关注公众号,发现CV技术之美

论文链接:https://arxiv.org/abs/2205.09113
项目链接:尚未开源
01
摘要
02
Motivation
深度学习社区正在经历一种趋势,即统一解决不同领域问题的方法,如语言、视觉、言语等。在架构方面,transformer已成功地引入计算机视觉,并被确立为语言和视觉的通用构建块。对于自监督表征学习,BERT中的去噪/屏蔽自动编码(masked autoencoding)方法已被证明对从图像中学习视觉表征有效。为了统一方法,针对特定问题只引入了较少的领域知识,这促使模型几乎完全从数据中学习有用的知识。
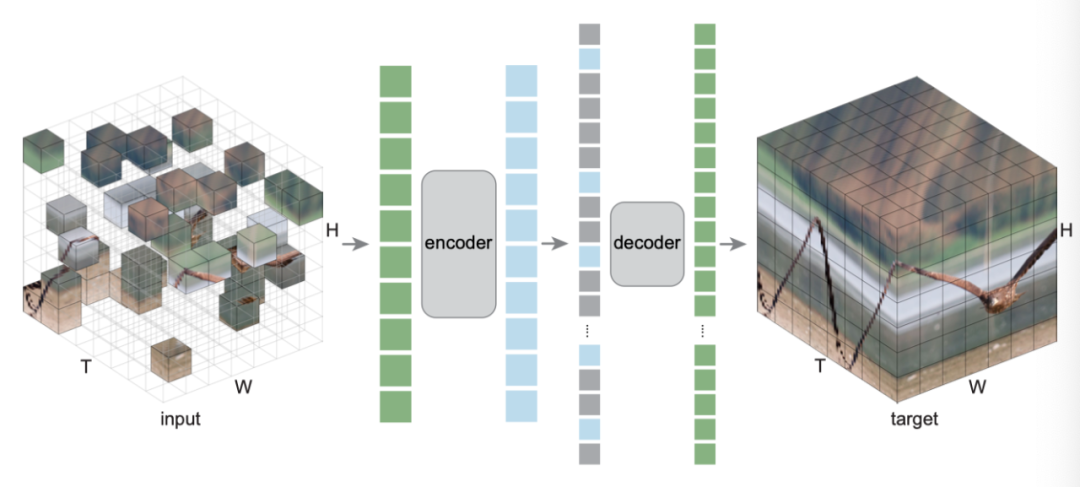
遵循这一理念,作者研究将MAE扩展到时空表征学习问题。本文的方法很简单:作者随机屏蔽视频中的时空patch,并学习自动编码器来重建它们(如上图)。本文的方法具有最小的领域知识:唯一的时空特异归纳偏差是embedding patch及其位置;所有其他组件对问题的时空性质都是不可知的。
特别是,本文的编码器和解码器都是普通的视觉Transformer,没有分解或层次结构,本文的随机mask采样对时空结构是不可知的。本文的方法预测像素值,并且不使用额外的问题特定tokenizer。简而言之,本文的方法简单地应用于时空patch集。尽管归纳偏差最小,但本文的方法取得了强有力的实证结果,表明可以从数据中学习有用的知识。

MAE的文献中假设,掩蔽自动编码方法中的掩蔽率(即移除token的百分比)与问题的信息冗余有关。例如,自然图像比语言具有更多的信息冗余,因此最佳掩蔽率更高。本文对视频数据的观察支持这一假设。作者发现,视频的MAE最佳掩蔽率为90%(如上图所示),高于对应图像的75%掩蔽率。这可以理解为自然视频数据在时间上相关的结果。极端的情况是,如果一个视频有T个相同的静态帧,则对所有时空patch进行1/T的随机采样将显示出大部分静态帧。因为在自然视频中,慢动作比快动作更容易发生,所以根据实验观察,掩蔽率可能非常高。
掩蔽率越高,实际解决方案越有效。MAE仅对可见token应用编码器之后,90%的掩蔽率将编码器时间和内存复杂性降低到<1/10。结合一个小型解码器,MAE预训练与编码所有token相比,理论上可以减少7.7倍的计算量。事实上,计算量大到数据加载时间成为新的瓶颈;即便如此,作者还是记录到了4.1倍的wall-clock加速。如此显著的加速对于大规模且耗时的视频研究非常重要。
作者报告了在各种视频识别数据集上的强大结果。MAE预训练极大地提高了泛化性能:在Kinetics-400上,与从头开始的训练相比,它将ViT-Large的准确率提高了13%,而总的来说,它需要更少的wall-clock训练时间(预训练加上微调)。本文的MAE预训练可以大大超过其监督的预训练对手。通过使用vanilla ViT,本文的方法与以前采用更多领域知识的SOTA法相比,取得了具有竞争力的结果。作者还报告了使用MAE对100万个随机、未经处理的Instagram视频进行预训练的结果。这些结果表明,在一个统一的框架下,视频的自监督学习可以以类似于语言和图像的方式进行。
03
方法
本文的方法是MAE对时空数据的简单扩展,目标是在通用和统一的框架下开发该方法,尽可能少地使用领域知识。
根据原始ViT,给定一个视频片段,作者将其划分为一个规则的网格,其中包含时空中不重叠的patch。patch通过线性投影进行铺展和嵌入。位置嵌入添加到嵌入patch中。patch和位置嵌入过程是唯一具有时空感知的过程。
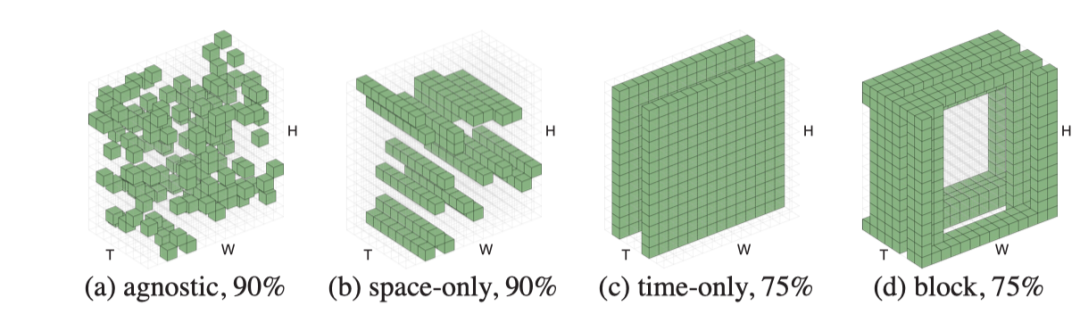
作者从嵌入的patch集中随机抽取patch。这种随机抽样与时空结构无关,如上图a。这种结构不可知的采样策略类似于1D中的BERT和2D中的MAE。
MAE中假设最佳掩蔽率与数据的信息冗余相关。对于非结构化随机掩蔽,BERT对语言使用了15%的掩蔽率,而MAE对图像使用了75%的掩蔽率,这表明图像比语言有更多的信息冗余。本文对视频的实证结果支持这一假设。作者观察到视频的最佳掩蔽率为90%。这符合通常的假设,即由于时间相干性,自然视频比图像具有更多的信息冗余。下图显示了本文方法在掩蔽率为90%和95%的未知验证数据上的MAE重建结果。
时空不可知采样可以比结构感知采样策略更有效。如上图b和c所示,仅空间或仅时间采样可能保留较少的信息,并产生非常困难的预训练任务。例如,掩蔽率为87.5%的8帧仅进行时间采样意味着只保留一帧,这就提出了一项非常具有挑战性的任务,即仅在给定一帧的情况下预测未来和过去。作者观察到,结构感知采样的最佳掩蔽比通常较低。相比之下,时空不可知采样更好地利用了有限数量的可见patch,因此允许使用更高的掩蔽率。

我们的编码器是一种普通的ViT,仅适用于可见的嵌入patch集。这种设计大大减少了时间和内存复杂性,并带来了更实用的解决方案。90%的掩蔽率将编码器复杂度降低到<1/10。本文的解码器是另一种基于编码patch集和一组mask token的联合的普通ViT。解码器特定的位置嵌入被添加到此集合中。因为解码器被设计成比编码器小,所以虽然解码器处理整个集合,但其复杂性小于编码器。在本文的默认设置中,与完全编码相比,整个autoencoder的复杂度降低了7.7倍。
解码器预测像素空间中的patch。原则上,可以简单地预测一个完整的时空patch(例如,t×16×16);在实验中,作者发现预测patch的单个时间片(16×16)是足够的,这样可以保持预测层的大小可控。本文预测了原始像素或其每个patch的归一化值。训练损失函数是预测与其目标之间的均方误差(MSE),在未知patch上求平均值。编码器和解码器对问题的时空结构不可知。与SOTA结构相比,本文的模型没有层次结构或时空分解,只依赖于全局自注意力,从数据中学习有用的知识。
04
实验
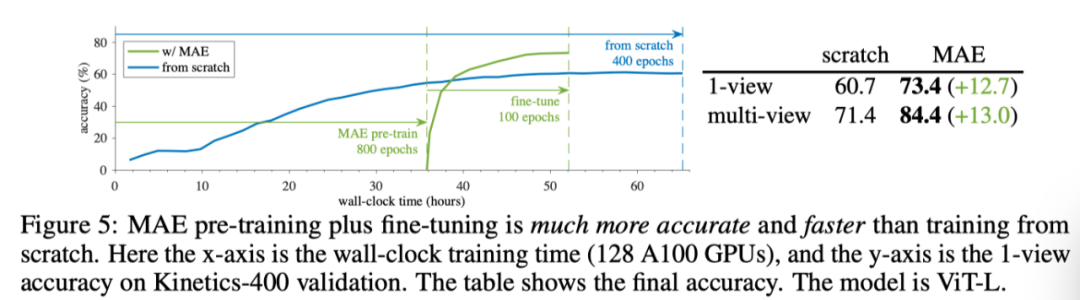
上图展示了使用标准ViT-L将MAE预训练与无预训练(即从头开始的训练)进行比较的结果。相比之下,使用MAE预训练800个epoch,相同ViT-L达到84.4%的准确率,与从头开始的训练相比,绝对值大幅增加13.0%。这一差距远大于图像识别任务的差距(∼ 3%),表明MAE预训练更有助于视频识别。
除了精度增益外,MAE预训练还可以降低总体训练成本,800 epoch MAE预训练仅需35.8小时。由于预训练,需要16.3小时的短时间微调,可以获得良好的精度。总体训练时间可以比从头开始的训练更短。这表明MAE是一种实用的视频识别解决方案。
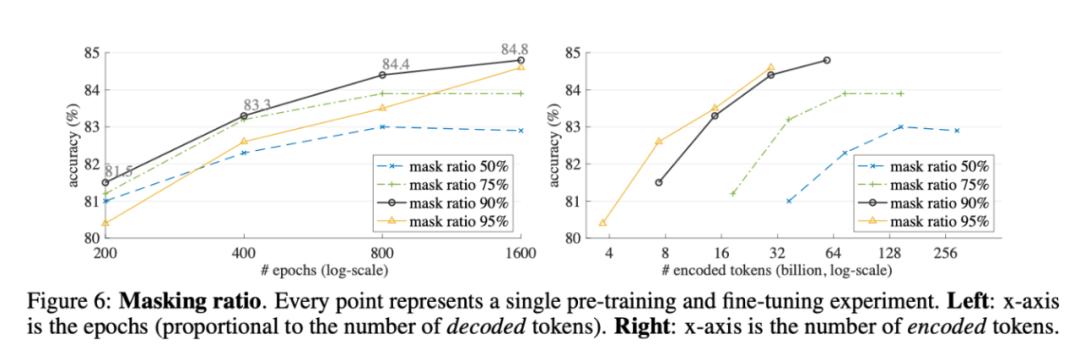
上图显示了掩蔽率与预训练周期的联合影响。90%的比例效果最好。95%的比例表现得出奇地好,如果训练足够长的时间,这可以会赶上。较高的掩蔽率导致编码器编码的token较少;为了更全面地查看,作者绘制了编码token总数和准确率的影响(上图右侧)。在这一衡量标准下,90%和95%的比率表现密切。
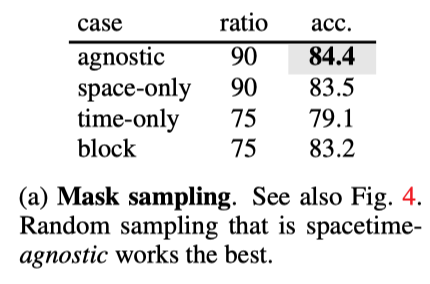
上表展示了不同mask策略的实验结果,可以看出随机采样的效果最好。
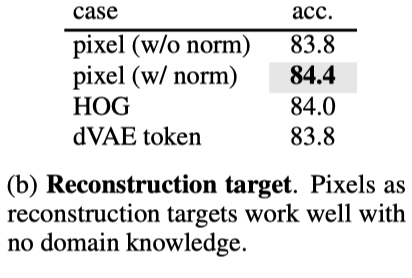
图展示了不同重建目标的实验结果。

上图展示了加入不同数据增强的实验结果。

由于本文的方法计算速度快,需要采用重复采样来减少数据加载开销。上表报告了其影响。重复使用2到4次可将wall-clock速度提高1.8倍或3.0倍,因为加载和解压缩的文件可重复使用多次。

上表展示了Decoder深度和宽度的影响。
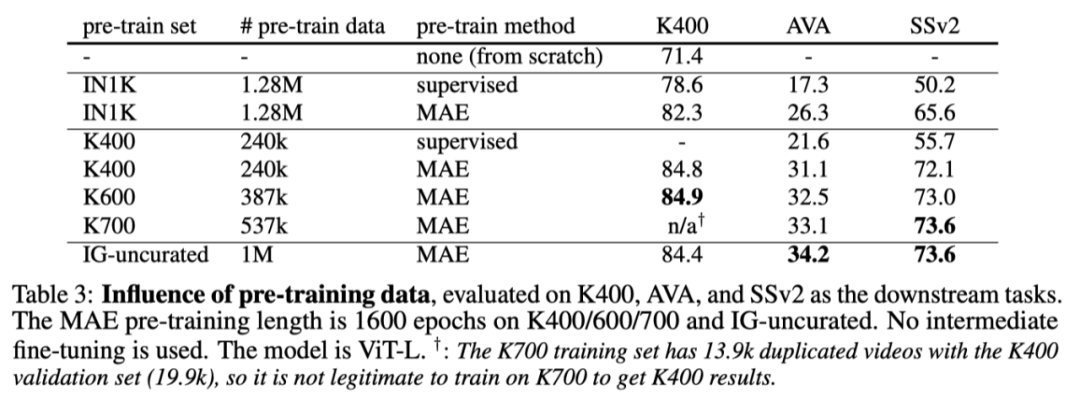
上表研究了不同数据集的预训练,并将其迁移到各种下游任务。
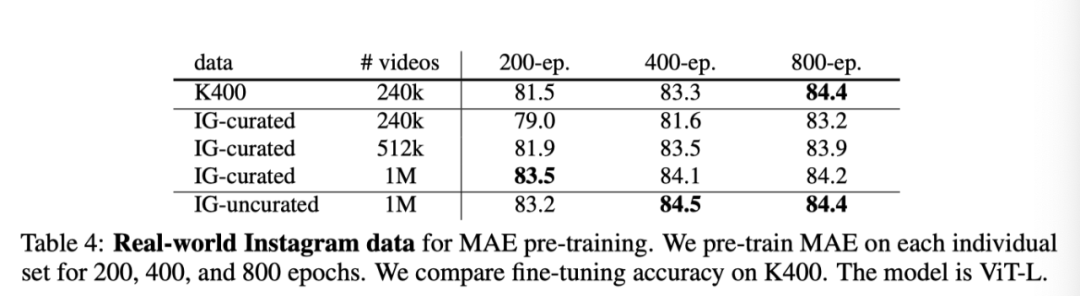
上表展示了用于MAE预训练的真实Instagram数据。作者对每一组MAE进行200、400和800个epoch的预训练,并比较了K400上的微调精度。模型为ViT-L。
05
总结
作者探索了MAE对视频数据的简单扩展,得出了一些有趣的观察结果:(i) 用最小的领域知识或归纳偏差学习强表示是可能的。这符合ViT工作的idea。与BERT和MAE类似,视频上的自监督学习可以在概念统一的框架中解决。(ii)本文的实验表明,掩蔽率是一般掩蔽自动编码方法的一个重要因素,其最佳值可能取决于数据的性质(语言、图像、视频等)。(iii)作者报告了关于真实世界、未经评估数据的预训练的结果。
尽管得到了这些观察结果,但仍然存在一些悬而未决的问题。本文研究的数据规模比语言对应的数据规模小几个数量级。虽然本文的方法在很大程度上提高了自监督学习的效率,但高维视频数据仍然是扩展的主要挑战。
[1]https://arxiv.org/abs/2205.09113

END
加入「计算机视觉」交流群👇备注:CV

动漫制作技巧是很多新人想了解的问题,今天小编就来解答与大家分享一下动漫制作流程,为了帮助有兴趣的同学理解,大多数人会选择动漫培训机构,那么今天小编就带大家来看看动漫制作要掌握哪些技巧?一、动漫作品首先完成草图设计和原型制作。设计草图要有目的、有对象、有步骤、要形象、要简单、符合实际。设计图要一致性,以保证制作的顺利进行。二、原型制作是根据设计图纸和制作材料,可以是手绘也可以是3d软件创建。在此步骤中,要注意的问题是色彩和平面布局。三、动漫制作制作完成后,加工成型。完成不同的表现形式后,就要对设计稿进行加工处理,使加工的难易度降低,并得到一些基本准确的概念,以便于后续的大样、准确的尺寸制定。四、
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
目前我正在使用这个正则表达式从YoutubeURL中提取视频ID:url.match(/v=([^&]*)/)[1]我怎样才能改变它,以便它也可以从这个没有v参数的YoutubeURL获取视频ID:http://www.youtube.com/user/SHAYTARDS#p/u/9/Xc81AajGUMU感谢阅读。编辑:我正在使用ruby1.8.7 最佳答案 对于Ruby1.8.7,这就可以了。url_1='http://www.youtube.com/watch?v=8WVTOUh53QY&feature=feedf'url
在神经网络方面,我完全是个初学者。我整天都在与ruby-fann和ai4r搏斗,不幸的是我没有任何东西可以展示,所以我想我会来到StackOverflow并询问这里的知识渊博的人。我有一组样本——每天都有一个数据点,但它们不符合我能够找出的任何明确模式(我尝试了几次回归)。不过,我认为看看是否有任何方法可以仅从日期预测future的数据会很好,而且我认为神经网络将是生成希望表达这种关系的函数的好方法.日期是DateTime对象,数据点是十进制数,例如7.68。我一直在将DateTime对象转换为float,然后除以10,000,000,000得到一个介于0和1之间的数字,我一直在将
我正在尝试训练一个前馈网络来使用Ruby库AI4R执行异或运算。然而,当我在训练后评估XOR时。我没有得到正确的输出。有没有人以前使用过这个库并得到它来学习异或运算。我使用了两个输入神经元,一个隐藏层中的三个神经元,一个输出层,正如我看到的预计算XOR前馈神经网络就像这样。require"rubygems"require"ai4r"#Createthenetworkwith:#2inputs#1hiddenlayerwith3neurons#1outputsnet=Ai4r::NeuralNetwork::Backpropagation.new([2,3,1])example=[[0,
关于yolov5训练时参数workers和batch-size的理解yolov5训练命令workers和batch-size参数的理解两个参数的调优总结yolov5训练命令python.\train.py--datamy.yaml--workers8--batch-size32--epochs100yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了。这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字。workers和batch-size参数的理解一般训练主要需要调整的参数是这两个:workers指数据装载时cpu所使
1.深度优先搜索(DFS)深度优先遍历主要思路是从图中一个未访问的顶点V开始,沿着一条路一直走到底,然后从这条路尽头的节点回退到上一个节点,再从另一条路开始走到底…,不断递归重复此过程,直到所有的顶点都遍历完成。例题P1605迷宫题目描述给定一个N×MN\timesMN×M方格的迷宫,迷宫里有TTT处障碍,障碍处不可通过。在迷宫中移动有上下左右四种方式,每次只能移动一个方格。数据保证起点上没有障碍。给定起点坐标和终点坐标,每个方格最多经过一次,问有多少种从起点坐标到终点坐标的方案。输入格式第一行为三个正整数N,M,TN,M,TN,M,T,分别表示迷宫的长宽和障碍总数。第二行为四个正整数SX,S
一、什么是web项目ui自动化测试?通过测试工具模拟人为操控浏览器,使软件按照测试人员的预定计划自动执行测试的一种方式,可以完成许多手工测试无法完成或者不易实现的繁琐工作。正确使用自动化测试,可以更全面的对软件进行测试,从而提高软件质量进而缩短迭代周期。二、构建测试用例的“九部曲”(一)创建流程包划分功能模块日常测试活动中,都会根据功能模块进行拆分,所以在设计器中我们可以通过创建流程包的方式来拆分需要测试的功能模块,如下图中操作创建一个电脑流程包并且取名为对应的功能模块名称,如果有多个功能模块就创建多个对应的流程包,实在RPA设计器有易用的图形可视化界面,方便管理较多的功能模块。(二)在流程包
目录需求基于JavaCV跨平台执行ffmpeg命令[^1]坑一内存不足坑二多个ffmpeg进程并行导致IO负载大,进而导致ioerror?坑三使用Java操作ffmpeg时,有时会卡死坑四Process的waitFor死锁问题及解决办法需求给透明背景的视频自动叠加一张背景图片基于JavaCV跨平台执行ffmpeg命令1我测试发现的本需求的最小依赖:dependency>groupId>org.bytedecogroupId>artifactId>ffmpeg-platform-gplartifactId>version>5.0-1.5.7version>dependency>核心代码:Stri