目录
这篇博客主要是针对于现有的热门的激光点云处理算法pointnet++如何分类自己的数据集展开的。在介绍基本的pointnet++算法的概念、基本步骤及思想、部分代码讲解之后,会介绍如何使用自己的数据集进行分类(涉及到详细的代码改进方法及步骤)。
详细的pointnet代码可以参考这篇博客:PointNet++详解与代码_自动驾驶小学生的博客-CSDN博客_pointnet++
三维数据的表述形式一般分为四种:
① 点云:由N NN个D DD维的点组成,当这个D = 3 D=3D=3的时候一般代表着( x , y , z ) (x,y,z)(x,y,z)的坐标,当然也可以包括一些法向量、强度等别的特征。这是今天主要讲述的数据类型。

② Mesh:由三角面片和正方形面片组成。
③ 体素:由三维栅格将物体用0和1表征。
④ 多角度的RGB图像或者RGB-D图像

而又由于点云更接近于设备的原始表征(即雷达扫描物体直接产生点云)同时它的表达方式更加简单,一个物体仅用一个N × D N \times DN×D的矩阵表示,所以点云成为了众多三维数据表示方法中最重要的一种。在测绘、建筑、电力、工业甚至如今最热门的自动驾驶等领域均有广泛的应用。
pointnet的提出主要是基于点云数据的旋转不变性以及置换不变性。详细可参考:【3D计算机视觉】从PointNet到PointNet++理论及pytorch代码_小执着~的博客-CSDN博客_pointnet
其基本的网络结构如下:
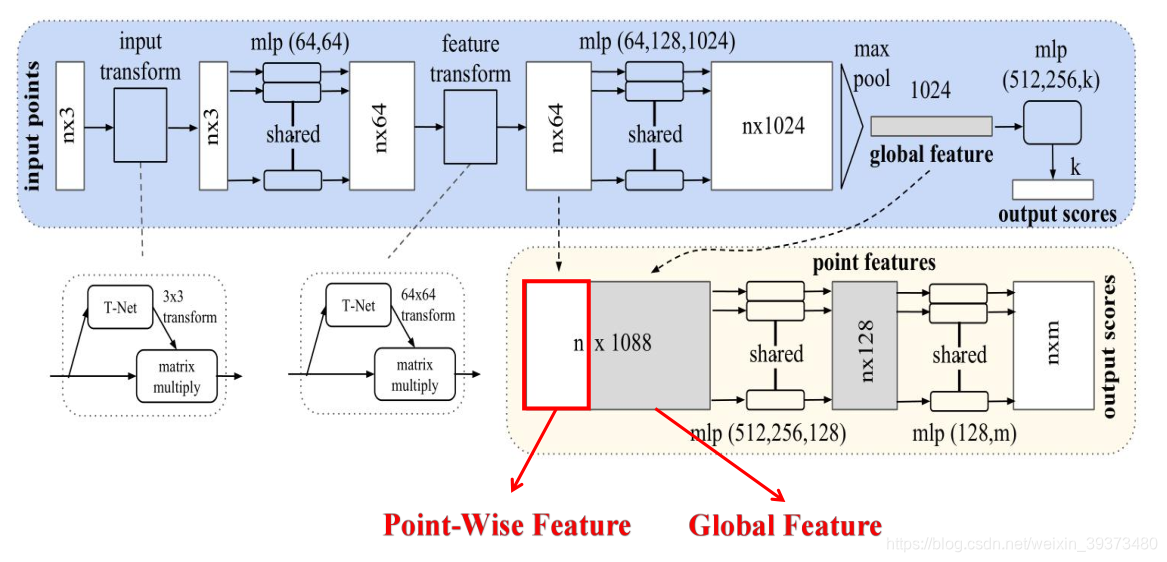
具体来说,对于每一个N × 3 的点云输入,网络先通过一个T-Net将其在空间上对齐(旋转到正面),再通过MLP将其映射到64维的空间上,再进行对齐,最后映射到1024维的空间上。这时对于每一个点,都有一个1024维的向量表征,而这样的向量表征对于一个3维的点云明显是冗余的,因此这个时候引入最大池化操作,将1024维所有通道上都只保留最大的那一个,这样得到的1 × 1024 的向量就是N个点云的全局特征。
如果做的是分类的问题,直接将这个全局特征再进过MLP去输出每一类的概率即可;但如果是分割问题,由于需要输出的是逐点的类别,因此其将全局特征拼接在了点云64维的逐点特征上,最后通过MLP,输出逐点的分类概率。
由PointNet网络结构可以看出,网络只是把全部点拼接在一起,提取一个全局特征,很少考虑一个点的领域结构,而领域是一个十分重要的概念。
PointNet不捕获由度量空间点引起的局部结构,限制了它识别细粒度图案和泛化到复杂场景的能力,简单理解就是功能不强,实际应用效果一般。
所以提出了pointnet++算法,相比于传统的pointnet算法有如下的优点:
1.一种分层的神经网络,在输入点集的嵌套分区上迭代使用PointNet。
2.利用度量空间的距离,能够利用上下文尺度的增长学习局部特征。
3.由于不同位置采集的点云数据的密度不一样,能够自适应地结合多尺度特征。
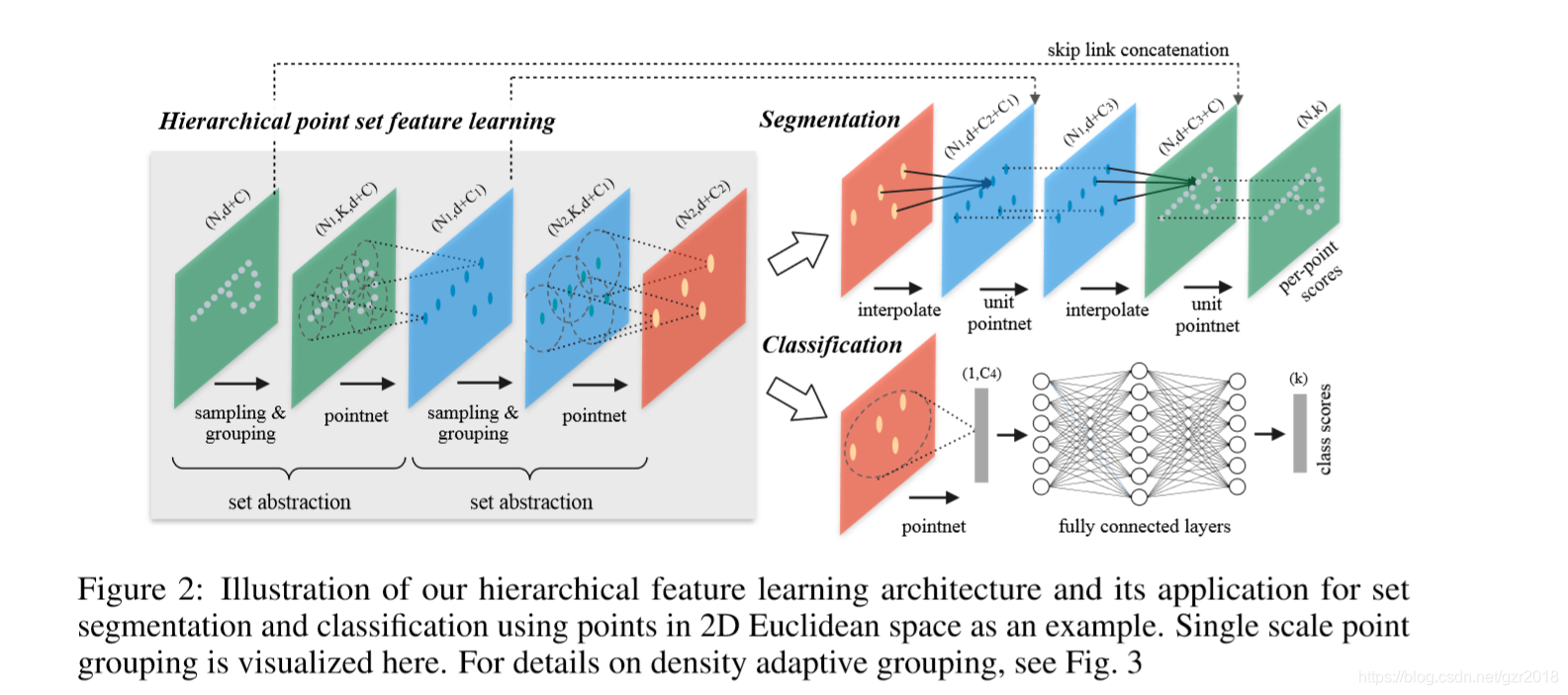
详细内容及代码讲解可以参考博客:PointNet++论文理解和代码分析 - gzr2018 - 博客园
我们都知道典型的常见的点云任务分为分割、分类、补全等,而从官网或者github上下载的数据代码中的数据集均是经典的官方数据集。如:分类多数是采用的modelnet40(即包含了车、飞机、椅子、包等的40分类的数据);分割多是采用的shapenet10。更多的点云数据集可以参考如下博客:点云数据集 资源汇总2_cugyjl的博客-CSDN博客_道路点云数据集
而我们想要利用标准的pointnet++代码跑通自己的数据集又该如何操作呢?接下来进行详细的讲解。
我们自己的数据集首先应该是点云类型的,我们通常可以在拿到数据集后利用点云可视化软件如:CloudCompare进行可视化转换,以确定其是否是我们需要的点云数据。如下图是利用CloudCompare软件打开的吉他和飞机点云输数据。


接着需要确定数据的格式:常见的点云数据均是由向量表示的。这些向量通常以X,Y,Z三维坐标的形式表示,而且一般主要用来代表一个物体的外表面形状。不经如此,除(X,Y,Z)代表的几何位置信息之外,点云数据还可以表示一个点的RGB颜色,灰度值,深度,分割结果等。在改进算法之前一定要先确定数据的格式,如标准的modelnet40中采用的就是包含了点云的方向信息的6维数据:

如果我们以点云分割为例,如何进行自己的点云数据的分割呢?
这一步骤即我们熟知的“打标签”,我们都知道二维的数据打标签的方法:即利用boundbox进行目标位置的框选,并把标注的位置标注能够区别于未标注位置的符号或者数字。如下即为常见行人检测跟踪任务中的标注方式:

而一般进行三维数据的标注一般采用CloudCompare软件进行,详细的操作步骤可以参考我的另一篇博客:如何利用CloudCompare软件进行点云数据标注_拉姆哥的小屋的博客-CSDN博客
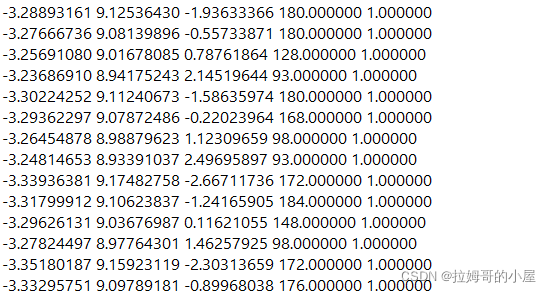
在完成数据标注之后我们就能拿到带有标签的点云数据集。下面数据的最后一列即表示人为标注后的标签1。
在点云的分割模型中可以按照点云是否分布均匀设置不同的算法,针对采样方法:大体分为单一尺度采样和多尺度采样两种。
单一尺度采样(ssg):是指传统的未经过多尺度采样而仅仅依靠初始设定的采样比例进行采样的方法。
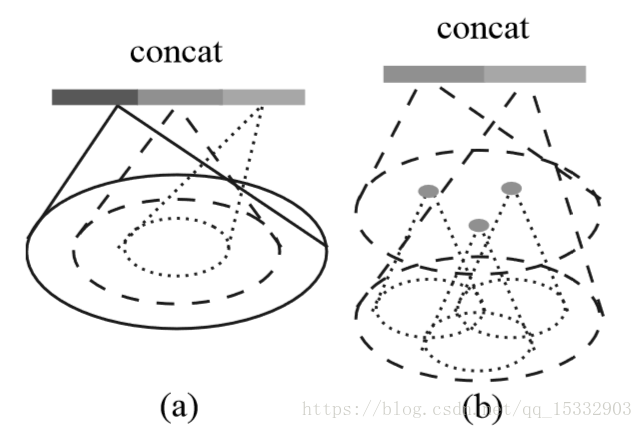
多尺度采样:又分为多尺度分组(MSG)如图(a)与多分辨率分组(MRG)如图(b)两类。
1)方案一:多尺度分组(MSG)
对于同一个中心点,如果使用3个不同尺度的话,就分别找围绕每个中心点画3个区域,每个区域的半径及里面的点的个数不同。对于同一个中心点来说,不同尺度的区域送入不同的PointNet进行特征提取,之后concat,作为这个中心点的特征。这个和图像里的spp(spatial pyrami pooling)思想类似,可以提取到不同尺度的局部特征,如图(a)即表示多尺度分组。
2)方案二:多分辨率分组(MRG)
MSG很明显会影响降低运算速度,所以提出了MRG,这种方法应该是对不同level的grouping做了一个concat,但是由于尺度不同,对于low level的先放入一个pointnet进行处理再和high level的进行concat。感觉和ResNet中的跳连接有点类似,如图(b)即表示多分辨率分组。
左边特征向量是通过一个set abstraction后得到的,右边特征向量是直接对当前patch中所有点进行pointnet卷积得到。并且,当点云密度不均时,可以通过判断当前patch的密度对左右两个特征向量给予不同权重。例如,当patch中密度很小,左边向量得到的信息就没有对所有patch中点提取的特征可信度更高,于是将右特征向量的权重提高。以此达到减少计算量的同时解决密度问题。
多尺度(MSG,MRG)和单一尺度相比(SSG)对分类的准确率没有什么提升. 如果点云很稀疏的话,使用MSG或者MRG就会获得更好的效果。
通常在官方给出的代码中会同时出现这几种点云处理模型,我们以训练效果较好的MSG算法为例给出训练自己模型的方法。
我们的点云数据可能与模型需要的数据不符,所以需要自己编写脚本进行数据的规范化。标准的点云数据处理的格式如下:
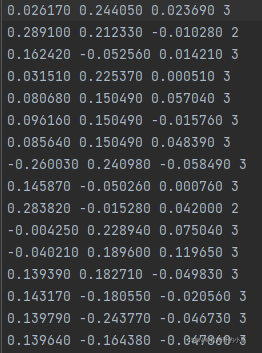
其只包含了点云的(x,y,z)坐标以及每个点对应的标签。而可能我们从CloudCompare中导出的数据有四列数据还有一列点云的强度信息:
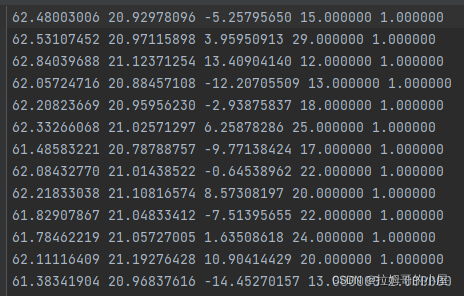
所以编写如下的脚本对多余的第四列数据进行去除(文件的具体路径自己设置):
# -*- coding:utf-8 -*-
import os
filePath = 'D:\\点云数据处理小组\\pointnet-my\\data\\shapenetcore_partanno_segmentation_benchmark_v0_normal\\03797390'
for i,j,k in os.walk(filePath):
for name in k:
print(name)
f = open(filePath+name) # 打开txt文件
line = f.readline() # 以行的形式进行读取文件
list1 = []
while line:
a = line.split()
b = a[0:3]
c = float(a[-1])
print(c)
if(float(a[-1])==36.0):
c=2
if(float(a[-1])==37.0):
c=3
b.append(c)
list1.append(b) # 将其添加在列表之中
line = f.readline()
f.close()
print(list1)
with open(filePath+name, 'w+') as file:
for i in list1:
file.write(str(i[0]))
file.write(' '+str(i[1]))
file.write(' ' + str(i[2]))
file.write(' ' + str(i[3]))
if(i!=list[-1]):
file.write('\n')
file.close()
# path_out = 'test.txt' # 新的txt文件
# with open(path_out, 'w+') as f_out:
# for i in list1:
# fir = '9443_' + i[0] # 第一列加前缀'9443_'
# sec = 9443 + int(i[1]) # 第二列数值都加9443
# # print(fir)
# # print(str(sec))
# f_out.write(fir + ' ' + str(sec) + '\n') # 把前两列写入新的txt文件
接着我们需要对划分训练集、测试集、验证集的json文件进行处理,由于我们采用的是自己的数据集,每一个txt的文件名与之前官方数据集中的文件名一定不一样,所以需要编写脚本对控制训练集、测试集、验证集读入的三个json文件进行修改。具体代码如下(路径名同样需要修改为自己的路径名):
import os
filePath = 'D:\\点云数据处理小组\\pointnet-my\\data\\shapenetcore_partanno_segmentation_benchmark_v0_normal\\03797390'
#####最后一行会出现一个, 报错!!!!!!!!!
######手动删除或改进程序
#####
file = '1.txt'
with open(file,'a') as f:
f.write("[")
for i,j,k in os.walk(filePath):
for name in k:
base_name=os.path.splitext(name)[0] #去掉后缀 .txt
f.write(" \"")
f.write(os.path.join("shape_data/03797390/",base_name))
f.write("\"")
f.write(",")
f.write("]")
f.close()最后在实际程序运行时发现会由于含0的数据过多而导致模型分类不准确,如下:
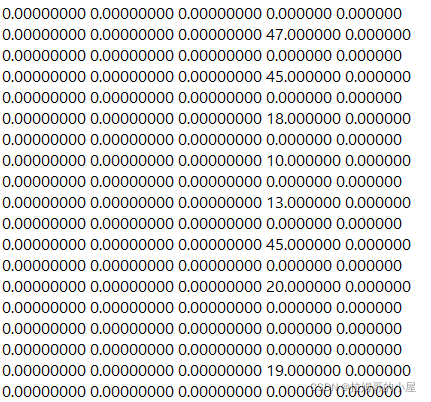
而根据具体项目的实际物理意义(这里的全0即表示未被激光探测到的位置,x,y,z坐标均标注为0),所以编写脚本程序对全0的部分进行去除:
# -*- coding:utf-8 -*-
import os
filePath = 'D:\\点云数据处理小组\\pointnet-my\\data\\shapenetcore_partanno_segmentation_benchmark_v0_normal\\03797390'
for i,j,k in os.walk(filePath):
for name in k:
list1 = []
for line in open(filePath+name):
a = line.split()
#print(a)
b = a[0:6]
#print(b)
a1 =float(a[0])
a2 =float(a[1])
a3 =float(a[2])
#print(a1)
if(a1==0 and a2==0 and a3==0):
continue
list1.append(b[0:6])
with open(filePath+name, 'w+') as file:
for i in list1:
file.write(str(i[0]))
file.write(' '+str(i[1]))
file.write(' ' + str(i[2]))
file.write(' ' + str(i[3]))
file.write(' ' + str(i[4]))
if(i!=list[-1]):
file.write('\n')
file.close()
我们打开项目文件夹下的model文件夹,选择以pointnet2_part_seg_msg为名的python文件,双击进入:
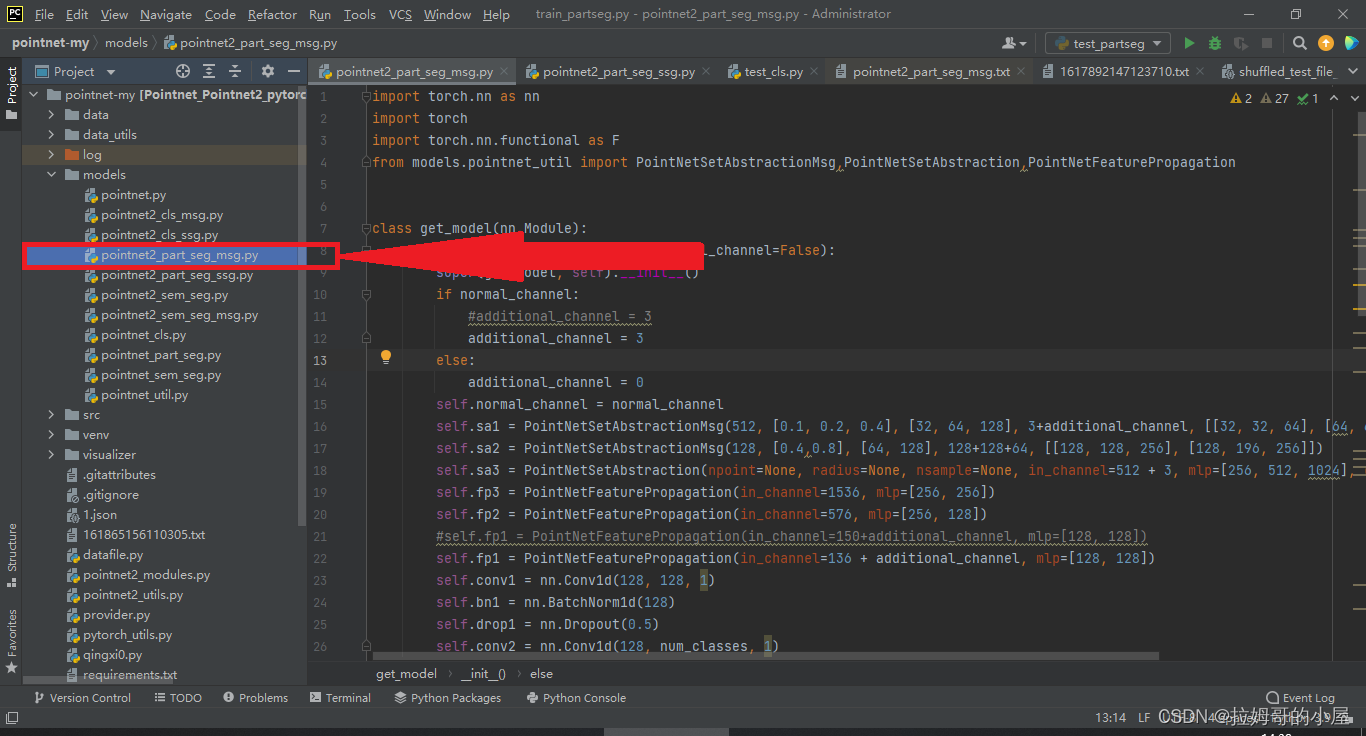
接下来我们需要修改的地方为PointNetFeaturePropagation的in_channel,具体方法为128+4*分割的总类个数,比如这里我们的分割采用的是两个物体,每个物体均为2分类,所以通道数为128+4*2=136:
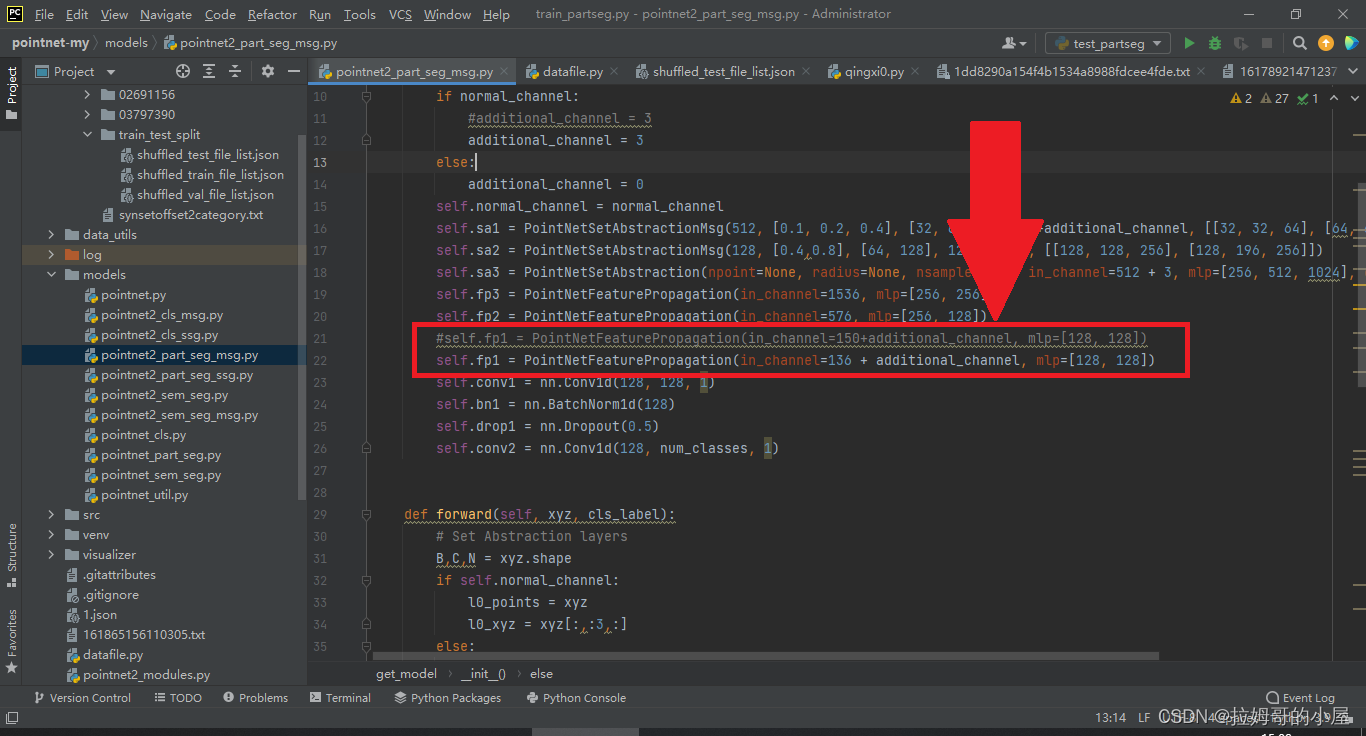
接着我们需要修改独热编码部分,将view方法中的第二个参数修改为需要被分割的物体的种类数:
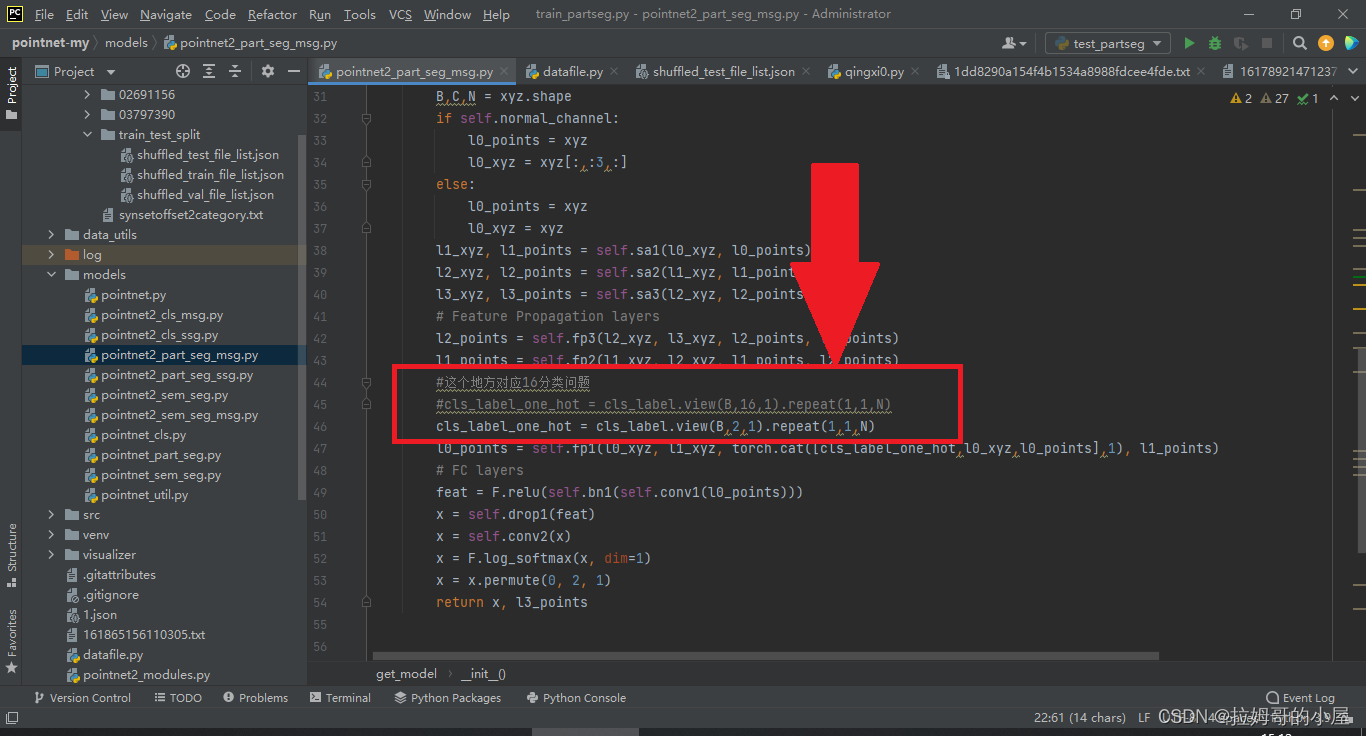
在训练模型的时候,我们需要修改要分类的对象seg_classes为我们自己的数据集对应的类别,如例子中的分类两个类别,每个类别有两个部件。(为了方便,我们保留了原来的'Airplane': [0, 1], 'Mug': [2, 3]这两个名字,同时应该注意,编号应该从0开始依次编号,若不是这样则会报错),同时应该注意自己的电脑是否支持cuda加速,如果没有GPU,则可以把代码后面所有的".cuda()"删去,程序才能正确运行。

接下来我们需要修改分割的物体总数num_classes为自己的类别个数,总共的部件数为自己的总个数:num_part。
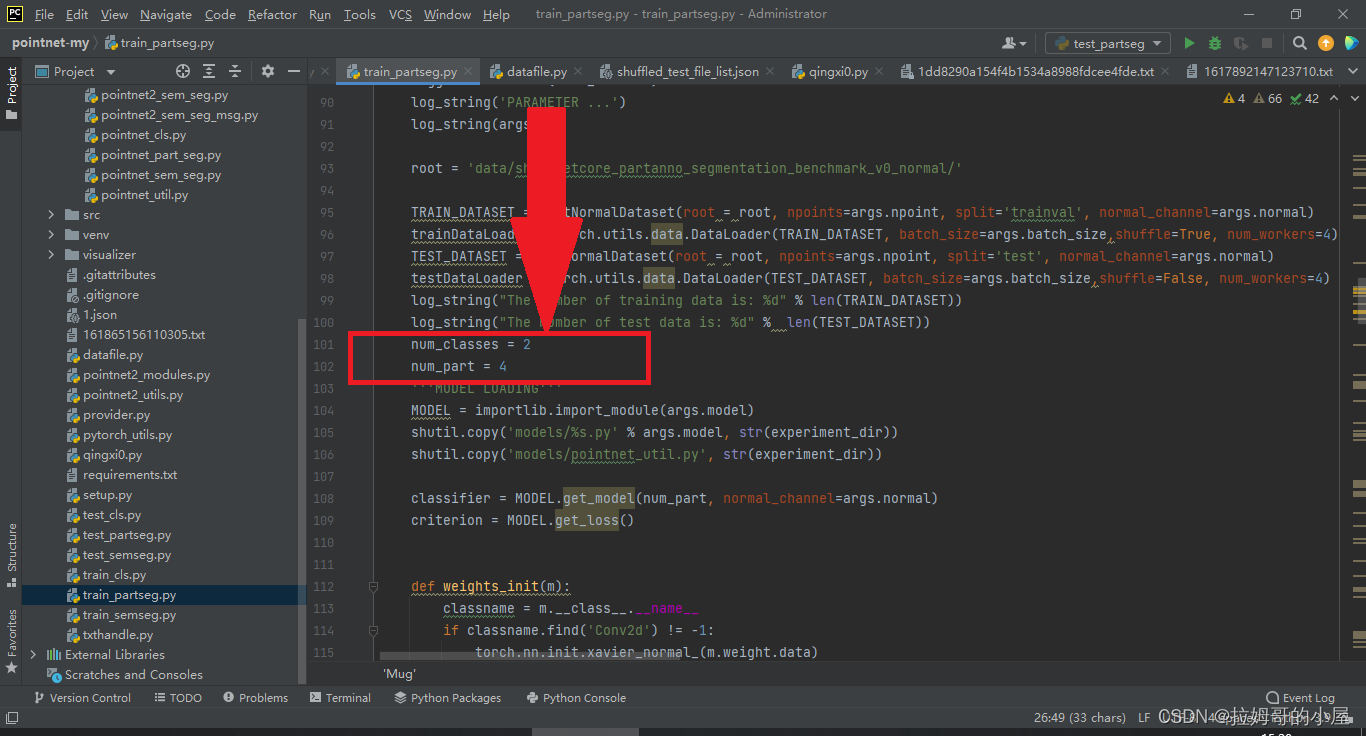
最后,右键运行程序,如果出现进度条则表明模型已经成功改进,可以跑通自己的数据集啦!
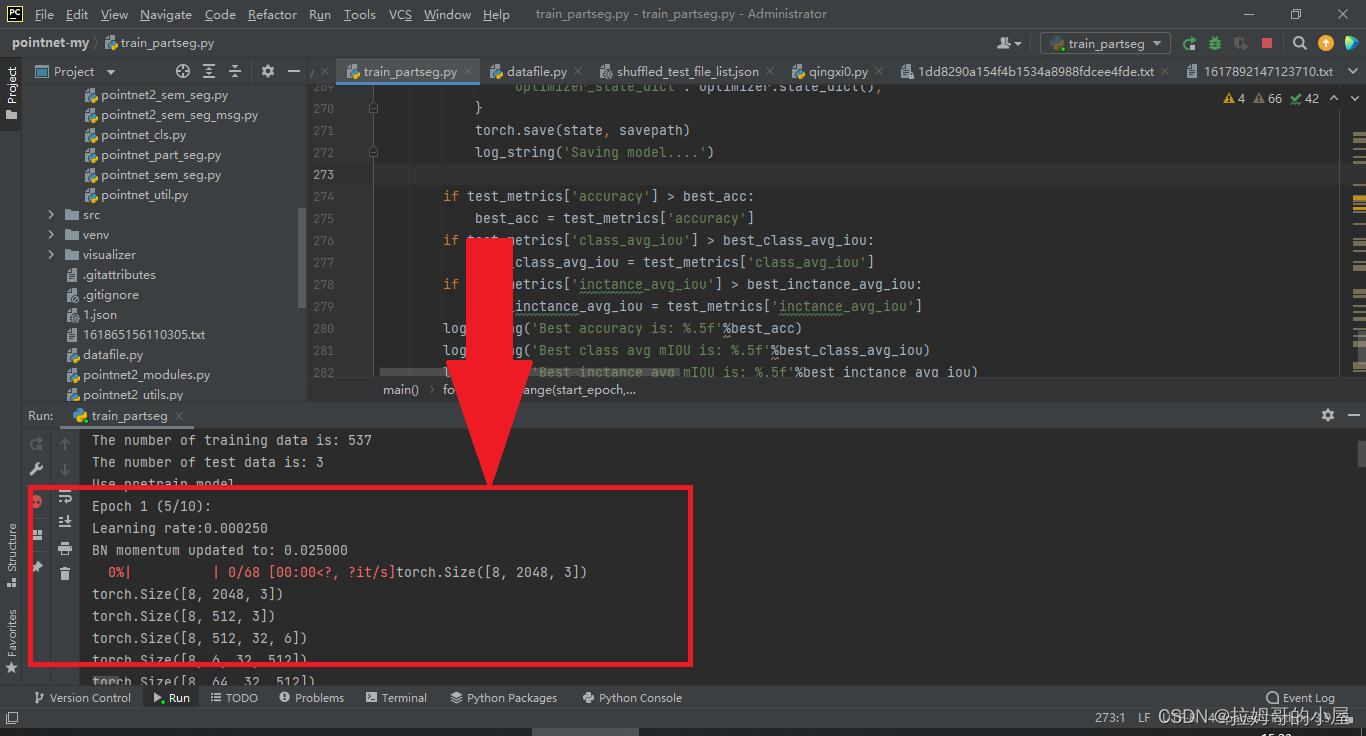
我们在用自己的数据集训练完模型后,将利用名为test_partseg的python文件进行模型的测试,为了更好的理解模型以及测试模型效果,我们有时需要打印出模型预测后的点云坐标。这里给出test_partseg文件的修改方法以及运行结果。
首先我们需要找到该python文件,接着与上面同样的修改如下图的两个地方:
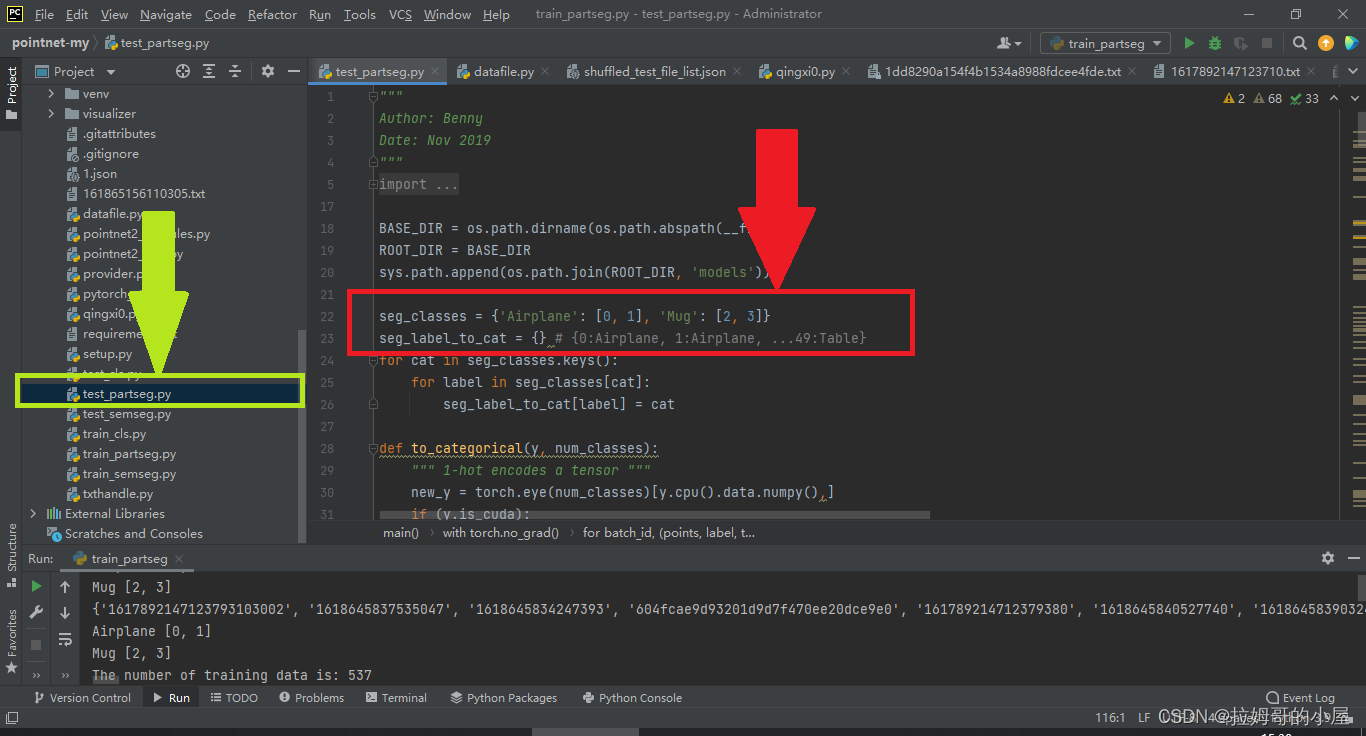
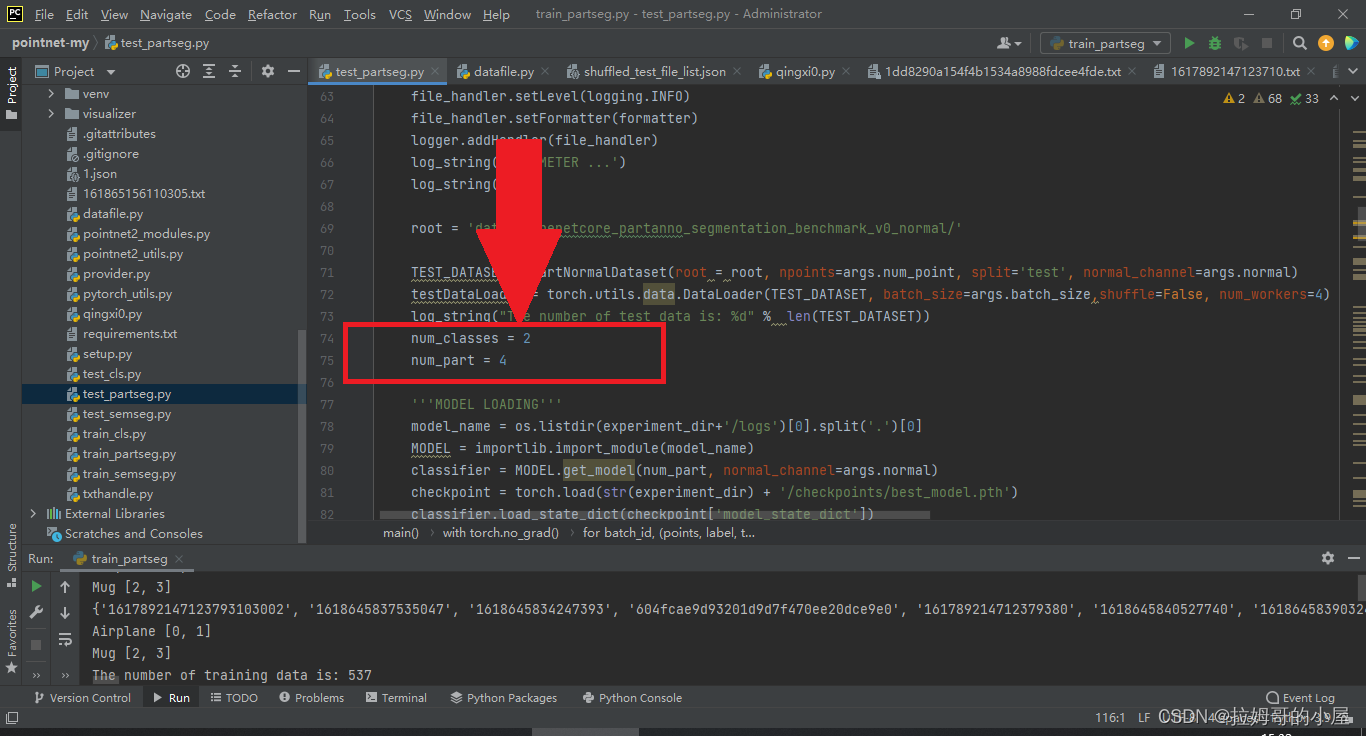
接着我们需要编写代码打印出分类后的具有不同标签的坐标,本例子中要打印两个物体的四个类别的坐标点,代码如下(部分代码):
for j in aaa:
#print(points1[i,j])
res1= open(r'E:\03797390_0_'+str(i)+'.txt', 'a')
res1.write('\n' + str(points1[i,j]).strip('[]'))
res1.close()
xxxxxx=xxxxxx+1
bbb = numpy.argwhere(cur_pred_val[i] == 1)
for j in bbb:
#print(points1[i, j])
res2 = open(r'E:\03797390_1_' + str(i) + '.txt', 'a')
res2.write('\n' + str(points1[i,j]).strip('[]'))
res2.close()
xxxxxx = xxxxxx + 1
ccc = numpy.argwhere(cur_pred_val[i] == 2)
for j in ccc:
#print(points1[i, j])
res3 = open(r'E:\02691156_2_' + str(i) + '.txt', 'a')
res3.write('\n' + str(points1[i,j]).strip('[]'))
res3.close()
xxxxxx = xxxxxx + 1
ddd = numpy.argwhere(cur_pred_val[i] == 3)
for j in ddd:
#print(points1[i, j])
res4 = open(r'E:\02691156_3_' + str(i) + '.txt', 'a')
res4.write('\n' + str(points1[i,j]).strip('[]'))
res4.close()
xxxxxx = xxxxxx + 1
修改完成后运行程序发现可以显示结果,表明修改成功!
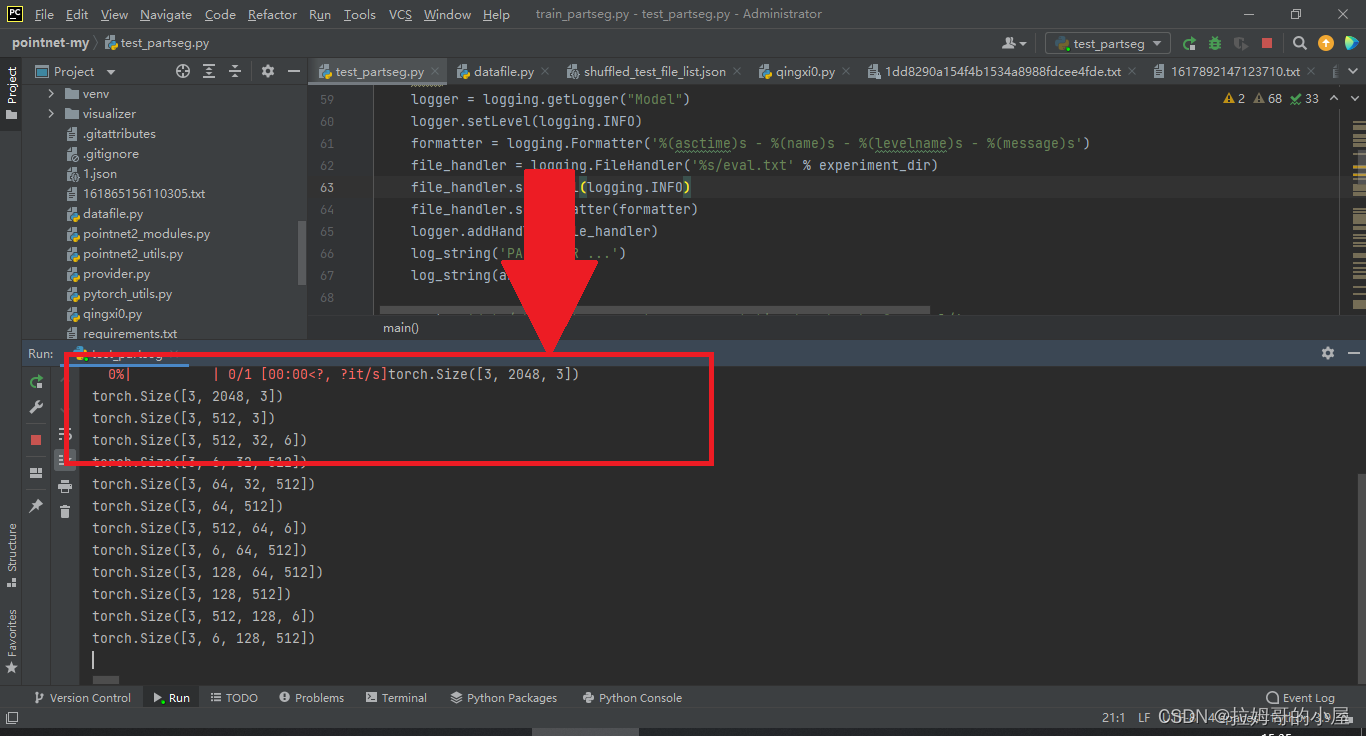
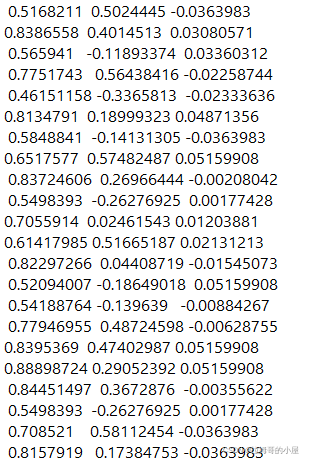
打印出的点云坐标格式如下:

最后如果需要代码或者点云数据资源的小伙伴可以私信我哦!
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我正在尝试在Rails上安装ruby,到目前为止一切都已安装,但是当我尝试使用rakedb:create创建数据库时,我收到一个奇怪的错误:dyld:lazysymbolbindingfailed:Symbolnotfound:_mysql_get_client_infoReferencedfrom:/Library/Ruby/Gems/1.8/gems/mysql2-0.3.11/lib/mysql2/mysql2.bundleExpectedin:flatnamespacedyld:Symbolnotfound:_mysql_get_client_infoReferencedf
文章目录1.开发板选择*用到的资源2.串口通信(个人理解)3.代码分析(注释比较详细)1.主函数2.串口1配置3.串口2配置以及中断函数4.注意问题5.源码链接1.开发板选择我用的是STM32F103RCT6的板子,不过代码大概在F103系列的板子上都可以运行,我试过在野火103的霸道板上也可以,主要看一下串口对应的引脚一不一样就行了,不一样的就更改一下。*用到的资源keil5软件这里用到了两个串口资源,采集数据一个,串口通信一个,板子对应引脚如下:串口1,TX:PA9,RX:PA10串口2,TX:PA2,RX:PA32.串口通信(个人理解)我就从串口采集传感器数据这个过程说一下我自己的理解,
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
前言一般来说,前端根据后台返回code码展示对应内容只需要在前台判断code值展示对应的内容即可,但要是匹配的code码比较多或者多个页面用到时,为了便于后期维护,后台就会使用字典表让前端匹配,下面我将在微信小程序中通过wxs的方法实现这个操作。为什么要使用wxs?{{method(a,b)}}可以看到,上述代码是一个调用方法传值的操作,在vue中很常见,多用于数据之间的转换,但由于微信小程序诸多限制的原因,你并不能优雅的这样操作,可能有人会说,为什么不用if判断实现呢?但是if判断的局限性在于如果存在数据量过大时,大量重复性操作和if判断会让你的代码显得异常冗余。wxswxs相当于是一个独立