指的是客户端和服务器之间的交互在请求之间是无状态的,从客户端到服务器的每个请求都必须包含理解请求所必须的信息,同时在请求之间的任意间隔时间点,若服务器重启,那么客户端是得不到相应的通知的.所以无状态的请求可以由任何可用的服务器回答.
在REST样式的Web服务中,每个资源都有一个地址,资源本身都是用过方法调用的目标,这些方法都是标准方法: PUT,GET,POST.
理解就是想要对互联网上的资源进行操作,就必须向资源所在的服务器发出请求,请求体重必须包含资源的网络路径,以及对资源进行的操作.
下图为正排(索引对应着文本内容)

下图为倒排(以文本内容为key,id为内容)

es是面向文档的数据库,一条数据在这里就是一个文档,下面给出对应关系:

es里的index可以看成一个数据库,type看成数据表(逐渐被弱化7.x版本后已被删除),documents相当于行.
1.put命令用于向es服务器发出添加索引的请求:若重复添加想用的索引,会报错
eg:http://192.168.41.131:9200/shopping 向虚拟机中的服务器添加shopping索引
2.索引查询:
2.1查询所有的索引
http://192.168.41.131:9200/_cat/indices?v
其中_cat表示查看的意思, indices表示索引

2.2单个索引查询:
http://192.168.41.131:9200/shopping 也就是在后面加上索引名字

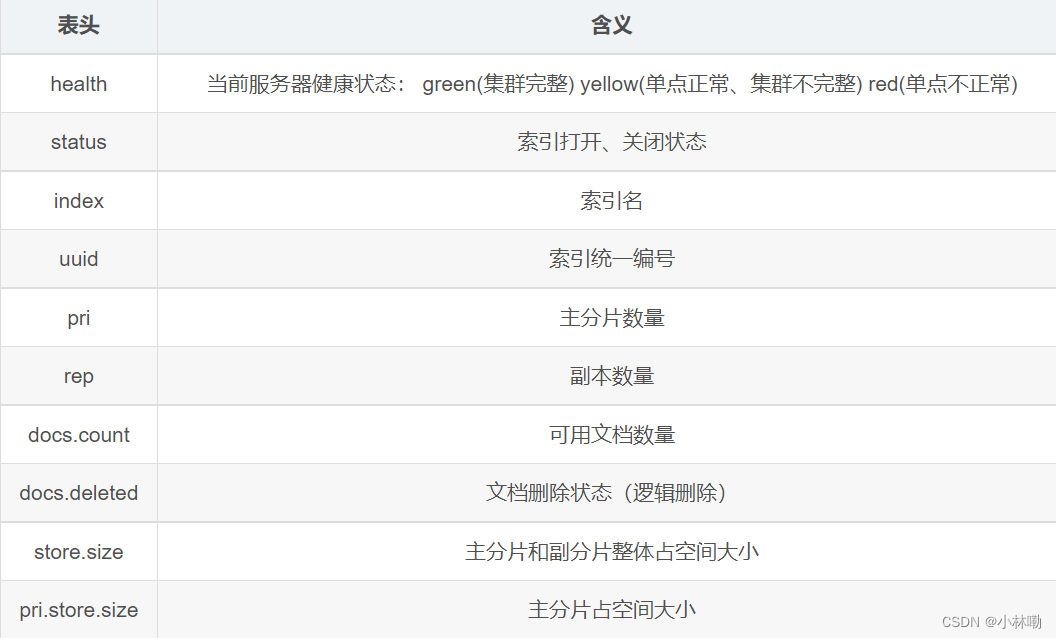
3.删除索引 就是将发送的方式改为delete即可.
http://192.168.41.131:9200/shopping
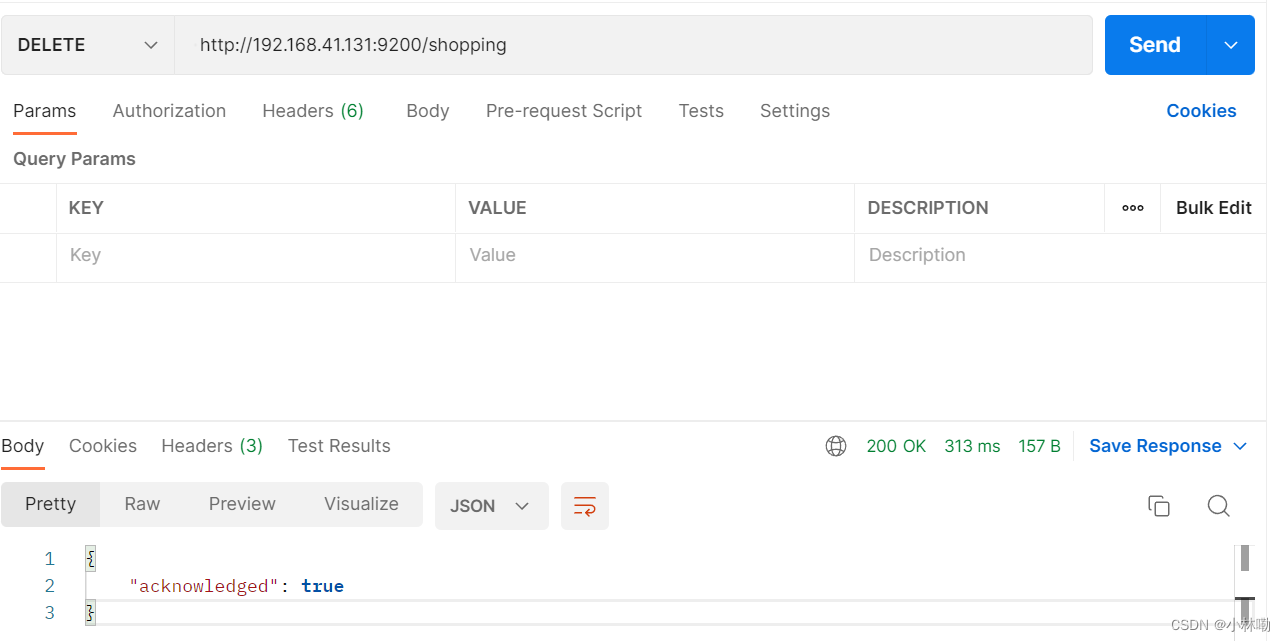
文档可以类比为关系型 数据库中的表数据,添加数据的格式为json.使用postman发送数据,注意post设置如下
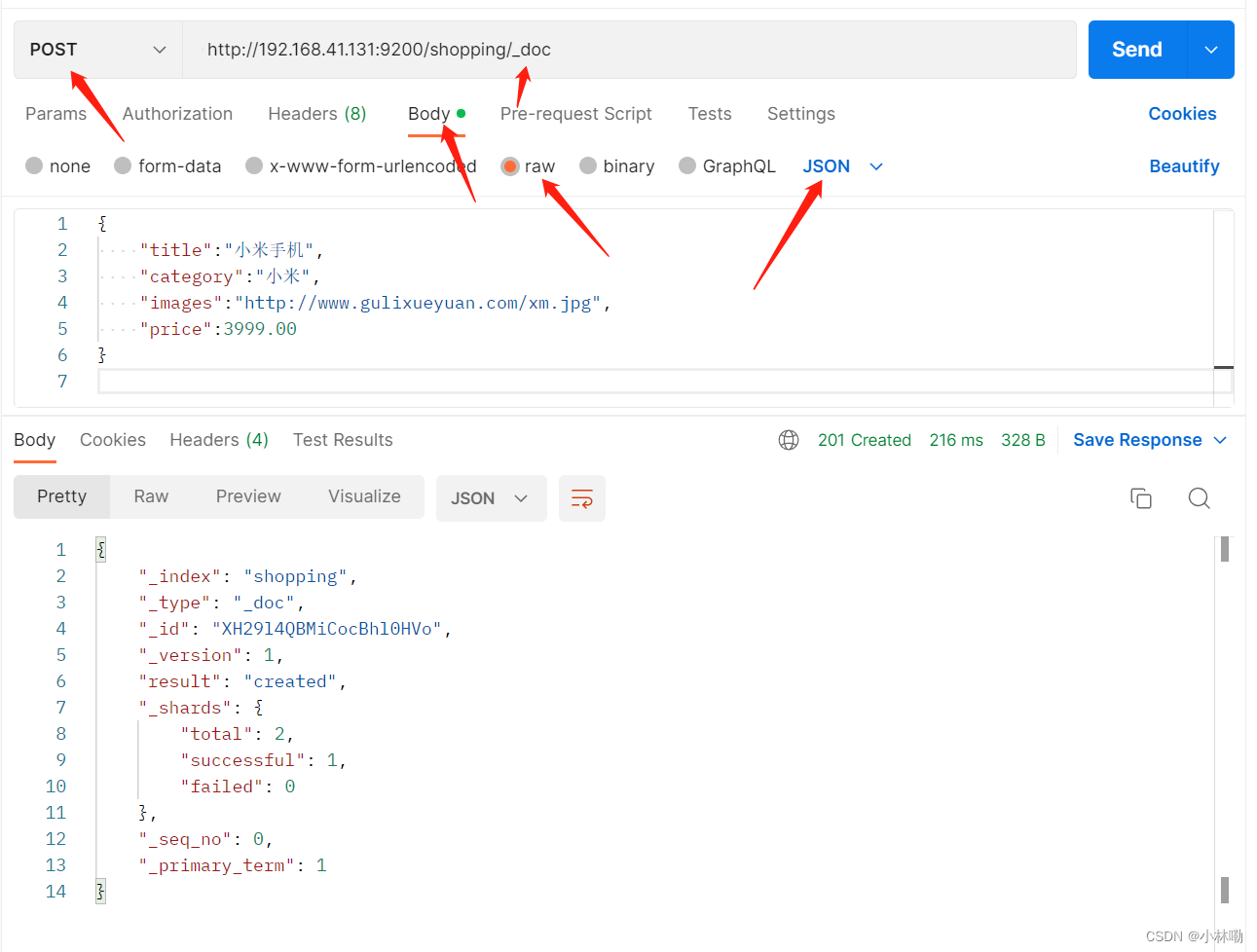
注意这里的数据创建时没有指定唯一数据标识,默认情况下,es服务器会自动生成一个随机标识(id),手动指定需要在创建时指定 :格式如下
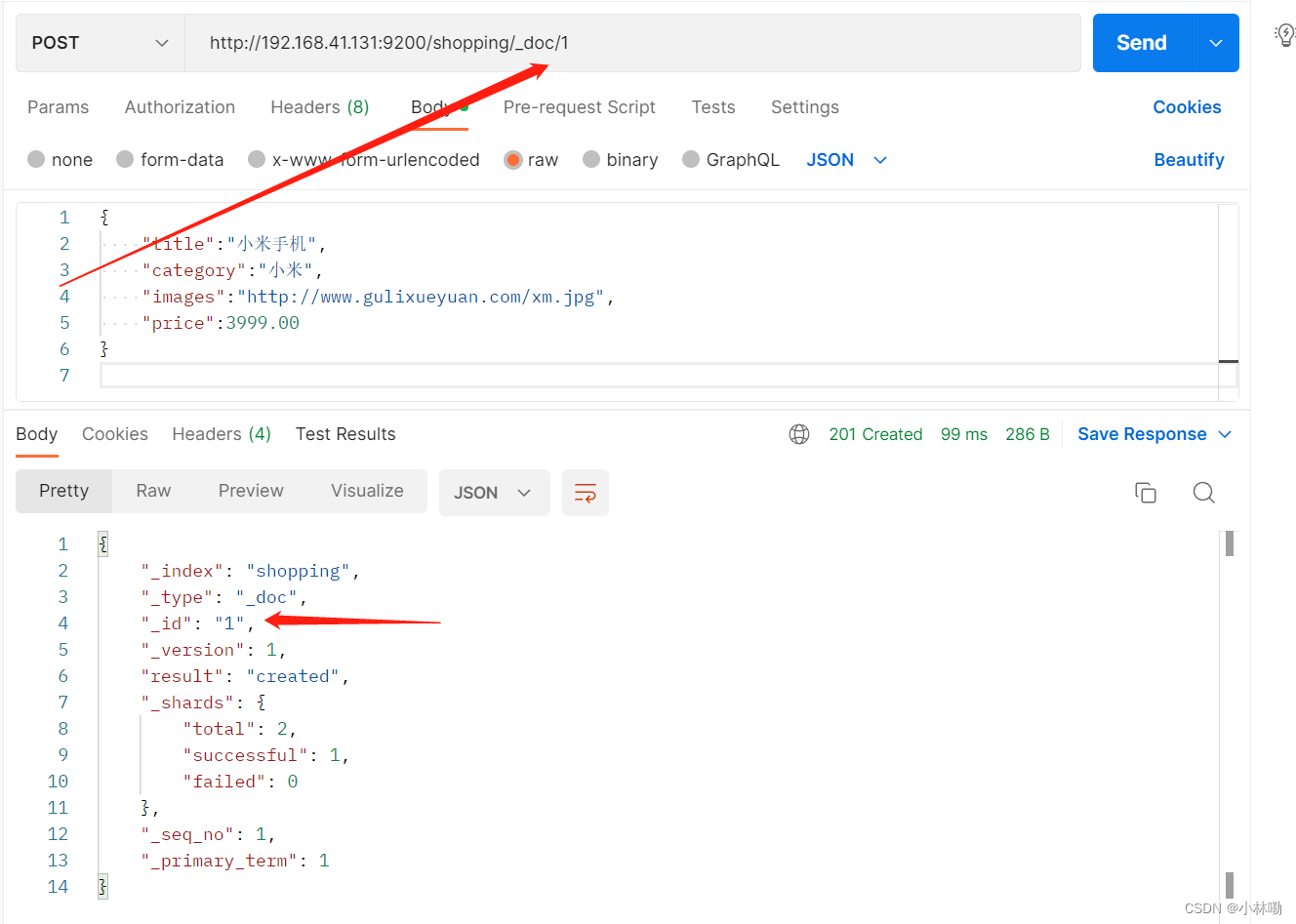
{
"_index": "shopping", //索引
"_type": "_doc",//类型-文档
"_id": "1",//id
"_version": 1,//版本
"result": "created",//结果(created表示创建成功)
"_shards": {
"total": 2,//分片-总数
"successful": 1,//分片总数
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}查询文档,需要指明文档的唯一性标识, 使用GET方法,类似如下
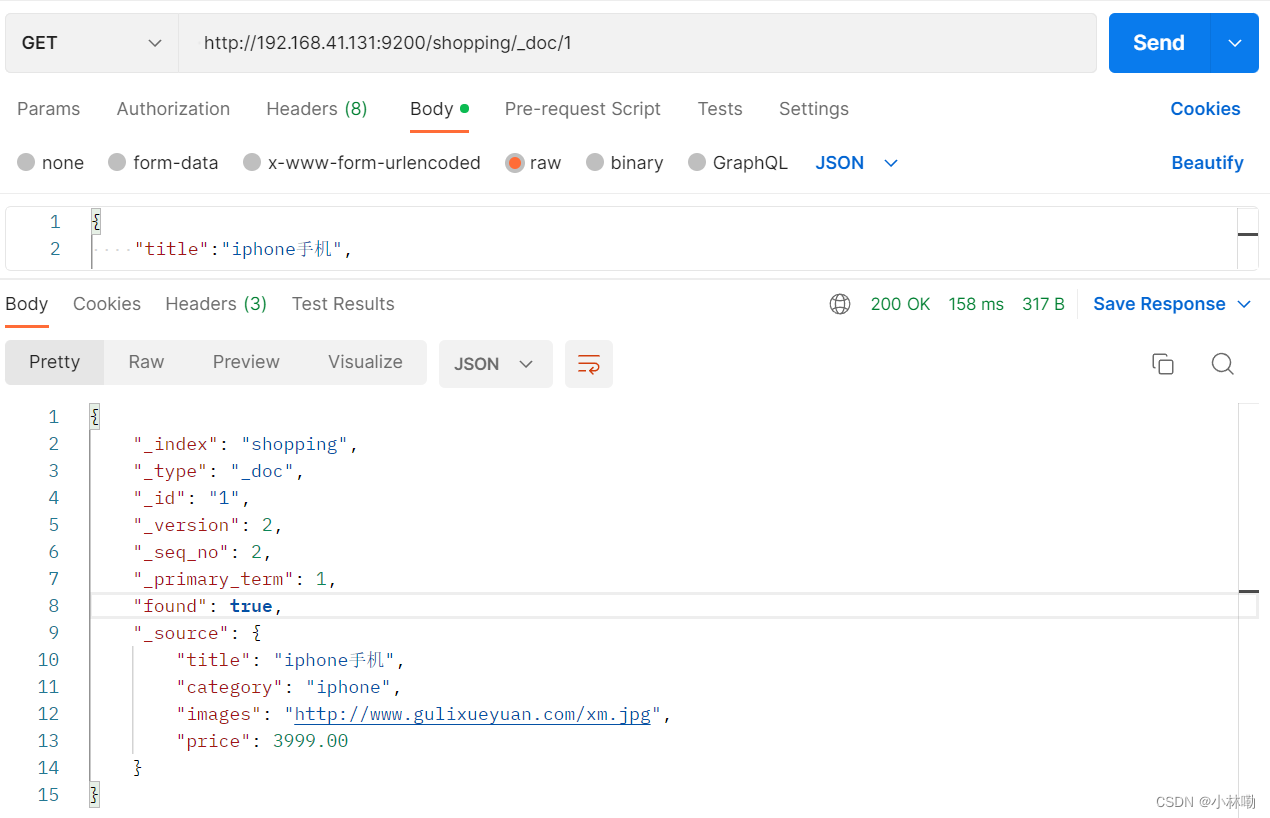
http://192.168.41.131:9200/shopping/_doc/1
如果查不到,会返回false
查询索引下所有的数据,在索引后加上_search
返回数据的格式如下
{
"took": 67,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "XH29l4QBMiCocBhl0HVo",
"_score": 1.0,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999.00
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"_score": 1.0,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999.00
}
}
]
}
}全量修改:
如果请求的url相同,那么输入不同的内容(请求体发生变化)会导致原有的数据被覆盖
局部修改:
将index后面添加_update,然后跟上doc的id,同样以post的形式发送,那么可以得到局部修改后的数据.注意在json中,添加了"doc"用来说明要修改的是个文档

删除时逻辑删除,不是物理删除,在删除后,他不会从磁盘立即移除.

1.可以使用url拼接的方式,但是不安全

2.使用json请求体查询(使用get方式)

3.查询全部文档内容

4.查询指定字段,注意json格式,添加了一个"_source"字段,且,位于query外侧 
5.分页查询
from指定查询的起始位置,size表示从起始位置开始的文档数量.如果搜索size大于10000,需要设置index.max_result_window参数 ,默认为10000。
6.指定数据的排序,按照price降序排序

7.多条件查询 也就是说多加几个math选项,同时注意添加了"must"字段(相当于数据库的&&字段),同时注意must后面加的是[],不是{}

如果想要表示"或" 那么使用should字段,注意filter和bool的包含关系,要把filter放到bool的括号里!!!!! gt表示大于

1.全文检索:类似搜索引擎,比如输入"小华"那么会返回品牌带有小和华任意一个字的所有标识,在本例中,显然是,小米和华为两个品牌.

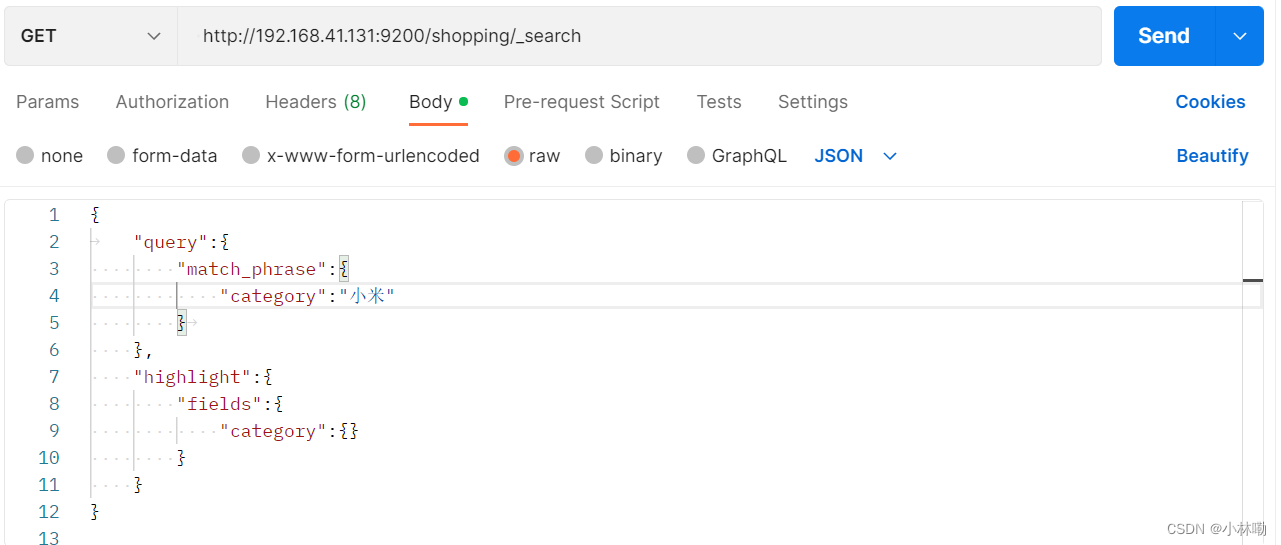
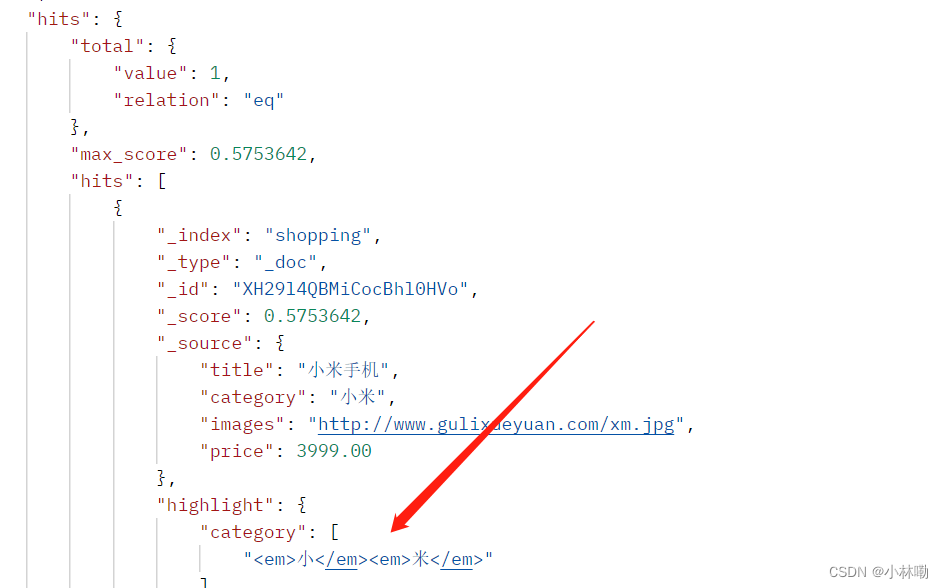
2.完全匹配 将match换成 match_phrase 此时会非常严格的执行匹配,一旦不匹配会返回空.当然也可以有个调节因子,slop 表示少匹配slop个元素也可以

3.高亮查询,就是增加个highlight模块
关键字:aggs,terms,聚合查询允许使用者对文档进行统计分析,类似于group by函数,当然还有其他许多聚合,比如最大值max,平均值avg.
带原始数据的聚合请求: 
如果不想带原始数据,那么,可以在args外指定一个size参数, size = 0

返回结果不包括其他条目,只有prices这一项

求平均值: 将上一步中的terms换成使用avg即可.

在建立 了索引之后就等于有了数据库中的database,然后我们需要创建写字段,也就是所谓的索引库映射工作,类似于关系型数据库的表结构.(建表过程).
映射:创建数据库的表字段需要的名称,类型,长度,约束等
1.新建一个索引库 user ,注意body不要带东西!

2.创建映射:插入三个属性 
3.添加数据

4.查询包含小的数据,注意url后面接的是_search

es数据类型(基本类型):
1.字符串类型:
1.text 会被分词的数据,
2.keyword 不会分词的字符串,可以设置是否需要存储 "index":"true|false"
2.数字类型:

3.Json没有日期类型,所以日期可以是
包含格式化日期的字符串,"2018-10-01"或者"2018/10/01 12:11:44"
代表时间毫秒数的长整型数字
代表时间秒数的整数
4.范围类型-range

es数据类型(复杂数据类型):
1.数组类型:array
es中没有专门的数组类型,所以使用[]定义即可.注意数组中的数据类型必须为同一类 型,不可以跨类型构建数组.
动态添加数组的时候第一个加入数组的数据类型决定了整个数组的数据类型
数组可以包含null值,空数组会被当做missing field 没有值的字段
给出一些示例:
① 字符串数组: ["one", "two"];
② 整数数组: [1, 2];
③ 由数组组成的数组: [1, [2, 3]], 等价于[1, 2, 3];
④ 对象数组: [{"name": "Tom", "age": 20}, {"name": "Jerry", "age": 18}].2.对象类型:object
json文档是分层的,文档可以包含内部对象,内部对象也可以进一步包含内部对象
添加示例,存储方式以及文档的映射结构如下
PUT employee/developer/1
{
"name": "ma_shoufeng",
"address": {
"region": "China",
"location": {"province": "GuangDong", "city": "GuangZhou"}
}
}
{
"name": "ma_shoufeng",
"address.region": "China",
"address.location.province": "GuangDong",
"address.location.city": "GuangZhou"
}
文档的映射结构:
PUT employee
{
"mappings": {
"developer": {
"properties": {
"name": { "type": "text", "index": "true" },
"address": {
"properties": {
"region": { "type": "keyword", "index": "true" },
"location": {
"properties": {
"province": { "type": "keyword", "index": "true" },
"city": { "type": "keyword", "index": "true" }
}
}
}
}
}
}
}
}
3.嵌套类型:nested
嵌套类型是对象数据类型的一个特例,可以让array类型的对象被独立索引和搜索. 嵌套对象实质是将每个对象分离出来, 作为隐藏文档进行索引.
创建映射:
PUT game_of_thrones
{
"mappings": {
"role": {
"properties": {
"performer": {"type": "nested" }
}
}
}
}
添加数据:
PUT game_of_thrones/role/1
{
"group" : "stark",
"performer" : [
{"first": "John", "last": "Snow"},
{"first": "Sansa", "last": "Stark"}
]
}
检索数据
GET game_of_thrones/_search
{
"query": {
"nested": {
"path": "performer",
"query": {
"bool": {
"must": [
{ "match": { "performer.first": "John" }},
{ "match": { "performer.last": "Snow" }}
]
}
},
"inner_hits": {
"highlight": {
"fields": {"performer.first": {}}
}
}
}
}
}
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
文章目录1、自相关函数ACF2、偏自相关函数PACF3、ARIMA(p,d,q)的阶数判断4、代码实现1、引入所需依赖2、数据读取与处理3、一阶差分与绘图4、ACF5、PACF1、自相关函数ACF自相关函数反映了同一序列在不同时序的取值之间的相关性。公式:ACF(k)=ρk=Cov(yt,yt−k)Var(yt)ACF(k)=\rho_{k}=\frac{Cov(y_{t},y_{t-k})}{Var(y_{t})}ACF(k)=ρk=Var(yt)Cov(yt,yt−k)其中分子用于求协方差矩阵,分母用于计算样本方差。求出的ACF值为[-1,1]。但对于一个平稳的AR模型,求出其滞
写在之前Shader变体、Shader属性定义技巧、自定义材质面板,这三个知识点任何一个单拿出来都是一套知识体系,不能一概而论,本文章目的在于将学习和实际工作中遇见的问题进行总结,类似于网络笔记之用,方便后续回顾查看,如有以偏概全、不祥不尽之处,还望海涵。1、Shader变体先看一段代码......Properties{ [KeywordEnum(on,off)]USL_USE_COL("IsUseColorMixTex?",int)=0 [Toggle(IS_RED_ON)]_IsRed("IsRed?",int)=0}......//中间省略,后续会有完整代码 #pragmamulti_c