目录
经验模态分解(Empirical Mode Decomposition,EMD)
原文:
N.E. Huang, Zheng Shen, Steven R. Long, et al, The empirical mode decomposition and the hilbert spectrum for nonlinear and non-stationary time series
analysis, Proc. R. Soc. Lond. A 454 (1998) 903–995.
(1).计算原始信号x(t)的极值点,然后使用三次样条插值根据极值点计算非平稳信号的上下包络线,并计算上下包络线的均值
(2).用原始信号x(t)减去上下包络线的均值,得到的信号h(t1)判断是否满足本征模态函数IMFs的两个条件:①极值点和零点的数目差不超过1,②上下包络函数的均值为0。
若不满足,则继续求h(t1)的上下包络线的均值,然后用h(t1)减去均值,得到h(t2)并判断h(t2)是否满足IMFs的两个条件,直至满足条件,得到第一个IMF1。
若满足,令其为IMF1,然后用原始信号x(t)减去IMF1,得到信号继续判断是否满足IMFs的条件。
通过以上迭代过程,可得到若干个IMFs,直至剩下单调信号分量。
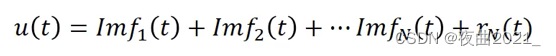
针对非平稳信号,第一次提出分解的思想,将信号分量与噪声分量自动分离,选择需要的信号分量重构,可实现去噪的目的。
①端点效应:上下包络线是根据信号极值点信息使用三次样条插值求得的,但是不能保证信号的左右端点恰好是局部极值,这样,信号的上下包络线在端点处会产生大的波动,分解出的本征模态函数失真,随着分解的进行,这种失真现象由外向内扩散,直至“污染”整个本征模态函数。
解决方法:多项式拟合延拓法、匹配延拓法、极值点对称延拓法、镜像闭合延拓法等
②模态混叠:不同模态的信号混叠在一起,一般有两种情况:一是不同特征尺度的信号在一个IMF分量中出现,另一种是同一个特征尺度的信号被分散到不同的IMF分量中。
(1).EEMD:集成经验模态分解(Ensemble empirical mode decomposition)
原文:Wu, Z., and N. E. Huang, 2009, Ensemble empirical mode decomposition: Anoise-assisted data analysis method: Advances in Adaptive Data Analysis,01, 1–41
EEMD是每次分解前都对原信号加入白噪声,然后再进行分解。重复多次后,取平均IMFs,缺点是由于加入了噪声,重构信号不准确。且计算非常耗时,不适用于实时分解
(2).CEEMD:Complementary EEMD(谷歌学术引用量800+)
原文:COMPLEMENTARY ENSEMBLE EMPIRICAL MODE DECOMPOSITION: A NOVEL NOISE ENHANCED DATA ANALYSIS METHOD.DOI: 10.1142/S1793536910000422
算法内容:

CEEMDAN:(谷歌学术引用量1300+)
原文:A complete ensemble empirical mode decomposition with adaptive noise:Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing ,2011
改进内容:在第一个筛选阶段加入适当的白噪声,后续分解出来的模态再继续加白噪声
(3).ICEMMD:improve CEEMD
原文:Colominas, M. A., G. Schlotthauer, and M. E. Torres, 2014, Improved complete ensemble EMD: A suitable tool for biomedical signal processing
奇异谱分析(Singular Spectrum Analysis, SSA)是一种处理非线性时间序列数据的方法,通过对所要研究的时间序列的轨迹矩阵进行分解、重构等操作,提取出时间序列中的不同成分序列(长期趋势,季节趋势,噪声等),从而进行对时间序列进行分析或去噪并用于其他一些任务。
原文:
Singular spectrum analysis in nonlinear dynamics, with applications to paleoclimatic time series
R Vautard, M Ghil-Physica D: Nonlinear Phenomena, 1989 - Elsevier
主要包括四个步骤:嵌入——分解——分组——重构。
有博主已经整理的很好了
参考文章链接:https://blog.csdn.net/Lucky_Go/article/details/103109045
步骤1:嵌入
对于一个一维N个采样点的时间序列:选择窗口长度L生成滞后矩阵X:

其中L(属于区间[2,N-1])的选择很重要,影响最终的分解效果。
步骤2:奇异值分解
对矩阵X进行奇异值分解:
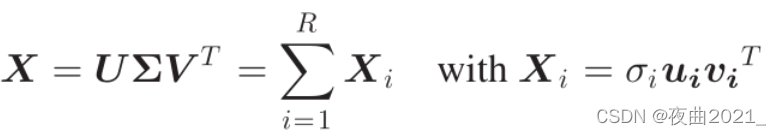
其中为对角矩阵,
为降序排列的奇异值,ui和vi分别是对应于正交矩阵U和V的列的左奇异向量和右奇异向量。
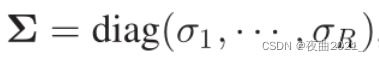
由于直接计算X的奇异值分解不好计算,因此先对其协方差矩阵C进行奇异值分解:
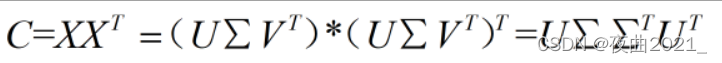
则其第i个奇异值等于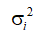
可得到矩阵C的奇异值和对应的特征向量U1,U2......Un:

矩阵V便可根据 两边同时取转置计算出来。注意U,V都是正交矩阵,即转置矩阵等于其逆矩阵,
两边同时取转置计算出来。注意U,V都是正交矩阵,即转置矩阵等于其逆矩阵,为对角矩阵,其逆矩阵为对角线上的数取倒数:
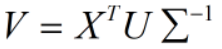
步骤3:分组
步骤4:对角线平均(重构)
SSA是无模型的,对时间序列既不要求平稳,又不假设参数模型,可广泛应用于各种时间序列。
SSA最关键的步骤是对轨迹矩阵进行SVD分解,然后可根据奇异值大小来判断对应的分量为信号分量还是噪声分量。奇异值越大的越代表信号分量。问题就在于如何确定一个阈值区分信号分量和噪声分量。
(1).truncated SVD (TSVD):截断SVD
参考文献:

此方法根据介于0和1之间的预定义百分比阈值直接截断奇异值。实际计算时,它测试从第一个特征值中累积的临时特征值是否大于或等于该阈值乘以所有特征值之和,然后,将小特征值设置为0以实现降秩。
缺点是这种方法需要根据经验预先定义窗口长度和阈值。
(2).singular value thresholding (SVT) :奇异值阈值法
参考文献:

该方法将降阶视为一个优化问题。优化问题的目标函数是最小化未知低秩信号矩阵和噪声观测特征向量加权组合建模的去噪信号矩阵之间的矩阵Frobenius范数。 权重的数量被设置为信号矩阵的秩。此外,通过OptShrink算法可以获得最优权重 。
缺点是此方法需要预先知道信号轨迹矩阵的秩,这是很难做到的。此外计算耗时大。
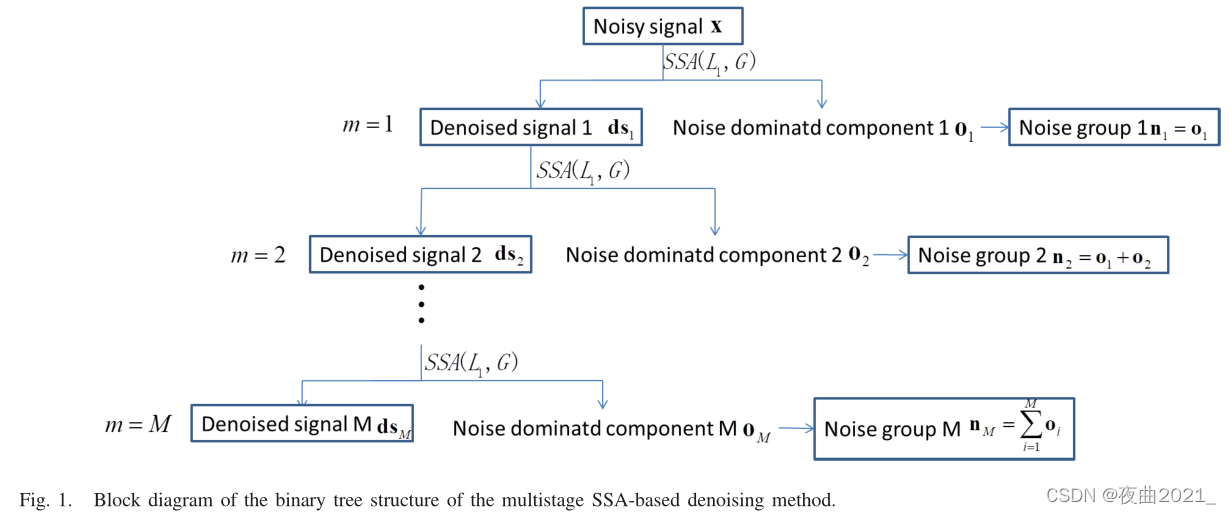
(3).Multistage Singular Spectrum Analysis:多级SSA
参考文献:Weichao Kuang , Shanjin Wang.Efficient and Adaptive Signal Denoising Based on Multistage Singular Spectrum Analysis.IEEE TRANSACTIONS ON INSTRUMENTATION AND MEASUREMENT, VOL. 70, 2021
算法步骤:
三、ITD
固有时间尺度分解(Intrinsic time-scale decomposition)可将非平稳信号自适应的分解为一系列固有旋转分量(proper rotation components)之和。
原文:Intrinsic time-scale decomposition: time–frequency–energy analysis and real-time filtering of non-stationary signals. MARK G. FREI, IVAN OSORIO.
我在我的应用程序中使用spree2.0.0稳定版。在产品展示页面上,所有变体都显示为单选按钮。我只想在下拉列表中显示它们。对此有什么想法吗?谢谢。 最佳答案 注意:此解决方案实现Spree“模板替换方法”,尤其是当您在应用程序设计或使用自定义设计中进行大量设计更改时。看这里http://guides.spreecommerce.com/developer/view.html否则,如果您使用的是Spree商店的默认设计或较小的更改,请使用“破坏”方法。前往:app/views/spree/products/_cart.html.erb
写在之前Shader变体、Shader属性定义技巧、自定义材质面板,这三个知识点任何一个单拿出来都是一套知识体系,不能一概而论,本文章目的在于将学习和实际工作中遇见的问题进行总结,类似于网络笔记之用,方便后续回顾查看,如有以偏概全、不祥不尽之处,还望海涵。1、Shader变体先看一段代码......Properties{ [KeywordEnum(on,off)]USL_USE_COL("IsUseColorMixTex?",int)=0 [Toggle(IS_RED_ON)]_IsRed("IsRed?",int)=0}......//中间省略,后续会有完整代码 #pragmamulti_c
目录一、inout在设计文件中的使用方法1.1、inout的第一种使用方法1.2、inout实现的第二种使用方法1.3、inout使用总结 二、inout在仿真测试中的使用方法一、inout在设计文件中的使用方法在FPGA的设计过程中,有时候会遇到双向信号(既能作为输出,也能作为输入的信号叫双向信号)。比如,IIC总线中的SDA信号就是一个双向信号,QSPIFlash的四线操作的时候四根信号线均为双向信号。在Verilog中用关键字inout定义双向信号,这里总结一下双向信号的处理方法。1.1、inout的第一种使用方法 实际上,双向信号的本质是由一个三态门组成的,三态门可以输出高电平,低电
我想从gtk3中的Widget发出自定义信号。在GTK2中,有一个名为signal_new的函数来创建一个新信号。您可以在此处查看示例:https://github.com/ruby-gnome2/ruby-gnome2/blob/ec373f87e672dbeeaa157f9148d18b34713bb90e/glib2/sample/type-register.rb在GTK3中,这个功能似乎不再可用。那么在ruby的GTK3中创建自定义信号的新方法是什么? 最佳答案 GTK3更改为使用define_signal方法而不是si
我想知道如何连接到带参数的信号(使用Rubyblock)。我知道如何连接到一个不带参数的:myCheckbox.connect(SIGNAL:clicked){doStuff}但是,这不起作用:myCheckbox.connect(SIGNAL:toggle){doStuff}它不起作用,因为切换槽采用参数voidQAbstractButton::toggled(boolchecked)。我怎样才能让它与参数一起工作?谢谢。 最佳答案 对您的问题的简短回答是,您必须使用slots方法声明要连接的插槽的方法签名:classMainGU
我有在服务器上运行的代码,在服务器硬关闭之前,发送了一个信号SIGTERM让我的代码知道它需要清理。我想在发生这种情况时运行代码并将信号发送回同一个程序,以便任何其他需要清理的代码都可以这样做。我不想捕获信号或改变信号行为,我只需要在我的程序的其余部分解释SIGTERM之前运行一些东西。目前我可以做类似的事情Signal.trap('TERM')doputs"Gracefulshutdown"exitend但如果同一个应用中的多段代码试图做同样的事情,它就不起作用了。例如:Signal.trap('TERM')doputs"Gracefulshutdown"exitendSignal.
对于体育新闻中文文本的关键字提取,常用的算法包括TF-IDF、TextRank和LDA等。它们的基本步骤如下:1.TF-IDF算法: -将文本进行分词和词性标注处理。-统计每个词在文本中的词频(TF)。-计算每个词在整个语料库中出现的文档频率(DF)和逆文档频率(IDF)。-计算每个词的TF-IDF值,并按照值的大小进行排序,选择排名前几的词作为关键字。2.TextRank算法:-将文本进行分词和词性标注处理。-将分词结果转化成图模型,每个词语为节点,根据词语之间的共现关系建立边。-对图模型进行迭代计算,计算每个节点的PageRank值,表示该节点的重要性。-选择排名前几的节点作为关键字。3.
光度学中的能量、通量、出度、照度、强度、亮度参数及其联系光度学中评价光的强弱有两种方式,一种是将光作为电磁波,考察其辐射的能量;另一种是以人眼视觉体验来评价光的强弱。前者被称为辐射量,后者被称为光学量。辐射量包括辐射能、辐通量、辐出量、辐照度、辐强度、辐亮度参数,与之相对应,光学量包括光能量、光通量、光出量、光照度、光强度、光亮度参数。通过该文章的阅读,读者还能掌握光学中的几个单位:流明,勒克斯,坎德拉,尼特的意义以及他们之间的关系。辐射量1.辐射能光以电磁波形式发射、传输或接收的能量。单位:焦耳。2.辐通量单位时间发射、传输和接收的辐射能。单位:瓦特。3.辐出度单位面积的辐射源辐射出的辐通量
我正在尝试掌握Rails计数器缓存功能,但无法完全掌握它。假设我们有3个模型ABCA属于B或C,取决于字段key_type和key_id。key_type表示A属于B还是C,因此如果key_type="B"则记录属于B,否则属于C。在我的模型a.rb中,我定义了以下关联:belongs_to:b,:counter_cache=>true,:foreign_key=>"key_id"belongs_to:c,:counter_cache=>true,:foreign_key=>"key_id"和在b和c模型文件中has_many:as,:conditions=>{:key_type=>"
人类生活在充满多样性的世界里。长久以来的研究发现,人类的脑与行为受到基因、环境和文化及其相互作用的塑造,然而这种影响发生的机制始终缺乏系统性探索与研究。近年来,前沿神经影像技术方法飞速进步,推动着多模态脑成像大数据集的产生和融合性探索,并让学界得以深入探究人脑宏观结构与功能连接组架构,为包括上述主题在内的许多有趣而重要的科学问题带来了新的启发和思路。2022年12月20日,北京大学物理学院、IDG麦戈文脑科学研究所高家红团队在《NatureNeuroscience》在线发表了题为“IncreasingdiversityinconnectomicswiththeChineseHumanConne