🐱作者:一只大喵咪1201
🐱专栏:《Linux学习》
🔥格言:你只管努力,剩下的交给时间!
信号
从生活中入手,例如发令枪,闹钟,红绿灯等等,这些都是信号。信号必须都是动态的,像路标就不能称之为信号。
以红绿灯为例,一看到红绿灯我们就知道红灯行,绿灯停,我们不仅能认识它是一个红绿灯,而且还知道应该产生什么样的行为,这样才算是能够识别红绿灯。
- 识别 = 认识 + 行为产生
对于红绿等这个信号,我们需要有如下几个共识:
现在将生活中红绿灯的例子迁移到进程中:
- 共识:信号是发给进程的。
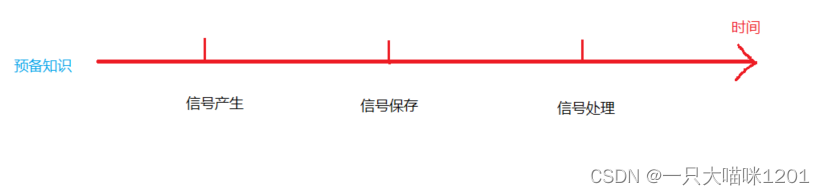
我们学习信号是学习它的整个生命周期,按照时间轴,分为信号产生,信号保存,信号处理。但是在这之前先需要学习一些预备知识。
进程能够识别的信号是已经写好的,它有62个:
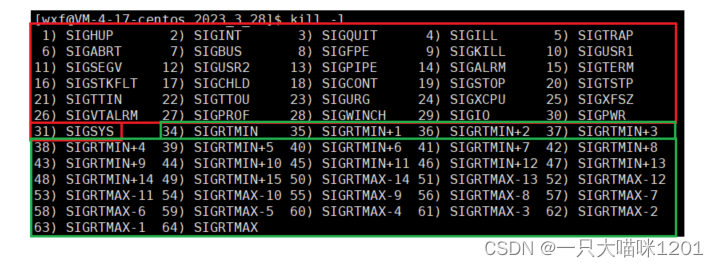
这其中没有32号和33号信号,所以一共有62个信号。而且这里我们只学习普通信号,对实时信号暂不做研究。
- 在使用这些信号时,可以用信号名,也可以用信号编号,它是一样的,都是宏定义后的结果。
根据我们对Linux的了解,信号存放在哪里呢?既然信号是给进程的,而进程是通过内核数据结构来管理的,所以我们可以推断出,信号放在进程的task_struct结构体中。
既然它是在PCB中,而且数量是31个,task_struct中必定不会设置31个变量来存放信号,数组还有可能,但是信号的状态只分为有和没有两种,所以再次推断,31个信号放在一个32位的整形变量中,每个比特位代表一个信号。
本喵写一段伪代码来示意一下:
struct task_struct
{
//进程属性
unsigned int signal;
//.......
}
就像在学习基础IO和进程间通信的时候,那些flags标志中的不同的比特位代表着不同的意义,这31个信号量也是这种方式:

具体的保存细节后面本喵再详细讲解。
问题来了,内核数据结构的修改,这个工作是由谁来完成的?毫无疑问是操作系统,因为task_struct就是它维护的,而且是存在于内存中的,只有操作系统才有权力去修改它,用户是无法直接操作的,因为操作系统不相信任何人。
所以说,无论哪个信号,最后的本质都是由操作系统发生给进程的,这里的发送本质就是在修改task_struct中存放信号那个变量的比特位。
- 信号发送的本质就是在修改PCB中的信号位图。
无论未来我们学习了多少中发送信号的方式,本质都是通过操作系统向目标进程发送信号。
所以操作系统一定会提供相关的系统调用,比如我们之前使用过的各自信号:
kill -9 pid值 //停止某个进程
kill -19 pid值 //暂停某个进程
kill -18 pid值 //继续某个进程
它们的底层一定是在调用相关的系统调用,来让操作系统修改PCB中的信号位图。
- 所谓的注册,就是告诉操作系统,当某个进程接收到某个信号后的处理方式。
既然是告诉操作系统,那么肯定会用到系统调用,该系统调用的名字是signal():
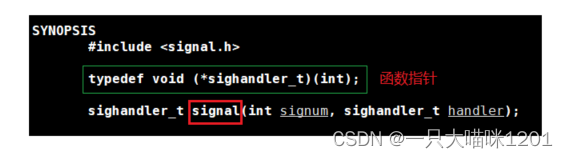
- int signal:要注册的信号编号
- sighandler_t handler:自定义的函数指针
可以将信号的处理方式写成一个函数,然后将函数名传递个signal,此时当进程接收到signum指定的信号编号时,就会执行我们定义的函数。
void handler(int signo)
{
cout<<"进程接收到的一个信号,编号:"<<signo<<endl;
}
函数的返回类型必须是void类型,形参必须是signo类型,名字可以随意。
补充:
我们之前,在shell的命令行中,会按crtl + c 来结束正在运行的进程。这种键我们称为热键。
ctrl + c本质是上一个组合键,操作系统识别到这种组合键后,会将它解释为2号信号SIGINT。

现在将我们自己写的函数注册为2号信号的处理方式。
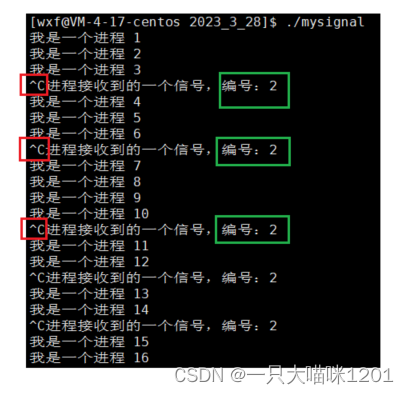
运行起来后发现,按上ctrl+c后,进程不会结束了。
- 所有信号的默认处理方式都是结束进程,只是不同的信号代表的意义不一样。
小实验:
我们将31个信号都自定义处理方式,并且不退出进程,那么这个进程是不是就无法退出了?
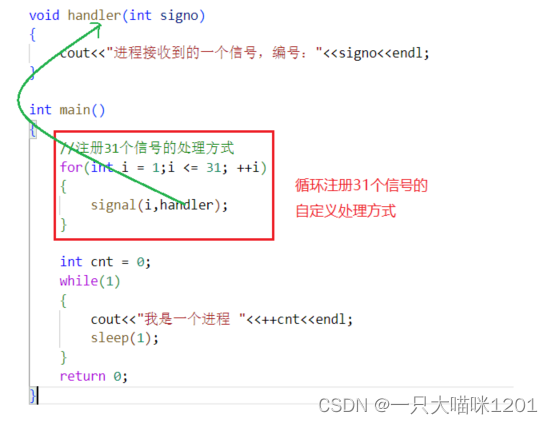
此时31个信号的自定义处理方式中都没有进程退出。
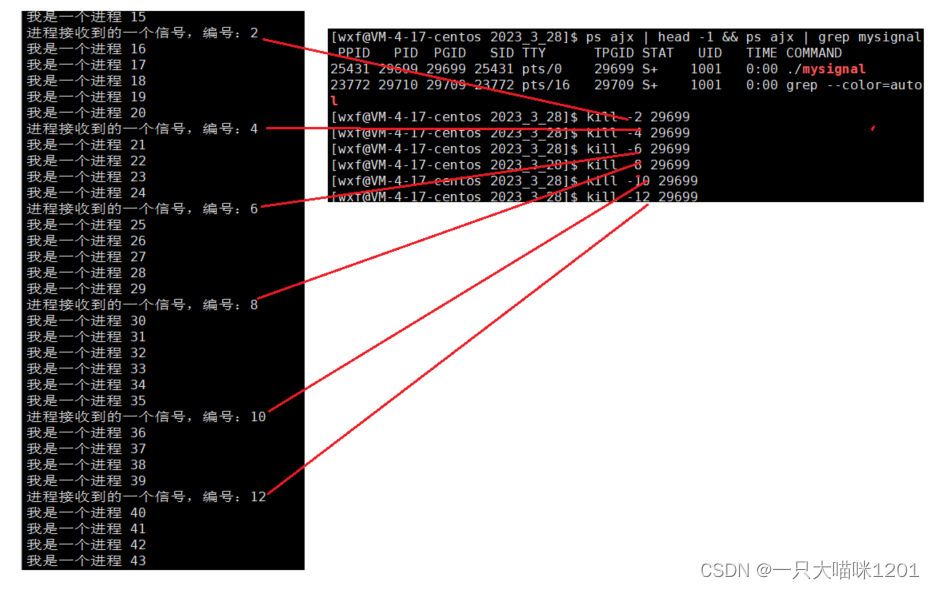
可以看到,给这个进程这么多信号,都没有结束,而且自定义处理方式也执行了,打印出了接收到的信号编号,但是进程还是在执行。
那这样是不是意味着这个进程无法结束了?不是的,操作系统就防着你呢,不会让这种恶意的东西存在的。
- 9号信号SIGKILL是不能够自定义处理方式的,所以该信号能够将这个进程结束掉。
kill -9 pid值//杀死指定进程
该指令可以结束任何进程,这就是操作系统留的后手。
有了上面的预备知识以后,就可以正式来研究信号了。
也就是在键盘上按一些热键,来给进程发送相应的信号,ctrl+c在上面本喵就讲解过了,它产生的是2号信号SIGINT。
还有常用按键ctrl+\,它产生的是3号信号SIGQUIT。
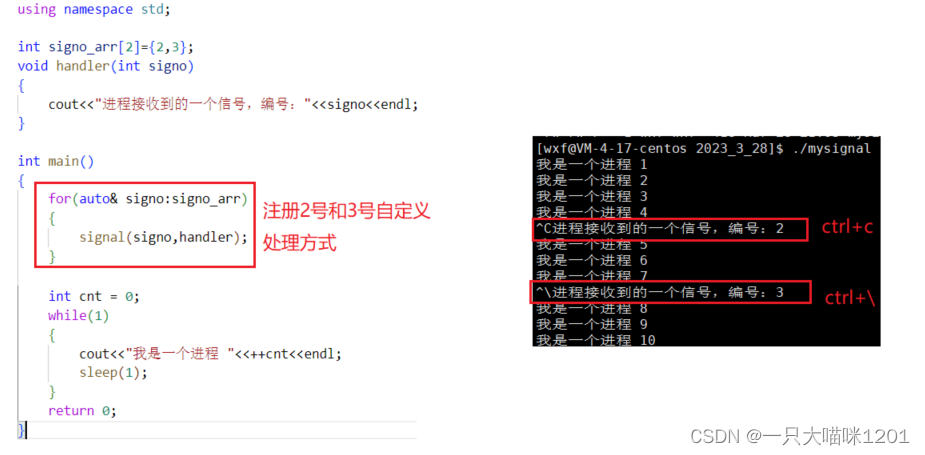
可以看到通过键盘产生了2号和3号信号。
系统调用kill():
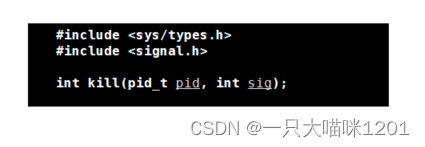
- pid_t pid:要给发信号的pid
- int sig:要发送的信号编号
- 返回值:发送成功返回0,失败返回-1
该系统调用是一个进程给另一个进程发送指定信号,可以向任意进程发送任意信号。
信号接收端:

这是一个一直在运行的程序,用来接收从其他进程发送过来的信号。
信号发送端:
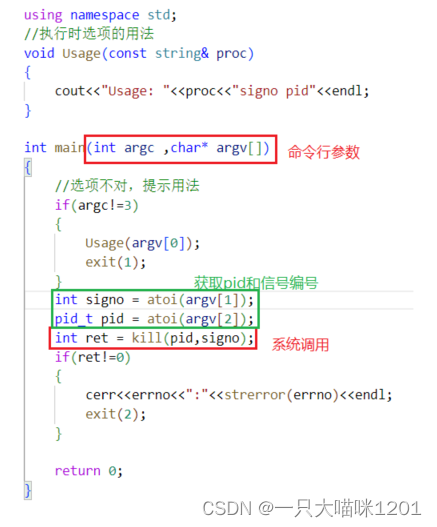
这是一个带有命令行参数的程序,输入的选项中的pid值和信号编号,在程序中在调用kill系统调用向指定pid的进程发送指定信号。
效果:
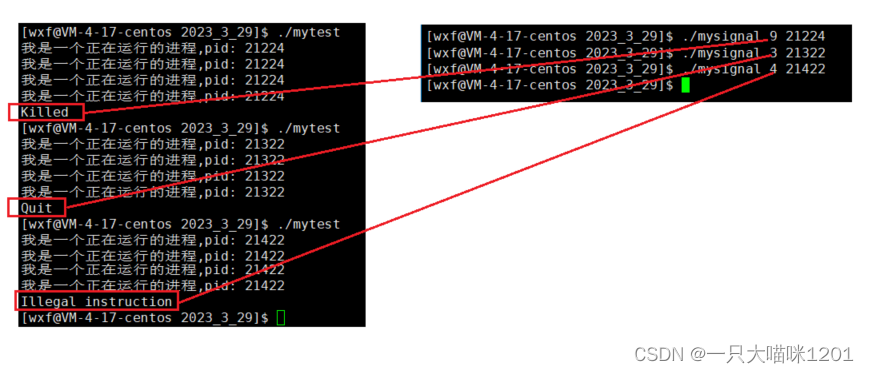
左边在执行mysginal的时候,输入对应的信号编号和pid,右边正在运行的进程就会接收到指定的信号而停止运行。
系统调用raise():
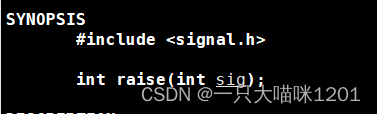
- int sig:要发送的信号
- 返回值:发送成功返回0,失败返回-1
该系统调用是由进程自己调用,也就是进程自己可以给自己发送任意信号。

通过命令行参数指定信号,在程序执行5秒钟后给自己发送该信号。
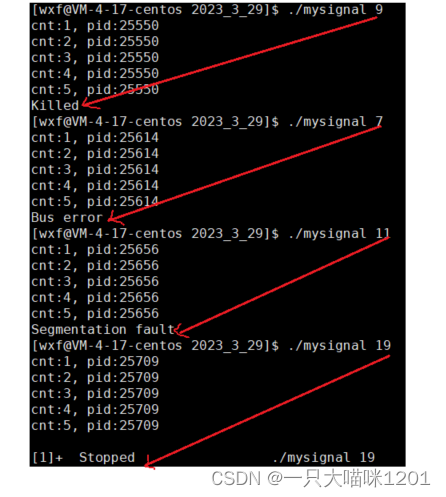
无论命令行输入哪个信号的编号,在5秒钟后,该进程都会给自己发送输入的信号,让进程结束。
系统调用abort():
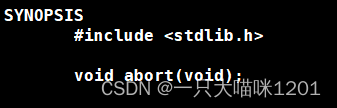
- 没有参数,没有返回值
该系统调用只能给自己发送指定的信号,该信号是SIGABRT,信号编号是6。

5秒钟后给自己发送SIGABRT信号。
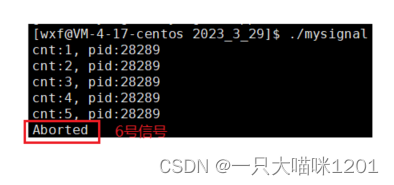
在运行5秒钟后,该进程接收到了6号信号SIGABRT。
虽然有3个系统调用来产生信号,但是归根到底都是在使用kill系统调用。
//raise本质
kill(getpid(),signo);
//abort本质
kill(getpid(),SIGABRT);
除0操作导致的硬件异常:
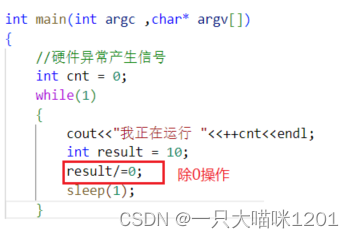
在这段代码中,有除0操作,我们知道,除0得到的是无穷大的数,所以在编程的时候是不允许出现的。
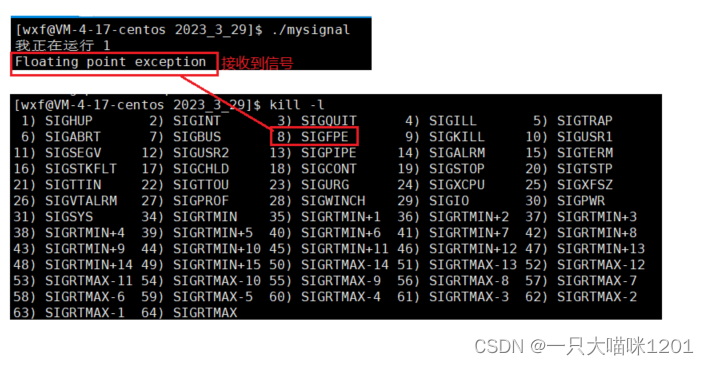
这其实就是一种硬件异常产生的信号。
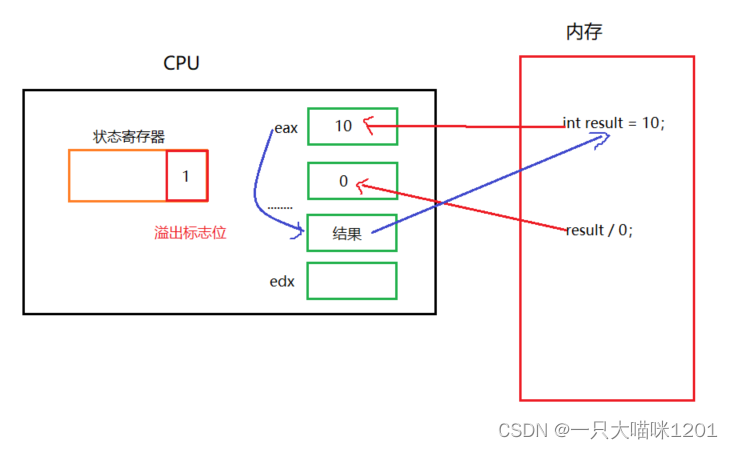
CPU会从内存中将代码中的变量拿到寄存器中进行运算,如果有必要,还会将运算的结果放回到内存中。
此时就意味着硬件产生了异常。而操作系统是一个进行软硬件资源管理的软件,CPU的中状态寄存器的溢出标志位置一后,操作系统可以第一时间拿到。
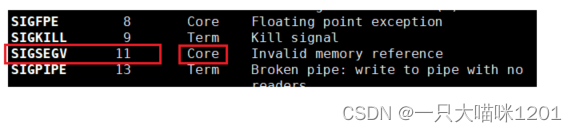
- 除0导致硬件异常以后,操作系统会给对应的进程发送SIGFPE信号。
当进程接收到SIGFPE信号以后,默认的处理方式就是结束进程。
现在我们对这个SIGFPE信号注册一个自定义处理方式:

只打印接收到的信号编号,进程不退出。
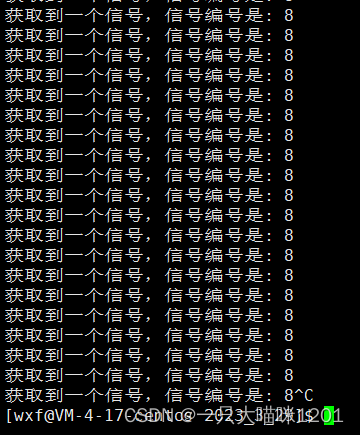
在进程运行起来后,怎么就开始鞭尸了呢?也就是这个信号被操作系统不停的发送给这个进程。
所以就会导致上面不停调用自定义处理函数,不停打印接收到的信号编号。
解引用空指针导致的硬件异常:
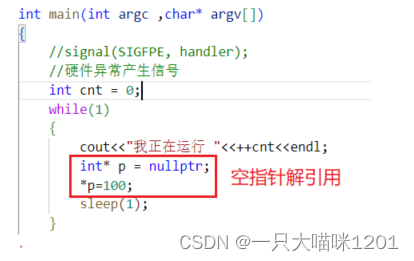
上面代码中存在对空指针的解引用操作,空指针的本质是(void*)0,而0地址处是不允许我们用户进行访问的,这部分属于内核空间。
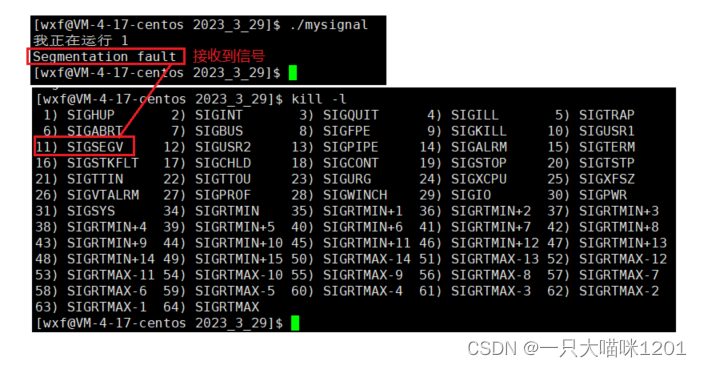
这同样是一种硬件异常产生的信号。
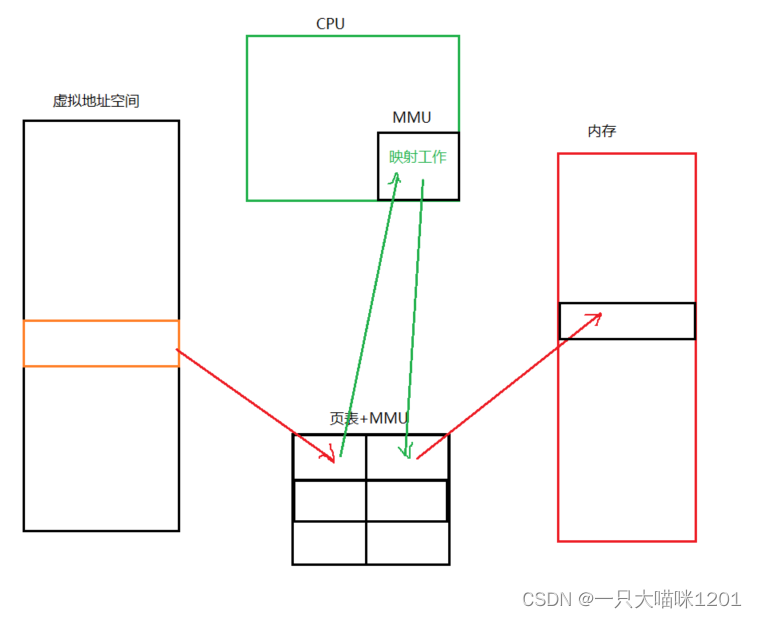
当进程接收到编号为11的SIGSEGV信号以后,默认的处理动作就是结束进程。
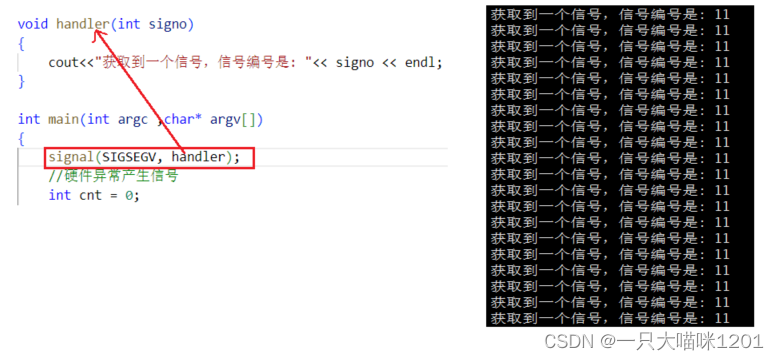
将这个信号注册自定义处理方式,同样打印接收到的信号编号,但是不结束进程,可以看到,和除0操作一样,也是在鞭尸,不停的打印。
- 硬件异常所产生的信号,如果不结束这个进程,我们是没有能力去处理这个进程的。
- 随着时间片的轮转,这个导致硬件异常的进程还会不停的调到,所以操作系统会不停的向进程发送信号。
读端关闭触发的信号:
比如在学习匿名管道的时候,当读端关闭的时候,写端所在进程就会收到编号为13的SIGPIPE信号结束进程。
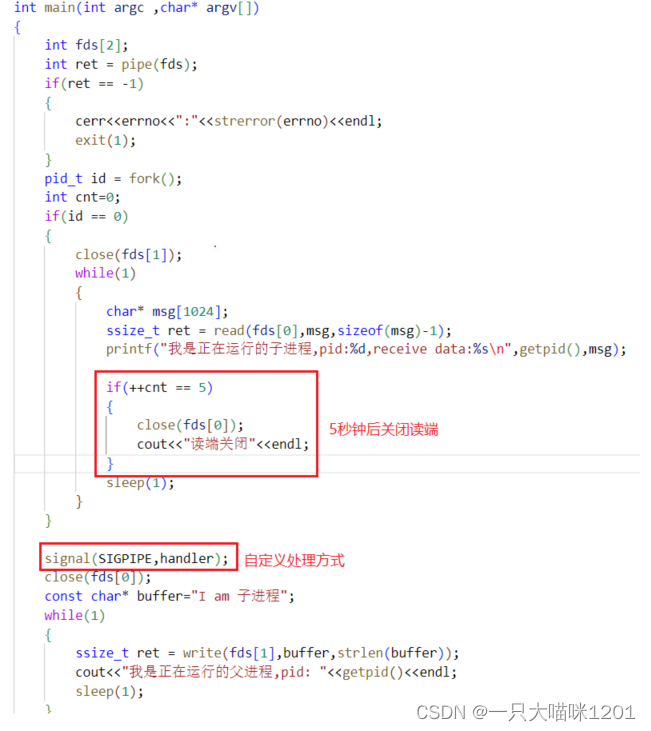
读端5秒钟之后关闭,写端进程注册自定义处理方式,打印写端接收到的信号编号,但是不结束进程。
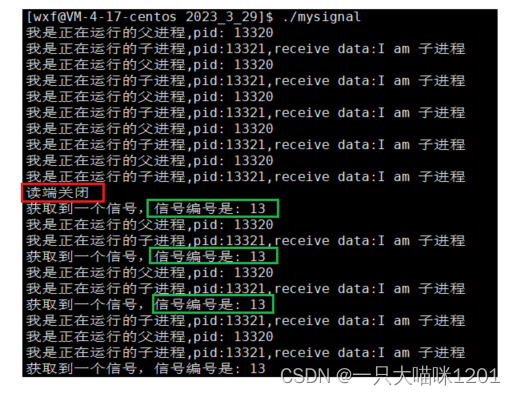
在读端关闭以后,写端的自定义处理方式中就接收到了系统发给的SIGPIPE信号,编号为13。
闹钟触发的信号:
闹钟就是系统中的定时器,使用的时候同样需要通过系统调用实现:

- 参数:要定的时长。
- 返回值:距离定的时间还差多少。

定时1秒钟,在循环中进行疯狂加1,设置自定义处理方式,打印定时到后收到的信号编号,并且统计这一秒中内进行了多少次加1操作。
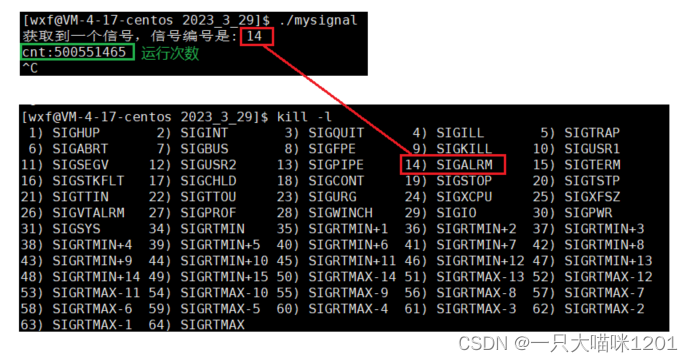
当定时1秒钟时间到了以后,自定义处理方式中打印出接收到的信号编号是14号的SIGALRM信号,并且统计出了1秒钟进行加1操作的次数。
如果想每隔一秒条件达成一次,产生一次SIGALRM信号,可以在这样处理:
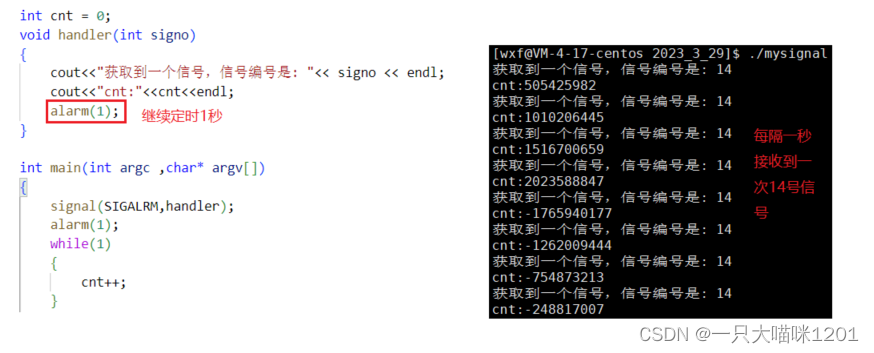
- 软件中某个条件达成以后,操作系统就会产生相应的信号,比如上面的SIGPIPE信号和SIGALRM信号。
闹钟的管理:
操作系统中会有很多个进程,我们可以创建一个闹钟,那么其他进程也可以创建闹钟,这样就会存在很多个闹钟,那么这些闹钟是怎么管理的呢?先描述再组织。
首先需要创建一个闹钟的结构体,伪代码:
struct alarm
{
unit64_t when;//定时时长
int type;//闹钟类型,一次性还是周期性
task_struct* p;//所属进程的地址
struct_alarm* next;//下一个闹钟的地址
//其他属性
}
大概就是这样的一个结构体来描述闹钟,必须由的肯定是定时时长,所属进程。
接下来就是组织了,用某一种数据结构来管理这些闹钟对象,为了方便管理,可以选择优先级队列prority_queuq来管理。
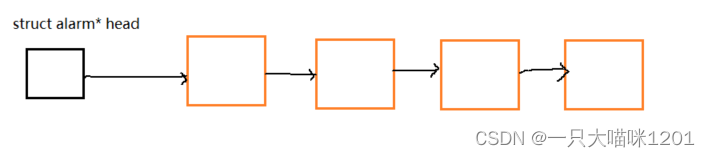
操作系统会周期性的检测链表中的这些闹钟,伪代码:
curr_timestamp > alarm.when;//超时了
//OS发送SIGALRM信号到alarm.p;
具体的实现细节有兴趣的小伙伴可以看看源码是怎么管理的,这里本喵只是介绍一种思想。
是否有一个疑问,31个信号的默认处理方式都是结束进程,并且还可以自定义处理方式,那么为什么要这么多信号呢?一个信号不就行了吗?
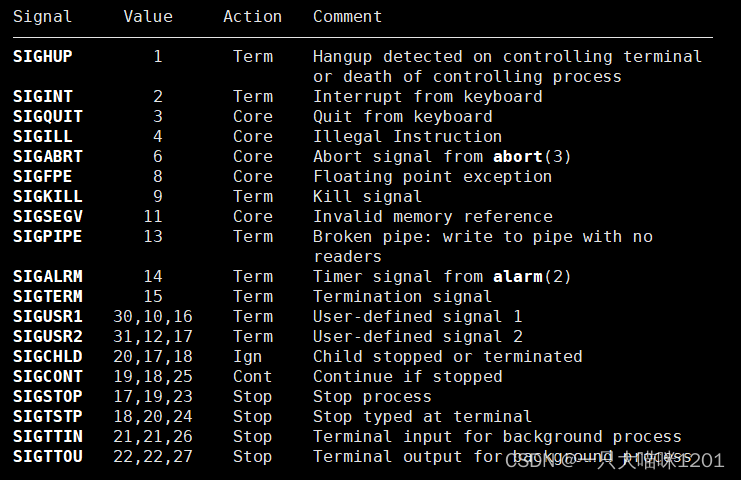
在man的7号手册中介绍了信号的名称,对应的编号,默认处理方式,以及产生该信号的原因。
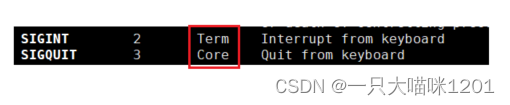
以信号2和3为例,他两的默认处理方式一个是Term,一个是Core。
那么这两个方式的区别在哪里呢?
- Term方式仅仅是结束进程,结束了以后就什么都不干了。
- 但是Core不仅结束进程,而且还会保存一些信息。
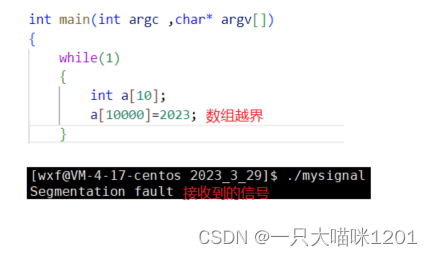
在数据越界非常严重的时候,该进程会接收到SIGSEGV信号,来结束进程。
在云服务器上,默认情况下是看不到Core退出的现象的,这是因为云服务器关闭了core file选项:
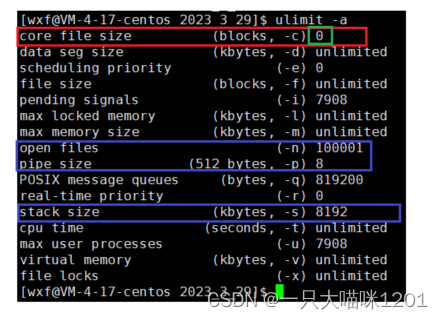
- 从这里还可以看到别的关于这个云服务器的信息,比如能够打开的最多文件个数,管道个数,以及栈的大小等等信息。
为了能够看到Core方式的明显现象,我们需要将core file选项打开:
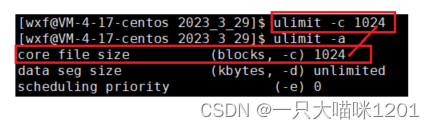
此时该选项就打开了,表示的意思就是核心转储文件的大小是1024个数据块。
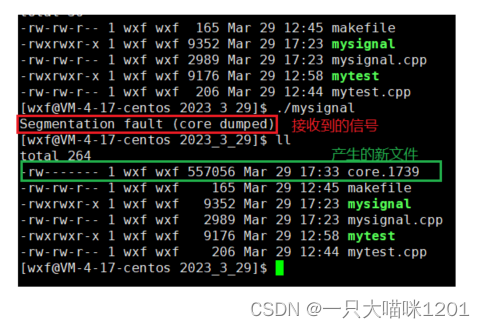
- core.1739:被叫做核心转储文件,其中后缀1739是接收到该信号进程的pid值。
对于一个奔溃的程序,我们最关心的是它为什么崩溃,在哪里崩溃?
- 核心转储的文件我们可以拿着它进行调试,快速定位到出现异常而崩溃的位置。
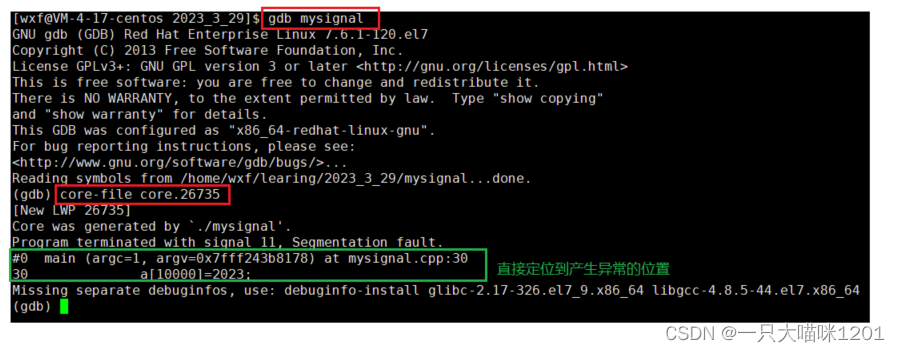
这就是核心转储的重要意义,它相比Term方式,能够让我们快速定位出现异常的位置。
篇幅有限,下篇文章再接着介绍。
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。我最近开始学习Ruby,这是我的第一门编程语言。我对语法感到满意,并且我已经完成了许多只教授相同基础知识的教程。我已经写了一些小程序(包括我自己的数组排序方法,在有人告诉我谷歌“冒泡排序”之前我认为它非常聪明),但我觉得我需要尝试更大更难的东西来理解更多关于Ruby.关于如何执行此操作的任何想法?
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
文章目录1、自相关函数ACF2、偏自相关函数PACF3、ARIMA(p,d,q)的阶数判断4、代码实现1、引入所需依赖2、数据读取与处理3、一阶差分与绘图4、ACF5、PACF1、自相关函数ACF自相关函数反映了同一序列在不同时序的取值之间的相关性。公式:ACF(k)=ρk=Cov(yt,yt−k)Var(yt)ACF(k)=\rho_{k}=\frac{Cov(y_{t},y_{t-k})}{Var(y_{t})}ACF(k)=ρk=Var(yt)Cov(yt,yt−k)其中分子用于求协方差矩阵,分母用于计算样本方差。求出的ACF值为[-1,1]。但对于一个平稳的AR模型,求出其滞
写在之前Shader变体、Shader属性定义技巧、自定义材质面板,这三个知识点任何一个单拿出来都是一套知识体系,不能一概而论,本文章目的在于将学习和实际工作中遇见的问题进行总结,类似于网络笔记之用,方便后续回顾查看,如有以偏概全、不祥不尽之处,还望海涵。1、Shader变体先看一段代码......Properties{ [KeywordEnum(on,off)]USL_USE_COL("IsUseColorMixTex?",int)=0 [Toggle(IS_RED_ON)]_IsRed("IsRed?",int)=0}......//中间省略,后续会有完整代码 #pragmamulti_c
目录一、inout在设计文件中的使用方法1.1、inout的第一种使用方法1.2、inout实现的第二种使用方法1.3、inout使用总结 二、inout在仿真测试中的使用方法一、inout在设计文件中的使用方法在FPGA的设计过程中,有时候会遇到双向信号(既能作为输出,也能作为输入的信号叫双向信号)。比如,IIC总线中的SDA信号就是一个双向信号,QSPIFlash的四线操作的时候四根信号线均为双向信号。在Verilog中用关键字inout定义双向信号,这里总结一下双向信号的处理方法。1.1、inout的第一种使用方法 实际上,双向信号的本质是由一个三态门组成的,三态门可以输出高电平,低电
