神经网络里的标准和人脑标准相比较 相差多少的定量表达。
首先要搞明白两个概率模型是怎么比较的。有三种思路,最小二乘法、极大似然估计,交叉熵
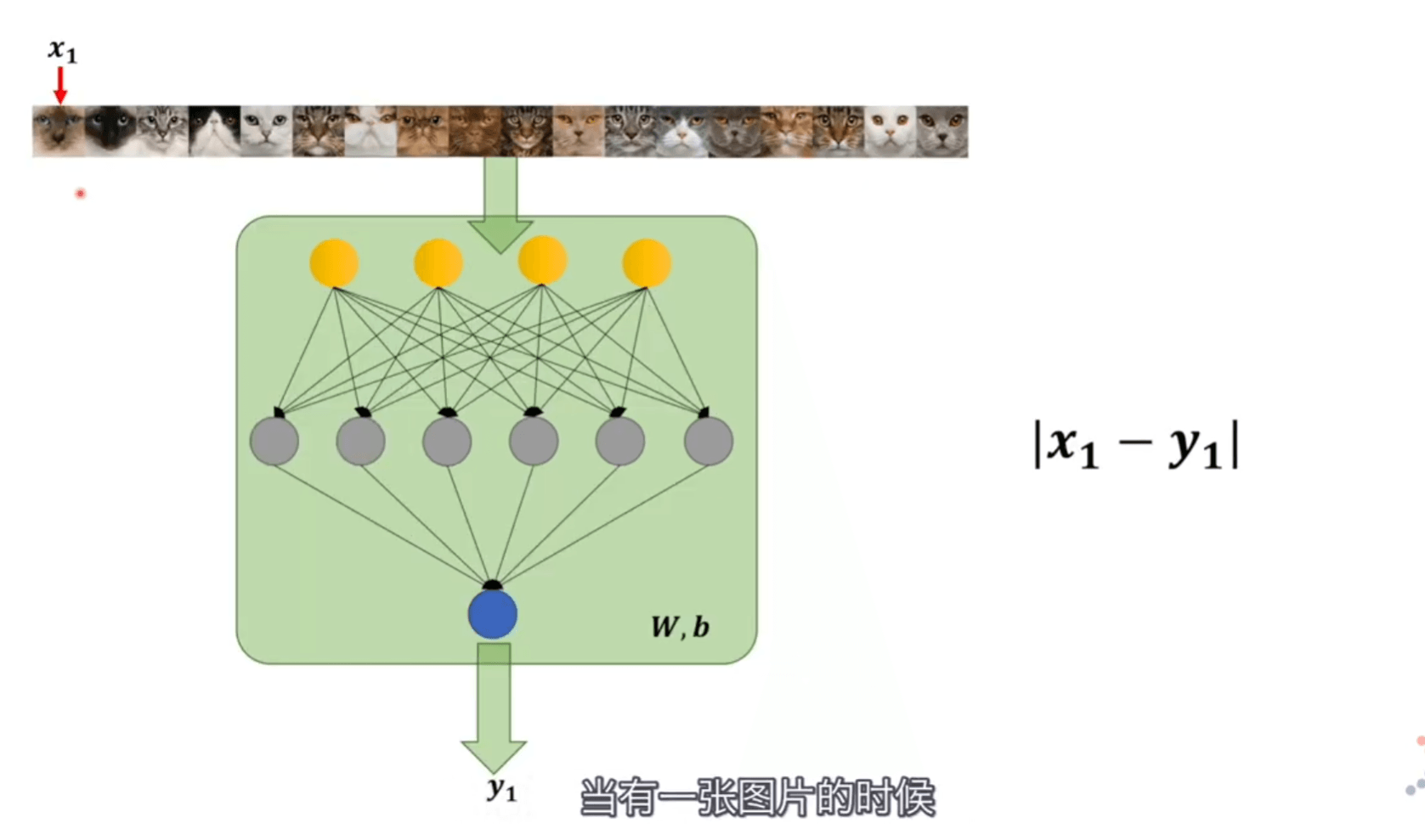
当一张图片人脑判断的结果是 \(x1\),神经网络判断的结果是 \(y1\),直接把它们相减 \(\left|x_{1}-y_{1}\right|\) 就是他们相差的范围。我们将多张图片都拿过来判断加起来,当最终值最小的时候,\(\min \sum_{i=1}^{n}\left|x_{i}-y_{i}\right|\) 就可以认定两个模型近似。
但是绝对值在定义域内不是全程可导的,所以可以求平方 \(\min \sum_{i=1}^{n}\left(x_{i}-y_{i}\right)^{2}\)
就这是最小二乘法,但是只用它判断两个概率模型差别有多少,去作为损失函数会比较困难。所以引入极大似然估计
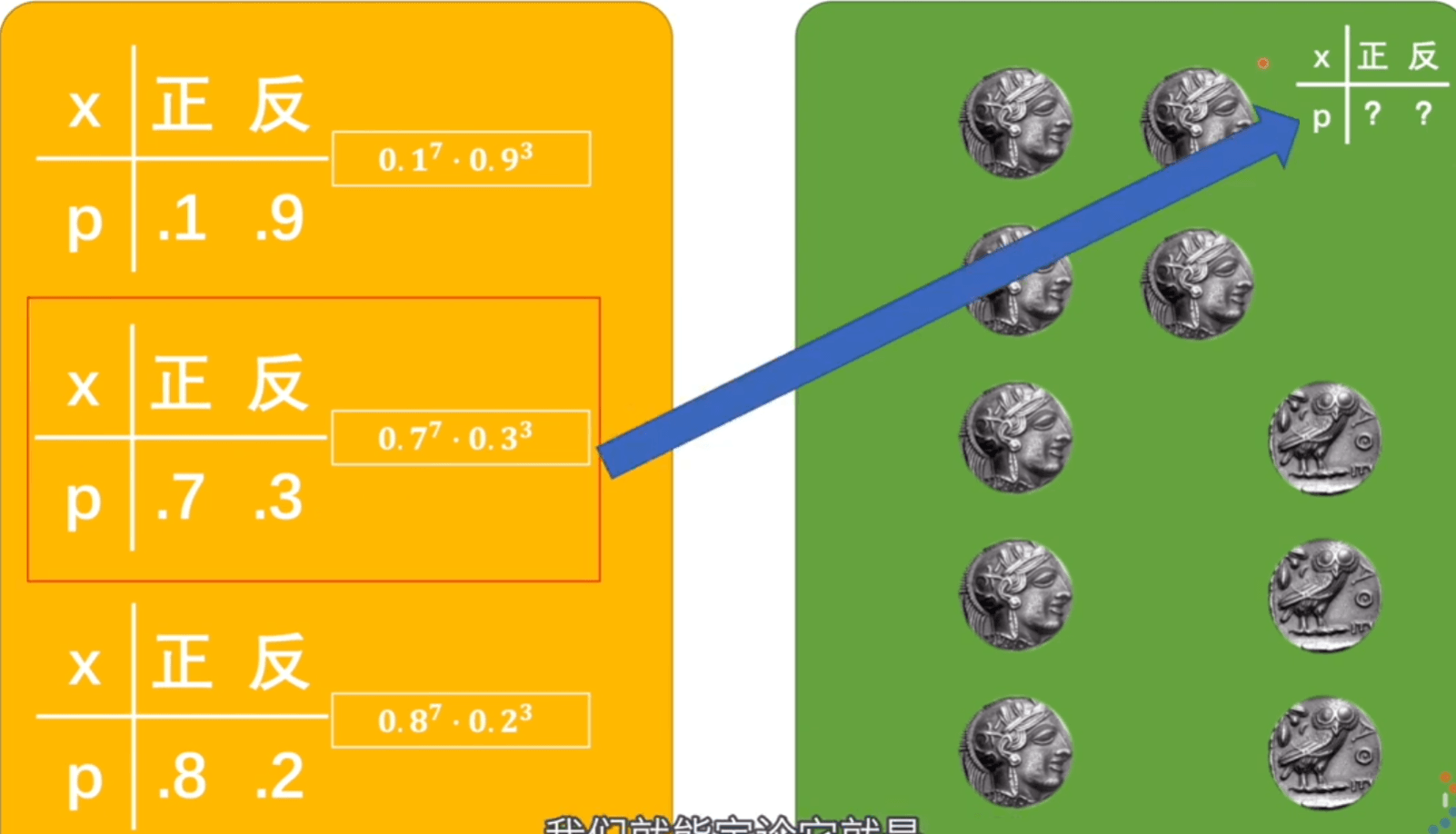
似然值是真实的情况已经发生,我们假设它有很多模型,在这个概率模型下,发生这种情况的可能性就叫似然值。
挑出似然值最大的,那可能性也就越高,此时的概率模型应该是与标准模型最接近的。
\(\theta\) 是抛硬币的概率模型,\(W,b\) 是神经网络的概率模型。前者结果是硬币是正还是反,后者结果是图片到底是不是猫。
在神经网络是这样的参数下,输入的照片如果是猫概率是多少、如果不是猫概率是多少,所有图片判断后,相乘得到的值就是似然值。取到极大似然值就是最接近的值。
但在训练的时候 \(W、b\) 无论输入什么样的照片都是固定的值,如果我们都用猫的照片来确定的话标签都是\(1\),那就没有办法进行训练,理论可行却没有操作性。但是我们还可以利用条件,训练神经网络的时候既可以得到 \(x_{i}\) 也可以得到 \(y_{i}\), \(y_{i}\) 的输出结果依赖 \(W,b\) 。每次输入照片不一样,\(y_{i}\) 的结果也就不一样。
\(x_{i}\) 的取值是 \(0、1\) ,符合二项伯努利分布,概率分布表达式为
\(x=1\) 就是图片为猫的概率。而 \(p\) 就是 \(y_{i}\) (神经网络认定是猫的概率),将其带入替换 $ P\left(x_{i} \mid y_{i}\right)$
我们更喜欢连加,在前面加 \(log\) ,并化简
所以,求极大似然值,就是求如下公式

要想直接比较两个模型,前提是两个模型类型是同一种,否则就不能公度。概率模型如果想要被统一衡量,我们需要引入熵(一个系统里的混乱程度)。
我们想获取信息量的函数,就要进行定义。并找寻能让体系自洽的公式。
将上面的第四条公式带入第三条得到如下第二条。为了使信息量定义能让体系自洽,我们给定定义 \(log\),这样符合相乘变相加的形式。
为了符合我们最直观的感觉,因为概率越小,信息量越大。而 \(log\) 函数单调递增,我们转换方向。
看计算机里多少位数据,给计算机输入一个16位数据,输入之前随便取的值是 \(1/2^{16}\) 的概率 ,输入之后的概率直接变为了 \(1\) 。信息量就是 \(16\) 比特。
信息量可以理解为一个事件从原来不确定到确定它的难度有多大,信息量大,难度高。
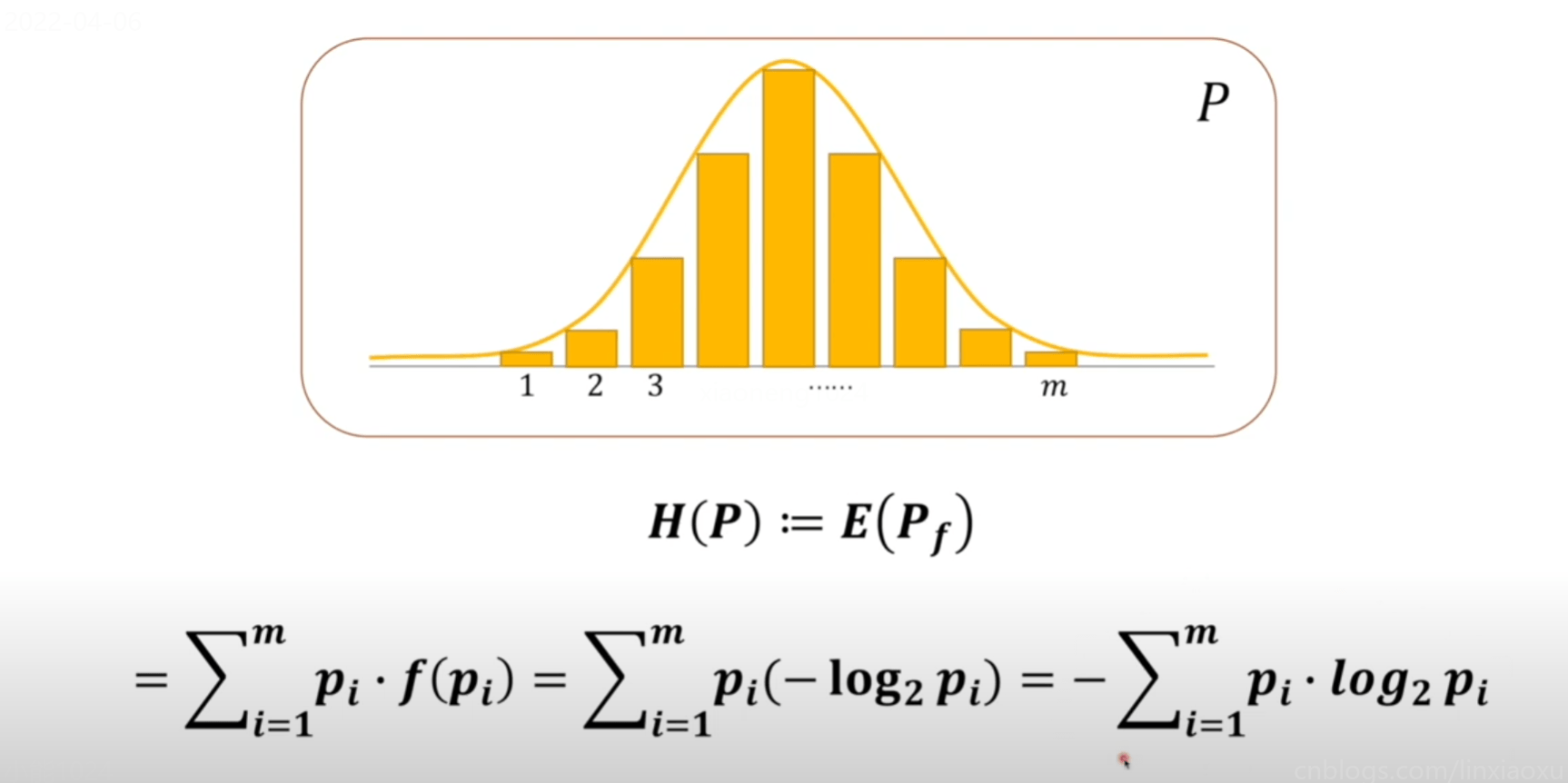
熵不是衡量某个具体事件,而是整个系统的事件,一个系统的从不确定到确定难度有多大
它们都是衡量难度,单位也可以一样都是比特。
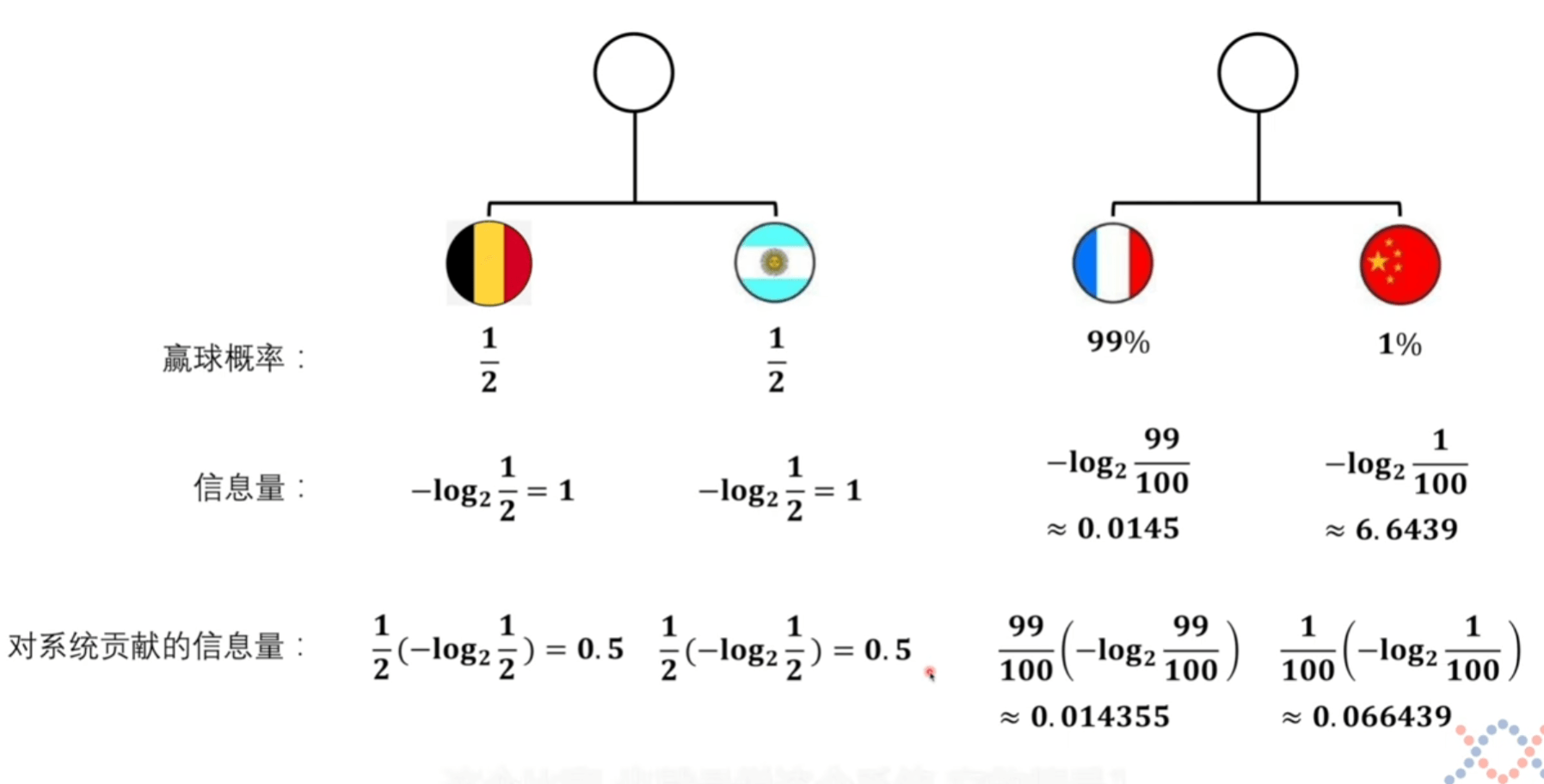
将上方对系统贡献的信息量可以看成是期望的计算。
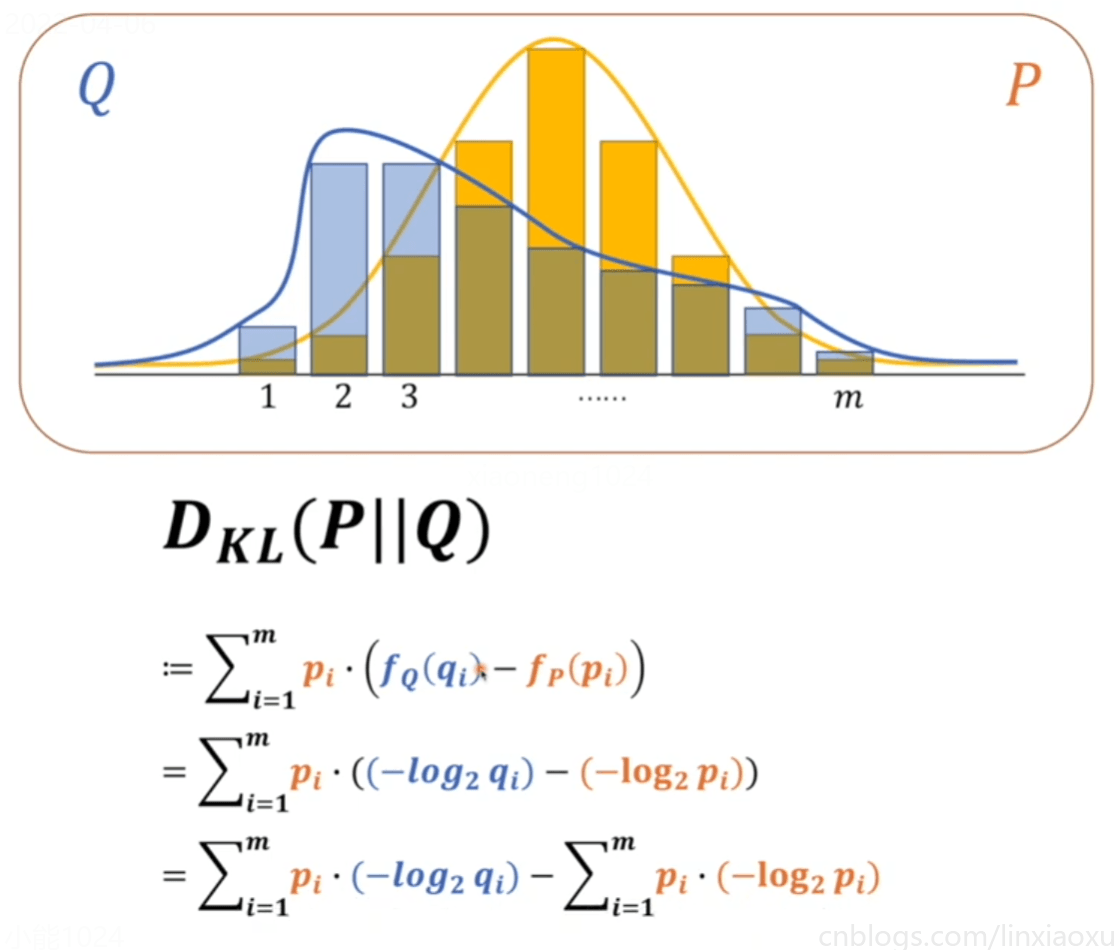

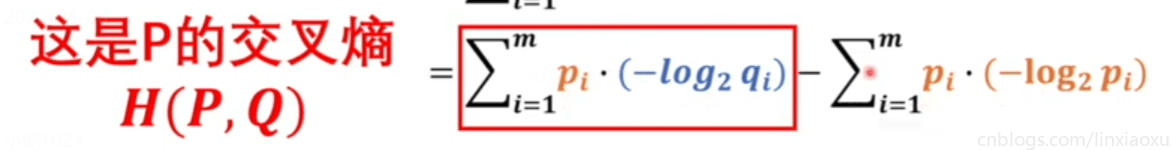
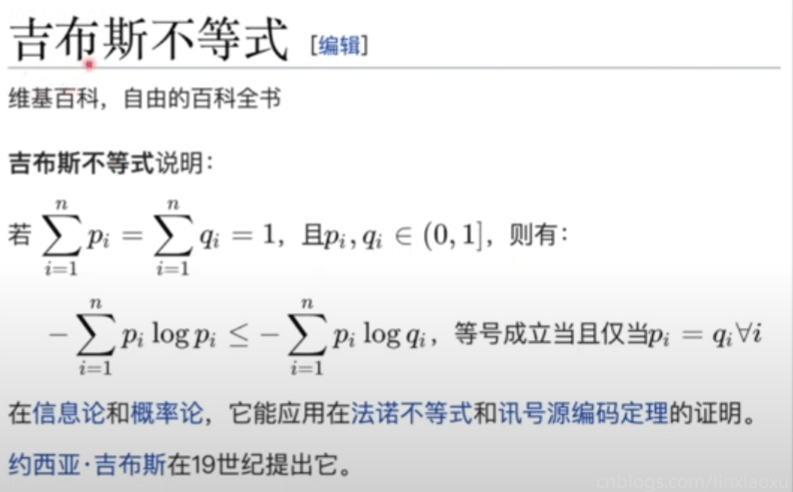
KL散度绝对是大于等于\(0\)的,当\(Q、P\)相等的时候等于\(0\),不相等的时候一定大于\(0\)
为了让\(Q、P\)两个模型接近,所以必须使交叉熵最小
交叉熵中 \(m\) 是两个概率模型里事件更多的那个,换成 \(n\) 是图片数量。
对\(m\)选择的解释:假如\(p\)的事件数量是\(m\),\(q\)的事件数量是\(n\),\(m>n\),那么写成\(∑\)求和,用较大的\(m\)做上标。就可以分解为,\(∑1到n+∑n+1到m\),那么对于\(q\)来说,因为\(q\)的数量只有\(n\),那么对应的\(q\)的部分\(∑n+1到m\)都等于\(0\)。
\(P\) 是基准,要被比较的概率模型,我们要比较的人脑模型,要么完全是猫要么不是猫。
\(x_{i}\) 有两种情况,而 \(y_{i}\) 只判断图片有多像猫,并没有去判断相反的这个猫有多不像猫,而公式里的 \(x_{i}\) 与 \(q_{i}\) 要对应起来,当 \(x_{i}\) 为 \(1\) ,要判断多像猫,当 \(x_{i}\) 为 \(0\) 的时候,要判断不像猫的概率。
最后我们推导出来,公式跟极大似然推导出来的是一样的。但是从物理角度去看两者是有很大不同的,只是形式上的一样。
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
在添加一些空格以使代码更具可读性时(与上面的代码对齐),我遇到了这个:classCdefx42endendm=C.new现在这将给出“错误数量的参数”:m.x*m.x这将给出“语法错误,意外的tSTAR,期待$end”:2/m.x*m.x这里的解析器到底发生了什么?我使用Ruby1.9.2和2.1.5进行了测试。 最佳答案 *用于运算符(42*42)和参数解包(myfun*[42,42])。当你这样做时:m.x*m.x2/m.x*m.xRuby将此解释为参数解包,而不是*运算符(即乘法)。如果您不熟悉它,参数解包(有时也称为“spl
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
有没有人用ruby解决这个问题:假设我们有:a=8.1999999我们想将它四舍五入为2位小数,即8.20,然后乘以1,000,000得到8,200,000我们是这样做的;(a.round(2)*1000000).to_i但是我们得到的是8199999,为什么?奇怪的是,如果我们乘以1000、100000或10000000而不是1000000,我们会得到正确的结果。有人知道为什么吗?我们正在使用ruby1.9.2并尝试使用1.9.3。谢谢! 最佳答案 每当你在计算中得到时髦的数字时使用bigdecimalrequire'bi
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
文章目录1、自相关函数ACF2、偏自相关函数PACF3、ARIMA(p,d,q)的阶数判断4、代码实现1、引入所需依赖2、数据读取与处理3、一阶差分与绘图4、ACF5、PACF1、自相关函数ACF自相关函数反映了同一序列在不同时序的取值之间的相关性。公式:ACF(k)=ρk=Cov(yt,yt−k)Var(yt)ACF(k)=\rho_{k}=\frac{Cov(y_{t},y_{t-k})}{Var(y_{t})}ACF(k)=ρk=Var(yt)Cov(yt,yt−k)其中分子用于求协方差矩阵,分母用于计算样本方差。求出的ACF值为[-1,1]。但对于一个平稳的AR模型,求出其滞
写在之前Shader变体、Shader属性定义技巧、自定义材质面板,这三个知识点任何一个单拿出来都是一套知识体系,不能一概而论,本文章目的在于将学习和实际工作中遇见的问题进行总结,类似于网络笔记之用,方便后续回顾查看,如有以偏概全、不祥不尽之处,还望海涵。1、Shader变体先看一段代码......Properties{ [KeywordEnum(on,off)]USL_USE_COL("IsUseColorMixTex?",int)=0 [Toggle(IS_RED_ON)]_IsRed("IsRed?",int)=0}......//中间省略,后续会有完整代码 #pragmamulti_c