译者 | 布加迪
审校 | 孙淑娟
过去十年是深度学习的时代。我们为从AlphaGo到DELL-E 2的一系列重大事件而激动不已。日常生活中出现了不计其数的由人工智能(AI)驱动的产品或服务,包括Alexa设备、广告推荐、仓库机器人和自动驾驶汽车等。

近年来,深度学习模型的规模呈指数级增长。这不是什么新闻了:Wu Dao 2.0模型含有1.75万亿参数,在SageMaker训练平台的240个ml.p4d.24xlarge实例上训练GPT-3大约只需25天。
但随着深度学习训练和部署的发展,它变得越来越具有挑战性。由于深度学习模型的发展,可扩展性和效率是训练和部署面临的两大挑战。
本文将总结机器学习(ML)加速器的五大类型。
在全面介绍ML加速器之前,不妨先看看ML生命周期。
ML生命周期是数据和模型的生命周期。数据可谓是ML的根源,决定着模型的质量。生命周期中的每个方面都有机会加速。
MLOps可以使ML模型部署的过程实现自动化。但由于操作性质,它局限于AI工作流的横向过程,无法从根本上改善训练和部署。
AI工程远超MLOps的范畴,它可以整体(横向和纵向)设计机器学习工作流的过程以及训练和部署的架构。此外,它可以通过整个ML生命周期的有效编排来加速部署和训练。
基于整体式ML生命周期和AI工程,有五种主要类型的ML加速器(或加速方面):硬件加速器、AI计算平台、AI框架、ML编译器和云服务。先看下面的关系图。
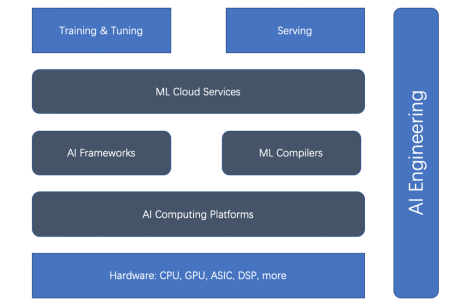
图1. 训练与部署加速器的关系
我们可以看到,硬件加速器和AI框架是加速的主流。但最近,ML编译器、AI计算平台和ML云服务已变得越来越重要。
下面逐一介绍。
在谈到加速ML训练和部署时,选择合适的AI框架无法回避。遗憾的是,不存在一应俱全的完美或最佳AI框架。广泛用于研究和生产的三种AI框架是TensorFlow、PyTorch和JAX。它们在不同的方面各有千秋,比如易用性、产品成熟度和可扩展性。
TensorFlow:TensorFlow是旗舰AI框架。TensorFlow一开始就主导深度学习开源社区。TensorFlow Serving是一个定义完备的成熟平台。对于互联网和物联网来说,TensorFlow.js和TensorFlow Lite也已成熟。
但由于深度学习早期探索的局限性,TensorFlow 1.x旨在以一种非Python的方式构建静态图。这成为使用“eager”模式进行即时评估的障碍,这种模式让PyTorch可以在研究领域迅速提升。TensorFlow 2.x试图迎头赶上,但遗憾的是,从TensorFlow 1.x升级到2.x很麻烦。
TensorFlow还引入了Keras,以便总体上更易使用,另引入了优化编译器的XLA(加速线性代数),以加快底层速度。
PyTorch:凭借其eager模式和类似Python的方法,PyTorch是如今深度学习界的主力军,用于从研究到生产的各个领域。除了TorchServe外,PyTorch还与跟框架无关的平台(比如Kubeflow)集成。此外,PyTorch的人气与Hugging Face的Transformers库大获成功密不可分。
JAX:谷歌推出了JAX,基于设备加速的NumPy和JIT。正如PyTorch几年前所做的那样,它是一种更原生的深度学习框架,在研究领域迅速受到追捧。但它还不是谷歌声称的“官方”谷歌产品。
毫无疑问,英伟达的GPU 可以加速深度学习训练,不过它最初是为视频卡设计的。
通用GPU出现后,用于神经网络训练的图形卡人气爆棚。这些通用GPU可以执行任意代码,不仅仅是渲染子例程。英伟达的CUDA编程语言提供了一种用类似C的语言编写任意代码的方法。通用GPU有相对方便的编程模型、大规模并行机制和高内存带宽,现在为神经网络编程提供了一种理想的平台。
如今,英伟达支持从桌面到移动、工作站、移动工作站、游戏机和数据中心的一系列GPU。
随着英伟达GPU大获成功,一路走来不乏后继者,比如AMD的GPU和谷歌的TPU ASIC等。
如前所述,ML训练和部署的速度很大程度上依赖硬件(比如GPU和TPU)。这些驱动平台(即AI计算平台)对性能至关重要。有两个众所周知的AI计算平台:CUDA和OpenCL。
CUDA:CUDA(计算统一设备架构)是英伟达于2007年发布的并行编程范式。它是为图形处理器和GPU的众多通用应用设计的。CUDA是专有API,仅支持英伟达的Tesla架构GPU。CUDA支持的显卡包括GeForce 8系列、Tesla和Quadro。
OpenCL:OpenCL(开放计算语言)最初由苹果公司开发,现由Khronos团队维护,用于异构计算,包括CPU、GPU、DSP及其他类型的处理器。这种可移植语言的适应性足够强,可以让每个硬件平台实现高性能,包括英伟达的GPU。
英伟达现在符合OpenCL 3.0,可用于R465及更高版本的驱动程序。使用OpenCL API,人们可以在GPU上启动使用C编程语言的有限子集编写的计算内核。
ML编译器在加速训练和部署方面起着至关重要的作用。ML编译器可显著提高大规模模型部署的效率。有很多流行的编译器,比如Apache TVM、LLVM、谷歌MLIR、TensorFlow XLA、Meta Glow、PyTorch nvFuser和Intel PlaidML。
ML云平台和服务在云端管理ML平台。它们可以通过几种方式来优化,以提高效率。
以Amazon SageMaker为例。这是一种领先的ML云平台服务。SageMaker为ML生命周期提供了广泛的功能特性:从准备、构建、训练/调优到部署/管理,不一而足。
它优化了许多方面以提高训练和部署效率,比如GPU上的多模型端点、使用异构集群的经济高效的训练,以及适合基于CPU的ML推理的专有Graviton处理器。
随着深度学习训练和部署规模不断扩大,挑战性也越来越大。提高深度学习训练和部署的效率很复杂。基于ML生命周期,有五个方面可以加速ML训练和部署:AI框架、硬件加速器、计算平台、ML编译器和云服务。AI工程可以将所有这些协调起来,利用工程原理全面提高效率。
原文标题:5 Types of ML Accelerators,作者:Luhui Hu
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
require"socket"server="irc.rizon.net"port="6667"nick="RubyIRCBot"channel="#0x40"s=TCPSocket.open(server,port)s.print("USERTesting",0)s.print("NICK#{nick}",0)s.print("JOIN#{channel}",0)这个IRC机器人没有连接到IRC服务器,我做错了什么? 最佳答案 失败并显示此消息::irc.shakeababy.net461*USER:Notenoughparame
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
文章目录1、自相关函数ACF2、偏自相关函数PACF3、ARIMA(p,d,q)的阶数判断4、代码实现1、引入所需依赖2、数据读取与处理3、一阶差分与绘图4、ACF5、PACF1、自相关函数ACF自相关函数反映了同一序列在不同时序的取值之间的相关性。公式:ACF(k)=ρk=Cov(yt,yt−k)Var(yt)ACF(k)=\rho_{k}=\frac{Cov(y_{t},y_{t-k})}{Var(y_{t})}ACF(k)=ρk=Var(yt)Cov(yt,yt−k)其中分子用于求协方差矩阵,分母用于计算样本方差。求出的ACF值为[-1,1]。但对于一个平稳的AR模型,求出其滞
目录0专栏介绍1平面2R机器人概述2运动学建模2.1正运动学模型2.2逆运动学模型2.3机器人运动学仿真3动力学建模3.1计算动能3.2势能计算与动力学方程3.3动力学仿真0专栏介绍?附C++/Python/Matlab全套代码?课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等);局部规划(DWA、APF等);曲线优化(贝塞尔曲线、B样条曲线等)。?详情:图解自动驾驶中的运动规划(MotionPlanning),附几十种规划算法1平面2R机器人概述如图1所示为本文的研究本体——平面2R机器人。对参数进行如下定义:机器人广义坐标