官网地址:https://seatunnel.apache.org/
文档地址:https://interestinglab.github.io/seatunnel-docs/#/
SeaTunnel是一个简单易用,高性能,能够应对海量数据的数据处理产品。
SeaTunnel的前身是Waterdrop(中文名:水滴)自2021年10月12日更名为SeaTunnel。2021年12月9日,SeaTunnel正式通过Apache软件基金会的投票决议,以全票通过的优秀表现正式成为Apache孵化器项目。
本质上,SeaTunnel不是对Saprk和Flink的内部修改,而是在Spark和Flink的基础上做了一层包装。它主要运用了控制反转的设计模式,这也是SeaTunnel实现的基本思想。
SeaTunnel的日常使用,就是编辑配置文件。编辑好的配置文件由SeaTunnel转换为具体的Spark或Flink任务。如图所示。
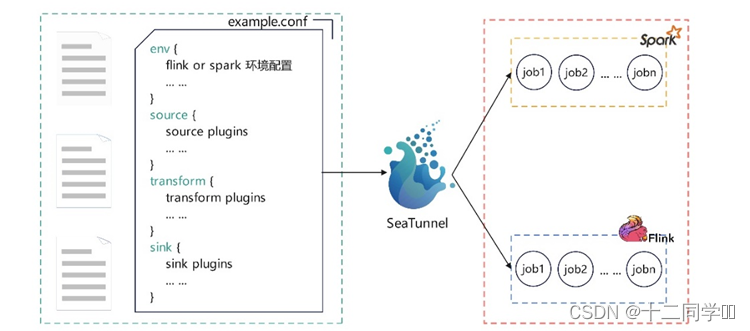
SeaTunnel适用于以下场景:
海量数据的同步
海量数据的集成
海量数据的ETL
海量数据聚合
多源数据处理
SeaTunnel的特点:
基于配置的低代码开发,易用性高,方便维护。
支持实时流式传输
离线多源数据分析
高性能、海量数据处理能力
模块化的插件架构,易于扩展
支持用SQL进行数据操作和数据聚合
支持Spark structured streaming
支持Spark 2.x
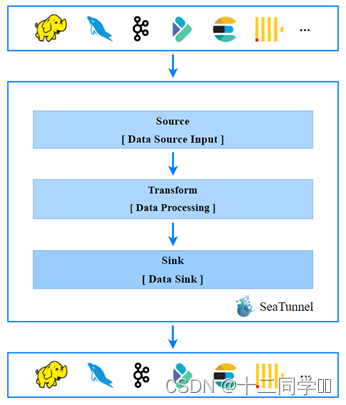
目前SeaTunnel的长板是他有丰富的连接器,又因为它以Spark和Flink为引擎。所以可以很好地进行分布式的海量数据同步。通常SeaTunnel会被用来做出仓入仓工具,或者被用来进行数据集成
| Spark连接器插件 | 数据库类型 | Source | Sink |
|---|---|---|---|
| Batch | Fake | √ | |
| ElasticSearch | √ | √ | |
| File | √ | √ | |
| Hive | √ | √ | |
| Hudi | √ | √ | |
| Jdbc | √ | √ | |
| MongoDB | √ | √ | |
| Neo4j | √ | ||
| Phoenix | √ | √ | |
| Redis | √ | √ | |
| Tidb | √ | √ | |
| Clickhouse | √ | ||
| Doris | √ | ||
| √ | |||
| Hbase | √ | √ | |
| Kafka | √ | ||
| Console | √ | ||
| Kudu | √ | √ | |
| Redis | √ | √ | |
| Stream | FakeStream | √ | |
| KafkaStream | √ | ||
| SocketSTream | √ |
| Flink连接器插件 | 数据库类型 | Source | Sink |
|---|---|---|---|
| Druid | √ | √ | |
| Fake | √ | ||
| File | √ | √ | |
| InfluxDb | √ | √ | |
| Jdbc | √ | √ | |
| Kafka | √ | √ | |
| Socket | √ | ||
| Console | √ | ||
| Doris | √ | ||
| ElasticSearch | √ |
| 转换插件 | Spark | Flink |
|---|---|---|
| Add | ||
| CheckSum | ||
| Convert | ||
| Date | ||
| Drop | ||
| Grok | ||
| Json | √ | |
| Kv | ||
| Lowercase | ||
| Remove | ||
| Rename | ||
| Repartition | ||
| Replace | ||
| Sample | ||
| Split | √ | √ |
| Sql | √ | √ |
| Table | ||
| Truncate | ||
| Uppercase | ||
| Uuid |
Java版本需要>=1.8
SeaTunnel支持Spark 2.x(尚不支持Spark 3.x)。支持Flink 1.9.0及其以上的版本。
去官网下载解压即可
在config/目录中有一个seatunnel-env.sh脚本

修改为自己的spark或者flink路径即可
官方的flink案例
1.选择任意路径,创建一个文件。这里我们选择在SeaTunnel的config路径下创建一个example01.conf
vim example01.conf
2.在文件中编辑如下内容
# 配置Spark或Flink的参数
env {
# You can set flink configuration here
execution.parallelism = 1
#execution.checkpoint.interval = 10000
#execution.checkpoint.data-uri = "hdfs://node1:9092/checkpoint"
}
# 在source所属的块中配置数据源
source {
SocketStream{
host = node1
result_table_name = "fake"
field_name = "info"
}
}
# 在transform的块中声明转换插件
transform {
Split{
separator = "#"
fields = ["name","age"]
}
sql {
sql = "select info, split(info) as info_row from fake"
}
}
# 在sink块中声明要输出到哪
sink {
ConsoleSink {}
}
3.开启flink集群
bin/start-cluster.sh
4.开启一个netcat服务来发送数据
nc -lk 9999
5.使用SeaTunnel来提交任务
bin/start-seatunnel-flink.sh --config config/example01.conf
6.在netcat上发送数据

7.在Flink webUI上查看输出结果
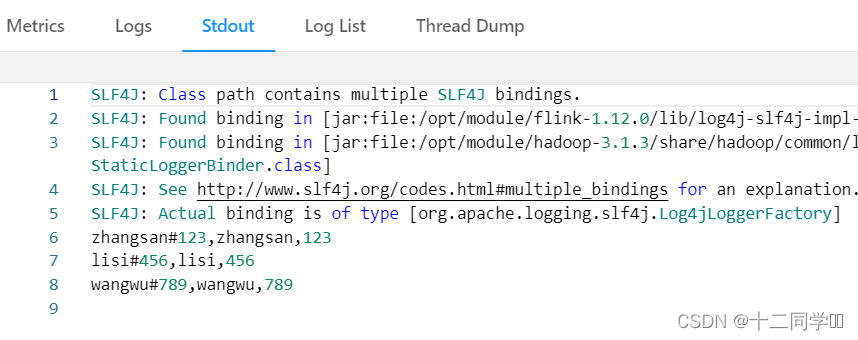
截至目前,SeaTunnel有两个启动脚本。
提交spark任务用start-seatunnel-spark.sh。
提交flink任务则用start-seatunnel-flink.sh。
start-seatunnle-flink.sh可以指定3个参数
分别是:
–config参数用来指定应用配置文件的路径
–variable参数可以向配置文件传值。配置文件内是支持声明变量的。然后我们可以通过命令行给配置中的变量赋值。
变量声明语法如下
sql {
sql = "select * from (select info,split(info) from fake) where age > '"${age}"'"
}
在配置文件的任何位置都可以声明变量。并用命令行参数–variable key=value的方式将变量值传进去,你也可以用它的短命令形式 -i key=value。传递参数时,key需要和配置文件中声明的变量名保持一致。
如果需要传递多个参数,那就在命令行里面传递多个-i或–variable key=value。
bin/start-seatunnel-flink.sh --config/xxx.sh -i age=18 -i sex=man
–check参数用来检查config语法是否合法(check功能还尚在开发中,因此–check参数是一个虚设)
一个完整的SeaTunnel配置文件应包含四个配置组件。分别是:
env{} source{} --> transform{} --> sink{}

在Source和Sink数据同构时,如果业务上也不需要对数据进行转换,那么transform中的内容可以为空。具体需根据业务情况来定。
Row是SeaTunnel中数据传递的核心数据结构。对flink来说,source插件需要给下游的转换插件返回一个DataStream,转换插件接到上游的DataStream进行处理后需要再给下游返回一个DataStream。最后Sink插件将转换插件处理好的DataStream输出到外部的数据系统。
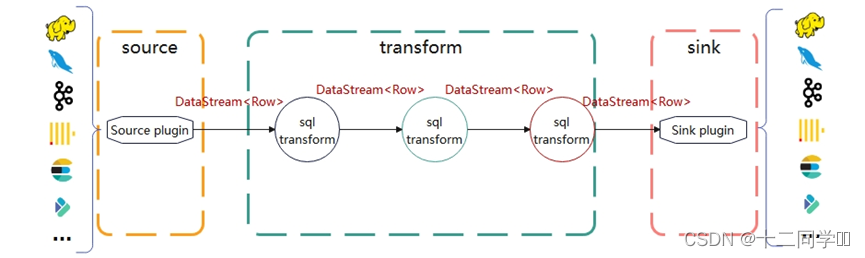
因为DataStream可以很方便地和Table进行互转,所以将Row当作核心数据结构可以让转换插件同时具有使用代码(命令式)和sql(声明式)处理数据的能力。
env块中可以直接写spark或flink支持的配置项。比如并行度,检查点间隔时间。检查点hdfs路径等。在SeaTunnel源码的ConfigKeyName类中,声明了env块中所有可用的key。如图所示:

source块是用来声明数据源的。source块中可以声明多个连接器。比如:
# 伪代码
env {
...
}
source {
hdfs { ... }
elasticsearch { ... }
jdbc {...}
}
transform {
sql {
sql = """
select .... from hdfs_table
join es_table
on hdfs_table.uid = es_table.uid where ..."""
}
}
sink {
elasticsearch { ... }
}
需要注意的是,所有的source插件中都可以声明result_table_name。如果你声明了result_table_name。SeaTunnel会将source插件输出的DataStream转换为Table并注册在Table环境中。当你指定了result_table_name,那么你还可以指定field_name,在注册时,给Table重设字段名。
transform{}块中可以声明多个转换插件。所有的转换插件都可以使用source_table_name,和result_table_name。同样,如果我们声明了result_table_name,那么我们就能声明field_name。
目前可用的插件总共有两个,一个是Split,另一个是sql。
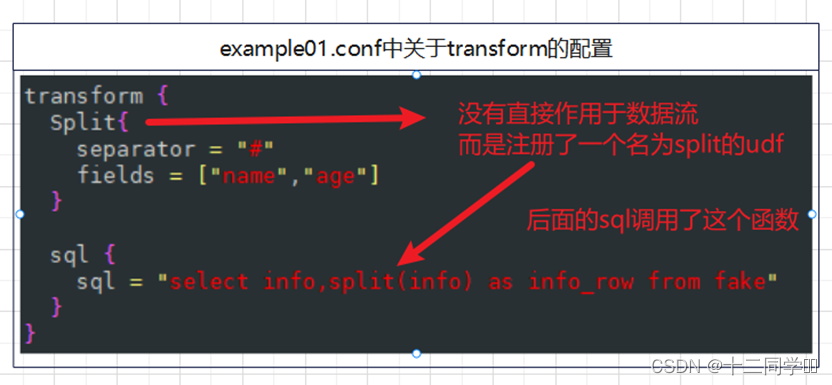
Split插件并没有对数据流进行任何的处理,而是将它直接return了。反之,它向表环境中注册了一个名为split的UDF(用户自定义函数)。而且,函数名是写死的。
指定soure_table_name对于sql插件的意义不大。因为sql插件可以通过from子句来决定从哪个表里抽取数据。
Sink块里可以声明多个sink插件,每个sink插件都可以指定source_table_name。不过因为不同Sink插件的配置差异较大,所以在实现时建议参考官方文档。
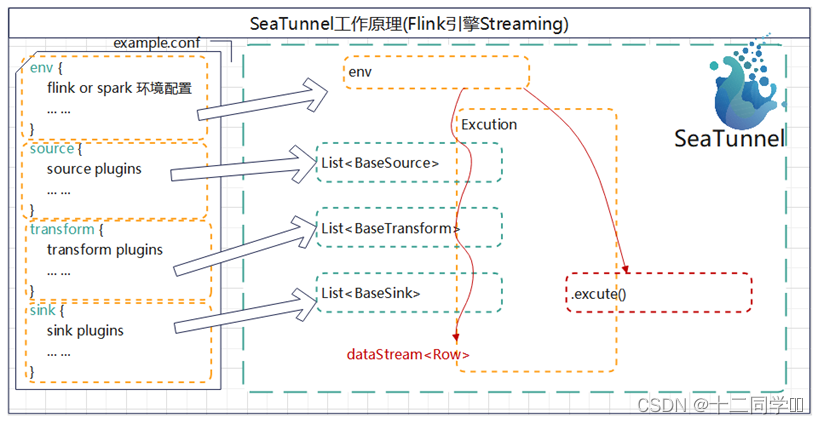
1.程序会解析你的应用配置,并创建环境
2.配置里source{},transform{},sink{}三个块中的插件最终在程序中以List集合的方式存在。
3.由Excution对象来拼接各个插件,这涉及到选择source_table,注册result_table等流程,注册udf等流程。并最终触发执行
用一张图将SeaTunnel中的重要概念串起来
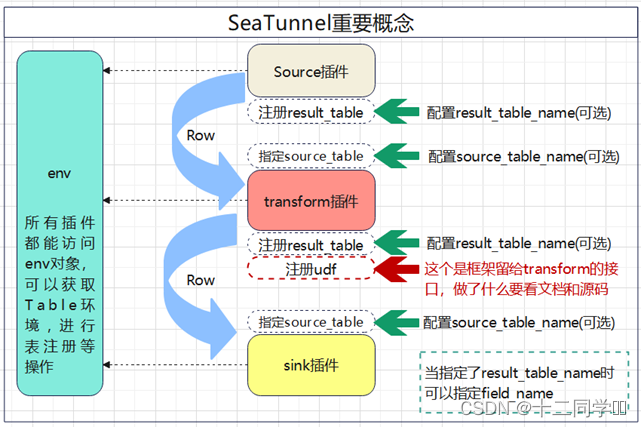
如果你不指定source_table_name,插件会使用它在配置文件上最近的上一个插件的输出作为输入。
这个已经在2.12版本里面启用,将hive-jdbc-3.1.2-standalone.jar放入flink的lib中
env {
# You can set flink configuration here
execution.parallelism = 1
#execution.checkpoint.interval = 10000
#execution.checkpoint.data-uri = "hdfs://node1:9092/checkpoint"
}
# 在source所属的块中配置数据源
source {
JdbcSource {
driver = org.apache.hive.jdbc.HiveDriver
url = "jdbc:hive2://node1:10000"
username = hive
query = "select * from yes.student"
}
}
# 在transform的块中声明转换插件
transform {
}
# 在sink块中声明要输出到哪
sink {
ConsoleSink {}
}
对test_csv主题中的数据进行过滤,仅保留年龄在18岁以上的记录
env {
# You can set flink configuration here
execution.parallelism = 1
#execution.checkpoint.interval = 10000
#execution.checkpoint.data-uri = "hdfs://hadoop102:9092/checkpoint"
}
# 在source所属的块中配置数据源
source {
KafkaTableStream {
consumer.bootstrap.servers = "node1:9092"
consumer.group.id = "seatunnel-learn"
topics = test_csv
result_table_name = test
format.type = csv
schema = "[{\"field\":\"name\",\"type\":\"string\"},{\"field\":\"age\", \"type\": \"int\"}]"
format.field-delimiter = ";"
format.allow-comments = "true"
format.ignore-parse-errors = "true"
}
}
# 在transform的块中声明转换插件
transform {
sql {
sql = "select name,age from test where age > '"${age}"'"
}
}
# 在sink块中声明要输出到哪
sink {
kafkaTable {
topics = "test_sink"
producer.bootstrap.servers = "node1:9092"
}
}
启动任务
bin/start-seatunnel-flink.sh --config config/example03.conf -i age=18
使用回话日志统计用户的总观看视频数,用户最常会话市场,用户最小会话时长,用户最后一次会话时间。
create database test_db;
CREATE TABLE `example_user_video` (
`user_id` largeint(40) NOT NULL COMMENT "用户id",
`city` varchar(20) NOT NULL COMMENT "用户所在城市",
`age` smallint(6) NULL COMMENT "用户年龄",
`video_sum` bigint(20) SUM NULL DEFAULT "0" COMMENT "总观看视频数",
`max_duration_time` int(11) MAX NULL DEFAULT "0" COMMENT "用户最长会话时长",
`min_duration_time` int(11) MIN NULL DEFAULT "999999999" COMMENT "用户最小会话时长",
`last_session_date` datetime REPLACE NULL DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次会话时间"
) ENGINE=OLAP
AGGREGATE KEY(`user_id`, `city`, `age`)
COMMENT "OLAP"
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
;
env {
execution.parallelism = 1
}
source {
KafkaTableStream {
consumer.bootstrap.servers = "node1:9092"
consumer.group.id = "seatunnel5"
topics = test
result_table_name = test
format.type = json
schema = "{\"session_id\":\"string\",\"video_count\":\"int\",\"duration_time\":\"long\",\"user_id\":\"string\",\"user_age\":\"int\",\"city\":\"string\",\"session_start_time\":\"datetime\",\"session_end_time\":\"datetime\"}"
format.ignore-parse-errors = "true"
}
}
transform{
sql {
sql = "select user_id,city,user_age as age,video_count as video_sum,duration_time as max_duration_time,duration_time as min_duration_time,session_end_time as last_session_date from test"
result_table_name = test2
}
}
sink{
DorisSink {
source_table_name = test2
fenodes = "node1:8030"
database = test_db
table = example_user_video
user = atguigu
password = 123321
batch_size = 50
doris.column_separator="\t"
doris.columns="user_id,city,age,video_sum,max_duration_time,min_duration_time,last_session_date"
}
}
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
文章目录1、自相关函数ACF2、偏自相关函数PACF3、ARIMA(p,d,q)的阶数判断4、代码实现1、引入所需依赖2、数据读取与处理3、一阶差分与绘图4、ACF5、PACF1、自相关函数ACF自相关函数反映了同一序列在不同时序的取值之间的相关性。公式:ACF(k)=ρk=Cov(yt,yt−k)Var(yt)ACF(k)=\rho_{k}=\frac{Cov(y_{t},y_{t-k})}{Var(y_{t})}ACF(k)=ρk=Var(yt)Cov(yt,yt−k)其中分子用于求协方差矩阵,分母用于计算样本方差。求出的ACF值为[-1,1]。但对于一个平稳的AR模型,求出其滞
写在之前Shader变体、Shader属性定义技巧、自定义材质面板,这三个知识点任何一个单拿出来都是一套知识体系,不能一概而论,本文章目的在于将学习和实际工作中遇见的问题进行总结,类似于网络笔记之用,方便后续回顾查看,如有以偏概全、不祥不尽之处,还望海涵。1、Shader变体先看一段代码......Properties{ [KeywordEnum(on,off)]USL_USE_COL("IsUseColorMixTex?",int)=0 [Toggle(IS_RED_ON)]_IsRed("IsRed?",int)=0}......//中间省略,后续会有完整代码 #pragmamulti_c
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。我来自C、php和bash背景,很容易学习,因为它们都有相同的C结构,我可以将其与我已经知道的联系起来。然后2年前我学了Python并且学得很好,Python对我来说比Ruby更容易学。然后从去年开始,我一直在尝试学习Ruby,然后是Rails,我承认,直到现在我还是学不会,讽刺的是那些打着简单易学的烙印,但是对于我这样一个老练的程序员来说,我只是无法将它