------
### 2.1 数据集包含 1000 个样本, 其中 500 个正例、500 个反例, 将其划分为包含 70% 样本的训练集和 30% 样本的测试集用于留出法评估, 试估算共有多少种划分方式。
1. 共有1000个样本,训练集70%则有700个样本,测试集则有300个样本
2. 算一下训练集和测试集中分别包含多少个正例、多少个反例。设训练集包含正例$x$个,则测试集包含正例$500-x$,设训练集包含反例$y$个,则测试集包含反例$500-y$个样本,得出方程组:
$$
\begin{cases}
x+y=700 \ (训练集正反例样本共700个) \\
{x \over y}={{500-x} \over {500-y}} \ (分层采样,数据分布一致)
\end{cases}
$$
易得$x=y=350$
3. 划分方式共有$C_{500}^{350} \times C_{500}^{350}$ 或者 $C_{500}^{150} \times C_{500}^{150}$。两式在数学运算上相等,第一个表示从500个正例中随机取350个正例,依次取两次;第二个表示从500个反例中随机取150个反例,取两次。
根据题意(学习算法所产生的模型是将新样本预测为训练样本数较多的类别),分别产生正例模型、反例模型,同测试集全部相反。故其\(错误率=100\%\)
\({1 \over F1}={1\over 2}\times({{1\over P}+{1\over R}})\)
\(BEP为P=R时,P或R的值\)
若\(F1_A>F1_B\),则\(({{1\over P_A}+{1\over R_A}})<({{1\over P_B}+{1\over R_B}})\)
又因为\(BEP_A=P_A=R_A,BEP_B=P_B=R_B\)
若\(F1\)中\(P=R\), 则\({{{2}\over{BEP_A}}<{{2}\over{BEP_B}}}\),即\(BEP_A>BEP_B\)
但\(F1\)中\(P\)和\(R\)往往不一定相等(相等为特例),所以\(A\)和\(B\)的\(BEP\)值无法进行比较。当且仅当\(P=R\)时,\(F1\)与\(BEP\)存在关系。
分类结果混淆矩阵如下。
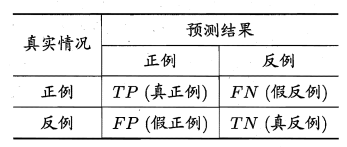
其中,\(R=TPR\)。而其他两个变量之间关系不明显。
式2.20及2.21已经在机器学习-学习笔记(二)中证明。
\(AUC\)表示\(ROC\)曲线与\(x\)轴所围的面积,而\(l_{rank}\)表示\(ROC\)曲线与\(y\)轴所围的面积。\(ROC\)曲线\(x、y\)取值均为\([0,1]\),故其总面积为\(1\)。所以\(AUC=1-l_{rank}\)。
错误率:$$E(f;D)={{FP+FN}\over{TP+FN+FP+TN}}$$
通过公式不难看出,只要出现错误的样例,\(TPR\)值会减小,\(FPR\)值会增大,即按照\(ROC\)曲线绘制方法,出现假例时,会沿\(x\)轴移动,所以在\(ROC\)曲线在最接近于如下图红线时,错误率最低(基本接近于0);当错误率等于\(50%\)时,即为随机胡猜,为图像中的蓝线。
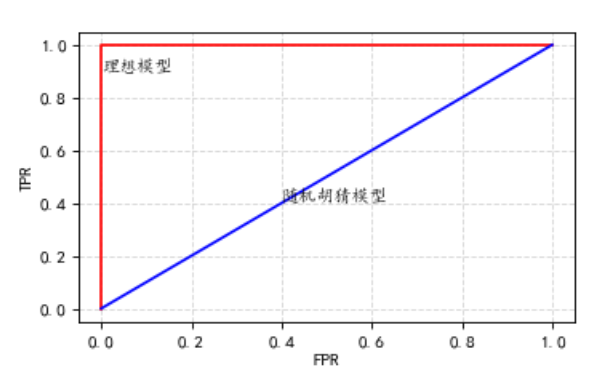
\(ROC\)曲线上每一个点都对应一个错误率,错误率越高,其\(ROC\)曲线越向\((1, 0)\)方向凹陷,若错误率越低,则\(ROC\)曲线越向\((0, 1)\)方向凸出。
先证任意一条 ROC 曲线都有一条代价曲线与之对应。在代价曲线中,一条\(ROC\)上的一点代表代价平面上的一条线段,多个\(ROC\)的点组成了唯一的\(ROC\)曲线,同时,多个代价平面线段(如下图红色限度)共同构成了唯一的代价曲线(下图蓝色线段)。即证
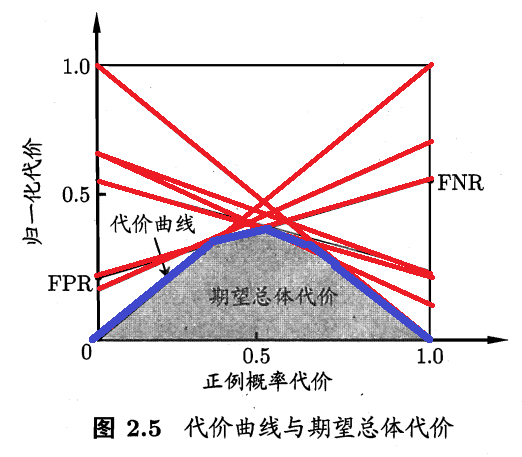
再证任意一条代价曲线都有一条 ROC 曲线与之对应。代价曲线上每一条线段都对应\(ROC\)曲线的一个点坐标,将代价曲线每一个线段都转化为\(ROC\)曲线上的点,将这些点按\(ROC\)曲线构造顺序连接,即可得出唯一的\(ROC\)曲线。但要注意的是,代价曲线反推得出的\(ROC\)曲线不一定是构造代价曲线的\(ROC\)曲线,可能比原来的少某几个点,例如,几条代价平面的线段交于同一点时,只可能选择其中两条,而多余的一条可能被忽略。但一定会有一条\(ROC\)曲线与其对应。
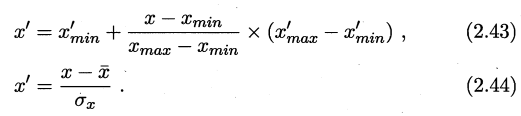
规范化:将原来的度量值转换为无量纲的值。通过将属性数据按比例缩放,通过一个函数将给定属性的整个值域映射到一个新的值域中,即每个旧的值都被一个新的值替代。
我所理解的规范化,其实就是将原有的数据等比例放大/缩小,使其映射到一个固定的数据范围中。
有3种规范化策略,分别是:最小-最大(min-max)规范化、z-score规范化、小数定标规范化。
Min-max规范化:
\(\frac{x_{\max }^{\prime}-x_{\min }^{\prime}}{x_{\max }-x_{\min }}\):等比例缩小
\(x-x_{\min }\):原数据的偏移量
整个公式意思就是,将原数据的偏移量等比例缩小,再在新范围的最小值上加上缩小后的偏移量,即可得出新数据的值。
优点:很明显,Min-max规范化保留了原数据之间偏移量的关系;可以指定数据规范化后的取值范围;是计算复杂度最小的一个方法。
缺点:需要预先知道规范后的最大最小值;若原数据新增数据超越原始范围,则会发生“越界”错误;若原数据有值离群度很高(即使得原数据最大或最小值很大),规范后的大多数数据会特别集中且不易区分。
\(z-score\)规范化:
该公式表示原数据减去所有原数据的均值\(\bar{x}\),再除以标准差\({\sigma}_{x}\),即为规范化后的数据。
将公式变形后易知,\(z-score\)规范化,其实是在计算每个数据相较于均值的偏差距离平方所占的所有偏差距离平方和的比例。
优点:可以将不同标准的数据转化为同一标准下;规范化后的结果易于比较;对于离群度较高的数据敏感度低,不会太受影响。
缺点:每次新增或删除原数据,其均值\(\bar{x}\)和方差\(\sigma_{x}\)均可能改变,需要重新进行计算;根据其计算原理易知,规范化后的数据取值范围基本在\([-1,1]\),数据之间分布较密集。
先引用浙江大学概率论与数理统计(第四版)第八章第三节对\(χ^2\)检验(卡方检验)的概念。
\(χ^2\) 检验(卡方检验)在浙大版概率论中已经阐明的面面俱到了,这里稍作总结一下。
\(χ^2\) 检验(卡方检验):主要用于检验两个变量之间是否存在关系,检验局部数据是否符合总体数据分布。主要是比较实际值和理论值之间的偏离程度。
这里的\(χ^2\) 检验(卡方检验)对单个分布样本和多个分布样本均可检验,但其检验方法不同。
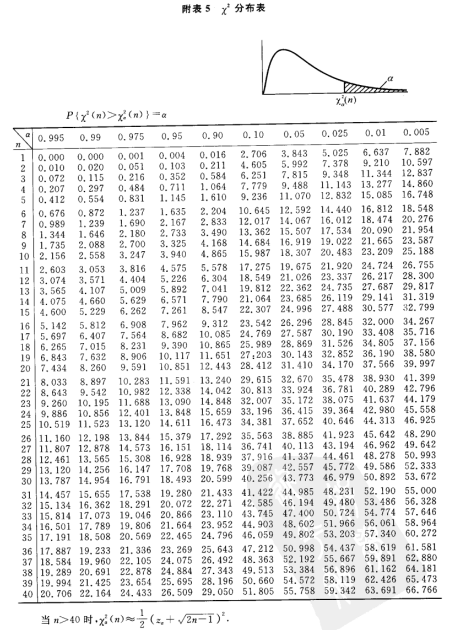

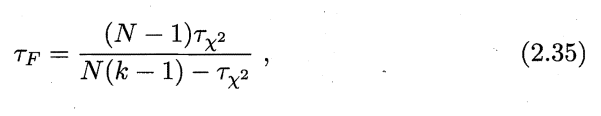
两式的区别在书中有所讲,2.34相较于2.35过于保守,2.34在\(k\)较小的情况下,倾向于认为无显著区别,而2.35恰恰可以解决这个问题。
这里要解决两个问题。第一个是为什么2.34保守,第二个是为什么2.35可以解决保守的问题。
第一个问题:为什么2.34保守?
其实不难理解,2.34服从自由度为\(k-1\)的\(\chi^2\)分布,其仅考虑了不同算法对方差产生的影响,而为考虑不同数据集对其产生的影响,所以较为保守。(这里应该通过对总体方差和样本方差的推导来证明)
第二个问题:为什么2.35可以解决保守的问题?
这里2.35就是服从自由度为\(k-1\)和\((k-1)(N-1)\)的F分布,既考虑了不同算法之间的影响,也考虑了不同数据集所带来的影响。(关于方差的推导过程,后续依次补齐)
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
require"socket"server="irc.rizon.net"port="6667"nick="RubyIRCBot"channel="#0x40"s=TCPSocket.open(server,port)s.print("USERTesting",0)s.print("NICK#{nick}",0)s.print("JOIN#{channel}",0)这个IRC机器人没有连接到IRC服务器,我做错了什么? 最佳答案 失败并显示此消息::irc.shakeababy.net461*USER:Notenoughparame
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
文章目录1、自相关函数ACF2、偏自相关函数PACF3、ARIMA(p,d,q)的阶数判断4、代码实现1、引入所需依赖2、数据读取与处理3、一阶差分与绘图4、ACF5、PACF1、自相关函数ACF自相关函数反映了同一序列在不同时序的取值之间的相关性。公式:ACF(k)=ρk=Cov(yt,yt−k)Var(yt)ACF(k)=\rho_{k}=\frac{Cov(y_{t},y_{t-k})}{Var(y_{t})}ACF(k)=ρk=Var(yt)Cov(yt,yt−k)其中分子用于求协方差矩阵,分母用于计算样本方差。求出的ACF值为[-1,1]。但对于一个平稳的AR模型,求出其滞
目录0专栏介绍1平面2R机器人概述2运动学建模2.1正运动学模型2.2逆运动学模型2.3机器人运动学仿真3动力学建模3.1计算动能3.2势能计算与动力学方程3.3动力学仿真0专栏介绍?附C++/Python/Matlab全套代码?课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等);局部规划(DWA、APF等);曲线优化(贝塞尔曲线、B样条曲线等)。?详情:图解自动驾驶中的运动规划(MotionPlanning),附几十种规划算法1平面2R机器人概述如图1所示为本文的研究本体——平面2R机器人。对参数进行如下定义:机器人广义坐标

