课程是CS188伯克利大学人工智能导论
参考文献:
部分截图来自学校老师的教学PPT
https://zhuanlan.zhihu.com/p/61895500
https://zhuanlan.zhihu.com/p/64368643
https://zhuanlan.zhihu.com/p/148256240
https://zhuanlan.zhihu.com/p/272652797
https://blog.csdn.net/qq_45902301/article/details/125055544
https://blog.csdn.net/wangyong1034/article/details/105017736
https://blog.csdn.net/xing565244161/article/details/47253211
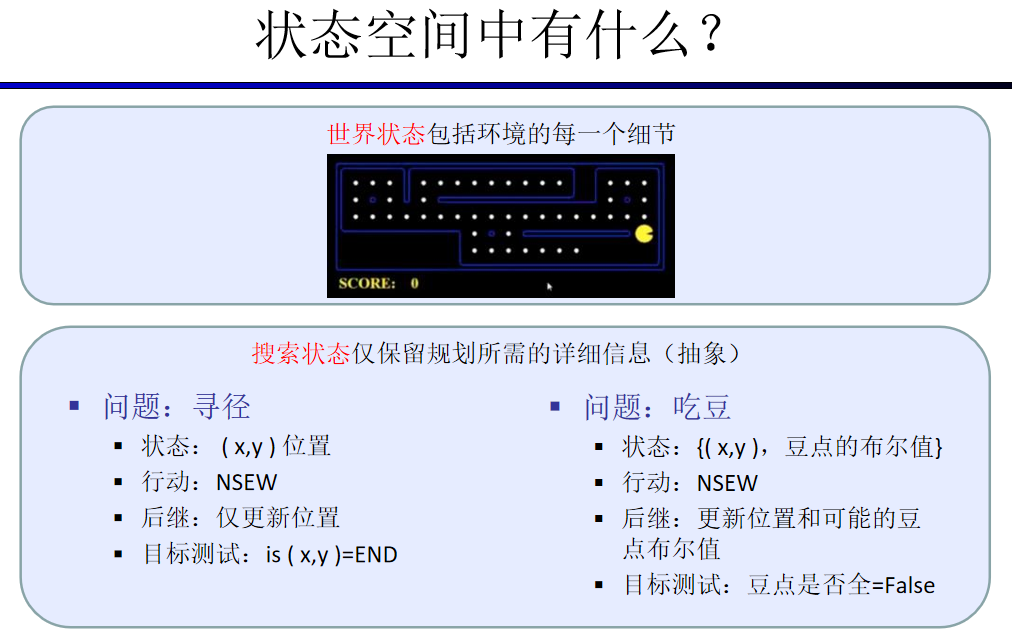
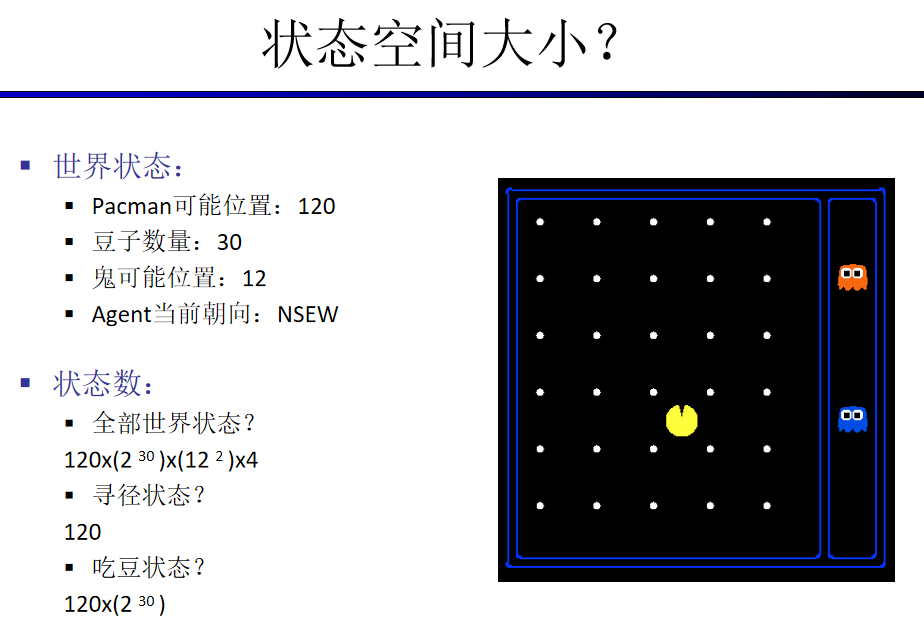
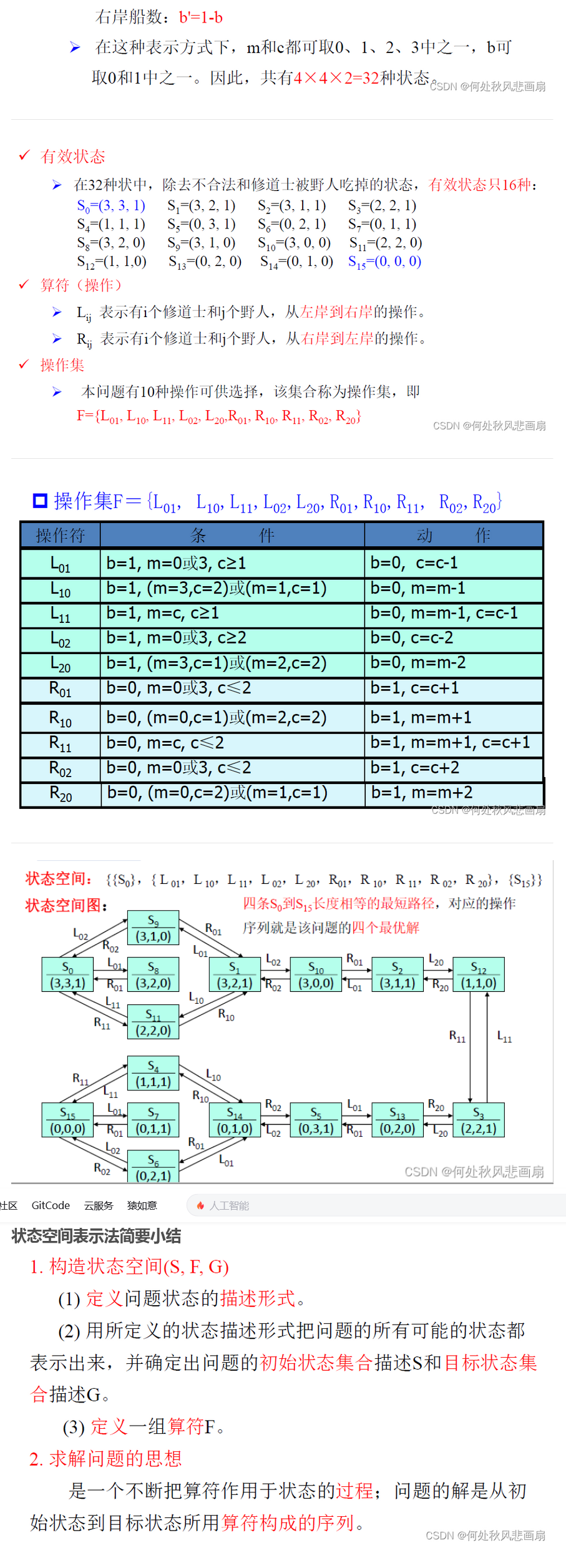
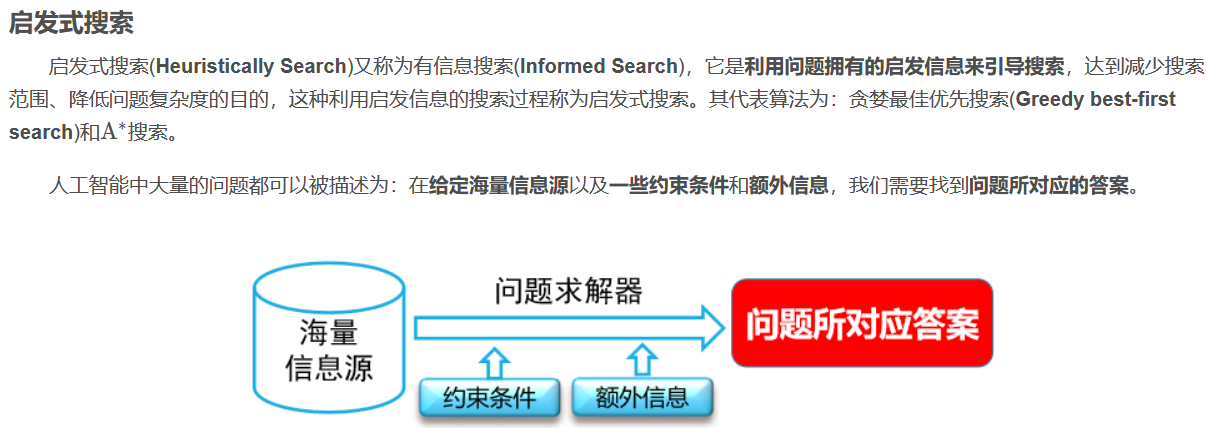
为了创建一个理性计划agent,我们需要一种方法来对agent存在的环境进行数学表达。为此,我们必须正式表达一个搜索问题(search problem)——给定agent的当前状态(state)(它在环境中的配置),我们如何尽可能最好地达到一个满足目标的新状态?讲一个问题公式化需要四个前提:
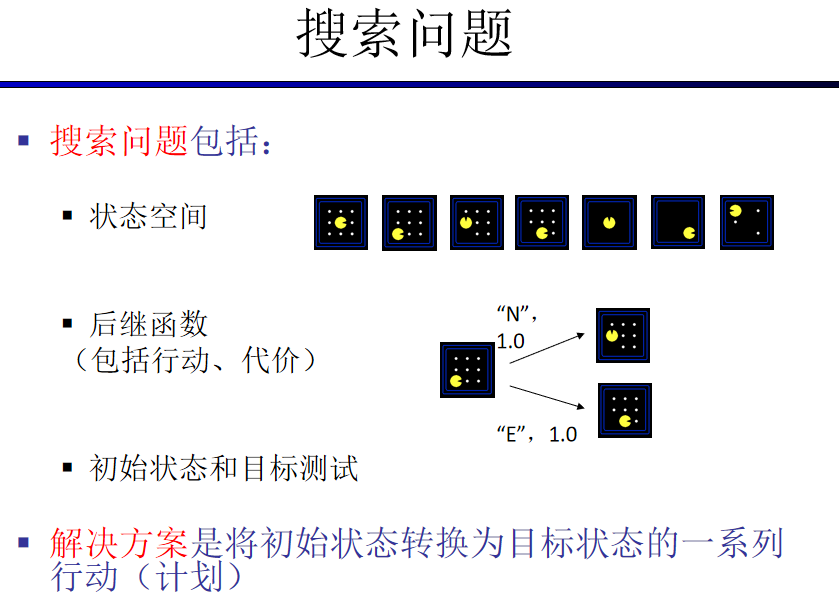 o
o


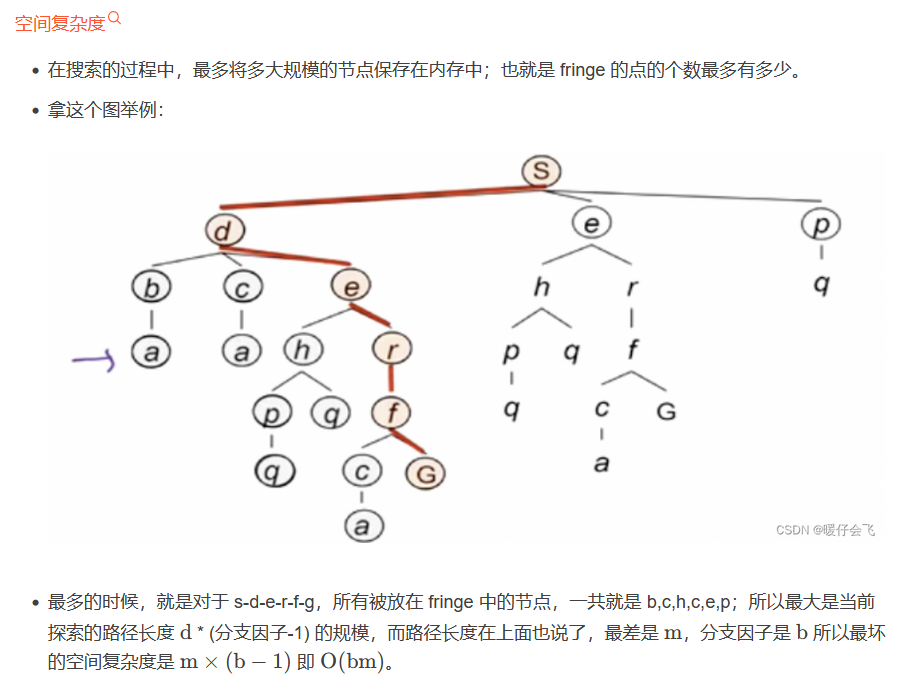
以下截图不完整,想看完整版的去看参考文献。




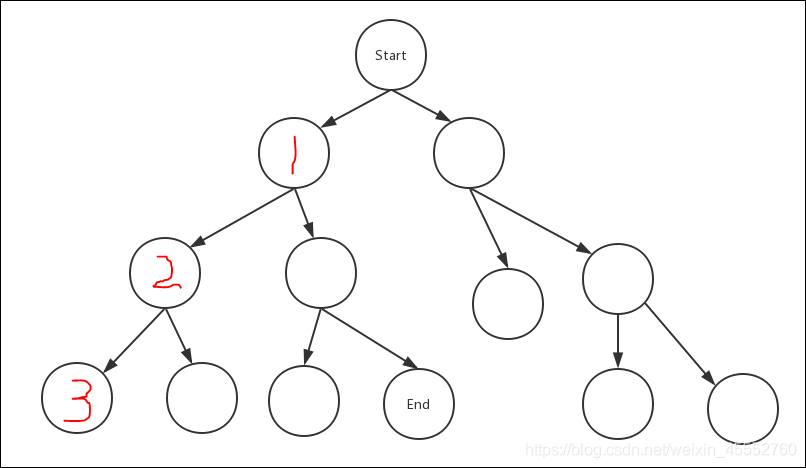
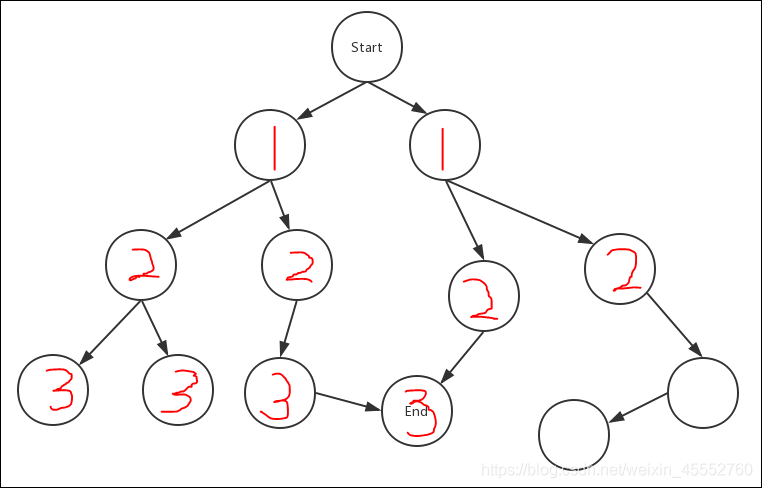
若走到叶子节点,便会退回上一节点,遍历上一节点的其他相邻节点(2 ->3-> 4)。
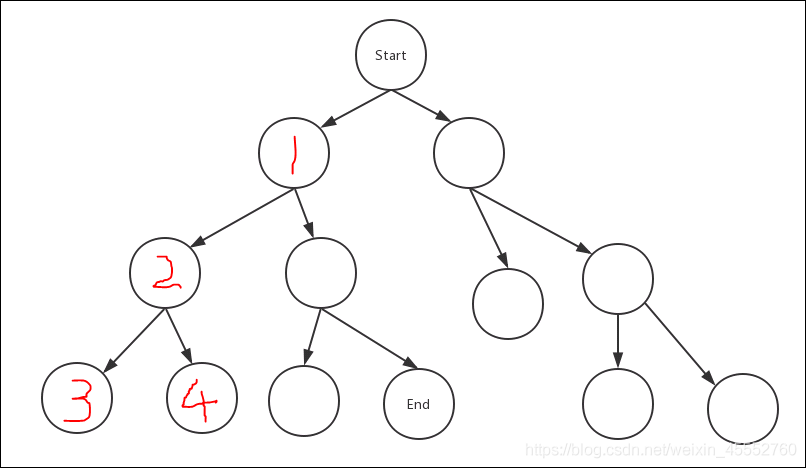
这样一直重复,直到找到最终目标节点。
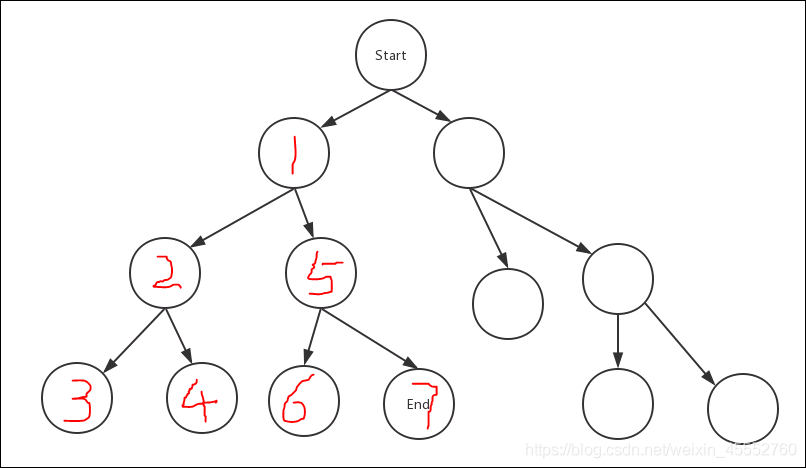
如你所见到的一样,这样的搜索方法像一根贪婪的蚯蚓,喜欢往深的地方钻,所以就自然而然的叫做深度优先算法了。

对于深度优先算法,强迫症就很不爽了,并表示:“为什么不干干净净,一层 一层地从start节点搜索下去呢,就像病毒感染一样,这样才像正常的搜索的样子嘛!”于是便有了BFS算法。广度优先算法便如其名字,它是以广度为优先的,一层一层搜索下去的。
BFS总是先访问完同一层的结点,然后才继续访问下一层结点,它最有用的性质是可以遍历一次就生成中心结点到所遍历结点的最短路径,这一点在求无权图的最短路径时非常有用。
还是以图的方式来演示,下图中start为搜索的初始节点,end为目标节点:
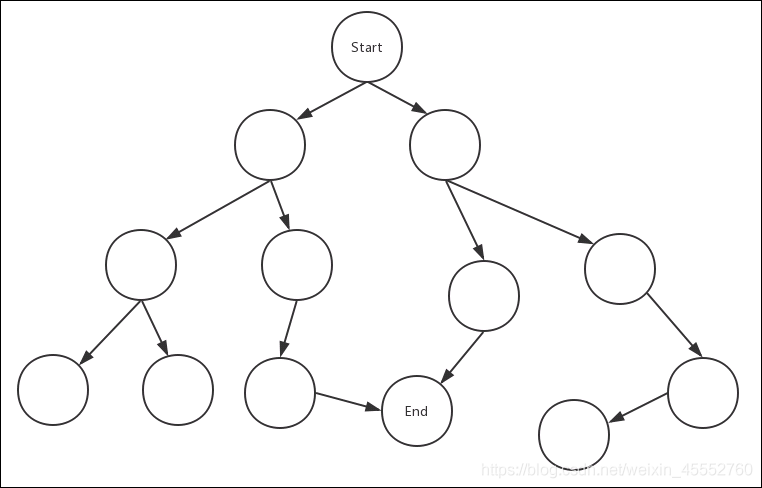
我们先把start节点的相关节点遍历一次
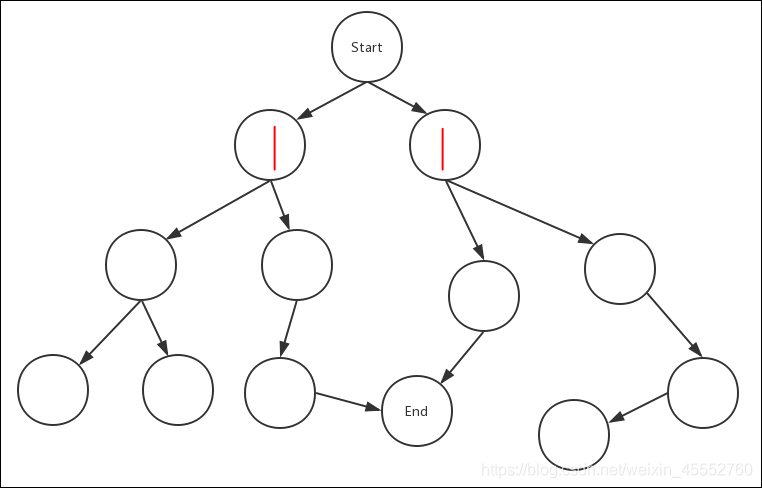
接下来把第一步遍历过的节点当成start节点,重复第一步
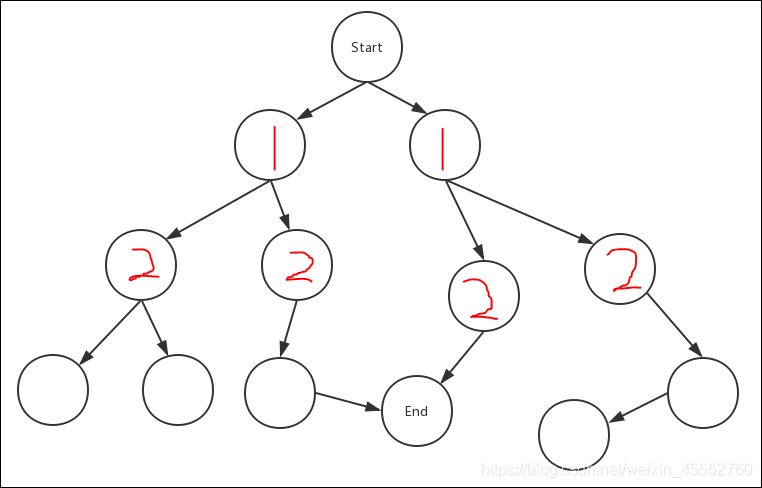
一直重复一二步,这样便是一个放射样式的搜索方法,直到找到end节点
可以看出,这样放射性的寻找方式,能找到从start到end的最短路径(因为每次只走一步,且把所有的可能都走了,谁先到end说明这就是最短路)。
从实现的角度上,在广度优先遍历的过程中,我们需要用到队列:
1. 首先扩展最浅的节点
2. 将后继节点放入队列的末尾(FIFO)
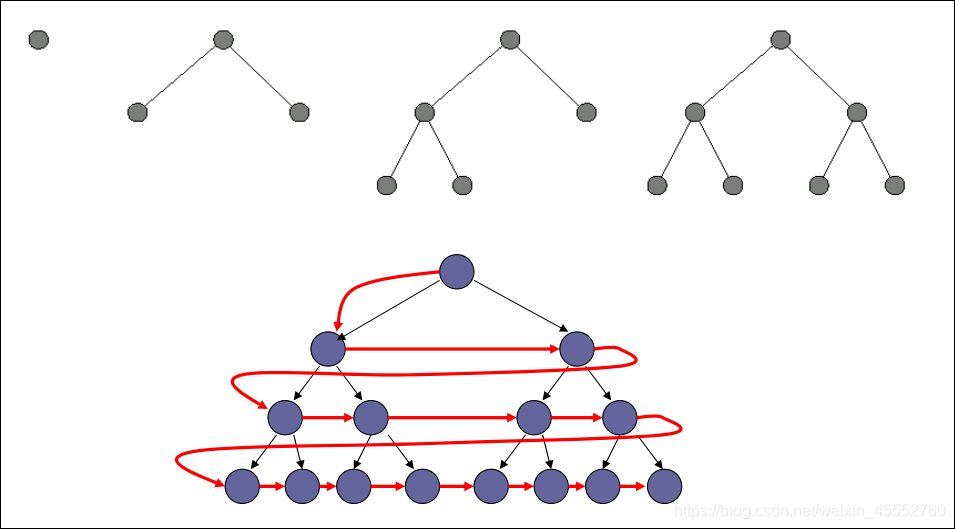
BFS是从根节点(起始节点)开始,按层进行搜索,也就是按层来扩展节点。所谓按层扩展,就是前一层的节点扩展完毕后才进行下一层节点的扩展,直到得到目标节点为止。


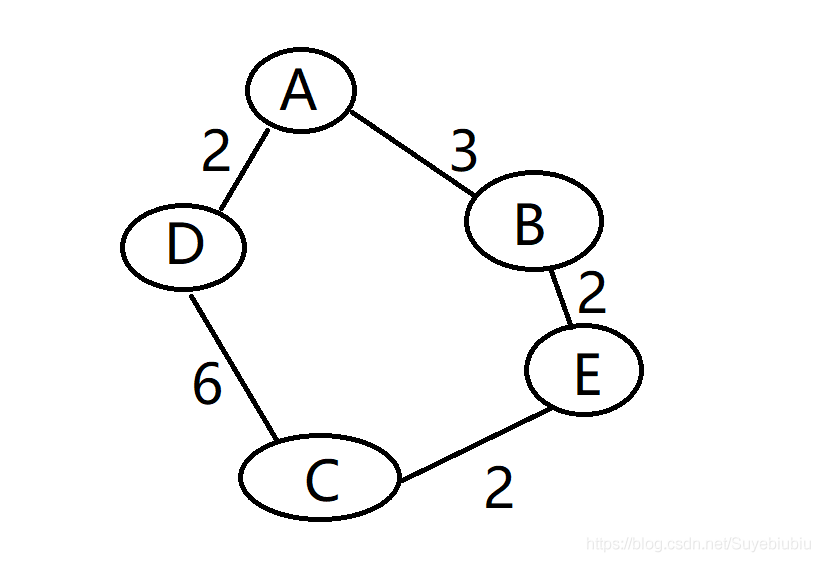



以下练习作为延伸理解
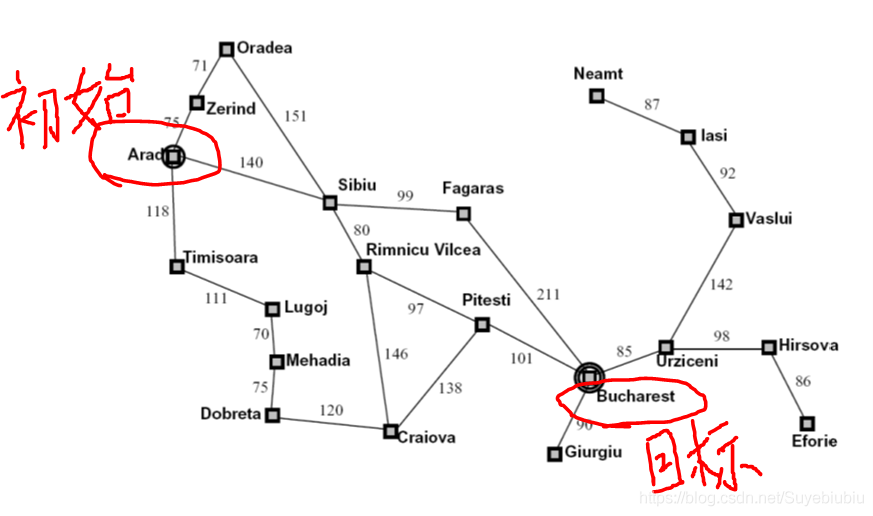
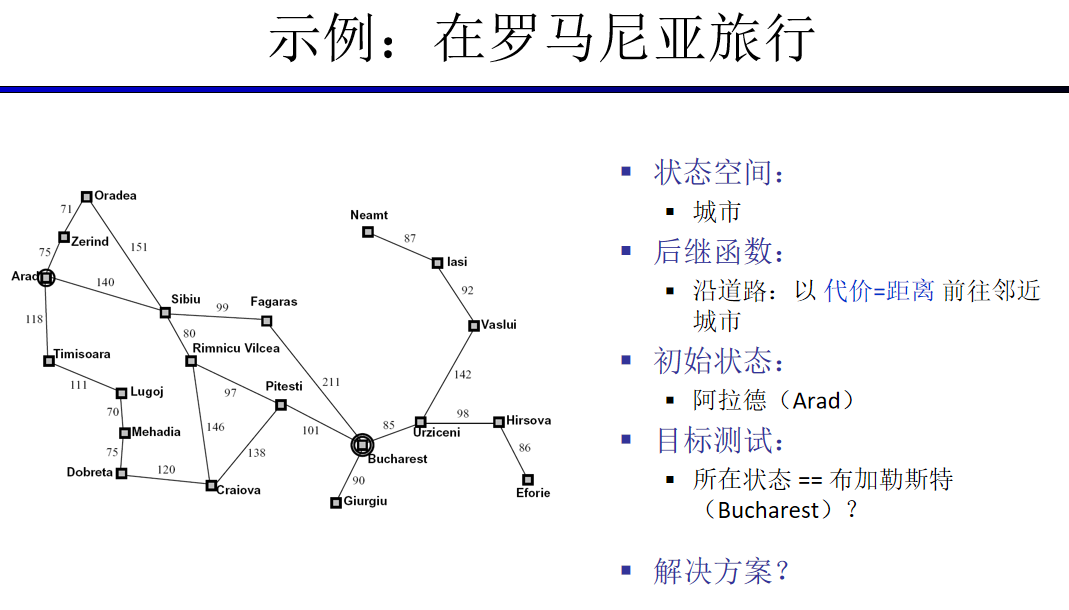
输入初始城市
Arad
输入目的城市
Bucharest
处理城市节点:Arad 父节点:None 路径损失为:0
孩子节点:Zerind 路径损失为:75
添加孩子到优先队列
孩子节点:Sibiu 路径损失为:140
添加孩子到优先队列
孩子节点:Timisoara 路径损失为:118
添加孩子到优先队列
处理城市节点:Zerind 父节点:Arad 路径损失为:75
孩子节点:Oradea 路径损失为:146
添加孩子到优先队列
孩子节点:Arad 路径损失为:150
处理城市节点:Timisoara 父节点:Arad 路径损失为:118
孩子节点:Arad 路径损失为:236
孩子节点:Lugoj 路径损失为:229
添加孩子到优先队列
处理城市节点:Sibiu 父节点:Arad 路径损失为:140
孩子节点:Oradea 路径损失为:291
孩子节点:Arad 路径损失为:280
孩子节点:Fagaras 路径损失为:239
添加孩子到优先队列
孩子节点:Rimnicu Vilcea 路径损失为:220
添加孩子到优先队列
处理城市节点:Oradea 父节点:Zerind 路径损失为:146
孩子节点:Zerind 路径损失为:217
孩子节点:Sibiu 路径损失为:297
处理城市节点:Rimnicu Vilcea 父节点:Sibiu 路径损失为:220
孩子节点:Sibiu 路径损失为:300
孩子节点:Craiova 路径损失为:366
添加孩子到优先队列
孩子节点:Pitesti 路径损失为:317
添加孩子到优先队列
处理城市节点:Lugoj 父节点:Timisoara 路径损失为:229
孩子节点:Timisoara 路径损失为:340
孩子节点:Mehadia 路径损失为:299
添加孩子到优先队列
处理城市节点:Fagaras 父节点:Sibiu 路径损失为:239
孩子节点:Sibiu 路径损失为:338
孩子节点:Bucharest 路径损失为:450
添加孩子到优先队列
处理城市节点:Mehadia 父节点:Lugoj 路径损失为:299
孩子节点:Lugoj 路径损失为:369
孩子节点:Drobeta 路径损失为:374
添加孩子到优先队列
处理城市节点:Pitesti 父节点:Rimnicu Vilcea 路径损失为:317
孩子节点:Rimnicu Vilcea 路径损失为:414
孩子节点:Craiova 路径损失为:455
孩子节点:Bucharest 路径损失为:418
替换状态: Bucharest 旧的损失:450 新的损失:418
处理城市节点:Craiova 父节点:Rimnicu Vilcea 路径损失为:366
孩子节点:Drobeta 路径损失为:486
孩子节点:Rimnicu Vilcea 路径损失为:512
孩子节点:Pitesti 路径损失为:504
处理城市节点:Drobeta 父节点:Mehadia 路径损失为:374
孩子节点:Mehadia 路径损失为:449
孩子节点:Craiova 路径损失为:494
处理城市节点:Bucharest 父节点:Pitesti 路径损失为:418
目的地已经找到了
从城市: Arad 到城市 Bucharest 查找成功
Arad->Sibiu->Rimnicu Vilcea->Pitesti->Bucharest

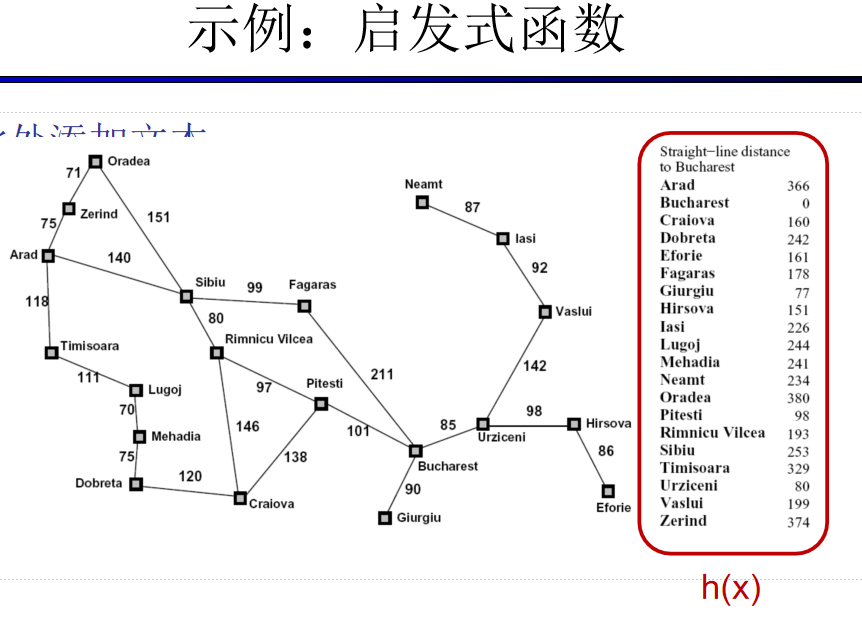

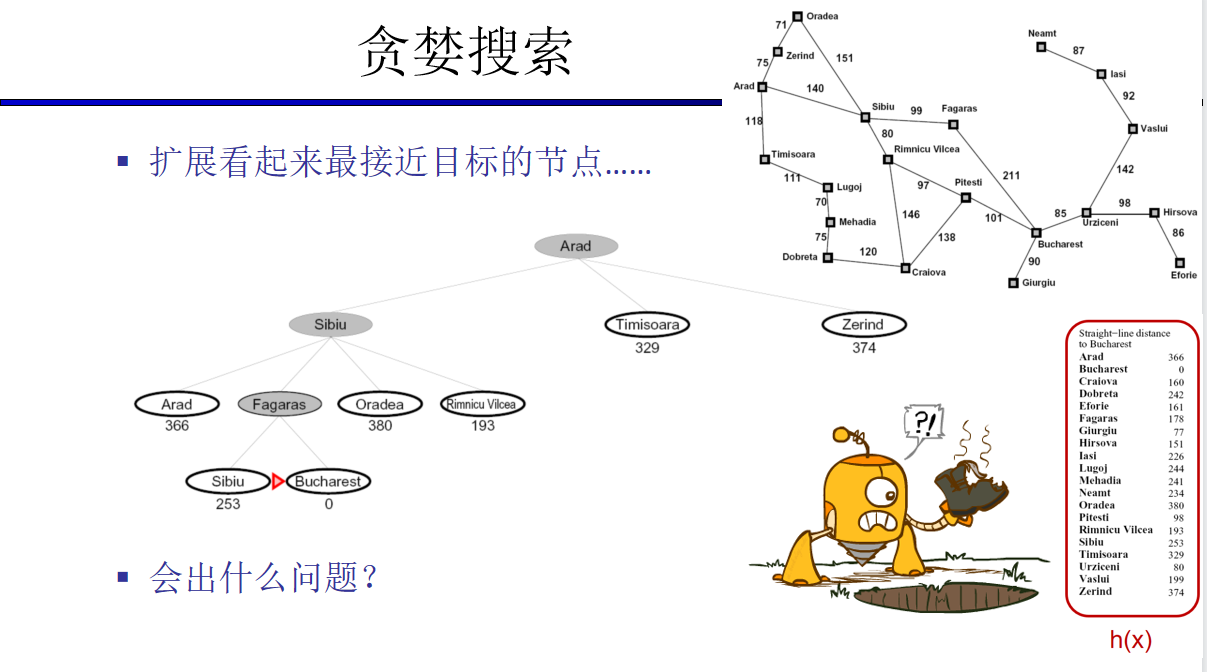
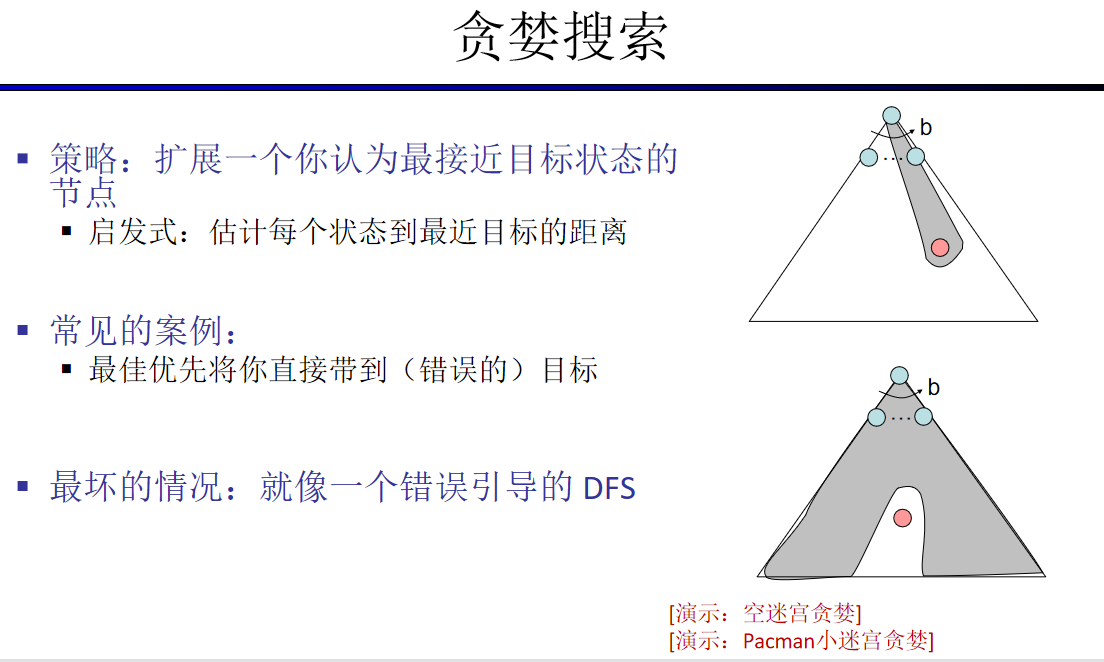


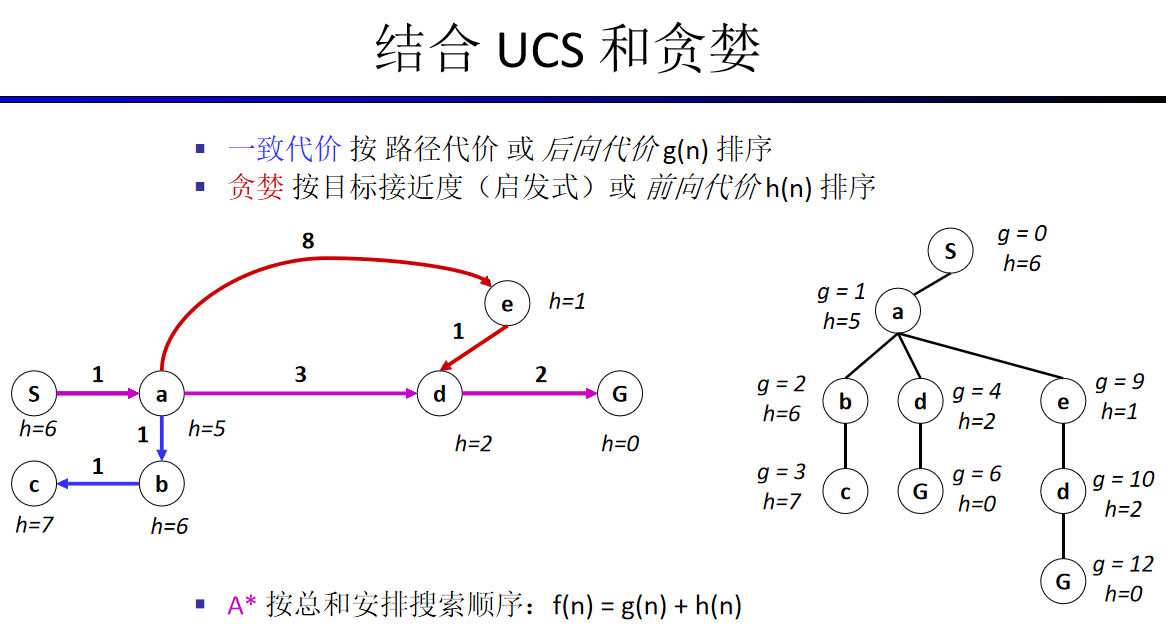

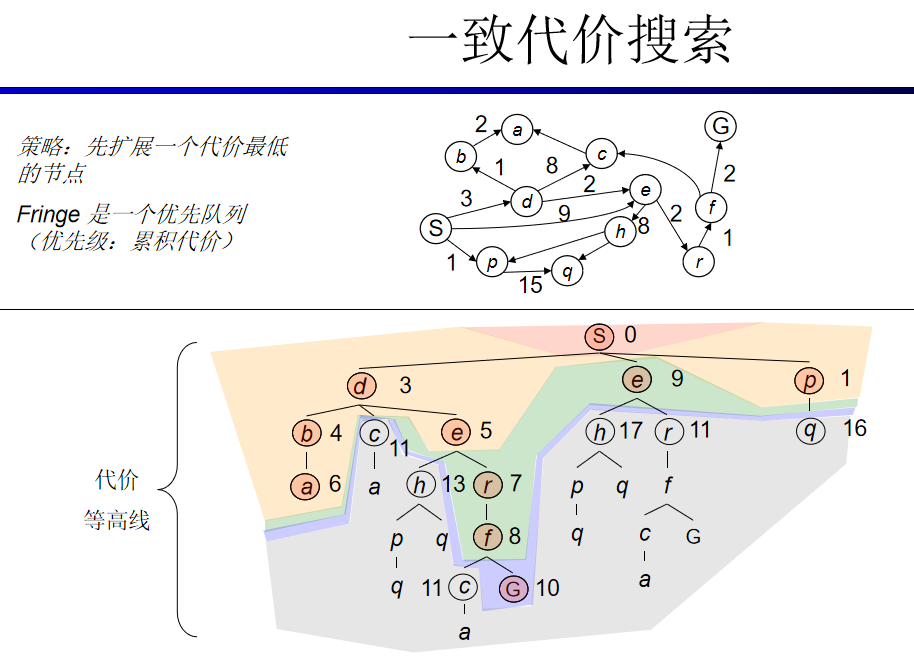
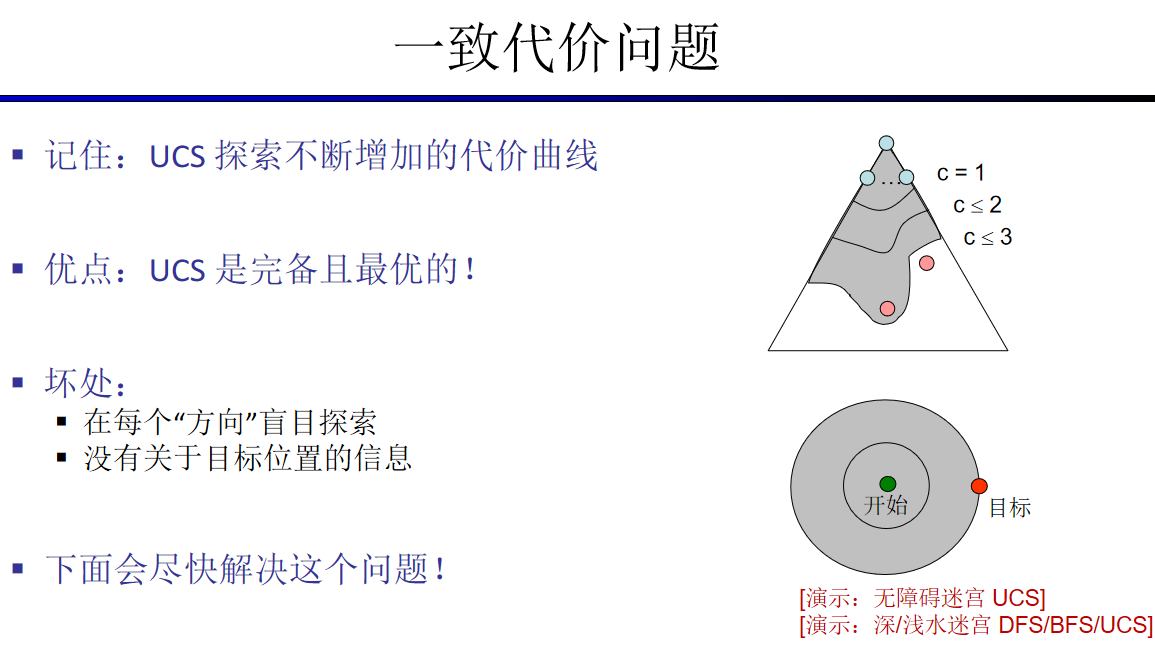
启发式搜索通常是松弛问题




A*搜索与一致代价搜索类似,
除了A*使用g+h而不是g。
A*搜索既是完备的也是最优的。


(1)一种极端情况,如果h(n)是0,则只有g(n)起作用,此时A* 算法演变成Dijkstra算法,就能保证找到最短路径。
(2)如果h(n)总是比从n移动到目标的代价小(或相等),那么A* 保证能找到一条最短路径。h(n)越小,A* 需要扩展的点越多,运行速度越慢。
(3)如果h(n)正好等于从n移动到目标的代价,那么A* 将只遵循最佳路径而不会扩展到其他任何结点,能够运行地很快。尽管这不可能在所有情况下发生,但你仍可以在某些特殊情况下让h(n)正好等于实际代价值。只要所给的信息完善,A* 将运行得很完美。
(4)如果h(n)比从n移动到目标的代价高,则A* 不能保证找到一条最短路径,但它可以运行得更快。
所以h(n)的选择成了一个有趣的情况,它取决于我们想要A* 算法中获得什么 结果。h(n)合适的时候,我们会非常快速地得到最短路径。如果h(n)估计的代价太低,我们仍会得到最短路径,但运行速度会减慢。如果估计的代价太高,我们就放弃最短路径,但A* 将运行得更快。
欧几里得距离就是上面的绿线,即欧氏距离




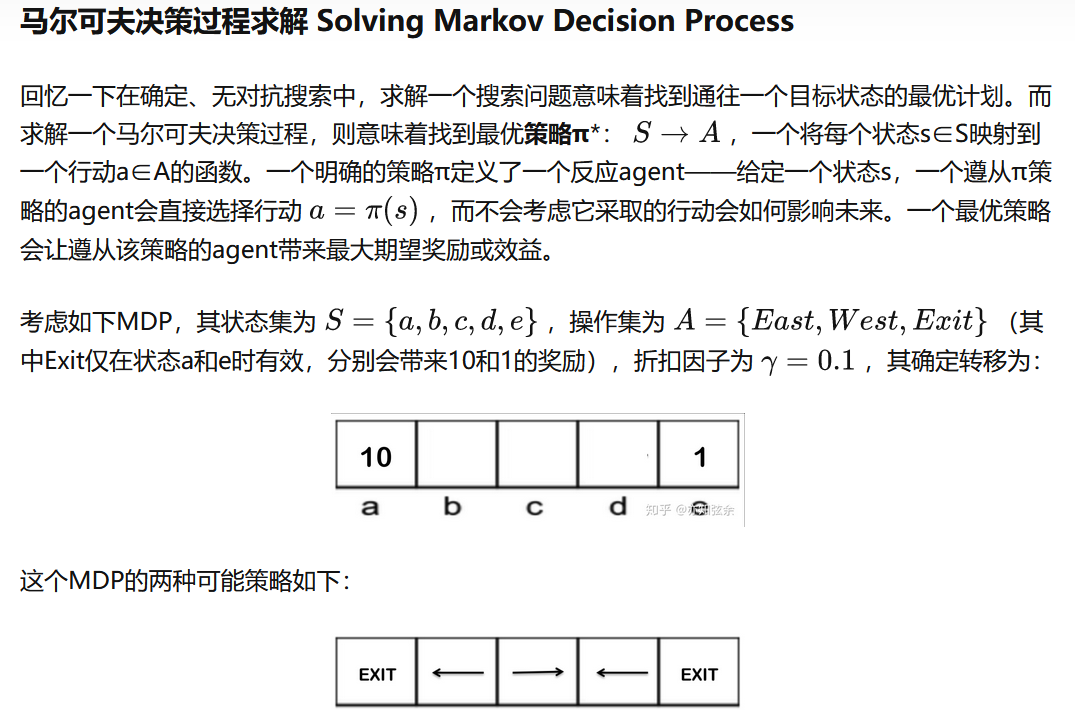
我们来介绍第二个CSP的例子:地图着色问题。这类问题是指,我们要用一些给定的颜色来给地图上色,并且相邻区域的的颜色必须不同。
约束满足问题常用约束图来表示,其中节点代表变量,边则代表变量之间的约束。有许多种不停的约束,每一种的解决方式也都不同:
我们来看一下澳大利亚地图的染色:
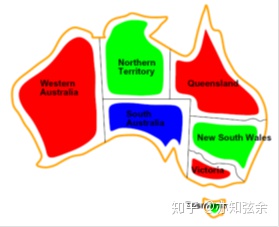
这个问题中的约束就是相邻区域颜色不能相同。于是,通过在每两个相邻的区域之间画一条边,我们能得到澳大利亚地图染色问题的约束图:
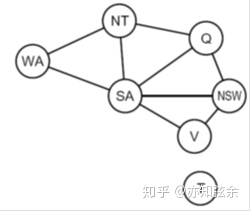
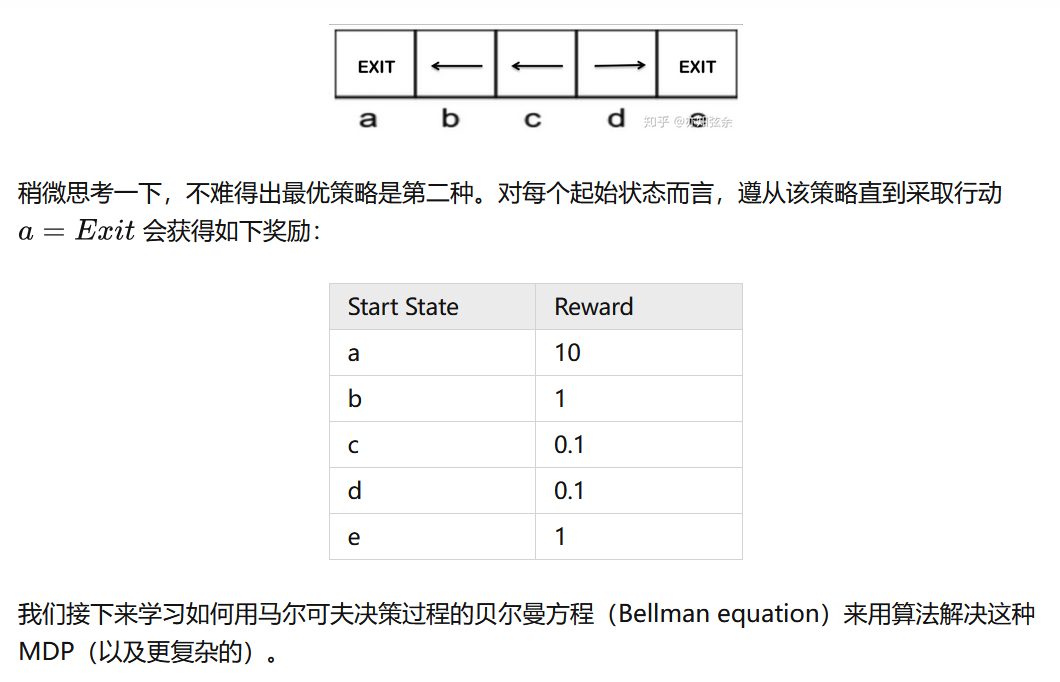
约束图的价值在于能帮助我们提取CSP的结构的有效信息。通过分析CSP的图,我们能确定关于它的一下信息,比如其连接/约束是稀疏还是紧密,或者它是否是树状的。在我们详细讨论求解约束满足问题时我们会深挖这些问题。
约束满足问题的传统解法是使用一种叫做回溯搜索(Backtracking search)的算法。回溯搜索是对专门针对约束满足问题的DFS的最优化,主要改善了两个法则:
迭代回溯过程的伪代码如下:

为了让这个过程更直观,我们来看一下分别用深度优先搜索和回溯搜索解决地图染色问题的局部搜索树:
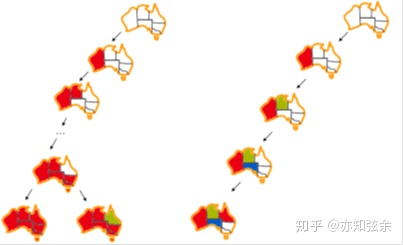
注意DFS在意识到问题之前已经把所有部分都涂成了红色,即便如此,也没有往正确的方向做出多少改变。另一方面,回溯搜索在一个值没有违背任何约束时将其赋值给一个变量,这样能明显减少回溯的次数。虽然回溯搜索相比较深度优先搜索的霸王硬上弓要有了很大的改进,我们仍然可通过过滤、变量/值的排序和结构上的探索进一步提高速度。

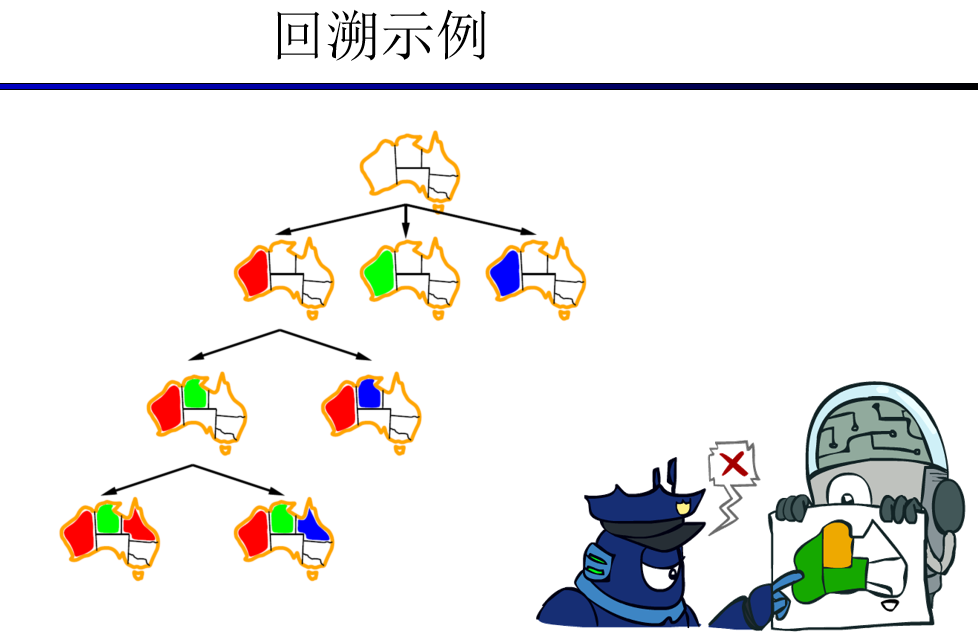
回溯 = DFS + 变量排序 + 失败(不相容)回溯
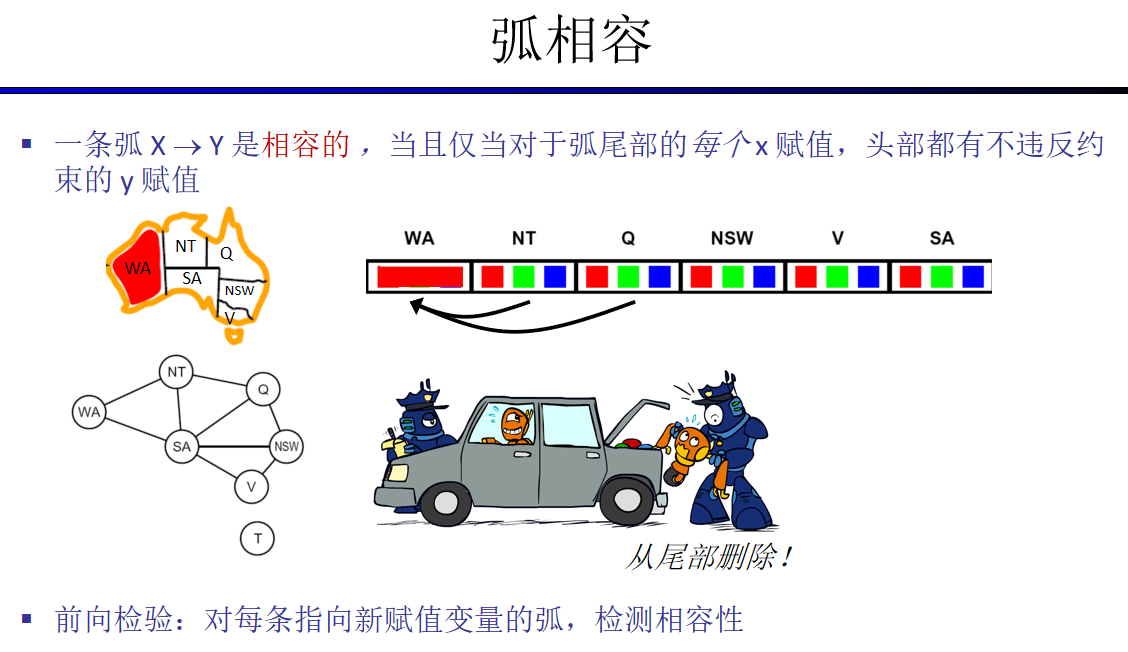
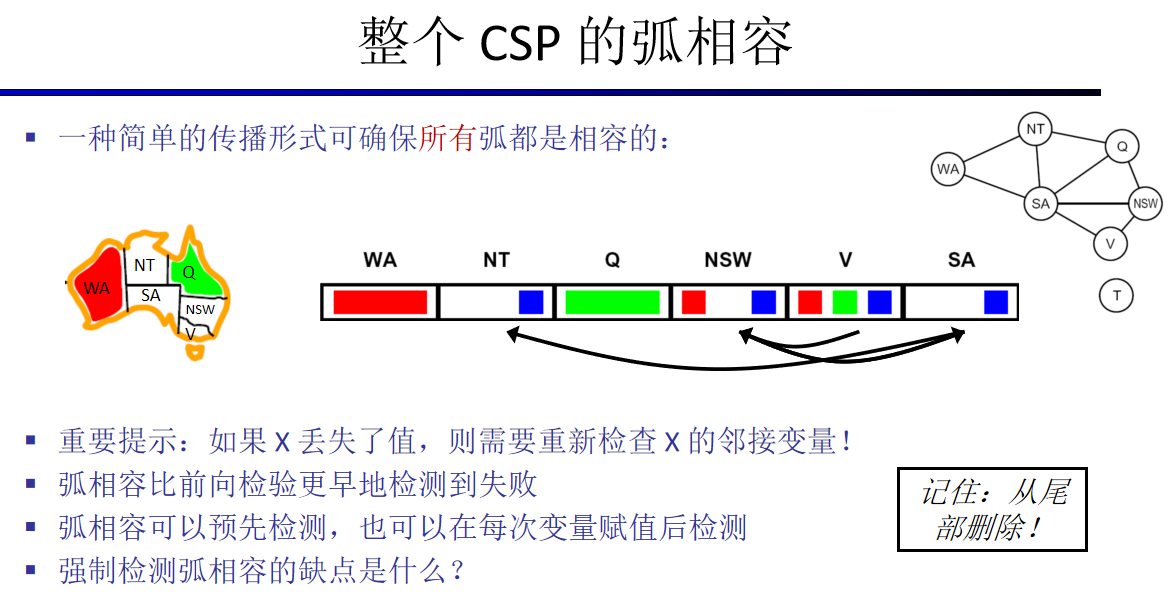
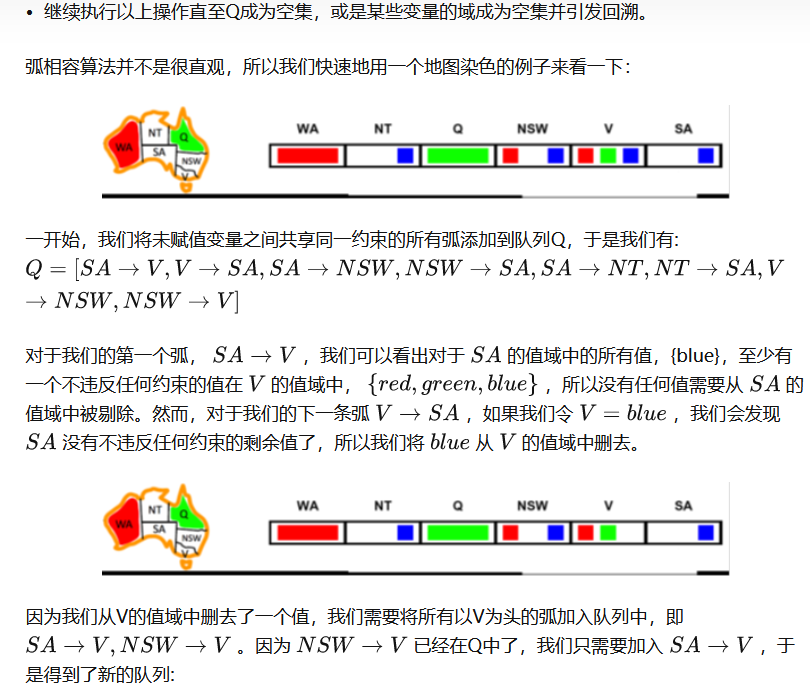
弧相容就是值域被删除的点要检查其所有相邻点的值域有无违反约束



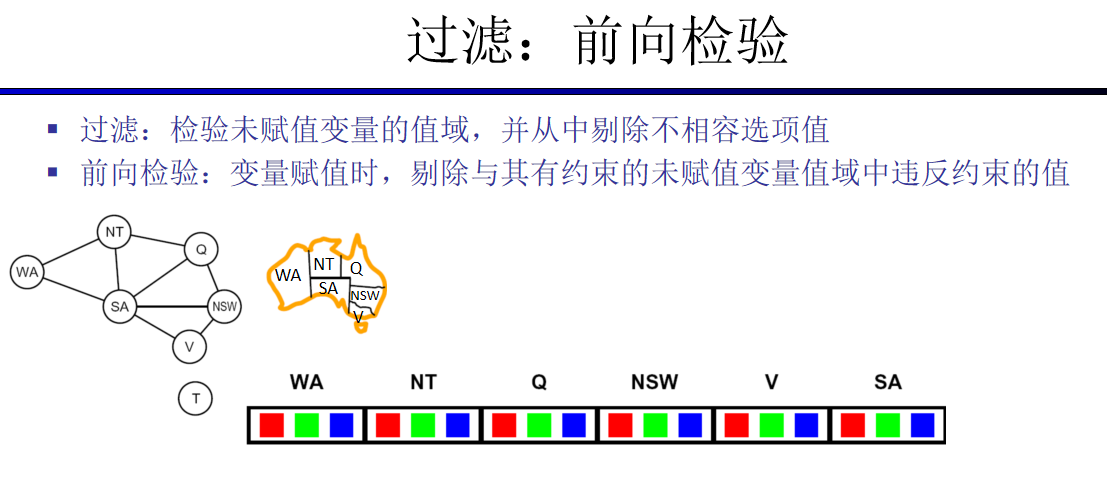
前向检测是一种深度优先搜索策略,它是回溯法的一种扩展。它采用了“向前看”的策略,即对一个变量进行赋值时,修改约束条件下相关变量的值域。其过程如下:
选择一个变量。
遍历变量值域。
根据变量的赋值,调整相关变量的值域空间。若不会导致DWO(Domain Wipe Out)则往下递归。
若有解则结束。否则恢复相关变量的值域空间,并回到步骤2。
该局部状态无解(对于步骤1选择变量,可使用启发式搜索优化。如MRV启发式,优先选择值域空间小的变量。)
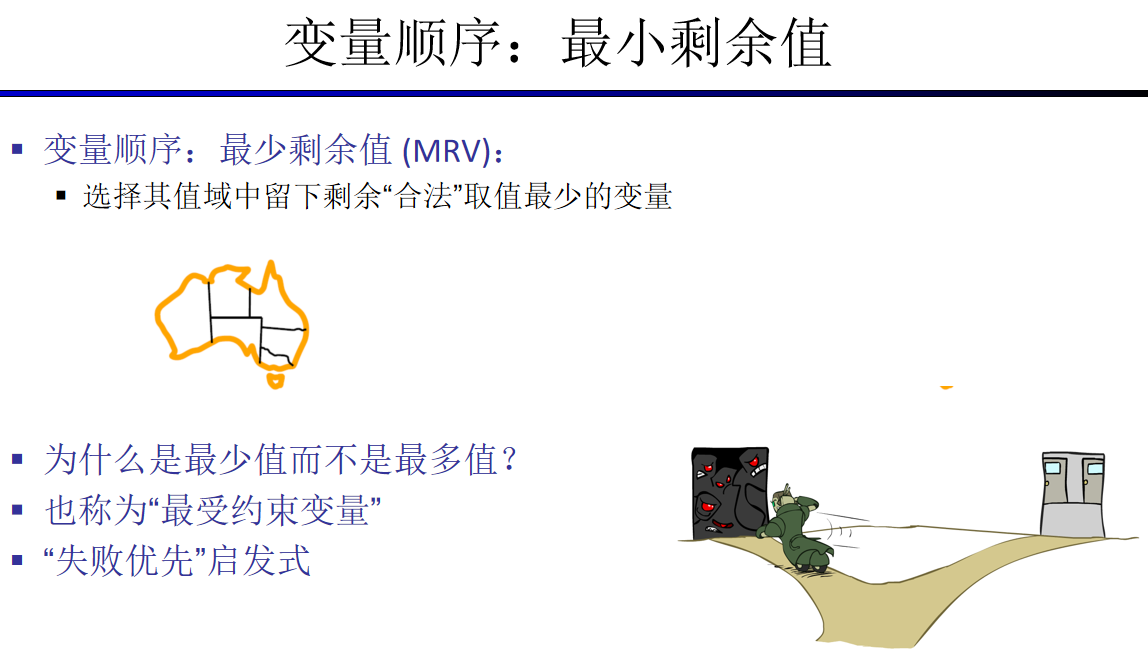
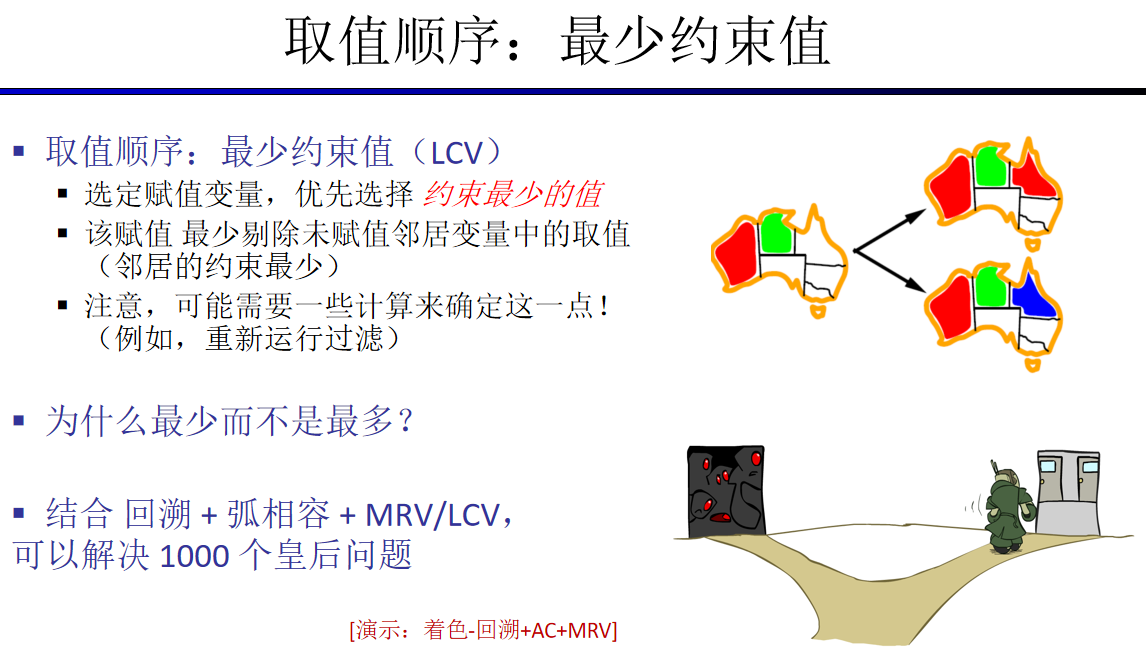
我们已经提到过,在解决CSP问题时,我们对涉及到的变量和值都进行排序。在实践中,使用两个基本原则——最小剩余值(minimum remaining values)和最少约束值(least constraining value)来“动态”地计算下一个变量和相应的值,通常要高效得多:
前言


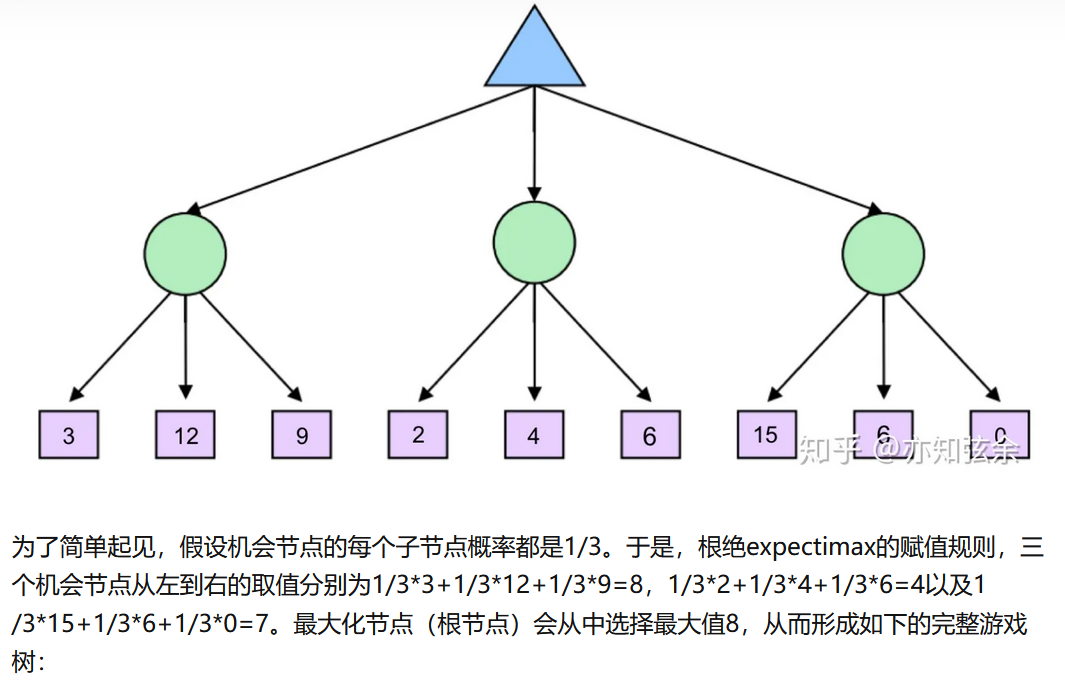
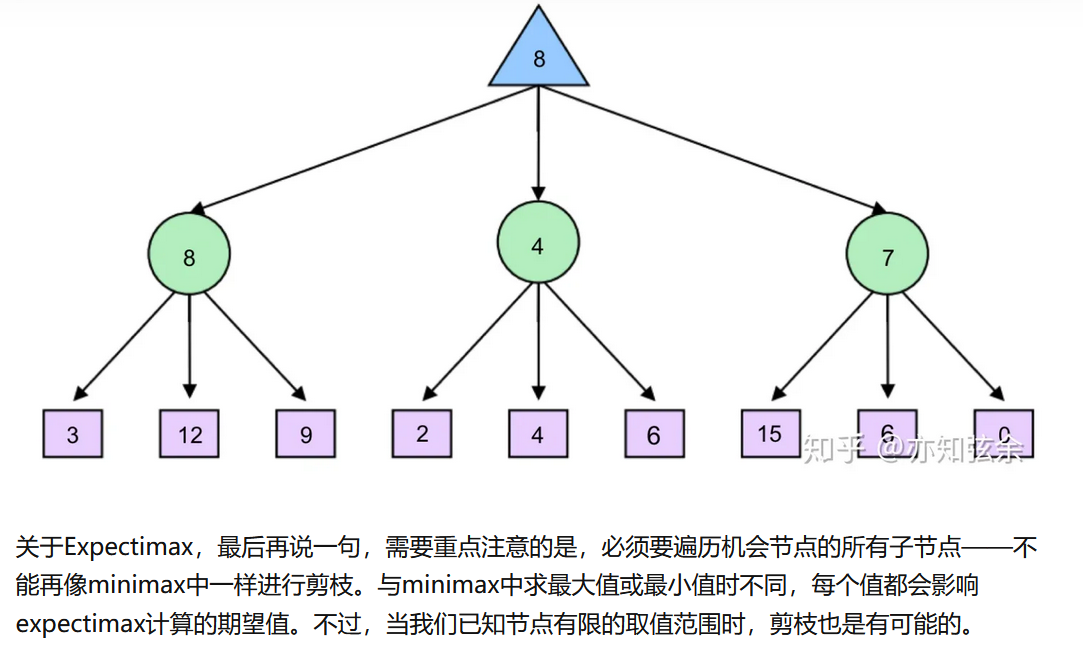

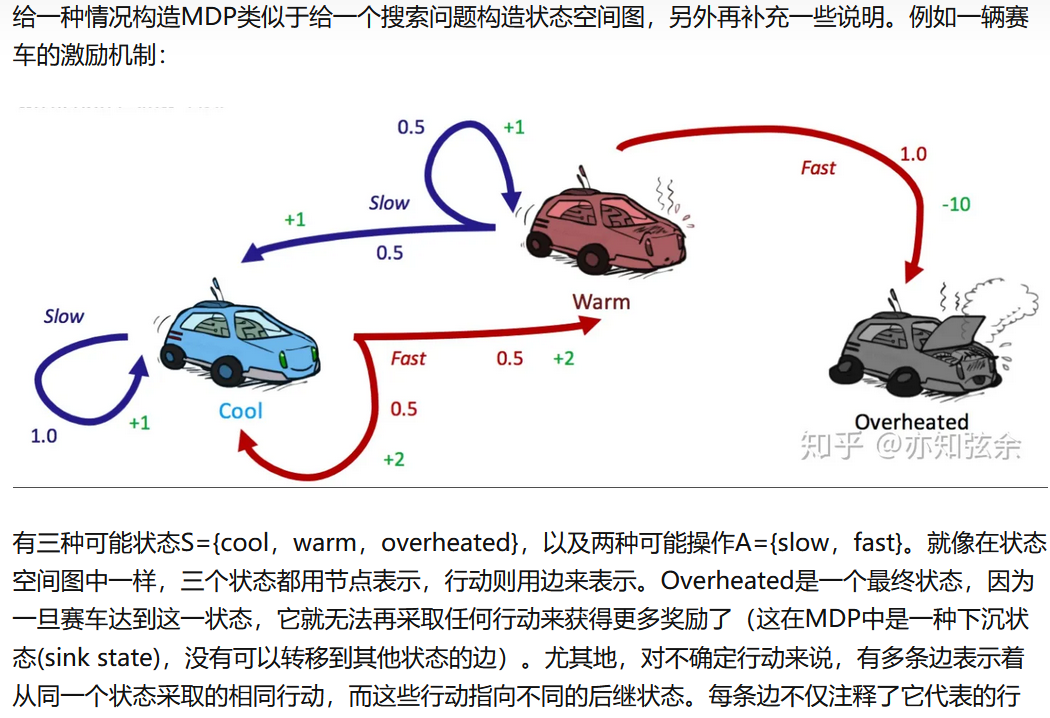
T就是概率函数,在下面的例子中就是0.5或者1,表示状态s采取a行动后得到状态s'的概率
R就是状态s采取a行动后得到状态s'的奖励,在下面的例子中奖励有1,2,-10


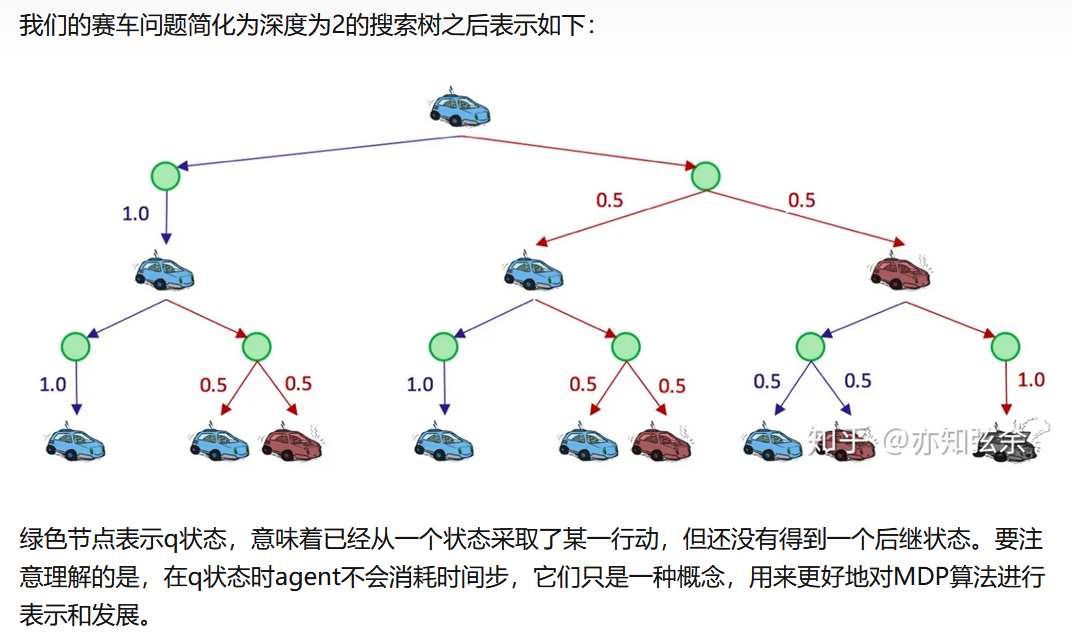








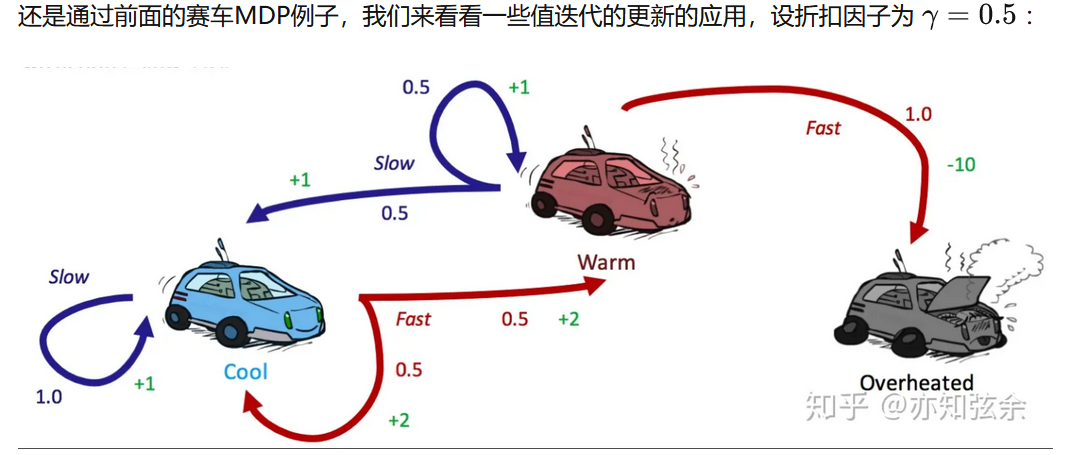

上面的V1(warm),+的位置写错了,注意了。
以V1(cool)为例
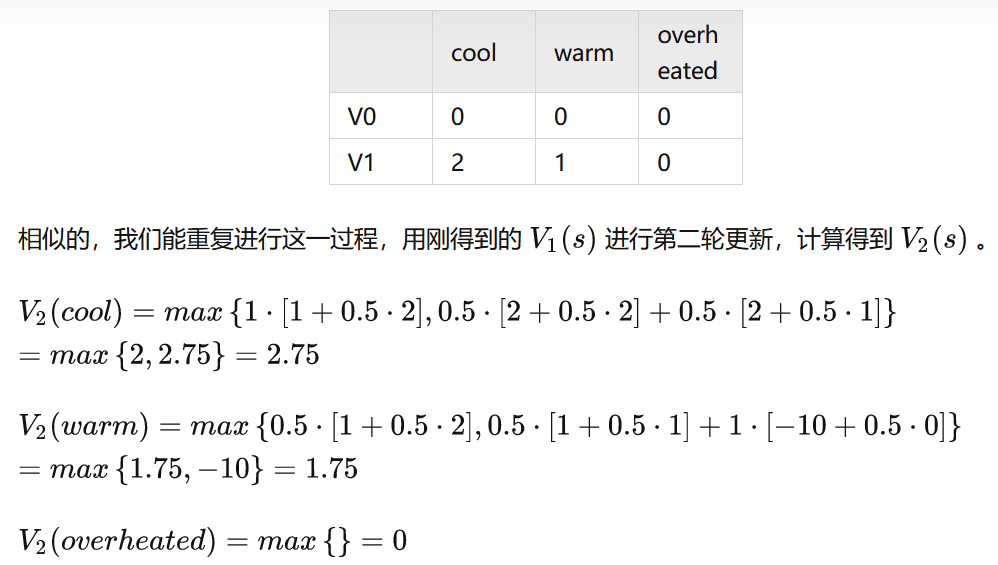
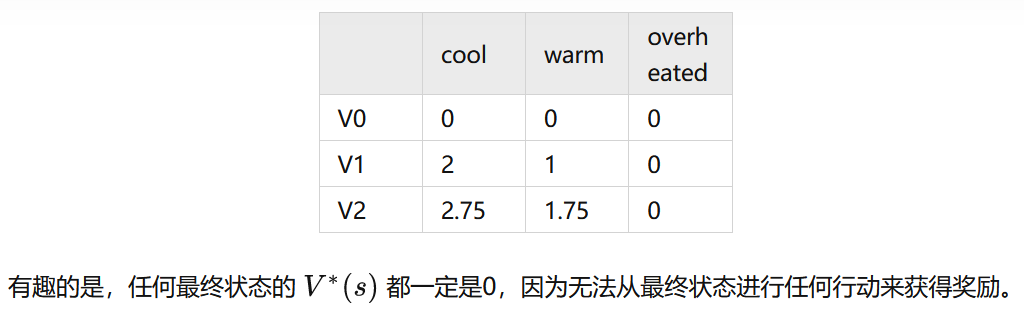



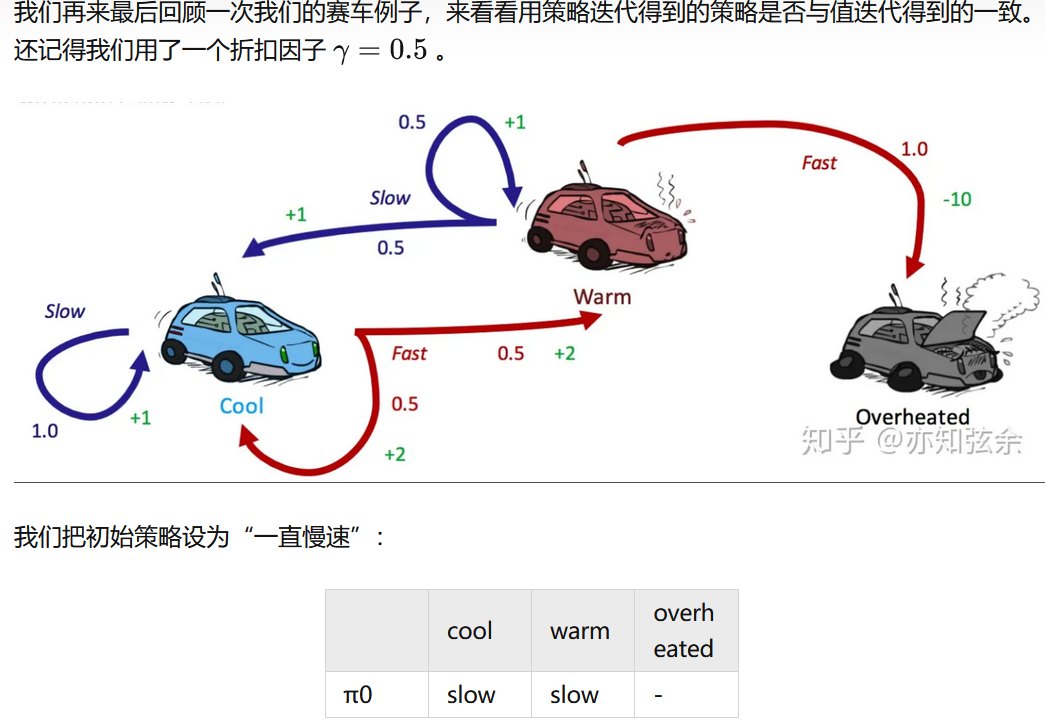
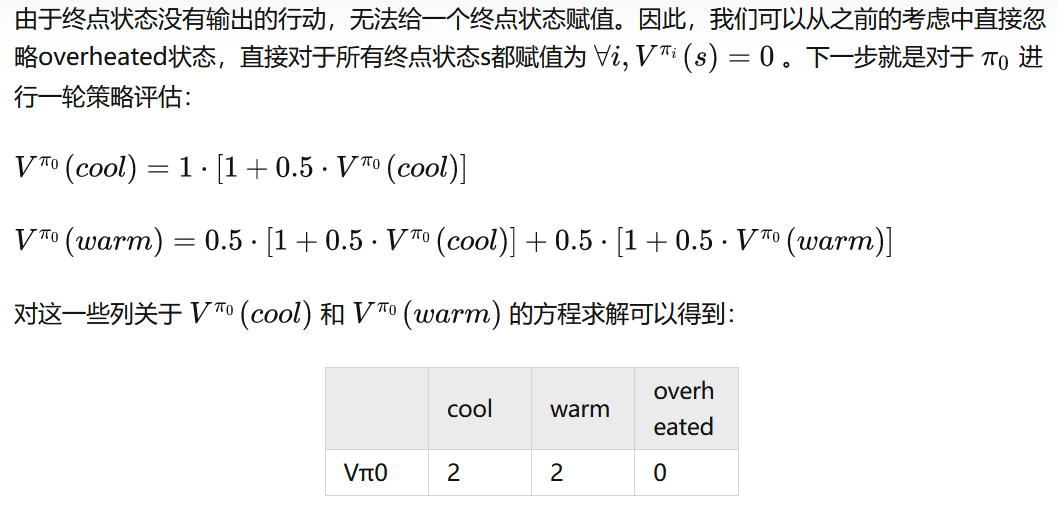

这个例子说明了值迭代真正的力量:只用两次迭代,我们就能得到赛车MDP的最优策略!这比在同一个MDP上进行值迭代要强多了,值迭代在进行这两次更新之后还要好多次迭代才能收敛。

将值迭代、策略评估、策略提取、策略迭代进行一个归纳总结:
先从贝尔曼方程开始,

在值迭代的第k轮,
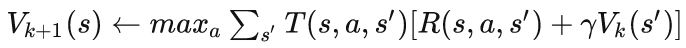

跟上面那个总结一样,值迭代用于计算状态的最优值。

总结就是:
值迭代的做题步骤:
1.设初值为0
2.重复求最优值操作直至收敛(按题目要求来,不一定要求到收敛,有些简单的题可以很快收敛)
3.收敛就是V*保持不变了

策略提取的背后的思想非常简单:如果你处于一种状态s,你应该采取会产生最大期望效益的行动a。
其实就是:最优值对应的行动a就是要提取的策略

总结:
策略迭代的做题步骤:
1.定义一个初始策略
2.对所有状态进行策略评估,评估次数不限,一般收敛了就停止评估了。(评估次数由题目来定)
3.用策略评估的值进行策略提取,提取次数不限,一般收敛了就停止提取了。(提取次数由题目来定)
4.策略改进,其实就是将收敛的策略评估的策略作为最优策略
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
文章目录1、自相关函数ACF2、偏自相关函数PACF3、ARIMA(p,d,q)的阶数判断4、代码实现1、引入所需依赖2、数据读取与处理3、一阶差分与绘图4、ACF5、PACF1、自相关函数ACF自相关函数反映了同一序列在不同时序的取值之间的相关性。公式:ACF(k)=ρk=Cov(yt,yt−k)Var(yt)ACF(k)=\rho_{k}=\frac{Cov(y_{t},y_{t-k})}{Var(y_{t})}ACF(k)=ρk=Var(yt)Cov(yt,yt−k)其中分子用于求协方差矩阵,分母用于计算样本方差。求出的ACF值为[-1,1]。但对于一个平稳的AR模型,求出其滞
前面一篇关于智能合约翻译文讲到了,是一种计算机程序,既然是程序,那就可以使用程序语言去编写智能合约了。而若想玩区块链上的项目,大部分区块链项目都是开源的,能看得懂智能合约代码,或找出其中的漏洞,那么,学习Solidity这门高级的智能合约语言是有必要的,当然,这都得在公链``````以太坊上,毕竟国内的联盟链有些是不兼容Solidity。Solidity是一种面向对象的高级语言,用于实现智能合约。智能合约是管理以太坊状态下的账户行为的程序。Solidity是运行在以太坊(Ethereum)虚拟机(EVM)上,其语法受到了c++、python、javascript影响。Solidity是静态类型
写在之前Shader变体、Shader属性定义技巧、自定义材质面板,这三个知识点任何一个单拿出来都是一套知识体系,不能一概而论,本文章目的在于将学习和实际工作中遇见的问题进行总结,类似于网络笔记之用,方便后续回顾查看,如有以偏概全、不祥不尽之处,还望海涵。1、Shader变体先看一段代码......Properties{ [KeywordEnum(on,off)]USL_USE_COL("IsUseColorMixTex?",int)=0 [Toggle(IS_RED_ON)]_IsRed("IsRed?",int)=0}......//中间省略,后续会有完整代码 #pragmamulti_c
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是