图的概述和存储结构(一)
文章目录
有一种说法是程序是由数据结构和算法组成的,这很能体现出数据结构在编码中的重要性。而代码优化的能力也是区别有基础的程序员和码农的重要标准,所以对于这一块的学习一定要稳重与细致,每一个章节都要实打实敲出能够实现该种结构的代码才算完成。
数据结构的学习本质上是让我们能见到很多前辈在解决一些要求时间和空间的难点问题上设计出的一系列解决方法,我们可以在今后借鉴这些方法,也可以根据这些方法在遇到具体的新问题时提出自己的解决方法。(所以各种定义等字眼就不用过度深究啦,每个人的表达方式不一样而已)在此以下的所有代码都是仅供参考,绝对不是唯一的答案,任何一种操作能达到相同的结果,只要逻辑上能行的通,复杂度上差不多,是无所谓怎么去实现最后的功能的。
图是由两个集合组成的V代表顶点集合 E代表边集合(一个顶点偶数对)
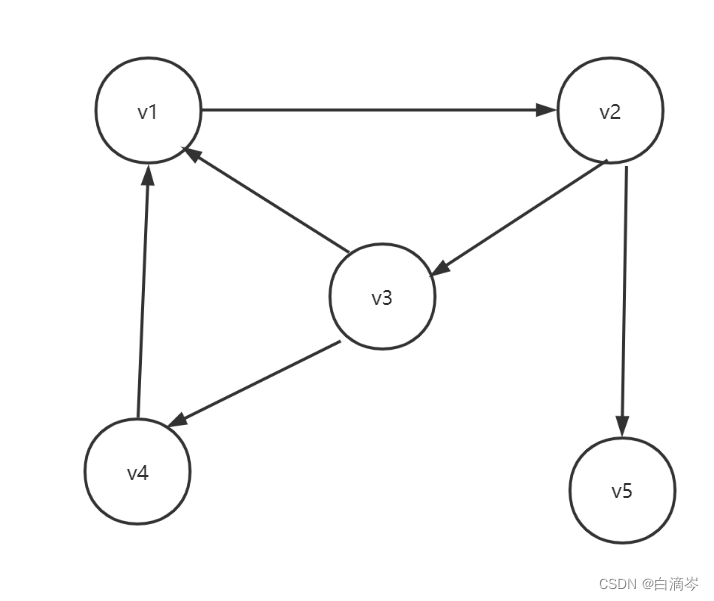
1.简单图
在图当中如果不存在顶点到其自身的边 且边不重复 的图叫做简单图;
2.无向图与有向图
没有方向的图是无向图、每条边都有方向的是有向图;
3.完全图
如果图中任意两个节点之间都存在一条边 称之为完全图。
1.端点和邻接点
在无向图中存在(i,j)那么顶点i和顶点j是两个端点 且 i和j互为邻接点;
在有向图中(i,j)那么顶点i是起点,顶点 j是终点;
2.度
无向图中顶点具有的边的数目就是度
有向图中
入度 以该顶点进入边的数目,
出度 以该顶点出去边的数目;
3.子图
有一个图是另一个图的顶点的子集,并且边的关系一致;
4.路径 路径长度
对于这个图
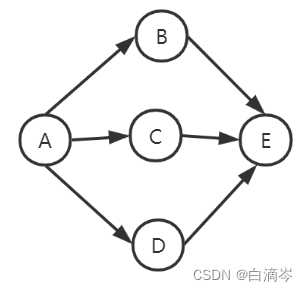
ADE是一条路径 很明显路径不止一条
而路径长度,是A到D到E边的数目
5.连通 连通图 连通分量
如果两个节点之间有路径 那么就是连通的如果任意节点连通 那么就是连通图
一个无向图中 一个极大连通子图(再多一个节点就连通不上了) 就是连通分量
一个有向图中 一个极大连通子图(再多一个节点就连通不上了) 就是强连通分量
6.稠密图 和 稀疏图
通常认为n个节点的图边数为nlogn那么小于nlogn的边叫稀疏图大于的叫稠密图
事实上视具体情况而定
7.权 和 网
图中每一条边所对应的数字 就叫权值(可以理解为对于工期 需要的时间)
对于带权的图 就称网
8.连通图的生成树
就是一个极小连通图(再减去一条边就不连通了)
生成树不止一个
图的存储分为:邻接矩阵 邻接表 十字链表 邻接多重表 边集数组
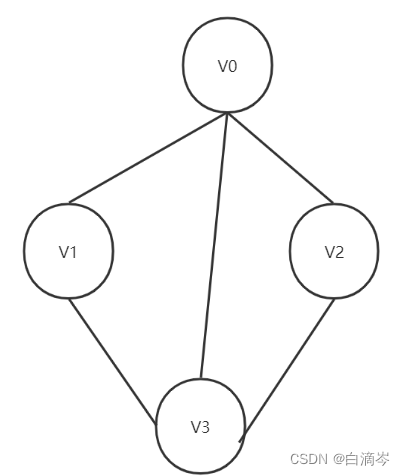
对于如此一个无向图而言 我们应该考虑怎么样去实现存储图的顶点和边的信息,
实际上我们可以用一个一维数组存储顶点的信息 和 二维数组来边的信息
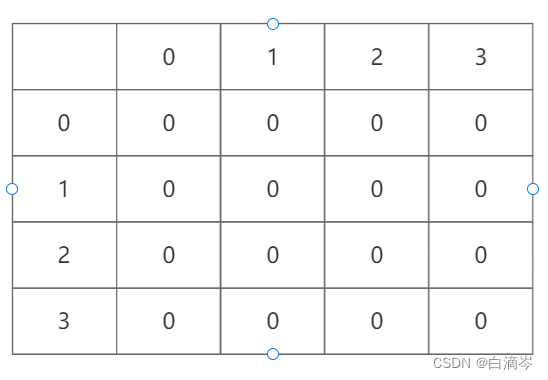 这是一个二维数组的具现化表格,表头代表的是顶点的下标
这是一个二维数组的具现化表格,表头代表的是顶点的下标
对一个非带权的图 0代表没有边 1代表有边,值得注意的是在实际中顶点指向自己的边是没有意义的,即对角线恒为0
如果是带权的图 初始化为0或者为一个不可能的值(如65535
那么对如此一个无向图,可以得到以下表格
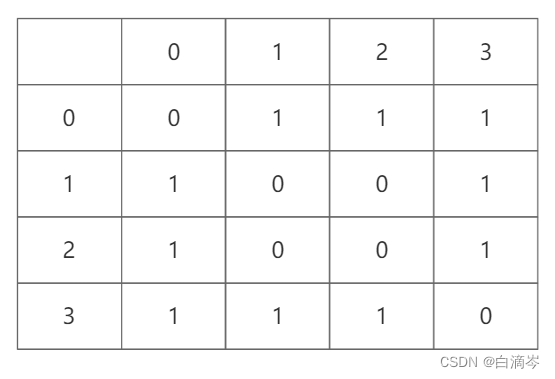
因为是无向图,顶点i既连接顶点j,又被顶点j连接,所以无向图是对称的关系
那么我们只要把上表的数据写入二维数组就是邻接矩阵
#include <stdio.h>
#include <stdlib.h>
#define MaxVertices 100
//邻接矩阵
typedef struct AdjacentMatrix
{
//顶点集
int Vertices[MaxVertices];
//边集
int Edge[MaxVertices][MaxVertices];
//顶点数 边数
int numV, numE;
}AdjMatrix;
void creategrahp(AdjMatrix* G)
{
int n, e;//n代表顶点数 e代表边数
int vi, vj;//vi vj代表边的两个顶点对
printf("要输入的顶点数和边数\n");
scanf_s("%d%d",&n,&e);
G->numV = n;
G->numE = e;
//图的初始化
for(int i = 0; i < n; i++)
{
for(int j = 0; j < n; j++)
{
if(i == j)
{
//一个非带权的图 0代表没有边 1代表有边
//边不指向自己 即对角线为0
G->Edge[i][j] = 0;
}
else
{
//如果是带权的图 初始化为0或者为一个不可能的值
G->Edge[i][j] = 65535;
}
}
}
//将顶点存入数组
for(int i = 0; i < G->numV; i++)
{
printf("请输入第%d个节点的信息\n",i + 1);
scanf_s("%d", &G->Vertices[i]);
}
//输入边的信息
for(int i = 0; i< G->numE; i++)
{
//如果输入的是顶点的值 需要从顶点集中查找对应的下标
//如果是带权图 还要输入权的信息
printf("请输入边的信息Vi,Vj\n");
scanf_s("%d%d",&vi,&vj);
G->Edge[vi][vj] = 1;
//如果是带权图 等于权值
//如果是有向图 就不对称
//如果是无向图 矩阵对称
G->Edge[vj][vi] = 1;
}
}
对于邻接矩阵来说如果图的边比较少,那么是空间浪费的,而邻接表弥补了这个缺点
邻接表
数组(顶点集)+链表(边集)的形式
顶点集

#define MAXVEX 100//表示顶点的数目
typedef struct VertexNode
{
//存放信息的值
char data;
//边表的头指针
EdgeNode* first;
}VertexNode;
边集

//边表的结构
typedef struct EdgeNode
{
//邻接的点所对应的下标
int adjvex;
//指向下一个的指针
struct EdgeNode* Next;
//权值
int weight;
}EdgeNode;
还是对这么一个无向图而言
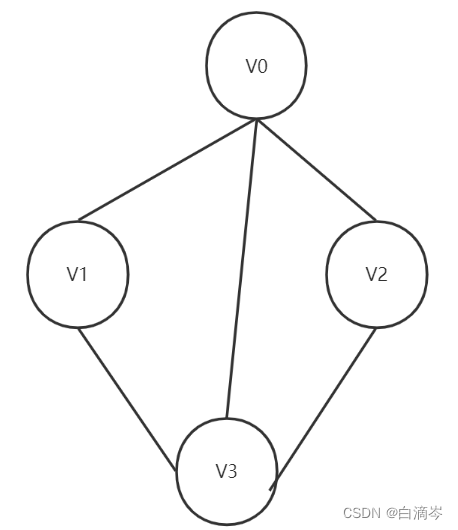
由上述的数组(顶点集)+链表(边集)我们可以画出以下关系图
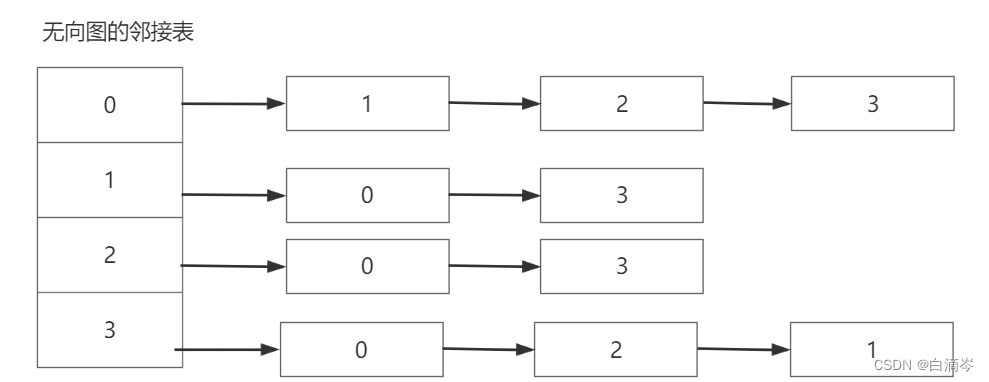
我把第一排单独拿出细说。
从无向图中我们可以看出节点V0与 V1 V2 V3三个节点连通,那么对于V0的顶点集来说,记录的是V0的数据和从V0出发指向其邻接点的指针(因为是无向图所以指针firstarc指向的第一个邻接点 可以是无先后顺序的);
V0的边集应该记录的这个邻接的点所对应的下标、指向下一个邻接点的指针、和权值(这里没有)
那么很容易能得到这张关系图,而其他的节点是一样的

#include<stdio.h>
#include<stdlib.h>
//邻接表
#define MAXVEX 100//表示顶点的数目
//边表的结构
typedef struct EdgeNode
{
//邻接的点所对应的下标
int adjvex;
//指向下一个的指针
struct EdgeNode* Next;
//权值
int weight;
}EdgeNode;
//顶点表的结构
typedef struct VertexNode
{
//存放信息的值
char data;
//边表的头指针
EdgeNode* first;
}VertexNode;
//邻接表的抽象结构
typedef struct
{
//顶点集合数组
VertexNode adjlist[MAXVEX];
//顶点的数量 边的数量
int numV, numE;
}Adjlist;
//以无向图构建邻接表
void creatadjlist(Adjlist* G)
{
printf("输入顶点数和边数\n");
scanf("%d%d", &G->numV, G->numE);
//输入顶点信息
for(int i = 0; i < G->numV; i++)
{
scanf("%c", &G->adjlist[i]);
getchar();//清空缓存区
G->adjlist[i].first = NULL;
}
//输入边的信息
//接收边的顶点偶数对的信息
int vi, vj;
for(int i = 0; i < G->numE; i++)
{
scanf("%d%d", &vi, &vj);
getchar();
EdgeNode* e1 = (EdgeNode*)malloc(sizeof(EdgeNode));
//判断是否创建成功
if(e1 == NULL)
{
printf("MALLOC FAIL\n");
exit(-1);
}
else
{
//头插
//这里的下标 就用vi vj表示
e1->adjvex = vj;
e1->Next = G->adjlist[vi].first;
G->adjlist[vi].first = e1;
//如果是无向图 反向插入一遍
EdgeNode* e2 = (EdgeNode*)malloc(sizeof(EdgeNode));
e2->adjvex = vi;
e2->Next = G->adjlist[vj].first;
G->adjlist[vj].first = e2;
}
}
}
而对于一个有向图而言,有向图的邻接表代表出度,逆邻接表表达入度
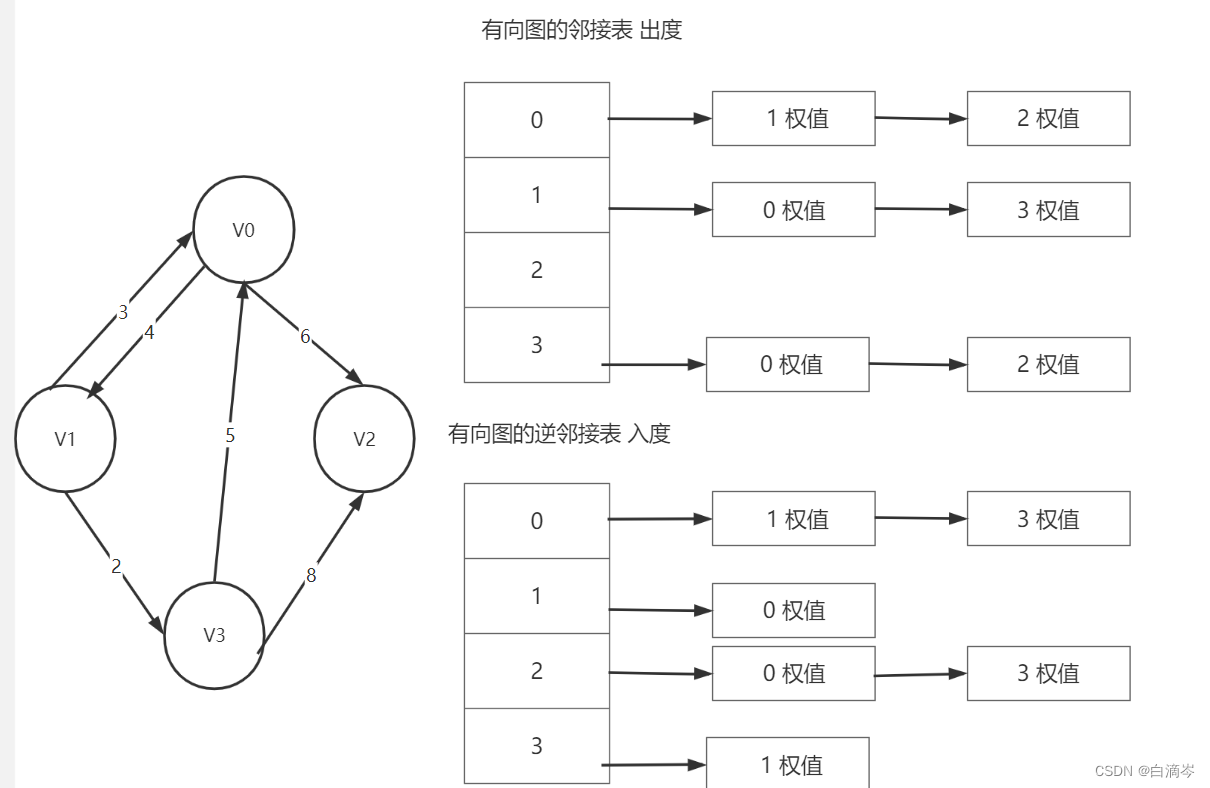
对于带权图一个元素代表出度顶点的下标,另一个元素代表边的权值
二者在代码上与无向图的邻接表没什么大的区别
邻接表可以说解决了邻接矩阵空间浪费的问题,并且邻接表本身并没有什么大的缺陷,如果说有缺点,那么是对于有向图而言对同时表示一个顶点的出度和入度麻烦,因为需要有邻接表和逆邻接表同时表示,那么有没有一种结构能解决这个问题呢?且听下回分解
还是那句话代码仅供参考,不是唯一答案
点向量坐标矩阵的几何意义介绍旋转矩阵的几何含义之前,先介绍一下点向量坐标矩阵的几何含义点:在一维空间下就是一个标量,如同一条直线上,以任意某一个位置为0点,以一定的尺度间隔为1,2,3...,相反方向为-1,-2,-3...;如此就形成了一维坐标系,这时候任何一个点都可以用一个数值表示,如点p1=5,即即从原点出发沿着x轴正方向移动5个尺度;点p2=-3,负方向移动3个尺度; 在一维坐标系上过原点做垂直于一维坐标系的直线,则形成了二维坐标系,此时描述一个点需要两个数值来表示点p3=(3,2),即从原点出发沿着x轴正方向移动3个尺度,在此基础上沿着y轴正方向移动两个尺度的位置就是点p3。
所有题目均有五种语言实现。C实现目录、C++实现目录、Python实现目录、Java实现目录、JavaScript实现目录题目n行m列的矩阵,每个位置上有一个元素你可以上下左右行走,代价是前后两个位置元素值差的绝对值.另外,你最多可以使用一次传送阵(只能从一个数跳到另外一个相同的数)求从走上角走到右下角最少需要多少时间。输入描述:第一行两个整数n,m,分别代表矩阵的行和列。后面n行,每行m个整数,分别代表矩阵中的元素。输出描述:一个整数,表示最少需要多少时间。
一、习惯约定图片来自PSINS(高精度捷联惯导算法)PSINS工具箱入门与详解.pptx二、基本旋转矩阵绕x轴逆时钟旋转α\alphaα角度Rx(α)=[ 1000cosαsinα0−sinαcosα]R_x(\alpha)=\begin{bmatrix}\1&0&0\\0&\cos\alpha&\sin\alpha\\0&-\sin\alpha&\cos\alpha\end{bmatrix}Rx(α)= 1000cosα−sinα0sinαcosα绕y轴逆时钟旋转α\alphaα角度Ry(α)=[ cosα0−sinα010sinα0cosα]R_y(\alpha
欧拉角、旋转矩阵及四元数1.简介2.欧拉角2.1欧拉角定义2.2右手系和左手系2.3转换流程3.旋转矩阵4.四元数4.1四元数与欧拉角和旋转矩阵之间等效变换4.2测试Matlab代码5.总结1.简介常用姿态参数表达方式包括方向余弦矩阵、欧拉轴/角参数、欧拉角、四元数以及罗德里格参数等。高分辨率光学遥感卫星主要采用欧拉角与四元数对姿态参数进行描述。这里着重讲解欧拉角、旋转矩阵和四元数。2.欧拉角2.1欧拉角定义欧拉角是表征刚体旋转的一种方法之一,由莱昂哈德·欧拉引入的三个角度,用于描述刚体相对于固定坐标系的方向。在摄影测量、空间科学或其它技术领域,一般用一组(三个)欧拉角描述两个空间坐标之间的旋
我理解RubystdlibMatrix是不可修改的,也就是说,例如。m=Matrix.zero(3,4)不会写m[0,1]=7但我非常想做...我可以用笨拙的编程来做,比如defmodify_value_in_a_matrix(matrix,row,col,newval)ary=(0...m.row_size).map{|i|m.rowi}.map(&:to_a)ary[row][col]=newvalMatrix[*ary]end...或者作弊,比如Matrix.send:[]=,0,1,7但我想知道,这一定是人们一直遇到的问题。有没有一些标准的、习惯的方法可以做到这一点,而不必使用
快速求三阶矩阵的逆矩阵前言一般情况下,我们求解伴随矩阵是要注意符号问题和位置问题的(如下所示)A−1=1[ ][−[ ]−[ ]−[ ] −[ ]]=A−1=1[ ][ M11−[M12] M13−[M21] M22−[M23] M31−[M32] M33]⊤\begin{aligned}&A^{-1}=\frac{1}{[\\]}\left[\begin{array}{cccccc}&-[\\]&\\-[\\]&&-[\\]\\\\&-[\\]&\\\end{array}\right]=\\\\&A^{-1}=\frac{1}{[\\]}\left[\b
在本文中,我们将探讨摄影机的外参,并通过Python中的一个实践示例来加强我们的理解。相机外参摄像头可以位于世界任何地方,并且可以指向任何方向。我们想从摄像机的角度来观察世界上的物体,这种从世界坐标系到摄像机坐标系的转换被称为摄像机外参。那么,我们怎样才能找到相机外参呢?一旦我们弄清楚相机是如何变换的,我们就可以找到从世界坐标系到相机坐标系的基变换的变化。我们将详细探讨这个想法。具体来说,我们需要知道相机是如何定位的,以及它在世界空间中的位置,有两种转换可以帮助我们:有助于确定摄影机方向的旋转变换。有助于移动相机的平移变换。让我们详细看看每一个。旋转通过旋转改变坐标让我们看一下将点旋转一个角度
为什么Matrix类没有方法来编辑它的向量和组件?似乎矩阵中的所有内容都可以读取但不能写入。我错了吗?是否有一些类似于Matrix的第三方优雅类允许我删除行并有意地编辑它们?如果没有这样的类(class),请通知我——我将停止搜索。 最佳答案 Matrix类的设计者一定是不可变数据结构和函数式编程的爱好者。是的,你是对的。无论如何,总有一个简单的解决方案可以满足您的需求。使用Matrix它可以做的事情,然后,只需使用.to_a来获得一个真正的数组。>>Matrix.identity(2).to_a=>[[1,0],[0,1]]另见N
在Ruby中是否有内置的打印可读矩阵的方法?例如require'matrix'm1=Matrix[[1,2],[3,4]]printm1让它显示=>1234在REPL中代替:=>Matrix[[1,2][3,4]]matrix的Ruby文档让它看起来像应该显示的那样,但这不是我所看到的。我知道编写一个函数来执行此操作是微不足道的,但如果有“正确”的方法,我宁愿学习! 最佳答案 您可以将其转换为数组:m1.to_a.each{|r|putsr.inspect}=>[1,2][3,4]编辑:这是一个“无积分”版本:putsm1.to_a
我正在尝试通过邻接列表构建一个图,这意味着我需要一个包含所有节点的列表,并且在每个节点类中,我还需要一个数据结构来保存所有相邻节点。只是想知道执行此操作的最佳结构是什么(快速搜索目标节点类)。数组行得通吗? 最佳答案 这是在Ruby中构建有向图的一种方法,其中每个节点都维护对其后继节点的引用,但可以通过名称引用节点。首先,我们需要一个节点类:classNodeattr_reader:namedefinitialize(name)@name=name@successors=[]enddefadd_edge(successor)@suc