Towards Personalized Federated Learning
尝试记录一下最近看的论文,顺便当个笔记同步了。
这篇是个性化联邦学习的综述,Towards Personalized Federated Learning
传统联邦学习存在的问题及局限性:
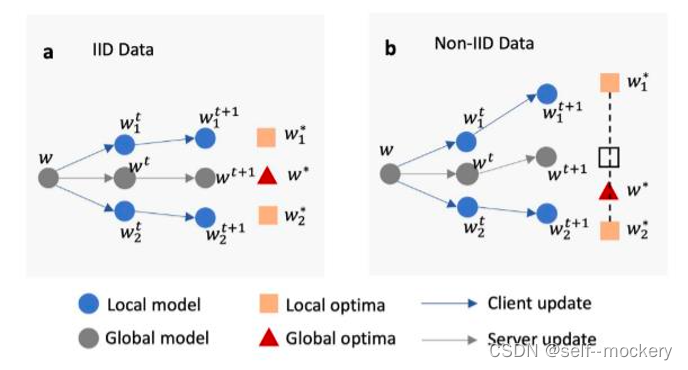
个性化联邦学习的主要策略: FL训练+本地适应训练
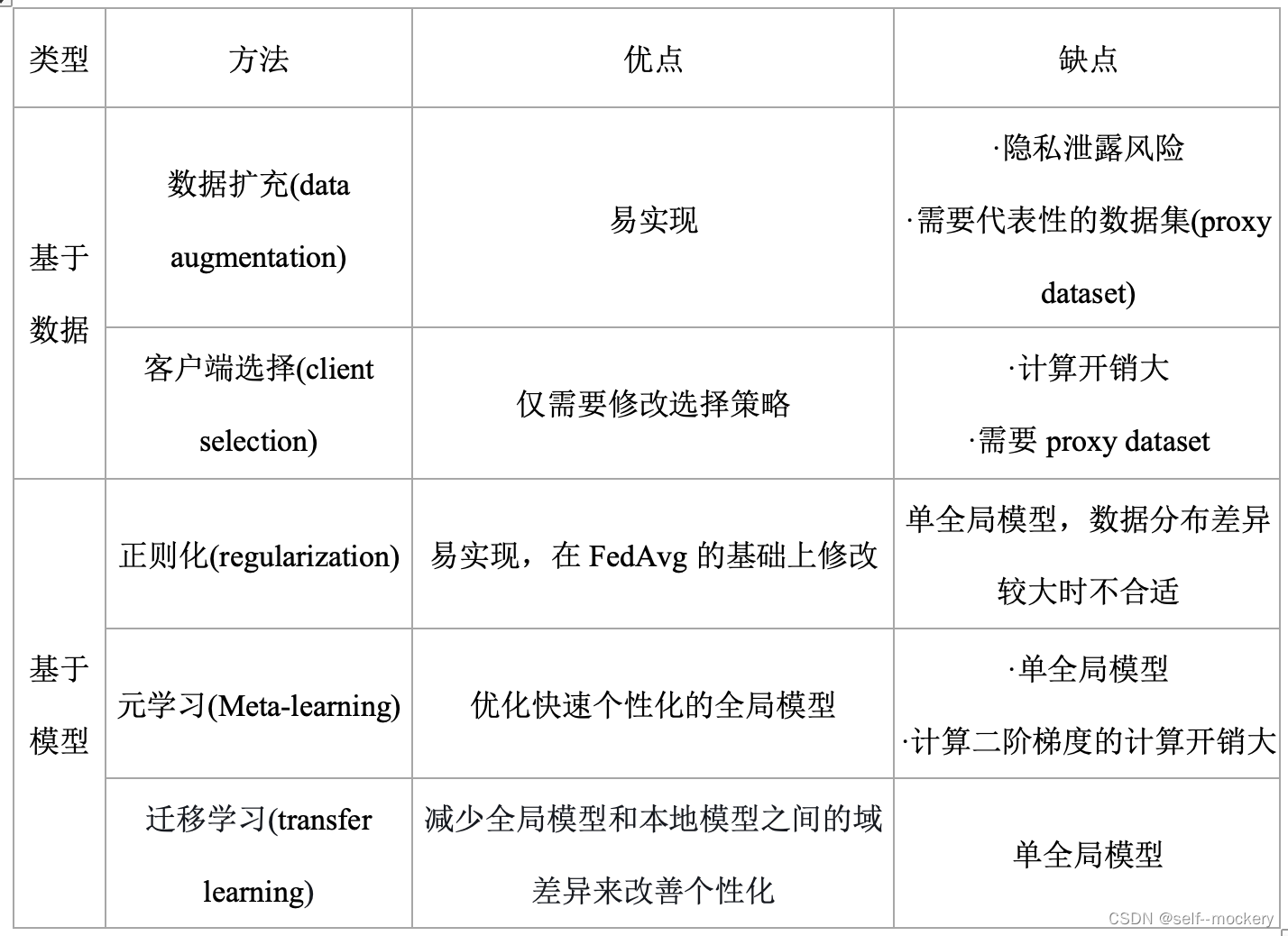
主要分为:
通过修改FL聚合过程来构建个性化模型
主要分为:
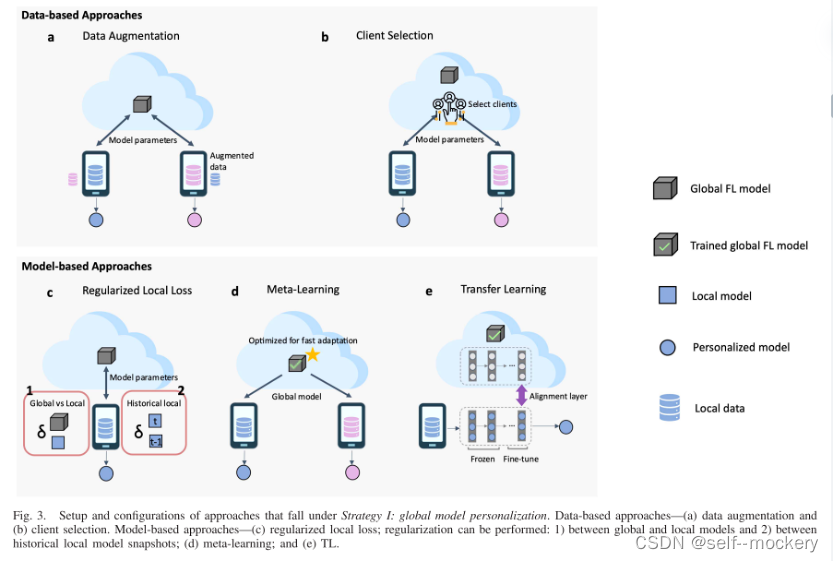
基于数据的缺点:需要修改本地数据分布,可能会导致丢失与客户个性化相关的数据信息。
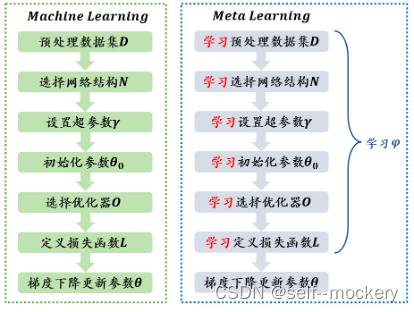
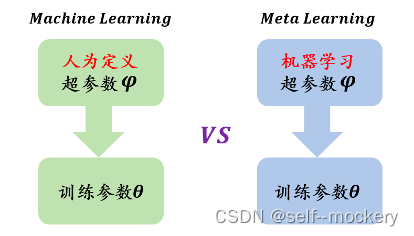
典型的元学习优化算法:模型不可知元学习(model agnostic meta- learn,MAML)
|
|
将元学习过程映射到FL过程中:元训练 —> FL全局训练; 元测试 —> FL个性化过程
(1) Pre-FedAvg[9],是在MAML基础上的FedAvg变种,以学习一个性能较好的初始全局模型
(2) pFedMe[10],在Pre-FedAvg的基础上优化,利用莫罗包络(Moreau envelopes),提高了准确性和收敛速率
(3) ARUBA框架[11],基于在线学习,实现FL设置下的自适应元学习。与FedAvg结合使用时,它提高了模型泛化性能,并消除了个性化过程中超参数优化的需要。
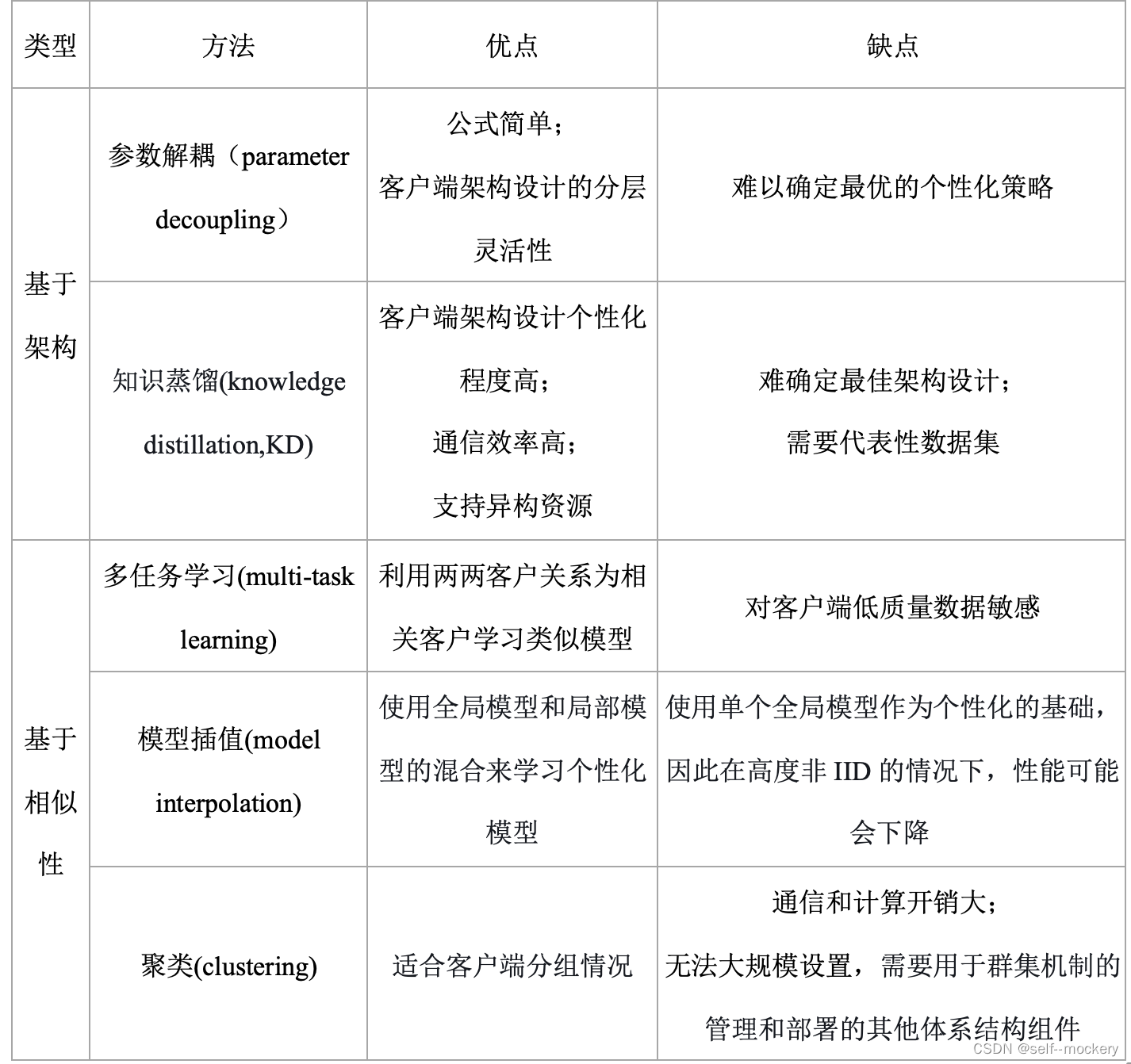
• 基于架构(architecture-based)
• 基于相似性(similarity-based)
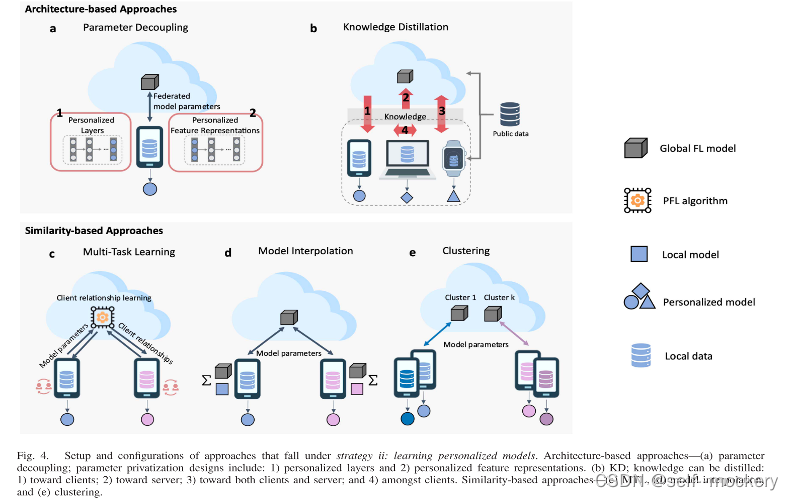
• 参数解耦(parameter decoupling):实现每个客户端的个性化层
• KD:支持每个客户端的个性化模型架构
VS 拆分学习(split learning, SL):在SL中,深度网络在服务器和客户端之间按层划分。与参数解耦不同,SL中的服务器模型不会转移到客户端进行模型训练。相反,在前向传播期间仅共享客户端模型的分离层的权重,而在反向传播期间,来自分离层的梯度与客户端共享。因此,与FL相比,SL具有隐私优势,因为服务器和客户端无法完全访问全局和本地模型。但是,由于顺序的客户端训练过程,训练效率较低。SL在非IID数据上的表现也比FL差,通信开销更高。
(1)基础层+个性化层[15]:基础层与FL服务器共享以学习低级通用功能;个性化深层由客户端保持私有,进行本地训练实现个性化
(2)LG-FedAvg[16],将本地学习和全局联邦训练相结合
(1) FedMD[12]:基于迁移学习(TL)和知识蒸馏(knowledge distillation,KD):对于每一轮通信,每个客户端都基于更新的共识使用公共数据集训练其模型,并在此后在其私有数据集上微调其模型。这使每个客户能够获得自己的个性化模型,同时利用其他客户的知识。
(2)FedGen[17]:生成teacher模型在FL服务器中进行训练,并广播给客户端。然后,每个客户端使用所学知识作为归纳偏差在特征空间上生成增强表示,以调节其本地学习。
(3)FedDF[18]:FL服务器构造p个不同的原型模型,每个模型代表具有相同模型体系结构 (例如,ResNet和MobileNet) 的客户端。对于每个通信回合,首先在来自同一原型组的客户端之间执行FedAvg,以初始化学生模型。然后通过集成蒸馏执行跨体系结构学习,其中在未标记的公共数据集上评估客户端 (教师) 模型参数,以生成logit输出,该logit输出用于训练FL服务器中的每个学生模型。
(4)FedGKT[19]:使用交替最小化来通过双向蒸馏方法训练小边缘模型和大服务器模型,但由于需要将本地数据的真实标签上传,存在隐私安全问题。
(5)D-Distillation[20]:体系结构不可知分布式算法。它假设有一个IoT edge FL设置,其中每个边缘设备仅连接到几个相邻设备。只有连接的设备才能相互通信。学习算法是半监督的,对私有数据进行本地训练,对未标记的公共数据集进行联合训练。对于每一轮通信,每个客户端在接收其软决策广播的同时向其邻居广播其软决策广播。然后,每个客户通过共识算法基于其邻居的软决策更新其软决策。然后,更新后的软决策通过对客户端的局部损失进行正则化来更新客户端的模型权重。此过程通过网络中相邻FL客户端之间的知识转移来促进模型学习。
• 多任务学习(multi-task learning)
• 模型插值(model interpolation)
• 聚类(clustering)
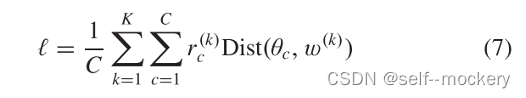
[1].N. V. Chawla, K. W. Bowyer, L. O. Hall, and W. P. Kegelmeyer, “SMOTE: Synthetic minority over-sampling technique,” J. Artif. Intell. Res., vol. 16, no. 1, pp. 321–357, 2002.
[2].H. He, Y. Bai, E. A. Garcia, and S. Li, “ADASYN: Adaptive synthetic sampling approach for imbalanced learning,” in Proc. IEEE Int.Joint Conf. Neural Netw. (IEEE World Congr. Comput. Intelligence),Jun. 2008, pp. 1322–1328.
[3].M. Kubat and S. Matwin, “Addressing the curse of imbalanced training sets: One-sided selection,” in Proc. ICML, 1997, pp. 179–186.
[4].Y. Zhao, M. Li, L. Lai, N. Suda, D. Civin, and V. Chandra, “Federated learning with non-IID data,” 2018, arXiv:1806.00582.
[5].E. Jeong, S. Oh, H. Kim, J. Park, M. Bennis, and S.-L. Kim, “Communication-efficient on-device machine learning: Federated dis-tillation and augmentation under non-IID private data,” 2018,arXiv:1811.11479.
[6].M. Duan, D. Liu, X. Chen, R. Liu, and Y. Tan, “Self-balancing federated learning with global imbalanced data in mobile systems,”IEEE Trans. Parallel Distrib. Syst., vol. 32, no. 1, pp. 59–71, Jul. 2021.
[7].Q. Wu, X. Chen, Z. Zhou, and J. Zhang, “FedHome: Cloud-edge based personalized federated learning for in-home health monitoring,”IEEE Trans. Mobile Comput., early access, Dec. 16, 2020, doi:10.1109/TMC.2020.3045266.
[8].Q. Li, B. He, and D. Song, “Model-contrastive federated learning,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2021, pp. 10713–10722.
[9]A. Fallah, A. Mokhtari, and A. Ozdaglar, “Personalized federated learning with theoretical guarantees: A model-agnostic meta-learning approach,” in Proc. NIPS, vol. 33, 2020, pp. 3557–3568.
[10]C. T. Dinh, N. Tran, and J. Nguyen, “Personalized federated learning with Moreau envelopes,” in Proc. Adv. Neural Inf. Process. Syst.(NIPS), vol. 33, 2020, pp. 21394–21405.
[11]M. Khodak, M.-F. Balcan, and A. Talwalkar, “Adaptive gradient-based meta-learning methods,” in Proc. NIPS, vol. 32, 2019, pp. 5917–5928.
[12]D. Li and J. Wang, “FedMD: Heterogenous federated learning via model distillation,” 2019, arXiv:1910.03581.
[13]Y. Chen, X. Qin, J. Wang, C. Yu, and W. Gao, “FedHealth: A federated transfer learning framework for wearable healthcare,” IEEE Intell. Syst.,vol. 35, no. 4, pp. 83–93, Jul. 2020.
[14]H. Yang, H. He, W. Zhang, and X. Cao, “FedSteg: A federated transfer learning framework for secure image steganalysis,” IEEE Trans. Netw. Sci. Eng., vol. 8, no. 2, pp. 1084–1094, Apr. 2021.
[15]M. G. Arivazhagan, V. Aggarwal, A. K. Singh, and S. Choudhary, “Fed-erated learning with personalization layers,” 2019, arXiv:1912.00818.
[16]P. Pu Liang et al., “Think locally, act globally: Federated learning with local and global representations,” 2020, arXiv:2001.01523.
[17]Z. Zhu, J. Hong, and J. Zhou, “Data-free knowledge distillation for heterogeneous federated learning,” in ICML, 2021.
[18]T. Lin, L. Kong, S. U. Stich, and M. Jaggi, “Ensemble distillation for robust model fusion in federated learning,” in Proc. NIPS, vol. 33,2020, pp. 2351–2363.
[19]C. He, M. Annavaram, and S. Avestimehr, “Group knowledge transfer:Federated learning of large cnns at the edge,” in Proc. NIPS, vol. 33,2020, pp. 14068–14080.
[20]V. Smith, C.-K. Chiang, M. Sanjabi, and A. S. Talwalkar, “Federated multi-task learning,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS),vol. 30, 2017, pp. 4427–4437.
[21]L. Corinzia, A. Beuret, and J. M. Buhmann, “Variational federated multi-task learning,” 2019, arXiv:1906.06268
[22]Y. Huang et al., “Personalized cross-silo federated learning on non-IID data,” in Proc. AAAI Conf. Artif. Intell., vol. 35, no. 9, 2021,
pp. 7865–7873.
[23]N. Shoham et al., “Overcoming forgetting in federated learning on non-IID data,” 2019, arXiv:1910.07796.
[24]F. Hanzely and P. Richtárik, “Federated learning of a mixture of global and local models,” 2020, arXiv:2002.05516.
[25]Y. Deng, M. M. Kamani, and M. Mahdavi, “Adaptive personalized federated learning,” 2020, arXiv:2003.13461
[26]E. Diao, J. Ding, and V. Tarokh, “Heterofl: Computation and commu-nication efficient federated learning for heterogeneous clients,” in Proc.ICLR, 2021, pp. 1–24.
[27]A. Ghosh, J. Chung, D. Yin, and K. Ramchandran, “An efficient framework for clustered federated learning,” in Proc. NIPS, vol. 33,
2020, pp. 19586–19597.
[28]L. Huang, A. L. Shea, H. Qian, A. Masurkar, H. Deng, and D. Liu, “Patient clustering improves efficiency of federated machine
learning to predict mortality and hospital stay time using distributed electronic medical records,” J. Biomed. Informat., vol. 99, Nov. 2019,Art. no. 103291.
[29]M. Duan et al., “FedGroup: Efficient federated learning via decomposed similarity-based clustering,” in Proc. IEEE Int. Conf Parallel Distrib. Process. Appl., Big Data Cloud Comput., Sustain. Comput. Commun., Social Comput. Netw.
(ISPA/BDCloud/SocialCom/SustainCom), Sep. 2021, pp. 228–237.
[30]M. Xie et al., “Multi-center federated learning,” 2020,arXiv:2005.01026.
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
文章目录1、自相关函数ACF2、偏自相关函数PACF3、ARIMA(p,d,q)的阶数判断4、代码实现1、引入所需依赖2、数据读取与处理3、一阶差分与绘图4、ACF5、PACF1、自相关函数ACF自相关函数反映了同一序列在不同时序的取值之间的相关性。公式:ACF(k)=ρk=Cov(yt,yt−k)Var(yt)ACF(k)=\rho_{k}=\frac{Cov(y_{t},y_{t-k})}{Var(y_{t})}ACF(k)=ρk=Var(yt)Cov(yt,yt−k)其中分子用于求协方差矩阵,分母用于计算样本方差。求出的ACF值为[-1,1]。但对于一个平稳的AR模型,求出其滞
写在之前Shader变体、Shader属性定义技巧、自定义材质面板,这三个知识点任何一个单拿出来都是一套知识体系,不能一概而论,本文章目的在于将学习和实际工作中遇见的问题进行总结,类似于网络笔记之用,方便后续回顾查看,如有以偏概全、不祥不尽之处,还望海涵。1、Shader变体先看一段代码......Properties{ [KeywordEnum(on,off)]USL_USE_COL("IsUseColorMixTex?",int)=0 [Toggle(IS_RED_ON)]_IsRed("IsRed?",int)=0}......//中间省略,后续会有完整代码 #pragmamulti_c
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
目录H2数据库入门以及实际开发时的使用1.H2数据库的初识1.1H2数据库介绍1.2为什么要使用嵌入式数据库?1.3嵌入式数据库对比1.3.1性能对比1.4技术选型思考2.H2数据库实战2.1H2数据库下载搭建以及部署2.1.1H2数据库的下载2.1.2数据库启动2.1.2.1windows系统可以在bin目录下执行h2.bat2.1.2.2同理可以通过cmd直接使用命令进行启动:2.1.2.3启动后控制台页面:2.1.3spring整合H2数据库2.1.3.1引入依赖文件2.1.4数据库通过file模式实际保存数据的位置2.2H2数据库操作2.2.1Mysql兼容模式2.2.2Mysql模式