文章目录
所谓自注意力机制就是通过某种运算来直接计算得到句子在编码过程中每个位置上的注意力权重;然后再以权重和的形式来计算得到整个句子的隐含向量表示。
自注意力机制的缺陷就是:模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置, 因此作者提出了通过多头注意力机制来解决这一问题。
在实践中,当给定相同的查询、键和值的集合时,我们希望模型可以基于相同的注意力机制学习到不同的行为,然后将不同的行为作为知识组合起来,例如捕获序列内各种范围的依赖关系(例如,短距离依赖和长距离依赖)。因此,允许注意力机制组合使用查询、键和值的不同的 子空间表示(representation subspaces)可能是有益的。
为此,与使用单独的一个注意力池化不同,我们可以独立学习得到
h
h
h 组不同的 线性投影(linear projections)来变换查询、键和值。然后,这
h
h
h 组变换后的查询、键和值将并行地进行注意力池化。最后,将这
h
h
h 个注意力池化的输出拼接在一起,并且通过另一个可以学习的线性投影进行变换,以产生最终输出。这种设计被称为 多头注意力,其中
h
h
h 个注意力池化输出中的每一个输出都被称作一个 头 Vaswani.Shazeer.Parmar.ea.2017。下图展示了使用全连接层来实现可以学习的线性变换的多头注意力。
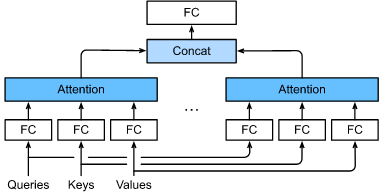
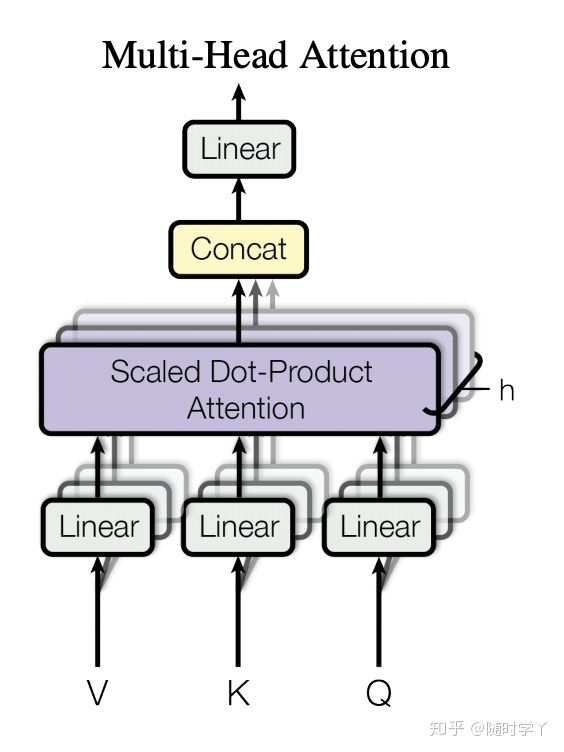
在实现多头注意力之前,让我们用数学语言将这个模型形式化地描述出来。给定查询 q ∈ R d q \mathbf{q} \in \mathbb{R}^{d_q} q∈Rdq、键 k ∈ R d k \mathbf{k} \in \mathbb{R}^{d_k} k∈Rdk 和值 v ∈ R d v \mathbf{v} \in \mathbb{R}^{d_v} v∈Rdv,每个注意力头 h i \mathbf{h}_i hi ( i = 1 , … , h i = 1, \ldots, h i=1,…,h) 的计算方法为
h i = f ( W i ( q ) q , W i ( k ) k , W i ( v ) v ) ∈ R p v , \mathbf{h}_i = f(\mathbf W_i^{(q)}\mathbf q, \mathbf W_i^{(k)}\mathbf k,\mathbf W_i^{(v)}\mathbf v) \in \mathbb R^{p_v}, hi=f(Wi(q)q,Wi(k)k,Wi(v)v)∈Rpv,
其中,可学习的参数包括 W i ( q ) ∈ R p q × d q \mathbf W_i^{(q)}\in\mathbb R^{p_q\times d_q} Wi(q)∈Rpq×dq、 W i ( k ) ∈ R p k × d k \mathbf W_i^{(k)}\in\mathbb R^{p_k\times d_k} Wi(k)∈Rpk×dk 和 W i ( v ) ∈ R p v × d v \mathbf W_i^{(v)}\in\mathbb R^{p_v\times d_v} Wi(v)∈Rpv×dv ,以及代表注意力池化的函数 f f f 可以是可加性注意力和缩放的“点-积”注意力。多头注意力的输出需要经过另一个线性转换,它对应着 h h h 个头拼接后的结果,因此其可学习参数是 W o ∈ R p o × h p v \mathbf W_o\in\mathbb R^{p_o\times h p_v} Wo∈Rpo×hpv:
W o [ h 1 ⋮ h h ] ∈ R p o . \mathbf W_o \begin{bmatrix}\mathbf h_1\\\vdots\\\mathbf h_h\end{bmatrix} \in \mathbb{R}^{p_o}. Wo⎣⎢⎡h1⋮hh⎦⎥⎤∈Rpo.
基于这种设计,每个头都可能会关注输入的不同部分。可以表示比简单加权平均值更复杂的函数。
有掩码的多头注意力:
微观下的多头Attention可以表示为:
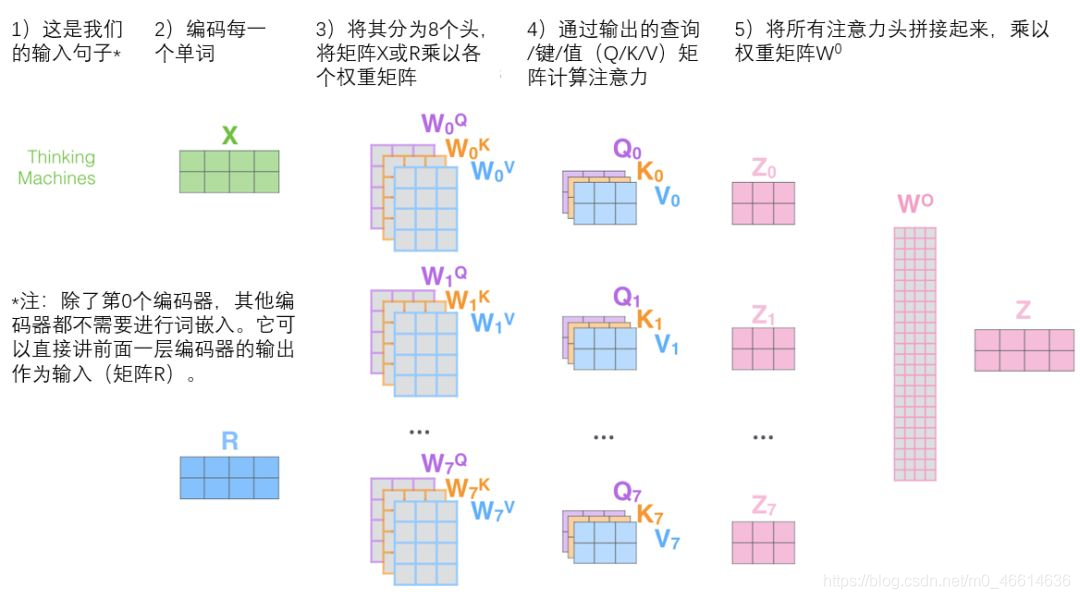
在实现过程中,我们选择了缩放的“点-积”注意力作为每一个注意力头。为了避免计算成本和参数数量的显著增长,我们设置了
p
q
=
p
k
=
p
v
=
p
o
/
h
p_q = p_k = p_v = p_o / h
pq=pk=pv=po/h。值得注意的是,如果我们将查询、键和值的线性变换的输出数量设置为
p
q
h
=
p
k
h
=
p
v
h
=
p
o
p_q h = p_k h = p_v h = p_o
pqh=pkh=pvh=po,则可以并行计算
h
h
h 头。在下面的实现中,
p
o
p_o
po 是通过参数num_hiddens 指定的。
import math
import torch
from torch import nn
from d2l import torch as d2l
def transpose_qkv(X,num_heads):
# 输入 `X` 的形状: (`batch_size`, 查询或者“键-值”对的个数, `num_hiddens`).
# 输出 `X` 的形状: (`batch_size`, 查询或者“键-值”对的个数, `num_heads`,`num_hiddens` / `num_heads`)
X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)
# 输出 `X` 的形状: (`batch_size`, `num_heads`, 查询或者“键-值”对的个数,`num_hiddens` / `num_heads`)
X = X.permute(0, 2, 1, 3)
# `output` 的形状: (`batch_size` * `num_heads`, 查询或者“键-值”对的个数,`num_hiddens` / `num_heads`)
return X.reshape(-1, X.shape[2], X.shape[3])
def transpose_output(X,num_heads):
"""逆转 `transpose_qkv` 函数的操作"""
X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])
X = X.permute(0, 2, 1, 3)
return X.reshape(X.shape[0], X.shape[1], -1)
class MultiHeadAttention(nn.Module):
def __init__(self,key_size,query_size,value_size,num_hiddens,
num_heads,dropout,bias=False,**kwargs):
super(MultiHeadAttention,self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = d2l.DotProductAttention(dropout)
self.W_q = nn.Linear(query_size,num_hiddens,bias=bias) # 将输入映射为(batch_size,query_size/k-v size,num_hidden)大小的输出
self.W_k = nn.Linear(key_size,num_hiddens,bias=bias)
self.W_v = nn.Linear(value_size,num_hiddens,bias=bias)
self.W_o = nn.Linear(num_hiddens,num_hiddens,bias=bias)
def forward(self,queries,keys,values,valid_lens):
# `queries`, `keys`, or `values` 的形状:
# (`batch_size`, 查询或者“键-值”对的个数, `num_hiddens`)
# `valid_lens` 的形状:
# (`batch_size`,) or (`batch_size`, 查询的个数)
# 经过变换后,输出的 `queries`, `keys`, or `values` 的形状:
# (`batch_size` * `num_heads`, 查询或者“键-值”对的个数,`num_hiddens` / `num_heads`)
queries = transpose_qkv(self.W_q(queries), self.num_heads)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads) # 将多个头的数据堆叠在一起,然后进行计算,从而不用多次计算
if valid_lens is not None:
valid_lens = torch.repeat_interleave(valid_lens,
repeats=self.num_heads,
dim=0)
output = self.attention(queries,keys,values,valid_lens) # output->(10,4,20)
# return output
output_concat = transpose_output(output,self.num_heads) # output_concat -> (2,4,100)
return self.W_o(output_concat)
让我们使用键和值相同的小例子来测试我们编写的 MultiHeadAttention 类。多头注意力输出的形状是(batch_size、num_queries、num_hiddens)。
# 线性变换的输出为100个,5个头
num_hiddens, num_heads = 100, 5
attention = MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens,num_hiddens, num_heads, 0.5)
attention.eval()
MultiHeadAttention(
(attention): DotProductAttention(
(dropout): Dropout(p=0.5, inplace=False)
)
(W_q): Linear(in_features=100, out_features=100, bias=False)
(W_k): Linear(in_features=100, out_features=100, bias=False)
(W_v): Linear(in_features=100, out_features=100, bias=False)
(W_o): Linear(in_features=100, out_features=100, bias=False)
)
# 2个batch,4个query,6个键值对
batch_size, num_queries, num_kvpairs, valid_lens = 2, 4, 6, torch.tensor([3, 2])
X = torch.ones((batch_size, num_queries, num_hiddens)) # query(2,4,100)
Y = torch.ones((batch_size, num_kvpairs, num_hiddens)) # key和value (2,6,100)
output = attention(X, Y, Y, valid_lens) # 输出大小与输入的query的大小相同
output.shape
torch.Size([2, 4, 100])
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
文章目录1、自相关函数ACF2、偏自相关函数PACF3、ARIMA(p,d,q)的阶数判断4、代码实现1、引入所需依赖2、数据读取与处理3、一阶差分与绘图4、ACF5、PACF1、自相关函数ACF自相关函数反映了同一序列在不同时序的取值之间的相关性。公式:ACF(k)=ρk=Cov(yt,yt−k)Var(yt)ACF(k)=\rho_{k}=\frac{Cov(y_{t},y_{t-k})}{Var(y_{t})}ACF(k)=ρk=Var(yt)Cov(yt,yt−k)其中分子用于求协方差矩阵,分母用于计算样本方差。求出的ACF值为[-1,1]。但对于一个平稳的AR模型,求出其滞
写在之前Shader变体、Shader属性定义技巧、自定义材质面板,这三个知识点任何一个单拿出来都是一套知识体系,不能一概而论,本文章目的在于将学习和实际工作中遇见的问题进行总结,类似于网络笔记之用,方便后续回顾查看,如有以偏概全、不祥不尽之处,还望海涵。1、Shader变体先看一段代码......Properties{ [KeywordEnum(on,off)]USL_USE_COL("IsUseColorMixTex?",int)=0 [Toggle(IS_RED_ON)]_IsRed("IsRed?",int)=0}......//中间省略,后续会有完整代码 #pragmamulti_c
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。我来自C、php和bash背景,很容易学习,因为它们都有相同的C结构,我可以将其与我已经知道的联系起来。然后2年前我学了Python并且学得很好,Python对我来说比Ruby更容易学。然后从去年开始,我一直在尝试学习Ruby,然后是Rails,我承认,直到现在我还是学不会,讽刺的是那些打着简单易学的烙印,但是对于我这样一个老练的程序员来说,我只是无法将它