都学了递归版的快速排序为何还要再学非递归实现?由于在递归过程中,如果数据量过大,那么实现时容易导致栈溢出,虽然代码没有问题,但是就是会崩,因此要将其改为非递归来实现
文章目录
如何做到将递归算法改为非递归算法?
简单的递归可以直接将其改为循环(如斐波那契),但是如果是复杂的递归算法,再直接改为循环十分复杂,而一般选用栈辅助将其改为非递归
再来回顾一下快速排序的思想。
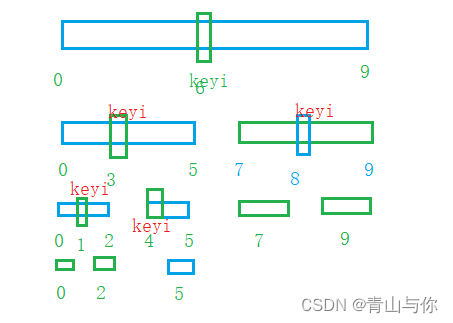
思想:在区间范围内选出一个关键字,经过单趟排序之后关键字位置左边的数据全小于或者等于它,关键字右边的数据全大于或者等于它。一趟排序将这个关键字排好了,同样也分隔出了它的左区间和右区间,再以同样的方法排它的左区间和右区间,直至区间范围为1或者不存在为止
而递归实现快速排序是每次控制的是区间,每次递归调用栈都是将区间压栈,每递归一次,区间都在变化。因此用栈实现快速排序时,入栈的是区间,而由于每次递归都是先排的左区间,而栈是一种后进先出的数据结构,所以在将区间入栈时要先将右区间压栈,然后再将左区间压栈,保证每次单趟排先将左区间排好再排右区间
单趟排。排出keyi此时分隔出keyi的左右区间,然后把他的左、右区间压栈,此时又对它的左右区间进行单趟排,排出keyi,分隔左右区间,每次单趟排完后会分隔出左右区间,然后左右区间入栈,直至最后区间为1或者不存在时,就不用再入栈了。总体是:
从栈中取一段区间,进行单趟排。单趟排序后分隔子区间(左、右区间)入栈。子区间只有一个值或者不存在就不入栈了
每一次单趟排是如何排的,这里用前后指针法实现,每次单趟排好后,返回关键字所在下标
那么用栈辅助改递归,这个栈从和而来,我这里是以前写好了,保存下来的,在vs中只需要选中源文件
然后点击鼠标右键找到
找到以前保存栈实现的文件,将其拷贝
之后再点击源文件
再点击

以前是新建但是现在是点击现有,然后找到当前程序所在目录,将刚才拷贝的栈实现的文件拷贝到当前程序中即可。
前后指针法排单趟
//前后指针法
int QuickSort3(int* a, int left, int right)
{
int begin = left;
int end = right;
//随机选数,主要针对已经有序的情况,提高性能
int randi = left + (rand() % (right - left));
if (randi != left)
{
Swap(&a[randi], &a[left]);
}
int key = left;
int cur = left + 1;
int prev = left;
while (cur <= right)
{
if (a[cur] < a[key] && ++prev != cur)
{
Swap(&a[cur], &a[prev]);
}
cur++;
}
Swap(&a[key], &a[prev]);
key = prev;
return key;
}
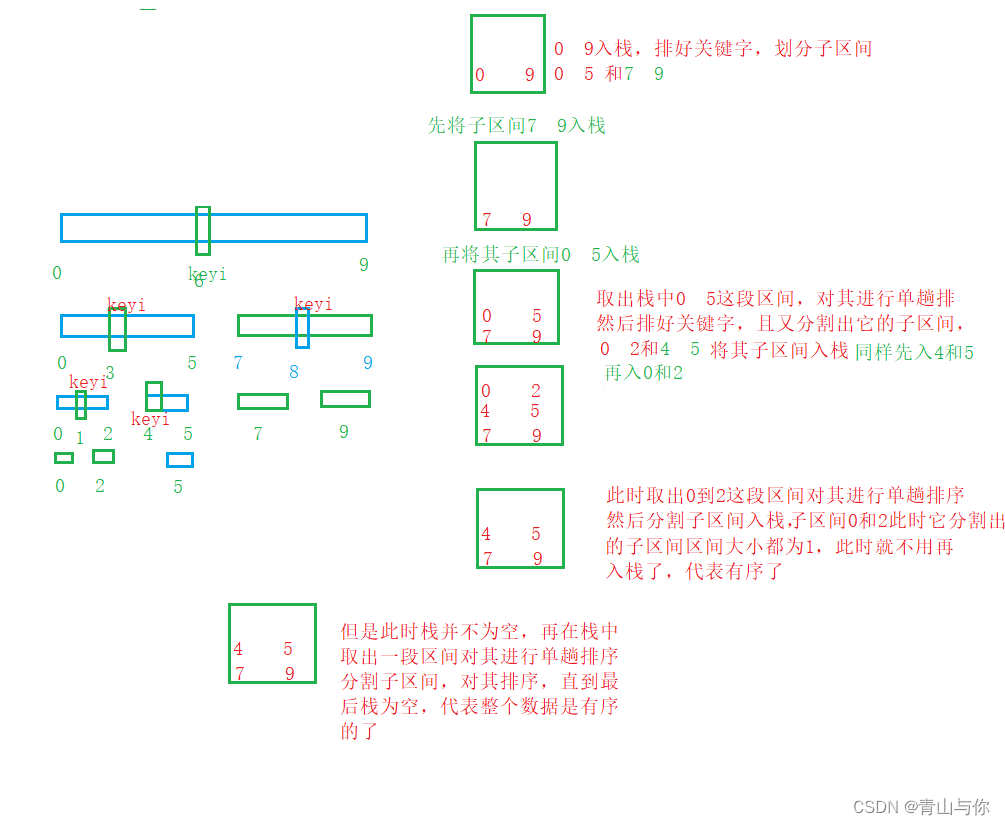
//取区间入栈然后对其单趟排,单趟排好keyi之后分割出它的子区间,将分割出的子区间入栈,再进行单趟排,再分割子区间入栈,每次单趟排排好一个数,直至区间范围为一或者不存在
//
void QuicksortNone(int* a, int begin, int end)
{
St st;
STInit(&st);
STPush(&st, end);
STPush(&st, begin);
while (!STEmpty(&st))
{
int begin1 = STTop(&st);
STPop(&st);
int end1 = STTop(&st);
STPop(&st);
int keyi = QuickSort3(a, begin1, end1);
if (keyi + 1 < end1)
{
STPush(&st, end1);
STPush(&st, keyi+1);
}
if (keyi > begin1)
{
STPush(&st, keyi - 1);
STPush(&st, begin1);
}
}
STDestroy(&st);
}
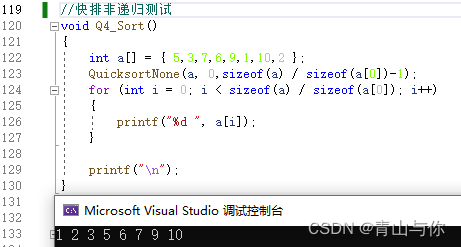
非递归快速排序时间复杂度O(nlogn),空间复杂度o(1)
适用于数组存在大量重复数据且最大值和最小值之差不是特别大的情况
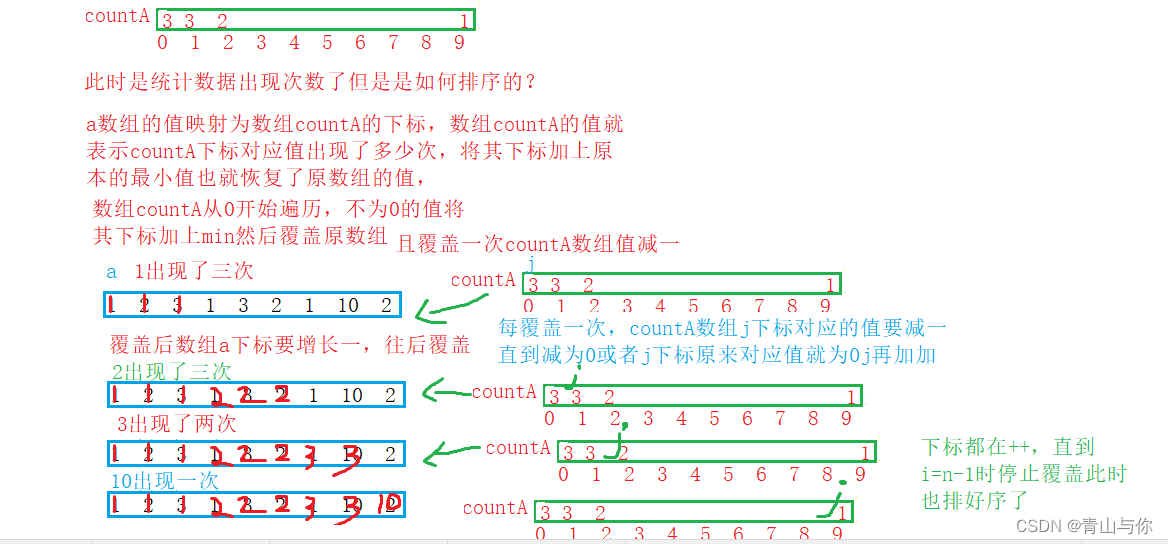
思想:统计数组中每个数据出现的次数,怎么统计?用一个新数组存储原数组数据出现的次数 。 这个数组如何来?当然是向内存动态申请开辟
新数组开辟多大空间合适?
由于存的是原数组数据出现次数,那么只需要数组数据值出现一次,那么它对应值作为下标的值就加一(开辟的数组内容全部初始化为0)
只要数组中的值出现一次,那么它对应的值作为新数组下标所对应的值就加一,那么新数组范围如何确定?
其实也就是原数组最大值与最小值之差,由于用原数组值作为下标 所以先遍历一遍找出数组中的最大值和最小值,这时确定新数组开辟大小
由于存储从0开始,所以需要原数组值减去它的最小值 最后将新开辟数组的下标再加上原数组最小值就可以直接覆盖原数组,如何覆盖的?
void CountSort(int* a, int n)
{
int max = a[0], min = a[0];
for (int i = 1; i < n; i++)
{
if (a[i] > max)
{
max = a[i];
}
if (a[i] < min)
{
min = a[i];
}
}
int range = max - min + 1;//要包含0,所以这个存储数组大小要开最大值和最小值之差再加一
//开一个数组用来统计数组数据出现的次数
int* countA = (int*)malloc(sizeof(int) * range);
if (countA == NULL)
{
perror("ocuntA fail\n");
return;
}
//将新开的这个数组内容全部都初始化为0
//由于它存储的内容是原数组数据出现的次数
memset(countA, 0, sizeof(int) * range);//c语言内置库函数将每个字节都初始化为0
//以原数组中的数据作为新开数组的下标,然后统计它出现的次数
//由于原数组最小值很可能不是从0开始
//而新数组要从0开始存储
//所以新数组下标是a[i] - min这个表达式
for (int i = 0; i < n; i++)
{
//将原数组内容它对应的数字为countA下标加加,即数组对应数据在数组中出现的次数
countA[a[i]-min]++;
}
int j = 0;
for (int i = 0; i < n; )//i<n后面的调整不可再加,原因是下面加了,如果再加会造成越界
{
//可以在这里做出调整,将其i--,但是这里多此一举
while (countA[j]--)
{
a[i++] = j + min;
}
j++;
}
free(countA);
}

计数排序时间复杂度为O(n+range)当range<n时,时间复杂度为O(n),空间复杂度为O(range),但是它的条件十分苛刻,需要很多重复数据且这些数据最大值和最小值之差不可过大,所以在现实生活中很少用到,但是在有些场景下会用到,所以还是值得一学,毕竟时间复杂度为线性的嘛。
尝试在我的RoR应用程序中实现计数器缓存列时出现错误Unknownkey(s):counter_cache。我在这个问题中实现了模型关联:Modelassociationquestion这是我的迁移:classAddVideoVotesCountToVideos0Video.reset_column_informationVideo.find(:all).eachdo|p|p.update_attributes:videos_votes_count,p.video_votes.lengthendenddefself.downremove_column:videos,:video_vot
我正在尝试按0-9和a-z的顺序创建数字和字母列表。我有一组值value_array=['0','1','2','3','4','5','6','7','8','9','a','b','光盘','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','','u','v','w','x','y','z']和一个组合列表的数组,按顺序,这些数字可以产生x个字符,比方说三个list_array=[]和一个当前字母和数字组合的数组(在将它插入列表数组之前我会把它变成一个字符串,]current_combo['0','0','0']
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
我需要用任何语言编写一个算法,根据3个因素对数组进行排序。我以度假村为例(如Hipmunk)。假设我想去度假。我想要最便宜的地方、最好的评论和最多的景点。但是,显然我找不到在所有3个中都排名第一的方法。Example(assumingthereare20importantattractions):ResortA:$150/night...98/100infavorablereviews...18of20attractionsResortB:$99/night...85/100infavorablereviews...12of20attractionsResortC:$120/night
我正在尝试按Rails相关模型中的字段进行排序。我研究的所有解决方案都没有解决如果相关模型被另一个参数过滤?元素模型classItem相关模型:classPriority我正在使用where子句检索项目:@items=Item.where('company_id=?andapproved=?',@company.id,true).all我需要按相关表格中的“位置”列进行排序。问题在于,在优先级模型中,一个项目可能会被多家公司列出。因此,这些职位取决于他们拥有的company_id。当我显示项目时,它是针对一个公司的,按公司内的职位排序。完成此任务的正确方法是什么?感谢您的帮助。PS-我
我正在构建一个小部件来显示奥运会的奖牌数。我有一个“国家”对象的集合,其中每个对象都有一个“名称”属性,以及奖牌计数的“金”、“银”、“铜”。列表应该排序:1.首先是奖牌总数2.如果奖牌相同,按类型分割(金>银>铜,即2金>1金+1银)3.如果奖牌和类型相同,则按字母顺序子排序我正在用ruby做这件事,但我想语言并不重要。我确实找到了一个解决方案,但如果感觉必须有更优雅的方法来实现它。这是我做的:使用加权奖牌总数创建一个虚拟属性。因此,如果他们有2个金牌和1个银牌,加权总数将为“3.020100”。1金1银1铜为“3.010101”由于我们希望将奖牌数排序为最高的,因此列表按降序排
我有一个随机大小的散列,它可能有类似"100"的值,我想将其转换为整数。我知道我可以使用value.to_iifvalue.to_i.to_s==value来做到这一点,但我不确定我将如何在我的散列中递归地做到这一点,考虑到一个值可以是一个字符串,或一个数组(哈希或字符串),或另一个哈希。 最佳答案 这是一个非常简单的递归实现(尽管必须同时处理数组和散列会增加一些技巧)。deffixnumifyobjifobj.respond_to?:to_i#IfwecancastittoaFixnum,doit.obj.to_ielsifobj
我经常迷上ruby的一件事是递归模式。例如,假设我有一个数组,它可能包含无限深度的数组作为元素。所以,例如:my_array=[1,[2,3,[4,5,[6,7]]]]我想创建一个方法,可以将数组展平为[1,2,3,4,5,6,7]。我知道.flatten可以完成这项工作,但这个问题是作为我经常遇到的递归问题的一个例子-因此我试图找到一个更可重用的解决方案。简而言之-我猜这种事情有一个标准模式,但我想不出任何特别优雅的东西。任何想法表示赞赏 最佳答案 递归是一种方法,它不依赖于语言。您在编写算法时要考虑两种情况:再次调用函数的情
我有一个数组:array=['Footballs','Baseball','football','Soccer']而且我需要计算看到Football或Baseball的次数,无论大小写和复数形式如何。这是我尝试做的,但没有成功:array.count{|x|x.downcase.include?'football'||x.downcase.include?'baseball'}编写这段代码的正确或更好的方法是什么?我正在寻找3作为答案。 最佳答案 我会将count与一个block结合使用,该block根据与您正在寻找的约束相匹配的正
例如,假设我有一个名为Products的模型,并且在ProductsController中,我有以下代码用于product_listView以显示已排序的产品。@products=Product.order(params[:order_by])让我们想象一下,在product_listView中,用户可以使用下拉菜单按价格、评级、重量等进行排序。数据库中的产品不会经常更改。我很难理解的是,每次用户选择新的order_by过滤器时,rails是否必须查询,或者rails是否能够以某种方式缓存事件记录以在服务器端重新排序?有没有一种方法可以编写它,以便在用户排序时rails不会重新查询结果