min_log_mel = (min_log_hz - f_min) / f_sp # same (Mels)
logstep = np.log(6.4) / 27.0 # step size for log region
if frequencies.ndim:
# If we have array data, vectorize
log_t = frequencies >= min_log_hz
mels[log_t] = min_log_mel + np.log(frequencies[log_t] / min_log_hz) / logstep
elif frequencies >= min_log_hz:
# If we have scalar data, heck directly
mels = min_log_mel + np.log(frequencies / min_log_hz) / logstep
return mels
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
Region是HBase数据管理的基本单位,region有一点像关系型数据的分区。region中存储这用户的真实数据,而为了管理这些数据,HBase使用了RegionSever来管理region。Region的结构hbaseregion的大小设置默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的RegionServer,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的RegionServer。RegionSplit时机:当1个region中的某个Store下所有StoreFile
昨晚看到IDEA官推宣布IntelliJIDEA2023.1正式发布了。简单看了一下,发现这次的新版本包含了许多改进,进一步优化了用户体验,提高了便捷性。至于是否升级最新版本完全是个人意愿,如果觉得新版本没有让自己感兴趣的改进,完全就不用升级,影响不大。软件的版本迭代非常正常,正确看待即可,不持续改进就会慢慢被淘汰!根据官方介绍:IntelliJIDEA2023.1针对新的用户界面进行了大量重构,这些改进都是基于收到的宝贵反馈而实现的。官方还实施了性能增强措施,使得Maven导入更快,并且在打开项目时IDE功能更早地可用。由于后台提交检查,新版本提供了简化的提交流程。IntelliJIDEA
文章目录认识unity打包目录结构游戏逆向流程Unity游戏攻击面可被攻击原因mono的打包建议方案锁血飞天无限金币攻击力翻倍以上统称内存挂透视自瞄压枪瞬移内购破解Unity游戏防御开发时注意数据安全接入第三方反作弊系统外挂检测思路狠人自爆实战查看目录结构用il2cppdumper例子2-森林whoishe后记认识unity打包目录结构dll一般很大,因为里面是所有的游戏功能编译成的二进制码游戏逆向流程开发人员代码被编译打包到GameAssembly.dll中使用il2ppDumper工具,并借助游戏名_Data\il2cpp_data\Metadata\global-metadata.dat
本人是音乐爱好者,从小就特别喜欢那个随着音乐跳动的方框效果,就是这个:arduino上一大把对,我忍你很久了,我就想用mpy做,全网没有,行我自己研究。果然兴趣是最好的老师,我之前有篇博客专门讲音频,有兴趣的可以回顾一下。提到可视化频谱,必然绕不开fft,大学学过这玩意,当时一心玩,老师讲的一个字都么听进去,网上教程简略扫了一下,大该就是把时域转频域的工具,我大mpy居然没有fft函数,奶奶的,先放着。音频信息如何收集?第一种傻瓜式的ADC,模拟转数字,原始粗暴,第二种,I2S库,我之前博客有讲过,数据是PCM编码。然后又去学PCM编码,一学豁然开朗,舒服,以代码为例:audio_in=I2S
前言 Slowloris攻击是我在李华峰老师的书——《MetasploitWeb 渗透测试实战》里面看的,感觉既简单又使用,现在这种攻击是很容易被防护的啦。不过我也不敢真刀实战的去试,只是拿个靶机玩玩罢了。 废话还是写在结语里面吧。(划掉)结语可以不看(划掉)Slowloris攻击的原理 Slowloris是一种资源消耗类DoS攻击,它利用部分HTTP请求进行操作。也叫做慢速攻击,这里的慢速并不是说发动攻击慢,而是访问一条链接的速度慢。Slowloris攻击的功能是打开与目标Web服务器的连接,然后尽可能长时间的保持这些连接打开。如果由多台电脑同时发起Slo
介绍pytest是一个非常成熟的全功能的Python测试框架,主要有以下几个特点:简单灵活,容易上手支持参数化能够支持简单的单元测试和复杂的功能测试,还可以用来做selenium/appnium等自动化测试、接口自动化测试(pytest+requests)pytest具有很多第三方插件,并且可以自定义扩展,比较好用的如pytest-selenium(集成selenium)、pytest-html(完美html测试报告生成)、pytest-rerunfailures(失败case重复执行)、pytest-xdist(多CPU分发)等测试用例的skip和xfail处理可以很好的和jenkins集成
目录一、原理部分1、什么是串行通信(1)并行通信与串行通信(2)串行通信的制式(3)串行通信的主要方式 2、配置串口(1)SCON和PCON:串行口1的控制寄存器(2)SBUF:串行口数据缓冲寄存器 (3)AUXR:辅助寄存器编辑(4)ES、PS:与串行口1中断相关的寄存器(5)波特率设置 3、串口框架编写二、程序案例一、原理部分1、什么是串行通信(1)并行通信与串行通信微控制器与外部设备的数据通信,根据连线结构和传送方式的不同,可以分为两种:并行通信和串行通信。并行通信:数据的各位同时发送与接收,每个数据位使用一条导线,这种方式传输快,但是需要多条导线进行信号传输。串行通信:数据一位一
📝学技术、更要掌握学习的方法,一起学习,让进步发生👩🏻作者:一只IT攻城狮。💐学习建议:1、养成习惯,学习java的任何一个技术,都可以先去官网先看看,更准确、更专业。💐学习建议:2、然后记住每个技术最关键的特性(通常一句话或者几个字),从主线入手,由浅入深学习。❤️《SpringCloud入门实战系列》解锁SpringCloud主流组件入门应用及关键特性。带你了解SpringCloud主流组件,是如何一战解决微服务诸多难题的。项目demo:源码地址👉🏻SpringCloud入门实战系列不迷路👈🏻:SpringCloud入门实战(一)什么是SpringCloud?SpringCloud入门实战
例如,我一直看到称为String#split的方法,但从未见过String.split,这似乎更合乎逻辑。或者甚至可能是String::split,因为您可以认为#split位于String的命名空间中。当假定/隐含类(#split)时,我什至单独看到了该方法。我知道这是ri中识别方法的方式。哪个先出现?例如,这是为了区分方法和字段吗?我还听说这有助于区分实例方法和类方法。但这从哪里开始呢? 最佳答案 不同之处在于您如何访问这些方法。类方法使用::分隔符来表示消息可以发送到类/模块对象,而实例方法使用#分隔符表示消息可以发送到实例对